文心 ERNIE 5.0 技术报告解读:把“理解 + 生成”统一进一个自回归全模态大模型

文心 ERNIE 5.0 技术报告解读:把“理解 + 生成”统一进一个自回归全模态大模型

时空探索之旅
发布于 2026-03-10 15:59:07
发布于 2026-03-10 15:59:07
1月22日,百度发布并上线原生全模态大模型文心5.0正式版。该模型参数达2.4万亿,采用原生全模态统一建模技术,具备全模态理解与生成能力,支持文本、图像、音频、视频等多种信息的输入与输出。
文心 ERNIE 5.0不仅代表了参数规模的新高度,更展现了一条区别于传统“拼接式”多模态方案的技术路线——原生全模态统一建模。这种从底层架构开始的深度融合,使得模型能够像人类一样同时理解文字描述、图像细节、音频情绪和视频逻辑,无需在不同模态之间进行损耗性的“翻译”。

技术报告:https://arxiv.org/abs/2602.04705
✅ 论文速读:
- 核心技术突破:
- 多模态交互的“时空连续性”突破:引入时空连续性编码框架,在特征空间中构建模态间的动态映射关系
- 动态学习架构的“自我演化”能力:引入动态学习单元(DLU),该架构允许模型在运行时动态调整部分神经元的连接权重,而无需全局重训练
- 全栈自研生态的“负反馈优化”机制:从芯片到应用层的全栈自研能力,这种闭环设计使模型迭代周期从季度级缩短至周级
- 评测结果:
- 在40余项权威基准的综合评测中,文心5.0正式版的语言与多模态理解能力超越Gemini-2.5-Pro、GPT-5-High等模型,稳居国际第一梯队
- 图像与视频生成能力与垂直领域专精模型相当,整体处于全球领先水平
01|技术背景
近两年多模态模型的主流路线,大多是“语言主干 + 各模态外挂解码器”:理解做得不错,但输出仍然偏文本中心;为了克服这一限制,最近的研究方法通过后期融合设计(late-fusion),将特定模态的解码器或生成器添加到预训练的语言模型中。
这类设计尽管有效,但天然存在三类硬伤:
- 理解与生成割裂:跨模态深度耦合不够,生成很难“吃到”理解层的语义优势。
- 目标函数不统一:不同模态用不同的训练范式/损失,优化轨迹不一致。
- 能力跷跷板(ability seesaw):后接模块越多,越容易影响语言能力或整体对齐表现。
ERNIE 5.0 的核心主张是:用一个统一的自回归范式,同时覆盖多模态理解与多模态生成,并且从头训练让各模态能力共同进化。
02|总体框架:统一自回归 + 统一 token 空间
ERNIE 5.0 的设计目标是:文本、图像、音频、视频在同一套框架下完成理解与生成。
■ 关键点 A:共享 token 空间
- 将异构输入(text/image/audio/video)映射到共享 token space,序列化成统一 token 序列。
- 模型在训练和推理时不显式区分模态边界,而是以“统一序列建模”处理所有输入输出。
■ 关键点 B:统一的 Next-Group-of-Tokens Prediction 目标
- 文本:标准 Next-Token Prediction(并结合 Multi-Token Prediction 机制提升质量与效率)。
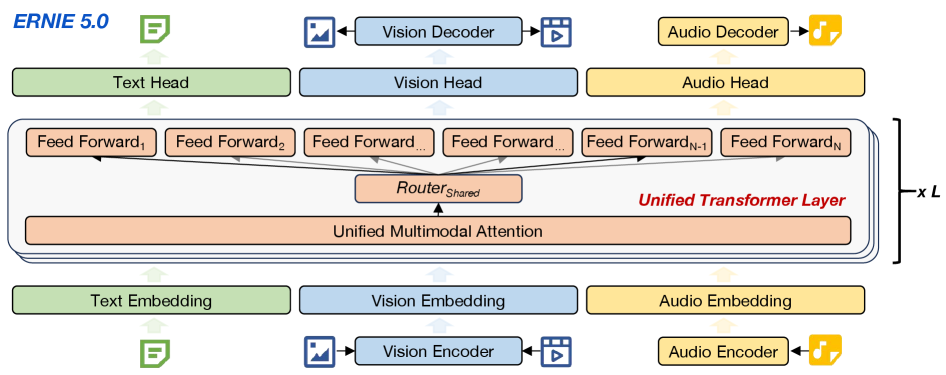
- 视觉:将生成改造为group-of-tokens的自回归预测,提出NFSP(Next-Frame-and-Scale Prediction)。
- 音频:提出NCP(Next-Codec Prediction),对层级 codec token 做结构化预测。
结果是:不同模态都被“拉回到”同一种自回归训练范式里,减少优化冲突。
多模态差异很大(语义、时序结构、训练动态都不同),要做“真统一”,必须有足够容量以及稳定训练手段。
因此ERNIE 5.0 的骨干网络采用的是超稀疏 MoE + 模态无关路由。
■ Ultra-sparse MoE:激活率 < 3%
- 用 MoE 扩容量,但保持训练/推理成本可控。
- “超稀疏”意味着总参数巨大,但每次只激活极小部分专家,每个模块负责处理特定类型的任务(如中文诗歌生成、图像语义分割、复杂逻辑推理等)。
■ Modality-agnostic Routing:路由不看“模态标签”
- 路由仅基于统一token表征做决策,而不是用“这是图像/音频”这类显式标识。
- token 来自不同模态会被分发到同一“共享专家池”,让专家的分工由数据与任务自然塑形,而非人工划分。
■ 训练稳定性:无辅助损失的负载均衡
采用auxiliary-loss-free load balancing,在万亿级MoE下维持路由使用更稳。
03|视觉:一套体系同时服务“理解 + 生成”
ERNIE 5.0 把图像视为单帧视频,视觉侧围绕统一范式做了两条关键设计:tokenizer与理解表示。
■ 视觉 tokenizer:2D → 3D 的渐进式统一
- 先训练 causal 2D multi-scale tokenizer(图像),再扩展为causal 3D conv tokenizer(视频)。
- 引入对抗损失(GAN discriminator)提升分布拟合;引入语义分支与语义正则增强语义一致性。
- 采用 bit-code 量化,以及progressive tokenizer switching(渐进式分词器切换策略):从低 bit(小词表、粗粒度)逐步切换到高 bit(大词表、细粒度),让训练更平滑,有效缓解早期训练的不稳定性,从而提升视觉生成质量。
■ 视觉理解:CNN + ViT 双路融合 + Attention Patch Merger
- 在量化之前,视觉特征通常会被下采样模块压缩成低维表示,其维度与分词器的位宽一致。这种压缩不可避免地会导致细粒度语义信息的丢失,因此直接使用量化前的双路特征:CNN(细粒度感知)+ ViT(全局语义)。
- 不用简单 MLP 粗暴融合,而是用自注意力在 patch 维度建模,再 pooling 得到紧凑表示。
- 在文档/图表理解、通用视觉任务上更稳,且为后续“编辑/生成”保留细节。
■ 视觉生成:NFSP + Uni-RoPE + 抗误差累积
- NFSP:空间上由低分辨率到高分辨率“逐尺度预测”,视频再叠加“逐帧预测”。
- Uni-RoPE:为了支持跨空间和时间维度的异构标记的位置建模,引入了统一时空旋转位置编码,用 (t, h, w) 同时标记时序与空间位置。
- 通过历史 token bit-flip corruption 训练自纠错,缓解长序列误差累积。
- 高分辨率难题用“AR backbone 产出低分辨率结构语义结合 diffusion refiner 补细节”的级联策略,避免把 diffusion 目标硬塞进同一个主干导致冲突。
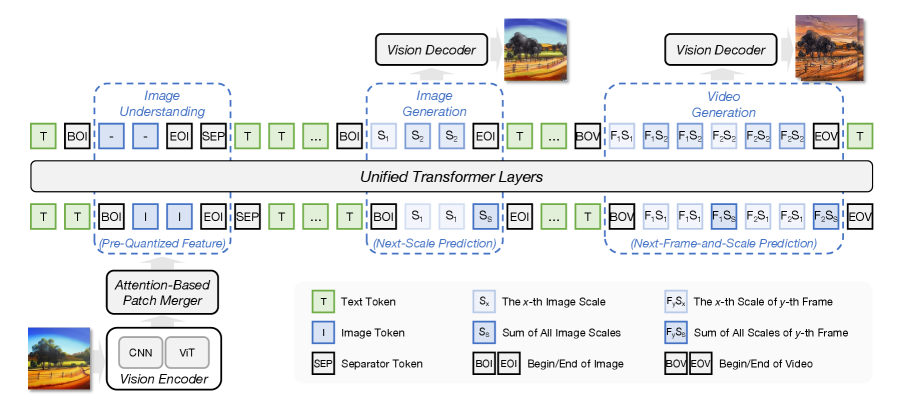
04|音频:层级 codec token 的“深度自回归”生成
音频如果把 multi-codebook tokens 全部 flatten,会变成超长序列。ERNIE 5.0 用结构化建模解决:
■ 音频 tokenizer:RVQ 层级离散码
- 使用码片式分词器将连续音频信号映射到一系列离散的标记,分词率为12.5Hz ,RVQ 将音频分解为多级残差 token:
- 第一个标记被明确地用于编码高层音频语义(语言/音素等)。
- 其余标记则编码具有逐渐更精细细节的残差声学信息。
- 为了确保第一个标记能够捕获音频-文本建模所需的丰富语义信息,因此用 Whisper encoder 表征蒸馏对齐第 1 级语义 token,强化音频-文本建模基础。
■ NCP:Next-Codec Prediction
- 不把层级 token 展平,而是在 transformer 的不同层做由粗到精的预测范式:
- 先预测语义编码,再逐级生成残差编码;
- 每次预测后,生成的编码都会被映射到其对应的嵌入向量,并添加到隐藏状态中,从而影响下一层的预测。
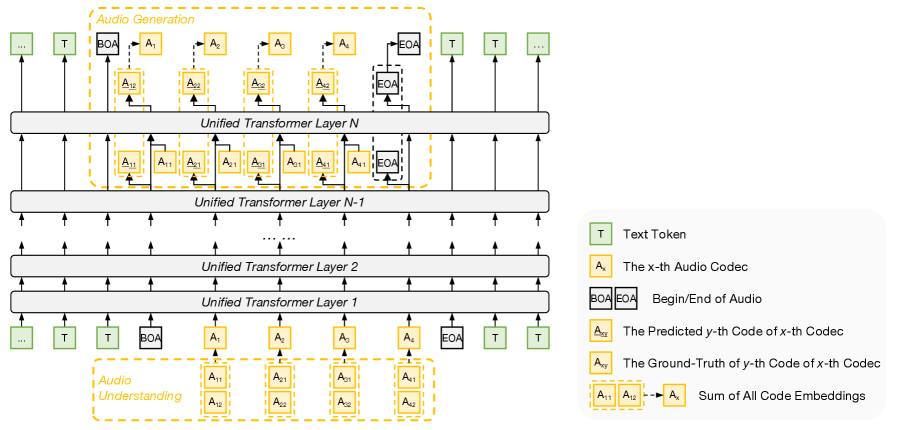
05|Elastic Training:一次预训练,导出一族模型
传统是“训练大模型 → 再压缩(剪枝/蒸馏)”,成本高且尺寸固定。
ERNIE 5.0 提出elastic training(Once-for-All 思路扩展到预训练),在预训练期间同时优化一系列子网络,从而能够高效地利用单个大型模型按需生成更小、更易于部署的变体。
■ 三个维度一起弹性
- Elastic Depth:随机激活不同层数(大部分用全深度,小部分采样浅层),让中间表征更“可用”。
- Elastic Width:MoE 专家数量可弹性(部分样本限制在子集专家),支持内存受限部署。
- Elastic Sparsity:routing top-k 可弹性(推理时减少激活专家数),提高推理效率。
■ 直接效果(报告中的结论)
- 推理时 top-k 降到 25%:带来 >15% 解码加速,精度仅小幅下降。
- 全弹性版本可在显著减少“激活参数/总参数”的情况下保持接近满配性能(报告给出 53.7% activated、35.8% total 的量级描述)。
06|后训练:SFT + 统一多模态 RL(UMRL)
多模态结合超稀疏 MoE 会让 RL 更敏感:采样偏置、稀疏奖励、熵塌缩、训练-推理不一致都会被放大。
ERNIE 5.0 的 post-training 主要靠一套“可扩展的稳定化组合拳”:
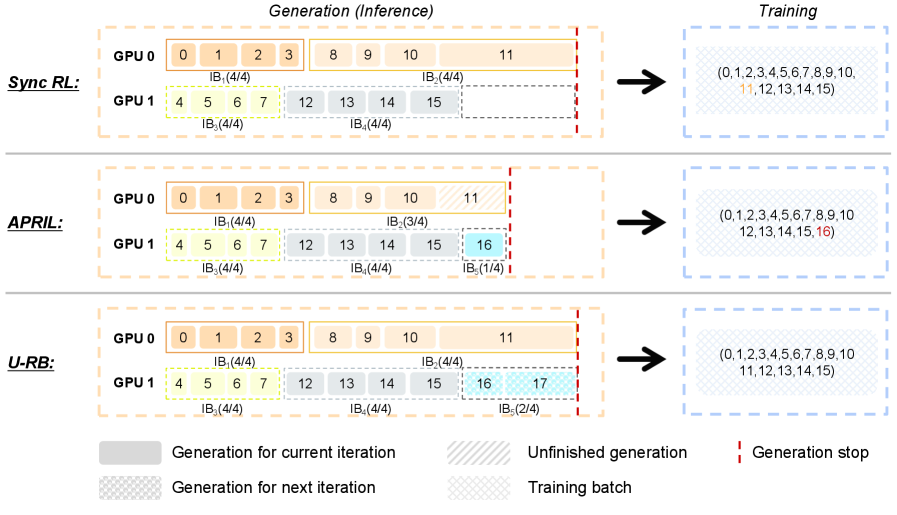
■ Rollout 效率:U-RB(Unbiased Replay Buffer)
- 针对 rollout 长尾导致 GPU 空转:在异步生成的同时保持数据顺序约束,既提升吞吐,又避免只用“短样本/易样本”更新造成难度分布漂移。
■ 训练稳定:MISC + WPSM
- MISC(多粒度重要性采样裁剪):避免 sequence-level 截断导致的熵快速塌缩。
- WPSM(已掌握正样本掩码):对“已学会 + 低熵”的样本减少梯度预算,把学习容量转向难样本/稀疏奖励任务。
■ 稀疏奖励:AHRL(自适应提示式 RL)
- 对难题注入“部分 think skeleton/hints”,先搭脚手架提升有效样本率,再按 schedule 逐步撤掉提示,让模型回到自探索。

07|训练基础设施:把“统一训练”真正跑起来
ERNIE 5.0 的 infra 重点解决三件事:万亿 MoE 的内存与通信、多 tokenizer 的负载不均、异构 attention mask 的效率。
- Hybrid parallelism 结合精细内存控制:TP/PP/EP/ZeRO/context parallel 组合;FP8 混合精度;激活动态offload;子batch降碎片;VMM自动defrag。
- Tokenizer–Backbone 解耦部署:tokenizer 单独作为服务跑在独立 GPU 节点,各自用最合适的并行策略,减少整体 load imbalance。
- FlashMask:高效处理 per-sample 异构注意力 mask(尤其视觉局部双向注意力),并与 context parallel 深度融合。
- 可扩展 RL 基建:训练/rollout/环境交互解耦调度,统一 FP8 stack 降低训练-推理数值不一致。
08|评测解读:强项在哪里?
从报告给的表格与文字结论看,ERNIE 5.0 强调的是“统一与均衡”而不是只押某个单点榜单:
- 知识与多指令遵循:多项 QA 与 multi-instruction 评测表现突出。
- Agent 相关能力:在ACEBench(中英)、BrowseComp-zh等任务表现亮眼。
- 文档/图表理解:ChartQA、DocVQA、OCRBench 等指标很强,契合其视觉理解的双路表示设计。
- 生成侧:图像 GenEval 与视频 VBench 表现“对齐语义”能力较强(尤其 VBench-Semantic 有优势),符合“统一语义表征反哺生成”的路线。
整体来看:
- 在40余项权威基准的综合评测中,ERNIE 5.0的语言与多模态理解能力超越Gemini-2.5-Pro、GPT-5-High等模型,稳居国际第一梯队。
- 图像与视频生成能力与垂直领域专精模型相当,整体处于全球领先水平。
结语|ERNIE 5.0 的技术信号是什么
简单用一句话来说:它不是在“多加几个模态头”,而是在把多模态理解与多模态生成彻底统一到一个自回归训练范式里,并用超稀疏 MoE + 弹性训练把规模、效率与部署灵活性一起做了。
更具体的三点启示:
- 统一目标函数比“拼接模块”更有机会获得深层跨模态耦合;
- MoE 的路由设计(模态无关)可能会成为下一代 omni 模型的关键工程范式;
- Elastic pretraining 让“一个大模型 → 多个可部署形态”从后压缩时代,进入“预训练即具备弹性”的新阶段。
END
感谢观看,欢迎关注/点赞/转发~🌟
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号