元强化学习教程 A Tutorial on Meta-Reinforcement Learning(1-3章)

元强化学习教程 A Tutorial on Meta-Reinforcement Learning(1-3章)

CreateAMind
发布于 2026-03-11 17:40:58
发布于 2026-03-11 17:40:58
元强化学习教程 A Tutorial on Meta-Reinforcement Learning
https://www.scribd.com/document/888094737/2301-08028v4



摘要 尽管深度强化学习(RL)已在机器学习领域推动了多项备受瞩目的成功案例,但其较差的数据效率以及所生成策略的泛化能力有限,阻碍了其更广泛的应用。缓解这些局限性的一个有前景的方法是将开发更优的强化学习算法本身视为一个机器学习问题,这一过程被称为元强化学习(meta-RL)。元强化学习最常在如下问题设定中被研究:给定一个任务分布,目标是学习一个策略,使其能够以尽可能少的数据快速适应该分布中的任何新任务。在本综述中,我们将详细描述元强化学习的问题设定及其主要变体。我们讨论如何从宏观层面,根据是否存在任务分布以及每个独立任务可用的学习预算,对元强化学习研究进行分类。基于这些类别,我们进一步综述了元强化学习的算法与应用。最后,我们提出了实现元强化学习成为深度强化学习从业者标准工具箱组成部分之路上尚待解决的开放性问题。
1 引言
元强化学习(meta-RL)指的是一类机器学习(ML)方法,其目标是“学会如何进行强化学习”。也就是说,meta-RL 方法利用样本效率较低的机器学习技术,来学习出样本效率更高的强化学习算法或其组成部分。因此,meta-RL 是元学习(meta-learning)的一个特例(Vanschoren, 2018;Hospedales 等,2020;Huisman 等,2021),其特点是所学到的算法是一种强化学习算法。
meta-RL 作为一种机器学习问题已被研究了相当长的时间(Schmidhuber, 1987;Schmidhuber 等,1997;Thrun 和 Pratt, 1998;Schmidhuber, 2007)。有趣的是,研究还发现大脑中存在与 meta-RL 类似的机制(Wang 等,2018)。
meta-RL 有潜力克服现有人工设计的强化学习算法的一些局限性。尽管过去几年深度强化学习取得了显著进展,并在多个领域取得成功案例,例如掌握围棋游戏(Silver 等,2016)、平流层气球导航(Bellemare 等,2020),或机器人在复杂地形中的运动控制(Miki 等,2022),但强化学习仍然高度依赖大量样本,这限制了其在现实世界中的应用。而 meta-RL 能够生成比现有方法样本效率高得多的(部分)强化学习算法,甚至能为先前难以解决的问题提供解决方案。
与此同时,样本效率提升的前景也伴随着两个代价。首先,元学习比标准学习需要显著更多的数据,因为它训练的是一个完整的“学习算法”(通常跨越多个任务)。其次,元学习是根据元训练数据拟合出一个学习算法,这可能会削弱其对其他数据的泛化能力。因此,元学习提供的是一种权衡:在测试阶段获得更高的样本效率,代价是训练阶段样本效率较低,以及测试阶段泛化能力可能受限。
示例应用:作为一个概念性例子,考虑用机器人厨师实现自动化烹饪的任务。当这样的机器人被部署到某人的厨房中时,它必须学习一个特定于该厨房的策略,因为每个厨房的布局和电器配置都不同。这一挑战进一步加剧,因为并非所有烹饪所需的物品都一目了然:锅具可能藏在橱柜里,香料可能放在高处的架子上,餐具可能隐藏在抽屉中。因此,机器人不仅需要理解整体布局,还需在发现特定物品后记住其位置。在新厨房中从零开始直接训练机器人过于耗时,且由于训练初期的随机行为可能带来安全隐患。一种替代方案是在单一训练厨房中对机器人进行预训练,然后在新厨房中进行微调。然而,这种方法并未考虑后续的微调过程。相比之下,元强化学习(meta-RL)会在一组训练厨房的分布上训练机器人,使其能够适应该分布中的任意新厨房。这可能包括学习某些参数以实现更好的微调,或直接学习将在新厨房中部署的完整强化学习算法。以这种方式训练的机器人不仅能更高效地利用所收集的数据,还能主动收集更高质量的数据——例如,专注于新厨房中不寻常或具有挑战性的特征。这种元学习过程比简单的微调方法需要更多样本,但只需执行一次,而由此产生的适应过程在部署到新测试厨房时可显著提高样本效率。
这个例子说明,一般来说,当需要频繁进行高效适应时,元强化学习可能特别有用,因为元训练的成本相对较小。这包括但不限于安全关键型强化学习领域,在这些领域中,高效的数据收集至关重要,而探索新行为的成本过高或具有危险性。在许多情况下,前期投入大量低样本效率的学习(例如在监督下、实验室环境或仿真环境中)是值得的,因为它能带来后续更优的适应能力。该例子代表了元强化学习的理想化应用场景。在实践中,元强化学习目前应用于更有限的机器人任务,例如机器人操作(Akkaya 等,2019;Zhao 等,2022b)和机器人运动控制(Song 等,2020b)。
综述范围:本综述聚焦于机器学习领域的元强化学习主题,不包含神经科学等其他领域中关于元强化学习的研究。与元强化学习密切相关的机器学习主题将在第2.6节中讨论。为全面反映机器学习领域内元强化学习研究的广度与深度,我们调研了2017年至2022年间多个主要机器学习会议的论文集,以及相关专题研讨会的成果。我们发现,元强化学习文献的大部分内容出现在2016年之后,且绝大多数贡献集中在三个会议:NeurIPS、ICML 和 ICLR。完整的会议和研讨会列表请见附录A。尽管本综述主要强调这些会议及指定时间段内的成果,我们也讨论了部分范围外的相关论文。从这些会议和研讨会的论文集中,我们检索了明确提及“元强化学习”的论文,以及虽未明确提及但我们判断仍符合该主题的论文。最后,我们并不声称本综述覆盖了调研范围内所有元强化学习研究,而是旨在提供一个对最核心思想和总体研究方向的全面概览。
综述概览:本综述旨在为读者提供进入元强化学习领域的切入点,同时反思该领域的当前状态与开放研究方向。第2节中,我们将定义元强化学习及其可应用的不同问题设定,并介绍两个示例算法。第3节将探讨元强化学习中最主流的问题设定:小样本元强化学习(few-shot meta-RL)。在此设定中,目标是学习一种能够快速适应的强化学习算法,即仅需少数几个回合(episodes)即可学会一个任务。
这些算法通常在给定的任务分布上进行训练,并通过元学习掌握如何高效适应该分布中的任意任务。图1.1展示了一个说明该设定的简化示例:一个智能体经过元训练,学会如何在二维平面上导航至不同的(初始未知的)目标位置。在元测试阶段,该智能体能够高效适应具有未知目标位置的新任务。

在第4节中,我们探讨“多样本”(many-shot)设定。该设定的目标是学习通用型强化学习算法,而非局限于狭窄任务分布的算法——类似于当前实践中所使用的算法。这一设定有两种形式:一种如上所述,在任务分布上进行训练;另一种则是在单一任务上训练,同时在标准强化学习训练过程中进行元学习。
接下来,第5节介绍元强化学习的一些应用场景,例如机器人领域。作为综述的总结,我们在第6节讨论当前的开放性问题。这些问题包括:小样本元强化学习中如何泛化到更广泛的任务分布、多样本元强化学习中的优化挑战,以及如何降低元训练成本。
为对本综述所引用的元强化学习研究提供高层次概览,我们在每一节内均附有一个汇总表格,收集该节讨论的代表性论文。
2 背景
元强化学习(Meta-RL)可以广义地描述为学习强化学习算法的部分或全部。在本节中,我们将对元强化学习进行定义和形式化。为此,我们首先从定义强化学习(RL)开始。

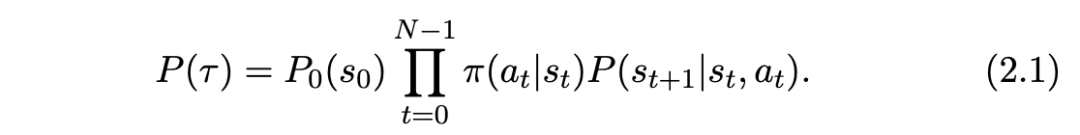

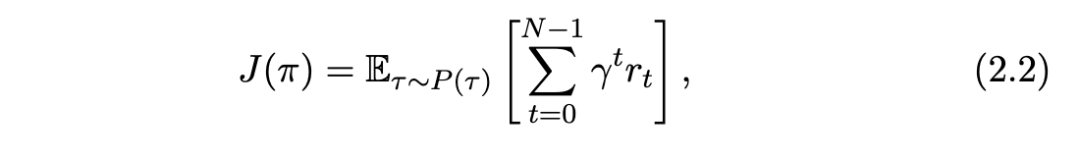

2.2 元强化学习(Meta-RL)定义
传统的强化学习(RL)算法是由人类设计、工程化和测试的。元强化学习(meta-RL)的想法是使用机器学习来学习算法 f 的(部分)内容。RL学习一个策略,而元强化学习学习输出策略的RL算法 f。这并没有完全消除过程中的人类努力,而是将其从直接设计和实现RL算法转变为以数据驱动的方式开发训练环境和参数化,以学习它们的一部分。

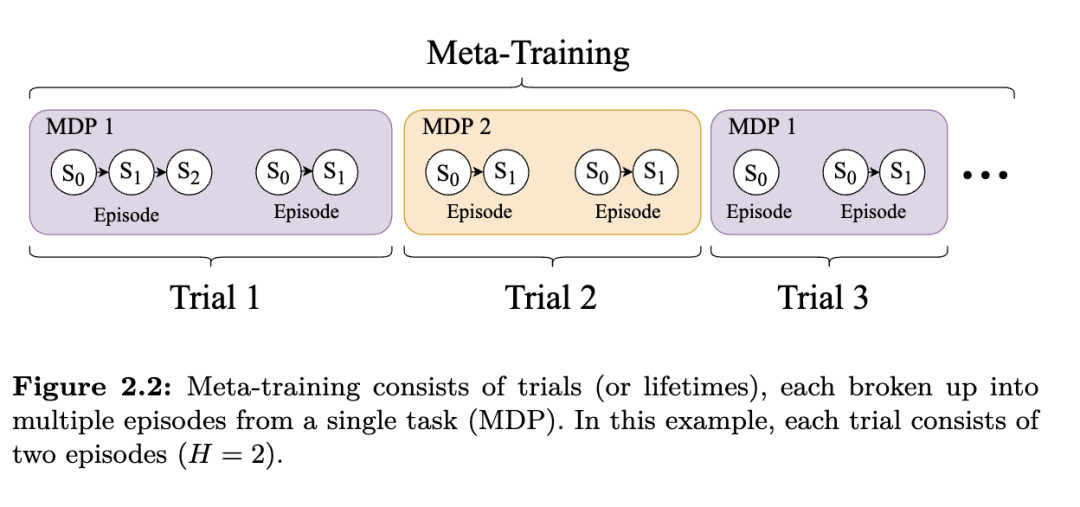

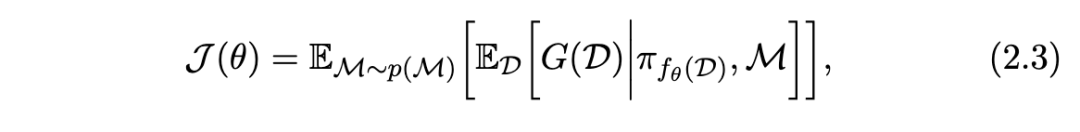

2.3 POMDP 形式化


其次,这一视角使我们能够与贝叶斯强化学习(Bayesian RL)建立联系(Duff and Barto, 2002; Ghadirzadeh et al., 2021)。具体而言,贝叶斯强化学习通过显式维护任务的后验分布,并使用贝叶斯推断进行更新,来求解该 POMDP。贝叶斯框架提供了一种方便的方法,用于整合先验知识并显式地维持不确定性。利用该框架,可以构建一个新的 MDP,其状态包含 POMDP 隐藏状态的后验分布,或等价地,包含 MDP 状态和任务的后验分布。这种 MDP 被称为贝叶斯自适应马尔可夫决策过程(Bayes-adaptive Markov decision process, BAMDP)。这种构造允许学习一个马尔可夫策略来解决元强化学习问题,从而实现最优探索。BAMDP 和贝叶斯最优策略将在第 3.5 节中讨论。然而,由于贝叶斯强化学习方法必须显式建模并更新 MDP 上的分布,因此仅在简单领域且无强近似的情况下才具有可处理性。例如,即使可扩展的贝叶斯强化学习方法也可能局限于离散状态空间的 MDP(Guez et al., 2013)。相比之下,元强化学习方法无需人为设计贝叶斯后验的近似,而是可以学习如何根据需要建模这些组件。例如,大多数元强化学习方法只需对先验有采样访问权限,而不需要显式知道先验。元强化学习智能体可以从样本中隐式地学习任务先验的模型。
最后,尽管元强化学习通常考虑的是 MDP 上的分布,但也可以考虑 POMDP 上的分布。在这种情况下,每个任务本身也是部分可观测的。这构成了另一种类型的 POMDP,称为元-POMDP(meta-POMDP)(Akuzawa et al., 2021)。元-POMDP 可以写成一个 POMDP,其中隐藏状态的一部分在整个试验过程中保持不变,且可以对现有方法进行调整以适应这种结构(Akuzawa et al., 2021)。
2.4 示例算法
我们现在介绍两种经典的元强化学习(meta-RL)算法,它们优化由公式 2.3 给出的目标:模型无关的元学习(Model-Agnostic Meta-Learning, MAML),该方法使用元梯度(Finn et al., 2017a);以及通过慢速强化学习实现快速强化学习(Fast RL via Slow RL, RL²),该方法采用依赖历史的策略(Duan et al., 2016b; Wang et al., 2016)。许多元强化学习算法都基于与 MAML 和 RL² 类似的概念和技术,因此它们是进入元强化学习领域的极佳切入点。


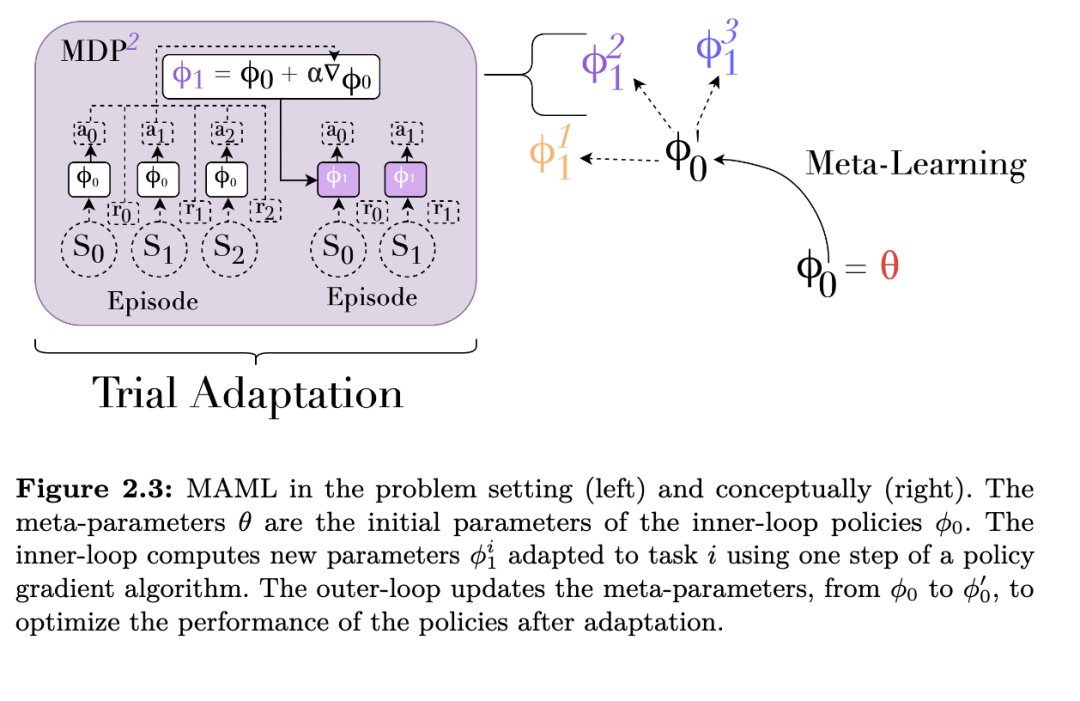


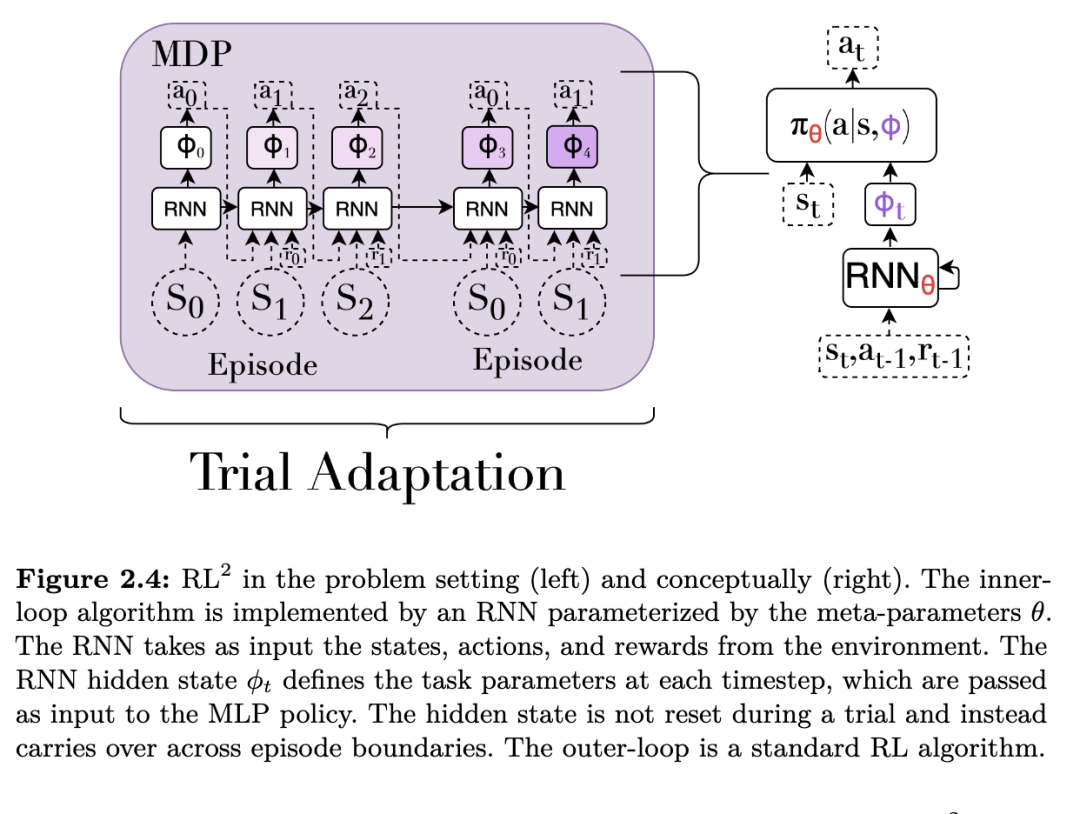
这两种不同的元强化学习方法——MAML 和 RL²——各自具有独特的优势与劣势。一方面,MAML 的内层循环采用通用的策略梯度算法,在特定条件下,它能够从初始状态开始,为任意给定任务(包括任务分布之外的任务)学习策略。另一方面,RL² 直接近似由公式 2.3 所定义的元强化学习目标的最优策略。这种策略被称为贝叶斯最优策略(Bayes-optimal policy),将在第 3.5 节中进一步讨论。贝叶斯最优策略总是在对 MDP 身份存在不确定性的情况下选择能最大化期望回报的动作;而依赖策略梯度的 MAML 只有在内层循环中收集完整个 episode 后才能进行参数更新。然而,RL² 的一个缺点是,当在任务分布之外的任务上进行测试时,它面临严峻的泛化问题。在狭窄任务分布上进行的端到端强化学习训练,可能无法产生在分布外任务上具有良好泛化能力的策略。
2.5 问题类别
尽管上述问题设定适用于所有元强化学习(meta-RL)研究,但文献中已根据两个维度形成了不同的聚类:任务时间跨度 H是短(仅几个 episode)还是长(数百个 episode 或更多),以及任务分布 p(M)是否包含多个任务或仅包含单个任务。这形成了四类问题,其中三类已产生了实用的算法,如表 2.1 所示。我们在图 2.5 中展示了这些类别之间的差异。

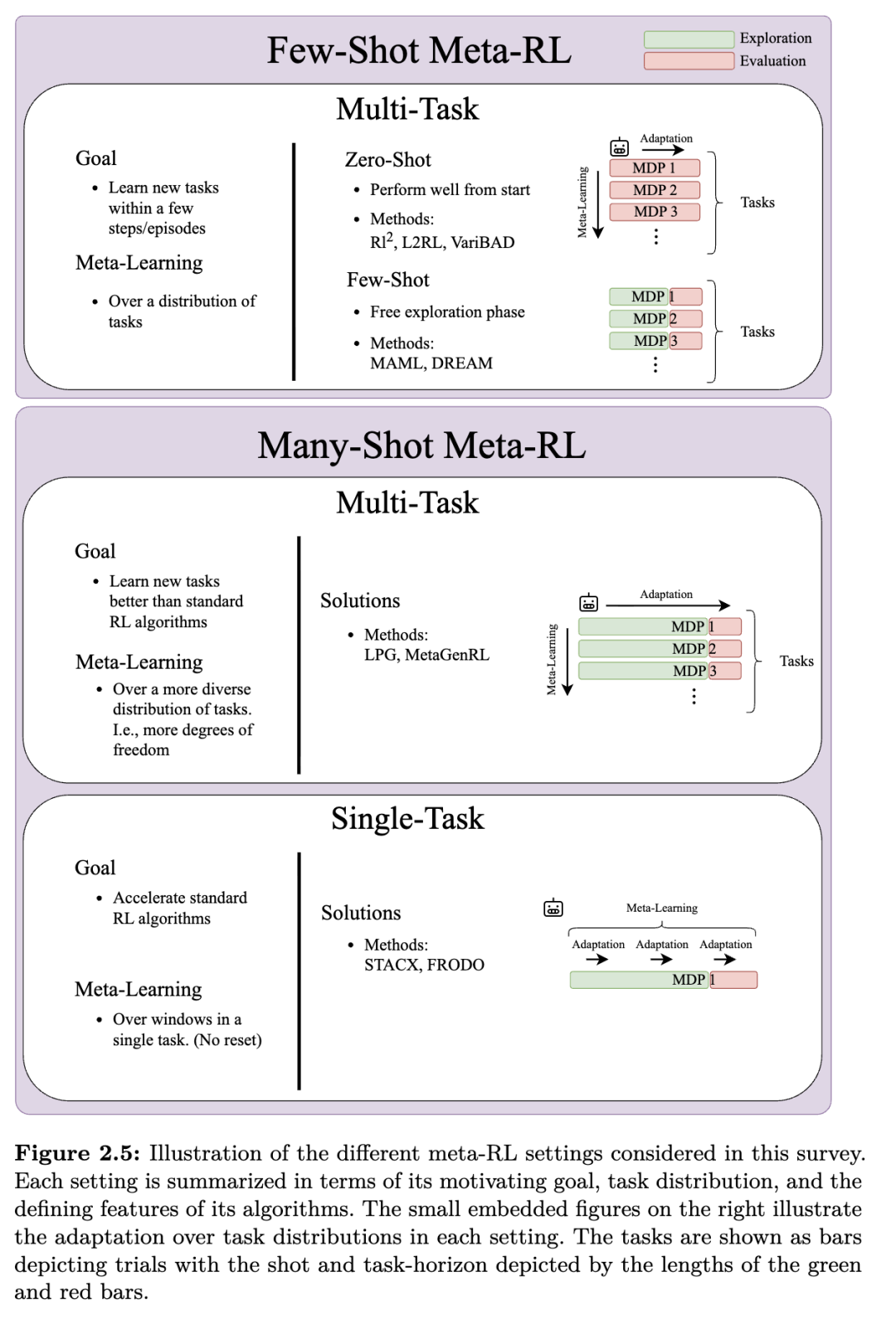
表2.1中的第一个聚类是“小样本多任务设定”(few-shot multi-task setting)。在此设定中,智能体必须在仅经历少数几个episode内,快速适应从其训练任务分布中采样的一个新MDP。这一要求体现了元强化学习的核心思想:我们希望利用任务分布来训练智能体,使其能够以尽可能少的环境交互次数,学会该分布中的新任务。“小样本”(few-shot)这一名称借用了小样本分类(few-shot classification)中的术语(Vinyals 等,2016;Snell 等,2017;Finn 等,2017a),在小样本分类中,模型仅凭每个类别中的少量样本即可学会识别新类别。在元强化学习中,探索episode的数量 K在某种程度上类比于分类中的“样本数(shots)”。该设定将在第3节中详细讨论。
虽然小样本适应直接回应了元强化学习的核心动机问题,但有时智能体所面临的适应问题过于困难,以至于在少量episode内取得成功是不现实的。例如,当适应的任务不在训练任务分布的支持集内时,就可能出现这种情况。在这种情况下,内层循环可能需要数千个甚至更多episode才能为新任务生成一个良好的策略,但我们仍希望通过元学习使内层循环尽可能数据高效。我们将在第4节讨论这种“多样本多任务设定”(many-shot multi-task setting)。
元强化学习主要关注多任务设定,在该设定中,内层循环可以利用任务之间的相似性,学习出更数据高效的任务适应过程。相比之下,在标准强化学习中,智能体通常被训练用于解决单个复杂任务,且需要经历大量优化步骤。由于这种方式往往数据效率极低,研究人员开始探索:即使没有相关任务分布的访问权限,元学习方法是否仍能提升效率?在这种情况下,效率提升必须来源于智能体在其单一生命周期内的知识迁移,或在训练过程中对本地训练条件的适应。针对“多样本单任务设定”(many-shot single-task setting)的方法通常与多样本多任务设定中的方法相似,因此也在第4节中一并讨论。
第四个聚类是“小样本单任务设定”(few-shot single-task setting),在该设定中,一个假想的元学习器需在没有其他相关任务迁移的情况下,在少数几个episode内加速单个任务的学习。然而,由于智能体的生命周期过短,内层循环不太可能有足够时间学习出一个数据高效的任务适应过程并据此生成策略。因此,据我们所知,目前尚无研究专门针对这一设定。
2.6 相关工作
相关领域本综述的目标是介绍、总结并突出元强化学习(meta-RL)领域的研究成果。目前已有一些综述文献(Thrun 和 Pratt, 1998;Hospedales 等, 2020;Wang 等, 2020b;Parker-Holder 等, 2022;Kirk 等, 2023)涵盖了部分元强化学习方法,但它们在几个关键方面有所不同。Thrun 和 Pratt(1998)以及 Hospedales 等(2020)虽然都包含元强化学习方法,但更侧重于广义的元学习,包括元监督学习(meta-supervised learning)。Wang 等(2020b)综述的是小样本学习(few-shot learning)方法,但元强化学习的范畴比小样本学习更广,因为元强化学习不仅包含多样本问题,且在小样本设定下还需要依赖任务分布进行学习。Parker-Holder 等(2022)综述的是自动强化学习(AutoRL)方法,但也包含非学习型算法用于适应新MDP。Kirk 等(2023)综述的是强化学习中的泛化方法,其中包括元强化学习方法,但也涵盖非学习型算法以及无需适应的问题——即单一策略无需针对特定任务定制即可达到最优性能的问题。在所有相关机器学习领域中,元监督学习(meta-SL)和多任务强化学习(multi-task RL)与元强化学习关系最为密切。
元监督学习 元强化学习与元监督学习研究之间存在诸多相似之处。与元强化学习类似,元监督学习也考虑任务分布。但不同的是,元强化学习中的任务由马尔可夫决策过程(MDP)定义,而元监督学习中的任务由固定数据集定义。一些算法曾被同时提出用于元监督学习和元强化学习(Finn 等, 2017a;Mishra 等, 2018)。此外,许多算法设计选择在这两个设定中均有对应形式。例如,在小样本设定中,元强化学习中对先前状态使用注意力机制的方法(Ritter 等, 2018a;Fortunato 等, 2019;Team 等, 2023),与元监督学习中基于核函数的方法(Santoro 等, 2016;Vinyals 等, 2016;Sung 等, 2018)相对应。这些方法将在第3.3节中进一步讨论。此外,在多样本设定中,优化器和目标函数的元学习在元强化学习(Houthooft 等, 2018;Kirsch 等, 2019;Oh 等, 2020;Bechtle 等, 2021;Lu 等, 2022a;Lan 等, 2023)和元监督学习(Andrychowicz 等, 2016;Li 和 Malik, 2017;Bechtle 等, 2021)中均有研究,相关内容将在第4.3节中介绍。最后,模仿学习(imitation learning)通常被视为与强化学习密切相关的研究方向,因为二者均处理序列决策问题。因此,我们将在第3.6节中讨论用于模仿学习的元监督学习。
除了问题设定和方法上的相似性,元强化学习与元监督学习也存在一些关键差异。尤其值得注意的是,元监督学习通常处理固定数据集,而元强化学习则不然。在元强化学习中,经过适应的策略需要主动收集更多数据,并将这些数据反馈回数据集以支持进一步适应。这就引入了一个“为适应特定任务而收集数据”的问题。此外,由于元强化学习智能体必须快速适应,因此它也必须快速探索。快速探索及其带来的挑战是元强化学习独有的特性,也是第3节中重点讨论的核心主题。
多任务强化学习多任务强化学习与元强化学习一样,也考虑MDP的分布。然而,元强化学习智能体必须自行识别所遇到的MDP,而在多任务强化学习中,智能体可以直接访问任务的真实表示(ground-truth representation)。虽然部分多任务强化学习的解决方案(如PopArt,Hessel 等, 2019)可直接应用于元强化学习(Grigsby 等, 2024),但评估方式的差异也使得某些方法无法直接迁移。例如,多任务强化学习通常在有限的离散任务集合上进行评估,而元强化学习智能体在测试阶段常常会遇到全新任务(Yu 等, 2020a;Teh 等, 2017)。这使得多任务方法可以为每个任务训练独立的网络(Teh 等, 2017),而此类方法在元强化学习中无法直接适用。
总体而言,多任务强化学习可被视为元强化学习的一个“简化版本”,因为MDP的表示已知,因此无需从数据中学习该表示,也无需为适应而进行探索。事实上,有一整类元强化学习方法正是试图显式推断MDP身份,从而将元强化学习问题简化为更易处理的多任务强化学习问题——相关内容将在第3.3节中讨论。然而,也存在元强化学习可行而多任务强化学习不可行的情况。由于多任务强化学习中的泛化不依赖测试时的数据条件,因此其泛化始终属于“零样本泛化”(zero-shot generalization)。在实践中,若任务表示信息不足,这种泛化可能无法实现。例如,若任务以独热编码(one-hot categorical vector)表示,则可能完全无法泛化到训练中未见过的类别。但在这种情况下,元学习仍可能有效——只要能从数据中推断出更具信息量的任务表示,或通过测试阶段的额外学习来弥补训练分布的稀疏性。
3 Few-shot Meta-RL
在本节中,我们将讨论“小样本适应”(few-shot adaptation),即智能体在多个任务上进行元学习,并在元测试阶段必须在极少数时间步或episode内快速适应一个新但相关的任务。
举一个具体例子,回顾机器人厨师学习在家庭厨房中烹饪的场景。如果为每个用户的家庭厨房从零开始用强化学习训练一个新策略,将需要在每个厨房中收集大量样本,这会造成浪费,因为通用的烹饪知识(例如如何使用炉灶)在不同厨房之间是可以迁移的。在客户购买的机器人进入其家中时浪费大量数据样本可能是不可接受的,尤其是当机器人的每一个动作都有可能损坏厨房时。元强化学习(meta-RL)可以从数据中自动学习一种适应程序,以应对新厨房中出现的差异(例如餐具的位置)。在元训练阶段,机器人可以在仿真环境或有人类监督和安全措施的环境中,在多个不同厨房中进行训练。然后,在元测试阶段,机器人被售予客户并部署到一个新厨房中,它必须快速学会在该厨房中烹饪。然而,使用 meta-RL 训练这样的智能体涉及独特的挑战和设计选择。
具体而言,我们从以下几个维度对现有文献进行总结:内层循环(inner-loop)的设计、探索(exploration)机制、监督信号(supervision)的形式,以及强化学习算法是基于模型(model-based)还是无模型(model-free)。我们首先按内层循环的类型对方法进行分类,因为大多数研究都聚焦于不同的内层循环参数化方式。我们关注探索机制,因为与元监督学习(meta-SL)相比,学习如何探索是元强化学习独有的挑战(如第2.6节所述)。我们根据可用的监督信号,对使用模仿学习或其他形式监督信号的密切相关问题设定进行分类。最后,我们综述基于模型的元强化学习方法,因为它们与无模型方法存在不同的权衡。不过,我们仅简要讨论基于模型的方法,因为大多数元学习文献集中于无模型设定。


尽管上述每一类代表了一个离散的研究聚类,但其他作者可能采用不同的分类方式,或使用不同的名称指代这些聚类。例如,参数化策略梯度方法有时被称为“基于梯度的方法”(gradient-based methods,Finn 等, 2017a;Rakelly 等, 2019),或被归入元监督学习中更大的“基于优化的方法”(optimization-based methods,Hospedales 等, 2020)类别。此外,黑箱方法和任务推断方法有时被统称为“基于上下文的方法”(context-based methods,Rakelly 等, 2019)。
除了内层循环的参数化设计,相关的设计选择还包括基础策略(base policy)的表示形式以及外层循环算法(outer-loop algorithm)的选择。每种方法还必须明确指定:哪些基础策略参数由内层循环进行适应,哪些是元参数(meta-parameters)。我们将这种设计选择称为“适应后的策略参数”(adapted policy parameters)。针对本节中三种元参数化类型,我们将分别讨论其内层循环、外层循环及适应后的策略参数。
探索(Exploration) 尽管这些方法各不相同,它们也共享一些挑战。其中一个挑战就是“探索”——即为适应而收集数据的过程。在小样本学习中,探索决定了智能体在“少数几次尝试”(shots)期间如何采取动作。随后,智能体必须决定如何利用所收集的数据来调整基础策略。为了实现样本高效的适应,探索本身也必须高效。具体而言,探索必须聚焦于任务分布中的差异(例如餐具位置的不同)。在第3.4节中,我们将讨论探索过程,以及如何通过结构化设计来支持探索。虽然所有小样本方法都必须学会探索未知的MDP,但探索方法与任务推断方法之间存在尤为紧密的联系。一般来说,探索可用于实现更优的任务推断,反之,任务推断也可用于实现更优的探索。任务推断支持更好探索的一种具体方式是:量化对任务的不确定性,并基于该量化结果选择动作。这种方法可用于学习最优探索策略,我们将在第3.5节中讨论。
监督信号(Supervision) 元强化学习方法在对可用监督信号的假设上也有所不同。在标准元强化学习问题设定中,奖励信号在元训练和元测试阶段均可用。然而,在每个阶段提供奖励都面临挑战。例如,人工设计一个信息丰富的元训练任务分布可能很困难;而在部署阶段(元测试)使用昂贵传感器测量奖励可能不切实际。在这种情况下,必须采用特殊方法,例如自动为外层循环设计奖励,或构建一个无需依赖奖励条件的内层循环。或者,可以提供比奖励更具信息量的监督信号。我们将在第3.6节中回顾这些设定、挑战及相关方法。
基于模型的元强化学习(Model-Based Meta-RL) 一些元强化学习方法显式地学习马尔可夫决策过程(MDP)的动力学模型和奖励函数。这类方法被称为“基于模型的方法”,与不显式学习环境模型的“无模型方法”相对。基于模型的方法具有一些优势,例如样本效率更高、支持离策略(off-policy)的元训练。此外,对于某些任务分布,使用现成的规划算法配合学习到的模型,可能比直接学习一个复杂策略更容易。然而,基于模型的方法通常需要实现额外的组件,并且在渐近性能上可能较低。我们将在第3.7节中讨论这些权衡,以及基于模型的强化学习在元强化学习中的应用。本节讨论较为简略,原因有三:第一,大多数元强化学习文献关注的是无模型强化学习;第二,元强化学习中基于模型与无模型之间的权衡,与广义强化学习中的情况类似;第三,大多数基于模型的元强化学习方法都有对应的无模型版本,而这些无模型方法在前文中通常已经讨论过。
元强化学习的理论研究(Theory of Meta-RL) 最后,我们探讨元强化学习领域的理论研究。尽管元强化学习是一个相对较新的研究领域,但已有若干研究揭示了其中一些有趣的理论挑战。这些理论洞见与实证研究结果高度相关——而实证研究构成了当前元强化学习领域的主体。在第3.8节中,我们将综述元强化学习领域的重要理论工作。我们相信,元强化学习的理论研究仍有广阔探索空间,因此希望本综述能激发未来更多相关研究。
3.1 参数化策略梯度方法

适应后的策略参数 PPG 算法通常通过元学习获得一个初始化参数,然后在内层循环中对该初始化进行调整。与仅调整单一初始化不同,一些 PPG 方法学习的是初始策略参数的完整分布 p(ϕ0)(Yoon 等, 2018;Gupta 等, 2018b;Wang 等, 2020c;Zou 和 Lu, 2020;Ghadirzadeh 等, 2021)。该分布可用于建模策略上的不确定性。初始参数的分布可以通过有限数量的离散粒子表示(Yoon 等, 2018),也可以通过变分推断拟合的高斯近似表示(Gupta 等, 2018b;Ghadirzadeh 等, 2021)。此外,该分布本身也可在内层循环中被更新,以获得对(部分)模型参数的后验分布(Yoon 等, 2018;Gupta 等, 2018b)。更新后的分布既可用于建模不确定性(Yoon 等, 2018),也可用于时间上延展的探索——如果策略参数被周期性地重新采样(Gupta 等, 2018b)。
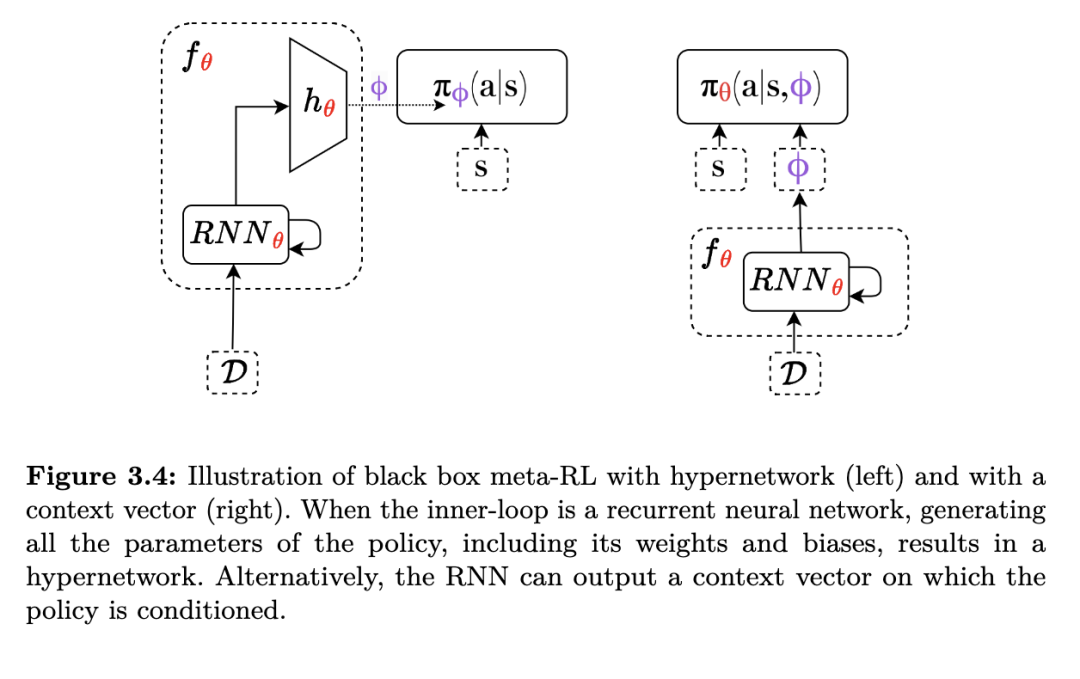
另外,一些 PPG 方法在内层循环中仅调整极少数量的参数。它们不调整所有策略参数,而是只调整一个子集(Zintgraf 等, 2019;Raghu 等, 2020)。例如,有一种方法仅调整策略网络最后一层的权重和偏置(Raghu 等, 2020),而其余参数在整个内层循环过程中保持不变。另一种方法仅调整一个称为“上下文向量”(context vector)的向量,策略的行为依赖于该向量(Zintgraf 等, 2019)。在这种情况下,策略本身的输入参数化了可能行为的范围。我们将策略写作 πθ(a∣s,ϕ),其中 ϕ是经过适应的上下文向量。策略的权重和偏置,以及初始上下文向量,构成了在内层循环中保持不变的元参数。我们在图 3.1 中展示了上下文向量的使用方式。
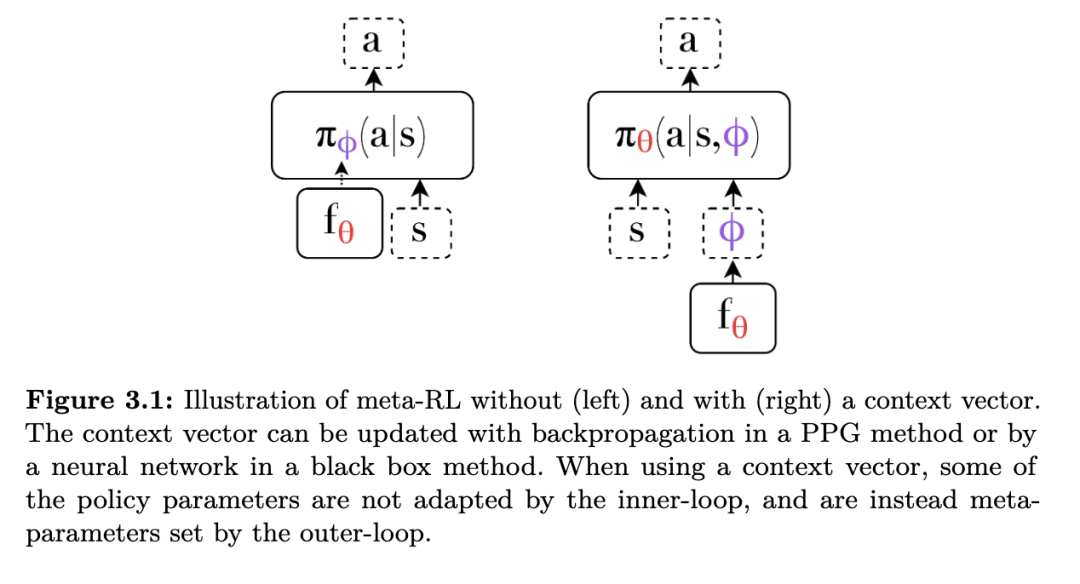
考虑算法“通过元学习进行上下文适应”(Context Adaptation via Meta-learning, CAVIA)(Zintgraf et al., 2019)。CAVIA 与 MAML 类似,但它仅调整一个上下文向量,该向量初始化为零向量:
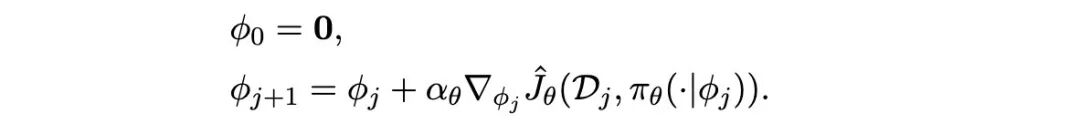
虽然对 ϕ的更新方式与 MAML 相同,但这里的 ϕ表示一个作为输入传递给策略网络的向量,而网络的所有权重和偏置在整个适应过程中保持不变。在内层循环中仅调整部分参数的一个好处是,它可能缓解在任务分布中仅需少量适应时的过拟合问题(Zintgraf et al., 2019)。
外层循环优化中的元梯度估计 PPG 算法在外层循环中的有效学习需要访问对 元梯度(meta-gradients)的估计,即外层目标函数相对于元参数的梯度。最常见的方式是通过直接使用策略梯度算法优化公式 2.3 来计算元梯度。然而,简单地在外层循环中应用策略梯度方法可能导致次优的偏差-方差权衡。已有大量研究探讨了如何改进这种权衡,特别是在估计 PPG 方法的元梯度时(Stadie et al., 2018;Foerster et al., 2018a;Rothfuss et al., 2019;Mao et al., 2019;Liu et al., 2019;Fallah et al., 2020;Vuorio et al., 2021;Tang, 2022;Fallah et al., 2021;Tang et al., 2021;Tack et al., 2022;Liu et al., 2022a)。接下来,我们将讨论 PPG 方法中元梯度估计的偏差-方差权衡,以及由选择不同权衡点所衍生出的算法。
由公式 2.3 给出的元强化学习目标关于元参数 θ的无偏梯度可按如下方式计算。由于任务分布不依赖于元参数,我们可以分别估计每个任务的元梯度,然后进行组合。单个任务的元梯度表达式为:
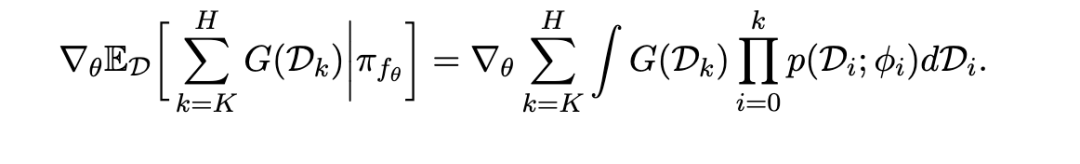
此处,我们考虑到先前轨迹的回报不受未来轨迹策略的影响。因此,我们将轨迹概率的乘积范围限制为仅从 i=0到 k。由于轨迹的概率依赖于 θ,我们使用对数导数技巧(log-derivative trick)来计算该乘积的梯度:

其中,第一个梯度项是针对第 k条轨迹相对于元参数的常规策略梯度,而求和中的梯度项则是针对第 j条轨迹(0≤j≤k−1)上策略相对于元参数的梯度。这些后一项有时被称为“采样修正项”(sampling-correction terms),在实践中常被忽略,从而导致有偏的元梯度估计(Al-Shedivat et al., 2018a;Stadie et al., 2018)。
回顾一下,PPG 方法会生成一系列策略,并通常在 K=H−n的条件下优化公式 2.3,其中 n是最终策略收集的 episode 数量。任何一个策略所采取的动作都会影响后续策略所观察到的数据,因此这些动作也会影响后续策略的期望回报。采样修正项正是为了考虑这种依赖关系。忽略这些项相当于在训练内层循环以优化元强化学习目标时,忽略了早期策略所采取的动作,从而引入了对元梯度估计的偏差(Al-Shedivat et al., 2018a)。这种偏差有时会对元学习性能产生不利影响,但无偏估计器的高方差往往占主导地位(Stadie et al., 2018;Fallah et al., 2020;Vuorio et al., 2021)。
大量研究探讨了一种最初用于计算高阶元梯度的元梯度估计器(Foerster et al., 2018a;Rothfuss et al., 2019;Farquhar et al., 2019;Liu et al., 2019;Mao et al., 2019;Tang et al., 2021;Tang, 2022;Liu et al., 2022b)。在实际中,PPG 算法使用基于样本的策略梯度算法来更新内层循环中的策略参数。基于样本的内层循环的高阶元梯度与使用期望策略梯度的内层循环不同。Foerster et al. (2018a) 和 Rothfuss et al. (2019) 认为,基于样本的内层循环的高阶元梯度应近似于期望内层循环的元梯度,并为此推导出替代的基于样本的内层更新函数。尽管这些元梯度估计器仍然存在偏差,但它们的方差对内层样本数量的依赖性比无偏元梯度估计器更温和,因此可以在偏差-方差权衡中取得比朴素或无偏估计器更好的平衡点(Tang et al., 2021;Liu et al., 2022b)。为了进一步降低这类元梯度估计器的方差,Rothfuss et al. (2019)、Farquhar et al. (2019)、Liu et al. (2019) 和 Mao et al. (2019) 提出在估计器中忽略某些高方差项并引入基线。
另一种方法是,一些 PPG 方法并不需要高阶元梯度。例如,Finn et al. (2017a) 使用元梯度的一阶近似,而 Song et al. (2020a) 使用无梯度优化(参见 Nichol et al., 2018a 对监督元学习中提出的另一种一阶近似的介绍,最近也被应用于元强化学习,Ren et al., 2022a)。此外,当像 MAML 那样在有限任务数或内层循环中数据量有限的情况下进行元学习初始化时,甚至可能更倾向于在元训练期间完全不执行任何内层步骤,即不针对每个任务进行适应(Gao and Sener, 2020)。在这种情况下,任务适应仅通过测试时的微调实现。缺乏显式的元学习可被视为该方法的一个局限性,并将在第6节中进一步讨论。此外,也可以在外层循环中使用基于价值的算法,而不是策略梯度算法,从而完全避免元梯度问题(Sung et al., 2017)。
外层循环算法尽管大多数PPG方法在外层循环中使用策略梯度算法,但也存在其他替代方案(Sung 等, 2017;Mendonca 等, 2019)。例如,可以在外层循环中使用TD误差训练一个评论家(critic)Qθ(s,a,D),然后在内层循环中复用该评论家(Sung 等, 2017)。或者,可以不通过反向传播估计元梯度,而是使用进化策略(Evolution Strategies, ES)(Rechenberg, 1971;Wierstra 等, 2014;Salimans 等, 2017)(Song 等, 2020a)。此外,还可以训练特定于任务的专家策略,然后在外层循环中使用这些专家策略进行模仿学习。虽然这些方法并非通过直接优化公式2.3来学习探索行为,但在实践中仍可能有效。我们将在第3.6节中更全面地讨论外层循环中的监督机制。
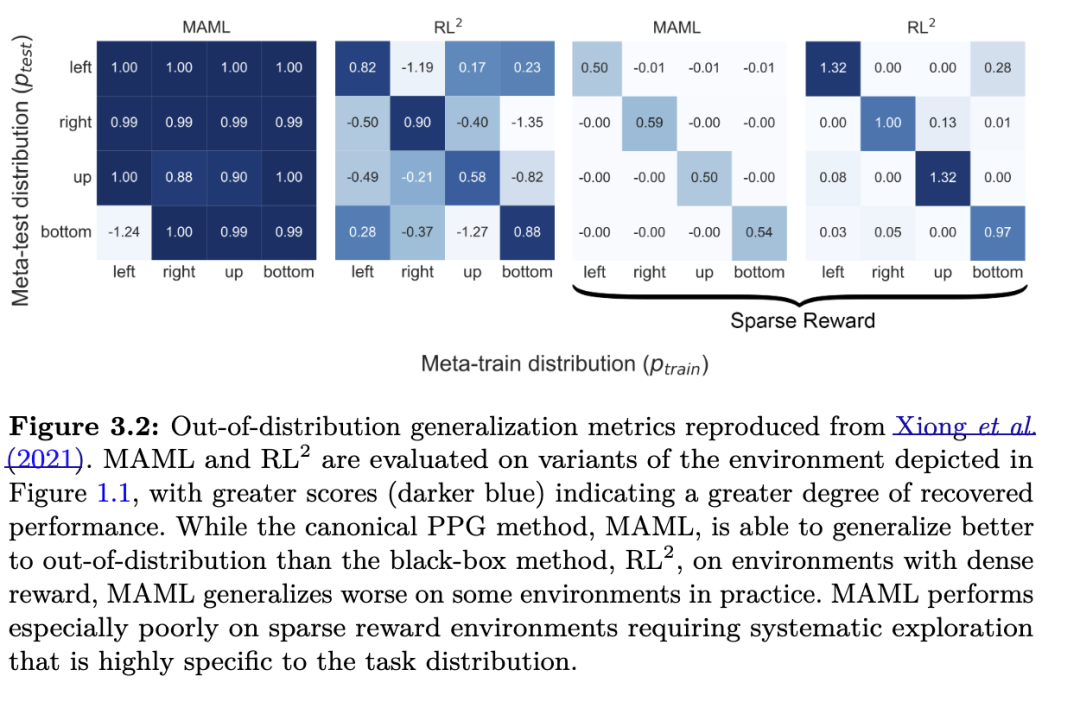
PPG方法的权衡 PPG算法的主要优势之一是,即使在元训练可用样本相对较少,或任务分布在元训练与元测试之间不一致的情况下,其内层循环仍能收敛到局部最优策略。PPG内层循环的收敛性通常在与标准策略梯度方法相同的假设下得到保证。例如,MAML的内层循环与REINFORCE(Williams, 1992)具有相同的收敛保证,因为它本质上就是从元学习得到的初始参数出发运行REINFORCE。甚至可以推导出收敛边界(Fallah 等, 2021)。然而,与任何随机梯度算法一样,REINFORCE所提供的保证相当弱。随机梯度算法在学习率足够小的情况下仅能收敛到局部最优解,这在元强化学习实践中可能带来问题(Xiong 等, 2021)。此外,在某些情况下,一次REINFORCE更新甚至可能使策略在当前任务上的表现更差(Deleu 和 Bengio, 2018)。我们在图3.2中复现了Xiong等人(2021)的实证结果。虽然PPG方法(如MAML)最终能在许多分布外任务上收敛到表现良好的策略,但在某些环境中(例如稀疏奖励环境),它在实践中却无法成功收敛。此外,Xiong等人(2021)还表明,通过在元测试阶段继续使用梯度步进行元训练,黑箱方法在实践中也可以实现类似的收敛效果。拥有一个最终能适应新任务的学习算法是可取的,因为这降低了对元训练阶段必须见到大量相关任务的依赖。
尽管将 fθ参数化为策略梯度方法可能确保适应过程具有泛化能力,但这种结构也带来了一种权衡。通常,内层循环的策略梯度具有高方差,并且需要覆盖完整episode的价值估计,因此梯度估计通常需要多个episode。因此,PPG方法通常不太适合那些要求在内层循环中每个时间步或极少数episode内实现稳定适应的小样本问题。这可能导致其性能相对于黑箱方法下降,例如图3.2所示的稀疏奖励环境,这类环境需要高度专业化和系统化的探索。此外,PPG方法在元训练阶段通常也样本效率低下,因为外层循环一般依赖于在线策略(on-policy)评估,而非能够高效复用数据的离线策略(off-policy)方法。
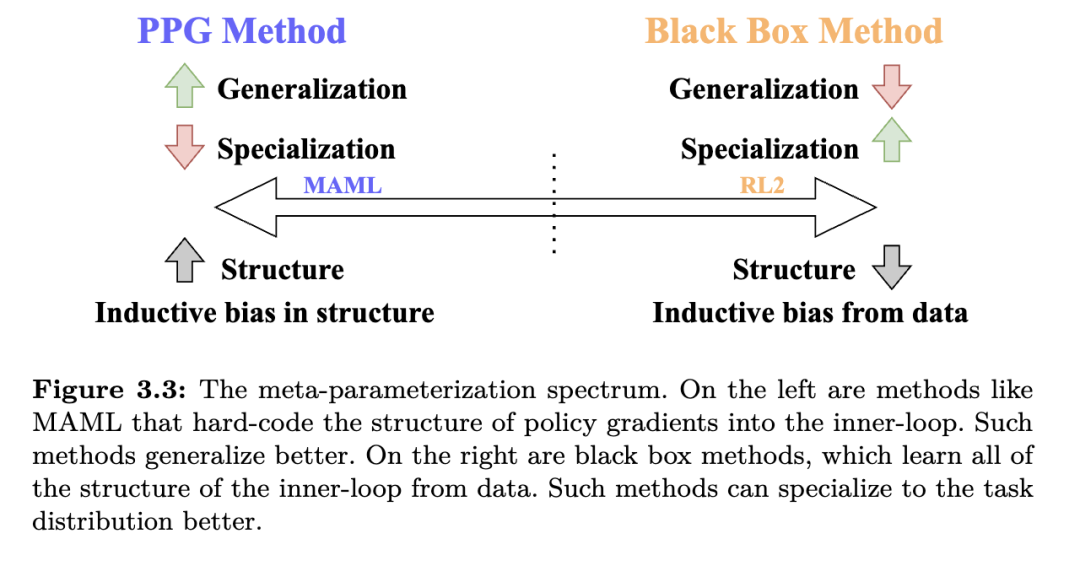
一般来说,存在一种权衡:一方面是对新任务的泛化能力,另一方面是在给定任务分布上的专业化程度。这种权衡由 fθ的参数化方式所施加的结构程度决定,决定了每种算法在这一谱系中的位置。PPG方法的结构使其位于确保泛化能力的一端附近。这一点在图3.3中有所体现。尽管该谱系总结了当前的方法,但这种权衡并不一定内在于问题设定本身,未来的研究可以探索能够兼得两者优势的方法。在下一节中,我们将讨论位于该谱系另一端的方法。
3.2 黑箱方法


一些方法将注意力机制与卷积相结合(Mishra et al., 2018),或在过去的循环状态上使用注意力(Ritter et al., 2018b;Fortunato et al., 2019;Team et al., 2023;Oh et al., 2016),而另一些方法则仅使用自注意力(self-attention)(Ritter et al., 2021;Wang et al., 2021;Team et al., 2023)。例如,为了关注过去的循环状态,查询向量 q可能是当前循环网络隐藏状态的函数,而键矩阵 K和值矩阵 V可能是(两个不同的线性投影)所有先前隐藏状态的计算结果,这些隐藏状态是基于数据集 D得到的。这类方法的一般化形式如图 3.5 所示。相比之下,自注意力模型首先将 Q、K和 V均表示为输入 D的线性投影,然后在多个连续的注意力层中,将其表示为前一层注意力输出的线性投影。
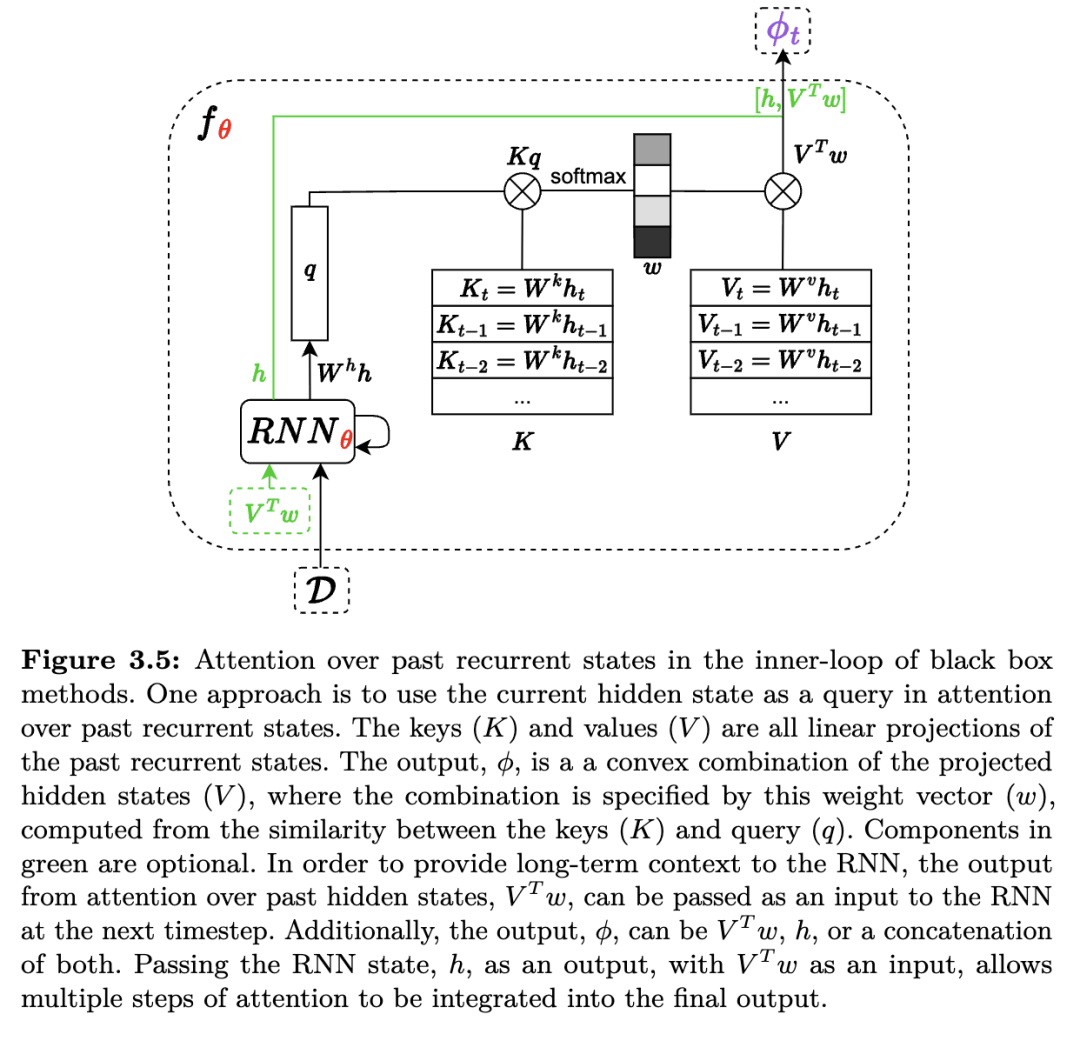
注意力机制似乎有助于在任务分布 p(M)之外对新任务进行泛化(Fortunato et al., 2019;Melo, 2022),而自注意力可能对复杂规划任务有帮助(Ritter et al., 2021)。然而,注意力机制在计算上较为昂贵:循环网络每时间步仅使用 O(1)的内存和计算量,而注意力机制通常需要每时间步 t使用 O(t2)的内存和计算量,这可能跨越多个episode。尽管存在快速近似注意力的方法(Katharopoulos et al., 2020),但在元强化学习中,解决方案通常仅保留最近若干次转换的固定数量记忆(Mishra et al., 2018;Fortunato et al., 2019)。尽管如此,无论是使用自注意力的Transformer还是循环神经网络,在元学习简单归纳偏置方面仍可能面临挑战,尤其是在由低维空间中简单底层规则生成的复杂任务分布中(Kumar et al., 2020;Chan et al., 2022)。
外层循环算法 虽然许多黑箱方法在外层循环中使用在线策略(on-policy)算法(Duan et al., 2016b;Wang et al., 2016;Zintgraf et al., 2020),但使用离线策略(off-policy)算法也是直接可行的(Rakelly et al., 2019;Fakoor et al., 2020;Liu et al., 2021),这能提高强化学习的样本效率。对于离散动作,也可以直接使用Q-learning(Fakoor et al., 2020;Liu et al., 2021;Zhang and Kan, 2022),此时内层循环必须相应调整。在这种情况下,内层循环估计Q值,而不是直接参数化策略。在元测试阶段,策略可以基于这些Q值贪婪地行动。这种方法可视为对循环Q网络(Hausknecht and Stone, 2015)的修改,以适应元强化学习设定,与其它最先进的元强化学习方法相比表现更优(Fakoor et al., 2020)。
黑箱方法的权衡 黑箱方法的一个关键优势是,它们能够迅速根据新信息调整策略,而PPG方法通常需要多个episode的经验才能获得足够精确的内层梯度估计。例如,考虑一个智能体在元测试阶段必须学习厨房中哪些物体是热的。在估计策略梯度时,PPG方法可能会多次接触热炉灶,直到学会避免为止。相比之下,黑箱方法可能产生一种适应过程,从不重复接触热表面超过一次。黑箱方法之所以能学习这种响应迅速的适应过程,是因为它们将内层循环表示为一个任意函数,该函数将累积的任务经验映射到下一个动作。
然而,黑箱方法也存在权衡。虽然它们能紧密拟合任务分布 p(M)上的数据假设,从而增强专业化能力,但它们往往难以在 p(M)之外泛化(Wang et al., 2016;Finn and Levine, 2018;Fortunato et al., 2019;Xiong et al., 2021)。以机器人厨师为例:虽然它可能学会不接触热表面,但如果在元训练期间从未见过炉灶,一个黑箱机器人厨师不太可能学会如何使用炉灶这一全新的技能。相比之下,PPG方法在元测试阶段只要有足够数据,仍可能学会此类技能。尽管已有研究尝试通过扩展元训练任务集并手动添加归纳偏置来提升黑箱方法的泛化能力(见第4节),但选择使用黑箱方法还是PPG方法,通常取决于所解决问题中所需的泛化与专业化的程度。
此外,PPG方法与黑箱方法在外部优化挑战上也存在权衡。一方面,如第3.1节所述,PPG方法通常估计元梯度,而该梯度计算困难(Al-Shedivat et al., 2018a),尤其在长任务时间跨度下(Wu et al., 2018)。另一方面,黑箱方法没有内置优化方法的结构,因此从零开始训练可能更困难,即使在短时间跨度下也会面临外层优化挑战。黑箱方法通常使用循环神经网络,可能遭受梯度消失或梯度爆炸问题(Pascanu et al., 2013)。此外,循环神经网络在强化学习中的优化尤为困难(Beck et al., 2020),而Transformer在训练中可能更加棘手(Parisotto et al., 2020;Melo, 2022)。尽管大型Transformer在元强化学习中已取得显著成功,但这些方法通常需要课程学习和知识蒸馏来稳定训练(Team et al., 2023)。因此,黑箱方法在元强化学习中虽能实现快速学习,但也给元学习带来了新的挑战。
一些方法结合了PPG和黑箱组件(Vuorio et al., 2019;Xiong et al., 2021;Ren et al., 2022a)。特别是,即使在训练完全黑箱方法时,策略或内层循环也可在元测试阶段使用策略梯度进行微调(Lan et al., 2019;Xiong et al., 2021;Imagawa et al., 2022)。
3.3 任务推断方法 与黑箱方法密切相关的是任务推断方法,它们通常与黑箱方法共享相同的参数化形式,因此可被视为黑箱方法的一个子集。然而,内循环的参数化可能专门针对任务推断方法(Rakelly 等,2019;Korshunova 等,2020;Zintgraf 等,2020),这些方法通常通过优化不同的目标,训练内循环执行不同的功能。
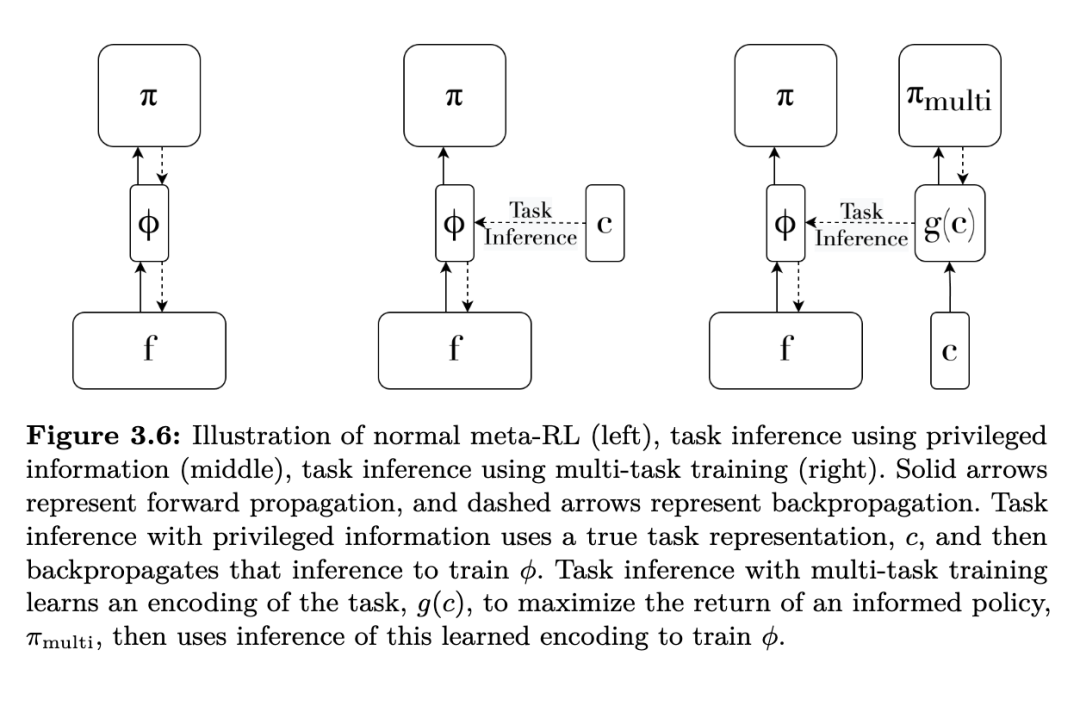
任务推断方法通常旨在在内循环中识别智能体必须适应的MDP(马尔可夫决策过程)或任务。在元强化学习(meta-RL)中,智能体必须反复适应一个未知的MDP,其表示并未作为输入提供给内循环。虽然智能体最终的目标是最大化奖励,但内循环的全部目的可被描述为识别任务。智能体关于“应做什么”的信念可以表示为一个任务分布。如第2节所述,该后验分布构成了元强化学习问题的充分统计量或信息状态(Subramanian 等,2022)。既然我们已经知道该充分统计量的形式,内循环可以直接建模它,而无需端到端地学习从历史到动作的映射。任务推断即是在给定当前观测数据条件下,推断该任务后验分布的过程。
考虑智能体已唯一识别任务的情况。此时,智能体已知MDP,实际上可直接使用经典规划技术(如值迭代)计算最优策略。在这种情况下,不再需要进一步学习或数据收集。更实际地,若任务分布规模合理且有限,我们甚至可以避免显式规划——只需在元训练阶段直接学习从任务到最优策略的映射。事实上,在元训练阶段训练一个以真实任务为条件的策略,可被视为多任务强化学习(multi-task RL)的定义(Yu 等,2020a)。在多任务情况下,学习的是从已知任务到策略的映射;而在元强化学习中,唯一的区别是任务未知。因此,任务推断可被视为将元学习问题转化为更简单的多任务设置的一种尝试。
当任务分布中仍存在不确定性时,任务推断方法通常不是将单一任务映射到基础策略,而是将当前数据所给出的任务分布映射到基础策略。这可被视为学习一个以(部分)推断任务为条件的策略。在此情况下,学习过程即为减少任务不确定性的过程。智能体必须收集有助于识别任务的数据——也就是说,智能体必须进行探索,以降低任务推断所给出的后验分布中的不确定性。因此,任务推断是构建探索策略的一种有效框架,许多任务推断方法也被视为探索工具,我们将在第3.4节讨论。最优地处理任务分布中的不确定性是困难的,相关内容将在第3.5节讨论。
在本节中,我们将讨论两种使用监督学习但需要对元训练可用信息做出假设的任务推断方法;随后讨论无需此类假设的替代方法,以及内循环通常如何表示。最后,我们将总结任务推断方法相关的权衡取舍。表3.1汇总了这些类别及任务推断方法。





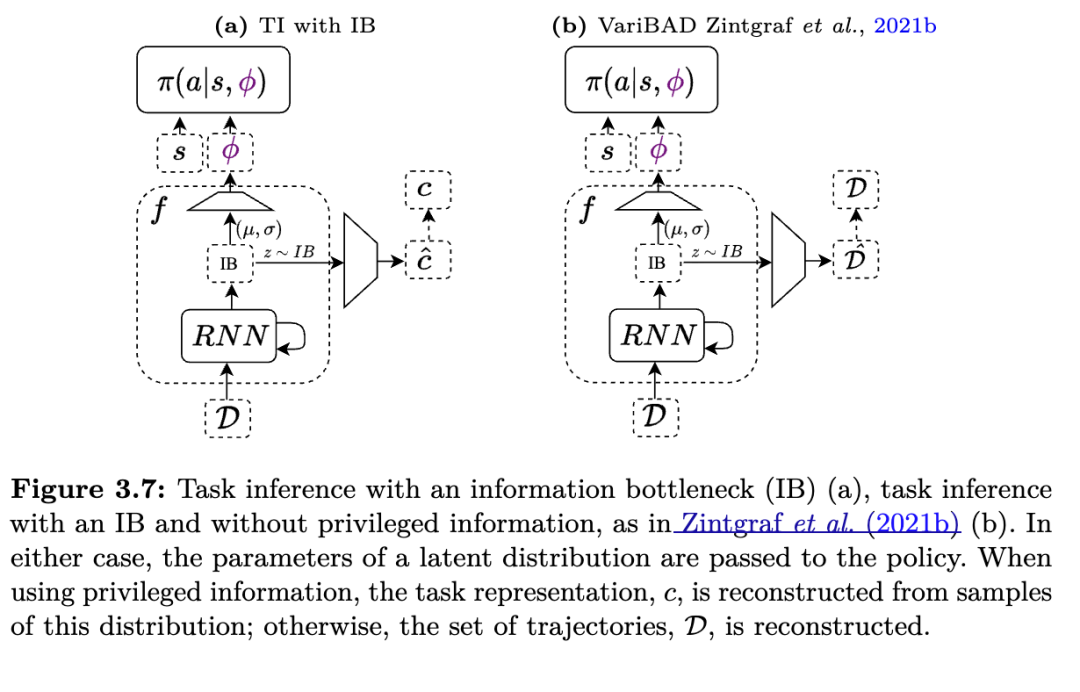

任务推断的权衡任务推断方法与其他方法相比存在权衡。首先,我们考虑与 PPG 方法的比较,然后与黑箱方法比较。与 PPG 方法相比,任务推断方法对内循环施加的结构更少。一方面,PPG 方法由于额外的结构,能更好地泛化到新任务。当新任务无法用元训练期间学到的任务表示来表示时,任务推断方法会失败(Rimon 等,2022),而 PPG 方法通常可以通过策略梯度适应新任务。另一方面,PPG 方法不太可能恢复出像任务推断一样高效的算法。对于任务推断可行的任务分布,将此类方法拟合到任务分布可能实现更快的适应。如果分布中任务不多,且可以从少量连续状态转移中轻松推断,那么使用任务推断方法推断潜在任务比使用 PPG 方法学习新策略更具样本效率。这是图 3.3 中所示的泛化与专业化之间的权衡。
与黑箱方法相比,任务推断方法施加了更多结构。一方面,任务推断方法通常通过使用特权信息(Humplik 等,2019;Kamienny 等,2020;Liu 等,2021)或自监督(Zintgraf 等,2020;Zintgraf 等,2021c)添加额外的监督,这可能使元训练更稳定、更高效(Humplik 等,2019;Zintgraf 等,2020)。这尤其有用,因为常用于任务推断和黑箱方法的循环策略在强化学习中难以训练(Beck 等,2020)。另一方面,有证据表明,在元强化学习中使用超网络架构和合理的初始化可以稳定黑箱训练(Beck 等,2023),并且训练内循环以完成非公式 2.3 所定义的目标,可能相对于给定任务分布上的元强化学习目标来说是次优的。黑箱方法与任务推断方法之间的实证比较见表 3.2。
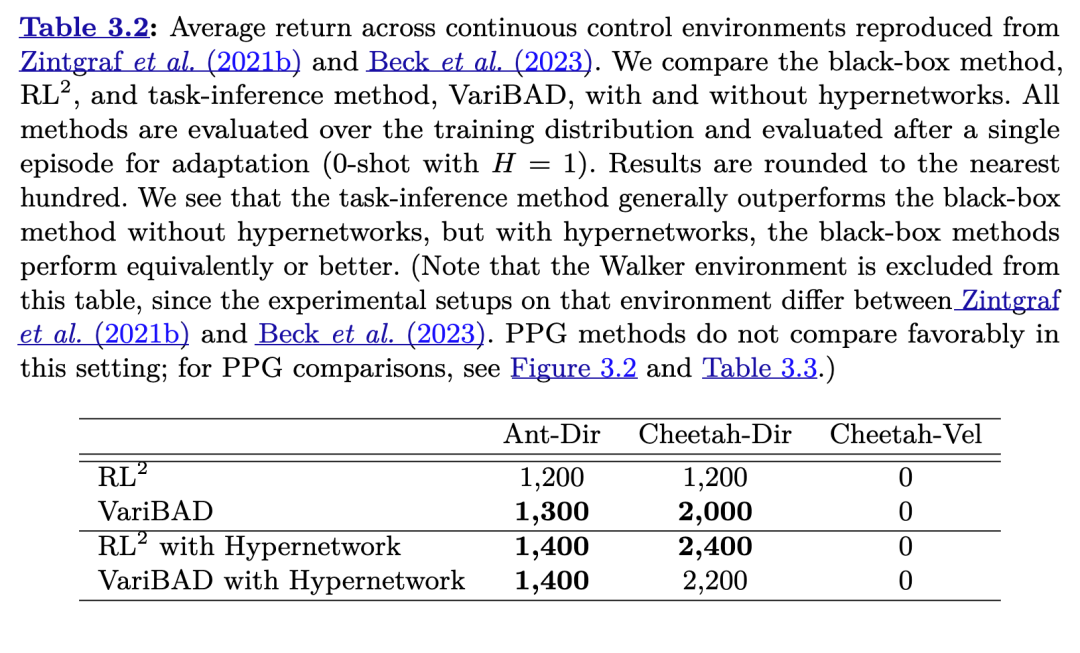
表3.2. 除了与PPG方法和黑箱方法的比较之外,任务推断方法还提供一些额外的优势。那些对奖励函数和动态模型进行建模的任务推断方法可用于采样额外的(想象出的)任务(Rimon 等,2022),这可被视为一种基于模型的元强化学习,相关内容将在第3.7节中讨论。此外,正如我们在第3.4节中所示,任务推断方法在探索方面也非常有用。
回想一下,在少样本适应(few-shot adaptation)设置中,每次试验时,智能体被放置到一个新任务中,并允许与该任务交互若干个回合(即其“少样本”数量 K),然后在接下来的几个回合中(即公式 2.3 中的 H−K个回合)对其解决任务的能力进行评估。图 3.8 展示了这一过程的示意图。直观上,智能体必须在最初的几个回合中进行探索以收集信息,从而能够在后续回合中最好地解决任务。更一般地说,这里存在一个探索-利用权衡(exploration-exploitation trade-off):智能体必须在采取探索性动作以学习新任务(可能甚至超出初始的少数几个回合)和利用已有知识以获得高奖励之间取得平衡。在前 K个回合中,由于没有给智能体提供任何奖励,因此总是最优的策略是进行探索。然而,在剩余的 H−K个回合中,最优的探索程度取决于评估阶段 H−K的长度:当 H−K较大时,更多的探索是最优的,因为牺牲短期奖励以学习更好的策略从而获得更高的长期回报是值得的;而当 H−K较小时,智能体必须更多地利用已有知识,以便在时间耗尽之前尽可能多地获得奖励。在本节中,我们将综述一些应对这种权衡的方法。表 3.4 总结了这些类别。正如第 2 节所讨论的,该探索问题存在一个最优解,它能最大化元强化学习目标。在下一节中,我们将讨论一个形式化地最优实现这种权衡的框架。

端到端优化 或许最简单的方法是通过直接最大化元强化学习目标(公式 2.3)来端到端地学习探索与利用,这正是黑箱元强化学习方法的做法(Duan 等,2016b;Wang 等,2016;Mishra 等,2018;Stadie 等,2018;Boutilier 等,2020)。这类方法隐式地学习探索,因为它们直接优化元强化学习目标,而该目标的最大化本身需要探索。更具体地说,只有当策略在前 K个回合中进行了适当的探索,才能最大化后续 K−H个回合的回报,因此从原理上讲,最大化元强化学习目标可以产生最优的探索行为。然而,当需要更复杂的探索策略时,以这种方式学习探索可能极其低效。一个问题在于,要在后面的 K−H个回合中学习利用,就必须已经在前 K个回合中完成探索,但探索本身又依赖于良好的利用行为来提供奖励信号(Liu 等,2021)。例如,在机器人厨师任务中,机器人只有在找到所有食材后才能学习烹饪(即利用),但它只有在成功做出饭菜的情况下才被激励去寻找食材(即探索)。因此,如果没有先学会探索,就很难学习利用,反之亦然,因此端到端方法可能难以以样本高效的方式学习那些需要复杂探索行为的任务,相比本节后面将讨论的更具结构化的方法。
一种端到端学习探索的方法还通过修改奖励来鼓励探索。E-RL²(Stadie 等,2018)是一种端到端方法,它在外循环中将前 K个回合的所有奖励设为零。虽然忽略这些奖励会引入稀疏性,但在短视地最大化即时、密集奖励可能会阻碍为长期奖励所需探索的情况下,这种方法可能是有帮助的。一般来说,许多方法通过对元强化学习目标的端到端优化增加更多结构,以解决那些需要复杂探索行为的任务分布。
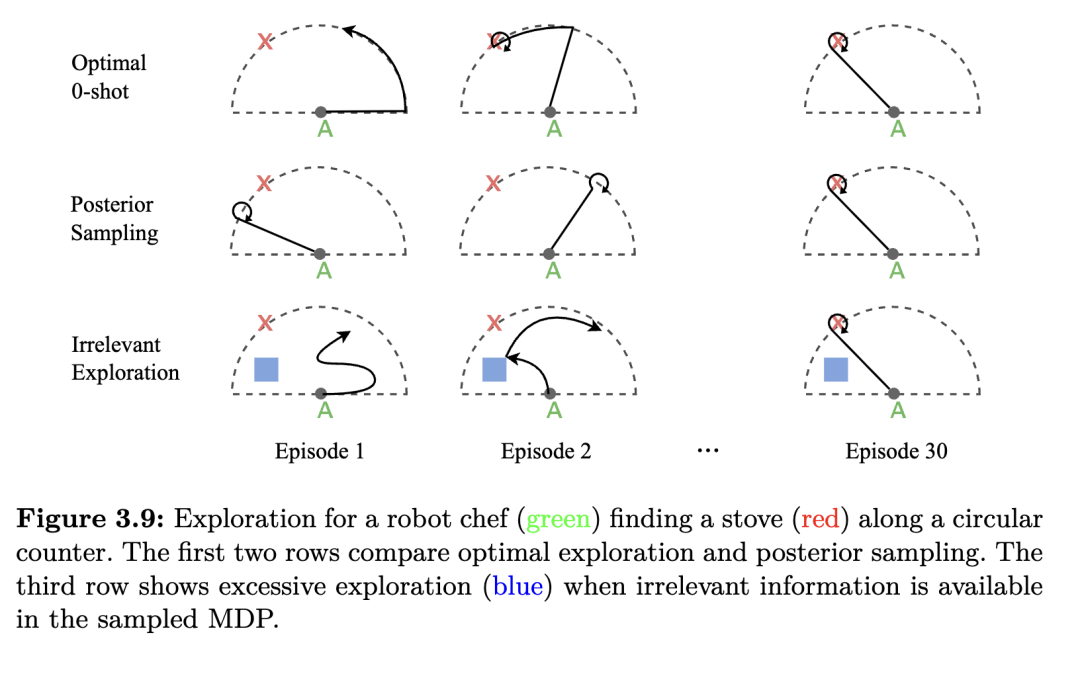
后验采样 为了克服隐式学习探索的挑战,Rakelly 等(2019)提出通过后验采样(posterior sampling)直接进行探索,这是 Thompson 采样(Thompson, 1933)在MDP上的扩展。该方法的内循环(PEARL)在算法 3 中描述。当智能体被置于一个新任务中时,基本思想是维护一个关于任务身份的概率分布,然后通过与任务交互不断迭代地细化该分布,直到它大致收敛为真实任务身份的点质量。后验采样通过在每个回合中从该分布中采样一个任务身份的估计值,并假设该估计值为当前回合的真实任务身份来进行行动,从而实现这一点。随后,该回合的观测结果用于通过黑箱方法(Rakelly 等,2019)或直接梯度下降(Gupta 等,2018b)更新该分布。

然而,后验采样也存在一个缺点。首先,由于所采用的策略始终条件于一个采样的任务,因此在这种方法中所有的探索行为都是由一个假设自己已知当前任务的策略执行的。这意味着同一个策略同时用于探索和利用。这可能导致在公式 2.3 的意义上产生次优的探索行为。考虑一个机器人厨师需要在弯曲的厨房台面上找到炉灶的情形。最优的探索方式是,厨师沿着台面边缘行走,直到找到炉灶。如果厨师必须在每个回合结束时重置到初始位置(例如,为了在回合末充电),那么机器人会从上次停止的位置继续探索。相比之下,使用后验采样的厨师在每个回合中只是走到台面上尚未检查的一个不同点,重复这一过程,直到找到炉灶。
这种对比如图 3.9 所示。在元强化学习中,还存在其他探索方法,它们通过为探索增加结构来避免这一限制。
任务推断另一种避免隐式学习探索所带来挑战的方法,是直接通过鼓励探索的任务推断目标来学习探索(Zhou 等,2019;Gurumurthy 等,2020;Wang 等,2020a;Liu 等,2021;Fu 等,2021;Zhang 等,2021)。部分(但非全部)任务推断方法会使用此类目标以鼓励探索。利用任务推断的探索方法通常会添加一个内在奖励,以收集能消除任务分布不确定性的信息。换句话说,这些方法训练策略去探索那些有助于预测任务的状态。
具体而言,这些内在奖励通常激励改进状态转移预测(即适应动态模型和奖励函数)(Zhou 等,2019),或激励在任务分布上获得信息增益(Fu 等,2021;Liu 等,2021;Zhang 等,2021)。其核心思想是:只要恢复出任务本身,就足以学习最优策略,从而在后续回合中获得高回报。尽管任务推断奖励可能会激励超出必要程度的探索——正如我们在本节关于“元探索”的讨论中所指出的——但这些奖励可以通过退火(annealing)逐步衰减,从而使策略最终仍可通过端到端方式进行优化(Zintgraf 等,2021c)。
3.4. 探索与元探索 这些方法中的大多数使用独立的策略分别进行探索和利用,尤其是在探索回合可自由获取的情况下(Zhou 等,2019;Gurumurthy 等,2020;Liu 等,2021;Fu 等,2021)。内在奖励用于训练探索策略,而标准的元强化学习目标(由公式 2.3 给出)则用于训练利用策略。探索策略在前 K 个回合中执行探索,随后利用策略基于探索策略所收集的数据,在剩余的 H−K 个回合中执行利用。
有一种方法称为 DREAM(Liu 等,2021),它首先识别对利用策略有用的信息,然后直接训练探索策略仅恢复这些信息。这一点至关重要,特别是在“少样本”数量 K 过小、无法彻底探索所有动态和奖励函数的情况下——因为其中大部分内容可能是无关的。例如,探索墙上的装饰品可能提供有关任务动态的信息,但对于试图烹饪餐食的机器人厨师而言却是无关紧要的。以这种方式学习任务表示可被视为多任务训练,如第 3.3 节所述,其旨在解决无信息性(如独热编码)或无关的任务信息问题。这种多任务训练在探索背景下尤其有益,因为在多任务阶段用于学习任务表示的策略也可被重用为利用策略。
虽然从理论上讲,探索策略和利用策略可以完全按顺序进行元训练,但在实践中,为了训练稳定性,二者通常同时训练(Liu 等,2021;Fu 等,2021)。DREAM 的元测试和元训练过程分别在算法 4 和算法 5 中描述。然而,DREAM 仍存在一些缺点。例如,DREAM 需要以已知任务表示形式提供的特权信息,并且当在给定的 K 个回合内无法充分探索时(例如在零样本设置下),DREAM 可能表现次优。


元探索 最后,在元强化学习中,与标准强化学习一样,仍然存在为外循环学习收集数据的过程。这被称为“元探索”,因为它必须探索探索策略的空间。虽然元探索可被视为外循环中的探索,但由于内外循环共享数据,且探索方法可能同时影响两个循环,因此二者之间的界限可能较为模糊。通常,仅依靠外循环中标准强化学习算法自身的探索行为,就足以实现充分的元探索。然而,一种常见的专门应对元探索的方法是添加内在奖励。事实上,上文所讨论的任何任务推断奖励的引入,都可以被视为元探索。这一点尤其明显,因为这种内在奖励可用于专门训练一个策略,以在元训练期间收集离策略(off-policy)数据。
然而,有时仅添加任务推断奖励并不足够。在这种情况下,可以引入与标准强化学习中功能类似的内在奖励。例如,使用随机网络蒸馏(Random Network Distillation, RND)(Burda 等,2019),可以添加激励新颖性的奖励(Zintgraf 等,2021c)。在这种情况下,新颖性是在状态与任务表示的联合空间中衡量的,而不仅仅像标准强化学习那样仅在状态表示空间中衡量。例如,HyperX(Zintgraf 等,2021c)添加的奖励为:
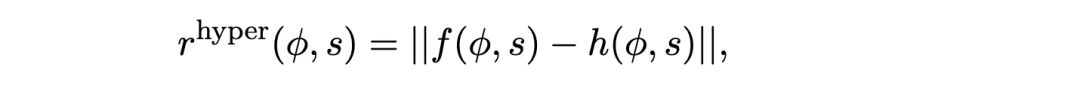

3.5 贝叶斯自适应最优性
我们迄今为止的讨论揭示了关于探索的两个关键直觉。首先,探索减少了当前任务的动力学和奖励函数的不确定性。至关重要的是,不加区分地减少所有不确定性并不是最优的。相反,最优的探索仅减少那些能增加未来预期回报的不确定性,而不会减少与任务无关或具有干扰性的状态空间部分的不确定性。其次,探索与利用之间存在张力:收集信息以降低不确定性并提高未来回报,可能会牺牲更即时的回报。在这些情况下,当探索时间有限时,智能体回退到所有任务中共享的行为,而不是去适应特定任务,可能是值得的(Lange 和 Sprekeler,2020)。因此,在一段时间内最大化回报需要仔细平衡通过探索获取信息,并利用这些信息以实现高回报。这引出了一个重要的问题:什么是最优的探索策略?为了回答这个问题,我们接下来介绍贝叶斯自适应马尔可夫决策过程(Bayes-adaptive Markov decision process)(Duff 和 Barto,2002;Ghavamzadeh 等,2015),这是一种特殊的 MDP,其解是贝叶斯最优策略,该策略在探索与利用之间实现了最优权衡。然后,我们将讨论学习近似贝叶斯最优策略的实际方法,并从贝叶斯最优性的角度分析前一节中引入算法的行为。
贝叶斯自适应马尔可夫决策过程 为了确定最优的探索策略,我们需要一个框架来量化当策略被置于一个动力学和奖励函数未知的 MDP 中时所能获得的预期回报。从高层次来看,贝叶斯自适应马尔可夫决策过程(BAMDP),即一种特殊的 MDP,正是为此建模的:在每个时间步,BAMDP 量化对 MDP 的当前不确定性,并基于不确定性下的期望情况返回下一个状态和奖励。然后,最大化 BAMDP 下回报的策略,就是在未知 MDP 中最大化回报的策略。关键在于,BAMDP 的动力学通过将当前不确定性扩展到状态中,满足马尔可夫性质。换句话说,最优的探索策略显式地基于当前不确定性来决定何时以及如何进行探索和利用。

学习近似贝叶斯最优策略 直接计算贝叶斯最优策略需要在超状态上进行规划。由于超状态包含信念,即关于动力学和奖励函数的分布,这对除最简单问题外的所有问题来说通常都是不可行的。然而,存在实用的方法来学习近似贝叶斯最优策略(Lee 等,2019;Humplik 等,2019;Zintgraf 等,2020;Arumugam 和 Singh,2022)。核心思想是学习近似信念,并同时学习一个基于该信念的策略,以最大化 BAMDP 目标(公式 3.1)。

尽管 Team 等人(2023)证明了端到端学习复杂探索策略是可能的,但实现这一点可能仍需要借助课程学习(curriculum learning)、蒸馏(distillation)以及大量用于元训练的样本(Team 等,2023)。此外,他们任务分布中的元探索问题可能并未构成一个困难的元探索挑战,因为其智能体“并未利用所观察到的试验条件信息来调整自身行为”(Team 等,2023)。仅依靠元强化学习目标进行端到端训练本身就是一个困难的优化问题。Liu 等人(2021)指出了黑箱元强化学习算法面临的一个此类优化挑战:在尚未学会如何利用信息之前,学习如何探索并收集信息是困难的,反之亦然。
其次,上一节讨论的许多探索方法都考虑的是少样本(few-shot)设置,即智能体被给予若干个“免费”的回合用于探索,目标是在随后的回合中最大化回报。同样,BAMDP 目标也可以通过将初始奖励设为零来进行修改,以包含免费探索回合。根据免费探索回合数量的不同,BAMDP 的最优策略可能会鼓励截然不同的探索行为。例如,在机器人厨师任务中,最优的少样本探索行为可能是在最初的几个回合中彻底翻找抽屉和储藏室,寻找最佳的厨具和食材,然后再开始烹饪。相比之下,最优的零样本行为可能是在烹饪过程中(例如,水正在烧开时)顺带寻找厨具和食材,因为预先花费时间可能代价过高——尽管这可能导致使用不太合适的厨具或食材,尤其是在以较低折扣因子进行优化时。
更一般地说,专为少样本设置设计的方法试图在最初的几个免费探索回合中降低信念状态的不确定性,然后利用相对较低的不确定性来实现高回报。这与零样本设置中的行为形成对比,后者可能涉及探索与利用的交替进行。例如,PEARL 中的后验采样探索方法维护当前任务的后验分布(等价于信念状态),通过从该分布中采样、假设采样任务即为当前真实任务来执行探索,并根据观测结果更新后验分布,旨在压缩信念状态中的不确定性。类似地,DREAM 通过学习一个在少数免费探索回合中收集所有任务相关信息的探索策略,也试图将信念状态压缩至仅包含具有相同最优利用策略的动力学和奖励函数。
3.6 监督
在本节中,我们将讨论元强化学习(meta-RL)中所考虑的大多数不同类型的监督形式。在迄今为止讨论的标准设置中,元强化学习智能体在元训练的内循环和外循环中,以及在元测试中,均接收奖励监督。然而,情况并非总是如此。研究者已考虑了多种变体,从无监督情况(即在元训练或测试期间完全无奖励信息),到更强形式的监督(例如,在元训练和/或测试期间可访问专家轨迹或其他特权信息)。每种情况都构成一个不同的问题设定,具有独特的方法,如表3.5所示。下文我们将按监督程度从低到高的顺序讨论这些设定。
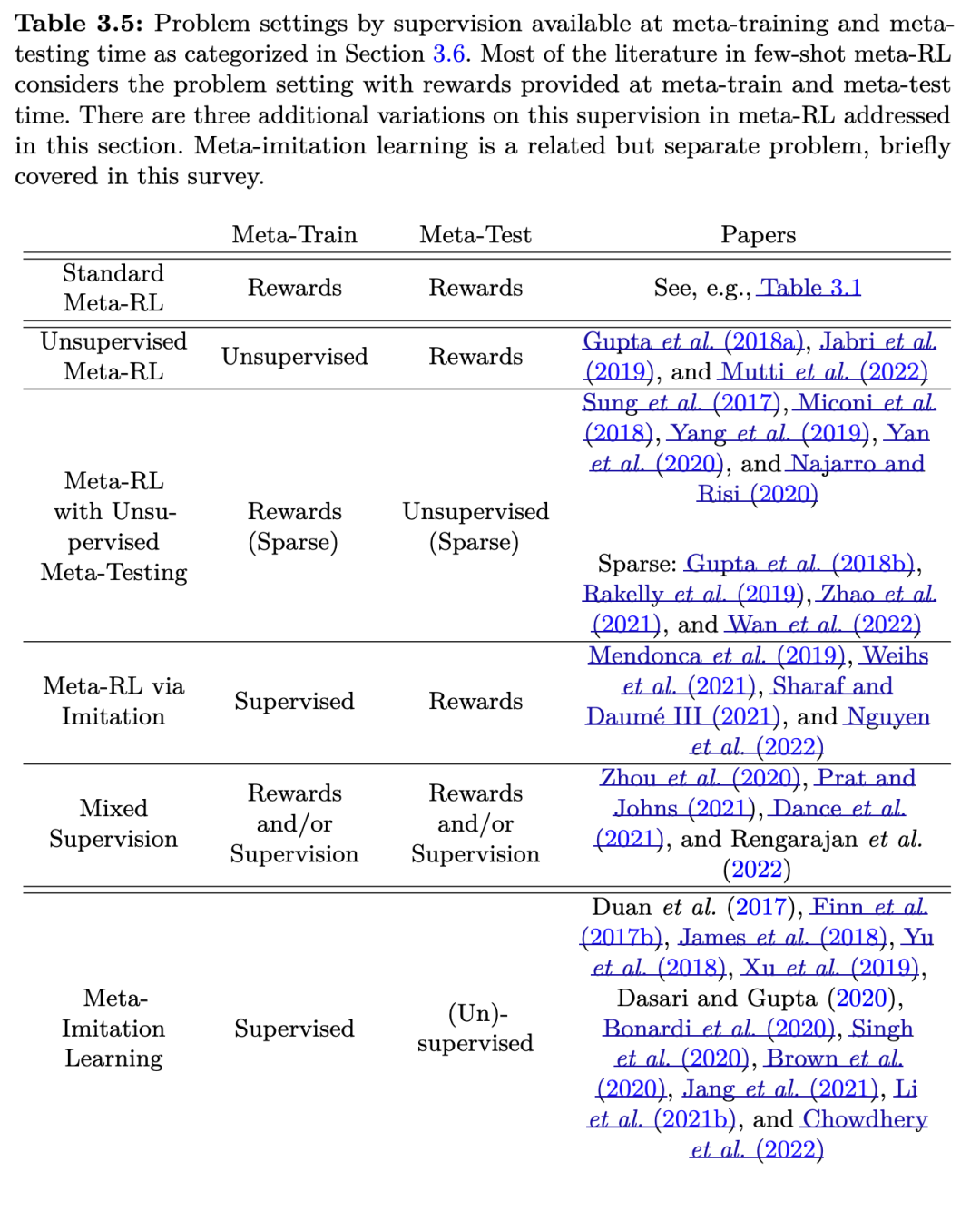
无监督元强化学习第一种问题设定提供的监督最少:在元训练阶段无任何奖励信息可用,但在元测试阶段奖励信息可用(Gupta 等,2018a;Jabri 等,2019;Mutti 等,2022)。例如,一个机器人厨师可能在标准化厨房中进行元训练,然后出售给顾客,每位顾客可能拥有自己专属的奖励函数。然而,训练该机器人的公司可能并不了解顾客的具体需求。在这种情况下,为元训练所需的MDP分布设计奖励函数非常困难,甚至难以定义一个我们预期测试任务会落在其支持集内的分布。一种解决方案是简单地创建鼓励在环境中生成最大多样性轨迹的奖励函数。这样,终端用户所期望的行为很可能与这些轨迹和奖励函数之一相似。
Gupta 等(2018a)和 Jabri 等(2019)尝试通过奖励彼此不同的行为,来学习一组多样化的奖励函数。一般来说,可以使用现成的无监督强化学习方法(Eysenbach 等,2019;Park 等,2024)来构建一组任务。一旦这组任务被创建出来,就可以像往常一样轻松执行元强化学习。
例如,Gupta 等(2018a)使用方法“多样性即你所需”(Diversity is All You Need, DIAYN,Eysenbach 等,2019)来构建这个奖励函数分布。具体而言,DIAYN 首先学习一个潜在变量 Z 以参数化奖励函数,同时学习一个多任务策略
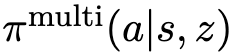
。DIAYN 通过最大化状态与潜在变量之间的互信息(以确保状态空间的划分)以及策略的熵来实现这一点:
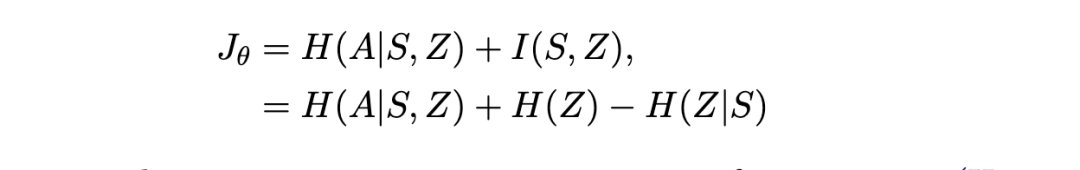

一旦训练完成,这类元强化学习智能体相比从零开始训练的强化学习方法能更快适应,并且在多个导航和运动任务上具有竞争力,这些任务基于人工设计的训练分布进行元训练。然而,这些领域相对简单,多样化的轨迹能够覆盖任务空间,因此与机器人厨师等更现实的领域之间仍存在差距。来自无奖励强化学习(reward-free RL)的方法(Touati 和 Ollivier,2021)在此背景下高度相关,因为它们也能仅利用动力学信息来学习表示。然而,在那种设定中,奖励函数是在测试时提供给智能体,或由人工手动估计,而不是由元学习算法推断得出。
元强化学习与无监督元测试 第二种设定假设在元训练阶段有奖励可用,但在元测试阶段则没有奖励。例如,生产机器人厨师的公司可能能够在实验室的多个厨房中安装许多昂贵的传感器用于元训练。这些传感器可检测台面是否被刮伤、是否发生水损,或家具是否损坏。所有这些信息共同用于定义奖励函数。然而,在每位客户家中安装这些传感器可能成本过高。在这种情况下,元测试阶段无法获得奖励。奖励存在于外循环中,但从未在内循环中使用,并且假设奖励信息无需用于识别任务。事实上,在此设定下,只有动力学在不同任务间发生变化。

或者,与其在元测试阶段完全没有奖励,我们可能仅有稀疏奖励。如果在元训练阶段有密集奖励,标准的元强化学习方法可以通过在外部循环使用密集奖励、在内部循环使用稀疏奖励直接应用(Gupta 等,2018b;Rakelly 等,2019;Zhao 等,2021)。如果元训练和元测试都仅有稀疏奖励,一种方法是在元训练阶段修改奖励函数。常用的方法是一种称为“事后任务重标记”(hindsight task relabelling)的经验重标记类型(Packer 等,2021;Wan 等,2022)。假设任务仅在奖励上不同,轨迹可以用其他任务的奖励重新标记,同时仍保持与MDP一致。训练可通过使用标准的离策略元强化学习算法进行(Rakelly 等,2019)。这在某些情况下特别有用,例如,原始任务中轨迹未达到目标状态,但在重标记后的任务中达到了。如何选择这样的任务是一个研究领域(Wan 等,2022)。或者,如果动力学不同,一种少样本方法允许策略在必要时显式地在任务间迁移,通过学习在任务之间映射动作,使得每个任务中的状态转移相似(Guo 等,2022)。另一种应对元测试阶段稀疏奖励的方法是引入辅助奖励以鼓励探索,如第3.4节所述。
通过模仿实现的元强化学习 第三种设定假设在元训练阶段可以访问专家演示,这比标准奖励提供了更强的监督。例如,机器人厨师可能可以获得由人类厨师提供的带标签监督。这种设定可以提高样本效率并减轻在线数据收集的负担。该问题设定要求访问专家策略或专家数据。如果专家事先未知,可以按任务进行训练。或者,在多样本设定中,由现有强化学习算法优化的策略可以提供监督,这一过程称为算法蒸馏(algorithm distillation)(Laskin 等,2023;Kirsch 等,2023)。为了改进现有强化学习算法,学习速度可以通过对示范数据进行子采样而非学习完整的专家数据轨迹来提升(Kirsch 等,2023)。一种方法,即引导元策略搜索(Guided Meta-Policy Search, GMPS,Mendonca 等,2019),提出在外循环中模仿任务专家。在这种情况下,外循环可以使用监督学习,而内循环仍然学习一个在元测试时基于奖励条件的强化学习算法。他们特别研究了使用专家标签来指导MAML风格算法最终策略的使用。如果专家不可用,同时训练特定任务的专家也可以导致稳定的元训练(Mendonca 等,2019)。


通过模仿实现的元强化学习目前仍相对未被充分探索。这可能是因为难以学习适用于探索性动作的正确监督信号。获取一个元强化学习专家需要知道如何在元强化学习问题中实现最优探索,而这通常是难以计算的(Zintgraf 等,2020)。因此,这些论文通常不使用通用专家,而是利用特定任务的专家——这些专家可通过在每个任务上运行标准强化学习轻松获得。然而,这些特定任务的专家仅能提供探索后行为的监督,例如在 MAML 风格算法中,经内循环一系列适应后最终策略所采取的动作。在这种情况下,对探索策略的信用分配(credit assignment)可能被忽略。一些论文使用相同的动作来同时监督必须探索的无信息策略和必须利用的有信息策略(Zhou 等,2020;Prat 和 Johns,2021);然而,在大多数环境中,探索与利用所需的动作通常是不同的。为解决这一问题,智能体可自适应地在端到端优化元强化学习目标与克隆有信息的多任务专家之间切换(Weihs 等,2021)。此外,也可以利用多任务策略生成奖励,以鼓励多任务策略与元强化学习策略之间的状态-动作分布相似,尤其在最大熵强化学习中(Nguyen 等,2022)。
元模仿学习 第四种被广泛研究的问题设定是元模仿学习(meta-imitation learning, meta-IL)(Duan 等,2017;Finn 等,2017b;James 等,2018;Yu 等,2018;Paine 等,2018;Seyed Ghasemipour 等,2019;Yu 等,2019;Goo 和 Niekum,2019;Dasari 和 Gupta,2020;Bonardi 等,2020;Singh 等,2020;Jang 等,2021;Li 等,2021a;Gao 等,2022)。虽然从技术上讲元模仿学习不属于元强化学习,因为其内循环并非强化学习算法,但它是一个密切相关的问题设定。尽管对元模仿学习方法进行全面综述超出了本文范围,我们仍在此简要介绍元模仿学习。
该设定假设在内循环中可访问每个任务的一组固定演示数据。大多数方法还在外循环中通过对固定数据进行行为克隆(behavioral cloning)来训练,这一过程也被称为元行为克隆(meta-behavioral cloning, meta-BC)。或者,外循环也可执行逆强化学习(inverse RL),我们称之为元逆强化学习(meta-IRL)(Seyed Ghasemipour 等,2019;Yu 等,2019;Xu 等,2019;Wu 等,2020;Hejna III 和 Sadigh,2022)。另一种将元学习用于逆强化学习的方法是通过少样本学习训练成功分类器(Xie 等,2018;Li 等,2021b)。与元行为克隆不同,元逆强化学习通常在线执行,因此往往需要模拟环境。对于行为克隆和逆强化学习,内循环和外循环通常都假设可访问专家提供的动作,但有一类工作考虑的内循环仅使用专家(可能是人类)访问过的状态序列,尽管部署在机器人系统上(Finn 等,2017b;Yu 等,2018;Dasari 和 Gupta,2020;Bonardi 等,2020;Jang 等,2021)。
元强化学习研究与元模仿学习研究之间存在诸多相似之处。在元模仿学习中,同样存在黑箱方法(Duan 等,2017;James 等,2018;Dasari 和 Gupta,2020;Bonardi 等,2020)、PPG 方法(Finn 等,2017b;Yu 等,2018)和任务推断方法(Jang 等,2021),以及仿真到现实(sim-to-real)方法(James 等,2018;Bonardi 等,2020)。例如,要将 MAML 适配到元行为克隆,内循环和外循环均使用离线数据上的行为克隆损失进行计算,而非使用策略梯度。一种类似 Finn 等(2017b)的 MAML 适配于元行为克隆的算法如算法 7 所示。同样,要将 RL² 适配到元行为克隆,RNN 对离线数据集进行摘要,而非在线数据,而外循环使用行为克隆。一种 RL² 适配于元行为克隆的算法如算法 8 所示。

许多当代论文在“上下文学习”(in-context learning)的名称下讨论元模仿学习问题设定(Brown 等,2020)。上下文学习通常指在序列模型的激活中进行学习,并常隐含使用变换器(transformer)(Raparthy 等,2023;Lee 等,2024)。上下文学习是一种现象,而元学习是实现它的显式方法。黑箱方法和任务推断方法可被视为两种学习激发上下文学习的方式。上下文学习既可用于指代上下文模仿学习,也可用于指代上下文强化学习(Lee 等,2024)。特别是大型语言模型,近年来获得了广泛关注(Devlin 等,2019;Brown 等,2020;Chowdhery 等,2022),它们执行上下文学习(Brown 等,2020),这可被视为显式的元模仿学习,其中每个提示(prompt)被视为一个任务。此外,这些模型还具备涌现的元模仿学习能力,即在训练过程中并未显式设计元模仿学习,但可通过文本形式将新数据集作为提示与查询一起传入模型,例如在少样本提示中(Chowdhery 等,2022),这表明元强化学习中也值得探索类似的能力。
混合监督 除了上述最常研究的设定之外,Zhou 等(2020)、Prat 和 Johns(2021)、Dance 等(2021)以及 Rengarajan 等(2022)考虑了一些相关但不同的设定。在这些设定中,内循环首先接收一个演示,随后进入一个试错式强化学习阶段。演示数据通常来自离线收集的固定数据集,但也可能由在该固定数据集上通过元模仿学习训练的独立策略提供在线数据作为补充(Zhou 等,2020)。演示数据本身可能提供监督(动作和奖励)(Prat 和 Johns,2021),也可能不提供(Dance 等,2021),或两者结合(Zhou 等,2020)。最后,在试错阶段,智能体在外循环中可能使用强化学习进行监督(Dance 等,2021),可能使用模仿学习(Zhou 等,2020),或两者的某种组合(Prat 和 Johns,2021)。
3.7 基于模型的元强化学习
到目前为止,我们讨论的大多数算法都是无模型的,即它们不学习MDP动力学和奖励的显式模型。另一种方法是显式学习此类模型,然后通过规划定义策略,或利用模型生成的数据训练策略。这种方法被称为基于模型的强化学习(model-based RL),在元强化学习中可发挥重要作用(Harrison 等,2018;Sæmundsson 等,2018;Nagabandi 等,2019b;Nagabandi 等,2019c;Galashov 等,2019;Mendonca 等,2020;Kaushik 等,2020;Lin 等,2020a;Lee 等,2020b;Perez 等,2020;Co-Reyes 等,2021a;Xian 等,2021;Hiraoka 等,2021;Seo 等,2022;Wang 和 Van Hoof,2022;Shin 等,2022)。基于模型的元强化学习方法总结见表3.6。在本节中,我们将简要综述基于模型的元强化学习方法。讨论内容有限,原因如下:大多数基于模型的方法在第3节中已有对应的无模型方法;在标准强化学习中存在的基于模型与无模型方法之间的权衡,在元强化学习中基本相同;且元强化学习文献的大部分研究集中于无模型方法。

已有多种不同类型的基于模型的元强化学习被研究。为调整模型参数,部分基于模型的元强化学习论文采用类似MAML的梯度下降方法(Mendonca 等,2020;Kaushik 等,2020;Co-Reyes 等,2021a;Nagabandi 等,2019b),部分则采用类似RL²的黑箱循环神经网络(RNN)方法(Nagabandi 等,2019b)。另一种方法是对固定数量的历史状态转移进行编码(Lee 等,2020b),或使用变分推断(Sæmundsson 等,2018;Perez 等,2020)。基于模型的元强化学习中也出现了与无模型方法相似的主题,例如超网络的使用(Xian 等,2021)和状态转移的排列不变性(Galashov 等,2019;Wang 和 Van Hoof,2022),相关内容已在第3.2节和第3.3节中讨论。
一旦环境模型被学习,即可通过在有限时间范围内优化动作序列来选择最优动作序列。通常,仅执行该序列中的第一个动作,随后重新规划。这一过程可结合现成的规划器解决元强化学习问题,称为模型预测控制(model-predictive control)(Nagabandi 等,2019b;Lee 等,2020b)。或者,部分方法仅在策略训练时将模型用于生成额外数据(Hiraoka 等,2021;Rimon 等,2022;Seo 等,2022);部分方法将基于模型的元强化学习作为标准强化学习算法中的子程序,以提高样本效率(Clavera 等,2018;Hiraoka 等,2021);还有一些方法将学习到的模型参数作为输入提供给策略,再使用标准强化学习训练该策略(Mendonca 等,2020;Lee 等,2020b;Zintgraf 等,2020;Zhao 等,2021)。
然而,在最后一种情况下,基于模型的元强化学习与任务推断方法存在显著重叠,因为学习推断任务通常意味着学习一个含潜在变量的动力学模型。由于其他假设相似,我们在第3.3节中将任务推断方法与无模型方法一并讨论。
例如,一种简单的方法是学习一个黑箱环境模型(不使用独立规划器),运行标准强化学习算法,但在策略梯度估计中使用模型生成的额外数据。模型本身通过在策略收集的相同轨迹上对转移函数和奖励函数进行最大似然估计进行训练。此类模型的伪代码见算法9。在此基础上,可直接将策略条件化于为转移或奖励模型适配的参数上,这也可被视为一种任务推断方法。

总体而言,无模型元强化学习与基于模型的元强化学习之间存在权衡。一方面,当能够学习到精确模型时,基于模型的元强化学习方法可能具有极高的样本效率(Nagabandi 等,2019b)。基于模型的方法也可进行离策略学习,因为模型可通过监督学习训练。另一方面,基于模型的元强化学习可能需要实现额外组件,尤其对于需要超越现成规划器能力的长视野任务,且其渐近性能可能较低(Clavera 等,2018;Wu 等,2022)。
最后,在元学习背景下,基于模型的强化学习可能提供两个独特优势。第一,当元训练分布中的任务数量过少时,基于模型的元强化学习可允许采样补充的(想象的)任务(Rimon 等,2022)。第二,当现成规划器可行且需要复杂探索策略时,基于模型的元强化学习可能更容易实现。在无模型元强化学习中,元学习需要同时学习“收集何种数据”和“如何收集”;而在基于模型的强化学习中,探索任务可交由规划算法处理。在内循环中让规划器处理复杂探索,可能比直接学习探索策略更容易。
3.8 元强化学习理论
元强化学习理论旨在理解和形式化支配强化学习算法学习过程的基本原理。由于元强化学习是一个相对较新的领域,其理论探索深受相关领域——如元监督学习(meta-SL)和面向强化学习的多任务表示学习——的启发。然而,元强化学习带来了额外的挑战,因为其内循环需要学习一个强化学习算法。为了从理论上理解这些挑战,许多研究者采用了贝叶斯框架。本节整合了元监督学习与表示学习理论中的核心洞见,并概述了元强化学习领域内特有的理论进展。本节所讨论的论文总结见表3.7。

来自监督元学习的洞见 元学习(包括元强化学习和元监督学习)都致力于设计能够从给定任务分布中高效学习新任务的算法。这一学习过程的一个关键方面是开发能在不同任务间泛化的表示或归纳偏置。作为早期的理论贡献,Baxter(2000)通过研究在PAC(可能近似正确,Valiant, 1984)框架下相关任务家族中的归纳偏置学习,奠定了基础性工作,其目标是找到一个对任务家族中所有任务都适用的假设空间。更近期地,Tripuraneni 等(2021)提供了关于跨任务学习到的特征如何提升在新任务中学习效率的基本结果。一个专门针对MAML(Finn 等,2017a)的相关结果由 Collins 等(2022)提出。Finn 等(2019)、Khodak 等(2019)以及 Denevi 等(2019)进一步在在线凸优化框架下研究了MAML,他们假设任务相似性概念,即所有任务在参数空间中都接近某个固定的点,从而可以提供性能保证。这些发现虽然没有直接针对元强化学习,但为理解元强化学习算法中至关重要的表示学习方面提供了有价值的洞见。
面向强化学习的多任务表示学习 面向强化学习的多任务表示学习与元强化学习密切相关,因为它考虑的是在一组任务之间学习共享表示。然而,在表示学习中,学习探索策略或更一般地学习学习算法本身并不被考虑。尽管如此,这两个设定足够接近,使得多任务表示学习的理论成果可以为发展元强化学习的理论理解提供有益指导。
Yang 等(2020)和 Hu 等(2021)研究了线性MDP中的表示学习。他们展示了在一组并行任务上的遗憾界会随着任务集合中相关任务数量的增加而改善。此外,Cheng 等(2022)揭示了在低秩MDP(Agarwal 等,2020)中进行多任务表示学习,当任务总数超过某个阈值时,能显著提高样本效率。他们的发现强调了在下游任务中使用学习到的表示的效率,从而说明了多任务表示学习在强化学习中的实际益处。
元强化学习特有的理论进展 尽管专门研究元强化学习理论的研究仍有限,但已取得一些重要成果。特别是,关于元强化学习算法泛化边界的成果,为第2节中引入的少样本与多样本方法划分提供了原则性的动机。
Simchowitz 等(2021)、Tamar 等(2022)和 Rimon 等(2022)聚焦于元强化学习中的泛化问题。Tamar 等(2022)提供了关于学习近似贝叶斯最优策略(即优化公式2.3的策略)所需训练任务数量的PAC边界。Rimon 等(2022)表明该边界随任务分布 p(M)的自由度呈指数级增长。这些结果为解释为何元强化学习方法在窄任务分布上表现良好但在更广泛的任务分布上表现不佳提供了原则性解释。而 Tamar 等(2022)和 Rimon 等(2022)关注的是分布内泛化,Simchowitz 等(2021)则研究了分布外泛化问题,通过考虑Thompson采样算法中先验的错设情况来探讨,这类算法在元强化学习中常被考虑(Rakelly 等,2019)。
继续从贝叶斯视角出发,Chen 等(2022)将贝叶斯最优策略与任意MDP实例下的最优策略相比,给出了遗憾的上界,其中MDP实例是在先验下可能存在的。虽然 Chen 等(2022)关注最坏情况遗憾,Ye 等(2023)则给出了期望遗憾的上界。此外,他们还提出了一种基于策略消除的预训练和微调算法,实现了良好的遗憾表现。
最后,针对类似MAML的方法(Finn 等,2017a)正在进行持续的理论研究。Fallah 等(2021)推导出一种MAML算法变体的样本复杂度。Liu 等(2022b)和 Tang(2022)研究了MAML梯度估计器的偏差和方差,后者提出了一种具有有利偏差-方差权衡的新梯度估计器。
4 Many-shot Meta-RL
原文链接:https://arxiv.org/pdf/2301.08028v4#page=38.05
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号