CVPR 2026 | 用一句话告诉 AI 分割什么——MedCLIPSeg 让医学图像分割不再需要海量标注
原创
CVPR 2026 | 用一句话告诉 AI 分割什么——MedCLIPSeg 让医学图像分割不再需要海量标注
原创
CoovallyAIHub
发布于 2026-03-10 14:22:11
发布于 2026-03-10 14:22:11
假设你是一名放射科医生。
你面前有一张乳腺超声图像,你需要 AI 帮你标出肿瘤边界。
传统方法:你需要先准备几千张标注好的图像来训练模型,换个器官就得从头再来,换个医院的设备可能就不准了。
MedCLIPSeg 的方法:你输入一句话——"a hypoechoic mass with irregular margins in the upper breast region"(乳腺上方区域一个边缘不规则的低回声肿块)——AI 就能给你分割结果,附带一张不确定性地图告诉你"哪里我不太确定"。
screenshot_2026-03-09_15-22-38.png
而且,只用 10% 的标注数据,它就能超过很多用 100% 数据训练的方法。
这篇论文来自加拿大 Concordia 大学的 Taha Koleilat 团队,已被 CVPR 2026 接收,代码、模型和数据集已全部开源。

screenshot_2026-03-09_15-21-45.png
- 标题:MedCLIPSeg: Probabilistic Vision-Language Adaptation for Data-Efficient and Generalizable Medical Image Segmentation
- 作者:Taha Koleilat, Hojat Asgariandehkordi, Omid Nejati Manzari, Berardino Barile, Yiming Xiao, Hassan Rivaz
- 机构:Concordia University, Montreal, Canada
- 会议:CVPR 2026
- arXiv:2602.20423(2026.02.23)
- 代码:github.com/HealthX-Lab/MedCLIPSeg
- 模型/数据:huggingface.co/TahaKoleilat/MedCLIPSeg
医学图像分割的三重困境
在进入方法之前,先理解为什么这个问题如此棘手:
- 困境一:标注太贵。 医学图像的像素级标注需要专家逐个勾画,耗时耗力,而且不同专家画出来的都不一样。
- 困境二:边界模糊。 肿瘤和正常组织之间往往没有清晰的分界线,部分容积效应让决策变得困难。
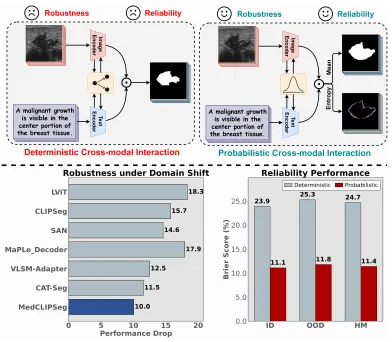
- 困境三:域偏移。 换一台扫描仪、换一个医院、换一批患者,模型性能可能直接崩塌。而传统的分割模型在出错时还不会"告诉你它不确定"——它会以 99% 的信心给你一个错误答案。
MedCLIPSeg 一次性瞄准了这三个问题。
核心思路:让 CLIP "看懂"医学图像,还知道自己"看不看得准"
MedCLIPSeg 的设计思路可以拆成三层:
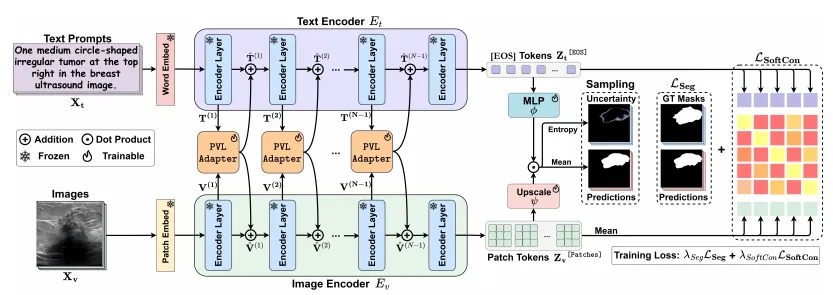
- 第一层:用文字引导分割
基于 CLIP 的图文对齐能力,MedCLIPSeg 用文字描述来引导分割——告诉模型"你要找的是什么",模型就去图中对应位置分割。
为什么这有用?因为临床描述比像素标注容易获取得多。医生每天都在写报告描述病灶,但很少有时间去逐像素勾画。
- 第二层:概率化注意力——让模型知道自己"不确定"
这是论文最核心的创新。
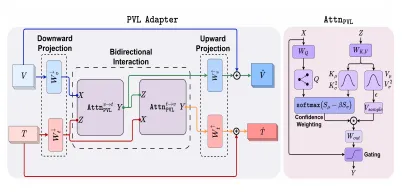
传统的 CLIP 适配方案用确定性(deterministic)表示来融合图文信息。MedCLIPSeg 把注意力机制中的 Key 和 Value 建模为概率分布(均值 + 方差),而不是固定向量。
这意味着什么?
- Key 的方差反映了图文匹配的不确定性→ 模型会自动降低不确定 token 的注意力权重
- Value 的方差反映了特征本身的不确定性→ 通过蒙特卡洛采样,推理时生成多次预测,取均值作为分割结果,取熵作为逐像素不确定性地图
这种设计自然地捕获了两类不确定性:偶然不确定性(数据本身的模糊性,如边界模糊)和认知不确定性(模型未见过的分布)。
screenshot_2026-03-09_15-23-39.png
- 第三层:双向融合 + 软对比损失
- 双向 PVL Adapter:视觉 token 和文本 token 互相增强(vision→text + text→vision),而不是单向的文本注入图像
- 软对比损失:用 patch 级别的图文对比学习来保持 CLIP 的泛化能力,用软标签(而非硬标签)处理语义相似的文本描述
整个过程不修改 CLIP 的预训练参数,只训练新加入的轻量级 Adapter。
screenshot_2026-03-09_15-24-06.png
实验:16 个数据集、5 种模态、6 个器官
这是这篇论文最有说服力的部分——实验覆盖范围极广。
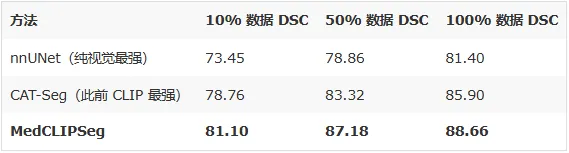
- 数据效率:只用 10% 数据就逼近最强模型的全量性能
screenshot_2026-03-09_15-11-20.png
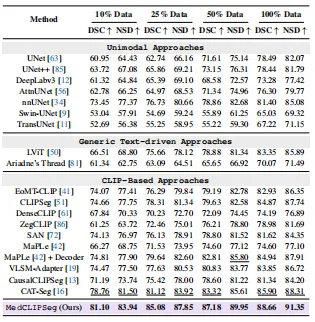
screenshot_2026-03-09_15-26-03.png
关键发现:
- MedCLIPSeg 用 10% 数据(DSC 81.10)已经逼近 nnUNet 用 100% 数据的性能(81.40)
- 在所有数据比例下均稳定领先 CAT-Seg 2-4 个百分点
- 100% 数据下达到 88.66% DSC / 91.35% NSD
- 域泛化:换个医院的设备,还准不准?
论文在 4 组跨域实验中测试泛化能力(训练 A 医院数据,直接测试 B/C/D 医院):
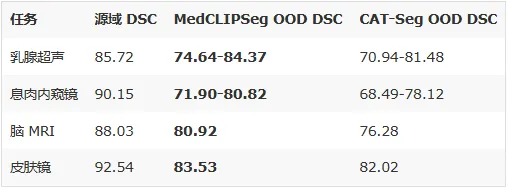
screenshot_2026-03-09_15-11-46.png
所有 OOD 场景下均为最佳。 这说明概率化建模确实提高了跨域鲁棒性。
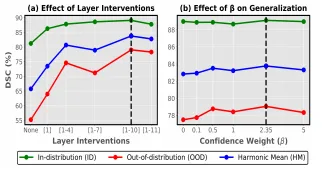
- 消融实验:每个组件贡献多少?
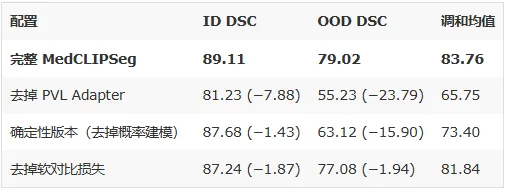
screenshot_2026-03-09_15-11-58.png
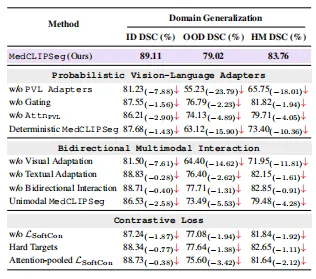
screenshot_2026-03-09_15-26-50.png
最重要的发现:
- 去掉 PVL Adapter → OOD 性能暴跌 23.8 个百分点,这是整个框架的基石
- 确定性 vs 概率化 → OOD 差距 15.9 个百分点,证明概率建模对域外泛化的贡献是决定性的
- 概率建模将 Brier 分数从 (23.9%, 25.3%) 降至 (11.1%, 11.8%),过度自信问题显著缓解
不确定性地图:AI 对自己的分割打"信心分"
这是 MedCLIPSeg 最具临床价值的功能。
推理时,模型通过 30 次蒙特卡洛采样生成多个预测,取均值作为最终分割,取预测熵作为不确定性地图。
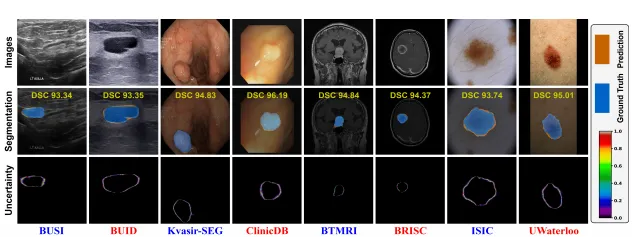
screenshot_2026-03-09_15-27-23.png
结果显示:
- 不确定性高度集中在病灶边界和专家标注有分歧的区域
- 不确定性与实际分割误差的 Spearman 相关系数达到 87.57%(域内)/ 80.41%(域外)
这意味着:AI 不确定的地方,往往就是它真的会出错的地方。 医生看一眼不确定性地图,就知道哪些区域需要自己再仔细检查。
screenshot_2026-03-09_15-28-33.png
这比一个"看起来很确定但实际上错了"的模型,要有用得多。
为什么这篇论文值得关注?
- 解决了 CLIP 做医学分割的"最后一公里"
之前的工作要么只冻结 CLIP 加一个解码器(效果有限),要么只做单向文本→视觉注入(泛化不足)。MedCLIPSeg 的双向概率融合,既保留了 CLIP 的泛化能力,又让它能做精细的像素级分割。
- 概率化不是"加分项",是"必需品"
消融实验清楚地证明:确定性版本在域内只差 1.4%,但域外差了 15.9%。也就是说,概率建模对模型在"舒适区"内的影响很小,但在"舒适区"外是救命的。
这恰好是临床场景最需要的——模型不怕在熟悉的数据上稍微逊色,但绝不能在陌生数据上自信地给出错误答案。
- 文本提示的设计比你想象的重要
论文中一个容易被忽略的实验(Table 4):
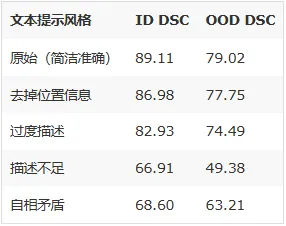
screenshot_2026-03-09_15-12-13.png
过度描述比描述不足好,但都不如简洁准确。 这给临床部署提供了重要的实操指导:prompt 不需要写得很长,但关键信息(位置、形态)不能少。
技术细节速览
概率注意力的数学直觉:
标准注意力:
MedCLIPSeg:
其中 是 Key 的均值和标准差,,。
翻译:注意力分数不仅看"匹不匹配",还要减去一个"不确定惩罚"。越不确定的 Key,权重越低。
实验配置:
- 骨干:UniMedCLIP ViT-B/16 + PubMedBERT
- 训练:100 epoch,学习率 3×10⁻⁴,batch size 24,Adam + 余弦退火
- 损失:0.5 × 分割损失(Dice + BCE 等权)+ 0.1 × 软对比损失
- PVL Adapter 介入层:深层,最优在第 10 层
- 推理:30 次蒙特卡洛采样
- GPU:单卡 NVIDIA A100 (40GB)
写在最后
医学 AI 领域有一个被反复验证的经验:模型不够准不是最可怕的,模型不知道自己不够准才是最可怕的。
MedCLIPSeg 的价值,不仅在于它的分割精度超过了此前的方法,更在于它把"不确定性"从一个学术概念,变成了一张可以直接给医生看的地图。
当 AI 能够诚实地说"这里我不确定",它才真正有资格进入临床。
你认为"不确定性感知"会成为医学 AI 的标配吗?欢迎留言讨论。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号