少即是多:微模型的递归推理

少即是多:微模型的递归推理

CreateAMind
发布于 2026-03-11 16:09:17
发布于 2026-03-11 16:09:17
Alexia Jolicoeur-Martineau
Less is More: Recursive Reasoning with Tiny Networks
少即是多:微模型的递归推理
https://arxiv.org/pdf/2510.04871

摘要
层次推理模型(HRM)是一种创新方法,它使用两个以不同频率递归的小型神经网络。这种受生物学启发的方法,在诸如数独、迷宫和ARC-AGI等难题任务上,表现优于大语言模型(LLMs),同时仅使用小型模型(2700万参数)和少量数据(约1000个示例)进行训练。HRM在利用小型网络解决难题方面前景广阔,但其原理尚未被充分理解,且可能并非最优方案。我们提出了微型递归模型(TRM),这是一种更为简洁的递归推理方法。在仅使用一个仅含2层的小型网络的情况下,其泛化能力显著超越HRM。TRM仅拥有700万参数,就在ARC-AGI-1上达到了45%的测试准确率,在ARC-AGI-2上达到8%,超过了大多数大语言模型(例如Deepseek R1、o3-mini、Gemini 2.5 Pro),而其参数量却不足这些模型的0.01%。
1 引言
尽管大型语言模型(LLMs)能力强大,但在解决困难的问答问题时仍可能面临挑战。由于它们是自回归地生成答案,所以存在较高的出错风险,因为单个错误的标记就可能导致答案无效。为了提高其可靠性,LLMs依赖于思维链(CoT)(Wei et al., 2022)和测试时计算(TTC)(Snell et al., 2024)。思维链旨在模仿人类推理,让LLM在给出答案前采样出逐步推理的轨迹。这样做可以提高准确性,但思维链成本高昂,需要高质量的推理数据(可能无法获得),并且可能很脆弱,因为生成的推理可能是错误的。为了进一步提高可靠性,可以使用测试时计算,即从K个答案中报告最常见的答案或最高奖励的答案(Snell et al., 2024)。
在这项工作中,我们表明,递归推理带来的益处可以得到极大提升,其改进远不止是渐进式的。我们提出了微型递归模型(TRM),这是一种改进且简化的方法,它使用一个仅包含2层、规模小得多的微型网络,在多种问题上实现了比HRM显著更高的泛化能力。通过这一方法,我们将数独极限测试集的准确率从55%提升至87%,迷宫困难测试集从75%提升至85%,ARC-AGI-1从40%提升至45%,ARC-AGI-2从5%提升至8%。
2. 背景 HRM的算法描述详见算法2。我们将在下文进一步讨论该算法的细节。
2.1. 结构与目标 HRM的研究重点是监督学习。给定一个输入,生成一个输出。假定输入和输出都具有形状 [B, L](当形状不同时,可以添加填充标记),其中 B 是批量大小,L 是上下文长度。
在这项工作中,我们表明,递归推理带来的益处可以得到极大提升,其改进远不止是渐进式的。我们提出了微型递归模型(TRM),这是一种改进且简化的方法,它使用一个仅包含2层、规模小得多的微型网络,在多种问题上实现了比HRM显著更高的泛化能力。通过这一方法,我们将数独极限测试集的准确率从55%提升至87%,迷宫困难测试集从75%提升至85%,ARC-AGI-1从40%提升至45%,ARC-AGI-2从5%提升至8%。

2.2. 两种不同频率的递归
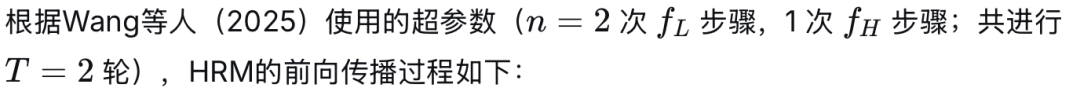


2.3. 使用一步梯度近似的定点递归




2.7 HRM总结 HRM利用两个不同频率(高频与低频)网络的递归和深度监督,学习在多个监督步骤中改进其答案(并使用ACT减少每个数据样本的处理时间)。这使得模型能够模仿极深的网络,而无需对所有层进行反向传播。该方法在常规监督模型难以应对的困难问答任务上取得了显著更高的性能。然而,该方法相当复杂,过于依赖不确定的生物学论据和无法保证适用的不动点定理。在下一节中,我们将讨论这些问题以及HRM潜在的改进目标。
3. 层次推理模型的改进目标 在本节中,我们确定了HRM的关键改进目标,这些目标将由我们提出的方法——微型递归模型(TRM)来解决。
3.1. 隐函数定理与一步梯度近似
HRM仅对6次递归中的最后2次进行反向传播。作者通过应用隐函数定理和一步近似来证明这种做法的合理性,该定理指出:当递归函数收敛到不动点时,可以在该平衡点处通过单步进行反向传播。


因此,尽管将隐函数定理和一步梯度近似应用于HRM有一定依据,因为残差通常会随时间推移而减小,但在实际应用该定理时,模型很可能并未达到不动点。
在下一节中,我们将展示可以绕过对隐函数定理和一步梯度近似的需求,从而彻底避免这个问题。
3.2. 自适应计算时间(ACT)导致前向传播次数加倍
HRM在训练期间使用自适应计算时间(ACT)来优化每个数据样本所花费的时间。如果不使用ACT,每个数据样本将需要花费 Nsup=16个监督步骤,这是非常低效的。他们通过一个额外的Q学习目标来实现ACT,该目标决定何时停止并转向新的数据样本,而不是继续在同一个数据上迭代。这可以更高效地利用时间,尤其是在使用ACT时,训练期间的平均监督步骤数相当低(根据他们报告的数据,在Sudoku-Extreme数据集上平均少于2步)。
然而,ACT是有代价的。这一代价没有直接在HRM的论文中显示,但在其官方代码中有所体现。Q学习目标依赖于一个停止损失和一个继续损失。继续损失需要对HRM进行额外的一次前向传播(包含全部6次函数评估)。这意味着,虽然ACT能更有效地优化每个样本的时间,但每个优化步骤需要2次前向传播。具体公式如算法2所示。
在下一节中,我们将展示如何避免ACT中两次前向传播的需求。
3.3. 基于复杂生物学论据的层次化解释
HRM的作者基于生物学论据来证明两个潜在变量和两个在不同层次运行的网络的设计是合理的,但这些论据与人工神经网络相距甚远。他们甚至尝试将HRM与对小鼠的实际大脑实验联系起来。尽管这很有趣,但这种解释使得理解HRM为何如此设计变得极其困难。考虑到其论文中缺乏消融实验表,以及对生物学论据和不动点定理(其并非完全适用)的过度依赖,很难确定HRM的哪些部分起到了什么作用以及原因。此外,不清楚他们为何使用两个潜在特征,而不是其他特征组合。
在下一节中,我们将展示递归过程可以得到极大的简化,并且可以用一种简单得多的方式来理解,这种方式不需要任何生物学论据、不动点定理、层次化解释,也不需要两个网络。这也解释了为什么2是最佳特征数(即

)。
4. 微型递归模型
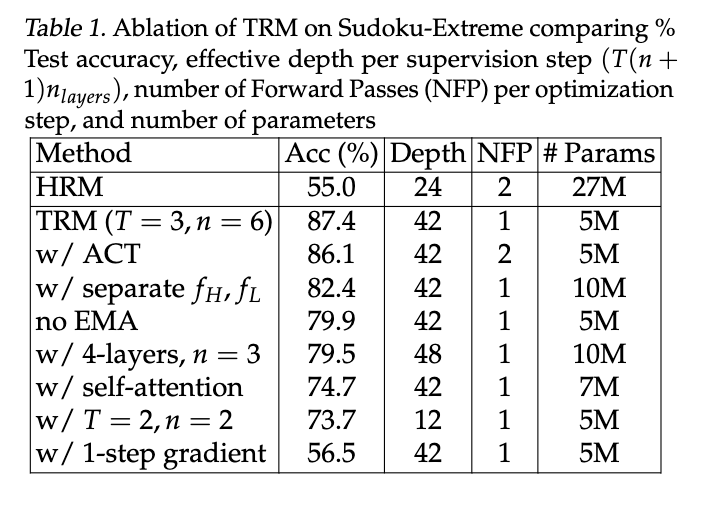
在本节中,我们介绍微型递归模型(TRM)。与HRM相反,TRM不需要复杂的数学定理、层级结构或生物学论据。它在泛化能力上表现更优,同时仅需一个微型网络(而非两个中等规模网络),并且ACT(自适应计算时间)仅需单次前向传播(而非2次)。我们的方法在算法3中描述,并在图1中展示。我们还在数独极限数据集(一个仅有1K训练样本但包含423K测试样本的困难数独数据集)上进行了消融实验,结果如表1所示。下文将阐述TRM的关键组成部分。
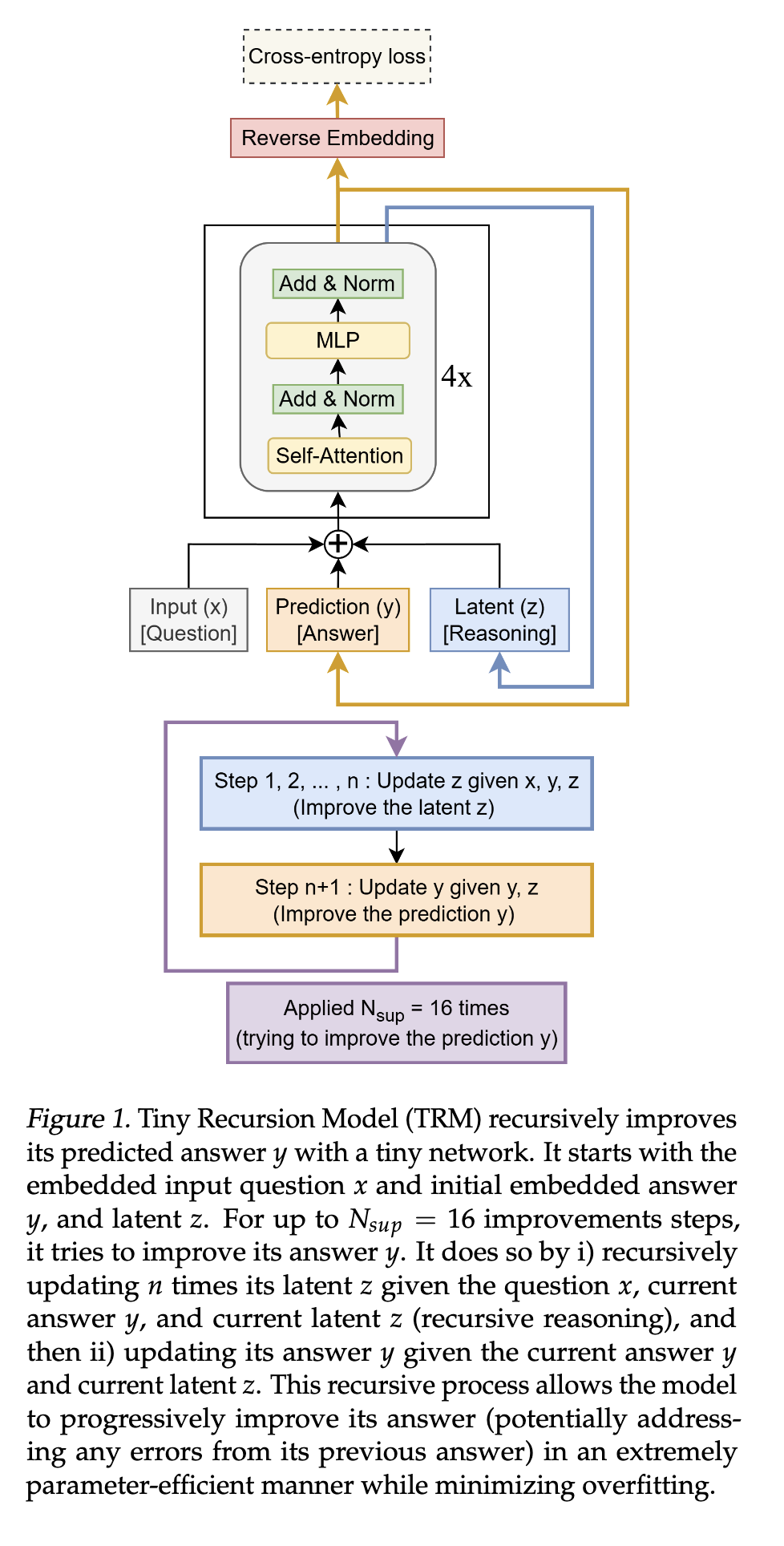
4.1. 无需不动点定理

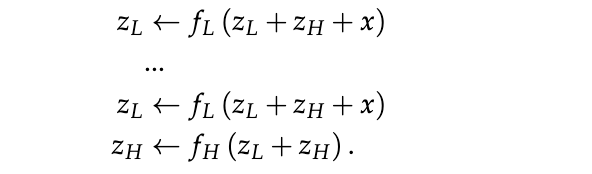


虽然这种解释很直观,但我们仍想验证使用更多或更少的特征是否有所帮助。结果如表2所示。
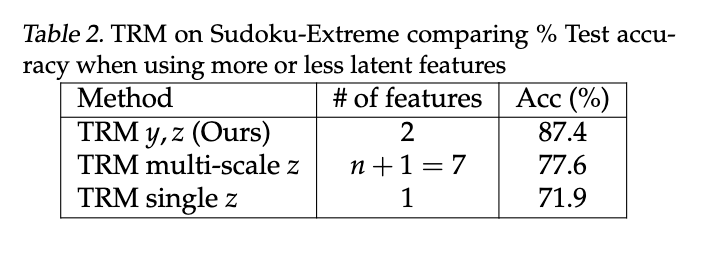

单一特征:类似地,我们测试了仅使用一个特征的想法,即在监督步骤之间只传递

。该方法在算法4中描述。通过这种方式,我们发现性能有所下降。这也是预期的结果,因为正如前面所讨论的,这迫使模型将解 y存储在 z中。
因此,我们在数独极限任务上探索了使用更多或更少潜在变量的情况,但发现仅使用 y和 z不仅是最简单、最自然的方法,而且能带来更高的测试准确率。

4.4. 少即是多
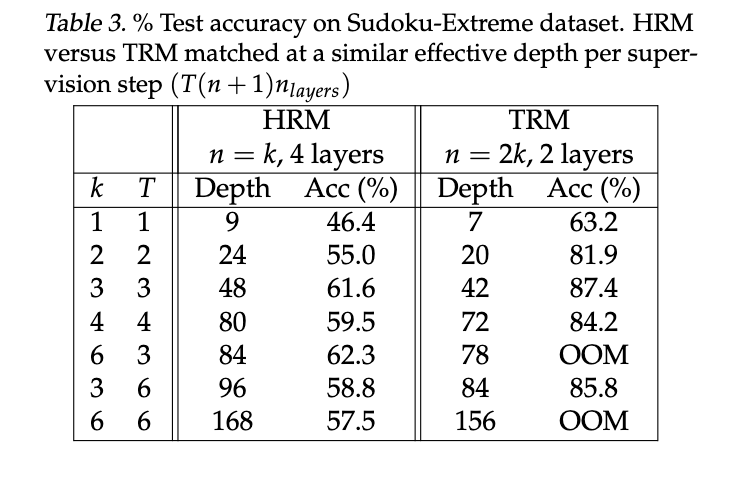
我们曾尝试通过增加层数来提高容量,以扩展模型。令人惊讶的是,我们发现增加层数会因过拟合而降低泛化能力。相反,在按比例增加递归次数(nn)的同时减少层数(以保持计算量和模拟深度大致相同),我们发现使用 2 层(而不是 4 层)可以最大化泛化能力。通过这样做,我们在 Sudoku-Extreme 上获得了更好的泛化能力(将 TRM 从 79.5% 提高到 87.4%;见表 1),同时将参数量减少了一半(再次强调)。
较小的网络表现更好,这相当令人惊讶,但 2 层似乎是最优选择。Bai & Melas-Kyriazi (2024)在深度平衡扩散模型的背景下也观察到了 2 层网络的最佳性能;然而,他们的性能与更大网络相似,而我们则观察到 2 层网络性能更好。这可能看起来有些不同寻常,因为对于现代神经网络,泛化能力往往直接与模型规模相关。然而,当数据过于稀缺且模型规模过大时,可能会出现过拟合的惩罚(Kaplan 等人, 2020)。这可能表明数据量过少。因此,使用具有深度递归和深度监督的微小网络似乎能让我们避免很多过拟合问题。
4.5. 针对固定小上下文长度任务的无注意力架构

4.7. 指数移动平均
在小数据集(如 Sudoku-Extreme 和 Maze-Hard)上,HRM 往往会迅速过拟合并随后发散。为了减少这个问题并提高稳定性,我们采用了权重指数移动平均(EMA),这是 GAN 和扩散模型中用于提高稳定性的常见技术(Brock 等人, 2018; Song & Ermon, 2020)。我们发现它能防止急剧崩溃并带来更高的泛化能力(从 79.9% 到 87.4%;见表 1)。
4.8. 优化递归次数

在下一节中,我们将展示 HRM、TRM 和 LLMs 在多个数据集上的主要结果对比。
5. 结果
遵循 Wang 等人 (2025) 的方法,我们在以下数据集上测试了我们的方法:Sudoku-Extreme (Wang 等人,2025)、Maze-Hard (Wang 等人,2025)、ARC-AGI1 (Chollet,2019) 和 ARC-AGI-2 (Chollet 等人,2025)。结果展示在表 4 和表 5 中。超参数详见第 6 节。数据集讨论如下。
Sudoku-Extreme包含极其困难的数独谜题(Dillion, 2025; Palm 等人, 2018; Park, 2018)(9x9 网格),仅使用 1K 训练样本来测试小样本学习能力。在 423K 个样本上进行测试。
Maze-Hard包含由 Lehnert 等人 (2024) 提出的程序生成的 30x30 迷宫,其最短路径长度超过 110;训练集和测试集各包含 1000 个迷宫。
ARC-AGI-1和 ARC-AGI-2是包含奖金的几何谜题。每个谜题都设计得对人类来说容易,但对当前的人工智能模型来说却很困难。每个谜题任务包含 2-3 个输入-输出演示对和 1-2 个待求解的测试输入。最终分数计算为在所有测试输入上经过两次尝试生成正确输出网格的准确率。最大网格尺寸为 30x30。ARC-AGI-1 包含 800 个任务,而 ARC-AGI-2 包含 1120 个任务。 我们还使用来自紧密相关的 ConceptARC 数据集(Moskvichev 等人,2023)的 160 个任务来增强我们的数据。我们提供了 ARC-AGI-1 和 ARC-AGI-2 在公共评估集上的结果。
虽然这些数据集规模较小,但为了改善泛化能力,使用了大量的数据增强。Sudoku-Extreme 对每个数据样本使用了 1000 次洗牌增强(在不违反数独规则的情况下进行)。Maze-Hard 对每个数据样本使用了 8 种二面体变换。ARC-AGI 对每个数据样本使用了 1000 次数据增强(颜色置换、二面体群变换和平移变换)。二面体群变换包括随机的 90 度旋转、水平/垂直翻转和反射。
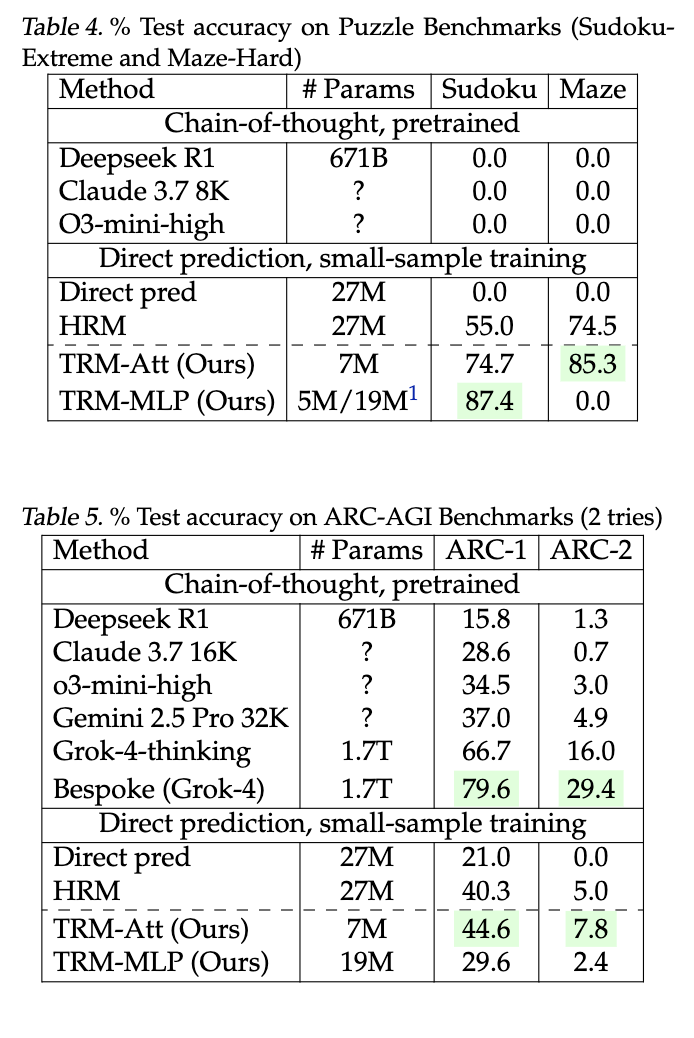
从结果中可以看出,不使用自注意力的 TRM在 Sudoku-Extreme 上获得了最佳的泛化能力(87.4% 测试准确率)。同时,使用自注意力的 TRM在其他任务上泛化得更好(可能是由于归纳偏差以及 MLP 在大的 30x30 网格上的过拟合倾向)。使用自注意力的 TRM 在 Maze-Hard 上获得 85.3% 的准确率,在 ARC-AGI-1 上获得 44.6% 的准确率,在 ARC-AGI-2 上获得 7.8% 的准确率,参数量为 7M。这显著高于使用 4 倍参数量(27M)的 HRM所获得的 74.5%、40.3% 和 5.0%。
6. 结论
我们提出了微型递归模型(TRM),这是一种简单的递归推理方法,通过在潜在的推理特征上进行递归并使用单个微型网络逐步改进最终答案,从而在困难任务上实现了强大的泛化能力。与分层推理模型(HRM)相比,TRM 不需要不动点定理、复杂的生物学论证,也不需要层次结构。它通过将层数减半并用单个微型网络替代两个网络,显著减少了参数量。它还简化了停止过程,无需额外的前向传播。总的来说,TRM 比 HRM 简单得多,同时实现了更好的泛化能力。
尽管我们的方法在 4 个基准测试中带来了更好的泛化性能,但我们所做的每一个选择都不能保证在所有数据集上都是最优的。例如,我们发现用 MLP 替换自注意力在 Sudoku-Extreme 上效果极好(测试准确率提升了 10%),但在其他数据集上表现不佳。不同的问题设置可能需要不同的架构或参数量。需要扩展定律来优化这些网络的参数化。虽然我们简化和改进了深度递归,但为什么递归比使用更大更深的网络帮助更大,这个问题仍有待解释;我们怀疑这与过拟合有关,但我们没有理论来支持这一解释。并非我们所有的想法都取得了成功;我们将在第 6 节简要讨论一些我们尝试过但未成功的想法。
目前,递归推理模型(如 HRM 和 TRM)是监督学习方法,而不是生成模型。这意味着给定一个输入问题,它们只能提供一个确定的答案。然而,在许多情况下,一个问题可能存在多个答案。因此,将 TRM 扩展到生成任务将是很有意义的研究方向。
原文链接:https://arxiv.org/pdf/2510.04871
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号