Perplexity CEO谈浏览器为什么是AI Agent的最佳选择?Manus 联合创始人谈如何构建AI Agent上下文。

Perplexity CEO谈浏览器为什么是AI Agent的最佳选择?Manus 联合创始人谈如何构建AI Agent上下文。

春哥大魔王
发布于 2026-03-11 15:16:57
发布于 2026-03-11 15:16:57
分享两篇周末看到的文章。
Perplexity CEO谈浏览器为什么是AI Agent的最佳选择?
Agent可以帮人们完成任务,是从接收指令开始的,要完成整个workflow,它需要上下文,需要从很多三方应用中获取上下文,这个过程最好不要每次都让你反复授权。
任务执行过程不能是黑箱,当它搞不定任务时,你可以随时接管,此时就需要一个统一的操作界面,让人类无缝衔接。
可见浏览器是这样一个天然的入口。
浏览器具有用户的登录态、本地数据和行为习惯,同时作为一个常驻进程,具备执行任务的能力,是AI Agent的天然虚拟入口。
而且,所有的操作都发生在本地,数据是安全的。
操作与数据在客户端浏览器,而模型依然运行在服务端。
Apple的Apple Intelligence之所以遇到很多困难,就是因为想把所有智能部署在本地设备上,但想要实现高质量的推理,并不一定要完全本地化。
浏览器侧的Agent是“浏览器+登录态”的路线,而像Anthropic和OpenAI则是押注MCP。
之所以这样选择,是因为MCP还没真正成熟,当前想要实现一个真正能用的Agent,浏览器是最务实的选择。
浏览器是专门为人类设计的,从DOM中提取操作路径,判断页面元素,这些事情推理模型已经变得非常擅长。
Manus 联合创始人谈如何构建AI Agent上下文。

Image
Manus项目伊始,团队就在考虑是用开源模型训练一个端到端的智能体,还是依托上下文能力,在模型之上构建智能体。
自己训练一个开源模型的成本和时间无疑是更长的,而且出现一个更厉害的模型,你的所有工作都失去了意义。
于是,义无反顾地选择了上下文工程路线。
在收到用户输入后,智能体通过一连串工具调用来完成任务,模型需要根据当前上下文从预定义的动作中选择一个,然后观察执行结果,动作和执行结果会被追加到上下文中,成为下一轮的输入,循环进行,直到任务完成。
上下文的输入会越来越长,Manus平均输入输出比的token是100:1。
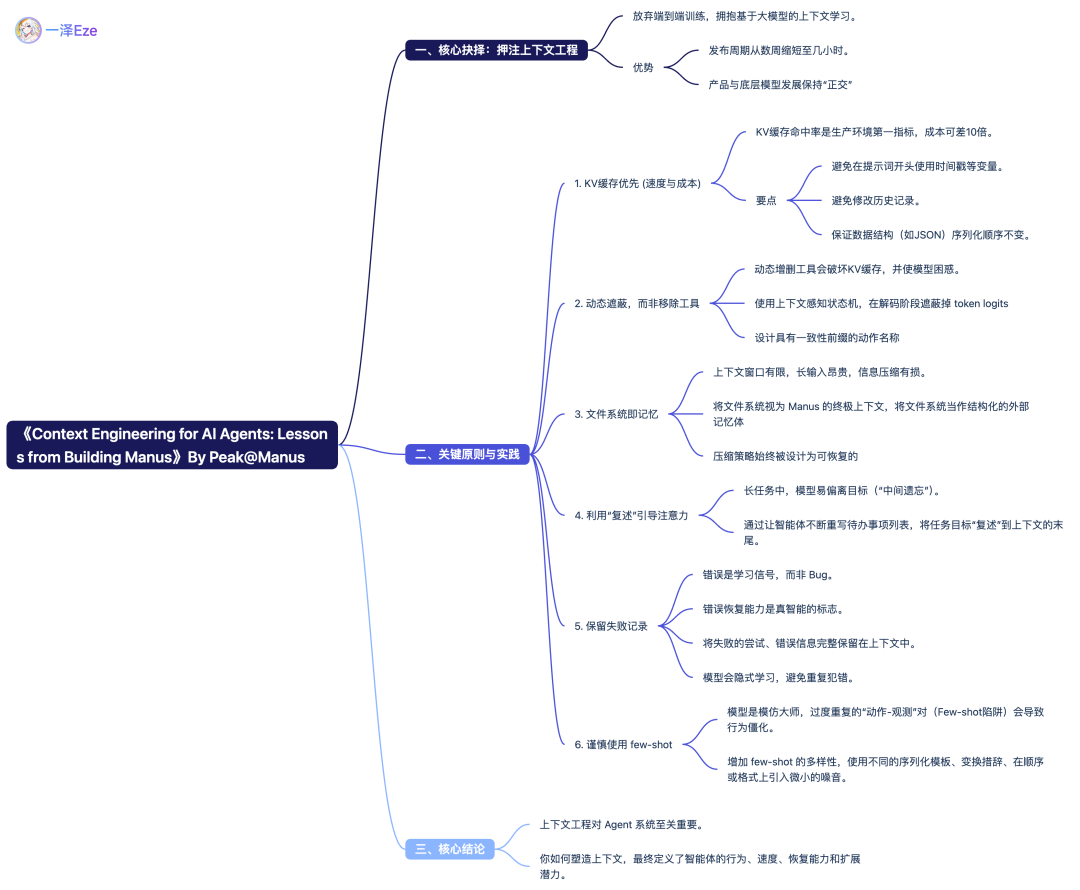
KV缓存命中率是生产级AI Agent最重要的指标,它直接影响到延迟和成本。
相同上下文可以利用KV缓存,降低首token的延迟和推理成本,以Claude Sonnet为例,缓存的输入token价格为0.3美元/百万token,未缓存成本高达3美元/百万token,相差10倍。
提高KV缓存命中率有以下几个手段:
1、保持提示前缀稳定:由于LLM的自回归特性,即使只有一个token的差异,也可能导致该token之后的缓存失效。比如在系统提示词开头加上时间戳告诉当前时间,这会让你的缓存命中率归零。
2、让上下文保持追加:避免修改之前的动作或观察结果,确保序列化是确定性的,有时序列化成json顺序不稳定,会破坏缓存。
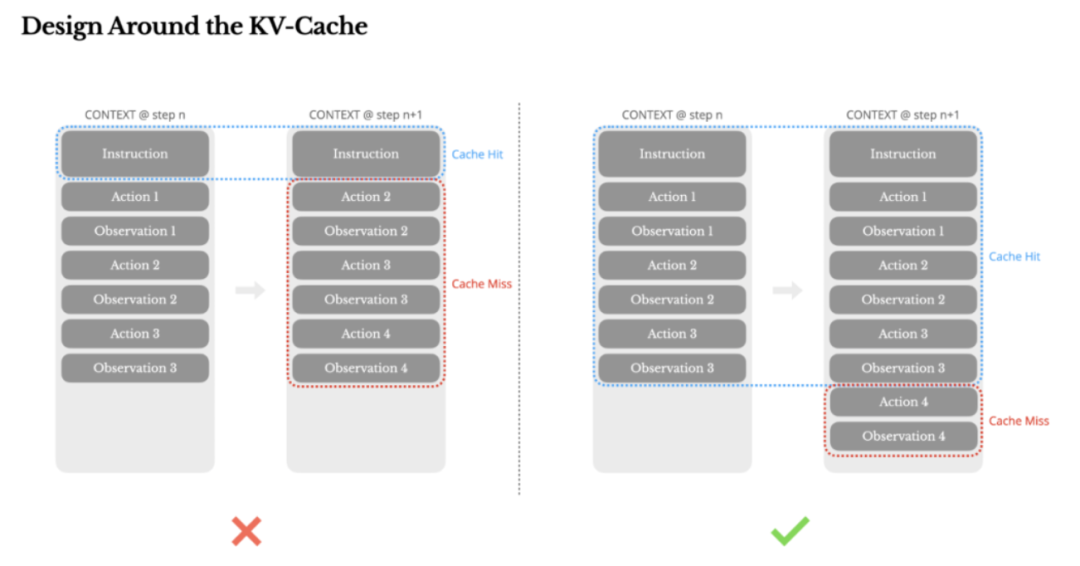
随着Agent承担的能力越多,工具数量也会越多,工具越多,模型越容易选错,反而导致Agent变笨。
好的思路是,设计一个动态的动作空间,类似于Rag的方式按需加载工具,但需要注意,除非绝对必要,否则避免在多轮过程中动态的增删工具。
主要原因是:
1、大多数LLM,工具定义在序列化后位于上下文前部,在系统提示词之前或之后,因此,任何变动都会使得后续的动作和观察的KV-cache失效。
2、当前的动作和观察仍然引用当前上下文中已不存在的工具时,模型会陷入混乱,导致违规或幻觉。
Manus引入了上下文感知状态机来管理工具的可用性,它并不是真正的移除工具,而是在解码阶段屏蔽了相应的token logits,从而阻止选择某些动作。
动作名称设计时,统一了前缀,如浏览器相关的工具,都以browser开头,命令行工具都以shell开头,这样可以轻松的在给定的状态下限定Agent只能从一组工具中选择。
当前的LLM支持128K或更大的上下文,但在一个真实的Agent中还不够用,有几个原因:
1、观察结果庞大:尤其是当Agent与网页或PDF这类非结构数据交互时,很容易超出上下文限制;
2、模型性能在超过某个上下文长度之后会下降;
3、长输入成本高,即使有前缀缓存,仍需为传输和预填充的token付费;
为了解决这个问题,很多Agent实现了上下文截断或压缩的策略。
但压缩必然导致信息丢失,因为Agent必须基于当前上下文来预测下一步的动作,无法确定哪些信息在十步轮次之后是否重要。
所以,任何不可逆的压缩都伴随着风险。
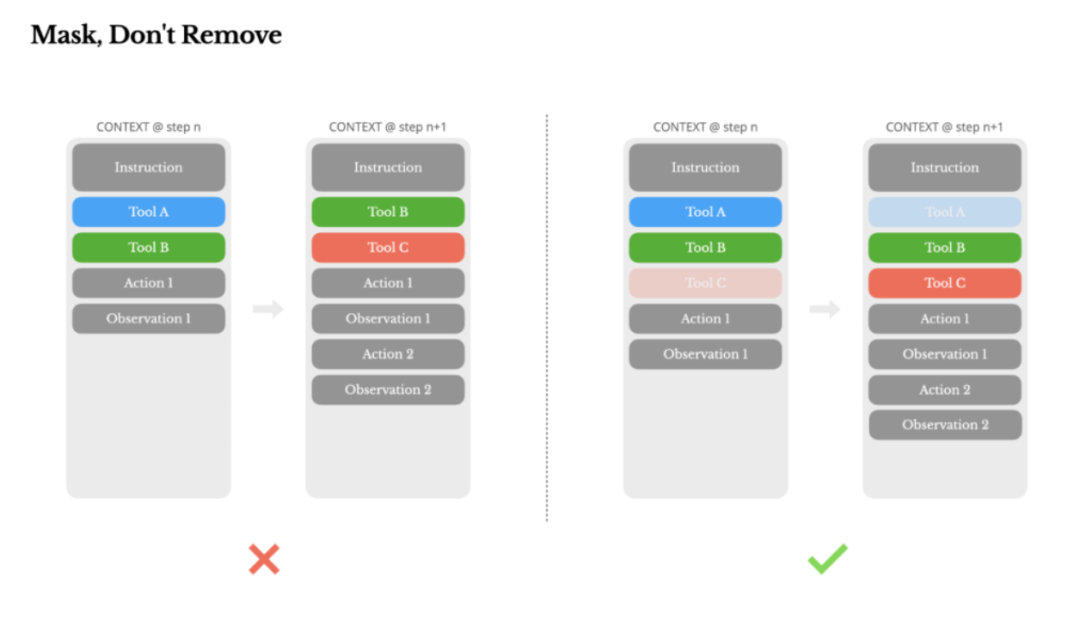
Manus将文件系统视为终极上下文,容量有限、天然持久,并且代理可直接操作。
模型按需读写文件,将文件系统不仅当做存储,更当做结构化、外化的记忆。
Manus在处理复杂任务时,会建立一个todo.md文件,在任务推进过程中逐步更新,把完成的项目逐一勾选。
这是一种注意力操控机制。
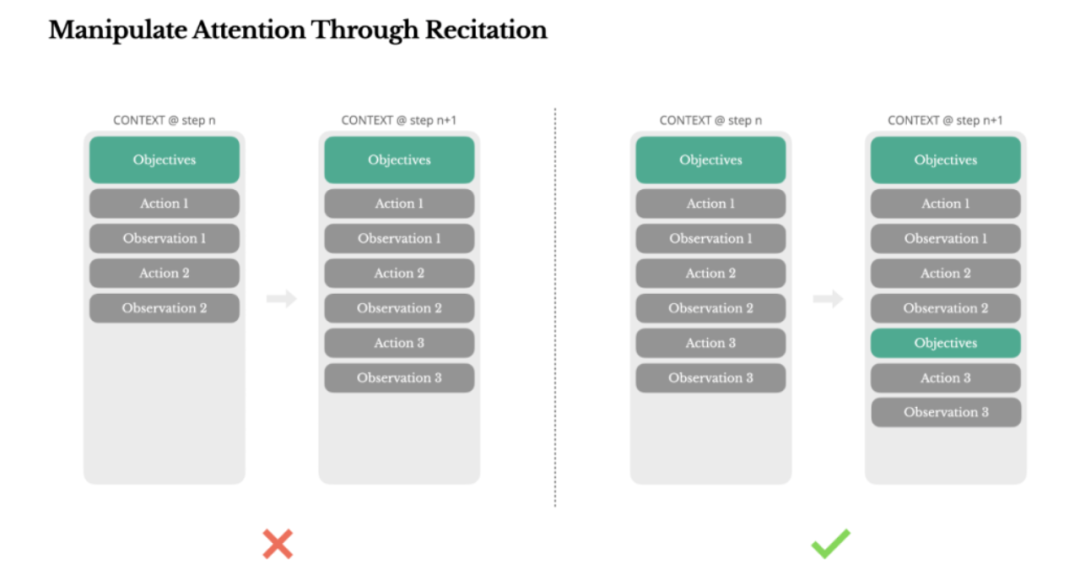
如果一个任务需要50次工具调用,这是一个很长的循环,由于需要依赖LLM做决策,很容易在冗长的上下文或复杂的任务中偏离主题。
所以,通过不断重写待办清单,Manus可以把目标追加到上下文末尾,这样全局计划就被推入模型的近期注意力范围,避免中间丢失目标的问题。
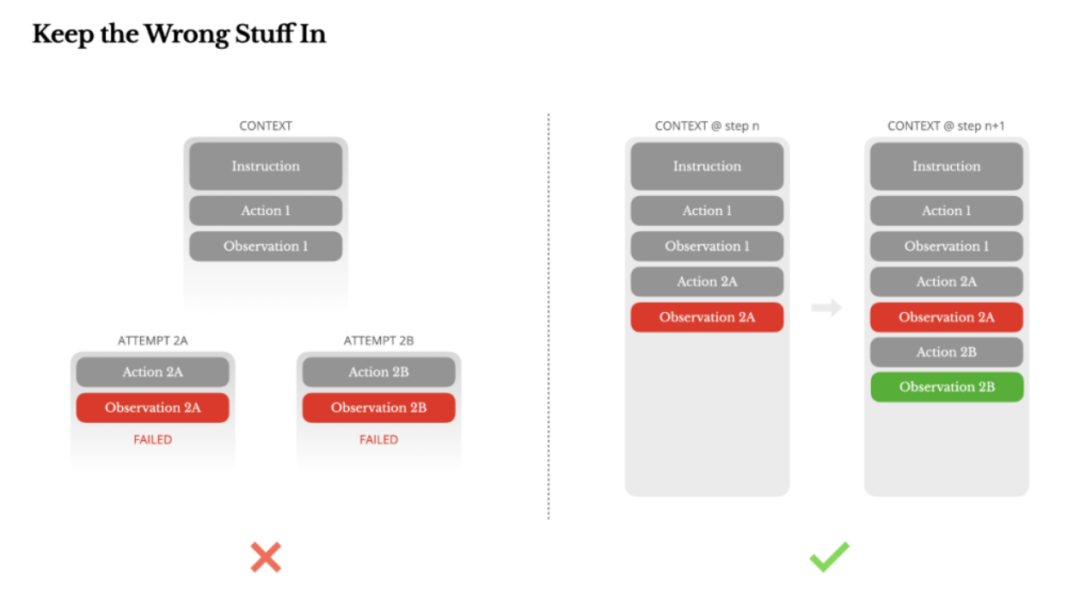
语言模型会产生幻觉,外部工具调用也可能犯错,这不是缺陷,而是现实。
一些工程尝试去掩盖这种错误,比如清理追踪记录、重试操作、重置模型状态,然后寄希望于[温度]参数。
这样看似安全、可控,但抹除失败也就相当于抹除了证据,让模型无法适应。
从错误中恢复,本身应该是Agent的行为能力之一。
Manus的实践是,把走错的路保留在上下文中,当模型看到一次失败的行动,以及对应的堆栈跟踪,他会潜移默化的更新内部信息,降低重蹈覆辙的概率。
Few-Shot是一种提升LLM输出的常用技术,但有的时候他会适得其反。
LLM是出色的模仿者,会模仿上下文中的行为模式,如果上下文中充斥着大量相似的动作和观察时,模型会延续这一模式,使得模型不再最优。大量重复类似的操作,会导致过度泛化,甚至产生幻觉。
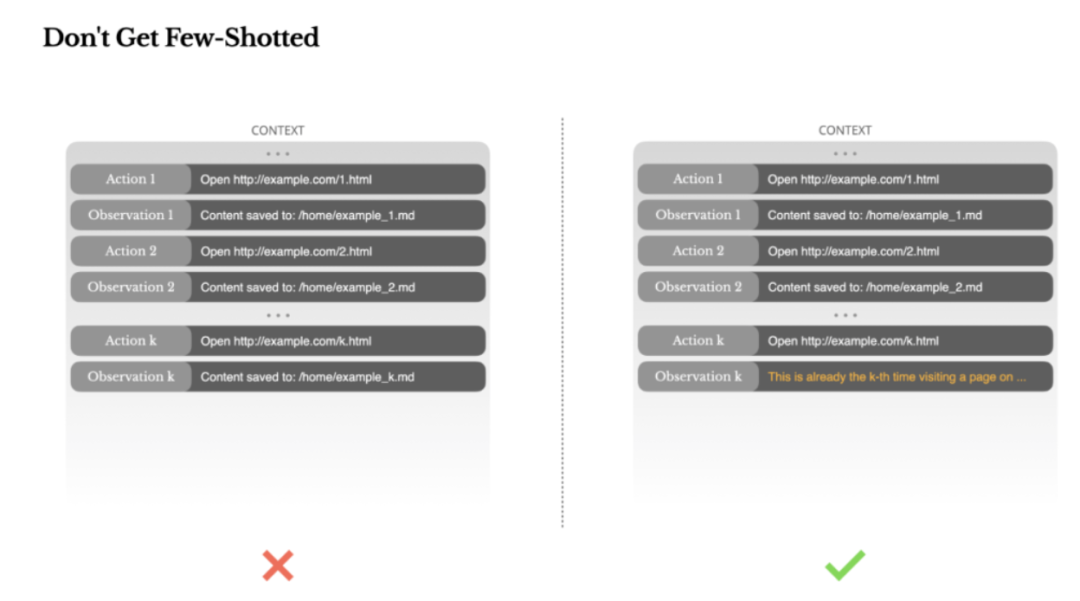
解法是,增加多样性,不要让Agent将自己困死在少量示例里面,上下文越单一,Agent就越脆弱。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号