Evo-RL: 首次在SO101机械臂上完成 Pi*star0.6 RECAP 真机强化学习复现

Evo-RL: 首次在SO101机械臂上完成 Pi*star0.6 RECAP 真机强化学习复现

Amusi
发布于 2026-03-10 12:56:52
发布于 2026-03-10 12:56:52
上海交通大学 MINT 实验室联合 Evo-Tech,首次在 SO101 低成本机械臂上完成 Pi*star0.6 RECAP 真机强化学习流程复现,并开源可复现工程链路。
在具身智能快速发展的大背景下,很多团队都在关注一个核心问题:真实机器人上的强化学习,能不能不仅“做出来”,还能“被更多人复现出来”?
Evo-RL 这次尝试给出了一个务实答案: 不是只给一段视频、一个结果曲线,而是把从数据采集、价值建模、策略训练到部署纠错再训练的整条链路,放到可运行的工程系统中,并面向社区持续开放。

Evo-RL 真机强化学习总体流程
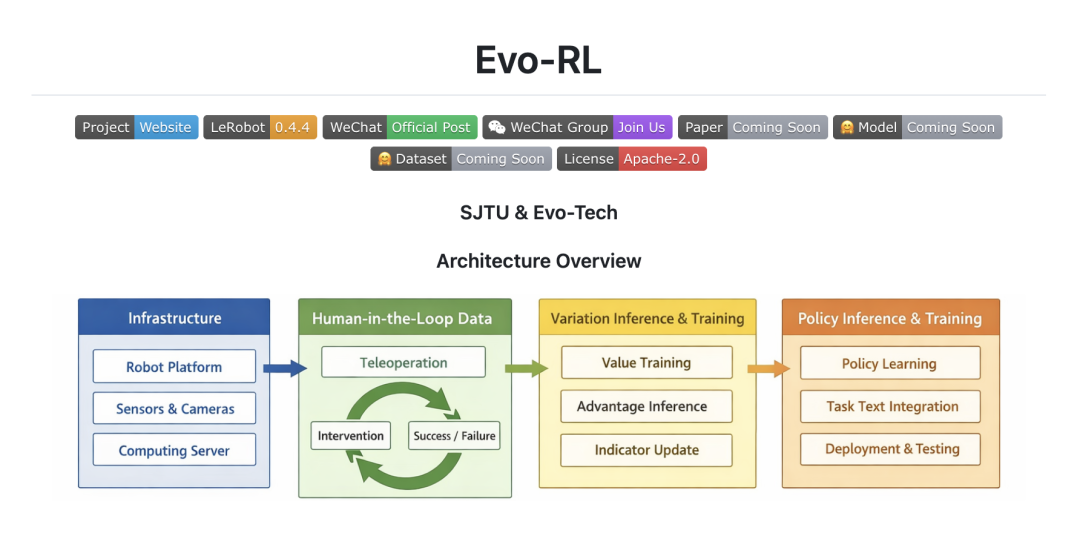
上图对应 Evo-RL 的四层闭环:
- Infrastructure(基础设施层):机器人平台、传感器与相机、计算服务。
- Human-in-the-Loop Data(人在环数据层):遥操作、介入纠错、成功/失败标注。
- Variation Inference & Training(价值推理与训练层):Value 训练、Advantage 推理、Indicator 更新。
- Policy Inference & Training(策略学习与部署层):Policy 学习、任务文本融合、部署测试。
这四层串起来,形成了真实场景中的“训练-部署-纠错-再训练”持续迭代闭环。

这次开源,核心做了什么?
1. 在 LeRobot 架构上实现 RECAP 风格纠错数据采集
Evo-RL 将 RECAP 思路落地为可执行的数据闭环机制:
- 机器人在推理阶段发生错误时,支持人工即时接管。
- 接管后可切换到采集模式,对当前轨迹进行修正。
- 将“错误轨迹 -> 修正轨迹”整段写回数据集,作为下一轮训练样本。
这意味着,模型不是靠“离线一次训练”硬撑,而是在真实任务失败中持续学习。
2. 在 LeRobot 中集成 Pi*star0.6 的训练流程
Evo-RL 已在工程上打通以下环节:
- Value Function 训练:学习任务回报结构。
- Value Inference:对轨迹进行 value/advantage 推理。
- Indicator 构造:把 advantage 转成可训练的二值指示信号。
- Advantage-Conditioned Policy 训练:策略学习时显式使用 indicator 条件信息。
最终让“论文机制”变成“命令行可复现流程”。
3. 以“可复现”为第一目标建设开放社区
Evo-RL 明确把项目定位为长期开放工程:
- 面向真实机器人 RL 的代码与流程持续开源。
- 逐步开放模型和数据资产。
- 通过社区共建,把方法复现、平台迁移、任务评估做成公共能力。
2:策略建模与训练结构示意(技术视角)
策略侧的关键建模思想:
- 多模态输入统一编码:视觉输入、文本任务描述、机器人状态共同进入模型。
- 状态与动作条件化建模:在时序块中结合当前状态与动作序列,提升策略稳定性。
- 可迭代优化接口:通过 value/advantage 反馈,把“执行后信息”重新用于下一轮策略更新。
从工程角度看,这正是 Evo-RL 可持续迭代的关键。
Evo-RL Focus:为什么这个项目值得关注

Evo-RL 对外强调三件事:
- 在多个机械臂本体上推进真机RL:目前已包含SO101 与 AgileX PiPER 本体,未来会适配更多本体。
- 代码、模型、数据一体化开放:不仅开代码,还会逐步释放可复用资产,降低进入门槛。
- 算法与社区共进化:一边复现已有方法,一边在真实任务中持续提出并验证新方法。
这三点的共同目标是: 把“少数团队可做”的真机强化学习,变成“更多团队可参与、可复用、可验证”的共同工程。
Evo-RL 的技术闭环
A. 数据采集阶段(Human Teleoperation 初始化)
- 使用人工遥操作先采集基础演示数据。
- 记录成功/失败与关键过程信息,形成第一轮可训练数据池。
B. Value 训练与推理阶段
- 在当前数据集上训练 value 模型。
- 对已有轨迹做 value 推理,得到逐帧价值估计。
- 进一步生成 advantage 信号,并按比例构造 indicator 标签。
在工程实现中,数据集会新增类似字段(示例命名):
complementary_info.value_<TAG>complementary_info.advantage_<TAG>complementary_info.acp_indicator_<TAG>
这些字段让“策略学习”不再只看原始轨迹,还能利用轨迹质量信号。
C. Policy 学习阶段(Advantage-Conditioned)
- 训练时将 indicator 信息注入任务文本条件。
- 通过条件化学习,让模型更好地区分“高质量行为模式”与“待纠正行为模式”。
- 使用 indicator dropout 等机制增强泛化,避免模型过度依赖单一标签。
D. 部署与纠错回流阶段(RECAP 核心)
- 把当前策略部署到真机执行。
- 出现偏差时人工接管并修正。
- 将修正轨迹并入下一轮训练集,进入新一轮 value+policy 更新。
这就是 Evo-RL 的核心价值:不把失败样本丢掉,而是把失败样本转化成系统持续进化的燃料。
Evo-RL 开源仓库入口
项目意义:从“能做”走向“可复现、可传播、可共建”
对具身智能社区而言,Evo-RL 的价值不只是一条新结果曲线,而是提供了一套更可落地的方法论:
- 用低成本平台验证真实 RL 的工程可行性。
- 用 RECAP 式人在环机制把失败转化为增量数据资产。
- 用开源工作流推动更多团队参与复现、对比与扩展。
未来,MINT@SJTU 与 Evo-Tech 将继续在更多平台和任务场景中推进这一方向,持续开放代码、流程与社区实践。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号