大型推理模型的强化学习综述(1-4章)

大型推理模型的强化学习综述(1-4章)

CreateAMind
发布于 2026-03-11 17:45:55
发布于 2026-03-11 17:45:55
A Survey of Reinforcement Learning for Large Reasoning Models
大型推理模型的强化学习综述
https://arxiv.org/pdf/2509.08827



摘要
本文综述了近年来强化学习(RL)在大语言模型(LLMs)推理能力方面的最新进展。RL 在推动 LLM 能力前沿方面取得了显著成功,尤其在解决复杂数理逻辑任务(如数学和编程)方面表现突出。因此,RL 已成为将 LLM 转化为推理大模型(LRMs)的基础方法。随着该领域的快速发展,进一步扩展 RL 以应用于 LRMs 现在不仅面临计算资源方面的基础性挑战,也面临算法设计、训练数据和基础设施等方面的挑战。在此背景下,及时回顾该领域的发展历程、重新评估其演进路径,并探索提升 RL 可扩展性以迈向人工超级智能(ASI)的策略显得尤为必要。本文特别考察了自 DeepSeek-R1 发布以来,将 RL 应用于 LLM 和 LRM 以增强其推理能力的相关研究,涵盖基础组件、核心问题、训练资源及下游应用,旨在识别这一快速演进领域未来的机遇与发展方向。我们希望本综述能促进未来关于 RL 在更广泛推理模型中应用的研究。
- 引言 强化学习(RL)[Sutton 等,1998] 已多次证明,即使仅提供狭窄、明确指定的奖励信号,也能驱动人工智能体在复杂任务上达到超越人类的水平。标志性系统如 AlphaGo [Silver 等,2016] 和 AlphaZero [Silver 等,2017] 仅通过自我对弈和奖励反馈进行学习,便在围棋、国际象棋、将棋和 Stratego [Perolat 等,2022;Schrittwieser 等,2020;Silver 等,2018] 等项目中击败了世界冠军,从而确立了 RL 作为高层次问题求解的一项实用且极具前景的技术。在大语言模型(LLMs)时代 [Zhao 等,2023a],RL 最初作为人类对齐的后训练策略而崭露头角 [Ouyang 等,2022]。广泛采用的方法如基于人类反馈的强化学习(RLHF)[Christiano 等,2017] 和直接偏好优化(DPO)[Rafailov 等,2023] 对预训练模型进行微调,使其遵循指令并反映人类偏好,显著提升了模型的有用性、诚实性和无害性(3H)[Bai 等,2022b]。
最近,一种新趋势正在兴起:面向大推理模型(LRMs)的强化学习 [Xu 等,2025a],其目标不仅是对齐行为,更是激励推理本身。两个近期里程碑(即 OpenAI o1 [Jaech 等,2024] 和 DeepSeek-R1 [Guo 等,2025a])表明,使用可验证奖励的强化学习(RLVR)——如数学题的答案正确性或编程题的单元测试通过率——训练 LLM,可使模型具备长程推理能力,包括规划、反思和自我修正。OpenAI 报告 [Jaech 等,2024] 指出,o1 的性能随着额外 RL 训练(增加训练时计算量)和推理时“思考”时间(测试时计算量)[Brown 等,2024;Liu 等,2025m;Snell 等,2024] 的增加而平稳提升,揭示了一条超越单纯预训练的新扩展维度 [Aghajanyan 等,2023;Kaplan 等,2020]。DeepSeek-R1 [Guo 等,2025a] 为数学任务采用显式的、基于规则的准确性奖励,为编程任务则采用编译器或测试驱动的奖励。该方法表明,大规模强化学习——特别是组相对策略优化(GRPO)——即使在后续对齐阶段之前,也能在基础模型中诱导出复杂的推理行为。
这一转变将“推理”重新定义为一种可被显式训练并可扩展的能力 [OpenAI, 2025a,b]:LRMs 在测试时分配大量计算资源用于生成、评估和修订中间思维链 [Wei 等,2022],其性能随计算预算的增加而提升。这一动态机制为能力提升开辟了一条与预训练期间的数据和参数扩展正交的补充路径 [Aghajanyan 等,2023;Kaplan 等,2020],同时利用奖励最大化目标 [Silver 等,2021],并在存在可靠验证器的场景下(如竞赛数学 [Guo 等,2025a;Jaech 等,2024]、竞赛编程 [El-Kishky 等,2025] 及部分科学领域 [Bai 等,2025])自动应用可验证奖励。此外,RL 还能通过自我生成训练数据 [Silver 等,2018;Zhao 等,2025a] 克服数据限制 [Shumailov 等,2024;Villalobos 等,2022]。因此,RL 越来越被视为通过持续扩展在更广泛任务上实现人工超级智能(ASI)的一项有前景的技术。
与此同时,进一步扩展面向 LRMs 的 RL 也带来了新的约束,不仅体现在计算资源方面,也涉及算法设计、训练数据和基础设施。RL 在 LRMs 中应如何以及在何处扩展以实现高级智能并创造现实世界价值,仍是悬而未决的问题。因此,我们认为现在正是回顾该领域发展历程、探索提升 RL 可扩展性以迈向人工超级智能之策略的恰当时机。综上,本综述从以下几个方面回顾了近期关于 LRMs 强化学习的研究:
- 我们介绍了在 LRM 背景下 RL 建模的初步定义(§2.1),并概述了自 OpenAI o1 发布以来前沿推理模型的发展(§2.2)。
- 我们回顾了近期关于 LRM 强化学习基础组件的文献,包括奖励设计(§3.1)、策略优化(§3.2)和采样策略(§3.3),比较了各组件的不同研究方向与技术路径。
- 我们讨论了 LRM 强化学习中基础性且仍具争议的问题(§4),如 RL 的作用(§4.1)、RL 与监督微调(SFT)的对比(§4.2)、模型先验(§4.3)、训练方案(§4.4)及奖励定义(§4.5)。我们认为这些问题亟需进一步探索,以支持 RL 的持续扩展。
- 我们考察了 RL 的训练资源(§5),包括静态语料库(§5.1)、动态环境(§5.2)和训练基础设施(§5.3)。尽管这些资源在研究和生产中均可复用,但仍需进一步标准化与开发。
- 我们回顾了 RL 在广泛任务中的应用(§6),如编程任务(§6.1)、智能体任务(§6.2)、多模态任务(§6.3)、多智能体系统(§6.4)、机器人任务(§6.5)及医疗应用(§6.6)。
- 最后,我们讨论了语言模型强化学习的未来方向(§7),涵盖新算法、新机制、新特性及其他研究路径。
- 基础知识
2.1. 背景
在本小节中,我们介绍强化学习(RL)的基本组成部分,并描述语言模型如何被配置为 RL 框架中的智能体。如图 3 所示,强化学习为序列决策提供了一个通用框架,其中智能体通过采取行动与环境交互,以最大化累积奖励。在经典的强化学习中,问题通常被形式化为一个马尔可夫决策过程(MDP)[Sutton 等,1998],其由一个元组 (S, A, P, R, γ) 定义。主要组件包括状态空间 S、动作空间 A、转移动态 P: S × A → S、奖励函数 R: S × A → ℝ,以及折扣因子 γ ∈ [0,1]。在每一步中,智能体观察到一个状态 st,根据由参数 θ 表征的策略 πθ 选择一个动作 at,获得一个奖励 rt,并转换到下一个状态 st+1。当将强化学习应用于语言模型时,这些概念可以经过最小程度的调整自然映射到语言领域。该映射总结如下:
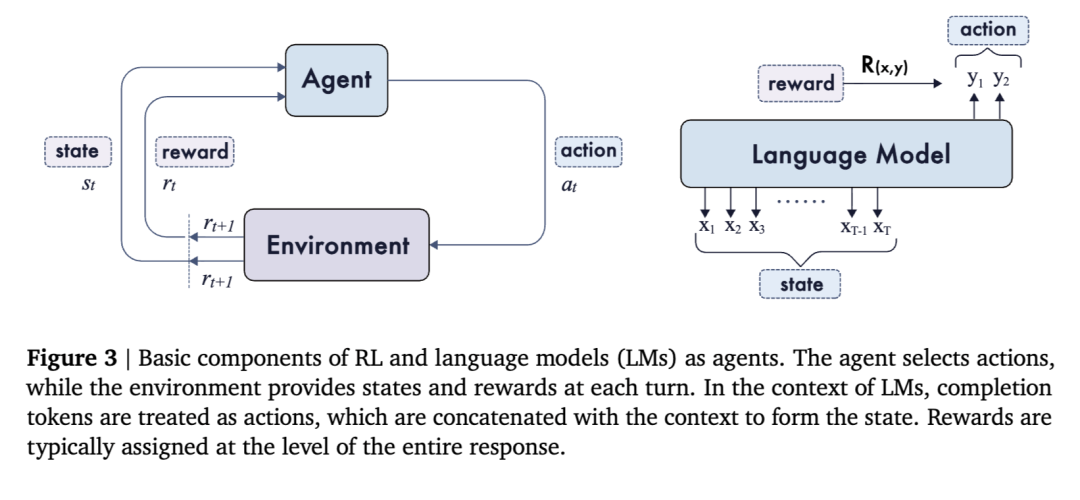

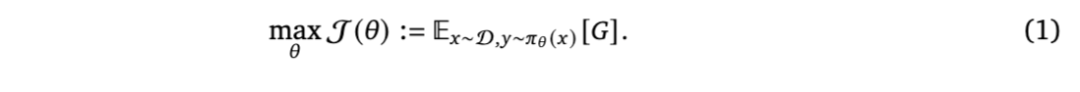
在实践中,通常会对学习到的策略进行正则化,使其趋向于一个参考策略 𝜋ref,通常通过 KL 散度约束实现,以稳定训练并保持语言质量。在接下来的章节中,我们将介绍多种建立在这一基础公式之上的算法。
2.2 前沿模型
在本小节中,我们概述了当前最先进的、采用类强化学习方法训练的大规模推理模型,大致按时间顺序沿三个主要方向组织:LRMs(大推理模型)、智能体型 LRMs 和多模态 LRMs。
在过去一年中,RL 逐步拓展了推理模型及其应用的前沿边界。首批大规模推理模型——OpenAI 的 o1 系列 [Jaech 等,2024]——确立了在训练时扩展 RL 与在推理时增加计算资源对提升推理能力的有效性,在数学、编程和科学基准测试中取得了领先成果。DeepSeek 的旗舰模型 R1 [Guo 等,2025a] 紧随其后,成为首个在各项基准上性能媲美 o1 的开源模型。它采用多阶段训练流程,确保模型能力全面均衡,并探索了无需监督微调的纯 RL 路径(即“零 RL”)。
随后,其他闭源模型迅速跟进:Claude-3.7-Sonnet [Anthropic, 2025a] 引入了混合推理能力;Gemini 2.0 和 2.5 [Comanici 等,2025] 延长了上下文长度;Seed-Thinking 1.5 [Seed 等,2025b] 强调跨领域泛化能力;o3 系列 [OpenAI, 2025b] 则展现出日益增强的推理能力。近期,OpenAI 推出了其首个开源推理模型 gpt-oss-120b [Agarwal 等,2025a],随后发布了迄今为止最强大的 AI 系统 GPT-5 [OpenAI, 2025a],该系统可在高效模型与深度推理模型 GPT-5 thinking 之间灵活切换。与此同时,开源社区持续拓展这一领域:在 Qwen 家族中,QwQ-32B [Team, 2025g] 性能与 R1 相当,随后推出的 Qwen3 系列 [Yang 等,2025a] 中,代表性模型 Qwen3-235B 进一步提升了基准分数。Skywork-OR1 系列模型 [He 等,2025d] 基于 R1 蒸馏模型构建,通过有效的数据混合与算法创新实现了可扩展的 RL 训练。Minimax-M1 [Chen 等,2025a] 是首个引入混合注意力机制以高效扩展 RL 的模型。其他工作包括旨在平衡精度与效率的 Llama-Nemotron-Ultra [Bercovich 等,2025];完全从零开始通过 RL 训练(无先前模型蒸馏)的 Magistral 24B [Rastogi 等,2025];以及强调长上下文推理能力的 Seed-OSS [Team, 2025a]。
模型推理能力的提升反过来也扩展了其在编程和智能体场景中的应用。Claude 系列一直以在智能体编程任务上的领先表现著称,其最新代表 Claude-4.1-Opus [Anthropic, 2025b] 进一步刷新了 SWE-bench 基准 [Jimenez 等,2023] 的最先进成绩。Kimi K2 [Team, 2025d] 是近期专为智能体任务优化的代表性智能体模型,构建了大规模智能体训练数据合成方法,并设计了一种支持不可验证奖励的通用 RL 流程。紧随其后,GLM4.5 [Zeng 等,2025a] 和 DeepSeek-V3.1 均强调工具使用与智能体任务,在相关基准上实现了显著提升。
多模态能力是推理模型得以广泛应用的关键组成部分。大多数前沿闭源模型,包括 GPT-5、o3、Claude 和 Gemini 系列,均原生支持多模态。其中,Gemini-2.5 [Comanici 等,2025] 特别强调在文本、图像、视频和音频等多个模态上的强大性能。在开源方面,Kimi 1.5 [Team, 2025d] 是迈向多模态推理的早期尝试,突出了长上下文扩展能力以及文本与视觉领域的联合推理。QVQ [Qwen Team, 2025] 在视觉推理与分析思维方面表现卓越;Skywork R1V2 [Wang 等,2025k] 通过混合 RL(同时使用 MPO 和 GRPO)平衡推理与通用能力。作为 InternVL 系列的重要补充,InternVL3 [Zhu 等,2025c] 采用了统一的原生多模态预训练阶段,随后的 InternVL3.5 [Wang 等,2025o] 采用两阶段级联 RL 框架,提升了效率与通用性。更近期的 Intern-S1 [Bai 等,2025] 模型专注于跨领域的多模态科学推理,得益于在线 RL 中的混合奖励设计,可同时在广泛任务上进行训练。其他近期模型包括专为高效训练和最小化解码成本设计的 Step3 [Wang 等,2025a],以及在大多数视觉多模态基准上达到最先进性能的 GLM-4.5V [Team 等,2025a]。
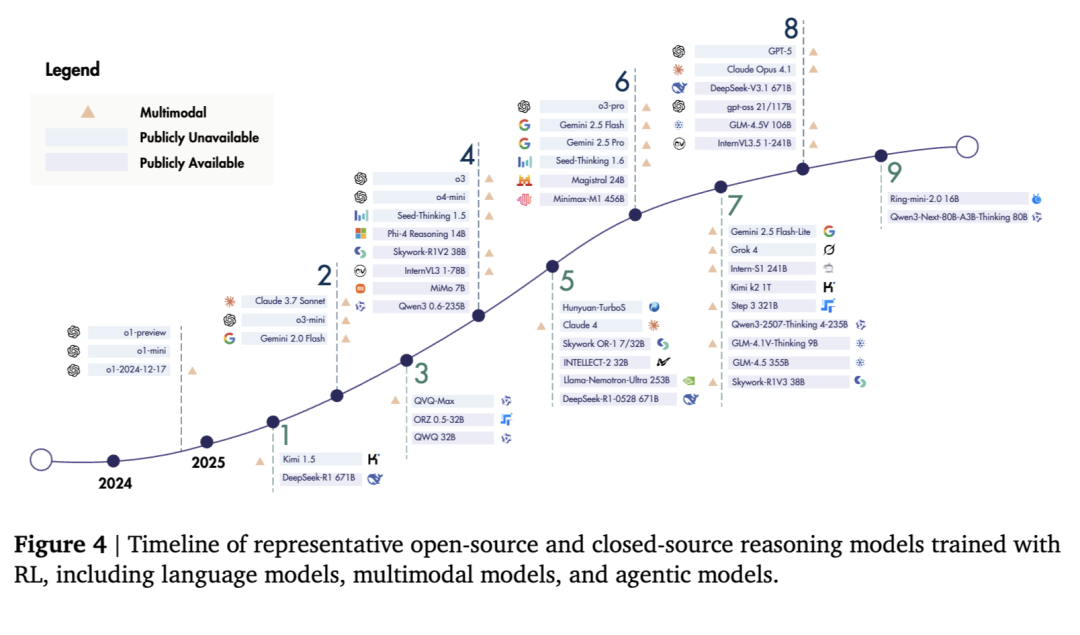
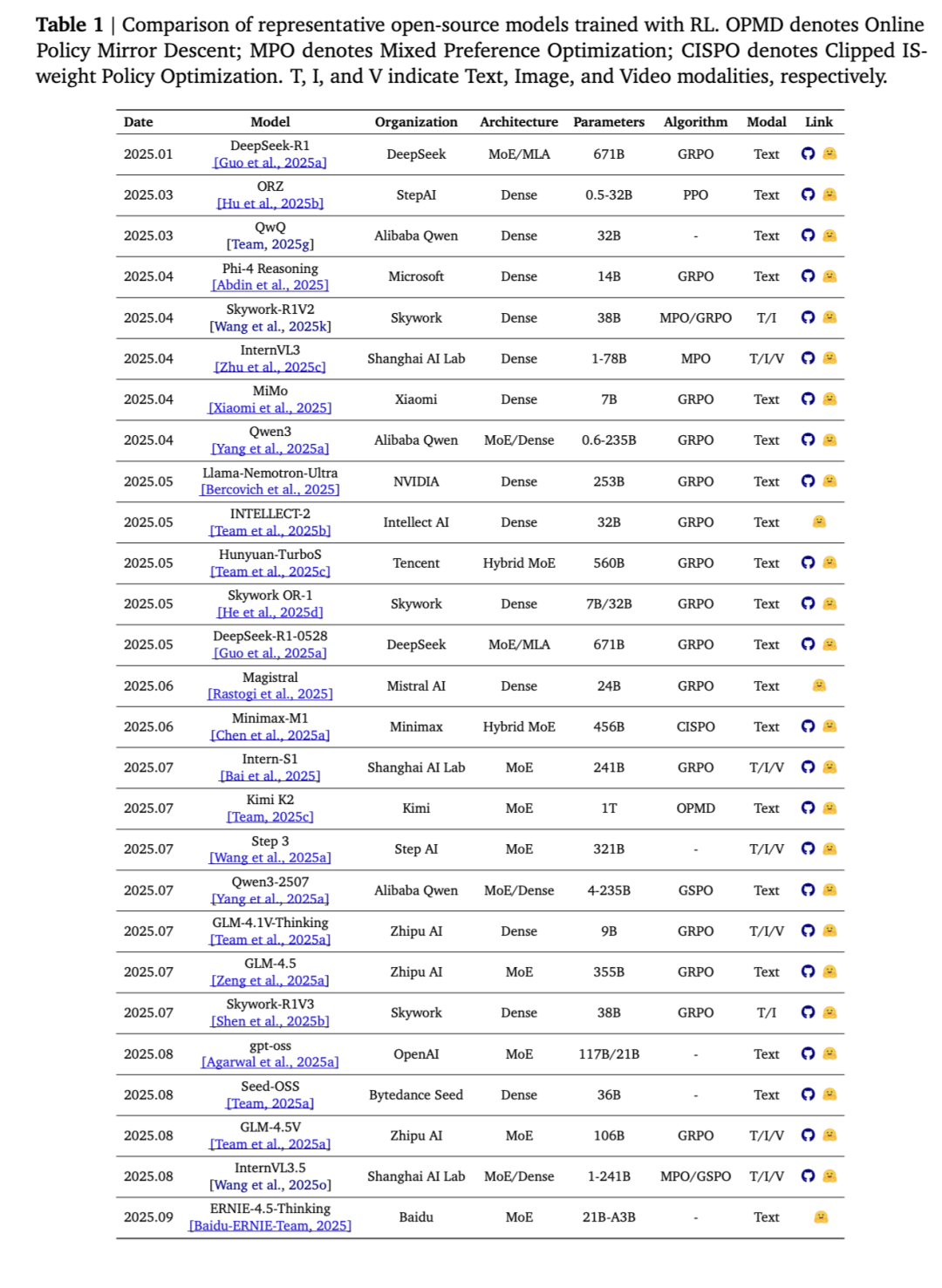
除上述模型外,我们在图 4 中提供了推理模型的完整列表,并在表 1 中详列了开源模型的具体信息。
2.3 相关综述
在本小节中,我们比较了近期与强化学习(RL)和大语言模型(LLMs)相关的综述文献。部分综述主要聚焦于 RL 本身,涵盖经典 RL 及其最新扩展。Ghasemi 等人 [2024] 提供了一项涵盖 RL 算法与现实挑战的通用综述;Huh 和 Mohapatra [2023] 聚焦于多智能体 RL;Zhang 等人 [2024b] 回顾了自我博弈技术;Wu 等人 [2025h] 综述了 RL 在计算机视觉任务中的应用。尽管这些工作为 RL 提供了广泛的视角,但并未明确探讨其在 LLMs 中的应用。
相比之下,其他综述则以 LLMs 及其新兴能力为核心,例如长程思维链推理 [Chen 等,2025m;Li 等,2025w;Xia 等,2024] 和自适应行为 [Feng 等,2025c;Sui 等,2025],其中 RL 常被作为支持这些进展的关键方法引入。Zhao 等人 [2023a] 对 LLM 的架构与应用进行了广泛概述,而近期研究则更集中于推理能力:Zhang 等人 [2025a] 综述了 DeepSeek-R1 发布后推理型 LLM 的复现研究;Chen 等人 [2025m] 探讨了长思维链推理;Li 等人 [2025w] 分析了从系统1到系统2推理的转变。这些研究将基于 RL 的方法(如 RLHF 和 RLVR)视为有用工具,但仅将其作为众多推理策略中的一项。
Sun 等人 [2025b] 从更广泛、结构化的视角探讨了通过基础模型实现的推理能力,重点介绍了专门为推理提出或适配的关键基础模型,以及在多样化推理任务、方法和基准上的最新进展。Zhang 等人 [2025b] 研究了 RL 如何赋予 LLM 自主决策与自适应智能体能力。Xu 等人 [2025a] 的研究更贴近我们的关注点,讨论了 LLM 的强化推理,强调试错优化如何提升复杂推理能力。Wu [2025] 则通过综述奖励模型与从反馈中学习的策略,补充了这一视角。然而,这些工作仍主要聚焦于推理性能或奖励设计,而非对 LLM 整体 RL 方法进行系统性梳理。
Srivastava 和 Aggarwal [2025] 是近期尝试弥合这两个领域的研究,综述了用于 LLM 对齐与增强的 RL 算法,主要方法包括 RLHF [Christiano 等,2017]、RLAIF [Lee 等,2024b] 和 DPO [Rafailov 等,2023]。但其重点仍主要放在“对齐”上,而非“推理能力”。
与以往综述或侧重通用 RL、或侧重 LLM 推理不同,我们以 RL 为核心,系统性地综合其在整个 LLM 训练生命周期中的作用,包括奖励设计、策略优化和采样策略。我们的目标是识别在 LRM 中扩展强化学习以迈向人工超级智能(ASI)的新方向,重点关注长期交互与演化过程。
- 基础组件
在本节中,我们回顾面向大推理模型(LRMs)的强化学习(RL)的基础组件,包括奖励设计(§3.1)、策略优化算法(§3.2)和采样策略(§3.3)。基础组件的分类结构如图5所示。
3.1 奖励设计
在本小节中,我们对面向 LRMs 的 RL 中的奖励设计进行系统性考察。我们首先在 §3.1.1 中讨论“可验证奖励”,这是最自然的起点。该方向已取得显著进展,典型代表是 DeepSeek-R1 的成功,其通过可验证的奖励机制证明了 RL 的可扩展性。与之相对,§3.1.2 探讨“生成式奖励”,即让模型自身参与验证或直接生成奖励信号。然而,无论是可验证奖励还是生成式奖励,通常都表现为稀疏的数值反馈。奖励信号的一个重要补充维度是其“密度”。因此,§3.1.3 考察了引入“稠密奖励”的方法。另一个分类维度在于奖励是基于外部真实标签计算,还是由模型直接估计得出。这一区别促使我们在 §3.1.4 中讨论“无监督奖励”。在上述四类奖励的基础上,我们在 §3.1.5 进一步探讨“奖励塑形”,分析如何组合或转换多样化的奖励信号以促进学习。
3.1.1.可证实的奖励
要点总结:
- 基于规则的奖励通过利用准确性和格式检查,为强化学习提供了可扩展且可靠的训练信号,尤其适用于数学和编程任务。
- “验证器定律”指出,具有清晰且可自动验证标准的任务能够实现高效的 RL 优化,而主观性任务仍具挑战性。
基于规则的奖励。奖励作为强化学习(RL)的训练信号,决定了优化方向 [Guo 等,2025a]。近期,在大规模 RL 训练大推理模型(LRMs)时,主要采用基于规则的可验证奖励。这类奖励通过鼓励更长、更具反思性的思维链(chain-of-thought),可靠地提升数学与编程推理能力 [Guo 等,2025a;Team,2025c;Yu 等,2025d]。这一范式在 Tülu 3 [Lambert 等,2024] 中被正式命名为 RLVR(基于可验证奖励的强化学习),其核心是用程序化验证器(如答案检查器或单元测试)替代学习得到的奖励模型。这类验证器在具有客观可验证结果的领域中提供二元、可检查的信号。随后,类似基于规则的可验证奖励设计被整合进 DeepSeek 的训练流程。例如,DeepSeek-V3 [Liu 等,2024] 明确引入了专为确定性任务定制的基于规则的奖励系统,而 DeepSeek-R1 [Guo 等,2025a] 进一步采用了基于准确性和基于格式的奖励。基于规则的奖励与基于结果或基于过程的奖励模型(RMs)形成对比,例如标准 RLHF 中使用基于人类偏好排序训练的学习型奖励模型 [Ouyang 等,2022],以及基于步骤级标注训练的过程奖励模型(PRMs)[Setlur 等,2024;Sun 等,2025c;Yuan 等,2025d]。DeepSeek-V3 和 DeepSeek-R1 表明,当奖励模型被扩展至大规模 RL 场景时,可能出现“奖励作弊”(reward hacking)问题;而通过尽可能采用基于规则的奖励,我们能确保系统更具可靠性,使其对操纵和利用更具抵抗力 [Guo 等,2025a;Liu 等,2024]。
在实践中,两类基于规则的可验证奖励被广泛使用:
- 准确性奖励:对于具有确定性结果的任务(如数学题),策略必须在指定分隔符内(通常为 \boxed{...})输出最终解,自动检查器随后将该输出与真实答案进行比对。对于编程任务,则通过单元测试或编译器提供通过/失败信号 [Albalak 等,2025;Chen 等,2025r;Guo 等,2025a]。
- 格式奖励:这类奖励施加结构约束,要求模型将其私有的思维链置于 <think> 和 </think> 标签之间,并在独立字段(如 <answer>...</answer>)中输出最终答案。这有助于在大规模 RL 中实现更可靠的解析与验证 [Guo 等,2025a;Lambert 等,2024]。
基于规则的验证器。基于规则的奖励通常源自基于规则的验证器。这些验证器依赖大量人工编写的等价规则,以判断预测答案是否与真实答案匹配。目前广泛使用的数学验证器主要基于 Python 库 Math-Verify¹ 和 SymPy²。此外,如 DAPO [Yu 等,2025d] 和 DeepScaleR [Luo 等,2025c] 等工作也提供了开源且成熟的验证器。近期,Huang 等人 [2025e] 指出了基于规则和基于模型的验证器各自存在的独特局限性,以指导设计更可靠的奖励系统。
在实践中,诸如数学解题和代码生成等任务虽然求解困难,但相对容易验证,因此满足高效 RL 优化的主要标准 [Guo 等,2025a;He 等,2025d]:存在明确的真实答案、具备快速的自动化验证手段、可规模化评估大量候选解,且奖励信号与正确性高度一致。相比之下,缺乏快速或客观验证手段的任务(如开放式问答或自由写作)对基于结果的 RL 仍具挑战性,因为它们依赖噪声较大的学习型奖励模型或主观的人类反馈 [Yu 等,2025e;Zhou 等,2025e]。
验证器定律(Verifier’s Law)指出:训练 AI 系统完成某项任务的难易程度,与该任务的可验证程度成正比³。该定律强调,一旦某项任务能配备稳健的自动化反馈机制,便可通过 RL 快速取得进步。第6节所讨论的成功应用印证了这一原则,其核心挑战正是设计可靠的可验证反馈。相反,第7节中强调的许多开放性问题,恰恰源于缺乏可靠的自动化奖励机制。
3.1.2.生成奖励
要点总结:
- 生成式奖励模型(GenRMs)通过提供细致的、基于文本的反馈,将强化学习扩展至主观性强、不可验证的领域,从而克服了基于规则系统的局限性。
- 一个主导趋势是训练奖励模型在评判前先进行推理,通常借助结构化评分标准引导评估,或在统一的强化学习循环中与策略模型协同演化。
尽管如前所述(§3.1.1),基于规则的奖励能为可验证任务提供可靠的信号,但其适用范围有限。许多复杂的推理任务,尤其是在开放式或创造性领域,缺乏客观的真实答案,使得简单的验证器难以处理。为弥合这一鸿沟,生成式奖励模型(GenRMs)作为一种强有力的替代方案应运而生。与输出单一标量分数不同,GenRMs 利用大推理模型(LRMs)的生成能力,产生结构化的批评、理由和偏好,从而提供更具可解释性和细致入微的奖励信号 [Mahan 等,2024;Zhang 等,2024a]。该方法解决了两个关键挑战:第一,它提升了对难以解析的可验证任务的验证鲁棒性;第二,更重要的是,它使强化学习能够应用于主观性强、不可验证的领域。
面向可验证任务的模型化验证器。基于规则系统的一个主要问题是其脆弱性:当模型以非预期格式生成正确答案时,系统常产生假阴性。为缓解这一问题,部分研究采用“基于规范的 GenRMs”作为灵活的模型化验证器。这些模型经过训练,能够语义上评估模型自由形式输出与参考答案之间的等价性。该方法已被用于开发轻量级验证器,以增强现有基于规则的系统 [Xu 等,2025g],也用于构建更全面、多领域的验证器,能够处理多样化的数据类型和推理任务 [Chen 等,2025b;Liu 等,2025n;Ma 等,2025c;Seed 等,2025a]。通过用学习得到的语义判断替代或补充僵化的字符串匹配,这些验证器在可验证领域为强化学习提供了更精确的奖励信号。
面向不可验证任务的生成式奖励。GenRMs 的另一核心应用是“基于评估的 GenRMs”,它使得在“验证器定律”不成立的任务上也能应用强化学习。该范式已从使用强大 LLM 作为零样本评估器,演进为复杂的、协同演化的系统。我们可以根据其核心设计理念对这些方法进行分类:
- 推理型奖励模型(学会思考):相较于简单的偏好预测,一大进步是训练奖励模型在做出判断前显式进行推理。这一方法是“LLM 作为评判者”概念的基础 [Li 等,2023b;Zheng 等,2023],即提示奖励模型生成思维链(CoT)式批评或理由。例如,CLoud RMs 首先生成自然语言批评,再据此预测标量奖励 [Ankner 等,2024]。将奖励建模视为推理任务的设计理念,现已成为最先进奖励模型的核心:它们在打分或给出偏好前,被训练生成详细的理由 [Chen 等,2025p;Guo 等,2025b;Hong 等,2025b;Liu 等,2025x;Wang 等,2025c;Zhou 等,2025c]。为进一步提升判断能力,这些推理型奖励模型本身常通过强化学习进行训练,使用基于其最终判断正确性的简单、可验证的元奖励 [Chen 等,2025l;Whitehouse 等,2025]。该研究方向还探索了不同奖励格式,例如从 token 概率推导软性奖励 [Mahan 等,2024;Su 等,2025c;Zhang 等,2024a],以及权衡逐点打分与成对比较打分方案的利弊 [He 等,2025a;Xu 等,2025c]。
- 基于评分标准的奖励(结构化主观性):为使主观任务的评估锚定在更一致的标准上,许多框架采用结构化评分标准(rubrics)。不同于依赖硬编码逻辑处理客观可验证任务的基于规则方法,评分标准方法利用自然语言描述来捕捉主观、不可验证领域中细致的评估标准——在这些领域,传统的二元规则已不足够。这包括使用 LLM 生成或遵循一套原则清单以指导评估。RaR [Gunjal 等,2025]、QA-LIGN [Dineen 等,2025]、Rubicon [Huang 等,2025f] 和 RLCF [Viswanathan 等,2025] 等框架均使用此类评分标准,生成细粒度、多维度的奖励。这一概念还可延伸为将高层任务分解为一组可验证的代理问题 [Guo 等,2025e],或生成特定领域的原则,如用于创意写作 [Jia 等,2025] 或科学评审 [Zeng 等,2025c]。此外,评分标准可兼具双重作用:既作为指导策略探索的教学支架,也作为最终奖励的评判标准 [Zhou 等,2025f]。
- 协同演化系统(统一策略与奖励):最先进的范式超越了静态的策略-奖励关系,转向生成器与验证器共同进化的动态系统。这可通过以下方式实现:
- 自我奖励(Self-Rewarding):单一模型生成自身的训练信号。这一方法在《自我奖励语言模型》[Yuan 等,2024] 中得到显著展示,并在多个框架中实现:模型在策略角色与验证器角色间交替 [Jiang 等,2025e];基于自身批评进行自我修正 [Team,2025c;Xiong 等,2025b;Zhang 等,2025m];或通过“完成后学习”将奖励函数内化 [Fei 等,2025b]。
- 协同优化(Co-Optimization):策略模型与独立的奖励模型并行训练。例如,RL Tango 使用共享的最终结果级奖励,联合训练生成器和过程级 GenRM [Zha 等,2025]。类似地,Cooper 通过协同优化两个模型来增强鲁棒性并缓解奖励作弊 [Hong 等,2025a]。其他工作则在一个模型内统一策略(“选手”)与奖励(“裁判”)功能,并通过统一的强化学习循环进行训练 [Lu 等,2025e]。
从静态评判者到动态协同演化系统的演进,通常由混合奖励方案支持——即结合基于规则与生成式信号 [Li 等,2025c;Seed 等,2025a]。此外,GenRMs 正被调整为提供更细粒度的过程级反馈,以解决复杂推理链中的信用分配问题 [He 等,2025f;Khalifa 等,2025;Xie 等,2025b;Zhao 等,2025b]。本质上,生成式奖励正被证明对于将强化学习扩展至通用型 LRMs 所瞄准的全任务谱系不可或缺。
3.1.3 稠密奖励
要点总结:
- 稠密奖励(例如过程奖励模型)提供细粒度的信用分配,有助于提升强化学习中的训练效率与优化稳定性。
- 对于开放域文本生成等任务,由于难以定义稠密奖励或使用验证器,其规模化扩展仍具挑战性。
在经典强化学习中,例如游戏和机器人操作任务 [Liu 等,2022;Schrittwieser 等,2020;Sun 等,2025d],稠密奖励在(几乎)每个决策步骤提供频繁反馈。这种奖励塑形缩短了信用分配的时间跨度,通常能提升样本效率和优化稳定性,但如果信号设计不当,也可能导致奖励误设或奖励作弊 [Hadfield-Menell 等,2017]。至于大语言模型的推理任务,稠密奖励通常是基于过程的信号,监督中间步骤而非仅关注最终结果,并已被证明有效,常常优于基于结果的奖励 [Lightman 等,2024;Uesato 等,2022]。根据 §2.1 中的定义,我们进一步依据动作和奖励的粒度,在 LLM 强化学习背景下形式化稀疏/结果奖励与稠密奖励,如表 2 所示。
Token 级奖励。DPO [Rafailov 等,2023] 及其后续工作 [Rafailov 等,2024] 表明,token 级奖励可计算为策略模型与参考模型之间的对数似然比值。Implicit PRM [Yuan 等,2025d] 进一步表明,可通过训练结果奖励模型(ORM)并使用 Rafailov 等人 [2024] 的参数化方法获得 token 级奖励。PRIME [Cui 等,2025a] 将 ORM 学习整合进 RL 训练中,并使用隐式 token 级奖励训练策略。SRPO [Fei 等,2025a] 在 PRIME 中移除了 ORM 并改进了优势估计。另一类工作则聚焦于使用内部反馈作为 token 级奖励,例如 token 熵 [Cheng 等,2025a;Tan 和 Pan,2025] 和策略性 n-gram [Wang 等,2025g]。
步骤级奖励。步骤级奖励的方法可分为两类:基于模型的方法和基于采样的方法。早期工作依赖人类专家标注步骤级稠密奖励 [Lightman 等,2024;Uesato 等,2022],成本高昂且难以规模化。
- 基于模型的方法:为降低标注成本,Math-Shepherd [Wang 等,2024b] 使用蒙特卡洛估计获取步骤级标签,并证明通过训练过程奖励模型(PRMs)进行过程验证在 RL 中有效。PAV [Setlur 等,2024] 通过优势建模进一步改进过程奖励。为缓解基于模型的步骤级奖励带来的奖励作弊问题,PURE [Cheng 等,2025b] 采用最小形式(min-form)而非求和形式(sum-form)的信用分配;而 Tango [Zha 等,2025] 和 AIRL-S [Jin 等,2025c] 则联合训练策略与 PRMs。随着生成式 PRMs 强大的验证能力 [Zhao 等,2025b](见 §3.1.2),ReasonFlux-PRM [Zou 等,2025]、TP-GRPO [He 等,2025f] 和 CAPO [Xie 等,2025b] 利用它们为 RL 训练提供步骤级奖励。然而,基于模型的稠密奖励易受奖励作弊影响,且在线训练 PRMs 成本高昂。
- 基于采样的方法:另一类工作使用蒙特卡洛采样进行在线过程奖励估计 [Guo 等,2025c;Hou 等,2025;Kazemnejad 等,2025;Li 等,2025r;Yang 等,2025g;Zheng 等,2025c]。VinePPO [Kazemnejad 等,2025] 通过蒙特卡洛估计改进 PPO。为改进步骤分割,SPO [Guo 等,2025c]、TreeRL [Hou 等,2025] 和 FR3E [Zheng 等,2025c] 使用低概率或高熵 token 作为分界点。为提升样本效率与优势估计,SPO [Guo 等,2025c]、TreeRPO [Yang 等,2025g]、TreeRL [Hou 等,2025] 和 TreePO [Li 等,2025r] 探索树状结构以实现细粒度过程奖励计算。MRT [Qu 等,2025b]、S-GRPO [Dai 等,2025a]、VSRM [Yue 等,2025a] 和 SSPO [Xu 等,2025f] 强制 LLM 在中间位置终止思考过程,从而高效估计步骤级奖励。PROF [Ye 等,2025a] 利用结果奖励与过程奖励之间的一致性,过滤噪声数据用于 RL 训练。
轮次级奖励(Turn-Level Rewards)。轮次级奖励评估每一次完整的智能体-环境交互(例如一次工具调用及其结果),在多轮任务中以单轮为粒度提供反馈。关于轮次级奖励的研究大致可分为两类:直接每轮监督,以及从结果级奖励中推导轮次级信号。
- 直接每轮监督:相关工作在每一轮提供显式反馈。例如,《情感敏感对话策略学习》[Zhu 等,2024] 利用用户情绪作为每轮奖励指导策略优化,展示了轮次级反馈如何提升对话智能体的交互质量。类似地,ToolRL [Qian 等,2025] 在每次工具调用步骤设计结构化奖励(格式与正确性),提供稠密的轮次级信号用于学习。Zeng 等人 [2025d] 进一步利用可验证信号配合显式轮次级优势估计,以改进 RL 中的多轮工具使用。此外,SWEET-RL [Zhou 等,2025g] 学习一个步骤/轮次级的评论家模型,提供每轮奖励与信用分配,从而实现显式轮次监督。近期,MUA-RL [Zhao 等,2025d] 将模拟用户交互纳入 RL 循环,每轮多轮交换均产生每轮反馈,使智能体能在逼真的用户-智能体动态中迭代优化策略。G-RA [Sun 等,2025g] 通过引入门控奖励聚合扩展了这一方向:仅当满足更高优先级的结果级条件时,才累积稠密的轮次级奖励(如动作格式、工具调用有效性、工具选择)。
- 从结果级奖励推导轮次级信号:其核心思想是将基于结果的监督分解或重新分配为更细粒度的单元。《基于全局反馈对齐对话智能体》[Lee 等,2025a] 将会话级分数转化为轮次级伪奖励;GELI [Lee 等,2024a] 利用多模态线索(如语调、面部表情)将会话级反馈细化为局部轮次级信号。类似地,SPA-RL [Wang 等,2025e] 通过进展归因将结果级奖励重新分配为每步或每轮贡献。ARPO [Dong 等,2025b] 沿此方向,从轨迹级结果(如工具使用后)中归因步骤/轮次级优势,有效将全局回报转化为局部信号。
总体而言,无论是直接在每次交互中分配,还是从结果分解中推导,轮次级奖励都充当了过程监督与结果监督之间的桥梁,在多轮智能体强化学习中对稳定和提升优化起着核心作用,更多细节见 §6.2。
3.1.4 无监督奖励
要点总结:
- 无监督奖励消除了人工标注的瓶颈,使奖励信号的生成规模取决于计算与数据,而非人力劳动。
- 主要方法包括从模型自身过程中提取信号(模型专属:一致性、内部置信度、自生成知识),或从自动化外部来源获取信号(模型无关:启发式规则、数据语料库)。
前沿语言模型在广泛任务中表现出色,包括许多极具挑战性的任务 [Glazer 等,2024;Jimenez 等,2023;Li 等,2024b;Phan 等,2025]。然而,推动这些模型发展的关键限制在于强化学习(RL)对人工生成奖励信号的依赖(§3.1.1–3.1.3)。对于需要超人类专业知识的任务,人工反馈往往缓慢、昂贵且不切实际 [Burns 等,2023]。为解决这一问题,一种有前景的方法是“无监督强化学习”,即使用自动生成、可验证的奖励信号替代真实标签。该方法是实现 LLM 可扩展 RL 的基础。本节综述这些无监督奖励机制,并根据其来源将其分为两类:源自模型自身的奖励(模型专属型),以及源自外部、非人工来源的奖励(模型无关型)。
模型专属型奖励。该范式仅利用大语言模型内部知识作为监督来源。其基本假设是:高性能模型将生成具有一致性、高置信度或评估上合理的输出。该方法具有高度可扩展性,仅需模型与计算资源即可生成近乎无限量的“标注”数据。然而,其闭环特性易导致奖励作弊与模型崩溃。
- 基于输出一致性的奖励:该方法假设正确答案会在多个生成输出中形成密集且一致的聚类。基础工作如 EMPO [Zhang 等,2025i] 和测试时强化学习(TTRL)[Zuo 等,2025b] 分别通过聚类和多数投票实现该机制。后续方法旨在通过提高效率(ETTRL [Liu 等,2025c])、引入推理轨迹(CoVo [Zhang 等,2025h]),或使用对比一致性对抗奖励作弊(Co-Reward [Zhang 等,2025w])来优化该方法。
- 基于内部置信度的奖励:另一种方法是从模型内部状态直接推导奖励,以置信度作为正确性的代理。信号可基于交叉注意力(CAGSR [Kiruluta 等,2025])、负熵(EM-RL [Agarwal 等,2025b]、RENT [Prabhudesai 等,2025]),或生成概率(Intuitor [Zhao 等,2025e]、RLSC [Li 等,2025h]、RLSF [van Niekerk 等,2025])。这些方法的成功往往依赖于基础模型的初始质量 [Gandhi 等,2025],且可能表现脆弱 [Press 等,2024;Shumailov 等,2023],因为它们依赖于诸如“正确与错误路径之间存在低密度分隔”等先验假设 [Chapelle 和 Zien,2005;Lee 等,2013]。
- 基于自生成知识的奖励:该范式利用模型自身知识创建学习信号,或作为评判者(自我奖励),或作为问题提出者(自我指导)。在自我奖励中,模型评估自身输出以生成奖励,这一概念由 Yuan 等 [2024] 和 Wu 等 [2024] 提出,并应用于 SSR-Zero [Yang 等,2025f] 和 MINIMO [Poesia 等,2024] 等工作。在自我指导中,一个“提出者”模型为“求解者”模型生成课程。“提出者”常因其生成难度适中的任务而获得奖励 [Chen 等,2025i;Huang 等,2025a;Zhao 等,2025a],而“求解者”的奖励可以是模型无关型(如 AZR 中的代码执行器 [Zhao 等,2025a]),或模型专属型(如 SQLM [Chen 等,2025i] 和 SeRL [Fang 等,2025a] 中的多数投票)。
模型无关型奖励。与模型专属方法不同,该范式从外部自动化来源获取奖励。该方法将学习过程锚定于外部信息,无需人工标注。其核心原则是:这些外部信号易于获取,无需人工干预。然而,由于精确反馈通常不可得,代理奖励的质量至关重要,奖励作弊的风险依然存在。
- 启发式奖励:该方法构成另一种形式的基于规则奖励,采用基于输出属性(如长度或格式)的简单预定义规则作为质量代理。这属于 §3.1.1 中讨论的特定情况。该方法由 DeepSeek-R1 [Guo 等,2025a] 首创,后经动态奖励缩放等技术优化 [Yu 等,2025d]。尽管可扩展,但这些启发式规则易被模型“游戏化”,导致表面改进而非真实能力提升 [Liu 等,2025t;Xin 等,2025]。
- 数据驱动型奖励:该方法从大规模未标注语料库的结构中提取奖励信号。类似于大规模预训练中的下一个词预测,RPT [Dong 等,2025c] 将下一个 token 预测重构为 RL 任务,将网络规模数据集转化为数百万训练样本。在元层面,SEAL [Zweiger 等,2025] 允许模型自生成训练数据与超参数,并以下游性能作为奖励。
总之,无监督奖励设计对于构建面向 LLM 的可扩展 RL 系统至关重要。模型专属范式通过利用模型内部知识促进自我改进,而模型无关范式则将学习锚定于外部自动化反馈。尽管两种方法均有效绕过了人工标注瓶颈,但仍易受奖励作弊影响 [Zhang 等,2025q]。未来可扩展 RL 很可能涉及混合系统,战略性结合这些方法——例如,使用数据驱动奖励进行预训练,使用模型专属自我奖励微调复杂推理任务,并辅以最小化人工监督以确保安全与对齐。
3.1.5 奖励塑形
要点总结:
- 奖励塑形将稀疏信号丰富为稳定、信息量充足的梯度,以支持 LLM 训练。
- 结合验证器与奖励模型,并采用组基线加 Pass@K 对齐目标,以稳定训练、扩大探索范围,并在大规模场景下匹配评估指标。
如前所述,在强化学习中,智能体的主要学习目标是最大化累积奖励,因此奖励函数的设计尤为关键 [Sutton 等,1998]。在前几小节中,我们介绍了多种奖励函数,包括可验证奖励(§3.1.1)、生成式奖励(§3.1.2)、稠密奖励(§3.1.3),甚至无监督奖励(§3.1.4)。除了奖励工程本身,同样重要的是考虑如何修改或增强奖励函数,以鼓励有助于达成目标解的行为。这一过程被称为“奖励塑形”[Goyal 等,2019;Gupta 等,2022;Hu 等,2020;Xie 等,2023],可分为基于规则的奖励塑形和基于结构的奖励塑形。
基于规则的奖励塑形。在基于 LLM 的 RL 中,最简单且最常用的方法是将基于规则的验证器奖励与奖励模型的奖励相结合,以生成总体奖励信号,如 Qwen2.5 Math [Yang 等,2024a] 所示。通常,使用一个常数系数平衡奖励模型与基于规则组件的贡献。该方法不仅对所有正确响应赋予相同奖励,还可根据奖励模型的评分进一步对响应排序。这一方法对更具挑战性的样本尤为有用,可避免所有奖励值均为 0 或 1 的情况,从而防止学习梯度失效 [Yu 等,2025d]。这种启发式组合策略广泛应用于开放域任务,通过整合基于规则的奖励与奖励模型 [Guo 等,2025b;Liao 等,2025a;Liu 等,2025x],为 LLM 的强化学习生成更具信息量和更有效的奖励信号 [Su 等,2025c;Zeng 等,2025c;Zhang 等,2024a]。另一种方法是组合多种基于规则的奖励,如结果级奖励和格式奖励,如 DeepSeek-R1 [Guo 等,2025a] 所采用,使 LLM 能够学习长程思维链推理。这些奖励包括基于格式的 [Xin 等,2025] 和基于长度的组件 [Liu 等,2025p],用于应对 LLM 输出中的各种异常情况。与使用固定奖励权重 [Team,2025d;Yao 等,2025b] 或启发式规则进行奖励插值 [Aggarwal 和 Welleck,2025;Zhang 和 Zuo,2025] 不同,Lu 等人 [2025f] 提出了动态奖励加权方法,结合超体积引导的权重自适应与基于梯度的权重优化,在多目标对齐任务上实现了更优性能 [Li 等,2025a;Liu 和 Vicente,2024]。近期研究还探索了多角色 RL 训练,为不同角色(如求解器与评论家)分配不同奖励函数 [Li 等,2025i]。这些奖励通常通过人工设定的常数进行组合。最新工作进一步探索多角色 RL 训练 [Li 等,2025i,j],为不同角色分配不同奖励函数,以鼓励多样化行为与目标 [Li 等,2025i],例如求解器与评论家角色。
基于结构的奖励塑形。与仅依赖单个样本的基于规则方法不同,基于结构的奖励塑形利用列表级或集合级基线,在一组候选样本上计算奖励。一个有影响力的方法是 GRPO [Shao 等,2024],它使用对同一问题 G 的响应组均值作为基线(或其变体,如留一法 [Ahmadian 等,2024] 或排序),并据此构建优势值用于 PPO 式更新 [Schulman 等,2017b]。近期研究进一步修改优化目标或信用分配策略,以促进更强探索并更紧密对齐评估指标,如 Pass@K [Yue 等,2025b]。例如,Walder 和 Karkhanis [2025] 对最终奖励进行联合变换,使优化直接等价于 Pass@K 等集合级目标,并提供低方差、无偏的梯度估计。Chen 等人 [2025x] 在推导和分析优势值及高效近似时直接以 Pass@K 为目标,将集合级目标分解回单个样本的信用分配。此类奖励塑形方法旨在稳定训练,鼓励策略进行更广泛探索,从而降低过早收敛到次优局部解的风险。
3.2 策略优化
在本小节中,我们首先提供策略梯度目标的数学形式化技术概述(§3.2.1)。接着,根据梯度计算过程中奖励的生成方式,我们将 RL 中的在线策略优化算法分为两类:基于评论家的方法(§3.2.2)与无评论家方法(§3.2.3)。此外,我们讨论了近期将在线策略 RL 与离线数据集结合以实现更复杂后训练(即离策略优化)的研究(§3.2.4),以及包括熵正则化与 KL 正则化在内的多种正则化技术(§3.2.5)。
3.2.1 策略梯度目标
如第 2.1 节所述,在 LLM 的强化学习(RL)中,上下文被视为环境,而下一层预测的概率分布则被视为策略。对于一个 RL 系统,其目标是找到一个最优策略,使得系统生成的期望累积奖励最大化。由于 LLM 拥有大量参数,针对 LLM 的 RL 策略优化算法大多为基于一阶梯度的方法。通常,RL 算法的目标是优化网络参数,以使期望奖励最大化。下文我们给出适用于 LLM 的 RL 算法梯度计算的一般性公式。





PPO 算法 [Schulman et al., 2017b] 最初被提出作为 TRPO 算法 [Schulman et al., 2015a] 的一种计算效率更高的近似方法。当标准策略梯度方法因数据效率低和鲁棒性差而表现不佳时,PPO 表现尤为出色。此外,与 TRPO 相比,PPO 实现更简单、通用性更强,且具有更好的样本复杂度。
然而,由于 LLM 具有复杂且较长的思维链(CoT)特性,其精确的目标函数、梯度估计和更新技术可以呈现多种不同形式,如表 3 所示。
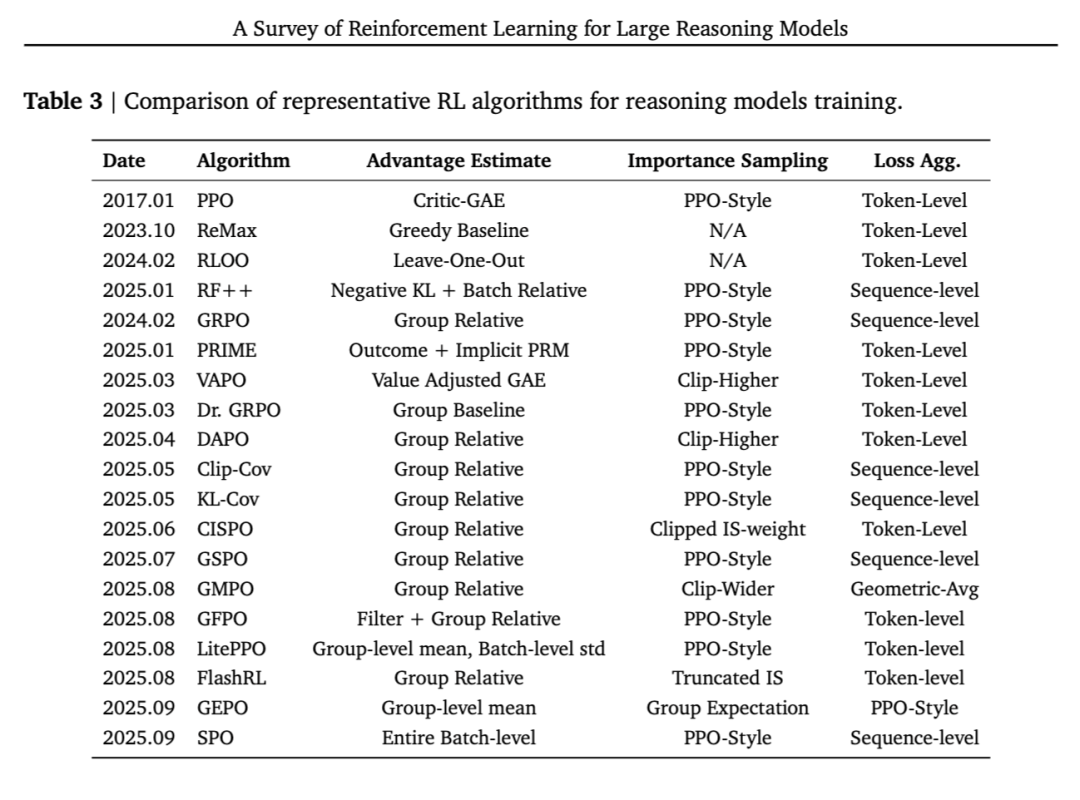
3.2.2 基于评论家的算法
要点总结:
- 评论家模型在一小部分标注数据上训练,为未标注的 rollout 数据提供可扩展的 token 级价值信号。
- 评论家需与 LLM 同步运行和更新,导致显著的计算开销,且在复杂任务上扩展性不佳。
强化学习中最早与大语言模型(LLM)相关的工作,聚焦于如何有效将 LLM 策略与外部监督对齐,以增强模型的指令遵循能力,同时确保模型具备有用性、诚实性和无害性。LLM 对齐最常用的方法是基于人类反馈的强化学习(RLHF)[Bai 等,2022a;Christiano 等,2017;Ouyang 等,2022;Stiennon 等,2020]。该技术将人类作为学习算法中的“评论家”,其具体步骤如下:首先,由 LLM 生成一组模型输出,并由人类标注以构建数据集;随后,利用该数据集训练一个奖励模型,以预测人类更偏好的响应;最后,该奖励模型与一个价值函数(即系统中的“评论家”)共同用于训练 LLM。训练通常采用 PPO 算法 [Schulman 等,2017b]。PPO 算法将目标函数形式化如下:
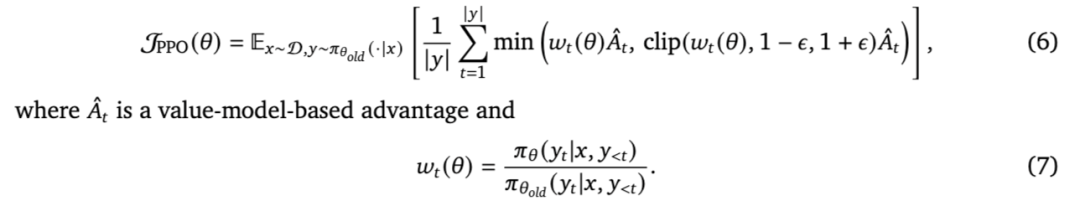

近期研究指出,对于需要长思维链(CoT)的复杂推理任务,衰减因子的扩展性不佳,并提出了价值校准 PPO [Yuan 等,2025f] 和 VAPO [Yue 等,2025c]、VRPO [Zhu 等,2025a] 等新机制,以增强评论家模型在噪声奖励信号下的鲁棒性。
此外,基于评论家的算法 [Hu 等,2025b] 还展示了在使用基于规则的奖励时,蒙特卡洛估计具有稳定的可扩展性。类似方法也通过实现过程奖励模型(PRMs)被应用于固定外部模型 [Lu 等,2024;Wang 等,2024b]。
引入评论家模型的另一种方法是引入隐式 PRM [Yuan 等,2025d]。该方法同样能够为可扩展的 RL 训练提供 token 级监督。不同于 GAE 方法,隐式 PRM [Yuan 等,2025d] 和 PRIME [Cui 等,2025a] 等方法采用特定的奖励模型形式,直接生成 token 级奖励。
3.2.3 无评论家算法
要点总结:
- 无评论家算法仅需序列级奖励进行训练,使其更具充分性与可扩展性。
- 对于 RLVR 任务,基于规则的训练信号能可靠防止与评论家相关的问题,如奖励作弊。
除了提供 token 级反馈信号用于模型训练的基于评论家的方法外,许多近期研究指出,对于使用强化学习的可扩展推理任务而言,响应级(即序列级)奖励已足够。这些无评论家算法对响应中所有 token 应用相同的基于规则或模型生成的响应级奖励,并在多种任务中展现出有效性。
与基于评论家的算法相比,无评论家方法无需单独的评论家模型,从而显著降低计算需求并简化训练过程。此外,当在基于规则的环境中训练大语言模型(LLM)时——即任何响应的奖励均可明确定义——无评论家算法可避免因评论家模型训练不佳而引发的奖励作弊问题。这一特性使得在上述场景中,无评论家算法比基于评论家的方法更具可扩展性。
经典的 REINFORCE 算法 [Williams, 1992] 是最早为强化学习开发的算法之一,已被应用于 LLM 问题 [Ahmadian 等,2024]。REINFORCE 的具体公式如下:
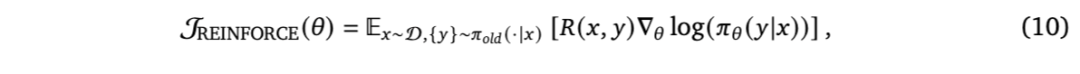
其中,𝑅(𝑥, 𝑦) 在 RLVR 任务中通常取值为 ±1。这种朴素的公式将整个序列视为单一动作,并将响应任务视为一个赌博机(bandit)问题。然而,原始算法通常因高方差而面临严重的不稳定性问题。ReMax [Li 等,2023c] 为 REINFORCE 引入了一种方差降低机制,采用贪心基线估计。Ahmadian 等人 [2024] 进一步提出了 RLOO,提供了一个无偏基线,获得更稳定的结果。REINFORCE++ [Hu, 2025] 借鉴了 PPO 和 GRPO 类算法中的技术(如裁剪和全局优势归一化),以提供更精确的优势估计和梯度估计。
目前最流行的无评论家 RL 方法之一是 GRPO [Shao 等,2024]。GRPO 的目标函数公式如下:
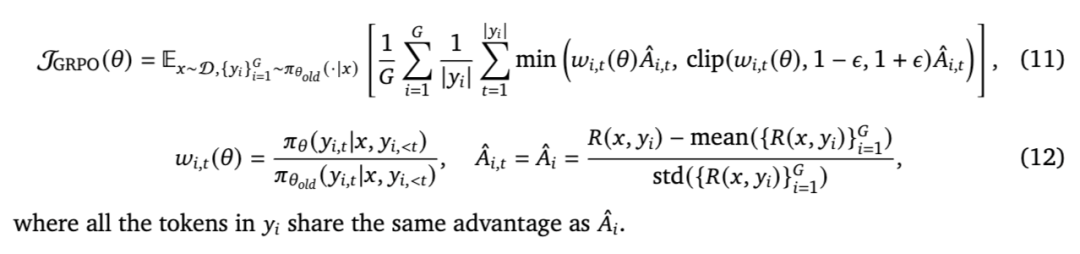
GRPO 是对 PPO 的一种无评论家改进,它不再使用由评论家提供的 GAE,而是对整个序列采用相同的优势估计值,该估计值通过组相对归一化计算,相比二元的基于规则奖励能提供更优的估计。与 PPO 和 REINFORCE 类方法相比,GRPO 的组基优势计算有效降低了训练信号的方差,并被证明可加速训练过程。其他近期方法,包括 DAPO [Yu 等,2025d]、CISPO [Chen 等,2025a]、Dr. GRPO [Liu 等,2025u]、LitePPO [Liu 等,2025w],通过对采样策略、裁剪阈值和损失归一化进行精细调优,进一步改进了 GRPO,以增强 RL 训练过程的稳定性。另一项近期工作 GSPO [Zheng 等,2025a] 将 token 级裁剪的重要性采样比率替换为序列级裁剪。
除了 REINFORCE 和 GRPO 相关算法外,还存在其他无评论家方法。VinePPO 通过用蒙特卡洛优势估计替代学习得到的评论家,对 PPO 进行了修改。CPGD [Liu 等,2025z] 提出了一种新颖的策略梯度目标函数,并结合漂移正则化机制。K1.5 [Team,2025d] 在基础模型训练中采用镜像下降的适配形式进行强化学习,成功增强了 LLM 的长上下文推理能力。Lv 等人 [2025] 最近提出了一种统一的策略梯度估计器,结合混合后训练算法,为 LLM 中的强化学习提供统一的策略梯度估计框架。SPO [Xu 和 Ding,2025] 引入了一种无组、单流策略优化方法,用持久的 KL 自适应值追踪器和全局优势归一化替代每组基线,在保持高效扩展于长视野和工具集成场景的同时,实现比 GRPO 更平滑的收敛和更高精度。HeteroRL [Zhang 等,2025c] 将 rollout 采样与参数学习解耦,支持去中心化异步训练,并通过 GEPO 在由延迟引起的 KL 漂移(理论上呈指数级)下降低重要性权重方差,即使在严重延迟情况下(例如 1800 秒时性能下降 <3%)仍能保持稳定。
策略优化中的重要性采样。由于强化学习中存在 rollout-奖励-训练循环,通常在计算上难以保证 rollout 数据严格遵循当前模型的策略分布。因此,引入了重要性采样以减少训练偏差。重要性采样在 RL 中的最初版本出现在 TRPO 中,其在目标函数中引入了 token 级重要性比率 𝑤𝑖,𝑡。该方法被近期许多工作广泛采用,如 GRPO。然而,该方法受限于 token 级重要性比率,因为对于长程思维链(CoT)上下文,实际分布比率难以有效计算。但 token 级重要性采样又给 RL 算法引入了另一种偏差,因为给定策略的实际采样分布应基于状态-动作对定义,而 token 级方法仅考虑当前动作。GMPO [Zhao 等,2025f] 试图通过引入几何平均来缓解这一问题,以提高对具有极端重要性采样比率的 token 的训练鲁棒性。在近期工作 GSPO [Zheng 等,2025a] 中,计算了序列级重要性采样因子。GSPO 增加了一个独特的归一化因子以确保概率比率可计算,但该方法仍是对真实重要性采样因子的一种有偏估计。
一个有前景的新方向是:超越标准在线策略梯度方法的理论框架,转而直接从监督学习理论推导出本质上的离策略算法 [Chen 等,2025c]。我们将在下一节详细介绍离策略优化方法。
3.2.4 离策略优化
要点总结:
- 离策略强化学习通过将数据收集与策略学习解耦,提升样本效率,支持从历史数据、异步数据或离线数据集中进行训练。
- 当前实践常混合使用离策略、离线与在线策略方法(例如 SFT+RL 或大规模离线学习),以提高训练稳定性和性能。
在强化学习中,离策略方法处理的是学习中的策略(目标策略)与生成数据的策略(行为策略)不一致的情况。这一核心区别允许智能体在数据收集过程中无需遵循最优行为,即可学习最优行动方案。这种灵活性是一项关键优势,通常比在线策略方法更具备样本效率——因为在线策略方法每次更新都需要从当前策略中直接采样新数据。这类方法的核心挑战在于校正行为策略与目标策略之间的分布偏移,通常通过重要性采样并结合加权目标函数来解决:

在大规模模型训练的实际应用中,离策略学习常以不同形式体现。近期研究大致可分为三个方面:1)训练与推理精度差异,即模型以高精度训练但以低精度部署,导致目标策略与行为策略之间出现差距;2)异步经验回放机制,通过在学习过程中重用历史轨迹,提升效率与稳定性;3)更广泛的离策略优化方法,包括优化器层面的改进、数据层面的离线学习,以及结合监督微调(SFT)与强化学习(RL)的混合方法。
训练-推理精度差异。一个显著的离策略场景源于训练模型与推理模型在参数精度上的差异,例如训练与推理采用不同框架 [Yao 等,2025a](如 vLLM 与 FSDP),或为加速推理而对模型进行量化 [Lin 等,2016],这体现了 LLM 推理中的非确定性 [He 和 Lab,2025]。通常做法是使用高精度参数(如 32 位浮点数)训练模型,然后部署低精度参数(如 8 位整数)的量化版本 [Liu 等,2025i]。这导致已部署的低精度模型作为行为策略生成真实世界交互数据,而高精度模型则作为训练过程中持续更新的目标策略。尽管这种不匹配构成了一个离策略学习问题,但研究表明,由量化引起的策略差异通常较小。因此,可通过简单的校正技术(如截断重要性采样,TIS [Ionides,2008;Yao 等,2025a])有效管理该差异,在保持加速推理优势的同时实现稳定训练。
异步离策略训练。异步训练天然与 LLM 的离策略强化学习相契合。多个“执行者”并行生成轨迹并将其追加到共享经验回放缓冲区,而一个中心化“学习者”从该缓冲区中采样小批次数据以更新目标策略。基于这一视角,近期多项方法有意重用历史轨迹,以提升效率与稳定性。例如,“回溯回放”(Retrospective Replay)[Dou 等,2025] 通过选择性回放早期推理轨迹,引导当前策略更新,从而增强 LLM 推理的探索能力。类似地,EFRame [Wang 等,2025b] 采用“探索-过滤-回放”机制,将过滤后的响应与新生成的 rollout 交错使用,以鼓励更深入的推理。在代码生成领域,“可能性与通过率优先经验回放”(PPER)[Chen 等,2024c] 进一步优先选择缓冲区中高价值代码样本,实现更稳定的优化。将这些思想扩展至多模态交互,ARPO [Lu 等,2025b] 将回放应用于 GUI 智能体,在稀疏奖励条件下通过重用成功轨迹提供可靠的学习信号。最后,RLEP [Zhang 等,2025d] 以早期运行中已验证的成功轨迹构建经验缓冲区,并将其与新 rollout 混合,以平衡可靠性与探索发现。这些方法共同表明,经验回放缓冲区已成为现代基于 LLM 的智能体进行异步离策略训练的基石。
离策略优化。近期在微调 LLM 方面的进展探索了超越传统在线策略 RL 的复杂优化策略。这些方法被广泛归类为离策略和混合策略优化,旨在通过创造性地利用多种来源的数据,提升样本效率、训练稳定性与整体性能。我们从以下方面介绍:
- 优化器层面的离策略方法:这类方法聚焦于改进优化过程本身,强调策略更新的稳定性和效率。例如,SPO [Cohen 等,2025] 引入一种软策略优化方法,支持稳定的在线离策略 RL;TOPR [Roux 等,2025] 提出一种锥形离策略 REINFORCE 算法,以提高稳定性和效率。ReMix [Liang 等,2025a] 则进一步强调高效利用离策略数据,以最大化可用信息的效用。
- 数据层面的离策略方法:一类离策略算法完全从大规模外部离线数据中学习 [Zhang 等,2025g]。例如,“动态微调”(DFT)框架 [Wu 等,2025i] 将 SFT 损失泛化为 RL 形式,并引入停止梯度机制,使其能像 SFT 一样在离线数据上训练,同时获得性能提升。同样基于离线数据,“直觉微调”(IFT)[Hua 等,2024] 增加了时间残差连接,融合 SFT 与 RLHF 目标,并显式建模并优化当前 token 对所有未来生成的影响。另一个相关方法是“直接偏好优化”(DPO)[Rafailov 等,2023],它直接从偏好数据中优化策略。这些方法共同代表了强化学习向更以数据为中心的方向演进,使模型能从海量多样的离线数据中学习出复杂策略。
- 混合策略方法:在更高效重用历史数据的同时,混合策略优化是另一重要趋势,它结合了 SFT 与 RL 各自的优势。该混合方法利用专家数据上 SFT 的稳定性,同时使用 RL 优化特定奖励函数,并通过两种主要方式整合监督数据:一是损失层面,将 SFT 与 RL 目标直接在损失函数中结合 [Lv 等,2025;Xiao 等,2025b;Zhang 等,2025k;?]。如 UFT [Liu 等,2025k]、SRFT [Fu 等,2025c]、LUFFY [Yan 等,2025a]、RED [Guan 等,2025] 和 ReLIFT [Ma 等,2025a] 均属此类,它们构建统一或单阶段训练过程,同步学习专家示范与 RL 反馈。二是数据层面,利用专家数据构建生成过程本身。在此,高质量数据作为前缀或锚点,引导模型探索 [Guo 等,2025d]。例如,BREAD [Zhang 等,2025p] 从专家锚点生成分支 rollout,Prefix-RFT [Huang 等,2025g] 通过前缀采样混合训练机制。通过在损失或数据层面混合策略,这些方法可防止奖励作弊,并确保模型保留 SFT 中学到的知识,从而构建出更鲁棒、更强大的复杂推理模型。
3.2.5 正则化目标
要点总结:
- 针对特定目标的正则化有助于平衡探索与利用,提升强化学习效率和策略性能。
- KL、熵和长度正则化的最优选择与形式仍是开放问题,每种方法均会影响策略优化与可扩展性。
如前文所述,确保训练稳定性并防止灾难性策略漂移至关重要。特别是对于长时域训练,KL 正则化和熵正则化等技术被广泛采用。

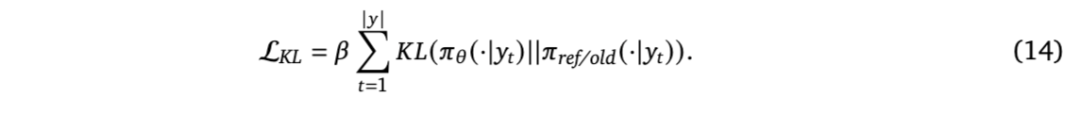
- 对于第一种情况,这是 RLHF 中常用的技术 [Ouyang 等,2022;Touvron 等,2023]。该方法最初被引入是为了防止模型被破坏性地更新。先前的研究认为,在数千步训练中引入 KL 惩罚对于维持稳定性、避免熵崩溃至关重要。为降低 KL 项过度限制进展的风险,Liu 等人 [2025] 将该方法与周期性参考策略重置相结合,即参考模型被更新为训练策略的最近快照。为了同时保持知识并增强推理能力,Wang 等人 [2025i] 对低熵 token 施加更强的 KL 正则化,而对高熵 token 施加较弱的正则化。然而,在面向 LLM 推理的强化学习背景下,由于其挑战性远高于标准 RLHF,此类 KL 正则化的必要性需要重新审视。近期许多研究指出,策略在训练过程中应自由探索,可能显著偏离初始状态以发现新的思维链(CoT)结构,因此 KL 约束可能是一种不必要的限制。因此,大多数近期工作主张完全移除 KL 惩罚 [An 等,2025;Arora 和 Zanette,2025;Chen 等,2025q;Cui 等,2025a;Fan 等,2025b;He 等,2025d;Liao 等,2025b;Liu 等,2025u;Yan 等,2025a;Yu 等,2025d],以简化实现、降低内存成本并实现更可扩展的 GRPO。
- 对于第二种情况,它可以作为策略损失中裁剪形式的替代方案 [Schulman 等,2017b]。Zhang 等人 [2025r] 讨论了前向 KL、反向 KL、归一化 KL 和标准化形式之间的差异。该方法也已被 Cui 等人 [2025b]、Lyu 等人 [2025]、Team [2025d] 采用,展示了其在不同 RL 训练规模下的潜力。尽管如此,其更深层次机制及其对可扩展 RL 的重要性仍处于探索之中。
熵正则化。在强化学习文献中,保持策略熵通常被认为是许多算法的关键方面 [Eysenbach 和 Levine,2021;Williams,1992;Williams 和 Peng,1991]。为此,策略熵通过正则化技术主动控制 [Haarnoja 等,2018;Schulman 等,2017b;Ziebart 等,2008]。

然而,在面向大语言模型(LLMs)的强化学习中,直接应用熵正则化既不常见,也往往无效 [Cui 等,2025b;He 等,2025d]。在损失函数中显式引入熵正则化项仍存在争议。部分研究者认为其有益,或采用标准系数 [Shrivastava 等,2025],或设计针对性损失函数 [Wu 等,2025e];而另一些研究者则持反对意见,认为它可能导致训练不稳定,甚至崩溃,尤其在稀疏奖励场景下 [An 等,2025;Liao 等,2025b]。许多研究表明,若不加干预,训练过程中常出现“熵崩溃”现象 [Cheng 等,2025a;Cui 等,2025b;Yu 等,2025d],从而阻碍策略在训练期间的有效探索。为解决这一问题,He 等人 [2025d] 动态调整熵损失项的系数;Yu 等人 [2025d] 采用“clip-higher”技术,使更多低概率 token 参与策略更新;Wang 等人 [2025m] 直接在 20% 高熵 token 上进行训练;Cheng 等人 [2025a] 和 Chen 等人 [2025j] 则通过将熵纳入优势计算来强调其作用。除上述显式最大化熵的技术外,Cui 等人 [2025b] 还从理论上解释了熵动态变化的底层机制,指出动作输出概率与其优势值之间的协方差是驱动熵变化的“引擎”。基于这一洞察,他们提出了 Clip-Cov 和 KL-Cov 方法,通过选择性约束协方差异常高的少量 token 来调控熵。
长度惩罚。近期大推理模型(LRMs)在复杂任务上的成功,验证了长思维链(long-CoT)推理的有效性。然而,更长的推理轨迹会带来更高的推理成本。为在推理预算与性能之间取得平衡 [Agarwal 等,2025a;He 等,2025e],许多研究致力于在保持模型性能的同时降低推理成本 [Aggarwal 和 Welleck,2025;Liu 等,2025p;Luo 等,2025a;Su 等,2025b;Xiang 等,2025]。例如,Aggarwal 和 Welleck [2025] 通过确保模型遵守用户指定的长度约束来控制推理长度;Yuan 等人 [2025a] 和 Luo 等人 [2025a] 在优化目标中设计了相对长度正则化项和准确性保持约束;Xiang 等人 [2025] 和 Liu 等人 [2025p] 则提出根据问题难度施加自适应长度惩罚,以保留模型能力。
3.3 采样策略
与静态数据集不同,强化学习依赖于主动构建的 rollout(轨迹采样),其中关于“采样什么”和“如何采样”的决策直接影响学习效率、稳定性以及所习得推理行为的质量。有效的采样策略不仅能确保训练信号的多样性和信息量,还能使学习过程与预期的奖励结构和策略目标保持一致。在本小节中,我们将综述动态与结构化采样方面的最新进展(§3.3.1),以及进一步优化采样和策略改进的超参数调整技术(§3.3.2)。
3.3.1 动态与结构化采样
要点总结:
- 高质量、多样化的 rollout 能稳定 RL 训练,并通过让智能体接触更广泛且有意义的经验来提升整体性能。
- 在探索多样化轨迹与保持高采样效率之间取得平衡,是强化学习中的一个根本性权衡。
采样已成为推理型大语言模型(LLM)强化学习微调中的一等公民(first-class lever),作为一种高效且自适应的机制,它能最大化数据利用率、减少无效计算、增强训练效果,或作为控制与引导手段,使 LLM 以结构化格式进行采样。
动态采样。动态采样根据在线学习信号(如成功率、优势值、不确定性或估计难度),动态调整用于 rollout 的提示选择及每个提示分配的计算预算。其主要目标是将计算资源集中于信息量丰富的样本,同时避免已饱和或无效样本。现有方法大致分为两类:
- 面向效率的采样:部分工作使用在线过滤,聚焦中等难度问题,以确保训练的有效性与效率。代表性设计如 PRIME [Cui 等,2025a],它通过在线过滤剔除过于简单或过于困难的问题。另一个例子是 DAPO [Yu 等,2025d],它对 rollout 已饱和(全正确)或退化(全错误)的提示进行过采样和过滤,反复采样直至每个小批次均包含具有非零优势值的提示,从而聚焦中等难度样本,维持信息丰富的梯度。在此基础上,优先采样方案根据失败率按比例分配 rollout 预算,如 𝑝(𝑖) ∝ (1 − 𝑠𝑖) 规则 [Team,2025d]。课程学习方法则在多个尺度上运作:类别级选择 [Chen 等,2025o] 使用非平稳多臂赌博机,而 E2H [Parashar 等,2025] 遵循由易到难的调度,并对小模型提供收敛性保证。效率优化方法包括预 rollout 筛选以跳过无用提示,以及基于难度的在线选择结合 rollout 回放 [Sun 等,2025e;Zheng 等,2025b]。POLARIS [An 等,2025] 通过离线难度估计形式化该过程,按模型规模构建“镜像-J”分布,持续移除已掌握项目,并在批次内进行信息替换。为进一步提升效率,近期进展使用轻量级控制器实现自适应采样 [Do 等,2025;Shi 等,2025b],无需修改算法;经验回放配合随机重排 [Fujita,2025] 通过均衡利用降低方差;增强型优先方法 [Li 等,2024a] 则根据经验池特征动态调整优先级权重。采样效率还可通过以专家数据结构化生成过程来提升:使用高质量演示作为前缀锚点,引导探索偏向搜索空间中更有希望的区域 [Guo 等,2025d;Huang 等,2025g;Zhang 等,2025p]。该领域正从均匀采样转向模型感知策略,结合项目级、类别级和难度级选择,以在每次 rollout 中获得更强的学习信号。
- 面向探索的采样:另有部分工作旨在利用动态 rollout 促进探索。ARPO [Dong 等,2025b] 提出熵引导 rollout,确保高不确定性,促使模型调用外部工具,从而提升多样性。DARS [Yang 等,2025h] 提出一种 rollout 机制,为不同难度的问题动态分配样本数量。Zhou 等人 [2025f] 提出 RuscaRL,在 rollout 过程中为策略提供不同评分标准(rubrics),以增强探索。与上述方法不同,G2RPO-A [Guo 等,2025d] 并不丢弃全错问题,而是在思考过程中加入引导,为困难问题生成正确样本。此外,Li 等人 [2025t] 利用最新的 𝑘 个检查点生成 𝑘 个响应,以防止训练过程中的遗忘现象。
结构化采样。结构化采样不仅控制采样内容,还控制推理轨迹的拓扑结构,使生成过程、信用分配和计算复用与问题求解的底层结构对齐。通过将 rollout 组织为树结构或共享/分段前缀,这些方法支持节点级奖励、更高效地复用部分计算(如 KV 缓存),并在内存与预算限制下实现更高的样本效率。我们重点介绍两种代表性方法:
- 搜索驱动的树状 rollout:其他工作利用蒙特卡洛树搜索(MCTS)进行树状响应生成,遵循经典阶段:初始化、选择、扩展和回溯。它们将单次推理视为一棵树而非单一链,并在节点级别分配奖励,从而产生更稠密/细粒度的过程信号。Hou 等人 [2025] 提出 TreeRL,一种在线策略树搜索框架,相比传统的思维链 RL(ChainRL),它通过更高效的搜索策略显著降低计算开销并取得更优性能。同时,ToTRL [Wu 等,2025c] 在合成谜题环境中引入“思维树”引导训练范式,使模型能够泛化到分布外任务(如数学推理)。此外,Yang 等人 [2025g] 将 MCTS 整合进训练流程,生成基于规则的细粒度过程奖励,提升策略优化中奖励信号的粒度与保真度。
- 共享前缀或分段式方案:尽管这些树搜索方法丰富了探索并提供细粒度奖励,其样本效率仍存局限。部分工作设计分段/共享前缀采样以提升生成效率 [Guo 等,2025c;Hou 等,2025;Li 等,2025r;Yang 等,2025g]。SPO [Guo 等,2025c]、TreeRPO [Yang 等,2025g]、TreeRL [Hou 等,2025]、FR3E [Zheng 等,2025c] 和 ARPO [Dong 等,2025b] 均从先前生成的前缀开始进行额外采样。TreePO [Li 等,2025r] 实现了一种分段式树采样算法,缓解了 KV 缓存负担,减少训练所需的 GPU 小时数,提升采样效率。
3.3.2 采样超参数
要点总结:
- 精细的超参数调优对于可扩展的强化学习至关重要,因为朴素的设置可能导致效率低下和训练不稳定(例如熵崩溃)。
- 可扩展的强化学习依赖于多种策略的整体组合,以平衡成本与稳定性,例如分阶段延长上下文长度和动态探索控制。
本小节总结了近期研究中针对采样的超参数调整策略。有效的强化学习训练需要在多个相互竞争的目标之间取得精细平衡,近期文献主要聚焦于两个核心维度的技术:1)管理探索与利用之间的权衡,以确保模型既能发现又能优化高效的推理路径;2)高效管理序列长度,在推理深度与计算成本之间取得平衡。
探索与利用的动态平衡。核心挑战在于平衡“探索”(发现新颖的推理策略)与“利用”(优化高奖励解)。主要调控手段包括温度(temperature)、熵正则化以及 PPO 的裁剪机制。在温度设置方面,策略差异显著:部分研究提出动态调整方法,例如分阶段逐步升高温度(如针对 4B 模型从 1.40 → 1.45 → 1.50,针对 7B 模型从 0.7 → 1.0 → 1.1),以在训练过程中逐步扩大轨迹多样性 [An 等,2025];或使用调度器动态调整温度,以维持稳定的熵水平 [Liao 等,2025b]。更规范化的做法建议将训练温度调校至缩放后熵值稳定在目标值 0.3 左右,该值被发现能实现最优平衡 [Liu 等,2025v;Wu 等,2025e]。其他研究则简单主张使用较高且固定的温度(如 1.0 或 1.2)以鼓励初期探索,但也指出仅靠此不足以防止长期熵下降 [Arora 和 Zanette,2025;Liu 等,2025j;Shrivastava 等,2025]。
长度预算与序列管理。几乎所有研究都需应对生成响应长度的管理问题,以在性能与成本间取得平衡。最普遍的策略是“分阶段上下文延长”[Luo 等,2025c]。具体做法是:RL 训练初期使用较短上下文窗口(如 8k),随后逐步扩展至 16k、24k 或 32k [Chen 等,2025q;Liu 等,2025j,v;Luo 等,2025c]。初期短上下文阶段被认为是关键,因为它迫使模型学习更简洁、token 效率更高的推理模式 [Chen 等,2025q;Liu 等,2025v;Luo 等,2025c]。另一种替代方案是在推理时应用长度外推技术(如 Yarn),使在较短序列上训练的模型能泛化至更长序列 [An 等,2025]。对于超出长度预算的响应,目前尚无共识:部分研究在响应接近最大长度时施加软性线性惩罚 [Yu 等,2025d],或在奖励函数中直接引入可调惩罚系数(𝛼)[Arora 和 Zanette,2025]。更精细的、分阶段依赖的策略是:在长度预算较短时(8k–16k)过滤(屏蔽损失)超长样本,而在预算较大时(32k)则施加惩罚——因为在极长上下文下,过滤可能产生负面影响 [Liu 等,2025v;Wu 等,2025e]。
纵观这些研究,有效的超参数调整体现为对探索(温度、熵目标、裁剪)、效率(分阶段长度课程)和序列管理(超长样本过滤、惩罚或推理时外推)的联合调优。这些方法可直接应用于大多数面向 LLM 的 GRPO/PPO 风格强化学习流水线。
- 基础性问题
在回顾了面向大语言模型(LLM)的强化学习(RL)流水线的关键组件之后,我们现在转向该领域中若干仍处于核心地位且常常悬而未决的基础性问题。在本节中,我们将阐明这些核心问题,呈现相互对立的观点,并总结每个开放性问题的近期进展。具体而言,我们将讨论以下挑战:
- §4.1 中探讨强化学习的根本作用(锐化 vs. 发现);
- §4.2 中探讨强化学习与监督微调(SFT)的边界(泛化 vs. 记忆);
- §4.3 中探讨模型先验的选择(弱模型 vs. 强模型);
- §4.4 中探讨训练算法的有效性(技巧 vs. 陷阱);
- §4.5 中探讨奖励信号的粒度(过程 vs. 结果)。
通过突出这些开放性问题,我们旨在厘清当前研究格局,并激励学界进一步探索面向大推理模型(LRMs)的强化学习之基础理论根基。
4.1 强化学习的作用:锐化还是发现
我们首先总结当前关于强化学习(RL)作用的两种主流观点:“锐化”(Sharpening)与“发现”(Discovery)。这两种观点看似直接对立。“锐化”观点认为,RL 并不会创造真正新颖的模式,而是对基础模型中已存在的正确响应进行提炼和重新加权。相反,“发现”观点主张,RL 能够发掘基础模型在预训练阶段未曾习得、且通过重复采样也无法生成的全新模式。
“锐化”与“发现”观点之间的分歧可通过多种理论视角加以理解。首先,从 KL 散度优化的角度看,监督微调(SFT)通常优化前向 KL 散度 𝐷𝐾𝐿 ( 𝑝𝑑𝑎𝑡𝑎 || 𝑝𝑚𝑜𝑑𝑒𝑙 ),表现出“模式覆盖”(mode-covering)行为:模型试图覆盖数据分布中的所有模式。而强化学习方法优化的是反向 KL 散度 𝐷𝐾𝐿 ( 𝑝𝑚𝑜𝑑𝑒𝑙 || 𝑝𝑟𝑒𝑤𝑎𝑟𝑑 ),表现出“模式寻求”(mode-seeking)行为:将概率质量集中于高奖励区域 [Ji 等,2024;Sun,2024]。近期的理论进展进一步丰富了这一理解。Xiao 等人 [2025b] 证明,RLHF 可被视为在偏好数据上进行的隐式模仿学习,从而在基于 RL 的对齐与行为克隆之间建立了深层联系。类似地,Sun [2024] 将 SFT 本身视为一种逆强化学习形式,揭示出即使是监督方法也隐含着奖励建模过程。这些观点表明,“锐化 vs. 发现”的争论可能是在探讨统一学习过程的不同方面:RL 的模式寻求特性提供了一种“锐化”机制,而其隐式奖励学习与组合能力则可能通过延长训练实现“发现”。
- 最初,DeepSeek-R1 [Guo 等,2025a] 通过 RLVR 展示了令人鼓舞的“Aha”(顿悟)行为,激发了如 TinyZero [Pan 等,2025c] 等轻量级复现工作,后者在简化训练方案和极少量代码下报告了类似现象。随后出现了领域特定的适配,如 Logic-RL [Xie 等,2025c],其展示了基于规则的 RL 如何培养反思与验证能力,并迁移到数学推理中。
- 然而,《RLVR 的极限》[Yue 等,2025b] 提出了支持“锐化”观点的反驳论据:Pass@K 评估表明,RL 能提升 Pass@1 性能,但在大 k 值下的广义采样中,其表现往往不如基础模型。这表明 RL 主要缩小了搜索空间,而非发掘根本性的新解路径。同时,相关争论质疑所观察到的“Aha”行为究竟是 RL 真正诱导产生,还是预训练阶段已潜藏的能力 [Liu 等,2025t;Setlur 等,2025]。机制分析进一步指出,RL 的增益常源于熵塑形或奖励代理。例如,高熵“分叉”token 似乎主导了性能提升 [Wang 等,2025m];最大化模型置信度(RENT)和 TTRL 可在无需外部奖励的情况下增强推理能力 [Prabhudesai 等,2025;Zuo 等,2025b];甚至虚假或随机奖励信号也能改变 Qwen 模型的行为 [Shao 等,2025],暗示 RL 常只是激活预训练中已存在的推理特征,而非学习全新能力。另一条并行研究路线将测试时搜索与计算视为元 RL 问题,提出 MRT 以稠密化进展信号,相比仅依赖结果的 RL,能更有效地扩展“思考时间”[Qu 等,2025b]。数据效率研究也表明,即使是极端情况如 1-shot RLVR,也能显著提升数学推理能力,再次支持“锐化”观点——即激发潜藏能力 [Wang 等,2025r]。与此互补,一项关于 RLVR 中探索的系统性研究 [Deng 等,2025a] 将 Pass@K 形式化为探索边界的度量,并揭示了训练、实例和 token 层面复杂的熵-性能权衡,从而将“锐化”观点置于统一的分析框架内。近期,Shenfeld 等人 [2025] 提出“RL 的剃刀原则”,证明在线 RL 比监督微调能更好地保留先验知识。他们指出,RL 的优势源于其在适应新任务的同时维持现有能力,而非发现全新的行为。
- 然而,近期若干研究重新打开了“发现”的可能性。ProRL [Liu 等,2025j] 报告称,足够长时间且稳定的 RL 可拓展基础模型的推理边界,同时提升 Pass@1 和 Pass@K 表现。ProRL v2 [Liu 等,2025j] 通过引入工程改进,提供了持续扩展的证据,并取得更强结果。同时,对 Pass@K 指标的批评催生了替代方案,如 CoT-Pass@𝑘,其理论依据是 RLVR 隐式激励正确的推理路径,而非仅奖励偶然正确的终点 [Wen 等,2025c]。互补方法通过自博弈问题合成维持熵并增强 Pass@K [Liang 等,2025c],或通过新颖策略目标直接优化 Pass@K [Chen 等,2025x;Walder 和 Karkhanis,2025],以维持 RLVR 的优势。Yuan 等人 [2025c] 进一步提供了支持“发现”观点的有力证据,证明 LLM 可通过组合现有能力在 RL 中学习新技能,表明 RL 能催生超越简单提炼预存模式的涌现行为。
“锐化”与“发现”之间的表面二分法,或许可通过近期揭示不同对齐范式深层联系的理论进展加以调和。Xiao 等人 [2025b] 的研究表明,RLHF 隐式执行模仿学习;而 Sun [2024] 证明 SFT 可理解为逆强化学习。这些洞见表明,监督方法与 RL 方法均运行于分布匹配与奖励优化的共享理论框架内。关键区别不在于这些方法能否发现新能力,而在于它们如何权衡探索与利用 [Schmied 等,2025]。RL 中反向 KL 的模式寻求特性提供了一种高效收敛至高性能区域的机制(锐化),而其隐式奖励学习与序列决策特性则在给予足够训练时间和适当正则化时,使现有能力组合成新行为(发现)[Liu 等,2025j;Yuan 等,2025c]。这一统一视角表明,争论应从“锐化还是发现”转向理解在何种条件下每种现象占主导地位。
4.2 强化学习 vs. 监督微调:泛化还是记忆
在本小节中,我们讨论强化学习(RL)与监督微调(SFT)的作用,聚焦于泛化与记忆之间的相互作用。当前对大语言模型(LLM)进行后训练主要有两种方法:SFT 和 RL。当前争论集中在两个核心问题上:1)哪种方法更能实现分布外(OOD)泛化?2)通过 SFT 进行的行为克隆是否设定了泛化能力的上限?近期,大量研究聚焦于此议题。尤其值得注意的是,Chu 等人 [2025a] 在文本与视觉环境中均得出直接结论,即“SFT 记忆,RL 泛化”。
近期两项研究进一步强化了这一对比。Huan 等人 [2025] 发现,在数学任务上进行强化学习(RL-on-math)往往能保持甚至提升在非数学任务和指令遵循上的表现,而对数学任务进行监督微调(SFT-on-math)则常导致负迁移和灾难性遗忘。他们基于潜在空间 PCA 和 token 分布(KL 散度)的诊断分析,以及 Mukherjee 等人 [2025] 的研究均表明,SFT 会导致表征和输出漂移(即记忆),而 RL 更好地保留了基础领域结构(即泛化)。与此互补,Zhou 等人 [2025d] 解剖了五种数学解题训练路径,观察到:1)在数学文本上持续预训练仅带来有限迁移;2)传统的短思维链(short-CoT)SFT 常损害泛化能力;但 3)长思维链 SFT 与基于规则的 RL(结合格式/正确性奖励)能拓展推理深度与自我反思能力,从而提升更广泛的推理能力;此外,在 RL 之前进行 SFT 预热可稳定策略,并进一步增强跨领域迁移。这些结果表明,在线策略目标与更长、更具反思性的轨迹能促进在分布偏移下仍保持鲁棒的可迁移模式,而短思维链 SFT 则倾向于对表面模式过拟合——这正映射了 RL 与 SFT 在泛化与记忆之间的经典分野。
当前该议题主要有三个研究方向:
- RL 展现出更优的泛化能力:Chu 等人 [2025a] 表明,RL 在分布外(OOD)性能上优于 SFT,而 SFT 倾向于在 GeneralPoints 和 V-IRL 任务上记忆数据。先前研究 [Kirk 等,2023] 也指出,RLHF(尤其在较大分布偏移下)比 SFT 更能有效泛化,尽管可能以降低输出多样性为代价。此外,DeepSeek-R1 [Guo 等,2025a] 证明,纯 RL 训练可自发涌现出高级推理行为,如反思与验证。
- RL 并非万能药:RL 的泛化能力强烈依赖于初始数据分布和验证奖励的设计。Jin 等人 [2025d] 发现,RL 可部分缓解过拟合,但在严重过拟合或突发分布偏移情况下(如 OOD “24点”游戏和频谱分析任务)仍无效。RL 的核心价值在于促进“恰当学习”[Swamy 等,2025]。当采用适当的重加权、信任域约束或动态重缩放时,SFT 可显著提升泛化能力,且通常能更好地为后续 RL 做准备 [Qin 和 Springenberg,2025]。实践中,SFT 可作为稀疏奖励 RL 的下界。
- SFT 与 RL 的统一或交替范式:Yan 等人 [2025a] 提出一个框架,通过整合离策略推理轨迹来增强 RLVR。Liu 等人 [2025k] 将 SFT 与 RL 融合进单一阶段目标,理论上突破了长视野样本复杂度瓶颈,实证上优于单独使用任一方法。Fu 等人 [2025c] 提出使用熵感知权重,将示范模仿(SFT)与策略改进(RL)在单阶段中联合整合。Zhang 等人 [2025p] 提供理论证据:在小模型、高难度或稀疏成功轨迹场景下,传统“先 SFT 后 RL”的两阶段方法可能完全失效;他们通过从专家锚点出发的分支 rollout 机制有效连接两个阶段。Ma 等人 [2025a] 发现,RL 擅长巩固和增强现有能力,而 SFT 更擅长引入新知识或新模型能力。
然而,若干挑战仍未解决。一大核心问题是如何区分真正的问题解决能力与单纯的答案记忆,同时避免数据污染 [Satvaty 等,2024]。目前仍缺乏标准化、可复现的分布外基准。此外,RL 训练对初始数据分布高度敏感;当 SFT 导致显著表征漂移时,RL 恢复和泛化的能力将受限 [Jin 等,2025d]。为应对这些挑战,需推广如 UFT [Liu 等,2025k]、SRFT [Fu 等,2025c] 和 Interleaved [Ma 等,2025a] 等框架,它们机制化地整合 SFT(用于引入新知识)与 RL(用于能力放大与鲁棒性)。Lv 等人 [2025] 也探索了自动化调度策略,以确定何时在 SFT 与 RL 之间切换以及如何有效分配二者比例。
总之,RL 在可验证任务和显著分布偏移下倾向于实现“真正的泛化”,但它并非万能解药。改进后的 SFT 有助于弥补泛化能力的剩余缺口。因此,最佳实践正逐步收敛于统一或交替的混合范式,以结合两种方法的优势 [Chen 等,2025c,h;Liu 等,2025k;Lv 等,2025;Wu 等,2025i;Zhu 等,2025e]。
4.3 模型先验:弱先验与强先验
近期研究表明,当与足够强大的模型先验和可验证的奖励信号相结合时,强化学习(RL)现已能在广泛任务中表现优异,从而将主要瓶颈从“规模”转向“环境设计与评估协议”⁴。从这一视角看,RL 的主要作用是重新锐化预训练阶段已编码的潜在能力,而非从零开始生成全新能力。
在本小节中,我们从三个关键维度考察这种依赖性:将 RL 应用于基础模型与指令微调模型的相对优势;不同模型家族(特别是 Qwen 与 Llama 架构)在 RL 响应性上的显著差异;以及针对弱先验与强先验模型提升 RL 效果的新兴策略,包括中期训练(mid-training)与课程设计。
基础模型 vs. 指令微调模型。DeepSeek-R1 首次探讨了将 RL 应用于基础模型或指令微调模型的问题,并提出了两种可行的后训练范式:1)R1-Zero,直接对基础模型应用大规模基于规则的 RL,从而涌现出长视野推理能力;2)R1,在 RL 之前引入短暂的冷启动 SFT 阶段,以稳定输出格式与可读性。独立地,Open-Reasoner-Zero [Hu 等,2025b] 证明,对基础 Qwen 模型采用极简训练方案,足以同时扩展响应长度与基准测试准确率,其训练动态与 R1-Zero 相似。这些发现表明,基础模型的先验更适合 RL,通常比从高度对齐的指令模型出发时获得更平滑的性能提升轨迹——因为后者根深蒂固的格式与服从先验可能干扰奖励塑形。
模型家族差异。更近期的研究强调,基础模型的选择会关键性地塑造 RL 结果。例如,One-shot RLVR [Wang 等,2025r] 显示,仅引入一个精心挑选的数学示例,即可使 Qwen2.5-Math-1.5B 在 MATH500 上的准确率提升一倍以上,并在多个基准上实现显著平均提升。然而,《虚假奖励》[Shao 等,2025] 揭示了相反的模式:Qwen 系列模型即使在随机或虚假奖励信号下也能获得显著增益,而 Llama 与 OLMo 模型则往往无此表现。这一差异凸显了模型先验的影响,并强调需在具有不同先验的模型上验证 RL 主张。观察到的不对称性表明,不同模型在预训练阶段对推理模式(如数学或代码思维链)的接触程度存在差异。Qwen 模型因广泛接触此类分布,往往更“RL 友好”;而同等规模的 Llama 模型在相同 RLVR 流程下常表现出脆弱性。
中期训练解决方案。实践中,研究人员发现可通过中期训练或退火训练策略弥合这一性能差距。在近期 LLM 研究中,“退火”指预训练后期阶段,此时学习率衰减,同时数据分布被重新加权,以强调小规模、高质量来源(如代码、数学和精选问答语料)。Llama 3 [Grattafiori 等,2024] 明确将此阶段命名为“退火数据”,描述了数据混合的变化及学习率线性衰减至零的过程。他们进一步报告,在此阶段注入少量高质量数学与代码数据,可显著提升面向推理的基准表现。更早前,MiniCPM [Hu 等,2024b] 提出了类似的两阶段课程,称为“稳定后衰减”。在衰减(退火)阶段,他们将 SFT 式高质量知识与技能数据与标准预训练语料交错混合,观察到的提升幅度大于仅在预训练后应用相同 SFT。类似地,OLMo 2 [OLMo 等,2024] 公开了现代中期训练方案:预训练分为长期、以网络数据为主的阶段,随后是较短的中期训练阶段,该阶段对高质量和领域特定来源(尤其是数学)进行上采样,同时线性将学习率衰减至零。更广泛地,当代中期训练策略将学习率调度与数据分布切换的联合设计视为首要关注点。例如,Parmar 等人 [2024] 表明,最优的持续预训练需要:1)两阶段分布课程,在后期阶段强调目标能力;2)退火式、非再升温的学习率调度,其中分布切换时机由学习率比例而非固定 token 数决定。近期一项系统性研究扩展了这一工作,证明采用“稳定后衰减”的中期训练课程(注入高质量数学与思维链问答语料),可使 Llama 模型在基于 RL 的微调下显著提升可扩展性,有效缩小与 Qwen 模型的性能差距 [Wang 等,2025u]。
综合来看,这些发现为弱先验模型家族提供了一个实用方案:通过中期训练强化推理先验,随后应用 RLVR。
强模型的改进。尽管许多复现研究倾向于基础模型,但越来越多证据表明,当课程、验证与长度控制被精心设计时,RL 仍可进一步提升强蒸馏/指令模型。例如,AceReason-Nemotron [Chen 等,2025q] 报告称,在蒸馏后的 Qwen 模型上采用“先数学后纯代码”的 RL 策略,可实现持续增益,分析显示其在 Pass@1 与 Pass@K 指标上均有提升。这些发现细化了“仅基础模型”的简化叙事:在适当约束下,指令/蒸馏起点模型也能受益,但优化过程更不容出错。另一条并行研究路线评估了推理模型的可控性。MathIF [Fu 等,2025a] 强调了一个系统性矛盾:扩展推理能力常会削弱指令遵循表现,尤其在长篇输出场景下。补充证据表明,显式思维链提示会降低指令遵循准确性,并提出了选择性推理缓解方案 [Li 等,2025l]。这些工作共同推动在 RL 中将多目标训练(格式、简洁性、服从性)与正确性/可验证性相结合。
我们可以从三个视角总结模型先验如何根本性地塑造 LLM 训练中的 RL 结果:1)基础模型作为 RL 起点始终优于指令微调模型,DeepSeek-R1 与 Open-Reasoner-Zero 均通过极简方案展示了涌现推理能力;2)不同模型家族表现出不对称的 RL 响应性:Qwen 模型即使在虚假奖励下也能获益,而 Llama/OLMo 模型则需通过退火学习率与高质量数学/代码数据注入进行精细中期训练;3)强蒸馏模型也能从 RL 中受益,但需要更复杂的课程设计与多目标优化。
随着 RL 越来越多地用于重新锐化潜在的预训练能力而非创造全新能力,研究焦点正转向整体优化“预训练→RL”流水线,而非将这些阶段独立对待。
4.4 训练方案:技巧还是陷阱
大规模模型的强化学习训练主要从 PPO 系列算法 [Schulman 等,2017b] 演化而来,通过多种工程技术维持训练稳定性 [Huang 等,2022],例如裁剪、基线校正、归一化和 KL 正则化。在面向 LLM 推理的强化学习背景下,DeepSeek-Math 与 DeepSeek-R1 引入了无评论家的 GRPO 算法 [Shao 等,2024],通过降低复杂度简化了训练流程。尽管取得这些进展,训练稳定性与效率方面的挑战依然存在,推动了一系列新方法的发展,包括动态采样、多种重要性采样比率和多层次归一化。
一种被广泛采用以增强探索的技术是“解耦 PPO 裁剪”(“Clip-Higher”),即上裁剪边界设置得高于下边界(例如 𝜖low = 0.2, 𝜖high = 0.28),以允许低概率但潜在有用的 token 概率更自由地上升 [An 等,2025;Liu 等,2025j;Yu 等,2025d]。Archer [Wang 等,2025i] 提出了针对不同熵水平 token 的双裁剪机制,而 Archer2.0 [Wang 等,2025h] 进一步对具有相反优势值的 token 采用非对称双裁剪。
- 数据与采样中的极简主义:Xiong 等人 [2025a] 对 GRPO 进行分解,发现最大性能提升来源于直接丢弃所有错误样本,而非依赖复杂的奖励归一化技术。他们提出,像 RAFT [Dong 等,2023] 或 “Reinforce-Rej” [Liu 等,2023a] 这样的方法,使用更简单的机制即可实现与 GRPO/PPO 相当的稳定性与 KL 效率。DAPO [Yu 等,2025d] 将“动态采样 + 解耦剪枝”系统化为可复现的大规模方法,并结合“Clip-Higher”策略(上裁剪边界高于下边界,如 𝜖low = 0.2, 𝜖high = 0.28),允许低概率但可能有用的 token 更自由增长,在 AIME24 基准的强基线模型上取得了最先进结果。类似地,GRESO [Zheng 等,2025b] 表明,预过滤可将 rollout 时间加速 2.4 倍,整体训练加速 2.0 倍,同时性能损失极小。
- 目标函数的结构化修改:GSPO [Zheng 等,2025a] 将比率与裁剪操作移至序列级别,相比 GRPO 在稳定性与效率上均有提升,尤其适用于专家混合模型(MoE)的稳定 RL 训练。S-GRPO [Dai 等,2025a] 进一步减少冗余推理,缓解了生成更长且不必要推理链的倾向,在多个基准上将序列长度缩短 35–61%,同时精度略有提升。
- 去偏与归一化之间的挣扎:Dr. GRPO [Liu 等,2025u] 指出 GRPO 中的一个关键偏差——“错得越久,错得越深”,并引入轻微算法修改以提升 token 效率。与此同时,其他研究(如 BNPO [Xiao 等,2025a])从自适应分布视角重新审视奖励归一化的重要性,提出了新的归一化族。这两派的证据相互矛盾,表明将归一化视为通用解决方案可能是误导性的。
Liu 等人 [2025w] 最近发表了一篇综述,采用统一评估框架,将常用技术整合进单一开源框架 [Wang 等,2025n],以支持隔离式、可复现的实验。该工作提供了一份路线图,阐明“哪些技术在何种设置下有效”,并证明极简方法组合可在多种配置下超越 GRPO 与 DAPO。更重要的是,它突出了当前领域最紧迫的挑战:实验设置不一致、报告不完整、结论相互冲突。这构成了当前研究社区应用 RL 的根本性局限。总而言之,尽管实用“技巧”对稳定 RL 训练至关重要,但“科学化训练”的本质在于可验证性与可扩展性。领域进步需要统一的实验协议、可验证的奖励结构,以及明确的可扩展性–性能–成本曲线 [Nimmaturi 等,2025],以证明某方法在扩展时仍保持有效,而非仅在特定数据或模型上有效。
4.5 奖励类型:过程奖励 vs. 结果奖励
在标准强化学习中,策略的目标是最大化期望累积奖励 [Sutton 等,1998]。“奖励即足够”(Reward is Enough)假说 [Bowling 等,2023;Silver 等,2021] 进一步提出,只要奖励设计得当,最大化回报原则上足以催生智能的所有方面。在面向大语言模型(LLM)的强化学习背景下,核心挑战在于如何提供有意义的奖励——例如训练奖励模型或验证器对输出进行评分,并将这些评分用于强化学习或搜索。常见方法包括:
- 结果奖励:仅评估最终结果(如答案正确性或通过单个测试);
- 过程奖励:通过对中间步骤提供稠密反馈,实现逐步评分 [Lightman 等,2024]。
- 如 §3.1.1 所示,当任务答案可验证时,结果奖励是应对复杂数学与编程任务最简单且最具可扩展性的方法。然而,仅依赖结果的方法可能隐性鼓励不忠实的思维链(chain-of-thought)[Arcuschin 等,2025],例如“先写答案,后编过程”,或奖励投机行为。近期研究 [Baker 等,2025] 指出,当前最先进的模型在现实场景中同样表现出不忠实推理和事后合理化现象。其他研究也强调,基于规则的 RL 容易引发奖励作弊和“推理幻觉”[Sun 等,2025h]。
- 过程奖励模型(PRMs)[Zhang 等,2025f] 天然有利于长链信用分配。Lightman 等人 [2024] 明确比较了两种奖励方式:在数学推理任务中,接受过程监督训练的 PRMs 更稳定、更可靠,显著优于仅接受结果监督的模型。然而,步骤级标注成本极高,且在不同领域间质量常显著下降 [Zhang 等,2025u]。相关研究表明,基于启发式或蒙特卡洛的合成方法往往泛化能力差,并引入偏差 [Yin 等,2025]。
总体而言,结果奖励提供“通过自动化验证实现可扩展的目标对齐”,而过程奖励则提供“可解释的稠密引导”。将二者结合——例如通过隐式过程建模 [Cui 等,2025a] 或生成式验证器 [Zhang 等,2024a]——可能代表奖励设计领域一个有前景的未来方向。
原文链接:https://arxiv.org/pdf/2509.08827
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号