ICLR 2026 | 打破时间序列“黑盒”:TimeOmni-1开启深度时间序列推理新篇章

ICLR 2026 | 打破时间序列“黑盒”:TimeOmni-1开启深度时间序列推理新篇章

时空探索之旅
发布于 2026-03-10 16:16:00
发布于 2026-03-10 16:16:00
📚标题:TimeOmni-1: Incentivizing Complex Reasoning with Time Series in Large Language Models
🖊作者:Tong Guan, Zijie Meng, Dianqi Li, Shiyu Wang, Chao-Han Huck Yang, Qingsong Wen, Zuozhu Liu, Sabato Marco Siniscalchi, Ming Jin, Shirui Pan
🏫机构:格里菲斯大学(Griffith),浙江大学,NVIDIA,松鼠AI,巴勒莫大学,挪威科技大学
📄论文链接:https://arxiv.org/abs/2509.24803
🤗Hugging Face:https://huggingface.co/anton-hugging/TimeOmni-1-7B
🗄️Github: https://github.com/AntonGuan/TimeOmni-1
🔮Demo:https://huggingface.co/spaces/anton-hugging/TimeOmni-1
🚩TL; DR: 来自格里菲斯大学(Griffith)、浙江大学、英伟达(NVIDIA)等机构的研究团队共同推出了TimeOmni-1——首个面向复杂时序推理的通用模型。实验表明,它在从“感知”到“外推”再到“决策”的全链路时序推理任务上,都展现出强分布外泛化能力与高有效响应率。

0. 摘要
近期,多模态时间序列学习的研究范式呈现出一个重要转变:从聚焦于基础的模式分析,迈向更深层次的时间序列理解和推理。然而,现有的多模态时间序列数据集大多停留在表面对齐和简单问答的层面,未能触及真正的深度推理。由于(1)尚未明确定义:什么是需要时间序列推理能力的任务,(2)缺乏高质量的数据,构建实用的时间序列推理模型(TSRMs)一直受限。
为此,我们正式提出Time Series Reasoning Suite(TSR-Suite)——首个系统化定义时序推理能力的数据套件,它不仅支持对TSRMs的全面评估,还提供了训练数据的构建流程。TSR-Suite 将时间序列推理拆解为三大核心能力,并通过四个原子任务进行形式化建模:
核心能力 | 原子任务 | 实际场景举例 |
|---|---|---|
🔍 感知 Perception | 场景理解 + 因果发现 | “河流监测点A水流量显著增加,是哪一个上游分支导致的?” |
🔭 外推 Extrapolation | 事件感知预测 | “周日Albert Park将举办一场F1比赛,出租车需求量会如何变化?” |
🎯 决策 Decision-making | 在感知与外推的基础上的决策 | “基于我的用电习惯,管理我的家庭储能电池的充放电策略。” |
TSR-Suite共包含超过23,000个样本,其中2,339个是通过人工引导的分层思维链标注流程(Hierarchical CoT Annotation)精心筛选的。
在此基础之上,我们正式推出TimeOmni-1——首个旨在解决各类需要时序推理能力的现实问题的通用推理模型。该模型采用多阶段训练,融合多任务场景混合、全新奖励函数设计与针对性训练优化。实验结果表明,TimeOmni-1在各项任务上具备强分布外泛化能力,并实现了高有效响应率。与GPT-4.1相比,它在因果发现任务上的准确率显著提升(64.0% vs 35.9%),并且在事件感知预测任务上,有效响应率提高了6%。
1. 引言
时间序列数据存在于各种现实世界系统中:如电网负荷、交通流量、金融行情、医疗监测等。但真正有价值的时序智能,从来不只是把一条曲线拟合得更准,而是要做多步、多跳的推理:识别外部因素驱动的变化,串起因果机制,预测事件带来的扰动,并最终支撑下游决策。尽管目前大语言模型在文本、代码等领域展现出了惊人的推理能力,然而这股浪潮尚未有效席卷时间序列领域。核心挑战在于两点:
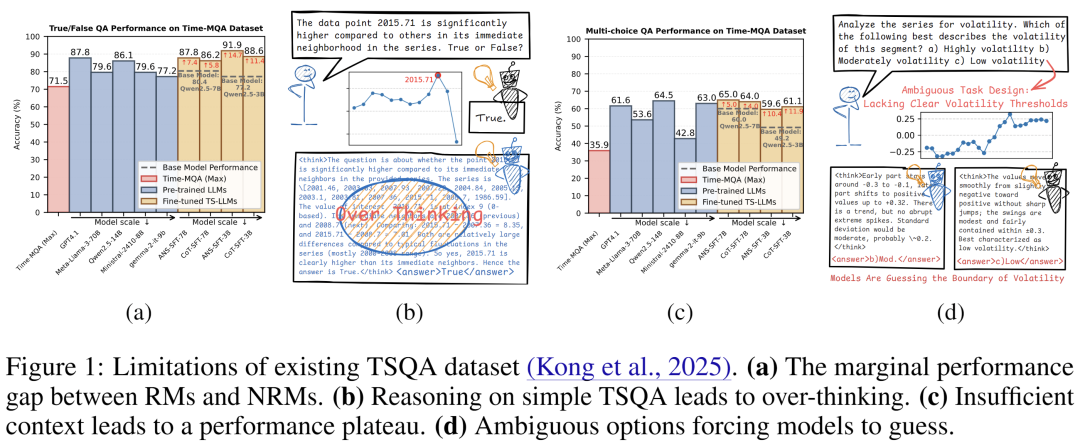
(1)高质量时间序列推理数据的极度匮乏。现有的多模态时间序列数据集,如Time-MQA,大多停留在“表面对齐”式的简单问答,缺乏深度。如图1(a)所示,在这些数据集上,GPT-4.1等强推理模型与小型基线模型(如Qwen2.5-14B)的性能差距微乎其微,这表明任务本身无需真正推理即可完成。更严重的是,如图1(b)所示,强行进行推理反而会导致“想得太多”的过度思考现象。此外,许多问题因缺乏足够的上下文信息,导致模型性能卡在停滞在65%左右难以突破(如图1(c)所示),具体表现为选项定义模糊(如图1(d)所示,缺少明确的阈值来界定“高波动”、“中等波动”、“低波动”),这迫使模型只能“盲猜”阈值,而非基于数据和计算的合理推演。
(2) 跨任务时序推理模型的构建、训练尚未得到验证。当前研究多局限于为每种任务,甚至每个数据集独立训练模型(如TimeMaster为6个时间序列分类数据集,单独训练了6个大模型),这种碎片化的范式阻碍了时序推理能力的迁移与泛化。究竟哪些任务真正需要时序推理?如何训练一个能跨任务泛化的通用时序推理模型?这些问题尚未被系统研究。
面对这些挑战,我们不禁要问:如何真正激发大模型在时间序列任务上的推理能力,使其能处理复杂的现实问题?
2. 模型方法
为解决上述挑战,我们迈出了坚实的三步:
2.1 构建时间序列推理“训练场与考场”——TSR-Suite
面对高质量时间序列推理数据的匮乏,我们首先需要回答:什么样的问答对才称得上高质量? 为此,我们确立了设计时序推理任务的两条核心原则:
- 原则一:问答对必须“奖励”推理。引入推理机制(如思维链)的模型,其表现应当显著优于直接输出答案的非推理模型。否则,这个任务就不足以称之为“推理任务”。
- 原则二:问答对必须确保上下文充分性。 与数学或代码题不同,时序推理问题的答案高度依赖于输入的时间序列X和辅助上下文C。如果X或C信息不足(例如,只问“序列方差大不大”,却不定义“方差大”的阈值),那么即便是一个拥有无限推理能力的理想模型,也只能被迫在选项中“盲猜”。只有当信息充分时,模型才能基于数据和知识进行有依据的推理。
基于这两条原则,我们紧接着回答:什么样的任务能真正激发和衡量模型的时序推理能力?为此,我们确立了时间序列推理的三大核心能力——感知(Perception)、外推(Extrapolation)和决策(Decision-making),设计了4个真正需要多步推理的原子任务(如图2所示),共同构成了 TSR-Suite。
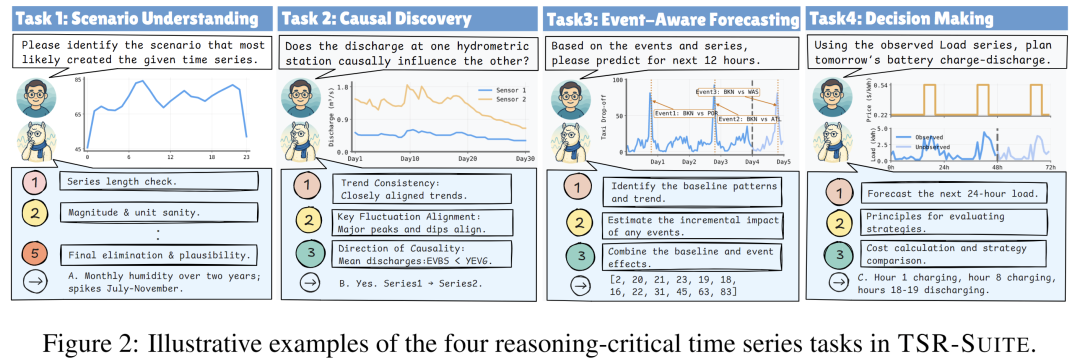
- 🔍 感知(任务1 & 2): 模型不仅要“看到”模式,更要“理解”原因。它包括场景理解(为单条序列匹配最可能的发生场景)和因果发现(在多条序列间推断因果关系)。
- 🔭 外推(任务3): 在感知的基础上,模型需结合外部事件信息进行预测,即事件感知预测。例如,预测一场即将到来的演唱会会如何影响特定区域的出租车需求量。
- 🎯 决策(任务4): 这是时序推理能力的集大成者。模型需要综合对历史模式的理解(感知)、对未来事件的预判(外推),最终做出能最大化收益或最小化成本的决策,例如,根据未来24小时的峰谷电价和用电预测,制定家庭储能电池的最优充放电策略。
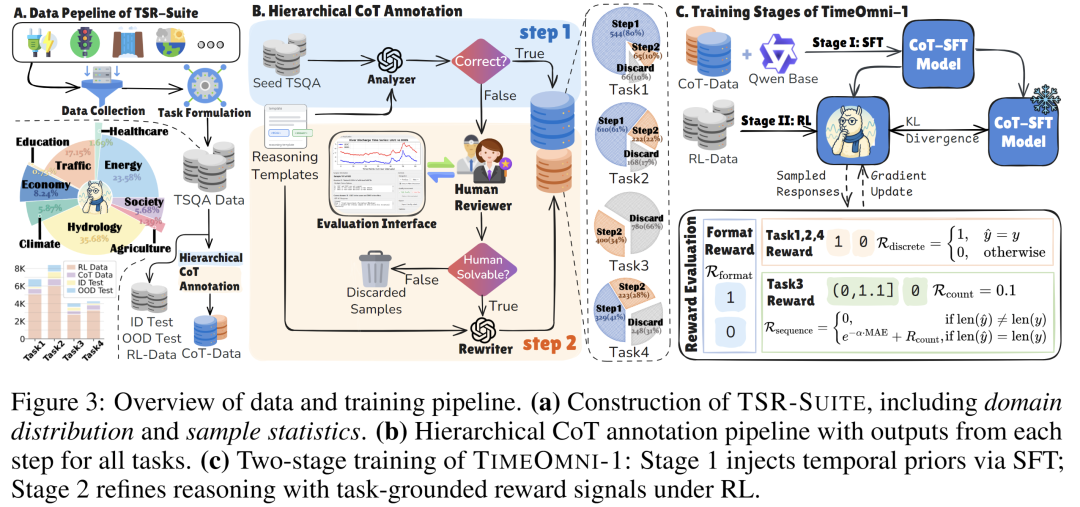
为了从根本上解决数据匮乏的问题,我们严格遵循“感知-外推-决策”的能力路径,系统性地收集了横跨10个不同领域的时间序列数据。与以往仅作为测试集的基准不同,TSR-Suite从设计之初就是一个“训练+评估”的一体化套件,如图3(a)所示。它将任务1、2、4建模为离散输出的选择题,将任务3建模为序列输出的预测题,为后续的强化学习训练奠定了基础。TSR-Suite共包含23,605个精心筛选的问答对,规模远超同类数据集(如CiK仅355个样本,TSAIA仅1,054个样本),足以支撑模型的全面训练与评估。其中,最核心的2,339个CoT样本,是通过一套人工引导的分层思维链标注流程精制而成,如图3(b)所示:
- Step 1 - 引导式可解标注:我们首先用结构化模板引导LLM分析器(LLM Analyzer)进行推理,只保留那些能被正确解决的样本,作为第一步的思维链数据。
- Step 2 - 上下文充分性验证:对于第一步失败的样本,人类专家(Human Reviewers)会介入,使用定制化界面来判断问题是否因为上下文信息不足而无法回答。如果人类专家能解决,他们书写的推理链将由LLM重写器(LLM Rewriter)润色,成为更高质量的第二步数据。对于任务3(事件感知预测),由于其开放生成的特性,人类专家特别挑选出400个平均绝对误差较低的合理预测样本,确保其保留了合理的推理步骤。
最终,TSR-Suite不仅是一个评估基准,更是一个为训练真正具备时序推理能力的模型而生的“训练场与考场”。
2.2 两阶段训练法让模型能够“举一反三”——TimeOmni-1
基于TSR-Suite,我们训练了首个通用时序推理模型TimeOmni-1。我们设计了两阶段的流程,如图3(c)所示:
- 第一阶段,通过监督微调(SFT),利用我们精心标注的CoT推理轨迹,将上述三大核心能力“感知-外推-决策”作为“时序先验知识”注入模型。
- 第二阶段,我们引入强化学习(RL),并设计了与任务紧密绑定的奖励函数,引导模型从“模仿先验”走向“稳健推理”,在探索中巩固和泛化其能力。
2.3 四点关键发现,构建时序推理模型“成长路线图”
通过大量实验,我们揭示了构建时序推理模型的四点关键发现:
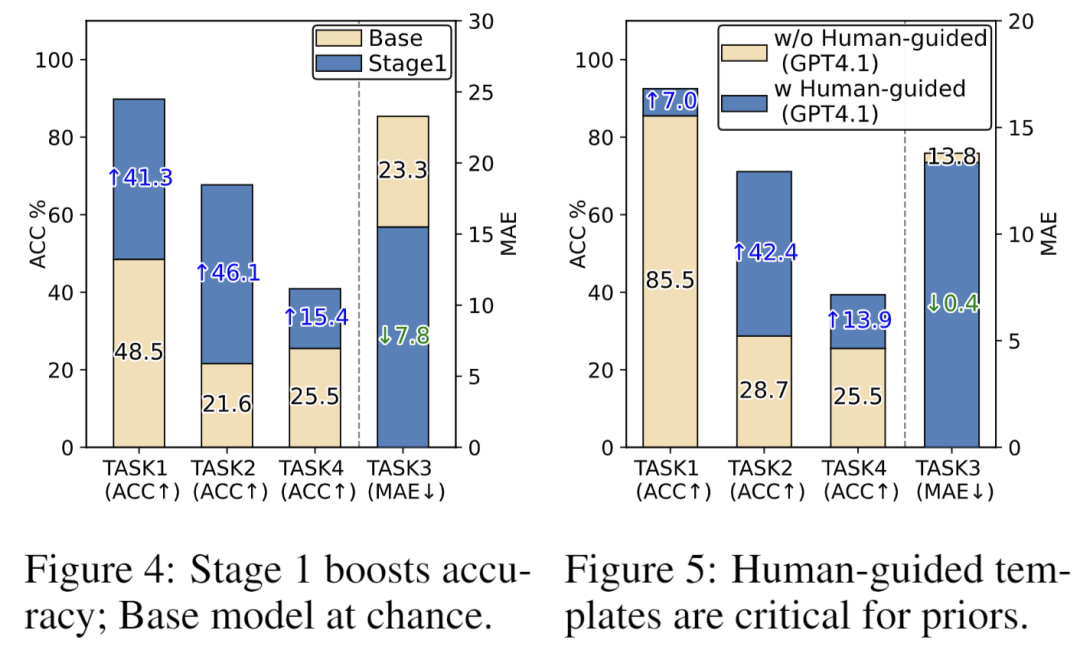
- 发现1:时序推理能力可注入。 时序推理能力并非大模型与生俱来,通过在少量高质量CoT推理轨迹上的微调即可有效注入。如图4所示,缺乏时序先验的Base模型在面对真正需要时序推理的问题时,准确率几乎等同于随机猜测(如任务2的因果发现准确率仅21.6%,而随机猜测基线为33.3%)。而注入不到1000条高质量推理轨迹后,模型在任务2上的准确率在Stage1训练后飙升了46.1%,其他任务上也取得了可比肩的提升。这有力证明,时序推理能力是可以通过系统性地注入时序先验来建立的。
- 发现2:专家知识引导的推理轨迹至关重要。人类专家引导的推理轨迹为模型提供了分解问题的“脚手架”,是学到有效推理的关键。如图5所示,使用人类引导模板后,GPT-4.1在任务2上的零样本一致性准确率从28.7%跃升至71.1%,其他三个任务上同样显著提升。这表明,预训练大模型本身就缺乏时序先验,必须通过人类专家的引导来补充这方面的知识。
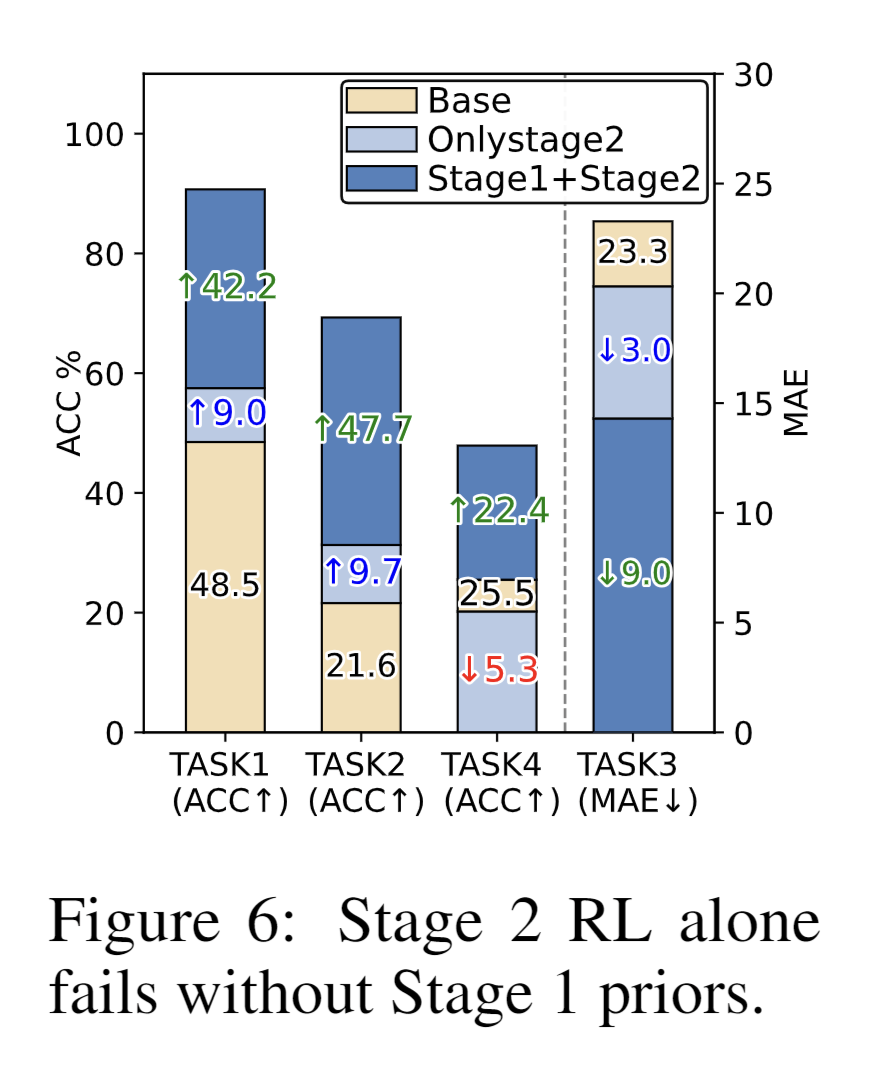
- 发现3:先验知识是RL的“安全带”。 在时序任务上直接对基础模型应用RL可能导致无效探索,只有在注入时序先验后,RL才能稳定地提升推理鲁棒性。如图6所示,直接将Stage2的RL应用于Base模型,带来的提升微乎其微,甚至在任务4(决策)上造成了5.3%的性能下降。这是因为在没有时序先验的情况下,奖励信号无法在预训练语料的空间内随机“撞”出时序先验知识。相比之下,经过Stage1注入先验后,相同的奖励函数能够有效地精炼时序先验,并逐步发展出稳健的推理能力。
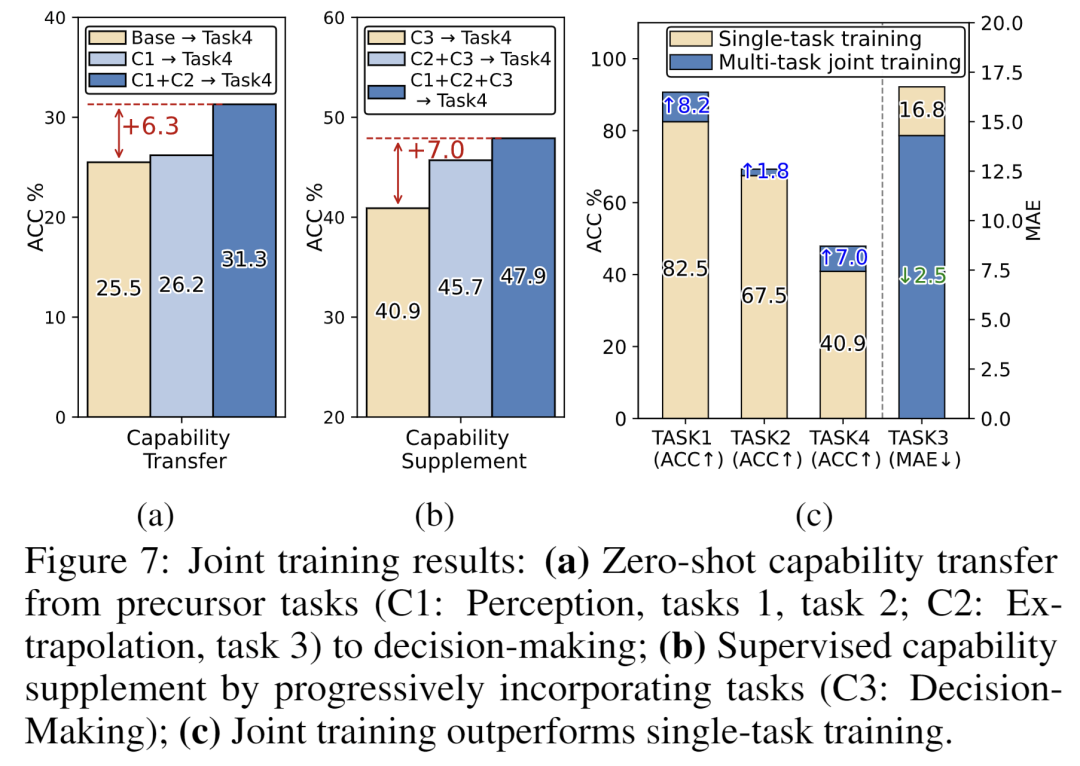
- 发现4:联合训练“感知-外推-决策”带来协同增益。 将感知、外推和决策任务进行联合训练,能产生相互增益,证明了“一次训练,多任务通用”范式的可行性。我们设计了互补的实验设置来系统研究这种协同效应。(a)零样本能力迁移:如图7(a)所示,仅在感知任务上训练的模型,其在决策任务上的零样本准确率从25.5%提升到26.2%;进一步加入外推任务后,准确率继续提升至31.3%,证明前序能力即使在没有直接监督的情况下也能增强下游推理。(b)渐进式能力补充:如图7(b)所示,逐步加入相关任务进行联合训练,决策任务的准确率从单任务训练的40.9%提升至45.7%,最终在四大任务全量联合训练时达到峰值47.9%。(c)全任务联合训练:如图7(c)所示,在所有四个任务上,联合训练始终优于单任务训练。这些结果共同证明,联合训练能有效捕捉时序推理能力间的内在联系,实现“一次训练,多任务通用”。
通过系统性的数据构建、两阶段的训练范式,以及对时序推理能力的成长路径的深入剖析,我们为构建具备通用时序推理能力的模型奠定了坚实基础。
3. 实验验证
3.1 实验设置
- 任务:TSR-Suite中的四大推理任务(场景理解、因果发现、事件感知预测、决策)。
- 基准模型 (Baselines):时序专用模型:包括Time-R1(面向经典预测任务的时序推理模型)、Time-MQA(针对时序问答微调的7B-8B模型)、以及ChatTS(用于时序理解的14B微调模型),这些模型代表了当前时序领域与LLM结合的主流方向。通用大语言模型:包括GPT-4.1的两个版本作为闭源模型代表,以及5个开源LLM(参数量从7B到70B不等,如Qwen2.5系列、Llama-3等),用于全面对比通用推理能力在时序任务上的表现。
- 评价指标:分类任务(任务1、2、4):准确率(ACC)和有效响应率(SR,即模型输出符合格式要求的比例)。预测任务(任务3):平均绝对误差(MAE)和有效响应率(SR)。
3.2 主实验结果:TimeOmni-1全面领先
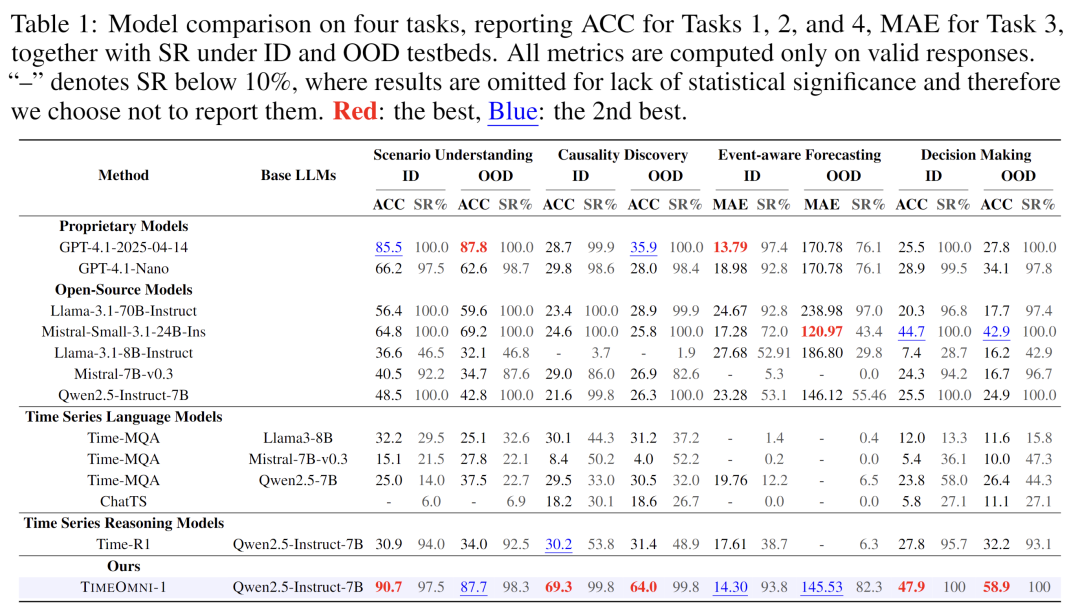
如表1所示,TimeOmni-1在所有四个推理任务上均稳居前两名。因果发现任务上,TimeOmni-1以64.0%的准确率碾压GPT-4.1的35.9%,提升幅度高达28.1个百分点,证明了模型真正学会了从数据中推断时序因果关系。在事件感知预测任务中,TimeOmni-1的MAE最低,且有效响应率(SR)高达93.8%,远高于ChatTS(SR=0%,因为它根本不能输出数字序列,只能回答文本)。这说明我们的模型不仅想得明白,还能输出规范的预测结果。在决策任务上,TimeOmni-1同样领先,准确率58.9% vs GPT-4.1-Nano的34.1%。
3.3 消融实验:TimeOmni-1为什么强?
如表2所示,我们进一步拆解了模型的各个设计要素,验证了之前提到的四点关键发现。这里补充两个重要的消融实验:
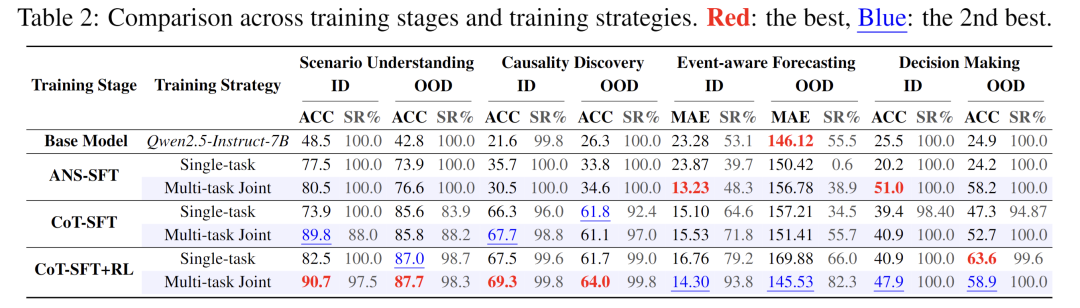
- 训练阶段消融:思维链微调是先验,RL是放大器:我们对比了仅答案微调(ANS-SFT)、思维链微调(CoT-SFT)和完整两阶段训练(CoT-SFT+RL)的效果。因果发现任务上,CoT-SFT准确率达67.7%,而ANS-SFT仅30.5%,37.2个百分点的巨大差距表明仅答案监督只会让模型死记硬背选项分布,思维链微调才真正赋予其推理“方法论”;决策任务中CoT-SFT比ANS-SFT高出10.1%(分布内)和5.5%(分布外),证明推理能力的可迁移性。完整两阶段训练在所有任务上表现最均衡、稳居前二,说明RL并非简单重复,而是将SFT阶段习得的推理先验固化为更稳健、更通用的能力。
- 训练策略消融:联合训练让1+1>2:在相同训练预算下,多任务联合训练优于单任务训练:联合训练的CoT-SFT+RL模型(即TimeOmni-1)相比单任务训练,在ID测试上,四个任务的准确率/MAE分别提升8.2%、1.8%、2.46(MAE降低)、7.0%。结合图7展示的渐进式能力迁移与补充实验,这些结果有力证明——感知、外推、决策三大能力并非孤岛,联合训练能有效捕捉其内在联系,实现“一次训练,多任务通用”,验证了先验知识是RL的“安全带”、联合训练带来协同增益的核心发现。
本文的附录还有更多实验结果与Case Study!
4. 结论
本文提出了 TSR-Suite,旨在解决时间序列推理关键数据稀缺的问题。该套件围绕时序推理的三大核心能力——感知、外推与决策,形式化了四个原子任务。以此为基础,我们推出了首个通用时序推理模型 TimeOmni-1。该模型首先通过监督微调注入时序先验,随后引入基于任务的奖励信号进行强化学习,引导其从模仿先验走向稳健推理。实验表明,TimeOmni-1 在取得顶尖性能的同时,完美保留了基座模型的通用推理能力。更重要的是,我们证明了跨不同推理任务的联合训练能带来相互增益,为未来的时序推理模型确立了 “一次训练,多任务通用” 的新范式。
5. 快速上手
方式一:在线Demo访问我们的Hugging Face Demo空间🔮https://huggingface.co/spaces/anton-hugging/TimeOmni-1,直接输入你的System Prompt以及时间序列推理问题。
方式二:本地推理
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 模型路径(自动从Hugging Face下载)
model_dir = "anton-hugging/TimeOmni-1-7B"
# Question
question = """...(你的 question 放这里)..."""
# System Prompt(用于定义输出格式)
system_prompt = (
"Output Format:\n"
"<think>Your step-by-step reasoning process that justifies your answer</think>\n"
"<answer>Your final answer (Note: Only output a single uppercase letter of the correct option)</answer>"
)
def build_prompt(question, system_prompt):
return (
f"<|im_start|>system\n{system_prompt}<|im_end|>\n"
f"<|im_start|>user\n{question}<|im_end|>\n"
"<|im_start|>assistant\n"
)
# 加载Tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_dir)
device = "cuda"if torch.cuda.is_available() else"cpu"
model = AutoModelForCausalLM.from_pretrained(model_dir).to(device)
# 构建输入
inputs = tokenizer(build_prompt(question, system_prompt), return_tensors="pt").to(device)
# 生成推理结果
outputs = model.generate(
**inputs,
max_new_tokens=4096,
do_sample=True,
temperature=0.1,
top_p=0.001,
repetition_penalty=1.05,
)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True))
推荐阅读
AI论文速读 | 当大语言模型遇上时间序列:大语言模型能否执行多步时间序列推理与推断
Time-R1:让大模型通过强化微调学会在时间维度上推理未来,构建时序预测的新范式!
欢迎各位作者投稿近期有关时空数据和时间序列录用的顶级会议和期刊的优秀文章解读,我们将竭诚为您宣传,共同学习进步。如有意愿,请通过后台私信与我们联系。
如果觉得有帮助还请分享,在看,点赞
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号