ICLR 2026 | DragFlow 让DiT也能“指哪打哪”:基于区域监督的拖拽式图像编辑新SOTA

ICLR 2026 | DragFlow 让DiT也能“指哪打哪”:基于区域监督的拖拽式图像编辑新SOTA

AI生成未来
发布于 2026-03-10 11:53:53
发布于 2026-03-10 11:53:53
作者:Zihan Zhou,Shilin Lu等 解读:AI生成未来

论文地址:https://arxiv.org/abs/2510.02253 项目代码:https://github.com/Edennnnnnnnnn/DragFlow 项目数据:https://huggingface.co/datasets/Edennnnn/ReD_Bench
亮点直击
- 首个基于 Diffusion Transformer(DiT)架构量身打造的图像精确区域编辑框架。
- 研究团队摒弃了传统的“逐点追踪”思路,创新性地使用“区域仿射监督”范式,充分释放了 FLUX.1 这类先进 DiT 模型的强大先验能力。
- 针对以往方法在复杂场景下的失真问题,该方法建立了图像拖拽编辑的新标杆。
为什么 DiT 时代的拖拽编辑需要新范式?
拖拽式图像编辑(Drag-based Image Editing)允许用户通过简单的“拖点”交互,实现对图像内容的精准操控,通过提供直接的空间位置干预,该方法在编辑控制性上远超文本引导。然而,现有方法大多基于 UNet 架构基础模型,如 Stable Diffusion (SD),普遍存在两大瓶颈:
- 先验能力不足:SD 生成先验较弱,优化后的潜在向量(Latent)常常偏离真实图像流形,使编辑后图像出现扭曲、模糊等失真伪影;
- 架构不匹配:随着 DiT 架构模型(如 FLUX)成为当前视觉生成主流,其强大的生成先验为解决失真问题带来了曙光。但我们发现,将传统拖拽策略迁移到 DiT 架构上难以带来直接有效的性能提升。
研究结果认为问题的根源在于 UNet 与 DiT 网络层的特征图粒度存在本质差异:
架构类型 | 特征图 (Feature Maps) | 与图像拖拽任务的关联 |
|---|---|---|
UNet (SD 1.x/2.x) | 经过瓶颈层高度压缩,空间紧凑,单个特征点聚合了广阔感受野的高级语义信息。 | 传统“点”级别监督信号(基于Motion Supervision 与 Point Tracking)足够提供强语义约束,在多数情况下可行。 |
DiT (FLUX.x) | 特征图精细且空间精确,每个点对应更窄的感受野,保留了更多局部细节而非全局语义。 | 传统“点”级别监督信号所能提供的语义较弱,难以为更复杂的 DiT 范式优化提供有效特征引导,导致编辑失败或效果退化。 |
通过可视化(如下图)可以发现,UNet 的特征多是模糊的语义团块,这意味着我们即使在 UNet 使用“点”级别操作,依旧可以有效干预周遭语义信息;而相比之下缩放到同样大小的 DiT 特征却能够清晰勾勒出物体的精细轮廓,如果依旧对后者进行“点”级别的追踪和约束,将难以有效带动区域特征编辑,如同盲人摸象。

提出的解决方案:DragFlow 编辑框架
为了攻克这一难题,我们提出了 DragFlow,一个专为 DiT 设计的 基于区域监督的 (region-based) 精确编辑框架。其核心创新包括:
- 区域级仿射监督 (Region-Level Affine Supervision):用整体区域的仿射变换替代脆弱的单点追踪,为 DiT 提供更丰富、更稳定的监督信号,从根本上解决了特征不匹配问题,并最大化消除了点操作固有的交互歧义;
- 适配器增强的反演 (Adapter-Enhanced Inversion):集成预训练的 IP-Adapter 等特征提取与适配器,通过额外注入 ID Embedding 显著提升在 CFG-distilled 模型(如 FLUX.1)上的主体一致性与反演保真度;
- 硬约束背景保持 (Hard-Constrained Background Preservation):摒弃使用掩码损失函数 (Mask Loss) 的经典方案,通过自适应梯度掩码(Gradient Mask)对背景非编辑区域施加硬性保护,彻底避免了背景污染问题。
- 多模态大语言模型 (MLLM) 辅助交互:利用 MLLM 先行分析、理解用户意图,生成供用户选择的编辑提示词和操作类型(如平移、形变、旋转),提升交互精度并最大化减少用户操作负担。
DragFlow 的完整框架如下图所示,它整合了 MLLM 辅助交互、IP-Adapter ID注入、Key & Value Caching,以及核心部分基于仿射的区域拖拽优化工作流。
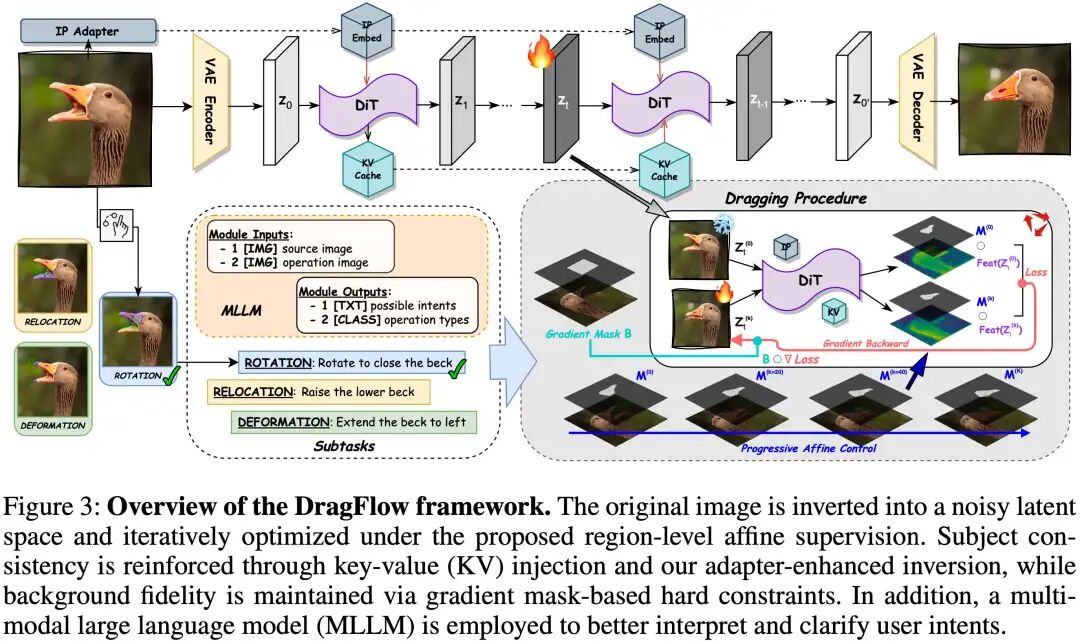
方法详解 | DragFlow:区域为王,精准掌控
DragFlow 的设计初衷是:将拖拽视为区域的整体变换,而非孤立点的位移。这套全新的范式,从监督方式、背景处理到身份保持,都为 DiT 的特性进行了深度定制。
① 区域级仿射监督:告别“点追踪”的烦恼
DragFlow 的核心是创新的区域级监督策略。它不再依赖于在每一步迭代中追踪手柄点的位置坐标,而是将用户指定的源区域(Source Region)作为一个整体,通过仿射变换逐步“移动”到目标位置。
1. 迭代式潜在向量优化 (Iterative Latent Optimization)
整个拖拽过程通过优化噪声化的潜在向量 来实现。优化的目标是让经过仿射变换后的目标区域 的特征,与优化开始前源区域 的特征保持一致。
损失函数设计如下:
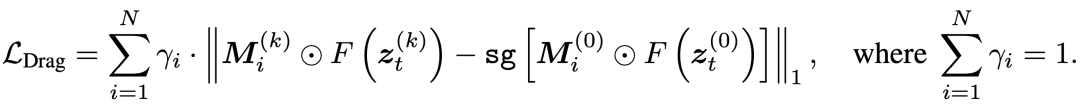
其中:
- 是从 DiT 中间层提取的特征。我们发现,DiT 的第 17 和 18 双流块(Double-stream Blocks)最适合用于拖拽优化。
- 是用户指定的源区域掩码,而 是在第 k 次迭代中,通过仿射变换计算出的目标区域掩码。
- 表示 Stop-gradient,确保梯度只流向待优化的 。
2. 仿射变换驱动的掩码传播 (Affine Transformation for Mask Propagation)
目标掩码 由源掩码 经过一个逐步变化的仿射变换 得到。变换参数 根据编辑类型(平移、形变或旋转)和迭代步数 线性插值生成。
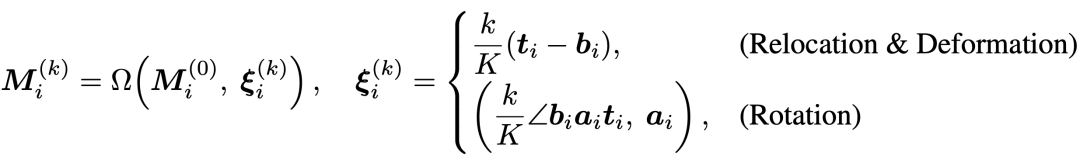
这种设计的两大优势:
- 提供丰富的语义上下文:对整个区域的特征进行匹配,相比单点特征,能为 DiT 提供更稳定、更鲁棒的梯度信号,有效避免局部最优和伪影。
- 消除追踪需求:由于DragFlow通过渐进式的几何移动监督区域,而不是追踪内容点,该方法从根本上避免了传统方法中因追踪失败而导致的编辑链式崩溃问题,过程更加稳定可靠。
② 背景与主体保真度:为 DiT 量身定制的策略
仅仅有好的监督信号还不够,在强大的 DiT 模型上,如何保持背景不变和主体身份一致,是更大的挑战,尤其是在有“反演漂移”问题的 CFG-distilled 模型上。
1. 背景保持:从“软约束”到“硬隔离”传统方法使用辅助损失项 来约束背景区域,但这在 DragFlow 中效果不佳,因为它会与拖拽损失 相互竞争,且对反演误差敏感。
我们的方案是施加硬约束:在每次梯度更新后,直接将背景区域的潜在向量重置为原始未编辑分支的值:
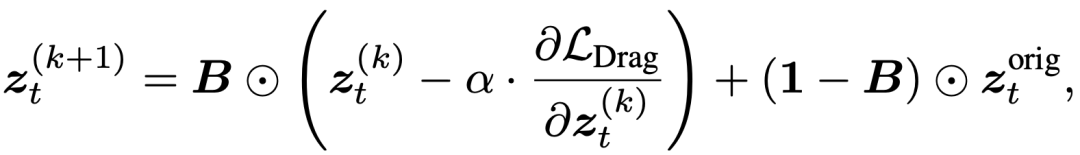
其中:
- 是包含所有编辑轨迹的背景掩码。
- 则是来自一个纯粹的重构分支,代表了最保真的原始背景信息。 这种“硬隔离”方法虽然增加少量计算开销,但效果远超软约束,能实现近乎完美的背景保真度。
2. 主体一致性:适配器增强反演
传统的键值注入(KV injection)在 FLUX 这类 CFG-distilled 模型上效果不佳。我们发现,FLUX 的反演漂移问题比 SD 更严重(见下表)。

为此,我们引入了适配器增强反演:在反演和生成过程中,注入一个预训练好的开放域适配器(如 IP-Adapter)所提取的主体身份表征。这无需任何额外训练,就能显著提升反演质量和编辑后的主体一致性。
如下图所示,通过额外在反演和取样过程中加入 IP-Adapter Embedding 后,人物身份的保持效果远超单独使用 KV 注入。

实验 | 两大基准测试,全面 SOTA
为了全面评估 DragFlow,我们构建了一个新的区域级拖拽基准 **ReD Bench**,它包含更丰富的区域-区域对应、任务类型标签(平移、形变、旋转)和意图描述。同时,我们也在现有的 DragBench-DR 上进行了兼容测试。
定量分析
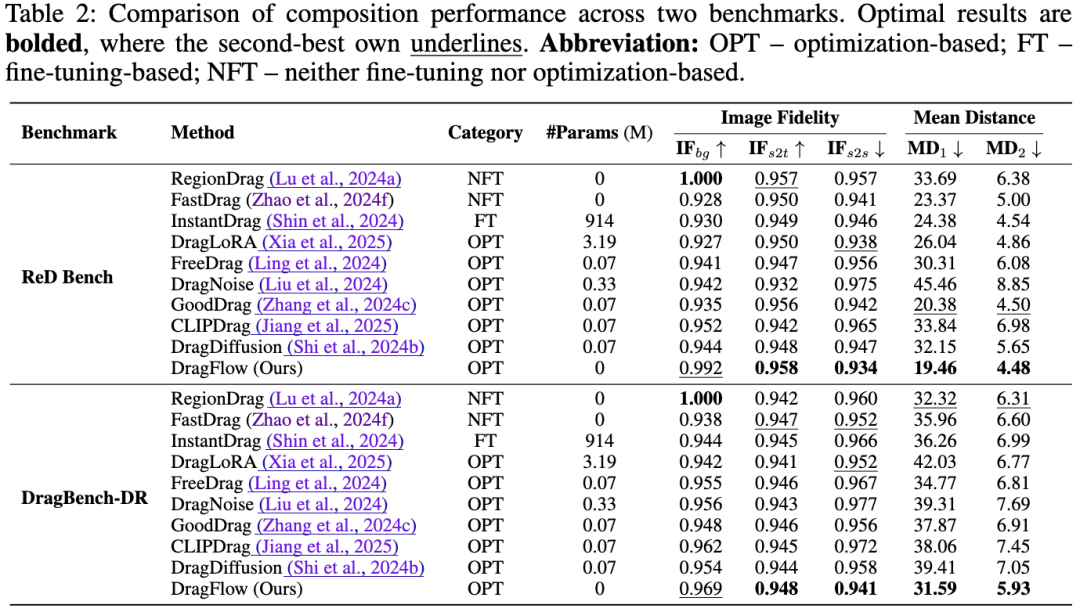
如 Table 2 所示,DragFlow 在基于两大基准的多个指标上取得了最佳表现:
- **平均距离 (Mean Distance (MD))**:DragFlow 取得了最低的 和 ,这两套 评估标准分别来源现有的 “点拖拽” 与 “块拖拽” 方法,该结果意味着 DragFlow 的编辑结果与用户指令的空间对齐精度达到了最高。
- **图像保真度 (Image Fidelity (IF))**:DragFlow 在背景保真度()、源区块到目标区块的内容保真度()以及拖拽前后源区块的内容区分度()上名列前茅,证明了其在精准编辑指定区域的同时,能最大程度保留图像质量和主体特征。
定性分析
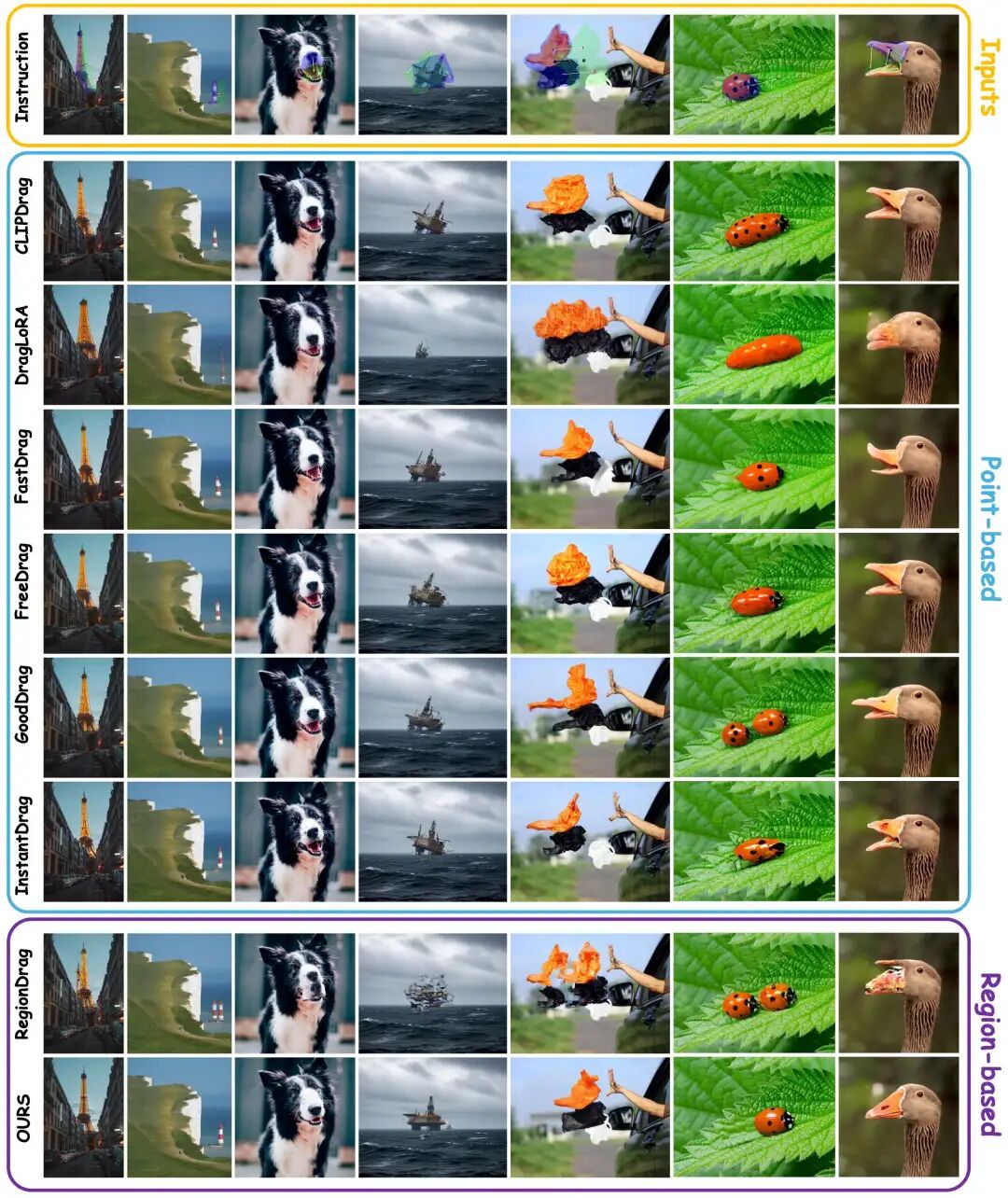
下图展示了 DragFlow 与其他现有方法的视觉定性比较。无论是复杂的结构(建筑),非刚性形变(动物),还是精细内容(钻井平台),DragFlow 都能精准地执行拖拽指令,同时保持场景的整体连贯性和真实质感。相比之下,其他现有方法或伴随严重结构扭曲、变换失败、或意图误解等失败情况出现。
消融实验
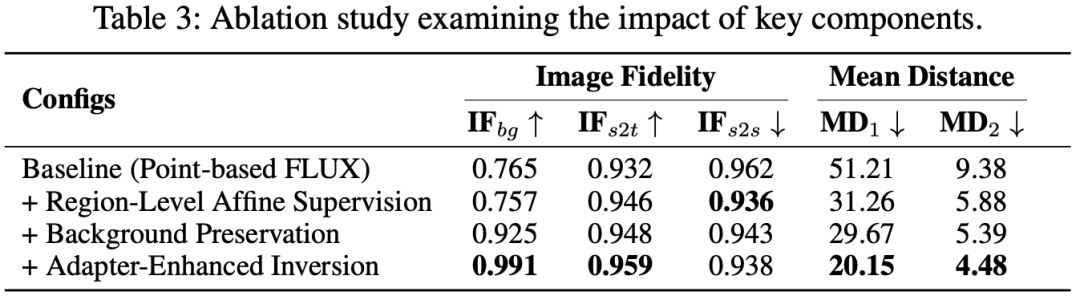
我们通过逐一添加 DragFlow 的核心组件来验证其有效性。结果(见 Table 3 和 Figure 6)清晰地表明:
- 从点基线切换到区域级仿射监督,MD 指标大幅降低 (51.21 -> 31.26),证明了区域监督的优越性;
- 加入背景保持模块后, 从 0.757 飙升至 0.925,背景质量显著提升;
- 最后引入适配器增强反演, 进一步提升,主体一致性得到加强,同时 MD 也降至最低 (20.15)。
定性分析(如下图)展示了各项消融操作的前后效果对比:

同时,消融实验中使用的多项量化指标也证实了 DragFlow 的各组件都是不可或缺且协同增效的:
总结 | DragFlow 开启 DiT 精确编辑新纪元
DragFlow 是拖拽式编辑领域的一次范式革命,其贡献与优势可总结为:
- 首创 DiT 拖拽框架: 首次成功将拖拽式编辑的能力从 UNet 迁移并适配到更强大的 DiT 架构上,释放了 FLUX 等模型的SOTA级生成先验。
- 区域监督核心: 提出的“区域级仿射监督”范式,用整体、鲁棒的区域特征匹配替代了脆弱、稀疏的点特征追踪,从根本上解决了 DiT 架构下的编辑难题。
- 系统性保真设计: 结合适配器增强反演与硬约束背景保持,为存在反演漂移的 CFG-distilled 模型提供了兼顾主体一致性与背景纯净度的完整解决方案。
- 构建新基准: 推出的 ReD Bench 为区域级拖拽编辑的研究提供了更全面、更贴近真实意图的评估标准。
DragFlow 不仅在各项指标上全面超越现有方法,更重要的是,它为如何利用新一代 DiT 生成架构的强大先验来进行精细化、可控的图像编辑,指明了一条清晰而有效的道路。
参考文献
[1] DragFlow: Unleashing DiT Priors with Region Based Supervision for Drag Editing
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号