机器学习与贝叶斯计算的未来

机器学习与贝叶斯计算的未来

CreateAMind
发布于 2026-03-11 18:39:04
发布于 2026-03-11 18:39:04
机器学习与贝叶斯计算的未来
Machine Learning and the Future of Bayesian Computation
https://arxiv.org/pdf/2304.11251

摘要
贝叶斯模型是研究复杂数据的有力工具,允许分析者编码丰富的层次依赖结构并利用先验信息;尤为重要的是,它们通过后验分布实现了对不确定性的完整刻画。实际的后验计算通常借助马尔可夫链蒙特卡洛(MCMC)方法进行,但对于高维模型及大量观测数据而言,该方法在计算上可能不可行。本文探讨了如何借鉴机器学习思想来改进后验计算,并通过四个具体案例(范例)展开未来可行方向的探讨:归一化流(normalizing flows)、贝叶斯核心集(Bayesian coresets)、分布式贝叶斯推理,以及变分推理。
关键词与短语:核心集(Coresets)、联邦学习(federated learning)、机器学习、归一化流、后验计算、变分贝叶斯(variational Bayes)。
- 引言 在科学、工业与政策领域中,对复杂的现实世界过程进行推理与预测引起了极大关注。贝叶斯模型之所以具有吸引力,是因为它允许构建富有表现力的生成模型,涵盖数据中的层次结构;通过先验自然地整合专家知识和/或既有研究成果;并通过后验分布与预测分布,对学习、推理与预测中的不确定性进行完整刻画。将贝叶斯统计应用于复杂现实数据时,主要障碍在于后验计算。实践中,后验计算——包括评估后验概率/期望、参数的可信区间、特征的后验包含概率、后验预测区间等——通常依赖马尔可夫链蒙特卡洛(MCMC)生成的后验样本实现。当后验分布具有复杂几何结构(例如多个相距遥远的众数,或存在几何/流形约束)时,标准MCMC方法往往难以收敛;即便对于结构简单的后验,当数据规模达到数千万甚至上亿观测时,采样也可能极具挑战性。本文聚焦贝叶斯计算的未来,尤其强调在高维、几何结构复杂、且潜在数据量达百万级的目标分布下的后验推理。
近年来机器学习取得的巨大成功,对我们构想贝叶斯计算的未来发展图景起到了关键作用。为使这一构想具体化,我们准备了四个彼此独立、涵盖前沿计算技术的范例(vignettes),均融合了机器学习的思想:第一个范例介绍归一化流(normalizing flows)作为一种针对复杂目标分布的自适应MCMC新工具;第二个范例介绍贝叶斯核心集(Bayesian coresets),作为一种采样前的数据压缩方法;第三个范例探讨面向海量数据集的分布式贝叶斯推理;第四个范例则介绍现代变分推理方法,适用于前述技术难以奏效的场景。所有章节均着重强调未来研究中富有前景的方向。
- 基于深度生成模型的采样
Metropolis–Hastings(MH)算法(常嵌套于Gibbs采样框架中)迄今仍是后验分布采样的最主流工具 [33]。其混合性能(mixing)的好坏,关键取决于MH建议分布(proposal distribution)对目标分布的逼近程度。随着目标分布维度升高、几何结构日益复杂,所需的建议分布也需具备更强的灵活性,而这使得调参愈发困难。因此,实践中通常退而采用更简单的建议分布——例如多元高斯分布——仅在局部较好地近似目标分布;参数则通过调节以促进高效探索,例如自适应学习后验协方差矩阵 [53, 139, 153],或通过离散化由目标分布驱动的动力系统(如Hamiltonian Monte Carlo)实现 [106, 86]。然而,这类局部方法的一大局限在于:实际上难以跨越低概率区域,导致对多峰分布的收敛速率极差 [90]。针对此问题,已有诸多解决方案被提出:从轻微修改局部核(kernel)以鼓励跨越低概率区域 [73, 114, 85],到构建全新的混合核——同时包含局部与全局成分 [7, 2, 129]。尽管取得上述进展,目前仍缺乏一种通用且高效的方案,用于对复杂高维分布进行采样。
我们相信,深度学习将在发展更优通用解法中发挥核心作用。深度生成模型已在估计与近似采样复杂高维分布方面展现出卓越成效,在图像/音频/视频合成、计算机图形学、物理/工程仿真、药物发现等诸多领域达到最先进水平 [56, 70]。在本范例中,我们将探讨如何利用深度生成模型设计更优的MH建议分布——既可用于增强现有核,亦可构建全新的分布。多数深度生成模型借助神经网络(NN)将一个简单基分布(如标准正态分布)进行变换,以逼近一个预先指定的经验分布。然而,将该思想应用于MH框架下的后验计算时,会面临两个实际难题: 第一,目标分布的样本在采样前尚不可得,这使得神经网络的训练过程变得复杂; 第二,MH每一步迭代均需计算接受概率,因而必须评估建议分布的密度。若建议分布是由神经网络对简单分布进行变换所得,则需对神经网络求逆(通常不可行),并计算其雅可比行列式(Jacobian)——后者在高维情形下往往数值上难以处理。
在本范例中,我们讨论通过自适应调整归一化流(Normalizing Flows, NF)建议分布,作为应对上述挑战的途径。第2.1节介绍归一化流;第2.2–2.3节涵盖其在MH中的应用及直接推广;第2.4节展望令人振奋的未来研究方向。
2.1 归一化流简介
在本节中,我们对归一化流(NFs)进行简要介绍,并强调其有用的性质。生成一类灵活提议分布的一种方法是,使用由神经网络参数化的微分同胚 f 来变换一个简单的 D 维随机变量 Z(例如,Z ~ N(0, I_D))。精心调整 f 可使得提议 Y = f(Z) 与目标分布高度吻合。在 MH 算法的每次迭代中计算接受概率需要评估提议密度,
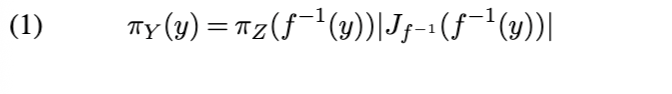

其计算复杂度为O(D)。平面流并非对所有参数和非线性激活函数的选择都可逆,然而存在高效的约束优化算法可确保其可逆性[137]。平面流的表达能力相对有限,构建合适的高维复杂提议可能需要多层堆叠。已有研究提出了改进的组件函数,包括径向流[137]、样条流[34]、耦合流[31]、自回归流[69]等。详见文献[70]对归一化流的综述,以及文献[122]关于离散流表达能力的理论分析。
连续归一化流(CNFs)[25]是离散框架的扩展,有望在增强表达能力的同时减少参数量和降低内存复杂度。其核心思想是将离散归一化流(DNFs)重新理解为一种计算粒子在离散时刻t ∈ [0, 1/K, 2/K..., 1]路径c(t)的方法。初始位置c(0)从Z中采样得到。在时刻1/K,位置更新为c(1/K) = f₁(c(0))。这一过程迭代重复,在时刻i/K从位置c(i/K)移动到时刻(i+1)/K的位置c((i+1)/K) = fᵢ(c(i/K))。最终得到路径(c(0), ..., c(1)),其终点位置即为来自Y的样本。CNFs考虑K → ∞的极限情况,其直觉是通过将Z的样本流经连续路径而非离散路径,可以获得更具灵活性的Y分布。这一思想可形式化为初值问题
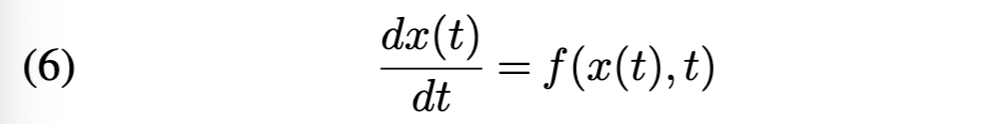

2.2 归一化流建议分布 本节概述利用归一化流(NFs)构建建议分布的现代方法。此后,我们始终以 π(y) 表示 D 维目标密度:


混合核(Mixture kernels) 通过将归一化流(NF)建议分布与经典核(classical kernels)相结合,可获得更高的初始接受率。例如,可交替使用 HMC(Hamiltonian Monte Carlo)和条件流(conditional flow)来提出样本:经典核生成的样本可用于训练和调节 NF;最终,NF 逐渐成为后验分布的良好近似,从而能够高效地提出全局性移动(global moves),实现比单独使用经典核更优的混合性能。文献 [40] 构造了一种建议机制,其确定性地交替执行——对每个独立的 NF 建议,约进行 10 次 MALA(Metropolis-Adjusted Langevin Algorithm)建议。所得到的采样器能高效探索多峰分布:MALA 在局部探索各单独峰,而 NF 则实现链在不同峰之间的“跳跃式”转移(teleportation)。关键在于:需确保采样器初始化时,每个峰中至少有一个粒子(particle),因为仅靠局部动力学本身几乎不可能发现新的峰。该算法在连续时间极限下被证明具有指数收敛速率。当流(flow)通过最小化 KL 散度进行自适应学习时,已有部分遍历性理论(ergodic theory)结果;但其他损失函数的情形尚未得到研究。
对现有核的增强(Augmenting existing kernels) 前述混合策略依赖经典核进行局部探索,直至积累足够数据以训练 NF。另一种思路则是利用 NF 增强经典核本身——即在采样链运行过程中动态改进经典核,而非训练一个独立的、辅助性的核。我们以 HMC 为例说明:HMC 中新状态 x′ 的提出过程为——先抽取动量 ν∼N(0,ID) ,再(通常使用蛙跳积分器 leapfrog integrator)近似求解对应的哈密顿动力学。该近似的一次时间步推进,首先执行动量的半步更新:

该过程重复预定次数,以生成最终的建议值;最终的动量将被丢弃。由此产生的建议分布是对称且保体积的,从而得到一个形式简洁的接受概率比。要跨越低概率区域,需要较大的速度(即动量),但若动量从高斯分布中采样,则出现大动量的概率很低。文献 [77] 利用归一化流(NFs)学习一组映射函数,用以动态地对动量和位置进行重缩放,从而促进对低概率区域的探索。具体而言,动量的半步更新被替换为:
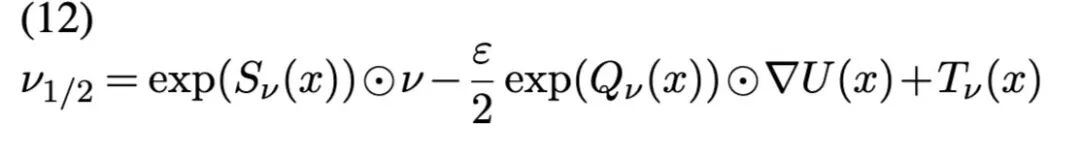

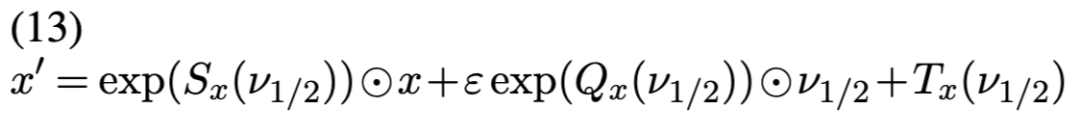
其中 Sx 、Qx和 Tx 均为归一化流(NFs)。动量再次使用公式 (12),以 x′ 替代 x 进行更新,整个过程重复迭代。当所有这些 NFs 均为零时,我们恰好恢复标准的 HMC 算法。允许这些 NFs 取非零值,将产生一个非常灵活的建议分布族,可通过重缩放和移动动量/位置,自适应地将采样器推离低概率区域。其可逆性及易于追踪的雅可比行列式(Jacobian)使得建议密度能够被高效计算。本处表述已从文献 [77] 中简化而来,原文还包含随机方向、随机遮蔽(random masking),以及在蛙跳迭代中引入条件归一化流等内容。到目前为止,上述增强技术仅应用于 HMC。然而,存在一大类动力学系统可用于生成建议分布,包括朗之万动力学(Langevin dynamics)、相对论动力学(relativistic dynamics)、Nose-Hoover 恒温器等 [86]。归一化流可采用与上述相同的配方,对所有这些算法进行增强。
2.3 建议分布的调参 对归一化流(NF)参数进行恰当调优,对于实现良好混合至关重要。实践中,调优通常通过自适应地最小化某个损失函数来实现。本节将介绍多种候选损失函数,包括测度论意义下的损失、统计摘要量(summary statistics)以及对抗式(adversarial)方法。
统计偏差(Statistical deviance) 最直接的方法是定义一个函数 d,用以度量建议分布与目标分布的接近程度,而后寻找使
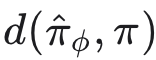
最小化的 NF 参数。设 G 为一概率密度函数空间,
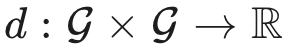
为任意衡量两个概率测度之间距离/差异/偏差的函数。我们假定:

可通过交替执行以下两步实现自适应估计:先通过 MH 生成一个样本,再利用损失函数(14)的梯度更新 NF 参数 [15]。该梯度可通过蒙特卡洛方法,利用先前的样本进行估计。在对 NF 与目标分布施加一定技术性假设的前提下,所得马尔可夫链是遍历的(ergodic),且具有正确的极限分布 [15]。
对于 d 的其他可行选择还包括:Hellinger 距离、(切片)Wasserstein 距离、全变差距离(total variation distance)等。其中许多度量目前尚未被探索用于归一化流的自适应估计,尚不清楚哪种度量能带来最佳性能。此类方法的主要局限在于:最小化分布差异只是间接地优化混合性能;接下来,我们将讨论直接以 MCMC 混合诊断量为目标的调优策略。
混合相关的摘要统计量(Mixing summary statistics)对于充分良好的混合而言,未必需要对目标分布进行高质量的全局逼近——特别是当 NF 与 HMC 等局部核联合使用时。在此类情形下,采用基于距离的损失函数显得过于雄心勃勃;相比之下,转而采用直接以良好混合为目标的损失函数,可能获得更优的实际性能。理想情况下,应最大化有效样本量(effective sample size, ESS),但该量依赖于整条马尔可夫链的历史,通常计算成本高昂。因此,文献 [77] 提出转而最小化滞后1自相关系数(lag-1 autocorrelation),这等价于最大化期望平方跳跃距离(expected squared jump distance, ESJD)[124]:

其中 λ>0 为一调节参数。该倒数项对期望平方跳跃距离较小的状态施加惩罚。[77] 还添加了一个形式相同的项,以加快预热阶段(burn-in)的收敛速度。这种复合损失被用于训练一种增强型 HMC 变体,所得到的采样器能高效地在相距较远的众数之间迁移。
其他摘要统计量亦可整合进此框架,例如考虑滞后 k 的自相关系数,或多链摘要统计量(如 Gelman–Rubin 统计量 [42])。此类损失函数的一个担忧在于:没有单一的摘要统计量能可靠判定一条链是否已充分混合;若盲目优化某一个统计量,可能导致难以察觉的病态行为(pathological behaviour)。接下来,我们将讨论另一种策略,它或可在“雄心勃勃的距离类方法”与“狭隘的摘要统计量类方法”之间取得折中。
对抗训练(Adversarial training)生成对抗网络(GANs)[47, 51] 通过极小极大博弈(minimax game)使两个神经网络相互对抗:一方为生成器(generator),负责将噪声转化为看似真实数据的样本;另一方为判别器(discriminator),负责判断任意给定样本是合成的还是真实的。GANs 可应用于 MCMC:将建议分布设为生成器,并训练一个判别器来区分建议样本与目标分布的先前采样样本。[147] 利用该思想自适应训练了一种归一化流建议分布,其在多峰分布上显著优于 HMC。
通过借鉴现代 GAN 文献中的诸多新思想,可进一步改进该方法。例如,条件 GAN(Conditional GANs)[101] 允许判别器与生成器依赖于外部变量进行条件建模。据此,可构建一种温度调节的对抗算法(tempered adversarial algorithm):通过以温度变量为条件,从而可能加速退火 MCMC(annealed MCMC)的混合速度。然而,复杂的 GAN 架构易出现模式崩溃(mode collapse)问题;因此,上述推广很可能需要结合改进的损失函数 [152, 93, 64, 163] 以及正则化技术 [52, 126, 140, 102]。
2.4 未来研究方向
我们已介绍了若干不同的核结构与损失函数,它们可相互组合,从而发展出新的自适应 MCMC 算法。本节将讨论当前方法存在的不足,并展望富有前景的长期研究方向。
理论保证(Theoretical guarantees)迄今为止,仅在最简单的情形下——即通过自适应最小化 KL 散度来调优一个独立的归一化流(NF)建议分布——存在部分遍历性理论结果 [15]。对于依赖式/条件式建议分布和增强型核,相关研究仍十分匮乏;尤其当采用摘要统计量或对抗式损失进行自适应调优时,尚无任何理论保证。这对基于摘要统计量的损失函数尤为令人担忧:目前尚不明确,仅最小化某一项指标(例如滞后1自相关)是否足以确保遍历平均值收敛至正确目标值。精确的理论结果将帮助我们理解这些方法在何种条件下成功或失败;此类理论基础是 NF 采样技术得以广泛采纳的必要前提。
约束后验(Constrained posteriors)本范例仅考虑目标分布支撑集为欧几里得空间的情形;然而在某些应用中,目标分布的支撑集为黎曼流形(例如球面或半正定矩阵空间)。当前多数流形采样算法依赖于两类动力学近似:一类定义在流形内部(intrinsic),另一类则通过对嵌入空间中的动力学进行投影诱导得出。对于多峰分布,这类基于动力学的方法可能逊于 NF 核。近期研究已成功将 NF 推广至黎曼流形,但相关构造通常对几何结构施加了较强限制(例如要求流形微分同胚于若干球面的笛卡尔积 [138]),或依赖于方差较高的雅可比项估计 [94]。此外,在流形上定义与计算建议分布与目标分布之间的距离类损失函数亦更具挑战性。发展适用于流形值变量的新型 NF 架构,并改进估计技术,有望在一大类支撑集为非欧空间的模型中实现高效采样。
我们的讨论亦未涉及离散参数。离散参数在贝叶斯应用中极为常见,例如聚类/离散混合模型、潜在类别模型及变量选择等。虽已有专门针对离散数据设计的 NF 架构 [151, 177],但现有方法灵活性有限,且无法通过简单堆叠更多神经网络层来提升表达能力,从而制约了其在 MH 框架中的实用性。一个更具前景的方向是:借助连续型 NF 的灵活性,将离散参数嵌入欧几里得空间,并对一个增广后验进行采样。已有若干 HMC 的变体被提出,以处理分段不连续的势函数 [121, 103, 32];其中,近期实现的不连续 HMC(Discontinuous HMC, DHMC)[115] 在有序变量(ordinal variables)采样中展现出卓越的实际性能。然而,基于嵌入的方法在处理无序变量(unordered variables)时仍面临困难:此时嵌入顺序具有任意性,多数嵌入方式会在增广后验中人为引入多峰性。NF 已成功用于增强连续 HMC [77] 以应对多峰分布;同样的策略有望用于改进 DHMC,提升其对无序离散变量的采样能力。
自动建议分布选择(Automated proposal selection)事先难以判断:对于某个特定后验分布的采样任务,究竟哪一种 NF 架构、核结构或损失函数能带来最高效的混合性能。若并行运行大量采用不同配置的马尔可夫链,将耗费大量时间;若其中某些链混合效果不佳,则大量计算资源将被浪费。因此,开发用于自动选择架构/核/损失函数的工具,将极大提升所述方法的可用性与普及度。
然而,这一目标在一般情形下极具挑战性,原因在于:(1)可能的采样器空间极为庞大;(2)不同架构与核之间未必具有可比性;(3)良好的混合性能无法通过单一数值摘要量准确刻画。
强化学习(reinforcement learning)、序贯决策(sequential decision making)与控制论(control theory)中的思想,或可为探索采样器空间提供具原则性的算法框架。例如,可将核/损失函数对
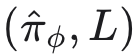
定义为状态空间,由一个智能体(agent)通过运行自适应 MCMC 与之交互。每次执行动作后,智能体可观察采样器的输出,如轨迹图(trace plots)与各类摘要统计量。其目标是:学习一种策略(policy),用于在最大化某种累积回报(例如所有链的累积有效样本量)的同时,选择下一个待运行的核/损失函数对。
作为初步尝试,可限定所有核具有相同结构(例如,仅改变 NF 架构的 HMC/NF 混合方案),并将损失函数限制为某类简单参数化族(例如,仅调节参数不同的滞后1损失函数)。如此可实现对状态空间的良好参数化,并适用现有的连续臂老虎机(continuous-armed bandit)算法 [1, 159]。而构建一种能高效探索本质上不同核结构与损失函数组合的序贯决策算法,仍是一项开放性挑战;这很可能要求我们更深入地理解各类核结构之间的理论关联,以及不同损失类型最小化后所引发的动力学行为。
我们预期:随着 NF 的广泛应用,将逐渐涌现出一些普适性规律——特定架构/核/损失函数将在某些问题类别中持续表现出色。例如,作者观察到,离散样条流(discrete spline flows)在高斯混合模型的采样任务中表现极为优异。此类经验法则可汇编为一份社区共建的参考手册,帮助统计学家迅速为其模型类别、维度、数据特征等匹配有前景的候选算法。即便机器学习研究日新月异,通过众包方式共建与维护该手册,亦可使统计学家及时跟进 NF 的最新进展。
加速调优(Accelerated tuning)本范例中提出的方案是:(1)选择一种 NF 核结构,(2)选择一个损失函数,(3)从随机初始化开始自适应地估计参数。然而,步骤(3)从随机初始化开始效率低下。迁移学习/元学习(Transfer/meta learning)可能提供工具,通过避免随机初始化来加速调优过程。例如,在迭代模型开发与敏感性分析中,通常需对稍有不同的先验设定重复进行相同的推理。为某一先验设定所估计的 NF 参数,可用于初始化其他先验设定下的采样器,从而可能消除对自适应调优的需求。


- 贝叶斯核心集(Bayesian Coresets)
大规模数据集——即单次完整遍历整个数据集计算代价高昂的数据集——如今已司空见惯。而传统的 MCMC 通常需对完整数据集进行多次遍历;在此类大规模数据场景下,这使得推理、迭代式模型开发、调参与验证过程变得繁琐且易出错。为在当代重要的实际应用中充分发挥贝叶斯方法的优势,亟需能够处理现代数据规模的高效推理算法。
过去十年中,涌现了大量针对大规模数据场景、计算高效的近似贝叶斯推理方法。其中一类方法——包括变分推理 [66, 158, 11] 与拉普拉斯近似 [145, 54]——将推理问题转化为可通过(可扩展的)随机梯度下降求解的优化问题 [57, 132]。然而,由于该问题通常非凸,上述方法往往缺乏切实可行的理论保证,且对初始化、优化超参数及优化过程中的随机性高度敏感。另一类方法——子采样 MCMC(subsampling MCMC)[9, 71, 88, 166, 3];近期综述参见 Quiroz 等 [130]——运行一个其转移步骤仅依赖于每次迭代中随机选取的数据子集的马尔可夫链。但其加速收益常被缺陷所抵消:各步中均匀子采样会导致 MCMC 要么混合缓慢,要么产生较差的近似效果 [63, 104, 10, 130, 131]。尽管可通过精心设计对数似然的有效控制变量来规避此限制(参见 Quiroz 等 [130],Nemeth 与 Fearnhead [108]),但此类设计通常高度依赖具体模型。
从根本上讲,高效处理大规模数据的问题,实质上是如何充分利用数据中冗余信息的问题。若欲基于一小部分样本对大规模数据集得出有根据的推理,则必须排除其余(大量)未检验数据中存在独特或重要新信息的可能性。一种直接将冗余性纳入其建模范式的方法是:贝叶斯核心集(Bayesian coresets)[59]。其核心思想是:用一个小规模加权子集来表征整个大规模数据集;随后,可将该核心集输入任何标准(乃至自动化)推理算法,从而以更低的计算成本实现后验推理。
核心集具备若干显著优势:第一,或许也是最重要的:核心集能保持原模型的重要结构。若原始贝叶斯后验分布具有对称性、弱可识别性、离散变量、重尾性、低维子空间结构等特性,则核心集所构建的后验通常亦保留这些特性——因为它与原模型采用相同的似然函数与先验分布。这一特性使核心集特别适用于复杂模型(例如,高斯渐近假设不成立的情形)。第二,核心集具有可组合性(composability):两个数据集的核心集通常可简单合并,从而自然形成其并集数据集的核心集 [37];这使其天然适用于流式与分布式场景 [19, 第4.3节]。第三,核心集是推理算法无关的(inference algorithm-agnostic):一旦构建完成,核心集即可直接输入绝大多数下游推理方法——特别是具有理论保证的精确 MCMC 方法——从而提升其可扩展性。第四,核心集通常附带理论保证:可明确刻画核心集大小与其后验近似质量之间的关系。
在本范例中,我们首先于第3.1与3.2节介绍贝叶斯核心集的基本原理与近期进展;继而在第3.3节探讨开放性问题及令人振奋的未来研究方向。
3.1 贝叶斯核心集简介
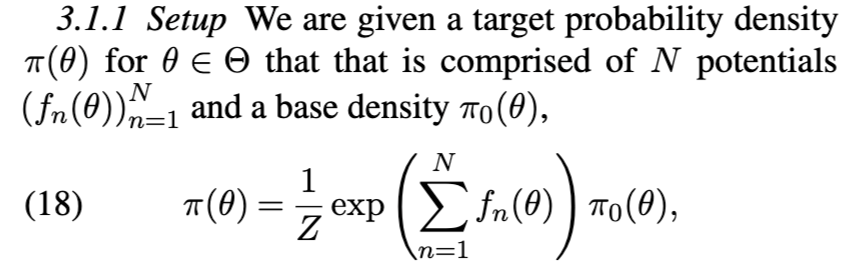

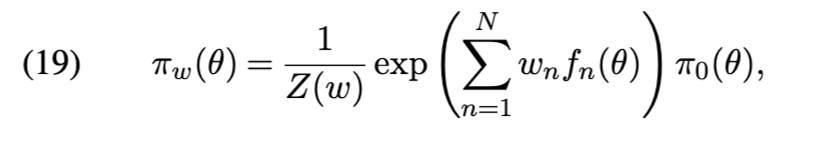

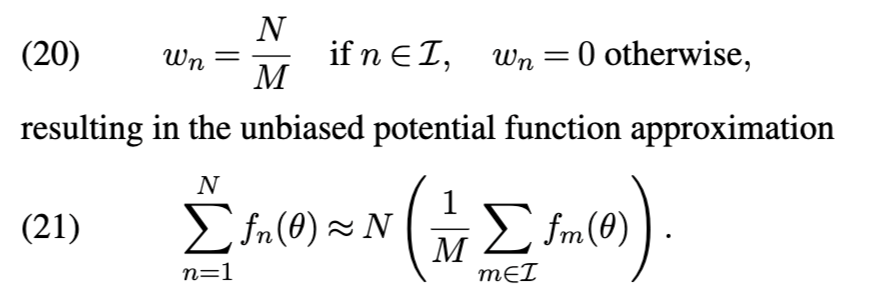
该方法简单且快速,但通常生成的后验近似效果较差。若通过非均匀概率选取数据点来构建子集,结果亦无显著改善 [59]。经验与理论结果均表明:为保持有界的近似误差,子采样所得核心集的规模必须随 NN 线性增长,因而不适合作为高效大规模推理的候选方案。因此,核心集构建通常需要更精细的优化。
稀疏回归(Sparse regression) 可将核心集构建问题表述为一个稀疏回归问题 [19, 18, 175]:
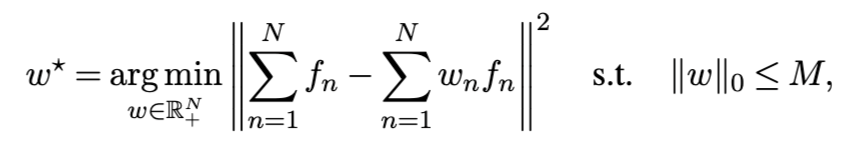

变分推理(Variational inference) 当前的前沿研究将核心集构建问题表述为在核心集族上的变分推理 [17]:
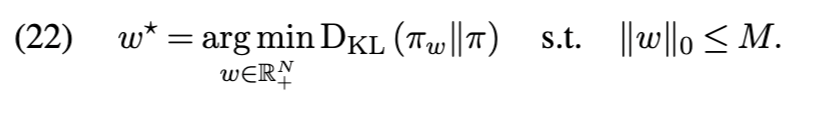
与稀疏回归公式不同,该优化问题无需专家用户输入。然而,评估 KL 目标函数(即式 (23))并非易事:

3.2 重要近期进展
贝叶斯核心集的研究尚处于早期阶段,且该领域发展迅速。此处我们重点介绍若干关键的最新进展。
核心集数据点选择(Coreset data point selection) 以往基于优化的核心集构建方法往往采用“逐点”贪心选择策略(“one-at-a-time” greedy selection),从而需要缓慢且难以调优的内外层嵌套循环结构 [19, 17]。近期工作 [23, 105, 60] 表明:可通过两步策略高效构建核心集,且不牺牲质量——首先对数据集进行均匀子采样以选定核心集点,随后对权重进行批量优化(batch optimization)。相比以往的逐点选择方法,该策略不仅显著更简单、更快速,还具备理论保证:对于具有强对数凹性或指数族似然的模型,只要核心集规模 M≳logN,则在子采样后,经最优加权的核心集后验与真实后验之间的 KL 散度在 N→∞ 时收敛于 0 [105]。需要指出的是,该保证并未说明我们是否总能找到最优权重,而仅表明:通过子采样选择核心集数据点,并不会成为限制最终可达成近似质量的瓶颈。

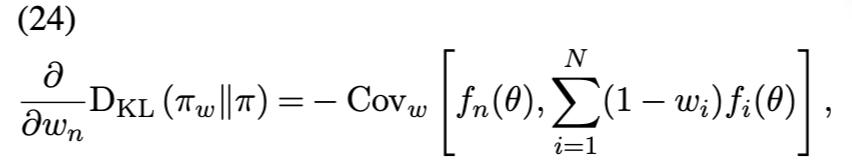

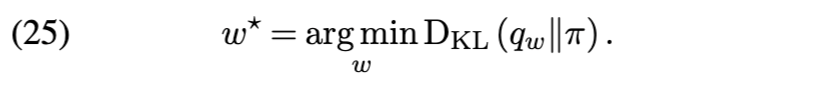

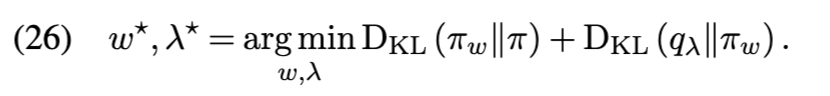

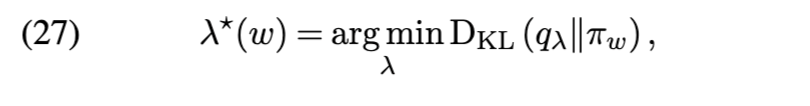
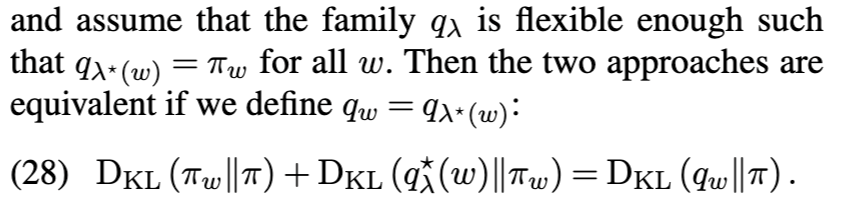

优化保证(Optimization guarantees) 尽管变分推理通常是非凸的,但核心集变分推理问题(公式 (22))却有助于提供理论保证。特别是,Naik、Rousseau 和 Campbell [105] 通过一种拟牛顿优化方案,实现了向最优核心集附近点的几何收敛:
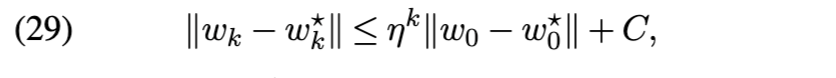

3.3 开放问题与未来研究方向
核心集构建方法与理论的近期进展,为一系列新方向的发展铺平了道路。本节将重点阐述若干重要开放问题及值得探索的研究领域。
复杂模型结构、数据与对称性 目前,核心集方法与理论正逐步在式 (18) 所示的基本模型设定(即有限维参数、条件独立同分布数据)下趋于成熟。然而,许多流行模型并不符合该框架,例如某些网络模型 [58]、连续时间马尔可夫链 [6] 等。其中部分模型的计算成本随 N 增长极快——例如高斯过程回归的复杂度为
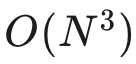
[167]——若能采用数据摘要方法,将大为受益。
即便某些模型在形式上属于式 (18) 的框架(如部分分层模型 [12]),若其潜在结构能更充分地暴露给核心集构建算法,也可能获得更优的摘要效果。换言之,仅对观测数据进行加权可能不足以捕捉模型深层依赖;将潜变量或中间表示纳入核心集构建过程,或可提升近似质量与效率。目前,如何系统性地将模型特异性结构(如层级性、交换性、稀疏性或对称性)整合进核心集设计,仍是亟待解决的问题。
在超越条件独立同分布(conditionally i.i.d.)数据设定的前提下,我们主张更广义地将此问题视为模型与数据的摘要化(model and data summarization),而非仅局限于核心集(coresets)这一具体情形。从抽象层面看,贝叶斯核心集仅是构建一类计算成本低廉、参数化的变分分布族 πwπw 的一个特例——该族可被严格证明包含真实后验 ππ(或与之足够接近的分布)。一般而言,并无理由要求此类摘要必须关联于一个稀疏加权数据子集;例如,我们可以:用子图(subgraphs)摘要网络结构 [118];用低维草图(sketches)摘要高维数据 [89];用更简洁的网络结构摘要昂贵且复杂的神经网络 [117];或用低秩随机近似(low-rank randomized approximations)摘要大型矩阵 [168];等等。
因此,亟待回答的核心问题是:对于式 (18) 以外的更复杂模型,核心集(或广义摘要化)的自然推广是什么?是否存在某种普适的底层原理,还是高效摘要化本质上是一个必须逐案解决的问题?
我们认为,解答上述问题的关键在于深入理解贝叶斯核心集、子采样、概率对称性以及统计模型中的充分性(sufficiency)之间的内在联系;参见,例如 [29, 74, 119]。实际上,贝叶斯核心集之所以可行,正是源于这样一个事实:我们可以将一小部分数据势函数(data potentials)视作“近似充分统计量”,并结合其生成过程所具有的对称性加以利用。倘若能在此方向上建立富有成效的联系,我们预期:当前基于子采样选取势函数“字典”(dictionary)、随后优化以精调近似的核心集构建方法,将可作为更一般模型下摘要化策略的良好模板。
改进的代理分布与优化方法

第一项——也是更可能实现的——目标是优化参数化代理分布本身。目前,相关方法通常涉及缓慢的内层循环优化,并依赖于基于自归一化重要性采样的高方差梯度估计。解决这两个问题将是该方法的重大进步。
第二项未来工作的重要领域——可能更具挑战性——是为通过此方法构建的核心集提供严谨的理论质量保证。主要困难在于:代理分布的优化问题与其它通用变分推理问题一样难以分析。

隐私保护、伪数据与分布式学习 分布式(或联邦式)学习指数据分散存储于多个数据中心,目标是在不传输原始数据的前提下,基于全部数据完成全局推理。目前已有适用于该场景的精确方法 [27, 21] 与近似方法 [143, 14]。此外,通常还要求各数据中心内部的数据在某种意义上对其他中心保持私密性。
核心集为分布式学习问题(包括标准情形与隐私保护情形)提供了一种潜在的极简解决方案。具体而言,核心集通常具备可组合性(composability):若对数据子集独立(且无需通信)地构建子核心集,则可简单合并得到整个数据集的核心集 [36]。核心集方法也已被拓展至隐私保护场景:或采用差分隐私方案训练伪点(pseudopoints)[92],或在共享前对核心集施加适当噪声 [38]。随后,各数据中心即可自由地相互共享其经隐私化处理的摘要,或将其提交至某个集中式节点进行统一推理。
目前已有少量初步工作探讨基于稀疏回归技术的分布式贝叶斯核心集构建 [19, 第4.3节],但该研究早于现代核心集构建方法的出现。此外,尚无文献专门系统研究分布式贝叶斯核心集(无论是否隐私保护)的理论与方法。因此,亟需回答如下问题: 我们应如何利用核心集构建的最新进展,高效构建适用于分布式学习问题的差分隐私贝叶斯核心集?在通信成本与核心集质量方面,可能达成哪些理论保证?
摊销式与极小极大核心集构建 当前贝叶斯核心集的构建方式是模型特异性的——即通过最小化式 (22) 中的 KL 目标函数完成。但在探索性分析或敏感性分析等场景中,常需评估多个候选模型;此时,须为每个模型重新调节核心集权重。由于这些重调优问题共享同一数据集,理应存在紧密关联;但如何高效构建多个相关核心集,目前仍是一个开放问题。具体而言: 核心集的泛化能力如何?是否存在一种方法,可构建一个经优化的核心集,使其适用于多个模型?能否摊销(amortize)为多个模型构建多个核心集的成本?
未来一项潜在研究方向是:构造一类类似式 (22) 的极小极大优化问题,但外层为对候选模型集合的极大化操作。沿此思路的一个关键问题是: 是否有可能用一个仅含 M≪N 个数据点的核心集,对所考虑模型中最坏情形(worst-case)仍提供合理近似?
另一种可能路径是借鉴“推理编译”(inference compilation)[75] 的思想,实现多核心集构建成本的摊销。具体而言,并非单独构建每个核心集,而是训练一个“核心集构建工件”(coreset construction artifact)——一个函数,其输入为候选模型与数据子样本,输出为核心集权重。换言之,我们学习如何构建核心集。此类工件最可能的候选形式是循环深度神经网络(recurrent deep neural network),正如推理编译等方法中常用者。该方向需考量的核心问题是:在哪些数据分析场景下,构建此类工件的前期投入,能被后续快速生成核心集权重所带来的收益所抵偿?
高维数据与模型 核心集方法最初聚焦于大规模问题中的样本数量NN 很大这一情形。但在实践中,现代大规模问题往往同时涉及高维数据与高维潜变量;其维度甚至可能随 NN 增长。已有实证表明,核心集在数据与参数维度为 10–100 的问题中效果良好;而伪核心集(pseudocoresets)[92, 91](即用合成伪数据点摘要原始数据)已成功应用于参数达 60,000 维、数据达 800 维的更大规模问题。但该领域成果仍有限,由此引出未来工作需解答的问题:
我们何时可预期核心集方法在高维数据与高维模型参数下仍普遍有效?为在该设定下获得严格理论保证,是否需对(伪)核心集方法进行修正?核心集权重优化的难度如何随维度升高而变化?

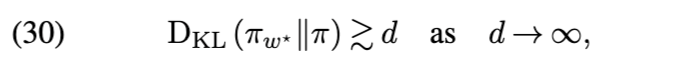
以高概率成立¹。从某种意义上讲,这并不令人意外:尽管数学形式简单,但高维情形下的高斯位置模型实属数据摘要的最坏情况——因为要张成一个 d 维空间,至少需要 d 个势函数 fn。
然而在实践中,高维数据通常并不呈现这种最坏情形行为;相反,它们往往呈现出某种更简单、更低维的结构(例如稀疏性、低秩性、流形结构等)。开发能充分利用此类结构的(伪)核心集方法,是使摘要技术真正适用于现代大规模问题的关键一步。
此外,假设核心集规模通常需随维度增长,则尚需进一步研究:随机权重优化的难度如何随维度升高而变化?值得探究的是,近年来深度学习中关于数据蒸馏(data distillation)的文献 [165] 是否蕴含可迁移至贝叶斯场景的洞见。
提升自动化水平与易用性 研究的最新进展首次使核心集成为一种实用的高效贝叶斯计算手段。但要使其为非专家用户所用,仍有许多工作要做: 首先且最重要的是,亟需开发一套通用、工程完善的核心集代码库,并与主流概率编程库(如 Stan 和 Turing [20, 41])实现良好接口。 其次,还需开发自动化方法,用于: (a) 选择核心集权重优化的调参参数; (b) 选择核心集规模; (c) 评估并汇总核心集质量。
其他散度度量 目前,所有变分核心集构建方法均以逆 KL 散度(reverse Kullback–Leibler divergence)为优化目标。一个直接的未来研究方向是:探究在式 (22) 中使用其他散度(例如 Rényi 散度 [80] 或 χ22 散度 [30])的效果。尽管这些散度很可能同样面临归一化常数 Z(w) 未知的挑战,但相较于逆 KL 散度,其他散度度量可能生成具有不同统计特性的核心集(例如更倾向于覆盖多峰、避免模式坍塌,或对尾部行为更鲁棒),值得系统性比较与探索。
- 分布式贝叶斯推理
分布式贝叶斯推理方法采用“分而治之”(divide-and-conquer)策略,以应对海量数据带来的挑战。它们利用分布式计算,降低蒙特卡洛算法的时间复杂度——尤其针对那些每次迭代均需多次遍历全部数据的算法。过去十年中,已发展出三类主要的分布式贝叶斯推理方法。
第一类方法最为简单,包含三个步骤:
- 将数据划分为互不相交的子集,并分布存储于多台机器上;
- 在所有机器上并行运行蒙特卡洛算法;
- 在中央机器上汇集来自各子集的参数抽样结果。
最后一步仅需一轮通信,因此这类方法属于单次通信学习(one-shot learning)方法 [161, 99, 107, 149, 164, 144, 100, 109, 142, 48, 27, 171, 65, 170, 98, 49, 50, 96, 28]。其核心思想在于:各子集所得参数样本提供了对真实后验分布的一种含噪近似;不同方法的区别主要在于其合并策略(combination schemes)。
第二类方法基于随机梯度 MCMC 的分布式扩展 [4, 72, 24, 35],通常以随机梯度朗之万动力学(Stochastic Gradient Langevin Dynamics, SGLD)[166, 87] 为基础。它们同样将数据划分为子集,但需在机器间进行多轮通信。每次迭代中,以一定概率选取一个子集,利用改进的 SGLD 更新规则抽取参数,并将该参数样本发送至中央机器。鉴于随机梯度方差较高且通信开销大,这推动了第三类方法的发展 [16, 127]。
第三类方法是分布式优化中全局一致性方法(如交替方向乘子法 ADMM [13, 123])的随机扩展。其流程为:将数据分片并存于各机器;在后验密度中引入辅助变量进行增广——这些辅助变量在给定参数条件下相互独立,且参数的边缘分布在特定极限假设下可还原为目标后验分布。前一假设对并行抽取辅助变量至关重要;后一条件则保障了渐近准确性。每次迭代执行同步更新:各数据存储节点并行抽取辅助变量,并将其发送至中央节点;中央节点再利用这些辅助变量抽取参数 [154, 136, 155, 127, 156]。
分布式贝叶斯方法具有三大主要优势:
- 算法无关性:多数方法可与任意蒙特卡洛算法便捷结合;
- 渐近理论保证:在较弱正则性假设下,近似后验与目标后验渐近等价;
- 可扩展性:易于拓展以适应特定应用约束,例如非参数模型中的样本聚类 [111] 与隐私保护的联邦学习 [67]。
第 4.1–4.3 节将介绍分布式贝叶斯推理的基本原理与近期进展;第 4.4 节探讨未来研究方向。
4.1 单次通信学习(One-shot learning)





局限性(Limitations) 单次通信学习方法的主要局限在于其依赖于子集后验分布的正态性假设。在某些情况下,对子集参数抽样进行缩放虽有一定帮助,但无法推广至椭圆型后验分布族以外的情形 [146, 157]。文献 [28] 指出了单次通信学习面临的另外三个问题:第一,子集后验通常难以捕捉多峰后验的支撑集(support),概率较高;第二,子集后验可能产生显著偏差,无法合理近似真实后验,从而违背另一重要假设;第三,子集后验抽样无法提供关于真实后验尾部的信息,导致尾部事件概率的估计效果较差。[28] 的一个关键观察是:机器间的通信对于提升子集后验近似精度至关重要。
4.2 分布式随机梯度 MCMC




DSGLD 的效率提升是以牺牲渐近精度为代价的。主要原因在于:较小的子集规模意味着子集内可能的子样本组合数量远小于标准 SGLD 更新中使用完整数据所能获得的数量。尽管已有研究开发出方差更小、渐近精度更高的梯度代理方法 [24, 35],但随机梯度的方差仍随 NN、KK 和数据异质性增加,导致收敛失败 [16]。
4.3 渐近精确的数据增广

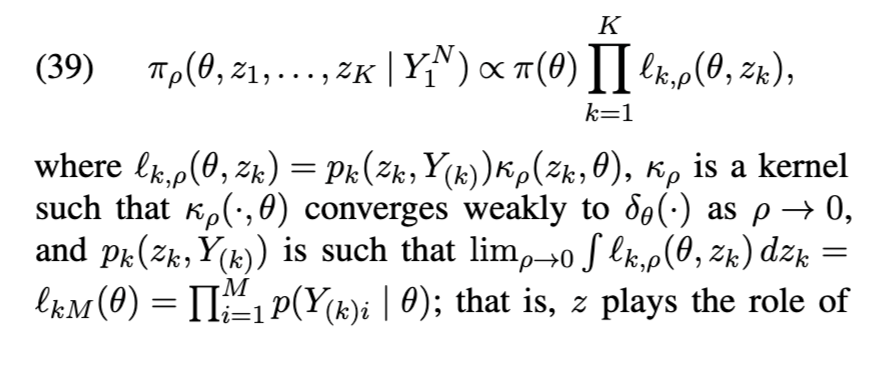
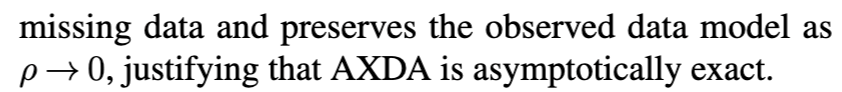

4.4 开放问题与未来研究方向
本节重点阐述分布式推断方法的局限性、重要开放问题及未来值得探索的研究领域。
高维与相依数据模型 针对独立数据模型,已有多种分布式贝叶斯推断方案;但它们难以推广至高维模型。目前关于高维模型中分布式推断方法的文献极为稀少 [65]。亟需发展能够利用高维问题中低维结构(如稀疏性、低秩性、流形结构等)的分布式方法。
多数分布式方法假设似然函数具有乘积形式(见式 (32))。然而,该假设对许多时间序列与空间模型并不成立。尽管已有适用于隐马尔可夫模型的单次通信学习方法 [162],但其仅适用于椭圆型后验分布族,无法推广;而 DSGLD 与 AXDA 算法目前尚无针对相依数据的扩展版本。
偏差与方差缩减

异步更新同步更新是 DSGLD 与基于 AXDA 的朗之万蒙特卡洛算法收敛性保证的关键;但当子集数量增大时,同步更新开销剧增,导致分布式计算的收益递减。若子集规模相近,异步更新可规避此类问题;但此时链 {θt} 不再是马尔可夫链,常规收敛性证明工具失效。异步 DSGLD 与 AXDA 扩展具有诸多实用优势。例如,[176] 已开发用于变量选择与混合效应模型的异步数据增广(DA)方法,但其向更广模型类的推广尚属未知。
广义似然函数基于广义似然函数的贝叶斯推断具备鲁棒性与目标导向推断等优势;但当前文献高度依赖分层模型的特定结构。已有初步研究探讨 AXDA 与近似贝叶斯推断之间的共性 [155]。为拓展应用,值得探索:
- 在误设模型中分布式扩展“截断后验”(cut posterior)[128];
- 基于广义似然的贝叶斯模型中的分布式推断。
应用场景分布式贝叶斯推断已在联邦学习中得到应用 [67]。此类方法特别适合多中心纵向临床研究的贝叶斯分析——因隐私限制,数据无法集中存储。目前相关应用实例仍很有限,因此,探索分布式方法的隐私保护扩展具有重要现实意义。
自动化诊断与易用性分布式方法的自动化应用与模型诊断尚未受到足够重视。单次通信学习可通过 R 的 parallel 包轻松实现 [150];但尚缺乏一种通用软件框架,以支持各类分布式算法的便捷部署。解决上述挑战,对推动分布式方法的广泛适用性至关重要。
- 变分贝叶斯
尽管前文已零星提及变分近似方法,本节特设一独立范例,专门聚焦于变分贝叶斯(Variational Bayesian, VB)方法:该方法通过在一类更简单的分布族中寻找一个成员,使其与真实后验分布之间的 KL 散度最小化,从而实现对后验分布的近似。下文将综述变分贝叶斯在理论与计算方面的若干近期进展,并展望未来研究方向。
5.1 变分贝叶斯简介

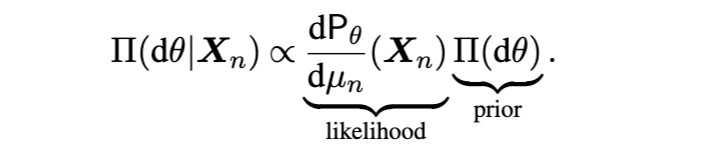


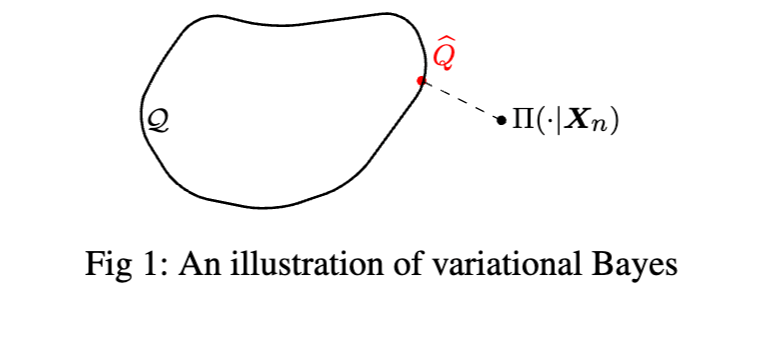

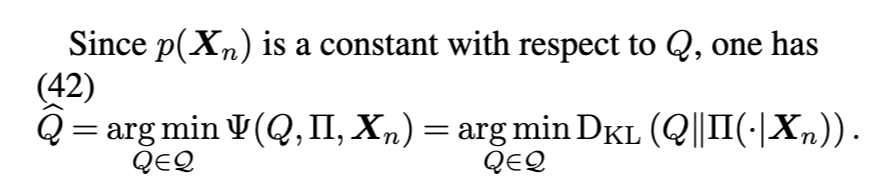

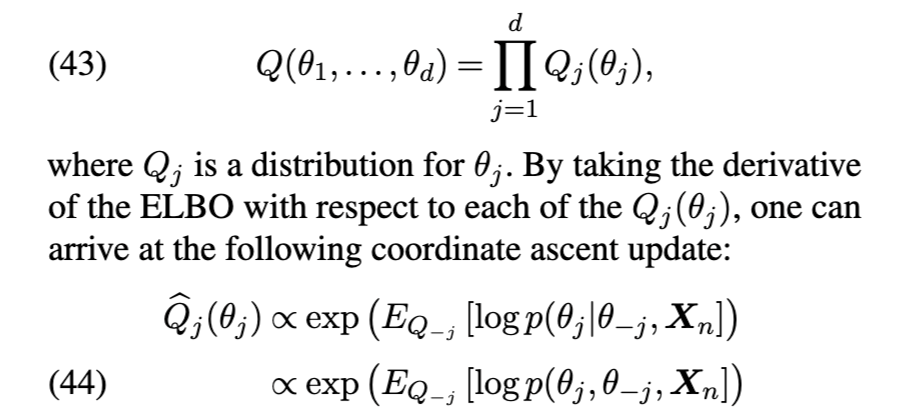

当统计模型包含潜在结构(如有限混合模型、主题模型和随机块模型)时,潜变量的维度通常与样本量同阶。对于大型数据集,CAVI 算法效率不高,因为它在每次迭代更新变分参数前需遍历整个数据集。在此背景下,随机变分推断(Stochastic Variational Inference, SVI)[57] 成为一种流行替代方案。SVI 利用小批量数据计算 ELBO 的梯度,从而采用随机梯度下降进行优化。
超越平均场类 CAVI 和 SVI 严重依赖于平均场假设,该假设排除了参数间的后验依赖性,从而导致后验不确定性的低估。这促使人们发展更复杂的变分族,但这些方法往往需要定制化的算法。黑盒变分推断(Black-box VI, BBVI)算法 [132]——包括基于梯度的黑盒 VI——已成为此类算法中的一类流行方法。文献 [62] 提出在黑盒 VI 中利用随机自然梯度,以提升效率并解决梯度估计方差过大的常见问题。

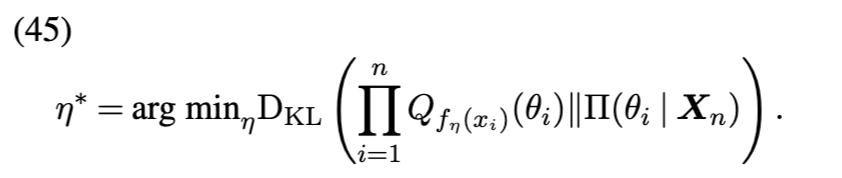

5.2 变分贝叶斯理论
为了验证贝叶斯后验的频率学最优性质(frequentist optimality properties),通常需要研究收缩速率(contraction rates)、模型选择一致性(model selection consistency)以及渐近正态性(asymptotic normality,又称 Bernstein–von-Mises (BvM) 定理)。在变分贝叶斯框架下,统计推断基于变分后验而非原始后验,因此自然有必要研究变分后验的频率学最优性。



此外,[125] 和 [173] 提出了可处理潜变量模型的变分贝叶斯理论框架。[5] 研究了似然函数被提升至分数幂次时的变分分数后验(variational fractional posteriors)的收缩性质。已有若干研究针对特定统计模型推导出变分后验的收缩速率——例如,混合模型 [26]、稀疏(高斯)线性回归 [135, 172]、稀疏逻辑回归 [134] 以及稀疏因子模型 [113]。
5.3 自适应变分贝叶斯
一项值得关注的近期进展是一种新颖且通用的变分框架,用于对多个模型空间集合进行自适应统计推断 [116]。该框架所产生的自适应变分后验不仅在后验收缩速率与模型选择方面具备最优理论性质,同时计算亦具可行性。
一般而言,在进行统计推断时,“真实参数的正则性”(regularity,例如光滑度、稀疏度、低秩性等)通常是未知的;而自适应推断(adaptive inference)的目标正是构建一类估计过程,使其在面对未知的真实正则性时仍能达到最优性能。为实现此目标,通常需预先准备若干复杂度各异的候选模型——例如:不同稀疏度的稀疏线性回归模型、不同神经元数量的神经网络,或不同组分数的混合模型——随后从中进行选择。
在频率学派框架下,实现自适应通常需在参数估计前进行(完全依赖数据的)模型选择,例如通过交叉验证或惩罚准则实现;而在贝叶斯框架下,已有研究尝试通过在多个模型空间集合上引入分层先验(hierarchical priors)以实现自适应 [44]。



自适应变分后验的计算可归约为对每个单独模型分别计算其变分近似。该框架具有普适性,可应用于大量具备多类不同复杂度子模型的统计模型中的自适应推断。当真实模型属于集合 MM 时,该自适应变分后验具有最优的收收缩速率与强模型选择一致性。该理论已被应用于多种丰富模型,并证明了其最优收缩性,包括:有限混合模型、稀疏因子模型、深度神经网络以及随机块模型。
5.4 开放问题与未来研究方向
变分贝叶斯后验的不确定性量化众所周知,变分后验倾向于低估后验不确定性。因此一个核心开放问题是:如何构建计算高效的变分后验,使其能够产出(a) 具有有效频率学覆盖(valid frequentist coverage)的可信区间(credible balls),和/或(b) 后验协方差矩阵与真实后验相匹配的结果?
目前,关于基于变分后验进行统计推断(如可信区间构造与假设检验)的理论研究极为有限。为此,我们需要一类类似于 Bernstein–von Mises(BvM)定理的极限定理——BvM 定理在一定正则性条件下保证原始后验依分布收敛于高斯分布;而我们需要的是变分后验在大样本下的极限分布刻画。[160] 在此方向上取得了初步且富有前景的结果,但对于更广泛的模型类及其对应变分族,仍亟需大量新研究。
基于梯度算法的理论保证当前针对变分贝叶斯的理论保证仅适用于变分优化问题的全局最优解。然而在实践中,该优化问题高度非凸,现有算法仅能保证收敛至局部极小值。对于某些变分族与模型类,不同局部极小值可能差异巨大,导致算法结果对初始点极为敏感。因此,为实际所用算法提供理论保证(而不仅是针对不可达的全局最优解)至关重要。例如:能否在有/无热启动(warm-start)条件下,为基于梯度的黑盒变分推断建立普适的理论保证?
在其他领域中,关于非凸优化的理论研究正持续发展,已有成果表明:在某些情形下,局部极小值可足够接近全局最优 [95, 39, 83, 78, 112]。但据我们所知,尚无任何工作系统研究变分贝叶斯所产生的局部极小值的理论性质。
基于生成模型的变分贝叶斯可利用深度生成模型(如归一化流 [137, 81])构建更丰富的变分族。凭借其卓越的表达能力,所得变分后验能高精度逼近极为广泛的靶向后验分布。尽管此类方法在实践中表现出色且实证性能强劲,目前尚无任何理论支撑——例如,尚无关于变分近似间隙(variational approximation gap)上界的理论结果,亦无关于其集中性质(concentration properties)的刻画。此外,如何选择神经网络架构及训练过程中的算法调参(如学习率、流层数、正则化强度等),以在计算效率与后验近似精度间取得最优权衡,是另一个重要且相关的问题——该问题的解决有望受益于更深入的理论理解。
在线变分推断(Online Variational Inference)给定未知参数的先验分布,后验分布可理解为观测数据后的信念更新;而更新后的后验又可作为新先验,用于接纳下一批新数据。该过程可反复进行,适用于流式数据分析 [97, 45, 68, 61]。每一步中,出于计算便利性,常使用变分后验(而非原始后验)作为新的先验 [82, 84, 110]。深入研究序列更新下的变分后验的统计性质,将是一项极具吸引力的方向。例如:其偏差是否会随时间累积?能否保证序贯近似下的长期一致性与收敛性?
- 讨论
得益于机器学习领域的近期突破,贝叶斯计算工具正以前所未有的速度演进。我们通过四个范例突显了这一现象:
- 第一个范例探讨了借助生成模型(特别是归一化流)进行采样;
- 接下来的两个范例聚焦于应对大规模样本量(large NN)的不同策略:核心集(coresets)采用变分方法压缩数据,近期方法更进一步借助深度神经网络构建灵活的代理分布族;而联邦贝叶斯学习方法则将后验计算分布于多台计算机之上;
- 最后,我们综述了变分推断(variational inference)——通过一个可追踪的近似替代真实后验。
类似主题尚可延伸出更多范例,例如:利用基于扩散的生成模型加速采样,或借助深度神经网络进行数据压缩以提升近似贝叶斯计算(ABC)的效率。
本文以三大共同主题作结——我们相信这些方向应在未来获得广泛关注,且适用于上述所有范例:
- 利用既有计算加速新推断;
- 通过新型软件提升方法的自动化水平与易用性;
- 为实证表现优异的算法提供坚实的理论支撑。
当前贝叶斯计算的常态是:每次后验推断均从零开始——例如,仅因先验稍作改变便需重新计算核心集;或将旧模型应用于新数据时,又需重新拟合一个变分近似。这种做法效率低下,因为相似模型的后验推断结果理应对当前模型的推断具有启发意义。若两个模型可直接比较(如仅先验略有不同),则易于复用既有计算(例如在优化中采用热启动)。但当模型维度不同(如在分层模型中增加一层参数)时,问题便变得棘手。我们期待:机器学习中处理类似问题的方法——尤其是迁移学习(transfer learning)——将为贝叶斯领域提供通用解决方案的突破口。
另一共性主题是对提升自动化与可及性的迫切需求。稳健可靠地实现涉及神经网络或其他机器学习技术的方法并非易事,通常需耗费大量时间与专家知识。鉴于机器学习发展迅猛,精心构建的实现可能尚未普及便已过时。因此,重点应放在开发兼具模块性与用户友好性的软件上:模块性使其足以抵御下一次机器学习革命的冲击;用户友好性则确保其可被大规模广泛应用。
最后,统计学家应警惕盲目采纳仅追求实用性能而牺牲理论保证的方法。那些虽计算迅速、却可能与真实后验任意偏离的后验“近似”,或许适用于黑箱预测任务,但在需要可靠、可复现的贝叶斯推断的场景中远远不够——尤其在科学与政策制定中,我们亟需恰当地刻画从数据中学习时的不确定性,并正视实践中涌现的复杂性(如模型不确定性、数据污染等)。理论保证对于避免严重误导性推断、防止从当前科学界常规产生的大规模复杂数据中得出灾难性结论,至关重要。
原文链接:https://arxiv.org/pdf/2304.11251
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号