MPG-SAM 2:结合掩码先验和全局上下文适配SAM 2以进行参考视频对象分割

MPG-SAM 2:结合掩码先验和全局上下文适配SAM 2以进行参考视频对象分割

CreateAMind
发布于 2026-03-11 17:08:03
发布于 2026-03-11 17:08:03
MPG-SAM 2: Adapting SAM 2 with Mask Priors and Global Context for Referring Video Object Segmentation
MPG-SAM 2:结合掩码先验和全局上下文适配SAM 2以进行参考视频对象分割
https://www.arxiv.org/pdf/2501.13667


摘要 参考视频对象分割(Referring Video Object Segmentation, RVOS)旨在根据文本描述对视频中的对象进行分割,这需要整合多模态信息和时间动态感知能力。Segment Anything Model 2(SAM 2)在各种视频分割任务中展现了卓越的效果。然而,其在离线RVOS中的应用面临两个主要挑战:将文本转化为有效的提示以及缺乏全局上下文感知。本文提出了一种新颖的RVOS框架,称为MPG-SAM 2,以应对这些挑战。具体而言,MPG-SAM 2采用多模态编码器联合编码视频和文本特征,生成语义对齐的视频和文本嵌入,以及多模态类别标记。设计了一个掩码先验生成器,利用视频嵌入和类别标记为目标对象及全局上下文生成伪掩码。这些掩码作为密集提示输入到提示编码器中,同时多模态类别标记作为稀疏提示,以生成适用于SAM 2的精确提示。为了为在线SAM 2提供全局视角,我们提出了一种分层的全局-历史聚合器,使SAM 2能够在像素级和对象级聚合目标对象的全局和历史信息,从而增强目标表示和时间一致性。在多个RVOS基准上的广泛实验表明了MPG-SAM 2的优越性以及所提模块的有效性。
1 引言 参考视频对象分割(Referring Video Object Segmentation, RVOS)[20, 26, 29, 42]旨在根据文本描述对视频中的目标对象进行分割。这项任务结合了视频分割和语言理解,不仅需要在传统视频对象分割(Video Object Segmentation, VOS)[1, 6, 31]中具备分割能力和帧间信息传播能力,还需要对更广泛的视频上下文中所提及的文本具有强大的理解能力。因此,RVOS的核心挑战在于高效对齐多模态信息并保持时间一致性。
最近,Segment Anything Model(SAM)[18]及其变体[16, 43, 51]在图像提示分割任务中展现了显著的效率和准确性提升,利用了强大的分割能力和交互式提示。SAM 2 [34]通过引入记忆机制增强时间一致性,将提示分割从图像领域扩展到视频领域,在VOS任务中取得了卓越的表现。然而,其在RVOS中的应用仍面临若干挑战。
首先,SAM 2架构中固有的缺乏文本提示的问题阻碍了生成与提供的文本描述相匹配的精确提示,如图1(a)所示。尽管一些研究探索了这一领域,但仍需进一步改进。例如,RefSAM [22]将文本嵌入投影为稀疏和密集提示以供SAM使用,但独立编码的文本提示可能无法完全捕捉视觉语义,限制了SAM分割能力的有效利用。AL-Ref-SAM 2 [15]采用GPT-4和Grounding DINO [24]将文本信息转化为目标对象的框提示,但其多阶段流水线高度依赖上游模型的时空推理能力,且庞大的模型参数量限制了部署和推理效率。因此,如何有效对齐视觉-语言特征并提供精确提示以指导解码过程,是将SAM 2适配到RVOS的关键。
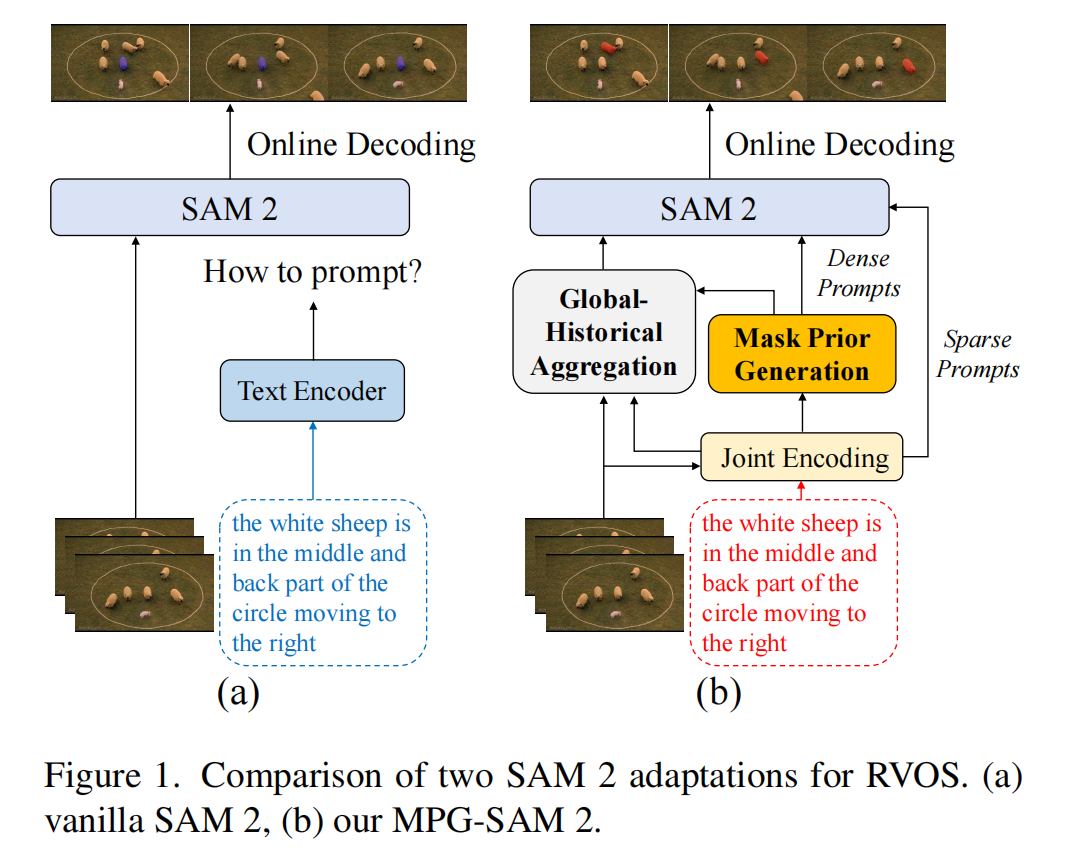
其次,在线模式下的SAM 2仅具有历史视角,而无法为离线模式下的RVOS提供全局视角,这可能会影响多模态信息的全局对齐以及目标对象的时间一致性。因此,将目标对象的全局上下文信息有效注入SAM 2对于RVOS至关重要。
为了解决这些挑战,本文提出了MPG-SAM 2,一种基于SAM 2改进的新型端到端RVOS框架。如图1(b)所示,我们的核心创新在于通过对齐的视频-文本特征生成精确提示和全局上下文,并将其注入SAM 2。具体而言,我们首先采用现有的多模态编码器联合编码输入视频和文本,生成语义对齐的视频和文本嵌入,以及多模态类别标记。然后,我们设计了一种新颖的掩码先验生成器,利用视频嵌入和多模态类别标记为目标对象生成每帧视频的伪掩码,作为SAM 2的密集提示,为掩码解码提供强大的位置引导。此外,遵循[52]的做法,我们将多模态类别标记通过多层感知机(MLP)后发送到提示编码器,作为稀疏提示。通过结合强大的密集和稀疏提示,为掩码解码器提供了精确提示,从而提升了性能。
为了将目标对象的全局上下文信息引入SAM 2,我们设计了一种分层的全局-历史聚合器,使SAM 2能够在掩码解码器之前从多个层次聚合目标对象的全局上下文和历史信息。这里的全局上下文主要来源于掩码先验生成器生成的全局视频特征。该聚合器由像素级和对象级融合模块组成。在像素级模块中,当前图像特征依次与SAM 2记忆中的历史特征和全局上下文交互,从而从多个角度增强像素级目标表示。类似地,在对象级模块中,掩码标记从全局视频特征和记忆中的历史掩码标记中聚合目标表示信息,生成用于掩码解码器的对象标记。
在多个RVOS基准上的实验结果表明,我们的模型达到了最先进的性能,所提出的模块也证明了其有效性。本工作的主要贡献可以总结如下:
• 我们提出了一种新颖的RVOS框架MPG-SAM 2,基于SAM 2引入了基于掩码先验的密集提示和多层次全局上下文融合,实现了在多个RVOS基准上的前沿性能。 • 我们设计了一种掩码先验生成器,利用全局视频特征和多模态类别标记为目标对象生成伪掩码,提供先前的位置线索作为密集提示,从而增强SAM 2的掩码解码能力。 • 我们开发了一种分层的全局-历史聚合器,将目标对象的全局上下文和历史记忆信息在像素级和对象级整合到SAM 2中。该模块使在线模式的SAM 2能够具备全局视角,增强了目标表示和时间一致性。
2 相关工作 参考视频对象分割(Referring Video Object Segmentation, RVOS) RVOS因其连接了视觉和语言领域而引起了广泛关注。早期方法,如RefVOS [2],将RVOS视为参考图像分割(Referring Image Segmentation, RIS)在视频领域的扩展。URVOS [35]通过结合RIS和半监督视频对象分割,在统一框架中使用注意力机制推进了这一方向。在后续研究[12, 21, 28, 38, 40]中,研究人员强调跨模态交互,进一步提升了RVOS的性能。然而,尽管取得了显著进展,多阶段流水线的计算成本和复杂性限制了其实际可行性。作为回应,基于查询的Transformer架构提供了高效解决方案,简化了框架但依然保持鲁棒性。特别是,MTTR [3]和ReferFormer [42]开创性地将DETR系列[5, 53]引入RVOS,提出了新颖的多模态交互机制。最近的方法[20, 26, 29, 36]通过先进的时序和多模态特征集成技术进一步优化了这些Transformer架构。例如,SgMg [29]通过用分割优化器替换动态卷积并利用光谱信息引导视觉特征融合,增强了ReferFormer的表现。SOC [26]在视频和对象级别实施分层时序建模,实现了早期多模态融合。最近,Losh [49]提出了一种联合预测网络,用于处理短句和长句,减少了动作和关系线索在分割中的过度影响。VD-IT [54]探索了文本到视频扩散模型在RVOS任务中的潜力,利用视频生成模型固有的丰富语义和一致的时间对应关系来确保时间实例一致性。为了应对MeViS [11]数据集中的更长序列和复杂场景,DsHmp [14]提出了一种静态文本解耦策略,增强了帧级和对象级静态与动态内容的时间理解能力,从而捕捉短期和长期运动洞察。
Segment Anything Model(SAM) SAM [18]是一种交互式分割模型,能够根据各种提示生成非语义掩码。经过大规模数据集训练,SAM在广泛常见对象上展现出强大的泛化能力。一些变体[16, 43, 51]专注于提高SAM的分割精度和计算效率。此外,SAM在多个领域得到了广泛应用,包括视频跟踪[8]、遥感图像解释[37]和医学图像处理[50]。最近,SAM 2 [16]将SAM扩展到视频领域,达到了最先进的性能。尽管SAM在使用框、点或掩码提示的视觉分割任务中表现出色,但它缺乏语言理解能力,无法直接处理参考分割任务。随着多模态大语言模型(Multimodal Large Language Models, MLLMs)的发展,最近的一些方法[19, 33, 44]利用MLLM对文本指导进行编码以实现SAM分割。具体而言,LISA [19]微调了LLaVA [23],通过提取特定提示的隐藏嵌入生成多模态特征。uLLaVA [44]扩展了这一方法,支持区域和像素级别的联合多任务处理。GLaMM [33]整合了视觉定位任务,并结合语言响应为模型提供多粒度分割提示。最近,EVF-SAM [52]引入了一种轻量级预融合架构,采用联合视觉-语言编码生成高质量的文本提示,从而实现了卓越的分割性能。
3 方法
3.1. 概述
我们提出的MPG-SAM 2的整体框架如图2所示。MPG-SAM 2由四个主要组件构成:多模态编码器、提出的掩码先验生成器、设计的分层全局-历史聚合器以及SAM 2。给定一个包含T帧的视频序列V = {It}和其对应的文本描述E = {el}(包含L个单词),多模态编码器首先对每一帧进行独立的联合编码,提取多模态[CLS]标记、视频块嵌入和文本嵌入。同时,SAM 2的图像编码器独立提取视频帧特征。掩码先验生成器接收视频块嵌入和多模态[CLS]标记,生成全局视频特征并为每一帧生成先验掩码。这些先验掩码与多模态[CLS]标记一起作为SAM 2的提示。分层全局-历史聚合器整合全局视频特征、文本嵌入以及来自SAM 2记忆中的历史掩码特征和标记,分层增强像素级图像特征和对象级对象标记的目标表示。最后,SAM 2的解码器基于提供的提示、对象标记和当前图像特征进行在线解码,以获得当前帧的精确目标掩码。
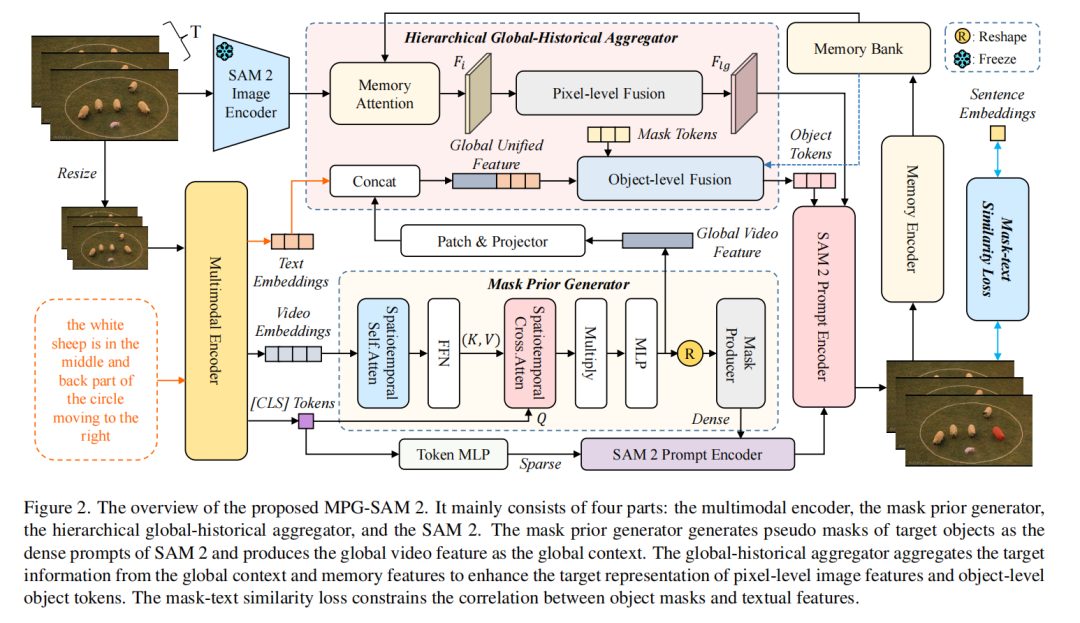
3.2. 特征提取

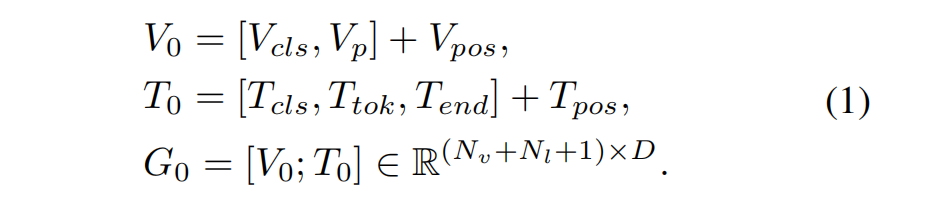

3.3. 掩码先验生成器 尽管在视频图像块嵌入 V和文本嵌入 T之间的语义对齐已被证明具有显著效果,我们发现当前框架中存在两个关键限制:(1) SAM 2 的视频特征 F固有地缺乏语言上下文,导致其与文本表示之间存在语义差距;(2) [CLS] 标记的帧无关特性限制了其建模视频序列中时间依赖性的能力,往往会导致分割伪影,包括目标错位和时间不一致性。为缓解这些限制,我们提出了一种新颖的方法,通过将 [CLS] 标记与语言增强的视频图像块嵌入融合,生成特定于帧的伪掩码先验。这些动态生成的先验提供了精确的像素级指导,显著增强了 SAM 2 的解码过程。



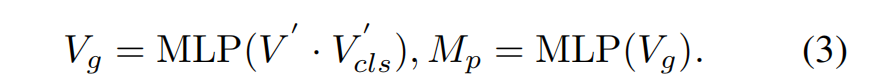

3.4. 分层全局-历史聚合器 与主要依赖过去信息的 VOS(视频目标分割)不同,RVOS(引用视频目标分割)强调对时间线索和文本线索的有效利用。受 [7] 的启发,我们提出了一种分层全局-历史聚合器,该聚合器将 SAM 2 的记忆机制与多级时间建模协同结合,从而在像素级和目标中心级实现全局上下文与历史分割结果的全面整合。如图 3 所示,分层全局-历史聚合器包含两个组件:像素级融合模块和目标级融合模块。
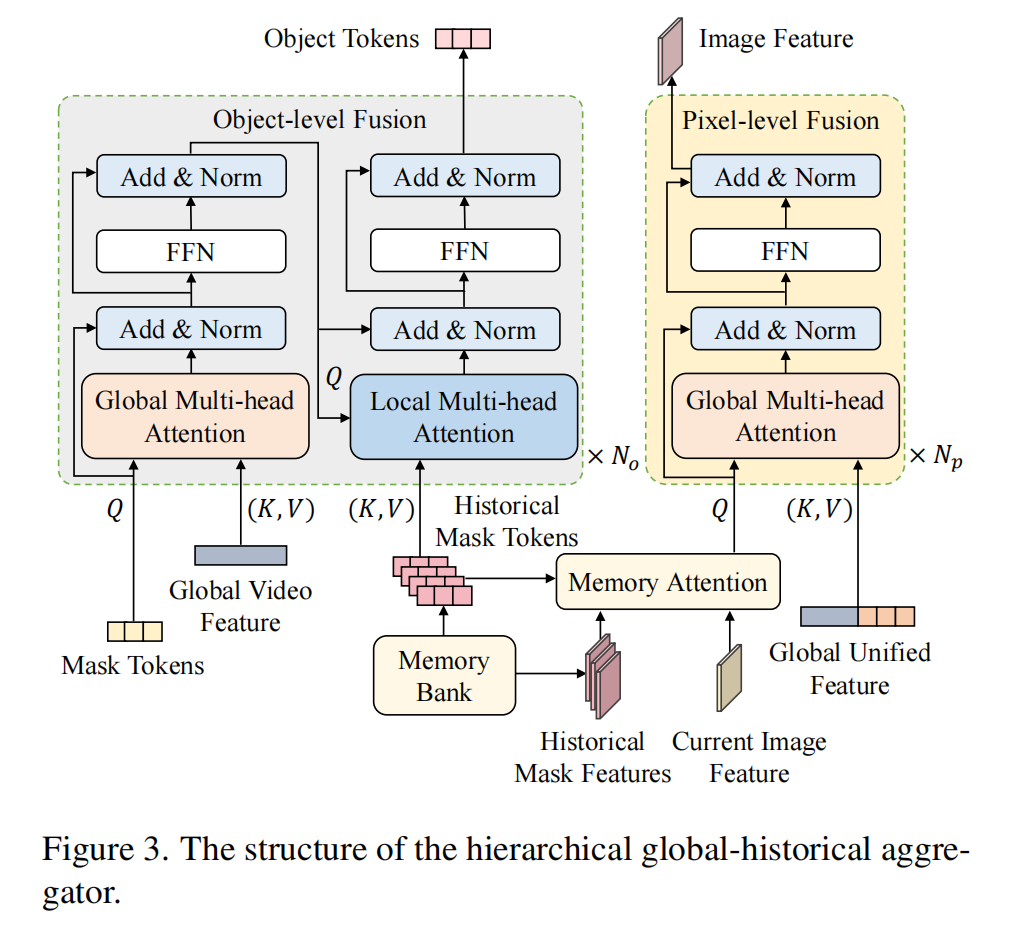

3.5. SAM 2 提示编码器与掩码解码器
在 MPG-SAM 2 中,提示编码器处理两种不同类型的提示:稀疏提示和密集提示。对于稀疏提示,按照 EVF-SAM [52] 的方法,我们将多模态编码器中的 [CLS] 标记 Vcls通过一个标记 MLP 投影,然后将其与零初始化的稀疏标记拼接,形成稀疏提示。密集提示则通过对来自掩码先验生成器的掩码先验 Mp进行上采样(通过线性插值)生成,以确保与 SAM 2 特征维度的空间对齐。
SAM 2 掩码解码器旨在协同利用这两种提示类型:(1) 稀疏提示与目标标记拼接,形成解码器的目标级查询;(2) 密集的像素级提示逐元素添加到视频帧特征中,为高分辨率特征层提供直接指导。尽管原始的 SAM 2 架构并不天然支持同时处理这两种提示类型,我们的修改实现了多模态稀疏嵌入与密集伪掩码先验的有效整合。这一架构改进显著增强了掩码解码器解析文本引用对象的能力,这对 RVOS 性能至关重要。
3.6. 训练损失
MPG-SAM 2 采用与 [42] 类似的总体损失函数,以约束预测掩码,如下所示:
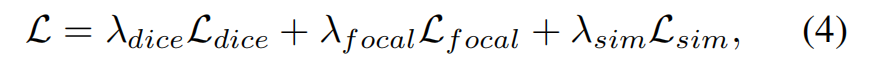
这里,Ldice 是 DICE 损失 [30],Lfocal 表示二值掩码的焦点损失(focal loss),而 Lsim 表示掩码-文本相似性损失,具体如下所述。
掩码-文本相似性损失(Mask-text Similarity Loss) :在 RVOS 任务中,评估分割掩码与真实掩码之间的相似性是至关重要的。然而,除了传统的基于掩码的评估标准外,还可以引入一种掩码-文本损失函数来评估分割结果。文本与掩码之间的相似性可以作为一种额外的评估指标。具体来说,我们使用句子嵌入 Ts 作为文本嵌入 T 的抽象表示,并通过 MLP 层将其在维度上压缩为一个标量,随后再扩展至与掩码相同的维度,并以此作为输出,用于计算文本与预测掩码 Mpre 之间的像素级相似性 Stp,以及文本与真实掩码 Mgt 之间的像素级相似性 Stg:

4. 实验
4.1. 数据集与评估指标
数据集(Datasets) :实验在几个关键的 RVOS 数据集上进行:Ref-YouTube-VOS [35]、MeViS [11] 和 Ref-DAVIS17 [17]。 Ref-YouTube-VOS 是 RVOS 领域中广泛认可的大规模数据集,其训练集包含 3471 个视频和 12913 条表达式,验证集包含 202 个视频和 2096 条表达式。 MeViS 是一个新建立的数据集,专注于运动分析,包含 2006 个视频和 28570 条标注。 Ref-DAVIS17 基于 DAVIS17 [32] 数据集构建,并为多种对象添加了语言标注,共包含 90 个视频。
评估指标(Evaluation Metrics) :我们遵循 [35] 中提出的标准化评估框架,采用区域相似性 J、轮廓准确性 F 及其平均值 J&F 作为评估指标,在 Ref-Youtube-VOS、MeViS 和 Ref-DAVIS17 的验证集上对模型进行评估。 由于 Ref-Youtube-VOS 和 MeViS 验证集的公开真实标注不可获取,我们通过官方服务器提交预测结果以获得评估结果。
4.2. 实现细节
模型设置(Model Settings) :我们使用 SAM 2-HieraLarge [34] 和 BEiT-3-Large [39] 的预训练权重来初始化 SAM 2 的相关模块和多模态编码器。 在特征解析过程中,每张图像分别被缩放到 1024×1024 和 224×224 的分辨率,作为输入提供给 SAM 2 图像编码器,其输出维度 C 为 256;以及多模态编码器,其输出维度 D 为 1024。 在层次化全局-历史聚合器中,像素级融合中用于全局视频特征的 patch 大小 pg 设为 2。像素级融合层数 Np 和对象级融合层数 No 均设为 1。 内存库的配置与 SAM 2 [34] 类似,最大可存储 7 帧历史掩码特征和 16 个掩码 token。
训练细节(Training Details) :由于 MeViS [11] 数据集的特定配置导致其对内存需求较高,实验是在 8 块 NVIDIA A800 GPU 上进行的,而其余数据集则使用 8 块 NVIDIA GeForce RTX 4090 GPU 进行训练。 MeViS 数据集的训练设置类似于 [14],每次训练输入 8 帧,并且在没有在 RefCOCO/+/g [27, 47] 上进行任何预训练的情况下直接对该数据集进行训练。 训练共进行 6 个 epoch,使用 AdamW 优化器 [25],学习率设为 2e-6。 对于 Ref-YouTube-VOS [35] 和 Ref-DAVIS17 [17] 数据集,我们采用类似 [29, 42] 的方法:首先在 RefCOCO/+/g [27, 47] 数据集上进行 10 个 epoch 的预训练,然后在 Ref-YouTube-VOS 上进行 6 个 epoch 的微调。 预训练阶段的 batch size 设为 8,学习率为 1e-5;微调阶段的 batch size 设为 1,学习率为 2e-6,每次输入 5 帧。 为了更好地与其他模块的预训练参数保持一致,我们将层次化全局-历史聚合器和掩码先验生成器的学习率设为 5e-5。 训练完成后,该模型无需额外训练即可在 Ref-DAVIS17 数据集上进行验证。 不同损失项的损失权重设置如下:λfocal = 2,λdice = 5,λsim = 2。
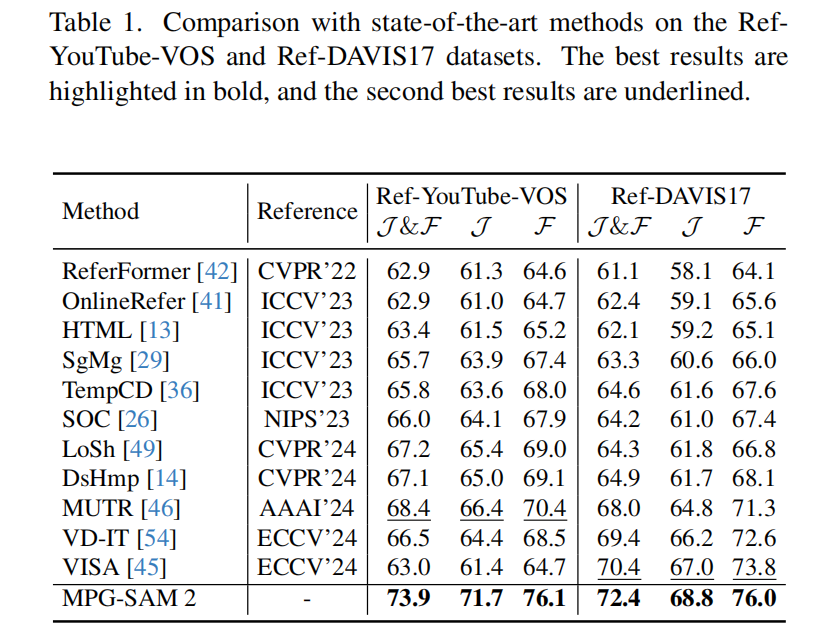
4.3. 与现有最先进方法的比较 Ref-YouTube-VOS 和 Ref-DAVIS17 数据集。 我们将所提出的 MPG-SAM 2 方法与几种最先进的方法进行了比较,结果如表1所示。我们的方法在两个数据集上均优于所有现有方法。在 Ref-YouTube-VOS [35] 数据集上,我们取得了 73.9% 的 J &F 分数,超过了最佳方法 DsHmp [14] 达 6.8% J &F,超过了 LoSh [49] 达 6.7% J &F。即使与使用额外训练数据的方法相比,我们的模型也表现出竞争力,超过 MUTR [46] 5.5% J &F。在 Ref-DAVIS [17] 数据集上,我们的方法达到了 72.4% 的 J &F 分数,比 VD-IT [54] 高出 3.0% J &F,并且超过了在额外数据集上训练的 VISA [45] 2.0% J &F。所有对比方法都采用了最优配置以突出模型性能。
MeViS 数据集。 我们还在 MeVis [11] 数据集上对 MPG-SAM 2 与现有方法(包括 URVOS [35]、LBDT [12]、MTTR [4]、ReferFormer [42]、VLT+TC [10]、LMPM [11]、VISA [45] 和 DsHmp [14])进行了对比实验,结果记录在表2中。在该数据集上,我们的方法获得了 53.7% 的 J &F 分数,超过了当前最先进的方法 DsHmp 7.3% J &F,证明了我们在利用时间信息方面的有效性。
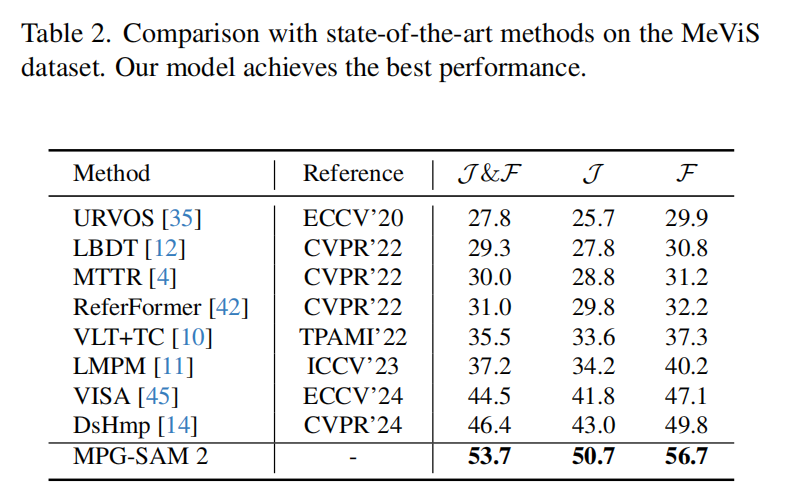
图4展示了我们的 MPG-SAM 2 模型与 SgMg [29] 在 Ref-YouTube-VOS 数据集上的可视化对比结果。结果清楚地表明,MPG-SAM 2 在预测精度和帧间一致性方面始终优于 SgMg。

尽管 MPG 能够在视频嵌入上实现时空自交互,但由于 BEiT-3 的嵌入尺寸较小(14×14),其计算和内存开销仍然可以接受。MPG 和 HGA 一起增加了 1.3G 的内存占用,并引入了 21M 参数,这是合理的。有关整体模型参数的详细分析,请参见附录。
4.4. 模型分析 在本节中,我们进行了全面的消融实验,以考察我们 MPG-SAM 2 中关键组件的效果以及不同模型配置的影响。所有实验均使用 Ref-Youtube-VOS 数据集进行。
组件分析。 为了探索我们模型中关键组件的影响,我们首先构建了一个仅由 SAM 2 和多模态编码器组成的基线模型。我们通过以下两种方式在视频基线上改进了基于图像的指代表分割任务:(1)提供每帧提示(Pper),而非仅第一帧;(2)使用 SAM 2 的记忆机制(Mem),而不是帧独立的分割。如表4所示,这些增强分别使基线提升了 10.4% J &F 和 3.2% J &F。
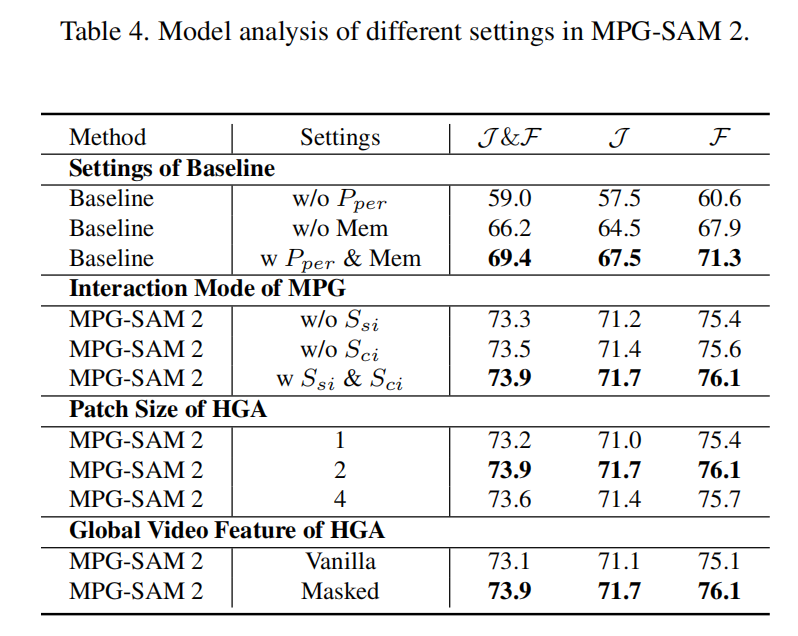
之后,如表3所示,我们首先在基线中加入了掩码-文本相似性损失(Lsim),带来了 0.9% J &F 的提升。在此基础上,我们引入了掩码先验生成器(MPG),此时特殊的 MPG-SAM 2 达到了 71.9% J &F,比之前的模型高出 1.6%。当仅将分层全局-历史聚合器(HGA)应用于带有 Lsim 的基线时,特殊 MPG-SAM 2 的 J &F 分数达到了 72.3%,表明提升了 2.0%,进一步验证了该模块的优越性。当所有组件集成后,我们的 MPG-SAM 2 实现了最佳性能,即 73.9% J &F。请注意,在性能计算过程中,HGA 中排除了记忆机制;当省略 MPG 模块时,仅未生成掩码先验,而全局视频特征的生成仍然保留。
掩码先验生成器。 在本节中,我们研究了掩码先验生成器(MPG)中不同的时空交互形式,结果见表4。当省略视频嵌入的整体时空自交互(Ssi)时,MPG-SAM 2 的性能下降了 0.6% J &F。同样地,当省略 [CLS] 令牌与视频嵌入之间的时空跨模态交互(Sci)时,模型性能下降了 0.4% J &F。这些发现突出了在生成掩码提示的过程中,从全局时空视角理解视频信息的重要性。
分层全局-历史聚合器。 分层全局-历史聚合器(HGA)的不同设置带来的影响也值得注意。首先,我们研究了在像素级融合过程中用于全局视频特征的 patch 大小 pg,尝试了 1、2 和 4 三种设置。如表4所示,patch 大小为 2 时模型性能最佳。这种配置在像素级融合过程中实现了关键信息和冗余信息之间的最优平衡,从而更有效地整合全局上下文。
此外,我们还探讨了输入到分层全局-历史聚合器中的全局视频特征的不同配置。一种称为“Vanilla”的简单方法是直接使用多模态编码器输出的视频嵌入作为全局特征。另一种被称为“Masked”的方法则是利用了融合了掩码先验信息的视频特征。表4中的结果显示,包含掩码信息的视频特征更有助于全局上下文的整合,因为它们能更好地强调全局帧掩码信息,从而指导当前帧的分割。
5 结论 本文中,我们提出了 MPG-SAM 2,这是一种创新的端到端框架,用于解决将 SAM 2 适配到 RVOS(指代表视频分割)任务中的挑战。我们的方法利用一个统一的多模态编码器,联合编码视频和文本特征,生成语义对齐的视频和文本嵌入,并生成多模态类别令牌。
视频嵌入和类别令牌被用于掩码先验生成器,以生成目标对象的伪掩码,作为密集提示为 SAM 2 的掩码解码器提供强有力的定位线索。为了弥补 SAM 2 在离线 RVOS 中缺乏全局上下文感知能力的问题,我们引入了一个分层的全局-历史聚合器。该模块使得 SAM 2 能够在像素级和物体级上整合目标对象的全局上下文和历史信息,从而增强目标表示和时间一致性。
在多个 RVOS 基准上的大量实验表明,我们的 MPG-SAM 2 优于现有最先进方法,并验证了我们所提出模块的有效性
原文:https://www.arxiv.org/pdf/2501.13667
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号