ICLR 2026 | MixLinear 时频互补 双域融合,0.1K 参数极端低资源下的多元时间序列预测

ICLR 2026 | MixLinear 时频互补 双域融合,0.1K 参数极端低资源下的多元时间序列预测

时空探索之旅
发布于 2026-03-10 16:15:12
发布于 2026-03-10 16:15:12
📝 论文标题:MixLinear: Extreme Low Resource Multivariate Time Series Forecasting with 0.1 K Parameters
🔗 论文链接:
OpenReview:https://openreview.net/forum?id=QUj0KuCumD
arXiv:https://arxiv.org/abs/2410.02081
🏆 论文发表: ICLR 2026
🔥 论文标题:长程时序预测、分割、自适应低秩谱滤波(Adaptive Low-Rank Spectral Filtering)
🖊️作者:Aitian Ma, Dongsheng Luo, Mo Sha
🏫机构:佛罗里达国际大学(FIU)
💻 开源代码(GitHub):https://github.com/aitianma/MixLinear
👤 作者主页:https://aitianma.github.io/
Aitian Ma(马艾田) :Ph.D. Candidate · Florida International University
研究方向:AIoT · 边缘学习系统 · 无线感知 · 时序预测
🎯 正在积极寻求 Faculty & Research Scientist 职位机会(2025-2026)
欢迎交流、合作与引用,如有问题欢迎通过邮件或 GitHub Issues 联系。
🎯 On the Job Market(2025–2026) )

一、逆势而行:为什么在"大模型时代"做极简模型?
过去两年,时间序列预测领域掀起了一场"军备竞赛"——Transformer 变体层出不穷,参数量从百万到千万,计算图越来越复杂,在公开 benchmark 上的数字也越刷越高。
但我们在做 AIoT 和边缘智能研究时,始终面对一个无法回避的现实问题:
那些漂亮的模型,根本跑不到设备上。
智能电表、传感器节点、工业 IoT 网关——这些设备的 RAM 可能只有几十 KB,没有 GPU,没有稳定的云连接。它们每天产生海量的多元时间序列数据,却没有任何一个"SOTA 模型"能真正部署在上面。
这就是我们提出 MixLinear 的出发点:能不能设计一个参数极致精简(≤0.1K)、计算高效,同时在长期时间序列预测(LTSF)任务上保持 SOTA 精度的模型?
这听起来像是一道不可能三角,但我们找到了突破口。
二、核心洞察:时间序列的"时频互补稀疏性"
在动手设计模型之前,我们先回答一个基础问题:时间序列的信息,究竟藏在哪里?
观察真实世界的时间序列(电力负荷、汇率、交通流量……),可以发现两类截然不同的结构:
局部动态(时域稀疏性):日内的用电波动、股价的短期震荡——这类信号在时域中呈现局部性,具有"分段线性可分解"的特征,用时域方法处理最自然。
全局模式(频域稀疏性):年度用电峰谷、季节性规律——这类信号在频域中只需极少数低频分量即可描述,本质上是"低秩"的。
这两类特征是互补的,却被现有模型用同一套架构强行建模:
- 纯时域模型(DLinear、SparseTSF):难以捕捉全局周期性;
- 纯频域模型(FITS):难以刻画局部尖锐波动;
- Transformer 类(PatchTST、iTransformer):两者都建模,但参数量高达数百万,成本极高。
MixLinear 的核心思路:既然两类特征天然分离,就用两条独立的轻量路径分别建模,最后加性融合——既无冗余,又不失表达力。
三、模型架构:双路径 + 极简线性变换
MixLinear 的整体架构如下图所示:
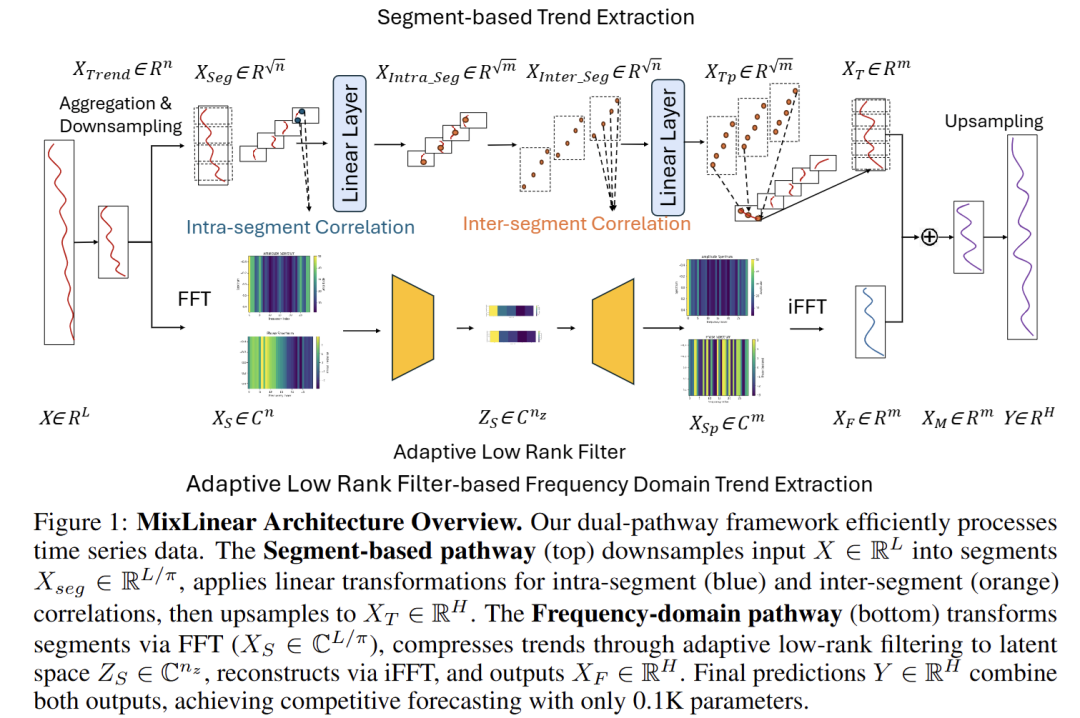
整个模型全程只依赖线性变换与傅里叶变换,没有任何注意力机制或卷积层。
3.1 时域路径:分段线性变换(建模局部特征)
目标:以 O(L) 复杂度捕捉时间序列的局部波动与跨段趋势。
核心步骤分三步:
- 分段:将下采样后的序列均匀划分为 N 个非重叠段,每段长度为 P;
- 双线性变换:
- 段内变换(Intra-segment):对每个段独立做线性压缩,捕捉段内局部特征,参数量 O(P);
- 段间变换(Inter-segment):将所有段内向量堆叠,通过线性变换建模跨段依赖,捕捉慢漂移趋势,参数量 O(N);
- 上采样重构:通过可学习上采样恢复至预测长度。
参数开销:仅 O(P + N),与通道数无关(通道共享参数)。
3.2 频域路径:自适应低秩谱滤波(建模全局特征)
目标:利用频域低秩稀疏性,以极少参数捕捉长期趋势与季节性。
核心步骤同样三步:
- FFT:将序列转换到频域,暴露全局频率结构,复杂度 O(L log L);
- 低秩滤波:不学习全尺寸滤波器(参数量 O(L·T)),而是引入秩约束分解——用编码矩阵将频域特征压缩到低维潜空间(默认秩 r=2),再用解码矩阵重建,参数量仅 O(r·L + r·T),通常 r=2 即可覆盖主要频率成分;
- iFFT 重构:逆变换回时域,上采样至预测长度。
秩-2 近似相比秩-16 减少 6 倍参数,却几乎不损失精度——这正是时间序列频域低秩假设的有力验证。
3.3 加性融合与输出
两路输出直接相加,再加回均值还原绝对数值:
Ŷμ
采用加性融合而非乘法融合,避免梯度不稳定,训练更稳定,且无额外参数开销。
四、极致的参数效率:究竟有多"极简"?
代入默认超参数(段长度 P=4,谱秩 r=2,下采样因子 s=4),MixLinear 总参数约 176 个(0.176K)。
以 720 步预测 horizon 为例,横向对比如下:
模型 | 参数量 | 类型 |
|---|---|---|
MixLinear | ~176 个(0.1K) | 双路径线性 |
SparseTSF | ~1,000 个(1K) | 稀疏线性 |
FITS | ~10,512 个(10K) | 频域线性 |
DLinear | ~数万 | 线性 |
PatchTST | ~6,310,000 个(6.31M) | Transformer |
iTransformer | ~数百万 | Transformer |
MixLinear 的参数量比 SparseTSF 少 81%,比 FITS 少 99%,比 PatchTST 少约 6 万倍。
更重要的是,MixLinear 的参数量随预测 horizon 增长呈近线性趋势,而 SparseTSF、FITS 呈陡峭增长——这意味着在超长 horizon 场景下,MixLinear 的优势会更加显著。
五、实验结果:精简不等于妥协
我们在 8 个标准 LTSF benchmark 上进行了全面评估,涵盖低维数据集(ETTh1/2、ETTm1/2、Exchange,7-8 通道)和高维数据集(Electricity 321 通道、Traffic 862 通道、Solar 137 通道)。
5.1 预测精度:与 SOTA 相当,部分场景超越
低维数据集亮点:
- Exchange 数据集(96 horizon):MSE 0.088,相比 SparseTSF(0.105)提升 16.2%;
- ETTh1 数据集(336 horizon):MSE 0.411,相比 SparseTSF(0.434)提升 5.3%;
- 长 horizon 鲁棒性:720 horizon 下,所有数据集均保持 Top-2 精度,MSE 波动不超过 0.005。
高维数据集亮点:
- Electricity(720 horizon):MSE 0.209,优于 FITS(0.212),与 SparseTSF 相当;
- Traffic(720 horizon):MSE 0.452,显著优于 TimesNet(0.640),与 SparseTSF 持平。
5.2 计算效率:速度快 2-3 倍
MACs(乘积累加操作)对比(720 horizon):
场景 | MixLinear | SparseTSF | FITS |
|---|---|---|---|
ETTh1(低维) | 196.56K | 277.20K | 292.32K |
Traffic(高维) | 24.2M | 34.14M | 36.00M |
MixLinear的MACs比SparseTSF低约41%,比FITS低约 49%。
推理速度对比:
场景 | MixLinear | SparseTSF | FITS |
|---|---|---|---|
Exchange(低维) | 0.25ms | 快 3.2× | 快 1.72× |
Electricity(高维) | 2.05ms | 快 2.12× | 快 2.58× |
六、消融实验:双路径的价值
通过移除单条路径的对照实验,我们验证了双路径协同的必要性:
低维数据集(ETTh1/2):仅时域路径优于仅频域路径,说明局部特征对低维数据更关键;双路径融合后精度进一步提升。
高维数据集(Electricity/Traffic):仅频域路径优于仅时域路径,说明高维数据更依赖全局频率模式;双路径融合后达到最优(Traffic MSE 0.452 vs 单频域路径 0.478)。
结论:两条路径捕捉的是互补信息,移除任一条都会导致性能下降,双路径的额外计算成本(仅增加少量 MACs)完全值得。
七、超参数鲁棒性:工程部署友好
实际部署时,超参数调整成本是工程师最关心的问题之一。我们对此做了详细分析:
段长度:低维数据最优为 4-8,高维数据对段长度几乎不敏感(Traffic 的 MSE 曲线近乎平直)。段长度从 2 增至 16 时,MACs 可降低 3 倍,为用户提供了精度-效率的灵活调配空间。
谱秩:r=2 即可实现近最优精度,增至 24 时 MSE 仅提升 0.005,但 MACs 从 275K 增至 350K。r=2 是默认配置,无需调参。
下采样因子:因子在 2-36 范围内波动时,MSE 变化不超过 2-3%,模型对此参数高度鲁棒,适配不同计算预算。
八、适用场景与部署建议
MixLinear 的设计天然适合以下场景:
🏭 工业 IoT & 边缘计算:传感器节点、PLC 设备直接运行本地预测,无需云端推理。
⚡ 智能电网 & 能源管理:实时负荷预测,毫秒级响应。
🚦 交通流量预测:高维(862 通道)场景下仍保持 2ms 以内的推理延迟。
📱 移动端实时预测:参数量 <200 个,可直接嵌入 MCU 或手机 APP。
☁️ 云端大规模部署:极低计算成本意味着同等算力下可服务更多并发请求,显著降低 inference 成本。
九、总结:极简背后的设计哲学
MixLinear 的核心贡献不仅仅是"参数少",而是揭示了一个重要的建模原则:
时间序列中存在天然的时频互补稀疏结构——局部动态适合时域分段线性建模,全局模式适合频域低秩近似。两者分离建模、加性融合,既无结构错配,又无参数冗余。
这一原则让我们用 176 个参数做到了百万参数模型才能达到的预测精度,实现了"高效化"与"精准性"的统一。
我们相信,在 AIoT 和边缘智能快速发展的今天,轻量高效的模型设计与大模型探索同样重要,甚至更为迫切。MixLinear 是我们在这条路上的一次尝试,希望它能为社区提供新的思路与参考。
推荐阅读
TPAMI & ICML Oral | SparseTSF:轻量且鲁棒的稀疏时序预测
ICLR 2026 | 打破CI/CD二元对立:CPiRi——基于通道置换不变性的多元时空解耦新范式
ICLR 2026 | 时间序列(Time Series)论文总结(上)【预测,多模态,预测×LLM,基础模型】
ICLR 2026 | 时间序列(Time Series)论文总结[下]【分类,异常检测,生成,插补,LLM与基础模型】
欢迎各位作者投稿近期有关时空数据和时间序列录用的顶级会议和期刊的优秀文章解读,我们将竭诚为您宣传,共同学习进步。如有意愿,请通过后台私信与我们联系。
如果觉得有帮助还请分享,在看,点赞
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号