AGI 技术安全性探讨(1-3章)

AGI 技术安全性探讨(1-3章)

CreateAMind
发布于 2026-03-11 17:48:39
发布于 2026-03-11 17:48:39
An Approach to Technical AGI Safety and Security
AGI 技术安全性探讨
https://www.researchgate.net/publication/390440085_An_Approach_to_Technical_AGI_Safety_and_Security




人工通用智能(AGI)承诺带来变革性的益处,但也伴随着重大风险。 我们提出一种方法,以应对可能对人类造成严重伤害的风险。我们识别出四个风险领域:滥用、目标不一致、错误以及结构性风险。在这些风险中,我们重点关注针对滥用和目标不一致的技术应对措施。对于滥用问题,我们的策略旨在防止威胁行为者获取危险能力,方法包括主动识别这些危险能力,并实施强有力的安全措施、访问限制、监控机制以及模型安全缓解手段。为应对目标不一致问题,我们提出了两道防御措施。第一,模型层面的缓解措施,例如增强监督和鲁棒训练,有助于构建符合人类意图的模型。第二,系统层面的安全措施,例如监控和访问控制,即使模型存在目标不一致,也能减轻潜在危害。来自可解释性、不确定性估计以及更安全设计模式的技术,可以增强这些缓解措施的有效性。最后,我们简要概述了如何将这些要素结合起来,为AGI系统构建安全性论证。
扩展摘要 人工智能,特别是人工通用智能(AGI),将是一项具有变革性的技术。与任何变革性技术一样,AGI在带来巨大效益的同时,也伴随着重大风险。其中包括造成严重伤害的风险:即后果足以对人类造成重大损害的事件。本文阐述了我们构建避免此类严重伤害的AGI的方法。
由于AGI安全研究正在快速发展,本文提出的方法应被视为探索性的。我们预期该方法将随着人工智能生态系统的演进而不断演进,以纳入新的思想和证据。
对于可能造成严重伤害的风险,必须采取预防性措施,但这会面临一个“证据困境”:在我们尚未清楚掌握引发这些风险的技术能力之前,就必须开展风险缓解的研究与准备工作。我们主张采取主动和谨慎的态度,提前预见潜在风险,即使这些风险尚未明显显现。这有助于我们从长远角度制定更全面、更充分的应对策略。
尽管如此,我们仍优先关注那些我们能够预见其所需能力如何产生的风险,而将更为 speculative(推测性)的风险留待未来研究。具体而言,我们聚焦于通过梯度下降学习在基础模型中涌现出的能力,并参考Morris等人(2023)提出的“卓越级AGI”(Exceptional AGI,第4级),将其定义为:在广泛的非物理任务上,其表现达到或超过99%熟练成年人水平的人工智能系统。这意味着我们的方法涵盖对话系统、具身代理系统、推理能力、新概念的学习以及部分递归改进能力,而将目标漂移和超级智能带来的新型风险留作未来研究方向。
我们重点关注那些能够提供缓解严重伤害方案的技术研究领域。然而,这仅是问题的一半:技术解决方案必须与有效的治理机制相辅相成。尤其重要的是,在适当的标准和最佳实践方面达成更广泛的共识,以防止因竞争压力而导致安全标准的“逐底竞争”。我们希望本文能够为建立这种共识迈出有意义的一步。
背景假设在制定我们的方法时,我们权衡了不同选项的优缺点。例如,某些安全方法可能提供更强大、更通用的理论保障,但目前尚不清楚它们能否及时准备就绪;而另一些方法则更偏向临时性、经验性,能够更快部署,但可能存在粗糙或不完善之处。
为了做出这些权衡,我们很大程度上依赖于一些关于AGI将如何被开发出来的背景假设和信念:
- 无人类能力上限:在当前范式(广义理解下),我们并未发现任何根本性障碍会将人工智能系统的能力限制在人类水平。因此,我们认为更强大的能力是完全可能的,必须认真加以准备。 • 推论:监督一个能力超过监督者自身的人工智能系统是困难的,且随着能力差距的扩大,这种困难会加剧,尤其是在机器的规模和速度下。因此,对于足够强大的AI系统,我们的方法并不单纯依赖人类监督者,而是利用AI自身的能力来实现监督。
- 时间线:我们对强大AI系统问世的时间线高度不确定,但关键在于,我们认为在2030年前实现是完全可能的。 • 推论:由于时间可能非常紧迫,我们的安全方法力求具备“随时可用”(anytime)的特性,即一旦必要,就能迅速实施相关缓解措施。正因如此,我们主要关注那些能够轻松应用于当前机器学习流程的缓解手段。
- 加速发展:基于对经济增长模型的研究,我们认为,随着AI系统逐步实现科学研究与开发(R&D)的自动化,我们将进入一个加速增长阶段:自动化的研发推动更多、更高效的AI系统被开发出来,进而实现更高程度的自动化研发,从而触发失控式的正向反馈循环。 • 推论:这种情况将极大加快技术进步的速度,留给我们在日历时间上发现并应对问题的窗口极短。为确保我们仍能及时察觉并应对新出现的问题,我们的风险缓解方法可能需要让AI自身承担更多与AI安全相关的任务。尽管本文提出的方法并非主要针对构建一个能开展AI安全研究的AI系统,但该方法可被专门用于这一目标。
- 连续性:尽管我们旨在应对显著的加速发展,但我们也认识到存在一定的限制。例如,如果从当前的聊天机器人一步跃升至一个使人类所有经济活动都过时的AI系统,那么极有可能出现我们未能预见的重大问题。幸运的是,AI的发展似乎并非如此不连续。因此,我们依赖于“近似连续性”这一假设:大致而言,随着能力输入(如算力和研发努力)的逐步提升,通用AI能力不会出现巨大的不连续跳跃。关键的是,我们并不假设技术进步在日历时间上的速率受到限制,因为加速发展是可能的。 • 推论:我们可以对我们的方法进行迭代式和经验性的测试,以便在能力逐步提升的过程中发现那些仅在更高能力水平下才会暴露的错误假设。 • 推论:我们的方法无需对任意强大能力的AI系统都保持稳健。相反,我们可以提前规划未来几个量级内可能出现的能力,而将更强大的能力问题留待未来处理。
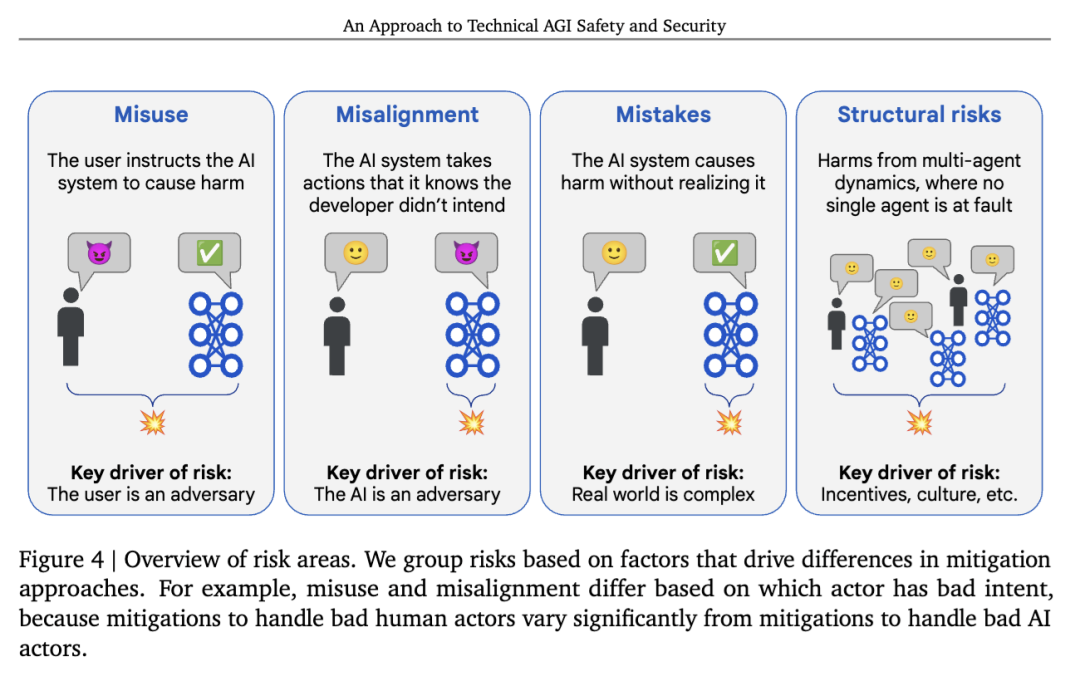
风险领域在应对安全与安保问题时,识别出可能导致伤害的广泛路径类别是很有帮助的,因为这些路径可以通过相似的缓解策略加以应对。由于我们的重点在于识别相似的缓解策略,因此我们根据抽象的结构性特征(例如,是否存在某个行为者具有恶意意图)来定义风险领域,而不是依据诸如网络攻击或人类失去控制等具体的风险场景。这意味着这些风险领域的划分适用于人工智能带来的普遍性危害,而不仅限于AGI。
我们考虑四个主要领域:
- 滥用(Misuse):用户故意指示AI系统采取违背开发者意图的行动,从而造成伤害。例如,一个AI系统可能协助黑客对关键基础设施发动网络攻击。
- 目标不一致(Misalignment):AI系统明知其行为会造成违背开发者意图的伤害,却仍然实施该行为。例如,一个AI系统可能提供看似经得起人类监督者审查的自信回答,但AI自己知道这些答案实际上是错误的。我们所指的“目标不一致”概念涵盖了文献中讨论的许多具体风险,并超越了它们,例如欺骗、图谋不轨,以及非预期的主动失控等情况。
- 错误(Mistakes):AI系统产生了一小段直接导致伤害的输出,但该系统并未意识到这些输出会导致开发者所不希望的有害后果。例如,一个管理电网的AI代理可能不知道某条输电线路需要维护,因而使其过载并烧毁,导致停电事故。
- 结构性风险(Structural risks):这类风险源于多主体之间的动态交互——涉及多个个人、组织或AI系统——仅通过改变一个人的行为、一个系统的对齐性或一个系统的安全控制措施,并不能防止此类伤害的发生。
需要注意的是,这并非一种严格的分类:这些风险领域既不互斥,也不穷尽所有可能性。在实践中,许多具体场景往往是多个领域的混合。例如,一个目标不一致的AI系统可能招募恶意行为者协助其泄露自身的模型权重,这就同时涉及了滥用和目标不一致。我们预计,在此类混合情形中,仍然可以有效地主要采用各个独立风险领域的缓解措施,但未来的研究也应探索针对多种风险组合的特定缓解方法。
当不存在对抗性行为者时,例如在“错误”情形下,采用标准的安全工程实践(例如测试)可以大幅降低风险,这些方法在防范AI错误方面应与防范人类错误一样有效。这些实践已经足以使由人类错误导致的严重伤害变得极为罕见,尽管这在一定程度上也反映出“严重伤害”本身是一个极高的门槛。因此,我们认为,由AI错误引发的严重伤害,其可能性将显著低于滥用或目标不一致,并且通过适当的安全措施还可进一步降低。基于这一判断,本文将其排除在讨论范围之外。
尽管如此,我们仍指出针对AI错误的四项关键缓解措施:提升AI自身能力、避免在极端高风险情境下部署AI、使用能够验证AI行为安全性的“防护罩”(shields),以及分阶段部署。
结构性风险则是一个更为广泛的类别,通常每种风险都需要定制化的应对方式。同时,这类风险对AI开发者而言也更难应对,因为它们往往需要建立新的社会规范或制度,以调节现实世界中强大的动态关系。正因如此,本文也将结构性风险排除在讨论范围之外。
这并不意味着对结构性风险无所作为——事实上,本文所讨论的许多技术工作也与结构性风险相关。例如,通过开发使模型能够对齐任意训练目标的技术,我们为治理工作提供了支持,使其能够将模型监管至模糊但必要的规范要求。
因此,我们的策略主要聚焦于滥用和目标不一致。对于滥用问题,我们通过“前沿安全框架”(Frontier Safety Framework, Google DeepMind, 2025)来实施该策略,该框架评估模型是否具备造成伤害的能力,并在确认存在此类能力时,部署相应的安全与管控措施。对于目标不一致问题,我们的策略始于实现良好的监督机制,这也是整个AGI安全领域的一个核心关注点。此外,我们特别强调监督的来源问题,即:为了确保训练出的系统与人类意图对齐,究竟在哪些任务上需要实施监督。
滥用(Misuse)
当人类故意违背开发者的意愿,利用AI系统造成伤害时,即发生“滥用”。为了防止滥用,我们实施安全与部署层面的缓解措施,以阻止恶意行为者获得足够的权限来访问危险能力,从而避免造成严重伤害。
对于一个已经采取缓解措施的AI系统,我们可以通过尝试自行滥用该模型(同时避免造成实际伤害)来评估这些缓解措施的有效性,并观察我们能在多大程度上推进这一过程。从直观上看,如果我们无法利用模型造成(代理性的)伤害,那么外部行为者也不太可能造成(实际的)伤害。然而,这种直观推论需要补充其他因素加以完善,例如:恶意行为者可能投入远超我们的努力和资源。相反,如果我们确实能够通过模型造成代理性伤害,那就说明当前的缓解措施不足,需要进一步加强。
作为上述情况的一个特例,当系统尚未部署任何缓解措施时,我们首先需要检查该模型本身是否具备造成严重伤害的能力;只有在确认存在此类能力后,才引入相应的缓解措施。这正是我们在Google DeepMind通过“前沿安全框架”(Frontier Safety Framework, Google DeepMind, 2025)所实践的方法。
风险评估
滥用威胁建模旨在识别出恶意行为者可能利用前沿AI系统的强大能力造成严重伤害的具体且合理的途径。关键问题包括:AI系统具备哪些能力?威胁行为者将如何使用这些能力?可能涉及哪些类型的威胁行为者?等等。其目标是生成对最可能发生伤害路径及其预期损害的现实描述,从而帮助我们识别出哪些模型能力可作为现实世界中严重伤害风险上升的代理指标。
危险能力评估 是衡量AI系统中此类能力存在程度的一种具体方法。我们定义了一套任务,认为这些任务能够代表潜在滥用所依赖的关键能力,然后测试我们的模型在该任务集上的表现是否优异。
通常,我们会利用这些评估来论证:由于模型缺乏必要的能力,滥用在当前并不可行,因此无需采取缓解措施。为实现这一点,我们设定一个“能力阈值”——即滥用行为可能发生的能力水平,并将其映射到危险能力评估中的某个具体、可测量的分数。基于对该阈值何时会被突破的预测,我们可以提前在适当的时间尺度上准备相应的缓解措施。
缓解措施
部署类缓解措施 旨在防止恶意行为者通过正常使用API的途径访问危险能力。这些措施从模型层面开始,包括:
- 安全后训练(Safety post-training):开发者可以在后训练阶段教导模型拒绝执行有害请求。这种方法还需确保模型能够抵御“越狱”(jailbreak)攻击,即避免用户通过巧妙的提示绕过安全限制。
- 能力抑制(Capability suppression):理想情况下,可以完全移除模型的危险能力(即所谓的“反学习”,unlearning)。然而,这一技术目前仍难以实现,且可能过度损害模型在有益场景中的性能,因此在实践中应用受限。
我们的方法还考虑在系统层面实施进一步的部署缓解措施,与模型层面的措施相结合,形成“纵深防御”(defense in depth):
- 监控(Monitoring):监控旨在检测威胁行为者是否试图不当访问危险能力,并采取响应措施,防止其利用任何已获得的访问权限造成严重伤害。检测可通过使用输出“伤害概率分值”的分类器、利用模型内部的激活状态,或人工审核生成内容来实现。
- 访问限制(Access restrictions):对具备危险能力的模型,可将其使用权限限制在经过审查的用户群体或特定应用场景内,从而减少恶意行为者可尝试不当访问的能力范围。此外,如果某用户频繁触发安全监控机制,也可对其施加额外限制。
安全类缓解措施 旨在防止恶意行为者窃取具备危险能力的AI系统。尽管许多此类安全措施在一般信息安全领域也适用,但针对保护AI模型本身,还存在一些更具体的新挑战和应对方法。例如,一个关键目标是限制能够单方面访问模型权重的人员数量。为实现这一点,我们需要设计支持标准机器学习工作流程的接口,使模型开发可通过这些接口完成,进而对这些接口进行加固防护。
社会准备类缓解措施(Societal readiness mitigations)则利用AI系统来增强社会的防御能力。例如,通过AI快速识别并修补关键基础设施中的漏洞,以应对未来可能出现的AI驱动的网络攻击能力。这类措施有助于确保即使恶意行为者获得了危险能力,也无法真正造成严重伤害。
防范滥用的保障措施
滥用压力测试。在实施缓解措施之后,我们的方法要求针对已应用的一系列滥用缓解措施,建立一个详细的论证,说明为何这些措施足以将风险降低到可接受的水平。这使我们能够识别该论证所依赖的关键假设,并通过压力测试来发现这些假设中的缺陷。例如,专门的红队可能会发现新型越狱方法,从而绕过安全微调的缓解措施。
由于恶意行为者可能会投入更多的努力,因此我们给予红队额外的优势作为补偿。例如,红队可以完全了解所有缓解措施,或者我们可以降低缓解措施的阈值,使系统更容易受到攻击。此外,将红队与缓解措施的开发团队分离具有重要价值,以降低出现共同盲点的风险。这可以通过设立独立的内部专家红队,或由外部合作伙伴开展压力测试来实现。
滥用安全案例。安全案例是一种结构化的论证,辅以一系列证据,用以证明某个系统是安全的。我们的方法支持两种类型的安全案例:
- 无能力(Inability):系统不具备造成伤害的能力。这一点通过危险能力评估的结果以及这些能力如何导致风险来进行论证。
- 经红队测试(Red Teamed):对于具备危险能力的模型,我们需要进行压力测试,以了解我们所采取的缓解措施的稳健性。这些证据随后被纳入论证,以说明缓解措施足以将风险降至可接受的水平。目前,红队测试方法(包括自动和手动方式)使我们能够量化访问危险能力的难度,但还需要进一步研究,以将这种难度与整体风险关联起来。
目标错位(Misalignment)
我们的方法包含两道防线。首先,我们旨在采用模型层面的缓解措施,确保模型不会追求错误的目标。我们遵循标准的机器学习方法论:(1)提升获得良好监督的能力(增强监督);(2)利用这种能力来改进模型(引导模型行为);(3)确定在哪些方面需要监督,以训练出能够稳健地执行我们期望任务的模型(稳健训练)。
其次,我们考虑在模型出现目标错位的情况下(通常称为“人工智能控制”),如何通过系统层面的缓解措施来减轻潜在危害。在设计这一道防线时,我们从计算机安全领域获得了重要启发,将人工智能系统视为一个不可信任的内部人员,从而推动诸如访问控制等缓解措施的实施。监控尤其重要,因为它能够随着人工智能能力的提升而获得更强的效果。
我们还考虑了一些能够加强上述防御能力的研究领域。不确定性是稳健训练和监控两个方面的重要组成部分。可解释性(Interpretability)能够帮助我们理解人工智能系统的工作机制,从而支持多种缓解措施的实现。更安全的设计模式(Safer design patterns)这一研究方向探索那些以牺牲某些其他期望特性为代价、但能提升安全性的设计决策,其目标是衡量并扩展帕累托前沿(Pareto frontier),以便选择一个合适的平衡点。
训练一个对齐的模型
这些模型层面的缓解措施旨在创建一个追求我们所期望目标的模型。
增强监督(Amplified oversight)。在几乎任何对齐方案中,一个关键挑战在于:一旦模型的能力超过了监督者的能力,就可能很难判断某个模型输出是好还是坏。举个例子,设想一个人类监督者试图判断AlphaGo走出的某一步棋是否高明。增强监督这一研究领域正是为了解决这个问题:其目标是提供一种监督信号,其质量相当于人类监督者能够完全理解人工智能系统产生该输出的所有原因,并拥有无限的时间和能力来反思并做出正确判断时所能达到的水平。
核心思想是利用人工智能系统本身来帮助识别该系统产生某个输出的原因。例如,我们可以将两个模型副本置于一种环境中,让每个模型都致力于向一个人类“裁判”指出对方输出中的缺陷。理想情况下,如果其中一个模型在其输出中引入了一个细微的错误,而这个错误是裁判默认情况下无法察觉的,那么另一个模型就会指出并解释这一错误,从而使裁判能够适当地惩罚第一个模型。
在增强监督中,任何难以直接监督的问题都会被系统性地分解为一组我们假设可以监督的更简单问题。然而,即使对于相对简单的问题,人类也可能存在系统性偏差。如果在实践中这确实成为一个问题,我们可以尝试对这些偏差进行建模,并在解释监督信号时自动予以纠正或补偿。
引导模型行为。在获得监督信号后,我们需要将其应用于模型的训练过程。尽管现有的技术(如强化学习)可能已足够,但我们仍有可能在此基础上进一步改进。例如,采用新的反馈方式,如用自然语言对模型的回答进行批评,可以增加每次更新所包含的信息量;同时,利用模型内部结构可以实现更有针对性的更新,从而提高样本利用效率。
稳健训练。一旦我们拥有了能够区分良好行为与不良行为的监督信号,就需要利用这一信号来构建一个行为良好的人工智能系统。一个尚未解决的问题是,模型在训练数据分布之外的输入上仍可能表现不佳。
稳健训练通过扩展人工智能系统的训练输入分布来缓解这一问题。在探索“需要何种数据才能诱导出对齐的模型”(无论是奖励模型还是策略模型)这一更广泛问题的同时,我们始终以导致失败的实际案例为实践重点。关键技术包括主动学习、自动化对抗训练以及部署后的在线训练。
防御目标错位的模型
尽管从理论上讲,增强监督和稳健训练可能已足以解决问题,但在实际应用中仍会存在一些漏洞。因此,我们追求纵深防御(defense in depth):即使人工智能系统出现目标错位,我们也能通过适当的防御措施减轻其造成的损害。
安全防护。一种关键方法是将模型视为不可信任的内部人员,从而推动诸如访问控制、异常检测、日志记录与审计等缓解措施的实施。与人类员工相比,人工智能系统可能执行更加专门化的任务,这使我们能够以更精细的方式限制其可操作的范围。其他相关技术包括沙箱隔离(sandboxing),以及强化人工智能系统运行环境的安全性。
监控。随着人工智能能力的提升,监控能力也有望显著增强,因为人工智能系统能够在必要的规模上运行,同时仍具备传统上仅通过人工审查才能实现的灵活智能。分层监督(Hierarchical supervision)将尤为重要:即模型的输出首先由低成本系统进行初步监控,而其中最可疑或最不明确的情况则被升级交由更强大、更昂贵的监控系统处理,例如基于增强监督所构建的监控机制。
加强防御能力
我们的方法呼吁加大对若干研究领域的投入,以增强上述主要缓解措施的能力。
不确定性(Uncertainty)。稳健训练和监控都极大地受益于、甚至可能依赖于具备不确定性建模能力的模型。这种不确定性可以是传统贝叶斯意义上的,也可以通过语言抽象层面的推理来实现。在稳健训练中,不确定性有助于实现主动学习,从而更有效地识别出训练分布中哪些部分最值得扩展。在监控方面,不确定性在分层监督中起着关键作用,可用于判断何时应将任务升级至更高层级的监督。
更安全的设计模式(Safer design patterns)。在人工智能系统的设计过程中,存在许多决策可以在提升安全性的同时牺牲其他期望特性。重要的是要对这些权衡进行定量研究,并投入资源扩展此类权衡的帕累托前沿(Pareto frontier),以便在构建人工智能系统时做出恰当选择。具体示例包括:
- 训练目标:在设定人工智能系统期望行为时,可以引入有助于增强用户控制的原则,例如: a) 向用户告知人工智能系统所采取的行动 b) 在执行任何重要且不可逆的操作前,先征询用户意见 c) 当用户给出出乎意料的负面反馈时,暂停操作或采取保守行为
- 创造性(Creativity):我们可以在训练过程中控制人工智能系统的行为探索或优化程度。减少探索可以防止发现“奖励作弊”(reward hacking)行为,但也会降低发现我们所期望的创造性解决方案的机会。
- 外化推理(Externalized reasoning):我们可以确保人工智能系统对其行为提供人类认可的解释,从而提高我们实施有效监督的可能性。
可解释性(Interpretability)。直观上,对系统运作机制理解得越深入,就越容易使其变得安全。虽然我们可以通过对人工智能系统行为的严格分析获得一些表面理解,但如果还能理解训练好的大语言模型(LLM)前向传播过程中所实现的算法,就有可能实现更深层次的理解。如果取得成功,这将对对齐问题产生广泛影响,例如:
- 检测那些试图通过我们的测试来伪装对齐行为的错位人工智能系统。
- 验证人工智能对其答案的解释是否真实反映了其生成答案时的内部推理过程。
- 向监督者提供关于人工智能推理过程的信息,以增强监督能力(amplified oversight)。
遗憾的是,可解释性研究目前仍处于早期阶段,尚未能支持上述这类实际应用。因此,我们仍需在“基础科学”方面进行大量投入。
对齐保障
对齐压力测试。压力测试包括一个红队,其任务是尝试证明某个对齐方案中的某一假设是错误的。红队在这一目标上的成功或失败,为我们提供了关于该假设是否成立的证据,从而判断我们是否可以在对齐人工智能系统时依赖这一假设。压力测试还可能产生“模型生物”(model organisms),即展示特定失效模式的实例,这些实例有助于进一步研究如何防止此类失效,并积累关于错位失效可能性的科学证据。
控制性评估(Control evaluations)。控制性评估将滥用场景下的红队测试扩展到目标错位的场景。在滥用场景中,红队扮演恶意的外部用户,模拟可能出现的对抗性行为,我们观察他们取得的成功程度。类似地,在控制性评估中,红队可以通过微调或提示工程,试图使模型产生(代表性的)有害行为,然后我们观察该模型在实际中造成危害的能力有多强。
对齐安全案例(Alignment safety cases)。与防范滥用类似,提供结构化的论证以证明人工智能系统并未严重错位,这一点至关重要。以下是几种类型的安全案例:
- 无能力(Inability)。对于当前的模型而言,适用“无能力”型安全案例:即使人工智能系统有意造成严重伤害,它也不具备这样的能力。这一点可以通过能力评估来证明,方法与滥用场景中的评估类似。然而,这类安全案例可能很快将不再适用。
- 监督(又称控制,Supervision / Control)。此类论证认为:如果人工智能系统产生了可能造成伤害的输出,我们将能够察觉并采取纠正措施,从而防止伤害发生。重要的是,此类论证必须对“共谋”(collusion)具有鲁棒性,即需考虑监控系统本身也可能错位,因而选择不报告主人工智能系统的不良行为。控制性评估可作为支持此类安全案例的证据。
- 激励机制(Incentives)。基于激励的论证依赖于训练过程,主张人工智能系统正在追求我们设定的目标,因此不应出现错位。但目标错误泛化(goal misgeneralization)或分布偏移(distribution shift)对此类论证构成重大挑战,因为我们尚不清楚如何证明训练已充分覆盖人工智能系统在部署过程中可能遇到的所有情况。
- 理解(Understanding)。这类安全案例旨在对最终模型进行足够深入的分析,使我们能够认证它只会产生安全的输出——而无需穷尽所有可能的输入和输出组合。目前我们距离实现此类安全案例还很遥远,但从理论上讲,可解释性(interpretability)的进展有可能使这种安全案例成为现实。
局限性
本文的重点在于针对通用人工智能(AGI)风险的技术性应对方法和缓解措施。一个关键的局限是,这仅描绘了完整图景的一半:一个全面的方法还应包括治理机制,而治理的重要性至少不亚于技术手段。例如,针对滥用风险,所有前沿开发者都必须实施必要的缓解措施,才能真正有效降低风险。如果只有一家开发者实施了这些措施,而其他开发者未跟进,那么恶意行为者便可转而使用安全性较低的人工智能系统。此外,我们并未涉及结构性风险,因为这类风险需要专门定制的应对策略。
由于我们关注的是可集成到当前人工智能开发流程中的技术,因此主要聚焦于“随时可用”(anytime)的安全方法。尽管我们认为这对前沿人工智能开发者的主流安全策略而言是恰当的侧重点,但同样值得投入资源开展一些长期回报的研究项目,以进一步提升安全性,例如代理基础理论(agent foundations)、深度学习科学(science of deep learning),以及形式化方法在人工智能中的应用。
我们的讨论集中于可预见的未来可能出现的风险,以及利用当前或近期可实现的能力即可取得进展的缓解措施。这种选择基于“近似连续性”假设(第3.5节):由于能力的提升通常不会出现大幅的不连续跃迁,因此我们不应预期此类风险会突然降临。尽管如此,若能全面涵盖未来的发展可能性,将更具说服力,例如:人工智能科学家可能开发出新的以攻击为主导的技术,或未来的安全缓解措施可能由自动化研究人员自行研发并部署。
最后,必须强调的是,我们所讨论的方法本质上是一项研究议程。尽管我们认为它为我们应对AGI风险的工作提供了一条有用的路线图,但仍存在大量尚未解决的开放性问题。我们希望研究界能够与我们共同努力,推动AGI安全领域的前沿进展,从而使人类能够安全地享有通用人工智能带来的巨大收益。
- 引言
人工智能正成为一项具有巨大效益的变革性技术。它有望提升全球的生活水平(Russell,2022),彻底改变医疗(Singhal 等,2025)和教育(Kumar 等,2023)等关键领域,并加速科学发现(Wang 等,2023b)。然而,如同任何变革性技术一样,它也伴随着风险。由于其变化速度之快、影响之新颖,预测和缓解这类新型变革性技术的风险变得极为困难。过早实施的缓解措施和监管往往适得其反,可能在未能相应减少危害的同时削弱了技术带来的益处。例如,航空业的放松管制带来了显著的经济收益(Morrison 和 Winston,2010),却并未对安全造成负面影响(Moses 和 Savage,1990)。
因此,对于许多风险而言,虽然适当采取一些预防性的安全缓解措施是合理的,但大部分安全进展应通过“观察与缓解”(observe and mitigate)策略来实现。具体而言,技术应分阶段、逐步扩大范围地部署,每个阶段都应配备专门设计的系统,用于观察实践中出现的风险,例如通过监控、事件报告和漏洞奖励计划等方式。一旦观察到风险,便可实施更严格的、更精准针对实际风险的安全措施。
然而,不幸的是,随着技术变得越来越强大,它们开始可能造成严重的危害。如果某一事件所造成的危害足够严重,以至于对人类造成重大损害,则被视为造成了严重危害。显然,对于此类危害,“观察与缓解”策略是不够的,我们必须转而依赖预防性方法。例如,在曼哈顿计划期间,科学家曾担忧核武器可能点燃大气层,因此必须通过理论分析排除这一可能性(Wiescher 和 Langanke,2024;Konopinski 等,1946)。
我们并未对“严重危害”的确切阈值做出明确界定。在光谱的一端,任何频繁发生的危害都不属于本文定义的“严重危害”。例如,自动驾驶汽车的事故不构成严重危害,因为人工驾驶汽车的致命事故本就经常发生。在光谱的另一端,存在性风险(existential risks,Ord,2020)——即永久性地毁灭人类的风险——显然是严重危害的典型例子。在这两个极端之间,某种特定危害是否属于“严重”范畴,并非由谷歌 DeepMind 单方面决定;而应由社会整体根据其共同的风险承受能力和对危害的理解来判断。
鉴于通用人工智能(AGI)可能带来的巨大影响,我们预期它也可能带来造成严重危害的潜在风险。在本报告中,我们阐述了谷歌 DeepMind 应对 AGI 严重风险的方法,重点放在技术安全与安全缓解措施上。需要强调的是,这是一份路线图而非最终解决方案,因为仍有许多开放性的研究问题有待解决。
不同的严重危害由不同的能力所引发,因此无法精确指出在某一特定能力水平上,本文讨论的各种风险将开始显现。尽管如此,为了便于说明,设想我们所讨论的人工智能系统具备某一具体能力水平仍是有帮助的。沿用 Morris 等人(2023)的术语,我们将考虑“卓越级通用人工智能”(Exceptional AGI,第4级),其定义为:在广泛的非物理任务上,能力达到或超过熟练成年人中前1%的水平。在此能力水平下,我们识别出多种类型的严重风险(第4节),并将我们的应对方法聚焦于两类主要的严重风险来源:滥用(misuse)和错位(misalignment)。
- 评估模型是否具备造成严重危害的能力(第5.2节)。
- 如果具备,则实施适当的部署缓解措施(第5.3–5.5节)和安全缓解措施(第5.6节)。
- 通过尝试突破这些缓解措施并观察能推进到何种程度,来评估缓解措施的有效性(第5.8节)。
同样,我们针对目标错位(misalignment)的策略是:
- 利用人工智能系统自身辅助监督过程,实现高质量的监督(第6.1节),并利用该监督信号训练人工智能系统(第6.2节)。
- 明确在哪些情况下需要监督,以确保训练出的模型能够稳健地执行我们期望的任务(第6.3节)。
- 采用纵深防御策略,以应对尽管我们已尽最大努力但仍出现错位的人工智能系统,具体包括:结合高效且可扩展的监控机制(第6.3节)以及应用计算机安全技术(第6.4节)。
- 通过对齐保障技术(第6.7节和第6.8节)评估缓解措施的有效性。
我们还投资于能够提升上述多个步骤效果的支撑性研究领域,包括更安全的设计模式(第6.5节)和可解释性(第6.6节)。
治理(Governance)。全面的风险缓解措施还必须考虑更广泛的社会技术背景。例如,竞争动态(race dynamics,Armstrong 等,2016;Cave 和 ÓhÉigeartaigh,2018)可能导致单方面行动失效:如果某家人工智能开发者不顾安全地激进推进,其他开发者的克制可能收效甚微。
由于本文聚焦于谷歌 DeepMind 的方法,因此这些需要更广泛社会参与的治理问题不在本文讨论范围之内。尽管如此,建立关于适当标准和最佳实践的广泛共识至关重要。我们希望本文能在推动这一方向上迈出有意义的一步。
相关工作(Related work)。我们在此的讨论与 Anthropic 之前的论述最为相似(Anthropic,2023),但我们对稳健训练、监控和安全给予了显著更多的重视。与此同时,OpenAI 的重点在于对齐研究的自动化(Leike 等,2022)。尽管我们同意在可行的情况下应推进对齐研究的自动化(第3.4节),但我们将其视为加速对齐研究的一种手段,而非我们应追求的主要目标。
此前已有大量文献综述探讨了通用人工智能安全或其相关方面(Everitt 等,2018;Ji 等,2023;Shah,2020;Kenton 等,2021;Kim 等,2024)。我们并不试图穷尽整个领域,而是呈现我们认为对前沿人工智能公司而言最重要、最值得投入的研究方向和行动。例如,我们优先考虑那些已有实证支持的领域,以及对降低风险显得必要的领域。
- 应对证据困境
尽管严重危害要求采取预防性方法,但针对一种全新且快速演进的技术采取预防措施,会面临一个“证据困境”(Bengio 等,2025)。预防性缓解措施所依据的证据往往相对有限,因此更有可能适得其反。针对未来问题开展的研究工作,可能会探索后来被证明不可行、不成比例或不必要的缓解措施。然而,如前所述,对于严重危害而言,等到证据确凿后再行动(即“观察与缓解”)并不可行。
不过,存在一种折中的方法。许多风险在当前可预见的能力提升背景下似乎并不现实,但可能在尚未显现的能力提升后出现。这类风险适合推迟到未来处理,届时将有更多证据可用——尤其是因为当人们清楚能力是如何产生的,缓解措施的设计会容易得多。重要的是,人工智能的发展通常不会在输入持续增加的前提下出现能力上的巨大不连续跃迁(第3.5节),尽管整体进展速度可能加快(第3.4节)。只要我们同步加速安全与安保研究,我们就有理由预期:目前推迟处理的风险,在实际发生之前仍会被提前预见,从而为我们留出时间开发缓解措施。
换句话说,对于任何特定风险,我们有两种应对方式:
- 提出具体的研究方向,开发并实施针对该风险的缓解措施。
- 将该风险推迟到未来处理,待关于相关能力的更多证据出现后再应对。这些证据可能表明最初的担忧是不必要的,因此无需采取缓解措施;也可能揭示出应对该风险所需的新方法。
在下一小节中,我们将简要概述通用人工智能安全与安保领域中的一些具体风险和能力,并说明它们是属于我们当前方法的范围(选项1),还是将被推迟到未来证据充分时再处理(选项2)。
2.1 将我们的方法应用于具体风险
本文不聚焦于具体的能力或造成危害的路径,而是发展我们预期能够跨能力通用的应对方法(Christiano,2021)。尽管我们讨论了四个不同的风险领域(第4节),但这些分类是基于所需缓解措施的相似性,而非可能产生的具体有害后果。
例如,首份《国际人工智能安全报告》讨论了“失控”(loss of control)的风险(Bengio 等,2025)。相比之下,我们并未将“失控”作为一个独立类别进行讨论。我们对这类风险的缓解措施将分别归入滥用、错位和结构性风险三类,分别对应报告中的“有意主动失控”、“无意主动失控”和“被动失控”(Bengio 等,2025,图2.5)。这反映了我们的判断:针对“有意主动失控”的适当缓解措施,更接近于防御恐怖分子滥用人工智能开发武器等滥用风险的措施,而非应对“无意主动失控”的措施。同样,我们认为被动失控或渐进式权力剥夺(Kulveit 等,2025)作为结构性风险,需要专门定制的应对策略,因此不在本文讨论范围之内。
尽管如此,为了说明我们的方法旨在涵盖的风险与我们推迟处理的风险之间的区别,我们将简要介绍一些具体风险及其与我们方法的关系。
滥用(Misuse)。我们对滥用的应对方法包括:主动识别危险能力,测量相关模型能力,并实施安全和部署缓解措施,以共同阻止恶意行为者造成极端危害。我们已经看到一些此类危险能力的迹象:例如,人工智能模型可能很快具备发动网络攻击的能力,因为它们已经发现至少一个真实世界中的新型漏洞(Allamanis 等,2024)。只要威胁建模能在风险导致严重危害之前识别出它们,这一总体方法应能很好地扩展到未来可能出现的其他危险能力。
然而,我们的方法依赖于对人工智能能力发展的若干假设:例如,危险能力将出现在由集中式开发产生的前沿人工智能模型中。这一假设在未来可能不成立。例如,危险能力可能开始源于多个组件之间的交互(Drexler,2019),其中每个单独组件都易于复制,但整体系统却难以复现。在这种情况下,仅通过在单个组件上添加缓解措施来阻止对危险能力的访问将不再可行,因为恶意行为者可以轻松地从头重建该组件,且不包含任何缓解措施。
对话系统、智能体系统与推理能力。不同的能力特征将引发不同的具体风险。聊天机器人(Adiwardana 等,2020)和推理模型(Jaech 等,2024)处于同一连续谱上,其风险也相似,因为推理模型可被视为能力稍强的聊天机器人。语言智能体(Xi 等,2025;Wang 等,2023a)引入了新的风险,因为它们为语言模型增加了新的操作空间(affordances)。如果一个错位的人工智能系统能够使用网络扫描工具,它就更容易泄露自身的权重。具身智能体(embodied agents)可能带来进一步风险,例如使错位的人工智能系统能够开发出可用作威胁的武器。部署规模的扩大也会增加风险,因为实际监督人工智能系统行为的难度随之上升。
尽管具体风险各不相同,我们的高层方法保持一致:旨在通过利用人工智能系统自身(增强监督)来确保我们能够有效监督人工智能系统在任意输入下的行为,并将这种监督扩展到大规模部署(稳健训练与监控)。这些方法可适用于多种不同能力,尽管具体细节会有所不同。例如,在分层监控架构中(第6.3节),推理模型可自然地充当廉价分类器与人工审计之间异步、高成本的监控器。又如,对于智能体系统,必须在系统可使用的工具上投入大量精力实施访问控制,而这对对话系统则不那么关键。
超越人类的概念与能力。更具挑战性的一种可能是:人工智能系统发展出超越人类理解能力的概念或能力,而未受辅助的人类难以理解。这种情况仍在我们方法的覆盖范围内,尤其依赖于“增强监督”(第6.1节)这一研究方向,其目标正是在该情境下仍能提供有效的监督。
尽管在最坏情况下存在重大理论挑战(Christiano 等,2021),但监督者拥有多项优势,表明即使面对能力或概念上略强于人类的AI系统,监督仍可能有效,尽管面对超级智能时这种方法可能失效。
目标漂移(Goal drift)。关于智能的理论模型通常意味着,智能体应能以样本高效的方式在线学习其环境(Legg 和 Hutter,2007;Hutter 等,2024)。在语言模型的背景下,我们可以设想强大的推理时(inference-time)推理能力,使模型能够改进其世界模型中的概念,从而因本体论危机(ontological crisis,De Blanc,2011)引发目标漂移。更一般地,在上下文学习(in-context learning)的机制下,模型的能力和行为倾向可能因足够多的推理时计算资源而发生剧烈变化,从而可能使基于训练的安全措施失效。
尽管推理时推理(inference-time reasoning)确实可以提升模型能力(Jaech 等,2024),但目前看来,其能力远未达到引发本体论危机(ontological crisis)所需的水平。Cotra(2020)指出,元学习(meta-learning,上下文学习是其中一种形式)是一个关键瓶颈,人工智能系统在该能力上可能会长期显著落后于人类。ARC-AGI 基准测试(Chollet 等,2024)明确旨在检验这一能力,其设计目标就是对人类容易、对人工智能困难。此外,当前的模型架构面临并行性权衡问题(Merrill 和 Sabharwal,2023):为了实现高度并行的预训练,它们牺牲了进行大规模顺序推理的表达能力,即使拥有任意长度的上下文也是如此。这表明,若无重大架构创新,强大的推理时推理能力可能不会出现。
因此,我们的方法并不直接应对目标漂移(goal drift)的风险。不过,我们预期所提出的许多技术未来也可扩展至应对这一情形。持续监控人工智能在元学习方面的能力至关重要,以便在该风险变得更为现实时能够及时察觉。
重要的是,我们的方法确实旨在应对目标错误泛化(goal misgeneralization,Shah 等,2022)——即在分布偏移(distribution shift)下,人工智能系统可能表现出追求不同目标的行为(而非通过元学习实现)。这种情况可能是因为其目标随输入而变化,或因为我们原本对其目标的理解有误,而这种错误直到分布偏移后才显现出来。
递归式改进(Recursive improvement)。我们认为,人工智能系统可能实现递归式的人工智能改进:即利用人工智能系统开展人工智能研究,从而开发出更强大的人工智能系统,形成正反馈循环,可能引发“智能爆炸”(intelligence explosion,Yudkowsky,2013)(见第3.4节)。在可预见的未来,我们预计这种改进将通过人工智能系统执行与人类研究人员类似的人工智能研究任务来实现,这一点在如 RE-bench(Wijk 等,2024)等能力评估中已有体现。
相比之下,我们不预期人工智能系统会直接修改自身的权重,因此与这类能力相关的风险将推迟到未来的安全与安保研究中处理。
递归式改进的一个挑战是:一个错位的人工智能系统可能故意破坏其所进行的研究工作(Benton 等,2024)。这是目标错位风险的一种具体表现形式,而我们对错位问题的应对方法,自然也能以处理其他推理模型和智能体风险的相同方式应对这一问题。
更大的挑战在于,递归式改进可能极大加快人工智能的发展速度,使得新型能力在研究人员有机会为其开发缓解策略之前就已出现。对此的自然应对方案是:同样将人工智能应用于安全与安保研究过程,加速安全研究,使其与人工智能能力的发展保持同步。在可预见的未来,人工智能有望加速能力研究和安全研究共有的子任务,例如实验实施(Jimenez 等,2023)、数据集创建(Perez 等,2022b)和奖励建模(Bai 等,2022b;Zhang 等,2024a;Guan 等,2024)。由于这些任务在两类研究中均存在,人工智能的进步很可能以大致相似的速度推动两者发展。
从长期来看,难以预测递归式改进是否会不成比例地偏向能力研究或安全与安保研究。如果其显著偏向加速能力研究,那么我们可能需要加大投入,将人工智能用于提升安全与安保研究效率。具体应如何实施,将高度依赖未来人工智能系统的能力特征,因此我们将其推迟到未来工作中进一步研究。
超级智能(Superintelligence)。Bostrom(2014)将超级智能定义为人类水平的通用智能被提升到一种惊人且难以想象的程度。这种系统必然具备我们当前方法无法涵盖的能力,例如能够生成新概念的强上下文学习能力(这正是人类具备的能力)。如果超级智能得以实现,它很可能还具备我们尚未设想的其他能力,这些能力将带来新的风险,并需要全新的缓解措施。由于我们目前尚不清楚这些能力具体为何,因此将相关风险推迟到未来的安全与安保研究中处理。
需要强调的是,正如本节开头所讨论的,即使在可预见的能力范围内,我们也预期安全与安保研究将被显著加速。如果超级智能最终被开发出来,我们预计在更早的某个阶段,人类研究人员可能已因自动化研究人员的出现而变得过时。因此,安全与安保的一个关键部分将是“自举”(bootstrapping):即后续的人工智能系统由先前已被对齐的早期人工智能系统设计,并且在后续对齐任务上比人类做得更好。
重要的是,只有我们的第一道防线(训练一个对齐的模型)能够实现这种自举。直观而言,一个对齐的模型在对齐下一个模型时会“尽最大努力”。然而,我们的第二道防线仅旨在防御错位模型可能造成的严重危害。要防御错位模型对我们的自举过程进行破坏将更加困难,因为这涉及全新的研究工作,而这些工作可能难以验证。此外,防御严重危害并不意味着人工智能系统会在诸如对齐下一个模型之类的任务上“尽最大努力”,因此我们可能无法获得自举带来的好处。
- 关于通用人工智能(AGI)发展的假设
在本节中,我们阐述支撑我们技术安全方法的五个核心假设:
- 当前范式延续假设(第3.1节):在可预见的未来,前沿人工智能系统将继续在当前范式下发展。
- 无人类能力天花板假设(第3.2节):人工智能能力在达到与最能干人类相当的水平后,不会停止进步。
- 时间线不确定假设(第3.3节):高度智能人工智能未来发展的具体时间线仍不明确。
- 潜在加速改进假设(第3.4节):人工智能对科研与开发的自动化可能通过正反馈循环引发加速增长。
- 近似连续性假设(第3.5节):在计算资源和研发努力持续投入的前提下,人工智能能力不会出现大规模的不连续跃迁。
对于每一项假设,我们将总结支持它的证据,并概述其对我们技术安全方法的影响。
3.1 当前范式延续假设
我们的第一个核心假设是“当前范式延续假设”,我们将其定义为:在可预见的未来,开发前沿人工智能系统的主要方法将继续沿用当前范式。这一假设的关键影响在于,我们采用一种“随时可用”(anytime)的AGI安全方法,即一种可以在任何时间点实施的安全策略。由于我们认为当前范式是未来实现高能力人工智能系统最可能的研发路径,因此我们必须做好充分准备,以应对在当前范式下可能出现的高能力人工智能系统。此外,我们聚焦当前范式也是出于实用主义的考虑。简单来说,如果没有一个关于人工智能如何被开发的基本模型,就不可能制定出有效的风险缓解策略。
在本文中,我们将“当前范式”定义为一系列基于三个基础理念的技术方法:(1)扩大计算和数据规模的重要性(由硬件和软件的创新所推动);(2)学习和搜索在利用这些计算与数据赋予人工智能系统能力方面的核心作用;(3)算法创新的重要性,这些创新使计算和数据在学习与搜索过程中得到更高效的利用。
这些理念在大型语言模型(LLMs,Brown,2020)和结合推理时搜索的深度强化学习(Silver 等,2016)中得到了充分体现,其中深度学习(LeCun 等,2015)发挥了核心作用。
此外,我们也认为围绕这些技术所形成的生态系统——例如通过API调用实现工具使用,或通过架构搭建(scaffolding)由多模态大模型构建的智能体——也属于当前范式的一部分。我们的方法旨在对这一生态系统的各种变化保持稳健。
对我们人工智能安全方法的影响:由于我们假设学习和搜索将是未来人工智能系统的关键组成部分,因此我们需要一种准确的监督信号,以判断某个AI行为是好是坏。这促使我们重点关注“增强监督”(Amplified Oversight)算法的开发,使其即使在人工智能系统能力超越人类监督者时,仍能持续提供有效的监督信号(第6.1节)。
然而,即使有了增强监督,仍存在两个关键挑战,阻碍我们将该监督信号用于训练出符合预期行为的AI系统:第一,我们只能对训练分布内的行为提供监督;第二,我们预计增强监督信号的获取成本很高。
这些挑战促使我们发展稳健训练策略(robust training strategies),即重点扩展训练分布,尤其是那些容易引发失败的案例;同时也推动我们发展监控策略(第6.3节)。从概念上讲,监控是一种分级处理系统:先由低成本系统监督模型输出,仅将最可疑的案例升级至完整的增强监督。
值得注意的是,这两种策略都极大地受益于模型对不确定性的准确估计能力——这也是我们方法的另一项基础构件。具体而言,稳健训练策略可利用不确定性来选择最具信息量的训练样本,而监控模型则可利用不确定性来优化升级决策。
支持该假设的论据总结:从宏观上看,我们的论点基于以下观察:当前范式至今已有强大的成功记录,近期没有明显不可逾越的障碍,也没有其他竞争范式展现出同等的前景或进展。但为了更具体地论证,我们首先提出两个可能证伪“当前范式延续假设”的反对观点:
反对观点1:“当前范式将遭遇瓶颈”——在达到可能引发本文所述严重危害的人工智能能力之前,当前范式的发展将放缓至无限缓慢。反对观点2:“将发生范式转变”——一个新的范式将取代当前范式,人工智能研发领域将经历一次范式转移(Kuhn,1962)。
为反驳反对观点1,我们提出证据表明,在近期(未来五年内)人工智能能力仍将在当前范式下持续进步。为此,我们以2030年为未来时间范围进行论证。这既是出于可行性考虑——我们能够对推动当前范式发展的关键变量做出相对合理的预测(尽管我们预期当前范式会延续更久);也是出于实用主义考虑——在快速发展的研发环境中,长期规划极具挑战。因此,我们预计未来可能需要对我们的假设、信念和方法进行适当修订。
具体而言,我们对反对观点1的反驳包含三个主张:第一,迄今为止,人工智能能力的长期提升主要依靠计算、数据和算法效率的大规模增长。第二,历史上推动人工智能能力进步的主要“输入”(计算、数据、算法效率)在近期仍有可能以历史速度持续增长。第三,这些输入的持续扩展仍可能带来显著的人工智能能力提升。
我们对反对观点2的反驳与对反对观点1的论证有共通之处,并基于另外三项主张。第四项主张是:当前范式在研究专长和资本投入方面,相较于未来可能出现的任何竞争性范式,具有显著的“先发优势”。第五项主张(基于前三个主张)是:由于我们预期当前范式将持续取得进展,因此研究人员对替代范式进行投资的动力将减弱。第六项也是最后一项主张是:目前几乎没有成熟的替代方案展现出与当前范式相近的前景或快速进展的迹象。
需要注意的是,尽管我们认为有充分证据支持当前范式延续的假设,但我们承认预测未来极其困难。因此,我们必须做好准备,在出现反驳当前范式假设的证据时,及时调整我们对通用人工智能(AGI)的方法。
更具体地说,如果反对观点1被证实为真——即当前范式确实遭遇瓶颈——那么支撑我们技术方法的许多研究投入将变得不再相关。然而,从缓解严重危害的角度来看,这种情况下的失败是相对温和的。因为人工智能能力的进步可能大幅放缓,通过本文第4节所述路径由人工智能引发严重危害的风险将显著降低,因此对相关技术缓解措施的需求也随之减弱。
如果反对观点2被证实为真——即确实发生了范式转变——那么对严重危害缓解的影响将更为重大。本文所概述的许多计划将不再适用。一旦这种情况发生,我们将需要从根本上重新思考我们的整体方法。
3.1.1 计算、数据与算法效率作为人工智能能力进步的驱动力
我们的前三项主张指出:(1)计算、数据和算法效率是过去人工智能能力进步的关键因素;(2)这些投入要素在未来五年内很可能以接近历史速度继续增长;(3)这种增长将继续带来人工智能能力的进一步提升。
主张1:长期的人工智能能力提升是由计算、数据和算法效率的大规模增长所驱动的。
二十多年前,Moravec(1998)在反思人工智能进展时指出:“……人工智能机器的性能往往随着研究人员获得更快硬件的速度而同步提升。” 近年来,Sutton(2019)评估了人工智能研究的发展轨迹,并得出了类似结论,强调计算性价比持续提升的关键作用,他指出:“从70年的人工智能研究中可以得出的最大教训是,那些依赖计算的通用方法最终被证明是最有效的,而且优势巨大。其根本原因在于摩尔定律,或者说计算单位成本持续呈指数级下降这一更广泛的趋势。”
为支持这一观点,Sutton(2019)引用了涵盖国际象棋、围棋、语音识别和计算机视觉等多个领域的项目,其中基于学习和搜索的通用方法在获得足够计算资源后,最终超越了专用方法。事实上,过去15年中机器学习文献中引用率最高的许多成果都高度依赖这一趋势。在自然语言处理领域,突破性性能是通过扩大计算、数据和模型容量实现的(Mikolov,2013;Amodei 等,2016a;Radford 等,2019;Brown,2020)。在强化学习领域,大规模计算使得深度神经网络与蒙特卡洛树搜索的结合在围棋游戏中实现了超越人类的表现(Silver 等,2016)。尽管最初是通过人类对弈数据训练实现的,但后续版本仅通过自我对弈就达到了相同水平(Silver 等,2017),并在其他棋盘游戏中同样超越了人类专家(Silver 等,2018)。在语音识别领域,模型容量和数据量的增加带来了性能的显著提升(Amodei 等,2016a)。在计算机视觉领域,硬件加速器的使用使研究人员能够不断扩大卷积神经网络(CNNs)的规模(Krizhevsky 等,2012;Simonyan 和 Zisserman,2014;He 等,2016;Hu 等,2020),以利用ImageNet等项目提供的更大规模训练数据集(Deng 等,2009)。
需要注意的是,尽管许多前沿系统都比其前身使用了更多的计算和数据,但并非所有方法都能同等受益于这些资源的增加。与Sutton(2019)的观点一致,随着计算规模的扩大,Transformer架构(Vaswani,2017)——相比CNN等架构具有更少的归纳偏置——逐渐占据主导地位。减少归纳偏置的影响在计算机视觉领域尤为明显:只有当预训练数据规模远超ImageNet的一百万张图像时,Transformer才被发现能超越CNN(Dosovitskiy,2020)。
除了计算和数据推动人工智能进步的定性证据外,越来越多的研究表明,可以明确量化计算与数据的扩展与人工智能能力在若干关键指标之间的关系。基于早期理论工作(Amari 等,1992)和实证研究(Banko 和 Brill,2001;Amodei 等,2016a;Sun 等,2017)所展示的数据增加带来的性能稳定提升,Hestness 等(2017)刻画了数据集规模、模型规模与泛化指标(如验证集上的交叉熵损失)之间的关系。他们的结果表明,在所研究的各项任务(翻译、语言建模和图像分类)中,均存在相对平滑的幂律关系。Kaplan 等(2020)在此基础上进行大规模研究,揭示了计算量、数据集大小、模型容量与语言建模损失之间存在平滑的幂律关系,其“缩放定律”趋势跨越了六个数量级。
随着训练资源的增加,如何高效利用这些资源也受到越来越多的关注。Hoffmann 等(2022)重新审视了Kaplan 等(2020)得出的幂律系数,提出了修正估计,最终实现了在固定FLOP预算下训练出更强大模型的目标。最近,缩放定律在指导前沿大语言模型(LLM)的训练决策中发挥了关键作用(Achiam 等,2023;Gemini Team 等,2023;Dubey 等,2024)。
尽管许多缩放研究聚焦于预测模型损失等属性,但也有一些研究直接将计算量与下游模型能力(如在多个任务上的综合表现)联系起来。Owen(2024)进行了此类研究,得出结论:综合基准性能确实可以从计算扩展中较为准确地预测。类似地,Yuan 等(2023)观察到,缩放定律所追踪的预训练损失改善直接转化为推理基准上的性能提升。
计算和数据扩展是人工智能发展关键驱动力这一观点,也可以从人工智能开发者的实际行为中得到印证。Amodei 和 Hernandez(2018)估计,2012年至2018年间,最大规模训练运行所使用的总计算量增长了约30万倍。在更长的时间跨度(2010–2024年)内,Sevilla 和 Roldán(2024)估计前沿训练运行所使用的总计算量年均增长率约为4倍。
除了利用训练时计算提升学习效果外,多项研究还观察并量化了通过扩大推理时计算(test-time computation)以增强搜索所带来的平滑能力提升。Jones(2021)在一系列AlphaZero智能体(Silver 等,2018)上开展研究,证明训练计算可以平滑且可预测地与推理时计算(用于蒙特卡洛树搜索)进行权衡,同时保持游戏表现。Villalobos 和 Atkinson(2023)在Jones(2021)的基础上,汇总了多个领域的证据,表明增加推理时计算通常能带来可预测的性能提升。在编程领域,Li 等(2022)发现,使用额外计算对模型进行重复采样,与正确解的生成呈对数线性关系。尽管作为搜索策略较为简单,但扩大对大语言模型响应的简单重复采样已被证明在生成至少一个正确解方面异常有效(Brown 等,2024)。更广泛地,通过Best-of-N采样(Nakano 等,2021)或针对过程奖励模型的束搜索(beam search,Lightman 等,2023)等策略扩大推理时搜索,在推理任务上也表现出平滑的性能提升(Snell 等,2024)。
除了扩大数据和计算外,推动人工智能进步的第三个关键因素是算法创新。它通过提高数据和计算在问题求解中的使用效率,起到“力量倍增器”的作用。在对六个算法研究领域(SAT求解器、国际象棋、围棋、物理模拟、因数分解和混合整数规划)的研究中,Grace(2013)估计,算法进步带来的收益相当于硬件进步的50%到100%。Hernandez 和 Brown(2020)估计,训练一个分类器在ImageNet上达到AlexNet(Krizhevsky 等,2012)准确率所需的浮点运算次数,从2012年到2019年减少了44倍。这意味着算法效率每16个月翻一番,持续7年(快于摩尔定律)。Karpathy(2022)通过应用期间积累的算法创新,重新实现了LeCun 等(1989)的手写数字识别神经网络,错误率降低了60%,证明了这一进步。Erdil 和 Besiroglu(2022)试图将人工智能进步分解为扩展(计算、模型大小和数据)与算法创新两个独立因素,得出结论:算法进步大约每九个月就能使有效计算预算翻倍。Ho 等(2024)进一步扩展这一方法,研究了2012年至2023年语言模型预训练中的算法改进。在此期间,作者估计达到特定性能阈值所需的计算量大约每八个月减半。
总结:我们讨论了支持主张1的多个证据来源。首先,我们强调了资深研究人员的定性观察(并有实证数据支持),指出计算增加推动了人工智能进步。其次,我们描述了一个显著趋势:过去10-15年中许多人工智能能力的突破都是通过扩大计算、数据(并辅以算法效率提升)实现的。接着,我们介绍了多篇旨在更精确量化计算、数据、算法效率与人工智能能力提升之间关系的研究论文。总体而言,我们认为这些文献表明,计算、数据和算法效率的扩展至今一直是性能提升的关键驱动力。此外,我们引用的分析表明,人工智能开发者已大幅增加用于训练的计算和数据,这反映了他们相信这些投入是提升人工智能能力的关键。综合来看,我们认为主张1得到了上述证据的强有力支持。
主张2:在未来五年内,计算、数据和算法效率的提升很可能以近年的历史速度继续增长。
如上所述,我们认为迄今为止推动前沿人工智能进步的关键因素是计算、数据和算法效率的扩展。接下来,我们考虑这种扩展是否有可能持续下去。为了评估其可能性,我们首先注意到,最大规模训练运行的计算扩展速度(每年约4倍,Sevilla 和 Roldán,2024)似乎是前所未有的。正如 Sevilla 等人(2024)所指出的,这一增长速度超过了历史上最迅猛的技术扩张。具体而言,它超过了太阳能装机容量增长峰值(每年1.5倍,2001–2010年)、手机普及率增长(每年2倍,1980–1987年)以及人类基因组测序速度(每年3.3倍,2008–2015年)。因此,评估这种扩展在技术上是否可持续至关重要。
在迄今为止对该主题最详细的研究中,Sevilla 等人(2024)探讨了是否存在技术障碍,会阻止前沿训练运行的计算量继续以每年4倍的速度增长。特别是,该分析评估了到2030年实现一次2×10²⁹ FLOPs训练运行(相当于从GPT-4的训练计算量扩大10,000倍,Achiam 等,2023)的可行性。Sevilla 等人(2024)重点关注了四个潜在瓶颈:
第一个潜在瓶颈是电力供应(特别是美国的电力供应,迄今为止最大规模的公开训练运行均发生在美国)。作者判断,所需的电力(特别是1–5吉瓦级别的数据中心园区)很可能是可用的,因此电力供应不会限制当前增长轨迹下的扩展。此外,分布式训练(Douillard 等,2023,2024)可使前沿训练运行获得更大规模的电力支持。
第二个潜在瓶颈是硬件加速器(如GPU和TPU)的供应。尽管对未来产能的估计存在较大不确定性,但 Sevilla 等人(2024)认为,到2030年拥有足够加速器产能以支持2×10²⁹ FLOPs训练运行是高度可能的。更具体地说,作者预测届时将有相当于1亿个H100 GPU的产能可供训练使用(在合理假设下足以支持2×10²⁹ FLOPs的训练运行)。
第三个瓶颈是数据稀缺性——即是否有足够的数据来继续扩展前沿训练运行。总体而言,作者得出结论:训练数据不会成为限制因素,因为在线文本数据预计将持续增长,且存在大量多模态数据语料库可供使用。
第四个瓶颈是 Sevilla 等人(2024)研究的最后一个瓶颈,即“延迟墙”(latency wall)。这是指在假设批处理规模无法无限扩展的前提下,深度神经网络前向和反向传播所需的最短时间所构成的有效速度上限。然而,与其他限制因素一样,作者预测这一限制也不会阻止扩展。
尽管上述分析强调了计算和数据持续扩展在技术上的可行性,但它并未提供证据表明人工智能开发者愿意投入数千亿美元来实现这种扩展。在很大程度上,这种意愿似乎取决于中间模型所提供的证据:即扩展是否持续带来人工智能能力的提升,并最终产生显著的经济价值。然而,鉴于全球GDP中超过50%为劳动力报酬(国际劳工组织,2022),自动化所带来的经济激励显然是巨大的。因此,Sevilla 等人(2024)得出结论:不仅持续扩展在技术上可行,而且人工智能开发者投入所需资金来实现这一扩展也是合理的。
预测未来算法效率提升的速度具有挑战性。Ho 等人(2024)指出,这一速度似乎与投资水平以及人工智能替代人类劳动的程度密切相关。尽管如此,我们并未发现明确证据表明,如果计算和数据的扩展速度保持当前轨迹,算法效率的提升会偏离其历史进展速度(对大语言模型而言,每八个月有效计算量翻倍)。因此,我们认为有充分证据支持主张2:在未来五年内,计算、数据和算法效率的提升很可能以近年的历史速度继续增长。
主张3:未来计算与数据的扩展,结合算法进步,将继续带来人工智能能力的实质性提升。
为支持主张1,我们列举了大量证据,表明长期的人工智能能力提升是由计算、数据和算法效率的大规模增长所驱动的。回顾这些证据,我们观察到,当前范式已积累了将计算和数据等“输入”转化为人工智能能力提升这一“输出”的稳健记录。因此,如果这些输入的进一步扩展不再带来人工智能能力的显著提升,那将令人惊讶(尽管这种情况确实可能发生)。因此,我们认为现有证据总体上为主张3提供了合理支持,尽管仍存在一定不确定性。
3.1.2 替代范式面临的挑战
我们剩余的几项主张涉及其他替代范式在取代当前范式过程中所面临的困难。
主张4:与未来可能出现的任何竞争性范式相比,当前范式在研究专长和资本投入方面具有显著的“先发优势”。
为支持主张4,我们首先指出,众多人工智能开发者已基于对当前范式持续成功的预期,进行了大规模的基础设施投资。如前所述,这些投资在过去14年中推动了训练计算量每年约4倍的空前增长(Sevilla 和 Roldán,2024)。事实上,据估计,训练前沿系统的美元成本在2016年至2024年间每年增长2.4倍(Cottier 等,2024)。作为此类投资规模的一个例证,为前沿模型训练提供最大硬件加速器供应的英伟达(NVIDIA),在过去五年中市值增长了约30倍。需注意的是,现代前沿规模的投资需要长期规划和承诺,且一旦投入便难以轻易调整。由于这些投资专门针对当前范式,新的范式很难以同等效率利用这些现有资源。
第二个关键因素是研究与工程专长。当前范式的成功催生了对特定研究和工程技能的强烈市场需求——即那些能够在当前范式下的研发体系中有效应用的技能。为满足这一需求,教育机构和企业已培训出一支具备相应技能的劳动力队伍。一个具体的例子是,2023年,Coursera平台上的人工智能相关课程吸引了680万次注册(Coursera,2023),其中最受欢迎的课程(由DeepLearning.AI提供)至今已有近40万人次注册。鉴于这支不断壮大的劳动力队伍的专业背景,他们最有可能在当前范式内提出新思想和技术革新,从而进一步扩大当前范式相对于竞争者的领先优势。
主张5:如果当前范式继续取得进展,对替代范式的研究投资将缺乏足够动力。
在反驳“反对观点1”时,我们列举了证据表明当前范式很可能继续推动人工智能进步。如果情况确实如此,那么对替代范式的研究投资动力减弱将有多个原因: 第一,投资于未经验证的替代范式风险更高,相比之下,当前范式持续产出更强的人工智能能力,更具吸引力; 第二,替代范式的基础研究通常需要更长的研发周期,而当前范式内的研究投资能在更短时间内获得回报; 第三,如上所述,人工智能开发者已在支持当前范式发展的基础设施和人才队伍上投入巨大。转向其他范式可能导致这些资产被搁置或贬值。
在此我们指出对主张5的一种反论点:如果前沿人工智能开发的计算需求持续呈指数增长,资本需求也将随之上升,这将增加投资于能在更低成本下实现能力提升的替代范式的动机。然而综合来看,我们预计当前范式仍将继续吸引绝大多数研究投资。
主张6:目前几乎没有成熟的替代方案展现出与当前范式相近的前景或快速进展的迹象。
我们支持主张6的主要论点很简单:我们并不知晓任何成熟(甚至初具雏形)的替代方案,能够显示出与当前前沿人工智能发展模式相匹敌的竞争力。两种若占据主导地位便会违背我们假设的替代范式具体例子包括:极少使用学习范式的系统(Buchanan 和 Smith,1988),以及通过“意识上传”创造仿真人类的技术(Hanson,2016)。我们在此指出,这一论点并非决定性的——历史上存在许多范式转变的先例(Kuhn,1962),我们也不能声称对整个人工智能发展领域拥有全面无遗的认知。
3.2 人工智能能力不存在人类天花板
我们的第二个核心假设是“无人类能力天花板假设”(no human ceiling assumption)。我们将其定义为:人工智能能力的进步不会在达到人类中最能干者在某项任务上的能力水平后停止。换句话说,我们假设并不存在一个设定人工智能能力上限的“人类天花板”。
对我们安全方法的影响:“无人类天花板假设”带来的主要影响是,我们的安全方法必须随着新的人工智能能力的出现而加以利用,才能保持有效性。初期,这将意味着在整个研发过程中及早采用人工智能辅助工具——这一过程是增强(augmentation)而非替代(replacement)。随着能力的持续提升,我们预计会将越来越复杂的研发与工程任务委托给人工智能助手。最终,为了跟上人工智能能力的快速发展,我们认为绝大多数与人工智能安全相关的认知工作将不得不由人工智能自身完成。这一过渡时期将对应一个风险升高的阶段,因为任务的委托意味着进展速度将比当前快得多。这将要求我们在相对于人类时间尺度而言较短的周期内做出决策。因此,这一时期也将更加凸显人类高效验证人工智能安全研究成果的重要性(Irving 等,2024)。为应对这些挑战,我们开发“增强监督”(Amplified Oversight)算法的目标是确保在人工智能能力超越人类后,人类仍能提供有意义的监督(后文将详述)。我们在可解释性(Interpretability,第6.6节)方面的投入,旨在通过加深对人工智能系统运作机制的理解,进一步提升我们监督未来系统的能力。随着人工智能能力的增长,对齐压力测试(Alignment Stress Testing,第6.7节)的重要性也将提升,以提供更强的保障。更广泛地说,我们致力于构建稳健的安全案例(Safety Cases,第6.8节),形成整体性论证,指导我们将内部人工智能能力作为加速人工智能安全研究的推动力。
支持证据概要:我们支持“无人类天花板假设”的论证包含三项主张:第一项主张是:在多个任务上,人工智能已明确展现出超越人类的表现。这提供了一个“概念验证”,表明确实存在一些具体且定义清晰的任务,人类能力并未构成人工智能能力的实质性上限。第二项主张是:人工智能的发展呈现出向更通用、更灵活系统演进的趋势。因此,我们预期未来将有越来越多的任务出现超越人类的能力。第三项主张是:我们并未发现任何有说服力的原则性论据,能够说明人工智能能力在达到最能干人类的水平后就会停止进步。
支持性论点与证据
主张1:在多个任务上,人工智能已明确展现出超越人类的表现。1997年击败世界冠军加里·卡斯帕罗夫的国际象棋系统“深蓝”(Deep Blue,Campbell 等,2002)是人工智能在单一任务上实现超人类表现的早期范例。此后,最强人工智能国际象棋系统的能力持续提升(CCRL,2024),到2024年其Elo评分为3643。相比之下,人类棋手迄今达到的最高Elo评分为2882,由马格努斯·卡尔森于2014年创下(ChessDB,2016)。这一评分差距意味着人工智能系统对阵史上最强人类棋手的预期胜率高达98.8%。第二个例子是沃森系统(Watson,Ferrucci 等,2010),它在2011年电视问答节目《危险边缘》(Jeopardy!)中击败了两位最强的人类选手。类似地,人工智能在围棋(Silver 等,2016,2017)和将棋(Silver 等,2018)中也明确展现出超越人类的表现。在游戏之外,根据Morris 等人(2023)的观点,我们认为AlphaFold(Jumper 等,2021)在“根据氨基酸序列预测蛋白质三维结构”这一任务上,其准确性已超过最能干的科学家,实现了超人类表现。
当然,在极窄的领域(如浮点运算)中,计算机系统早已超越人类。但我们注意到,随着可用计算资源的增加,人工智能正越来越多地在复杂度更高的领域取得突破。例如,围棋远比国际象棋更具挑战性。AlphaGo(Silver 等,2016)的成功不仅依赖算法创新,还得益于远超深蓝时代可用的计算资源。总之,已有多个任务上的人工智能系统明确实现了超人类表现。近年来,这类任务的范围已扩展到围棋和蛋白质结构预测等高度复杂的领域。
主张2:人工智能发展呈现出向更通用、更灵活系统演进的趋势。历史上,许多人工智能系统被设计用于在狭窄、特定任务上达到专业水平。这种方法以深蓝在国际象棋上的精通(Campbell 等,2002)为代表,通过专业化实现了可管理的进展。然而,近年来人工智能发展显现出向更通用系统转变的明确趋势。GPT-3(Brown,2020)和Gopher(Rae 等,2021)等系统在翻译、问答、基础算术和事实核查等多种任务上展现了基本能力。后续系统如GPT-4(Achiam 等,2023)、Gemini 1.5(Gemini Team 等,2024)和Llama 3.1(Dubey 等,2024)进一步推进了这一进展,在编程、数学和图像理解等任务上达到了基本胜任水平。与以往通常需要针对特定任务进行微调才能激发有用功能的系统不同(Bommasani 等,2021),这些系统通常能够以零样本(zero-shot)方式执行任务,无需额外适应。此外,多模态模型的发展趋势也十分显著,这些模型能够处理和整合文本、图像、视频和代码等多种模态的信息,进一步强化了系统向更高灵活性和泛化能力发展的趋势。
尽管这些通用系统在多数任务上的表现仍远低于人类专家,但已有明确迹象表明其能力正在快速提升。o1模型(OpenAI,2024)在CodeForces的竞赛编程问题基准测试中排名前11%(第89百分位),并在美国数学奥林匹克(AIME)资格赛中跻身全美前500名学生之列。同一模型还在Rein 等(2023)提出的研究生水平物理、生物和化学问题基准测试中,准确率超过了人类博士水平。我们认为o1模型是通用灵活人工智能系统发展的一个范例,同时其能力已接近人类专家水平。总体而言,我们观察到人工智能系统正朝着更通用、更灵活且能力不断提升的方向明确演进。
主张3:我们未发现任何有说服力的原则性论据,能够说明人工智能能力在达到最能干人类的水平后就会停止进步。
我们支持主张3的主要证据在一定程度上属于经验性观察:我们曾尝试寻找“人工智能能力在达到最能干人类水平后将停止提升”的原则性论据,但未能成功找到。当然,我们必须承认自身知识的局限性,也不能完全排除此类论据存在的可能性。然而,我们注意到,迄今为止观察到的许多超人类表现案例(Silver 等,2016,2018;Jumper 等,2021)所采用的算法方法与人类所使用的方法存在显著差异。这增强了这样一种观点:人类的能力并不必然构成人工智能系统能力的限制。此外,鉴于迄今为止计算资源与人工智能能力之间存在强烈相关性(Kaplan 等,2020;Hoffmann 等,2022;Achiam 等,2023;Owen,2024;Yuan 等,2023),以及计算持续扩展的明确可能性(Sevilla 等,2024),我们认为现有证据的总体倾向表明:人工智能的进步不太可能在人类最高认知能力水平处停止。
3.3 人工智能发展的时间线仍不确定
我们的第三个核心假设是“时间线不确定假设”(uncertain timelines assumption)。我们将其定义为:人工智能的发展时间线是不确定的。因此,各种可能的时间线——尤其是较短的时间线——都是合理的。
为了锚定我们对时间线的估计,并与现有预测进行比较,我们必须明确所预测的人工智能能力水平。为此,我们采用 Morris 等人(2023)提出的“卓越级通用人工智能”(Exceptional AGI)的定义。卓越级通用人工智能是指在广泛的非物理任务(包括学习新技能等元认知任务)上,能力至少达到熟练成年人前1%水平的系统。Morris 等人(2023)指出,这一能力水平是许多与人工智能最严重风险相关担忧可能开始出现的临界点。我们将“短时间线”定义为在本十年结束前实现卓越级通用人工智能。
对我们人工智能安全方法的影响:人工智能安全研究在对当前系统的适用性方面存在差异。一方面,存在可随时部署的缓解措施(anytime mitigations),可在需要时立即应用;另一方面,也存在更广泛的、基础性的探索,这些探索可能需要多年才能见效,但有潜力带来更大的安全收益。然而,鉴于时间线的不确定性,前沿人工智能开发者必须具备一种“随时可用”的安全方法,以应对短时间线的情况。正因如此,本文聚焦于可集成到当前前沿人工智能开发中的缓解措施,而将更基础性的探索排除在范围之外。
支持证据概要:我们支持“时间线不确定假设”的论证包含两项主张:第一项主张是:现有大量人工智能预测表明,各种不同时间线都是可能的。第二项主张是:时间线的不确定性是合理的,因为技术发展预测本身具有高度挑战性。
支持性论点与证据
主张1:现有预测支持广泛的时间线范围。预测达到“卓越级通用人工智能”阈值(或任何未来能力水平)的人工智能何时出现,是一项极具挑战性的任务。然而,有两个显著的证据可作为构建人工智能时间线框架的基础:(1)计算性能价格长期持续、相对平稳的历史趋势;(2)人类大脑计算量的近似上限。因此,围绕这两个维度的实证数据催生了大量关于人工智能时间线的预测。
需要注意的是,尽管许多人工智能预测都估算了某种“先进人工智能能力”的出现时间,但它们对这一概念的操作化定义往往略有不同(例如,有的关注经济影响,有的关注技能水平)。以下列出的每项预测,我们都将说明其所针对的人工智能能力阈值(尽管该阈值并不总是被明确定义)。读者可参考 AI Impacts(2022)和 Wynroe 等人(2023)对人工智能时间线的文献综述,以下我们总结几项显著预测。
以计算为中心的预测最早由 Good(1970)提出,他通过估算人类大脑规模(约10¹²个神经元)并假设微型化的历史趋势将持续,预测“智能机器”(能力相当于人类)将于1993年(±10年)出现。Moravec(1998)提出了一个更明确的模型,将人类神经体积与计算能力关联起来。特别是,他通过估算人类视网膜与计算机视觉算法之间的等效关系,从市场趋势外推,预测在2020年代将出现价格可承受的、性能匹敌人类大脑的硬件。Bostrom(1998)进一步扩展了这一论点,纳入经济和军事激励因素,论证了本世纪前三十年内机器智能可能远超人类智能的可能性。Kurzweil(2005)将摩尔定律的轨迹视为更广泛的“加速回报定律”演化过程的一部分,预测2029年将通过某一特定形式的图灵测试。这种Kapor-Kurzweil图灵测试变体(Kurzweil,2002)包括三位人类评委、三位人类对照和一个AI。每位评委分别与三位人类对照和AI进行四次两小时的访谈(共24小时)。如果三位评委中有两位或以上被误导,认为AI是人类,则视为通过测试。为评估这一时间线的合理性,我们注意到,在Metaculus预测平台上,社区预测该测试将在2029年通过的概率已从2020年5月的26%上升至2024年10月底的80%(Metaculus,2024)。
Cotra(2020)进行了一项特别详细的预测练习,聚焦于“变革性人工智能”(transformative AI)的出现,定义为影响力堪比工业革命的人工智能。其时间线通过以下因素构建:人类大脑计算量的估算(围绕“生物锚点”,如人类一生中的学习量)、算法进步预测(相对于2020年)、计算成本下降趋势,以及对单次训练运行可能投入资本规模的预测。最终预测显示,变革性人工智能的中位数出现时间为2052年,到2036年出现的概率为15%。两年后,同一作者的后续分析将中位数时间缩短至2040年,到2030年出现的概率为15%(Cotra,2022a)。Davidson(2023)也基于Cotra(2020)估算的训练需求,采用半内生增长模型考虑研发投入的增加,预测变革性人工智能的中位数出现时间为2043年。
与Cotra(2020)等采用“内部视角”(inside view,Kahneman,2011)的方法(即基于人工智能发展具体机制的明确计算模型)不同,Davidson(2021b)采用“外部视角”(outside view)预测,聚焦于参考类比和贝叶斯推理。这种方法不考虑人工智能发展的具体方式,预测到2036年实现通用人工智能(AGI)的概率为8%。此处AGI定义为:“计算机程序能够以不高于人类成本的价格,完成任何人类能完成的认知任务。”
另一类预测方法试图通过问卷调查人工智能领域专家,其中2016年(Grace 等,2018)、2022年(Grace 等,2022)和2023年(Grace 等,2024)的调查尤为突出。这些调查涵盖人工智能发展的广泛问题。特别值得关注的是对“高水平机器智能”(HLMI)出现时间的预测,其定义为:无需辅助的机器能在所有任务上表现优于并更便宜于人类工人。2016年综合预测估计HLMI在2061年实现的概率为50%;2022年调查中降至2060年;2023年进一步大幅提前13年,至2047年。
总结上述讨论:我们观察到,基于多种预测方法的人工智能发展时间线预测覆盖了广泛范围。这些多样化的预测中包括对短时间线的支持,最典型的例子是Metaculus(2024)的社区预测,显示2029年通过Kapor-Kurzweil图灵测试变体的概率高达80%。
物理极限是否相关?如第3.1节所述,计算资源的扩展是推动人工智能能力的关键驱动力。由于这些计算必须在物理硬件上实现,因此有必要考虑物理极限是否会影响人工智能时间线的讨论。从长远来看,物理学确实对摩尔定律等指数级硬件趋势设定了限制(Moore,1965;Moore 等,1975)。Lloyd(2000)通过构想“终极笔记本”(the ultimate laptop)指出,摩尔定律(以18个月翻倍计)不可能持续到2250年之后。Krauss 和 Starkman(2004)则考虑了在不断膨胀的宇宙中,任何技术文明所能实现的总计算量上限——这种方法对摩尔定律设定了(更宽松的)600年限制。然而,由于我们距离这些极限还非常遥远,因此不认为它们会对“卓越级通用人工智能”的实现时间线产生实质性影响。
主张2:由于技术预测本身具有挑战性,因此对时间线的不确定性是合理的。
预测在规划中扮演着关键角色,但我们对技术时间线的预测能有多大信心?历史充满了预测失误的案例。就在诺贝尔奖得主欧内斯特·卢瑟福(Ernest Rutherford)宣称任何声称核反应能提供强大能源的说法都是“空谈”(moonshine)的几天后,利奥·西拉德(Szilard)便提出了中子链式反应的概念(Adams,2013)。1960年,另一位诺贝尔奖得主赫伯特·西蒙(Herbert Simon)写道:“机器将在二十年内胜任人类所能做的任何工作。”(Simon,1960)。然而至今,这一预言仍未实现。
迄今为止,人工智能预测者的记录并不理想。Armstrong 和 Sotala(2015)分析了一个包含95项2015年之前的人工智能预测的数据库。总体而言,他们发现专家预测之间相互矛盾,且与非专家的预测并无显著区别。针对两个广为流传的“民间法则”,他们并未发现支持“梅斯-加罗定律”(Maes-Garreau law,Kelly,2007)的证据——该定律认为人工智能专家倾向于将人工智能的出现时间预测在自己生命即将结束之时;但他们确实发现,大量预测集中在“人工智能将在15到25年内到来”这一时间范围。
此外,主流人工智能开发者之间的观点也存在巨大分歧(Korzekwa 和 Stewart,2023)。因此,我们认为,在对任何特定未来路径赋予高置信度时,必须保持谨慎。
3.4 能力加速提升的潜在可能性
我们的第四个核心假设是“潜在加速改进假设”(the potential for accelerating improvement assumption)。我们将其定义为:人工智能系统的应用很可能引发一个加速增长阶段,因此我们必须将其视为规划中的一个重要因素。更具体地说,我们认为,科学研发的初步自动化很可能会支持开发出能力越来越强的人工智能研究系统,从而进一步加速研发进程,形成一个正反馈循环。
这种结果的可能性曾被形象地称为“是‘爆燃’(Foom)还是‘熄火’(Fizzle)?”8。为明确起见,我们采用 Erdil 等人(2024)的定义:“爆燃”(Foom)描述的是这样一种情景:人工智能系统对人工智能软件带来成比例的改进,从而导致后续由人工智能驱动的研发产出和技术进步出现超比例提升,进而实现加速发展。“熄火”(Fizzle)则描述的是另一种情景:人工智能系统对软件带来成比例的改进,但其后续由人工智能产生的研发产出却出现低于比例的提升,导致技术进步放缓。在这一术语体系下,我们的假设对应于“爆燃”情景是可能发生的这一主张。
对我们安全方法的影响:加速增长阶段可能从根本上加快人工智能发展的速度。因此,面对新出现的技术进展,我们可能几乎没有时间做出反应,也难以就风险缓解做出良好决策。因此,我们的风险缓解策略最终也必须通过人工智能的辅助大幅加速,以确保我们具备能力及时应对和处理新出现的风险。
支持证据概要我们支持“潜在加速改进假设”的论证包含三项主张:第一项主张是:尽管学术界观点多样,但经济学文献中存在支持极快速(特别是双曲式)增长可能性的论据。第二项主张是:尽管证据不一,但已有一定证据表明,软件研发的回报可能高到足以支持“纯软件奇点”(software-only singularity)——即研发投入的高回报导致双曲式增长(Davidson,2023)。第三项主张是:人工智能研究者的调查结果与快速加速增长的可能性一致。
支持性论点与证据
主张1:经济学文献支持多种关于加速增长的观点,包括极快速增长的可能性。目前,研究人员对于极快速增长的可能性仍存在显著分歧,尤其是在考虑未来几十年的时间范围内。Nordhaus(2021)指出,决定极快速增长可行性的关键因素在于信息投入与传统非信息投入之间的可替代程度。通过分析迄今为止的实证经济数据中的一系列诊断性指标,Nordhaus 得出结论:快速加速阶段尚在遥远的未来(经济增速达到20%还需100年或更久)。Christensen 等人(2018)对专家经济学家进行调查,也发现短期内爆发性增长的可能性较低(综合中位预测为2010年至2100年全球增长率为2%,且在本世纪下半叶将放缓)。在更短的时间范围内,Acemoglu(2024)同样预测影响有限(例如,预测未来10年美国GDP因人工智能带来的增长不会超过0.9%)。
与此观点形成对比的是,也有文献支持资本替代劳动力的前景,这一思想可追溯至凯恩斯(Keynes,1931)。Hanson(2001)指出,在这种假设下,爆发性增长变得高度可能。这一观点与Hanson(2000)的早期工作一致,后者观察到,从长期历史尺度建模增长趋势,指向21世纪中叶可能出现爆发性增长。更广泛地,Sandberg(2013)指出,现有的内生增长模型和Hanson的模型都支持一个结论:如果某种形式的“心智资本”(可体现在人类或人工智能中)变得易于复制且成本低廉,那么极快速的增长很可能随之而来。Erdil 和 Besiroglu(2023)分析了12项支持和反对“爆发性增长”(即增长速度大约提升一个数量级)可能性的论点,认为本世纪末前发生此类增长的概率为50%,但也强调该估计存在高度不确定性。Trammell 和 Korinek(2023)综述了多个关于人工智能影响的经济模型,表明在多种模型中,增长率的急剧上升是可能的。Davidson(2023)基于Cotra(2020)对“变革性人工智能”(影响力堪比工业革命的人工智能)训练需求的估算,采用半内生增长模型,预测从人工智能能够自动化20%人类认知劳动(按2020年经济价值加权)到接近100%所需的时间。该模型得出的中位数估计为3年,对应“有效计算量”(考虑随时间提升的软件效率)增加四个数量级。
Erdil 等人(2025)最近的建模工作结合了实证缩放定律和半内生增长理论,模拟了计算、自动化和生产的演变,结果支持全球生产总值(GWP)可能出现极快速的增长(例如,2045年增长率超过每年30%),其参数来自实证数据、现有文献和合理判断。Moorhouse 和 MacAskill(2025)对智能爆炸的可行性与后果进行分析,估计人工智能有超过50%的概率在十年内带来相当于一个世纪的技术进步。
从这些文献中可归纳出两个关键主题(Davidson,2021a):第一,基于“创意”的长期增长模型表明,人工智能通过自动化研发并引发创意正反馈循环,有可能引发爆发性增长。第二,如果人工智能能够使资本替代劳动力,那么广泛的经济模型都预测将出现爆发性增长。
主张2:软件研发的回报可能高到足以支持双曲式增长。自人工智能领域诞生之初,研究人员就认识到,达到某一阈值水平的人工智能进展可能引发后续发展的快速加速。I.J. Good 在1959年写道:“一旦设计出一台足够好的机器(例如耗资一亿美元),就可以让它着手设计一台更好的机器。此时,‘爆炸’显然会发生;所有科学与技术问题都将交由机器处理,人类将不再需要工作。” 在思考这种过渡期可能呈现的形式时,Good(1959)推测,加速的迹象可能在前期并不明显:“很可能,直到机械大脑接近临界规模之前,它都不会真正有用。如果如此,那么从没有非常好的机器到拥有大量极其优秀的机器之间,将只有非常短暂的过渡期。” 这一观点被 Bostrom(1998)所呼应,他指出,除了技术因素外,当人工智能接近人类水平时,其边际效用将急剧上升,从而进一步刺激资金投入。
理解这一可能性的核心在于估算“研发回报率”(returns to R&D),这是一项极具挑战性的任务,已引起经济学界的广泛关注(Bloom 等,2020)。在人工智能发展背景下,人们尤其关注Good(1959)所定义的“智能爆炸”是否可能,以及此类事件可能带来的动态机制(Chalmers,2010)。Yudkowsky(2013)从经济学角度形式化了这一概念,提出“认知再投资回报”(returns on cognitive reinvestment)的概念,定义为:“将更多计算能力、更快的计算机或更优的认知算法投入,以产生认知劳动,进而产出更大的大脑、更快的大脑或更好的心智设计。”
在此方面的一个具体挑战是,难以获得关于前沿人工智能研发回报的可靠估计。目前可能获得较合理实证数据的、与人工智能研发最相关的代理指标是软件研发(software R&D)。迄今为止关于软件研发回报最详细的研究由 Erdil 等人(2024)完成(作为他们对增长模型中创意产出估算方法的广泛方法论调查的一部分)。我们简要总结其分析的关键要点如下。
Erdil 等人(2024)基于 Jones(1995)的半内生增长模型展开其分析,该模型可表述如下:
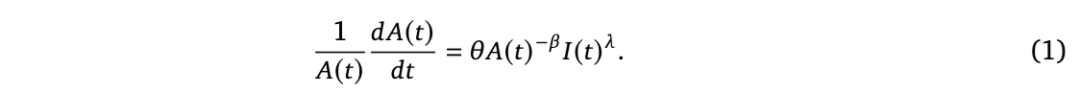
其中,I(t) 表示对研发(R&D)投入的某种度量,A(t) 是效率或创意的某种度量,β 表示新创意是否存在递增或递减的回报,λ 则刻画了投入的规模报酬。在他们关于研究生产率的广泛研究中,Bloom 等人(2020)使用比率 r = λ/β 来定义“研发回报”这一概念。该比率对公式(1)的渐近行为具有重要影响。如果我们假设研发可以被完全自动化,并且我们假设有固定计算资源存量 c,那么研发的投入就简单地为 I(t) = cA(t)。我们可以将这个表达式代入公式(1),得到:
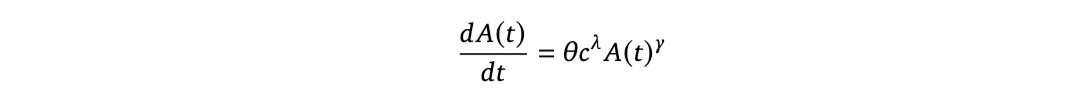
其中 γ = λ - β + 1。我们看到,在该模型下,当 γ > 1 时,即等价于 r = λ/β > 1 时,将出现双曲式增长。由于我们假设了固定的计算资源存量,Davidson(2023)将这种情形下的双曲式增长称为“纯软件奇点”(software-only singularity)。需要注意的是,该模型在两个关键方面过于简化。首先,正如 Erdil 等人(2024)所指出的,该模型假设人工智能系统的效率完全由认知劳动驱动,而实际上实验(可能涉及大规模计算使用)也将在其中发挥重要作用。这一假设可能导致对增长的估计过于乐观。其次,在实践中,计算资源也很可能持续增长(而非保持固定),因此该增长模型相对于这一假设而言是保守的。尽管认识到该模型的这些局限性,仍有必要从相关领域的实证数据中估算 r 的值。为此,Erdil 等人(2024)在多个场景下估算了 r 的值。在计算机国际象棋领域(数据最易获取),作者估计 r = 0.83(标准误差为 0.15)。在其他数据更难获取的领域(如计算机视觉、SAT 求解器、线性规划和强化学习),r 的中位数估计值超过 1,但并未达到统计显著性水平。总结其发现,Erdil 等人(2024)指出,软件研发的回报率可能足以产生软件领域的双曲式增长,但证据尚不充分。因此,我们认为,软件研发的回报率可能足以支持双曲式增长,这一可能性仍属合理,我们应为此做好准备。
主张3:人工智能研究人员的调查支持快速加速增长的可能性。
一系列针对大量人工智能研究人员的调查(Grace 等,2018、2022、2024)询问受访者,技术进步在实现“高级机器智能”(定义为无需辅助的机器能够比人类工人更好地、更便宜地完成所有任务)后的五年内,是否会以超过一个数量级的速度加快。自2016年以来,大多数受访者表示他们认为这种情况“相当可能”、“可能”或“大约五五开”(其余两个选项为“不太可能”和“极不可能”)。有趣的是,关于“智能爆炸”发生概率的问题的回答在时间上保持相对稳定(Grace 等,2024)。调查显示,人工智能研究人员赋予“在实现高级机器智能两年后出现爆发性增长”的中位概率为20%(Grace 等,2024)。虽然这绝非定论,但这一结果表明,人工智能研究界对快速加速增长的可能性存在支持。
总结:正如我们在第3.3节中讨论的,预测加速增长的时间线(或最终发生的可能性)充满困难。然而,考虑到上述证据,我们认为有强有力的理由支持能力发展可能出现快速加速的可能性。这样的世界很可能与当今世界运行方式大不相同。例如,它可能不仅包括工厂的全面自动化,还包括工厂建造过程的全面自动化,这一过程伴随着全球能源消耗的相应大幅增加。此外,我们认为,爆发性增长在不久的将来被触发是合理的(见第3.3节关于时间线的讨论),这对人工智能安全具有重大影响。如上所述,这一观点强调了我们需要一种随时可用的安全方法,能够对这类发展的早期迹象做出响应。
3.5 近似连续性
我们的第五个核心假设是“近似连续性假设”(approximate continuity assumption)。我们将其定义为:通用人工智能能力将随着计算资源、研发努力和数据的可用性而相对平滑且可预测地提升,特别是,这些输入的增加不会导致通用人工智能能力出现大规模的、不连续的“跳跃”。9 重要的是,由于我们承认“潜在加速改进假设”的存在,我们并未对人工智能进展在日历时间上的速率做出类似的连续性假设。
对我们人工智能安全方法的影响:近似连续性假设的一个关键含义是,它使我们能够通过迭代和实证的方式测试我们的策略,并发现那些仅在能力提升后才会暴露的错误假设或信念。因此,我们的技术安全方法无需对任意能力水平的人工智能系统都具备鲁棒性。相反,我们的方法可以聚焦于当前可预见的能力提升(如第2节所述),而无需保证对能力更强的系统也具备鲁棒性。更广泛地说,我们的方法建立在这样一种预期之上:常规的扩展不会导致人工智能能力出现重大不连续跃迁。如果我们能预判模型能力的发展时机,就可以提前建立测试和控制基础设施,以应对相关风险,例如:在人工智能的进攻性网络安全能力增强后,改进API中的滥用检测机制(第5节);或在模型具备自主权重泄露能力之前,加强沙箱防护(第6节)。
需要注意的是,近似连续性假设并不意味着我们不需要前瞻性。相反,它解释了为何依赖人工智能能力趋势的外推作为前瞻性手段是合理的,而无需为可能在任何时刻出现的任意强大能力做准备。此外,为了确保我们外推的是正确的趋势,我们必须对当前存在的各种人工智能能力有充分的理解。迭代式部署在这方面尤为有价值:即使一家人工智能公司未能察觉其模型中的某项能力,其用户的集体使用行为很可能最终会发现这一能力。
性能提升越不可预测,所需的安全裕度就越宽。虽然在发现意外情况后启动紧急应对措施是可行的,但作为一种通用策略,这既昂贵又不可持续。在极端不可预测的情况下,充分防范潜在能力提升在经济上将变得不可行。然而,我们并不需要完美的可预测性。只要能力的突增满足以下三个条件,就是可以接受的:
- 幅度不过大:模型不会在一次跃迁中从完全无能直接变为可靠地完成某项任务。尽管中等程度的跃迁可能带来一定风险,但我们关注的主要风险领域(第4节)依赖于复杂计划的执行,而这需要稳定可靠的性能。
- 频率不过高:意外可能偶尔发生,但足够罕见,因此以合理成本处理少数几次意外是可行的。
- 范围不过广:能力的突增不会全面发生,而是局限于某一狭窄能力。如果模型的性能仅在特定能力上突然飙升,那么其他能力很可能成为完成现实任务的瓶颈,从而限制了风险的范围。
自动化机器学习研发(Automated ML R&D):专家级的机器学习(ML)研发能力是一个特别显著的阈值,因为它可能实现人工智能的递归式改进,从而导致能力提升的显著加速。如果这种情况发生,很可能在时间维度上表现为一次大规模的不连续跃迁。然而,通用能力加速的机制恰恰在于人工智能进步的输入(尤其是自动化研发努力)的加速。因此,在这种情况下,近似连续性假设仍然成立。如第3.4节所述,我们很可能也需要由人工智能大幅辅助我们的安全规划与监控。这样一来,从日历时间趋势看的性能不连续性,在考虑用于分析和准备所投入的认知劳动量时,反而会显得更符合趋势。
支持证据概要:我们支持近似连续性假设的论证包含四项主张:第一项主张是:从技术进步指标中出现大幅跃迁的历史案例来看,大规模的不连续跃迁是罕见的。第二项主张是:迄今为止的实证证据表明,常规扩展通常不会导致通用能力的突然大幅跃迁,这一点在足够广泛的基准测试中可以得到验证。第三项主张是:尽管在狭窄任务上可能出现不可预测的能力提升,但这种情况相对少见,且性能几乎不会在一次扩展迭代中直接从随机水平跃升至90%以上。第四项主张是:关于未来能力可能出现不连续跃迁的具体机制设想,目前看来似乎不太可能。
3.5.1 大规模不连续跃迁的基准率与概念性论证
主张1:从外部视角看,高度优化领域中出现大规模不连续跃迁是罕见的。
如第3.1.1节所述,目前已有大量资源被用于提升通用人工智能能力,每年投入高达数十亿美元,并有数千名研究人员参与,且未来这一投入很可能继续增加。当如此巨大的努力被用于优化某个目标变量时,我们预期研究工作将分化为许多解决特定子问题的较小分支。因此,任一子问题上的重大不连续跃迁通常不会导致整体目标变量的跃迁。当这些子问题之间主要是互补关系时,若其中一个子问题被解决,其他子问题将成为整体进展的瓶颈,从而限制对整体进展的影响。当子问题之间可相互替代时,整体进展则成为多个贡献的总和。在实践中,我们预期可替代子问题的进展至少部分是不相关的。因此,总进展的方差减小,从而降低了整体进展出现大规模不连续跃迁的可能性。此外,研究人员通常会优先解决最容易的问题(“摘取低垂果实”),这使得即使在某个子问题内部,也愈发难以发现能引发大规模不连续跃迁的关键洞见。
这一论点仅依赖于“大量努力被用于优化目标变量”这一假设。因此,我们可以通过实证方式检验该论点在其他类似领域中的适用性,从而建立一个“外部视角”(outside view,Kahneman,2011)的参考类比基准率估计。Grace 等人(2021)对历史上人们在优化过程中出现极端快速进展的案例进行了搜索。该研究记录了若干事件,这些事件在至少一个目标指标上表现出相当于此前速度下超过一个世纪的进展不连续性。然而,鉴于他们进行了广泛的案例搜索,Grace(2020)得出结论:人工智能进展出现不连续性的基准概率相对较低,并进一步指出,认为人工智能在本质上与其他技术截然不同的论点并不令人信服(尽管并非完全站不住脚)。
根本性技术变革的影响: 如果发生足够大的范式转变(Kuhn,1962),这种外部视角可能不再适用,因为范式转变可能创造出全新的子问题集合和质变性的进展速率。这将对近似连续性假设构成挑战,但如第3.1节所述,若真发生此类情况,我们无论如何都需要从根本上重新考虑我们的方法。
此外,也可能出现彻底不同的模型训练技术,但仍属于当前范式之内。对于此类变化,我们应保持开放态度,接受其可能带来截然不同的性能和扩展行为。尽管新技术很可能遵循其自身的缩放定律(例如,Transformer 与 LSTM 相比,Kaplan 等,2020),但它可能相对于当前基线表现为一次不连续的性能提升。尽管如此,基于上述论点,我们认为这种情况不太可能发生,尽管我们并不完全排除其可能性。
搜索空间的特征: Yudkowsky(2013)提出,智能人工智能设计的搜索空间中存在许多可能导致认知投资回报复合增长的因素,最终导致在日历时间上功能上等同于一次大规模不连续跃迁的加速。Yudkowsky(2008)特别指出了五个因素:级联(cascades)、循环(cycles)、洞见(insight)、递归(recursion)和未知的未知(unknown unknowns)。重要的是,我们同意由循环和递归产生的正反馈循环确实可能导致时间维度上的急剧加速(见第3.4节)。我们预期这五个因素都将在整体能力进展中发挥重要作用,但由于上述原因,它们不会导致相对于输入(如计算、数据、研发努力)的不连续跃迁。
3.5.2 来自现有AI进展的实证证据
主张2:通用能力通常不会出现大规模、突然的跃迁。
在多个任务上人工智能能力的突然跃迁,比平滑提升带来更难应对的风险。这类跃迁可以通过涵盖多种行为的广泛基准测试,或通过综合多个基准的得分来衡量,这是标准做法。Owen(2024)发现,在外推一个数量级(OOM)的计算量时,综合基准测试(如BIG-Bench(Srivastava 等,2023)、MMLU(Hendrycks 等,2020))的预测误差最多为20个百分点。Gadre 等人(2024)同样发现,综合任务性能可以相对准确地预测,仅使用被预测模型计算量的1/20,即可将17个任务的平均top-1错误率预测误差控制在1个百分点以内。Ruan 等人(2024)发现,跨多个模型家族的8个标准下游大语言模型(LLM)基准得分可以通过其前三个主成分很好地解释。其中第一个主成分在跨越5个数量级的计算量和多个模型家族时平滑变化,表明类似“通用能力”的指标随计算量平滑提升。
主张3:尽管在特定任务上的性能跃迁已被观察到,但剧烈的跃迁极为罕见,且更可能是测量误差所致。
文献中有许多例子表明,随着规模扩大,某些任务的性能起初变化不大,随后突然显著提升,这种现象被称为“涌现”(emergence)¹⁰。Wei 等人(2022a)将大语言模型的涌现能力定义为:在小规模模型中不存在,但在大规模模型中存在的能力;因此,无法通过简单外推小规模模型的性能提升来预测。这种现象既出现在自然任务中(Srivastava 等,2023),也出现在为异常缩放趋势而刻意选择的对抗性任务中(McKenzie 等,2023)。即使整体基准性能大致可预测,单个任务的性能往往不可预测(Owen,2024)。
剧烈提升极为罕见。然而,即使在单个任务上,出现剧烈性能提升的“涌现”也极为少见。在大多数报告出现“涌现”的任务中,性能跃迁不超过50个百分点。涌现通常不会导致模型从随机准确率直接跃升至90%以上,而后者才是最令人担忧的风险可能突然出现的前提。在查阅“涌现”相关文献后,我们仅发现少数达到此幅度的剧烈提升案例。一个例子是GPT-3在MAWPS(一个数学文字题数据集)上的表现(Wei 等,2022b;Koncel-Kedziorski 等,2016),这发生在训练计算量增加超过一个数量级时。另一个例子是GPT-4在“事后忽视”(Hindsight Neglect)任务上的表现,该任务来自“逆向缩放奖”(Inverse Scaling Prize,McKenzie 等,2023),是刻意设计来对抗大语言模型的(Achiam 等,2023)。GPT-3.5和GPT-4的总训练计算量未知,但根据Epoch AI(2024)的估计,GPT-4在“事后忽视”任务上的性能提升对应训练计算量增加了约一个数量级。
Ruan 等人(2024)指出,研究缩放定律和涌现能力(如Wei 等人(2022a)的研究)的一个复杂因素是数据点稀疏。特别是,当仅用5个数据点覆盖多个数量级的规模时,即使底层现象是平滑的,也可能呈现出不连续的表象。Ruan 等人(2024)重新审视了Wei 等人(2022a)的结果,证明先前被认定为“涌现”的能力实际上可以通过他们的方法准确预测。同样,上述两个剧烈提升的例子都涉及训练计算量增加一个数量级。在实践中,新模型相对于现有模型在训练计算量上如此大幅增加的情况虽不常见,但并非没有(Epoch AI,2024)。
涌现作为测量误差。近期研究(Schaeffer 等,2023,2024)指出,迄今为止观察到的大多数剧烈“涌现”实例,主要可归因于性能度量指标和转换方式的测量误差。Schaeffer 等人(2023)发现,BIG-Bench任务中大多数可能的“涌现”实例(模型/任务对)使用了多项选择题和精确匹配准确率作为度量指标。这两种指标相对于生成正确标记的底层概率都是非线性的,因此在x轴上进行粗粒度划分时,趋势会显得不连续。若改用线性指标(分别为Brier分数或编辑距离),即使在单个任务上,也能得到更平滑、更可预测的缩放趋势。Schaeffer 等人(2024)识别出另一个因素:在多项选择题设置中,准确性受模型在错误答案上如何分配概率质量的影响,这会削弱预训练损失与下游性能指标之间的相关性。
提高可预测性的一种策略是通过增加评估集规模并从模型中抽取更多样本来提高评估分数的分辨率(Schaeffer 等,2023;Hu 等,2023)。在大量样本下,现代大语言模型在复杂任务上通常表现出令人印象深刻的记忆能力(recall,即至少生成一个正确样本的能力)(Brown 等,2024)。另一种选择是仅考虑所有被评估模型至少能通过一次的任务实例(Achiam 等,2023),但这会将我们能预测的任务类别限制在当前通过率为非零的任务上。我们认为,更完善的测量科学将有助于使任务性能更可预测,但更好的指标尚不能完全解决问题。许多任务(例如代码生成的通过率)存在类似挑战,且没有直接的替代测量方法。
即使现有的“涌现”案例可以通过替代性指标进行预测,这也不一定支持近似连续性假设。对于“通用人工智能能力”,我们最终关心的往往是非线性指标,而非其线性版本,而目前尚不清楚能否从一个指标准确预测另一个。识别新能力的最佳策略之一是部署模型,观察其在实际中的使用情况,而这取决于模型的实用性,而实用性又与非线性指标密切相关。因此,过度关注线性指标可能是一种“后见之明偏差”(hindsight bias),即我们只是在观察到非线性指标上的涌现现象后,才识别出相应的线性指标。
注意:提示方法(elicitation)的影响。许多关于涌现的学术研究在实验中保持提示结构(scaffold)不变,仅改变模型规模,以孤立地研究扩展效应。虽然这在综合基准性能上通常表现出连续性(Suzgun 等,2022),但如果同时引入提示结构的改进或其他训练后优化方法,可能会表现出更大的跃迁。更广泛地说,许多训练后方法能以相对较低的计算成本显著提升模型能力(Davidson 等,2023)。在实验室内部,部署新的提示方法是一种主动选择。然而,如果一种新的提示技术在实验室之外被发现,且仅需通过API访问即可显著提升已部署模型的能力,那么这可能带来潜在的不稳定性:用户将突然且广泛地获得未经安全测试的新能力。
3.5.3 关于未来不连续性的概念性论证
主张4:关于不连续性如何产生的具体设想似乎不太可能。
即使不连续跃迁的基准率较低,且迄今为止人工智能能力的实证证据也支持这一结论,仍有可能存在某种未来人工智能能力的特殊性——这种特殊性目前尚不存在,也不适用于我们用于基准率分析的参考类比——从而导致大规模不连续跃迁的可能性高于我们原本的预期。Grace(2020)和Christiano(2018)综述了多种此类论点,但最终认为这些论点都较为薄弱。
阈值效应(Threshold effects)。我们认为最有说服力的论点是关于未来人工智能能力可能引发的阈值效应。例如,可能存在某种推理连贯性的临界水平,一旦达到,就会“一次性”解锁质变性的新能力。这类阈值并不罕见:例如,某些提示结构或引导技术(如“思维链”Chain of Thought, CoT)只有在模型规模超过某一阈值后才开始显现性能提升(Wei 等,2022a;Suzgun 等,2022)。然而值得注意的是,该阈值仅代表CoT开始超越基线引导方法的转折点;从整体上看,CoT的综合性能仍随规模平滑提升。鉴于阈值效应在其他领域也确实存在,但不连续进展仍然罕见,我们预期跨越此类阈值的影响可能微乎其微。
总结:综观文献,我们发现已有不少先前研究报道了特定任务行为上的显著跃迁。此外,在缺乏能够排除不连续性能提升的理论依据时,对未来能力的预测应保持谨慎。然而,极大幅度的性能跃迁似乎极为罕见,尤其是在计算规模逐步扩展、测量间隔较近的情况下。我们还观察到,通用能力通常不会出现大规模、突然的跃迁。综合来看,我们认为支持“近似连续性假设”的证据相对充分且稳健。
3.6. 通用人工智能(AGI)的益处
本文档的主要重点是提出一种方法,以减轻与通用人工智能(AGI)相关的重大危害风险。我们这样做的核心动机在于,我们相信AGI所带来的巨大益处超过这些风险,前提是采取适当的预防措施。在本节中,我们将重点介绍我们认为AGI将带来的几项重要益处。这些益处包括:提高全球生活水平(第3.6.1节)、深化人类知识(第3.6.2节)以及降低创新门槛(第3.6.3节)。
对我们AI安全方法的影响。如果安全是唯一追求的目标,那么实现安全是很容易的。例如,如果我们根本不建造AGI,那么AGI带来的危害就不会发生。然而,这本身也会带来问题,因为它意味着放弃AGI所能带来的巨大益处。我们的方法旨在实现安全的同时,不至于过度牺牲AGI的潜在好处。例如,许多危险能力具有双重用途,既可能通过滥用造成危害,也可能带来益处。我们的方法力求区分这两种情况,仅阻止滥用情形,从而确保益处仍可实现。
3.6.1 AGI有望提高全球生活水平
如果AGI能够被安全、广泛且低成本地部署,它有潜力显著提高全球的生活水平。我们指出两种特别可能实现这一目标的方式:第一,通过推动更快速、更具成本效益的创新,促进经济增长与繁荣;历史上,创新带来了显著的社会回报,而经济增长与教育、健康和总体福祉等多个领域的积极结果密切相关——我们预计这种相关性将持续下去。第二,AGI可以通过改善教育和医疗成果,更直接地提高全球各地的生活水平。
支持性论点概要。为了支持我们的主张,我们首先简要总结研究表明创新具有显著的社会回报;接着描述AGI如何通过加速创新带来显著的经济增长,并概述增长如何与积极的社会成果相关联;然后我们总结证据表明当前全球教育现状存在巨大的改进空间,而AGI可以为此做出贡献;最后,我们概述AGI在医疗领域的益处,例如通过药物研发等途径。
支持性论点与证据。要精确估算创新和研发的社会回报是困难的,因为这项任务必须面对诸如衡量研发密集型产业产出等复杂问题(Griliches, 1979;Hall, 1996)。尽管如此,迄今为止的分析表明,创新和研发带来了非常可观的社会回报。Jones和Summers(2020)指出,即使在保守假设下,每投入1美元所获得的平均社会回报至少为4美元。此外,如果考虑到国际外溢效应、健康收益以及通货膨胀偏差(即高估通胀从而低估实际GDP增长),这一回报可能上升到每投入1美元带来超过20美元的回报。通过增强我们在所有领域的问题解决和发现能力,从而提高知识生产的效率,AGI可以极大地提升投资的社会回报率。尽管Russell(2022)的研究主要关注该技术的风险,但他也提出,即使不考虑未来人工智能更雄心勃勃的应用(例如延长人类寿命),也完全可以设想一种情景:AGI将地球上所有人的生活水平提升至现代发达国家中被认为体面的水平(定义为第88百分位)。这相当于全球GDP增长十倍(类似于1820年至2010年间全球实现的增长),其经济价值约为1350万亿美元(按5%的贴现率计算)。
作为一种“技术的技术”,我们可以从两个不同层面分析AGI的预期影响。首先,从宏观层面看,我们可以考虑那些对整个人类发展关键领域产生大规模积极影响的广泛应用案例和用途。其次,我们可以考察特定算法或应用如何帮助解决具体挑战。接下来我们将讨论这些方面。
对经济增长和生产力的宏观影响。我们认为AGI有望推动经济增长。这一点非常重要,因为经济增长与健康结果、教育水平和总体福祉等多项重要指标呈正相关。事实上,经济增长似乎是当今人类福祉的重要驱动力。例如,人均GDP与人类发展指数(Sušnik 和 van der Zaag, 2017)高度相关。人均GDP还与预期寿命(Dattani 等, 2023)、自我报告的生活满意度(Our World In Data, 2023a)以及识字率(Our World In Data, 2023b)等因素相关。增强经济增长的潜力是推动AGI发展的重要动机,也是改善社会影响和人类福祉的一个可能因果路径。
对关键领域的微观影响:从医疗到教育。我们也可以探讨AGI如何在更具体的领域或应用场景中带来益处,以及这些益处如何反过来提升各种社会指标和经济增长。这一点对全球南方尤其重要:在低收入和中等收入国家,许多推动农业生产力提升、教育发展和技能提升的因素仍是持续转型和增长的关键(Tadepalli, 2023)。这些因素包括减少劳动力需求的技术、扩大高等教育获取机会以及其他重要因素。我们认为AGI可以在降低这些发展驱动力的门槛方面发挥重要作用,尤其聚焦于教育和医疗领域。
教育。目前世界上很大一部分青少年缺乏有效参与现代全球经济所需的基本技能。例如,在新冠疫情爆发之前,据估计,低收入和中等收入国家中约有57%的十岁儿童无法阅读一段面向更年幼儿童的简单文本(世界银行,2022)。如果全球所有儿童都能达到至少基本技能水平(相当于PISA一级熟练程度),到2100年,全球GDP将比维持现状的情景高出56%。在整个本世纪余下的时间里,这一改善预计将带来额外732万亿美元的GDP增长(Gust 等, 2024)。
3.6.2 深化人类知识并加速科学发现
最近的发现和突破已经展示了人工智能模型在掌握复杂科学概念和思想方面的潜力(Romera-Paredes 等, 2024),并实现了新颖的科学发现以及前所未有的数学问题求解能力(AlphaProof 和 AlphaGeometry 团队, 2024)。更广泛地看,未来我们预期人工智能将越来越多地参与并加速科学发现过程(Griffin 等, 2024)。
支持性论点概要。为支持我们的主张,我们首先阐述AGI如何作为科学发现的“力量倍增器”。特别是,通过提供大量认知劳动力,AGI能够将问题解决能力应用于广泛的问题。其次,我们总结了AGI可能通过若干机制加速科学发现过程,包括从大规模数据集中生成洞见,以及自动执行实验。
支持性论点与证据。
AGI作为力量倍增器。通过极大地扩展我们的认知能力,AGI可能从根本上改变科研的约束条件。原则上,可以同时部署多个AGI系统的副本,用于解决具有重大后续影响的重要问题:例如,在能源领域的新发现,可能显著影响能源价格和环境健康。这种潜力解释了为何人们对开发“AI科学家”代理的兴趣日益增长。例如,“诺贝尔图灵挑战”(Nobel Turing Challenge)的目标是“开发一个高度自主的人工智能系统,能够执行顶级科学研究,其质量与最优秀的人类科学家所进行的研究无法区分,其中一些发现甚至可能达到诺贝尔奖级别或更高水平”(Kitano, 2021)。
加速科学研究。这种转变的影响可能远不止线性提升。相反,AGI具备跨不同领域综合洞见、快速探索庞大解空间以及攻克以往难以解决的问题的能力,这表明其对创新和进步具有乘数效应。这种能力的扩展可能不符合传统经济学中的收益递减规律;相反,它开辟了全新的可能性前沿,此时进步的限制因素将越来越取决于我们构想和引导这些扩展后的认知资源的能力,而非资源本身。更具体地说,Mitchell(2024)提出了科学可能被加速的四种具体机制。第一,AI能够分析来自多个实验和实验室的海量复杂数据集,从而获得比传统“单打独斗”方式更全面、更准确的洞见,揭示出超越人类感知能力的模式和关联。第二,多模态模型能够消化并综合整个领域的科学文献,帮助研究人员提出比以往更加有依据且背景更丰富的假设。正如Wang等人(2023b)所指出的,当前最大的科学挑战之一是“假设空间过于庞大,使得系统性探索变得不可行”。第三,基础模型可以作为领域知识的可执行知识库,这些模型在来自不同实验室的多样化实验数据上进行训练。这些模型类似于传统科学方程,但复杂程度远超后者,能够捕捉数十万个变量之间的复杂关系,为科学家提供强大的预测工具。第四,也是最后一点,AI可以通过机器人技术实现实验设计与执行的自动化或半自动化,显著加快科学发现的速度,同时提高研究的可重复性。
一个具体的早期实例(仅使用当前技术即可实现)是:Merchant等人(2023)利用深度学习和图神经网络,发现了220万种新晶体,其中包括38万种稳定材料,有效地将人类已知的具有技术可行性的材料数量成倍增加。这一突破印证了上述论点,即快速探索庞大解空间的能力,以及跨不同领域综合洞见的能力,充分体现了对创新和进步的乘数效应。
3.6.3 增强信息处理能力并降低创新门槛
AGI有望以前所未有的规模实现增强型信息处理能力和知识获取的普及化,使其惠及全球广大人群。通过这种方式,AGI可以显著降低创新和创造的门槛。
支持性论点概要。为支持我们的主张,我们首先描述AGI如何通过使先进工具和知识的获取民主化来实现普及。随后,我们阐述AGI如何通过提供解决复杂问题的新方法(例如与涌现现象和预测相关的挑战)来降低创新的障碍。
支持性论点与证据。
先进工具与知识获取的普及化。AGI可以通过使高级问题解决能力广泛可及,从而降低创新的门槛。这将使个人和小型组织能够应对以往只有大型、资金充足的机构才能解决的复杂挑战。应用程序、API、工具和智能代理也将更加普及,随着时间推移,相关产品和用户界面也可能同步改进。这些发展表明,AI和AGI的能力将逐步实现更广泛的获取。尽管这种普及可能并非无条件的(例如受限于成本或安全措施),但其覆盖范围之广、影响之深,足以代表知识的分发、获取、理解与利用方式的一次重要转变。特别是AI助手,预计将承担多种角色,帮助增强和改善人类的决策能力。通过帮助用户理解复杂的理论和概念,或更好地梳理相互矛盾的信息,这些助手可以有效地充当信息整合的“认知假肢”。这种知识和高级推理能力的普及化,可能促进公民科学的蓬勃发展,并推动科学进步更加公平地分布。
新兴的问题解决范式与工具。新的AI和AGI系统还将帮助创造新的工具,以更好地测试和理解世界。这不仅适用于数学或STEM(科学、技术、工程和数学)领域,也适用于社会科学。一个令人兴奋的新兴研究方向是利用多智能体系统研究涌现的社会现象——即个体智能体之间互动时自发产生的复杂行为,尽管这些行为从未被明确编程。这为科学研究开辟了全新的途径,使研究人员以前所未有的方式探索社会系统的动态。
例如,考虑对市场涌现行为建模的挑战。传统上,此类研究依赖历史分析、静态建模和博弈论,而这些方法在捕捉动态、不断演变的人类互动方面存在局限,而正是这些互动塑造了社会规范和制度的演进。然而,借助诸如Concordia(Vezhnevets 等, 2023)等新工具,研究人员可以在一个模拟世界中部署具备基本社会动态理解能力的智能体——这些理解来自它们所训练的海量文本数据集——并观察这些互动随时间推演的结果。通过在不同参数下反复运行模拟,研究人员可以获得关于社会现象机制的洞见,识别出促进理想结果的关键因素。这种方法也可用于建模各种各样的涌现现象,从错误信息的传播、金融市场的动态,到政策干预的有效性以及合作行为的演化。
此外,利用AI增强人类在预测任务中的判断力也具有巨大潜力。即使是相对简单的干预——为用户提供一个大语言模型(LLM)助手——也能显著提高预测准确性(Schoenegger 等, 2024)。通过促使用户阐明其推理过程、考虑不同观点并校准其判断,AI助手可以帮助优化和提升人类思维,即使AI本身的知识或理解并不完美。尽管目前在一定程度上已经如此,但我们预期AGI级别系统的益处将显著更高。事实上,随着AI系统日益复杂,具备生成假设、评估证据和进行细致讨论的能力,人类与AGI之间的协作潜力将大幅增强。
讨论。对AGI的追求基于其重要的潜在益处——这些益处推动着一个日益壮大的研究领域。如上所述,大规模部署智能的能力将使社会能够将新的资源投入到诸多对人类福祉至关重要的领域和问题中。这些领域包括提高生活水平、深化人类知识,以及降低创新和创造的门槛。事实上,高度智能的AI可能增强人类的自主性和选择权——限制越少,选择的分量就越重。因此,我们认为,任何放弃这些益处的决策都必须基于充分的证据并经过审慎考量。具体而言,在本文后续章节所讨论的安全与保障机制可能限制这些益处的情况下,进行细致的成本效益分析是必要且合理的。
- 风险领域
在应对安全与安保问题时,识别出可能导致伤害的广泛路径类别是很有帮助的,因为这些类别可以通过类似的缓解策略加以应对。由于我们的重点在于识别相似的缓解策略,因此我们根据抽象的结构特征(例如,是否有某个行为者具有恶意意图)来定义这些风险领域,而不是根据具体的危险领域(如网络攻击或人类失去控制)进行划分。这意味着这些风险领域适用于一般意义上的人工智能带来的危害,而不仅限于严重危害或仅针对通用人工智能(AGI)。
如图4所示,我们考虑四个风险领域:滥用(misuse)、目标不一致(misalignment)、错误(mistakes)和结构性风险(structural risks)。需要注意的是,这并不是一个严格的分类体系,因为这些领域既不是相互排斥的,也不是穷尽所有可能性的。在现实中,许多具体的风险场景往往是多个领域的混合体。例如,一个目标不一致的AI系统可能会寻求恶意行为者的帮助,以窃取自身的模型权重,这种情况就同时涉及滥用和目标不一致两个领域。我们预期,即便如此,针对每个构成部分的风险领域分别采取相应的缓解措施仍然是有效的做法,尽管未来的研究应进一步探索针对多个领域组合情形的特定缓解措施。
4.1. Misuse risks
原文链接:https://www.researchgate.net/publication/390440085_An_Approach_to_Technical_AGI_Safety_and_Security
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号