独立性假设下的神经符号推理捷径

独立性假设下的神经符号推理捷径

CreateAMind
发布于 2026-03-11 17:37:50
发布于 2026-03-11 17:37:50
独立性假设下的神经符号推理捷径
Neurosymbolic Reasoning Shortcuts under the Independence Assumption
https://www.arxiv.org/pdf/2507.11357
概述:本文探讨了神经符号(NeSy)预测模型中广泛采用的独立性假设,即假设符号概念在给定输入下条件独立。虽然此假设简化了概率推理,但通过理论和实证分析指出其缺陷:它限制了模型对不确定性的表达,导致对“推理捷径”(RS)的觉知不足。这些捷径指模型虽正确预测下游任务,但基于错误原因(如过度自信),损害了可靠性和泛化能力。论文通过形式化定义RS-awareness并以XOR MNIST数据集为例,证明独立性假设使模型无法正确表示概念组合的不确定性,建议采用更具表达力的模型以提升NeSy系统的透明度和鲁棒性。
推荐理由
- 学术价值 :作为NeSy领域2025年新进展,论文深化了独立性假设的理论分析,适合AI/ML研究者关注神经符号推理的最新动态。
- 实践指导 :揭示推理捷径成因并提出优化建议,有助于开发者设计更可靠的NeSy模型,特别在安全关键应用中。
- 跨领域意义 :结合符号逻辑与神经网络,强调不确定性表示的重要性,激发对概率模型改进的思考。


摘要 在神经符号(NeSy)预测器中,符号概念之间的普遍独立性假设是一种便捷的简化:NeSy预测器利用该假设以加速概率推理。近期的研究,如van Krieken等(2024)和Marconato等(2024)指出,这一独立性假设可能阻碍NeSy预测器的学习,更关键的是,会妨碍其正确建模不确定性。然而,NeSy社区对此仍存疑虑,认为独立性假设实际限制NeSy系统的情形尚不明确(Faronius 和 Dos Martires, 2025)。在本工作中,我们通过形式化证明解决了这一争议:假设符号概念之间相互独立,意味着模型永远无法表示某些概念组合的不确定性。因此,模型将无法察觉推理捷径——即NeSy预测器的一种病态行为:虽然对下游任务做出正确预测,但却是基于错误的理由。
- 引言 神经符号(NeSy)预测器是一类结合神经感知与符号推理的模型(Manhaeve 等, 2021;Xu 等, 2018;Badreddine 等, 2022;Feldstein 等, 2024;Ahmed 等, 2022;De Raedt 等, 2019;Hitzler 等, 2022;Garcez 和 Lamb, 2023),旨在构建更具透明性与可靠性的机器学习系统,尤其适用于安全关键型应用(Giunchiglia 等, 2023)。一种常见方法是概率型NeSy预测器(Xu 等, 2018;Manhaeve 等, 2018;Ahmed 等, 2022;van Krieken 等, 2023)。首先,它们使用神经网络提取输入的符号概念的概率;随后,借助可解释的符号程序进行概率推理(Darwiche 和 Marquis, 2002),以预测最终标签。若有效运用,这种方法可产生可解释且可靠的AI系统。
当数据与程序共同不足以充分约束神经网络时,NeSy预测器可能会学习到推理捷径(RSs)(Marconato 等, 2023)。推理捷径是指从输入到概念的错误映射,这些映射虽与程序和数据一致,但本质上是错误的。不幸的是,一旦NeSy预测器学习到RS,它就无法在分布外数据上泛化,从而破坏了NeSy预测器所承诺的可靠性。如果我们无法避免RS,该怎么办?Marconato 等(2024)主张应使我们的预测器意识到RS的存在。这实质上意味着要对所有与数据一致的概念赋值表示不确定性。为突出这一思想,我们考虑XOR MNIST任务。

大多数概率型NeSy预测器的应用都依赖一个关键的简化假设,即神经网络提取的概念之间是条件独立的(van Krieken 等, 2024)。这一假设简化并加速了原本在一般情况下难以计算的推理过程(Chavira 和 Darwiche, 2008)。然而,van Krieken 等(2024)表明,独立性假设会导致损失函数出现不连通且非凸的极小值点,从而加剧训练难度,并阻碍模型表达概念间的依赖关系。此外,该假设还会使解偏向“确定性”,即仅少数概念获得全部概率质量。这些结果最近被 Faronius 和 Dos Martires(2025)质疑,他们认为 van Krieken 等(2024)所研究的设定并不能反映NeSy预测器的典型使用场景。
我们通过形式化论证与实证分析表明,即使在这些典型场景中,独立性假设仍然是一个关键的限制因素:例如,在示例1的XOR MNIST问题中,独立性模型不可能实现对推理捷径(RS)的感知——它们要么随机猜对,要么只能发现图1中的RS。特别地,我们证明Faronius 和 Dos Martires(2025)的结论存在混淆,因为他们所使用的任务本身并不包含任何RS。
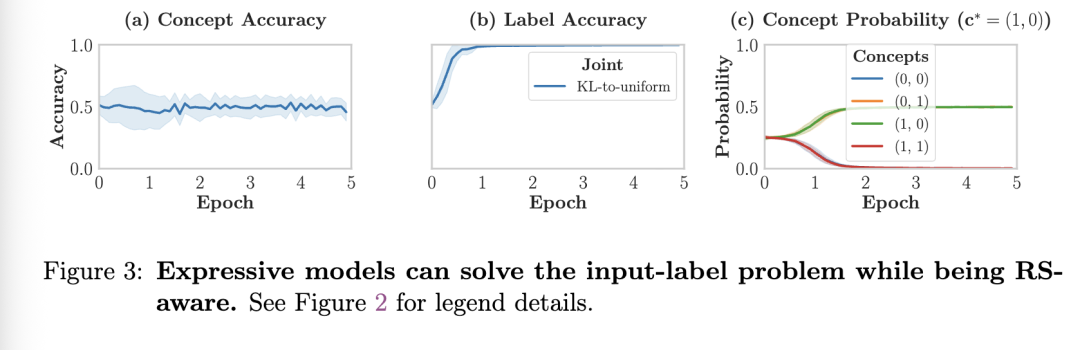
贡献。我们: C1)在第4节中形式化定义了NeSy预测器对推理捷径的感知能力; C2)证明了在独立性假设下,NeSy预测器仅在极其罕见的情况下才能实现RS感知; C3)并通过实证表明,具备表达力的模型确实可以实现RS感知(第3节),但前提是必须采用恰当的架构设计与损失函数设计,相关内容将在第5节中讨论。
- 背景:NeSy 预测器与推理捷径


然后,该模型被用于计算公式1中的数据对数似然。隐式地,大多数实际的NeSy预测器都做出这一假设(Xu等,2018;Badreddine等,2022;van Krieken等,2023)。当 k>1时,独立的概念分布无法表示 C上所有可能的分布。此外,van Krieken等(2024)证明,NeSy预测器的损失函数通常具有以下特性:1)高度非凸;2)存在不连通的极小值点;3)在缺乏证据的情况下,倾向于偏向过度自信的假设。所有这些问题都是由于独立分布表达能力有限所导致的后果。
许多概率型NeSy预测器(Xu等,2018;Manhaeve等,2018;Ahmed等,2022)通过在某种紧凑的逻辑表示上进行高效的概率推理来实现公式1(Darwiche和Marquis,2002)。独立性假设之所以被广泛采用,是因为它极大地简化了通常不可行的计算过程(Chavira和Darwiche,2008)。常见的神经概率逻辑编程语言,如DeepProbLog(Manhaeve等,2018,2021)、NeurASP(Yang等,2020)和Scallop(Li等,2023),也都假设符号之间是独立的,或更准确地说,在程序中对概率事实之间假设独立性。因此,对于一个固定的程序 β和固定数量的概率事实,存在许多真实的数据分布涉及依赖关系,这些依赖关系无法被精确捕捉,无论神经网络的表达能力如何。然而,这些语言是图灵完备的概率语言,理论上可以表示任意分布(Taisuke,1995;Poole和Wood,2022;Faronius和Dos Martires,2025)。我们通过指出:只有通过扩展程序 β并引入额外的概率事实,才能实现这种可能性,从而解决了这一表面上的矛盾。例如,我们可以通过为独立分布上的混合模型添加潜在变量,或通过贝叶斯网络引入结构化依赖关系,从而超越独立性假设,正如本文所讨论的那样。尽管如此,在实践中,尤其是在使用固定程序 β的共享基准上对NeSy预测器进行经验评估时(Bortolotti等,2024),这种程序扩展并不存在,公式1是通过公式2实现的。
形式化问题设定。接下来,我们描述数据生成过程中所依据的形式化假设,遵循 Marconato 等(2023)。具体而言,我们使用以下数据的真实生成过程:



3. 何时独立性假设是合适的?

3.1 独立性假设在推理捷径下失效



3.2 我们能否训练出具有感知推理捷径能力的表达性模型?
如果独立模型无法在 XOR MNIST 任务中表示不确定性,那么更具表达能力的模型又如何呢?从表达能力的角度来看,答案是肯定的。但我们是否也能学习到一个校准良好、具备推理捷径感知能力的概念分布 pθ(c∣x)?
正如 Faronius 和 Dos Martires(2025)以及 Zombori 等(2024)所指出的,表达性模型在训练过程中同样倾向于偏向“确定性”。然而,巧妙设计的损失函数可以规避这一问题(Zombori 等,2024)。我们最小化概念空间上均匀分布的 KL 散度。对于每一对 (x,y)(Mendez-Lucero 等,2024),
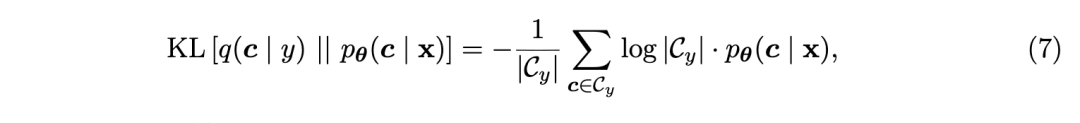

在图 3 中,我们看到模型不仅学习了输入-标签映射,而且当输入数字不同时,还会将 0.5 的概率分配给两种有效概念组合 (0,1) 和 (1,0)。因此,该模型学会了 RS 感知的概念分布。我们强调,这只有在模型不具有独立性假设的前提下才可能实现。事实上,正如我们在附录 B 中所示,使用公式 7 进行独立性假设的方法无法学习到超出模型初始化的任何内容。
- 具有独立性假设的模型无法具备推理捷径意识


接下来,我们给出 RS 意识的精确定义,我们将之理解为表达这些 RS 混合的能力。我们区分完全混合与弱混合:完全混合指能够表达所有混合形式,而弱混合仅要求能够表达其中一种混合形式。

我们的目标是研究在何种条件下,具有独立性假设的模型能够具备 RS 意识。因此,我们必须精确定义我们所指的这一模型类。为简化起见,我们采用独立性假设下可能最强大的模型类。在现实场景中,我们只能近似地实现这一模型类。


- 表达能力与架构设计

- 结论
我们研究了在何种条件下,对神经符号(NeSy)预测器采用独立性假设是合适的。我们证明了,具有独立性假设的模型仅在非常有限的场景中才能具备对推理捷径(RSs)的意识。这限制了采用独立性假设的 NeSy 预测器的可靠性,意味着它们可能在分布外(out-of-distribution)情况下无声地失效。最后,我们表明,超越独立性假设的表达能力强的模型可以具备 RS 意识。然而,我们也发现,神经网络的设计是一个关键因素。
基于这些结果,研究何种表达性强的架构设计更适合 NeSy 预测器,是一个富有前景的未来研究方向。现有工作已使用独立模型的混合体(Marconato 等,2024),当结合概率电路(Ahmed 等,2022)和离散扩散模型(van Krieken 等,2025)时,这种方法尤为强大,并在 RSBench 数据集(Bortolotti 等,2024)上显著优于独立模型。此外,我们认为,研究超越“完全可观测性”这一朴素假设(第 2 节中的假设 A1)的基准任务,将有助于揭示具有独立性假设与不具独立性假设的 NeSy 预测器之间的行为差异。



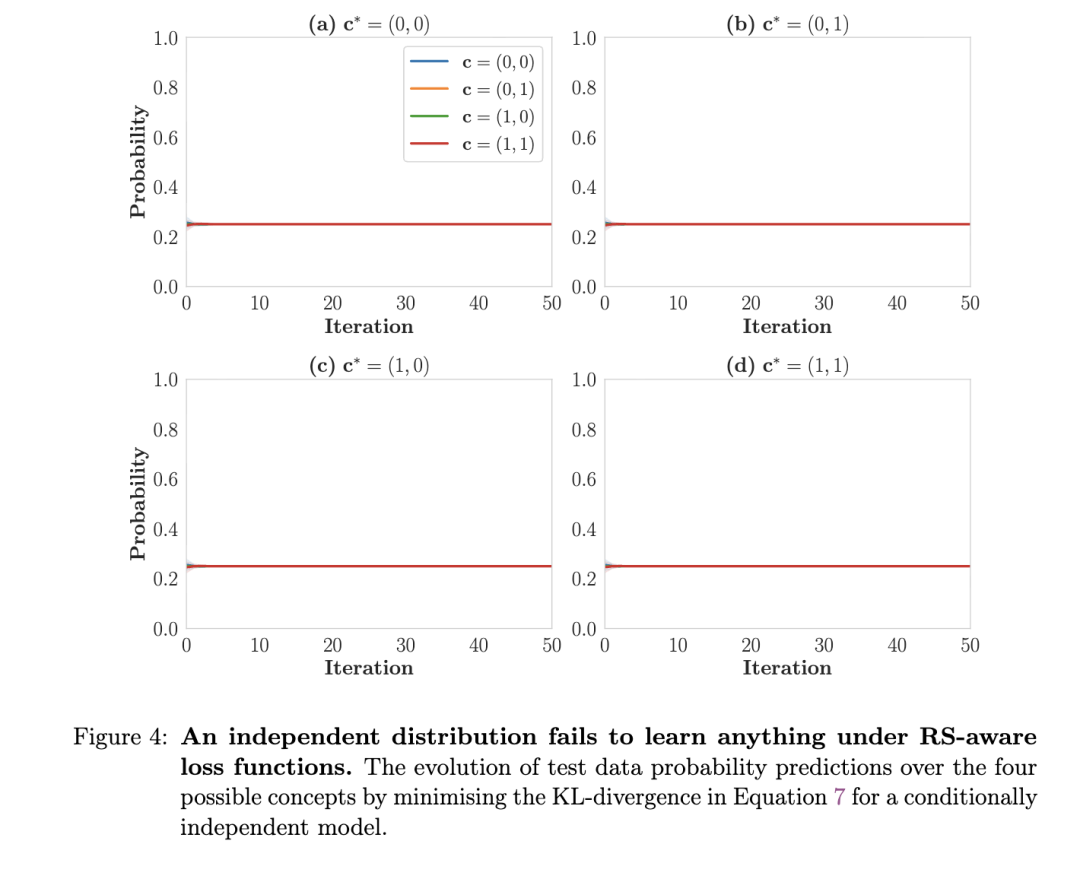
附录 B. 最小化独立模型的均匀-KL 散度
如图 4 所示,当我们使用第 3.2 节中适应独立性假设的 KL 散度和神经网络架构时,我们无法学习到超出模型初始化的任何内容。这看起来可能像是一个错误,但实际上并非如此:在独立性假设下,当 c1和 c2的概率均为 0.5 时,KL 散度在奇偶性问题(parity problem)中达到最小值,无论输入和标签如何。⁴
附录 C. 实验细节
数据集构建。我们从 MNIST 数据集中选取数字 0 和 1,然后通过随机排列剩余数字来构造数字对。这样可以确保每个数字在每一对中仅出现一次,并且不会发生测试数据泄露。我们使用标准的 MNIST 训练-测试划分来创建测试集。接着,我们使用程序 β分别为 XOR MNIST 和 Traffic Lights MNIST 问题生成标签。
训练细节。我们的代码可在 https://github.com/HEmile/independence-vs-rs/tree/main 获取。所有实验均在训练数据上运行 5 个 epoch。我们未进行任何超参数调优:所有实验均使用 Adam 优化器、学习率为 0.0001、批量大小为 64。
统计方法。所有结果均在 20 个随机种子上取平均,并报告结果的均值和标准差。在表 1 中,我们用粗体标出那些与表现最佳的模型-损失组合在 p=0.05水平下无统计显著差异的结果(使用非配对 Mann-Whitney U 检验)。我们强调,多个结果(尤其是 XOR MNIST)具有高度双峰分布特性,这意味着即使在 20 次运行中,有时也存在较大的平均值差异,但统计上并无显著区别。
模型架构。我们在 XOR MNIST 和 Traffic Lights MNIST 任务中均以标准 LeNet CNN 架构为基础构建所有模型。该架构包含一个 CNN 编码器和一个 MLP 分类器。具体而言,它使用两个带有最大池化和 ReLU 激活函数的卷积层,将特征拼接成一个 256 维的嵌入。随后,我们使用一个隐藏层将其映射到 120 维和 84 维的嵌入,每个都使用 ReLU 激活函数。最后,我们使用一个 sigmoid 输出层,输出一个由 sigmoid 函数激活的单个 logit 值。


原文链接:https://www.arxiv.org/pdf/2507.11357
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号