用于文本生成的递归神经网络

用于文本生成的递归神经网络

CreateAMind
发布于 2026-03-11 16:29:57
发布于 2026-03-11 16:29:57
用于文本生成的递归神经网络
Recurrent Neural Networks for Text Generation
https://link.springer.com/book/10.1007/978-3-031-76516-2

摘要:
当前计算机神经网络应用中的前沿实践之一,是通过在自然语言经典文学文本材料上训练,以改进语言生成式文本模型。其中颇具前景的方向是循环神经网络(RNN),其单元连接由有向序列定义,并可通过预先的自动化配置(训练)实现。为提升语言生成式文本模型在源文本情感(情绪语义)自动判别方面的能力,可采用更先进的RNN训练方法:其内部记忆机制可处理任意长度的动态关系序列。本文探讨了利用RNN与LSTM神经网络解决文本生成中最具挑战性与复杂性的问题之一——提升基于用户查询的搜索结果的语境适切性、语义丰富性与情感色彩。文中给出了构建神经元及含隐层神经网络的示例,详细分析了循环神经网络的结构及其应用领域,并展示了构建经典RNN以分析文本情感(情绪色彩)的实例。特别关注RNN的一种改进模型——长短期记忆网络(LSTM),该模型最适用于解决基于用户请求生成具有更高语境适切性、语义丰富性与情感色彩的文本这一问题。
关键词:生成式文本模型 · 循环计算机神经网络 · 长短期记忆 · 情感基调 · 语境语义 · 文学文本学习
1 引言
当今信息处理中一种现代且高效的方法是计算机神经网络,其可作为处理各类数据(从音频、图像到大规模文本等)的手段。人工智能技术及动态生成数据识别的数学方法[1]已被广泛应用于优先领域的实际问题求解,如数字经济各部门:例如,提出了保障网络安全的先进神经网络方法[2–4]、优化碳氢化合物开采中的生产流程[5],以及提升农业综合企业的效率[6]。研究者还聚焦于创新食品生产的数学模型[7]、智能工业机器人[8, 9],以及求解密码学[10, 11]、交通[12]、材料科学[13]与金融市场[14, 15]问题的数学工具。
在这些发展中,需求极高但最具挑战性的方向包括:提升自动化同声传译结果的质量[16],以及增强由“电子顾问”、聊天机器人等根据用户请求生成的文本的语境适切性、语义丰富性与情感色彩[17]。当前计算机神经网络应用中的前沿实践之一,是通过在自然语言经典文学文本材料上进行训练,以改进语言生成式文本模型[18–20]。其中颇具前景的方向是循环神经网络(RNN, recurrent neural network),其单元连接由有向序列定义,并可通过预先的自动化配置(即训练)实现。
为提升语言生成式文本模型在源文本情感(情绪语义)自动判别方面的能力,可采用新型循环神经网络训练方法[21, 22]。其内部记忆机制使得处理任意长度的动态关系序列成为可能[23]。
相较于多层感知机,RNN在从片段重建整体的任务中(如识别失真文本、手写文字、语音等)具有优势[24]。若采用长短期记忆(LSTM)方法训练文本生成神经网络,自然语言中的经典文学作品文本可作为优质的训练素材。
变换器(Transformer)模型是一种专门用于文本数据处理的深度学习方法。然而,此类模型可能运算较慢。文献[25]提出了一种基于扩散模型与高效变换器的新型文生图合成技术(ET-DM);ET-DM融合了扩散模型与高效率变换器。文献[26]提出了一个基于扩散模型(DM)的框架NetDiffus,用于合成网络流量生成——这是网络与计算系统中的新兴研究课题之一,并在若干机器学习任务上取得了性能提升。文献[27]提出了一种动态模型,可在数据空间中无需额外网络即高效生成复杂时间序列。文献[28]则提出了一种基于估计的条件扩散模型(CSDI),这是一种新型时间序列填补方法,利用基于估计的扩散模型实现。然而,现有方法仍存在生成质量较低、速度较慢等缺陷。
2 材料与方法
神经网络的优势包括以下几点:
- 消除输入数据噪声;
- 适应变化;
- 容错性;
- 性能。
缺点:
- 神经网络无法产生明确无歧义的答案;
- 多阶段问题求解。
生成神经文本是使用循环神经网络最为便捷的常见任务之一。
每当需要将一段文本从源语言翻译为目标语言时,就会产生文本生成的需求——因为要实现准确、有意义的翻译,不能逐字翻译,而需参考词与句子的序列。此外,在寻求当前流行的电子顾问或聊天机器人帮助时,也会遇到文本生成任务:在这些系统中,消息乃至用户的语音会被编码进语义空间,再由神经网络解码器从中提取适当含义,向用户提供合理回应。
语言模型中一个句子的概率定义如下:
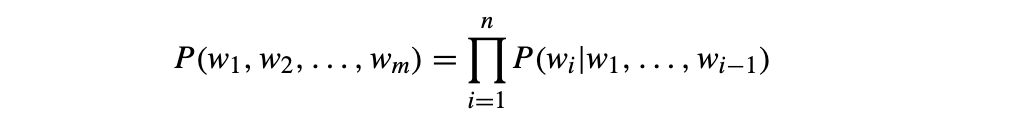
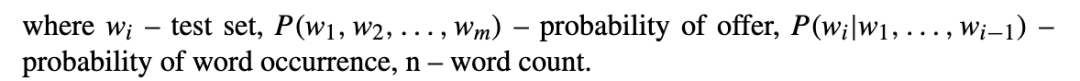
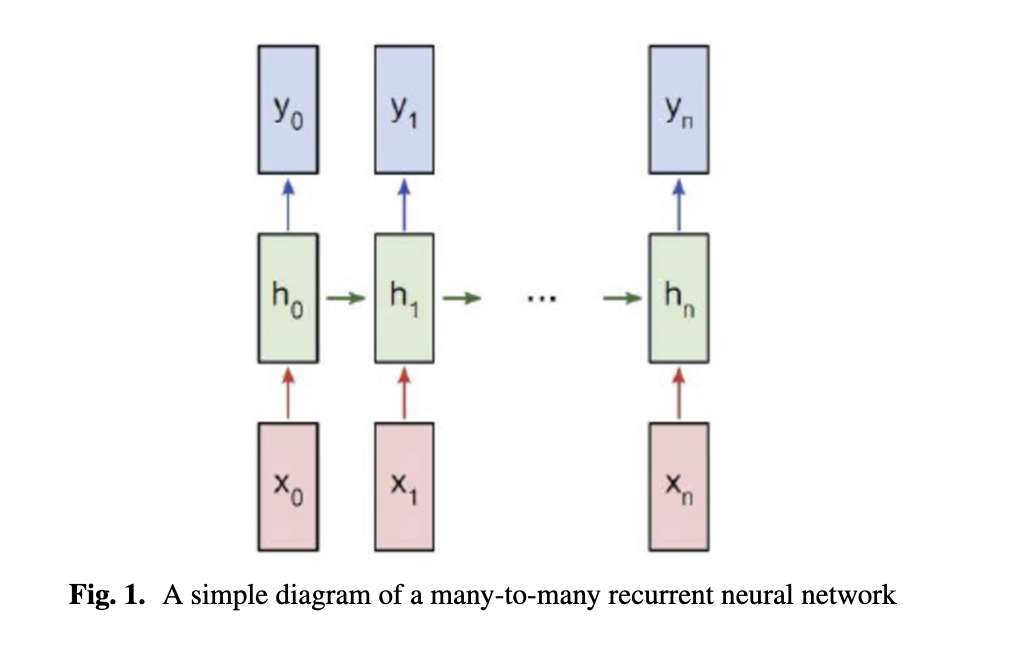
让我们通过一个简单的“多对多”方案(见图1)来考察循环网络的工作原理。

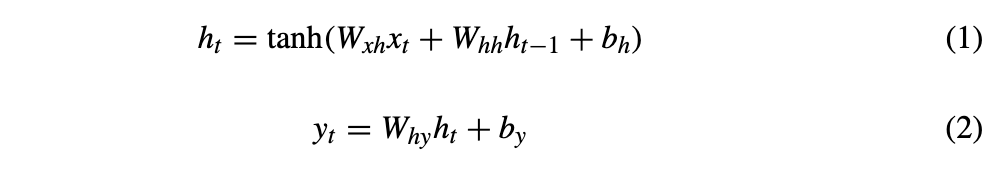
接下来将进行矩阵乘法运算,随后各向量被纳入最终结果中。可选用Sigmoid激活函数替代后续的双曲正切(tanh)激活函数。为解决句子情感(情绪色彩)评估问题,我们将采用RNN架构。
2.1 阶段一:训练
步骤1:数据准备。我们创建两个字典用于存放句子:一个用于网络训练(data_for_training),另一个用于测试(data_for_testing)。
步骤2:构建包含所有句子中出现词汇的词典,为每个词分配唯一索引(因RNN仅能处理数值,无法直接处理词语)。
步骤3:编写 createInputs 函数,用于生成由单位向量组成的数组,供后续循环网络使用。
步骤4:设定三个权重参数与两个偏置项。
步骤5:实现公式(1)与(2)。
2.2 阶段二:训练后模型测试
步骤1:训练RNN时采用损失函数——具体为交叉熵损失。借助损失函数,可通过梯度下降法训练网络,以最小化损失。
步骤2:设置前向传播阶段,缓存数据以供反向传播阶段使用。
步骤3:实现时间维度上的误差反向传播(BPTT)。
步骤4:测试RNN。在最后若干轮迭代(即迭代步数与逐次逼近过程)中,准确率达到峰值,损失值极小——表明该循环神经网络对简单句子情感基调(情绪色彩)的判断最为准确。
2.3 算法应用
使用RNN时常见问题是在长句训练中出现梯度消失现象:这源于激活函数取值趋近于零,导致梯度更新量趋近消失。为解决该问题,发展出一种特殊RNN架构——长短期记忆网络(LSTM)。
我们将实现一个LSTM循环网络,以其训练10首诗歌及普希金叙事诗体小说《叶甫盖尼·奥涅金》的节选,并生成文本序列。该神经网络以俄语进行训练。所选训练诗歌包括:

对数据文件进行处理:将所有字符转为小写,提取唯一字符并编号;将文本切分为固定长度为100个字符的序列(即每个“模板”的长度),每次以1个字符为步长滑动窗口,使得除前100个字符外,每个字符均可由其前100个字符预测。完成序列划分后,依据预先构建的字符映射表将字符转换为数值。数据准备完毕后,需将其转换为适配Keras(一种深度机器学习编程库)的格式:
- 将输入序列列表重塑为(模板, 序列, 键标识)形式;
- 将数值缩放到区间(0, 1);
- 将输出序列转换为“独热编码”(one-hot encoding),以预测49个唯一字符各自的概率分布,而非强制网络精确预测下一个字符。
每个目标值 y 被转换为长度为49的向量(其余位为0),仅对应字符所在位置置为1,以此表示该字符的标签。
我们构建一个含2个隐层的LSTM模型,每层包含256个记忆单元,并加入20%的Dropout;输出层采用Softmax激活函数,输出各字符的预测概率。损失函数选用交叉熵,并采用ADAM优化算法以加速收敛。
本模型目标在于:以最高精度预测训练数据集中的每个字符,并据此生成新文本。我们设置检查点(checkpoint),在每轮迭代结束时若损失下降,则保存全部网络权重。为优化模型,设训练轮数(epochs)为100,批尺寸(batch size)为64个模板。优化结果体现为一系列检查点;我们仅需选取损失最小(即精度最高)者。可观察到,自第98轮后检查点不再更新——表明后续轮次未能实现更低损失。
随后进入文本生成阶段:需另建一程序文件,加载原文并定义LSTM结构,唯一区别在于不再训练,而是载入先前保存的最优权重。生成时以原始序列起始,预测下一字符,截去首字符,循环迭代,直至生成指定长度(如500字符)的序列。运行代码首先输出随机选取的初始模板,随后逐字符生成。
最终生成的文本无拼写、标点及语法错误,已属重大进展;但仍需关注网络遗漏与重复之处:
- 缺失两行;
- 片段出现循环(但鉴于所用诗体特性,此问题可被谅解)。
LSTM网络在此任务中可谓“幸运”:首例测试中,它面对的是最复杂诗歌——因原文中存在大量相似甚至完全重复的诗句;此时若将生成长度由500减至250,效果或更佳。果然,第二例中生成文本与原文达到100%一致(因随机模板恰来自另一首诗)。故该实验可视为成功——归功于输入数据量小且训练充分。经100轮LSTM训练后,损失稳定于≤0.1,保障了生成准确性。
进而设想:若LSTM网络从某特定诗人作品中学习,能否产出新的“人工”杰作?须注意,即使仅达“可接受”质量的新诗句,亦需强大算力支持;而欲生成真正优美且富有意义的诗句,则需以海量文本作为训练数据。
我们以普希金若干诗作及《叶甫盖尼·奥涅金》节选为训练集,算法流程如下:加载文本文件,统一转为小写;将句子切分为独立序列;逐一处理每句:依词典将其转换为词索引序列,最终返回完整序列列表;统计总词数并加1,增设一特殊标记,用于标识测试阶段是否遇到新词(未登录词)。
构建训练样本时,循环遍历各序列(即逐行处理),生成新序列并加入训练集;因句子长度不一,需计算最长序列长度,并以零填充使所有序列等长。y(目标标签)部分已处理完毕,余下为x(输入)及其对应“标签”——即模型需预测后续词,故各序列末词即为标签。随后将其转换为类别标签:设词典总词数为10,则标签5对应 y = [0,0,0,0,1,0,0,0,0,0]。
与前述模型相比,本模型关键区别在于引入专为文本数据设计的嵌入层(Embedding);此外,加入一个双向层(Bidirectional layer)、一个隐层,以及输出层——其维度等于需预测的总词数。
需引入正则化以避免数据过拟合。分类交叉熵损失函数与ADAM优化器的选用与前例相同。
我们开始对网络进行优化与训练。本例中建议直接采用更多轮次(如200轮),以提升生成质量。
随后即可自由输入任意起始词序列,模型将据此生成后续内容:循环不断在每条序列末尾添加新词,直至达到预设长度;最终,所有预测词被追加至原文,并重新输入循环,以生成句子的下一部分。
值得指出的是,该模型能出色完成任务:不仅能按序生成新词,还能在相当程度上遵循某种风格。诚然,所生成文本尚无明显语义;但提升模型质量的唯一途径,是使用更庞大的训练数据与更多训练轮次,以进一步降低损失值。然而遗憾的是,所有这些改进均会显著增加程序运行时间。如前所述,若欲生成优美且富有意义的语句,必须依托高性能计算设备,方可在数分钟内处理海量数据;否则,模型训练过程可能耗时数小时乃至数日。
3 结果与结论 算法有效性测试结果见表1。
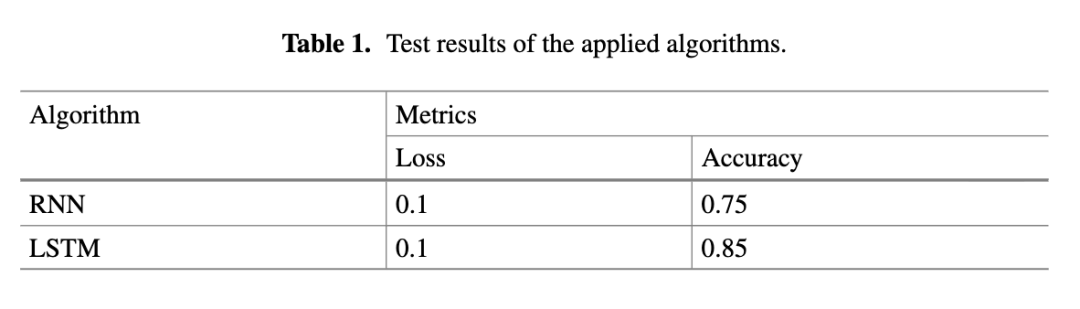
因此,本研究探讨了利用RNN与LSTM神经网络解决文本生成领域最具挑战性与复杂性的问题之一——即提升基于用户请求的搜索结果的语境适切性、语义丰富性与情感色彩。实践部分提供了构建单个神经元及含隐层神经网络的示例;文章详细考察了一种人工神经网络架构——循环神经网络(RNN),对其结构与应用领域进行了分析;实践环节还展示了构建经典RNN以实现文本情感(情绪色彩)分析的实例。本文特别聚焦于RNN的一种改进模型——长短期记忆网络(LSTM)。我们确信,LSTM因其优异的序列数据处理能力,最适合作为解决上述文本生成问题的有效途径。
原文链接:https://link.springer.com/book/10.1007/978-3-031-76516-2
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号