大模型推理的KVCache小IO瓶颈解析

大模型推理的KVCache小IO瓶颈解析

数据存储前沿技术
发布于 2026-03-09 18:12:34
发布于 2026-03-09 18:12:34
全文概览
作为Transformer架构的核心组件,KVCache决定了推理系统的吞吐量和延迟。然而,当单卡显存无法容纳完整缓存时,系统必须引入层级化存储,这一架构变更引入了复杂的I/O特征。
不同于训练阶段的大块连续读写,推理阶段的KVCache呈现出碎片化、随机化和延迟敏感的"小I/O"特性。这种特征如何产生?为何GB级别的缓存会表现出KB级别的I/O行为?如何识别和优化这些隐形瓶颈?
本文将从第一性原理出发,深入拆解KVCache的生成机理、更新逻辑以及由此衍生的I/O特征,为理解和优化长上下文推理系统提供详尽的技术参考。
阅读收获
- 掌握KVCache在Prefill和Decode两个阶段的本质差异,理解计算密集型与带宽受限型的二元对立特征
- 深入理解PagedAttention机制如何解决显存碎片化问题,同时分析其在卸载场景下引入的小I/O挑战
- 学会识别和量化KVCache的I/O特征,包括请求大小分布、读写不对称性和延迟敏感度等关键指标
- 了解向量数据库在RAG场景下的写入放大问题,以及如何通过系统设计优化整体存储性能
👉 划线高亮 观点批注

1. 引言:大模型推理的“内存墙”与I/O挑战
在大型语言模型(LLM)从实验环境走向大规模生产部署的过程中,计算范式经历了一场深刻的转变。随着模型参数量突破千亿(如Llama-3-70B, DeepSeek-V3)以及上下文窗口(Context Window)扩展至128k甚至1M token,推理系统的核心瓶颈已从传统的浮点运算能力(FLOPs)转移到了存储子系统,特别是显存容量(HBM Capacity)与显存带宽(HBM Bandwidth)。在这种背景下,Key-Value Cache(KVCache)作为Transformer架构中自注意力机制(Self-Attention)的中间状态存储,成为了决定推理吞吐量和延迟的关键变量 1。
当单卡显存无法容纳完整的KVCache时,系统架构必须引入层级化存储(Tiered Storage),将“冷”数据卸载至CPU内存或NVMe SSD。这一架构变更引入了复杂的输入/输出(I/O)特征。“小I/O特征”成为了制约系统性能的隐形杀手。不同于训练阶段的大块连续读写,推理阶段的上下文卸载和向量数据库交互呈现出碎片化、随机化和延迟敏感的特性。本文旨在从第一性原理出发,深入拆解KVCache的生成机理、更新逻辑以及由此衍生的I/O特征,为理解和优化长上下文推理系统提供详尽的技术参考。
2. KVCache生成原理:计算物理特性的二元对立
要理解KVCache为何成为瓶颈,首先必须从数学和物理层面剖析其生成过程。LLM的推理过程并非单一的同质化计算,而是由两个截然不同的阶段组成:Prefill(预填充/首词生成)和Decode(解码/增量生成)。这两个阶段在计算强度、内存访问模式以及KVCache的生成方式上存在本质的二元对立 1。
2.1 Transformer注意力机制的数学本质
KVCache的存在是为了加速自回归生成。在Transformer的自注意力层中,输入向量序列 被投影为三个矩阵:Query ()、Key () 和 Value ()。
注意力分数的计算公式为:
在自回归生成第 个token时,模型需要用到之前所有 个token的 和 向量。如果不进行缓存,每生成一个新token,都需要重新计算前 个token的 和 ,这将导致计算复杂度随序列长度呈二次方增长 。通过将历史token的 和 向量驻留在显存中(即KVCache),计算复杂度被降低为线性 ,这是一个典型的“空间换时间”策略 2。
2.2 Prefill阶段:并行计算与爆发式缓存生成
Prefill阶段负责处理用户的输入Prompt,并生成首个输出token。
2.2.1 生成机制
在这一阶段,模型接收完整的Prompt序列(长度为 )。由于Transformer架构在处理输入时具有并行性,所有的Prompt token可以同时通过模型层。这意味着GPU的Tensor Core被大量矩阵乘法(GEMM)任务填满。
- 计算特征: 计算密集型(Compute-Bound)。算术强度(Arithmetic Intensity,即FLOPs/Bytes)较高。
- KVCache生成: 在前向传播过程中,每一层的Attention模块会一次性计算出所有Prompt token的Key和Value向量。
- 内存写入行为: 这是一个爆发式的写入过程。假设Prompt长度为4096,模型为Llama-3-70B(80层,GQA 8 KV heads,维度128),在FP16精度下,瞬间产生的KVCache大小为:
这1.34 GB的数据必须在极短的时间内(通常几百毫秒)写入显存。虽然这对显存带宽(HBM带宽通常 > 2TB/s)来说不是瓶颈,但它瞬间占据了显著的显存容量 3。
高带宽存储器:单个显存颗粒/芯片的物理带宽能力
高带宽存储器:单个显存颗粒/芯片的物理带宽能力
2.2.2 性能瓶颈
Prefill的主要性能指标是首字延迟(TTFT, Time-To-First-Token)。由于主要受限于计算能力,Prefill阶段通常能很好地利用GPU算力。然而,在长文档处理(如100k输入)中,Prefill产生的KVCache可能直接耗尽显存,导致OOM(Out Of Memory)或强制触发卸载 1。
2.3 Decode阶段:串行计算与带宽受限的缓存读取
Decode阶段是逐个生成后续token的过程。
2.3.1 生成机制
这是一个严格的串行过程。第 个token的生成依赖于第 个token。
- 输入: 仅包含上一步生成的1个token。
- 计算特征: 内存带宽受限(Memory-Bound)。
- KVCache交互:
- 读取(Load): 为了计算当前token的注意力,GPU必须从显存中加载之前所有保存的KVCache(即Prompt的缓存 + 之前生成的token缓存)。
- 计算(Compute): 将当前token的 向量与加载的巨大 矩阵进行运算,并聚合 矩阵。
- 写入(Store): 计算出当前token的 向量,将其追加写入到显存中。
2.3.2 算术强度的坍塌
在Decode阶段,矩阵运算退化为矩阵-向量乘法(GEMV)。GPU必须搬运几个GB甚至几十GB的KVCache数据,仅仅为了进行极少量的浮点运算来生成一个token。
- 算术强度极低: 此时GPU的利用率(Utilization)通常极低,瓶颈完全在于显存带宽。
- 延迟敏感: 每一个token的生成时间直接决定了用户的阅读体验(即Token间延迟 ITL, Inter-Token Latency)。如果KVCache过大导致无法放入显存而必须从CPU或SSD读取,ITL将增加数个数量级,导致服务不可用 3。
2.4 总结:KVCache生成的二象性
特征 | Prefill (Prompt处理) | Decode (Token生成) |
|---|---|---|
并行度 | 高(全序列并行) | 低(逐Token串行) |
瓶颈类型 | Compute-Bound (算力) | Memory-Bandwidth Bound (显存带宽) |
KVCache行为 | 爆发式写入 (Bursty Write) | 持续读取 + 增量写入 (Heavy Read + Small Write) |
I/O特征 | 吞吐敏感 | 延迟敏感 |
性能指标 | TTFT | ITL / Throughput |
这种二象性导致了现代推理引擎(如vLLM, DistServe)倾向于采用Prefill-Decode分离(Disaggregation) 架构,将Prefill任务和Decode任务分配到不同的GPU甚至不同的服务器上,以避免计算密集型任务阻塞延迟敏感型任务 1。
3. 长上下文交互中KVCache的生命周期与更新机制
在长上下文(Long Context)和多轮对话(Multi-turn Conversation)场景下,KVCache不再是一个静态的缓冲区,而是一个高度动态的、需要精细管理的资源池。理解其更新机制是识别I/O瓶颈的前提。
3.1 传统连续内存分配的困境
早期的推理系统(如HuggingFace原生实现)要求KVCache在物理显存上是连续的。
- 预留浪费(Internal Fragmentation): 如果模型支持4096长度,系统必须为每个请求预留4096个token的显存空间,即使实际请求只有100个token。这导致显存利用率极低(通常低于20%-40%) 9。
- 碎片化(External Fragmentation): 当不同长度的请求不断进入和离开,显存会被切割成无法利用的小块。
- 更新代价: 如果生成的序列超过了预留空间,系统可能需要重新分配更大的连续块并进行内存拷贝,造成严重的延迟抖动。
3.2 现代更新机制:PagedAttention与分块管理
vLLM引入的PagedAttention从操作系统虚拟内存管理中汲取灵感,彻底改变了KVCache的更新方式。这是目前主流推理引擎(vLLM, SGLang, TensorRT-LLM)的事实标准 11。
3.2.1 逻辑块与物理块的解耦
系统将KVCache切分为固定大小的块(Block),例如每个Block存储16或32个token。
- 逻辑视图: 对模型而言,KVCache依然是连续的张量。
- 物理视图: 在显存中,Block可以离散存储在任意位置。
- 页表(Block Table): 维护逻辑块索引到物理块地址的映射。
3.2.2 动态更新流程
在长文本生成过程中,KVCache的更新变为一个“按需分配”的过程:
- 生成新Token: 解码步骤生成了第 个token。
- 检查当前块: 系统检查最后一个物理Block是否已满(例如容量16,当前已存15)。
- 直接写入(In-place Update): 如果未满,直接将新生成的 向量写入该Block的下一个槽位。这是一个极小的显存写入操作。
- 分配新块(Allocation): 如果已满,内存管理器从空闲池中申请一个新的物理Block,并在Block Table中添加一条新映射。
- 链接与写入: 新数据写入新Block的第一个槽位。
这种机制消除了外部碎片,并使内部碎片最大不超过一个Block的大小 9。
3.3 复杂场景下的更新:共享与分叉
在多轮对话或Parallel Decoding(如Beam Search)中,KVCache的更新涉及复杂的共享机制。
3.3.1 公共前缀共享(Prefix Caching)
当多个用户请求共享同一个System Prompt(例如“你是一个有用的助手...”)时,PagedAttention允许不同的请求在Block Table中指向相同的物理Block。
- 更新逻辑: 这些共享Block是只读的。当不同请求开始生成不同的后续内容时,系统会执行Copy-on-Write(写时复制) 或简单的分叉操作,为各自的新内容分配独立的Block。
- I/O影响: 这种机制大幅减少了显存写入量和占用量,但在发生Cache Miss时,需要重新计算或从外部存储加载,这直接关联到后文的I/O特征 12。
3.4 卸载(Offloading)场景下的更新
当长上下文导致显存不足时,更新机制必须通过PCIe总线与CPU内存进行交互。
- Swap-Out(换出): 系统根据驱逐算法(如LRU)选择最不常用的Block,将其从GPU HBM拷贝到CPU RAM。
- Swap-In(换入): 当模型需要再次访问这些Block(例如用户在多轮对话中引用了上文),系统需将其从CPU RAM拷回GPU。
- 更新特征: 此时的“更新”不再是简单的显存写入,而是涉及PCIe事务的数据搬运。这引入了显著的延迟 15。
4. 识别与表征KVCache的I/O特征:解构“小I/O”瓶颈
那么为什么GB级别的KVCache会表现出“小I/O”特征?如何识别和量化这些特征?
4.1 什么是“小I/O”?
在存储系统(SSD/NVMe)语境下,大I/O通常指128KB - 1MB以上的顺序读写,这类操作能充分利用设备的内部并行性,达到峰值带宽(如PCIe 4.0 SSD的7GB/s)。小I/O通常指4KB 及其以下的随机读写。
KVCache卸载表现为小I/O的原因:
- 分块粒度(Block Granularity): 即使总缓存很大,vLLM等框架的调度单位是Block。如果Block Size设为16,对于Llama-3-70B(GQA后KV维度较小),一个Block的大小可能只有几十KB到几百KB。
- 稀疏访问(Sparse Access): 在高级优化算法(如ShadowKV, RetrievalAttention)中,模型并不需要加载全部KVCache,而是只检索与当前Query相关的Top-K个Token 17。这些Token往往散落在内存的不同位置,导致物理层面的I/O请求是高度碎片化的随机读取。高度优化的KV检索算法是导致小IO的直接原因。
- 动态驱逐与预取: 内存管理器的驱逐是动态发生的,往往是零星地将个别Block换出,而不是一次性倾倒整个缓存。
4.2 KVCache I/O特征的定量表征
根据最新的研究数据(如19对FlexGen和DeepSpeed的I/O trace分析),KVCache卸载表现出以下关键特征:
4.2.1 请求大小分布 (Request Size Distribution)
- 主导粒度: 能够观察到128 KiB是主导的I/O请求大小 19。这是因为许多底层库(如CUDA driver或存储驱动)倾向于将数据合并或切分为128KB的chunk进行传输。
- 小包尾部: 尽管主导是128KB,但也存在大量更小的控制信息或元数据读写,或者在碎片化严重时的非对齐访问。
4.2.2 读写不对称性 (Read/Write Asymmetry)
KVCache的生命周期表现为WORM (Write-Once, Read-Many),但在卸载场景下,表现为极端的读多写少(就带宽而言),或读写混合的复杂模式。
- 读取带宽远高于写入: 实验数据显示,卸载时的平均读取带宽可达 2.0 GiB/s,而写入带宽可能低至 11.0 MiB/s 19。
- 原因: 写入(Swap-out)通常发生在显存将满时的被动驱逐,或者是生成结束后的异步保存,系统会尽量避免阻塞计算。而读取(Swap-in)发生在解码的关键路径上——GPU等着数据来做计算,因此会尽可能全速拉取数据。
- 写入的爆发性: 写入往往是Burst模式,而非Continuous模式。
4.2.3 延迟敏感度 (Latency Sensitivity)
这是“小I/O”成为瓶颈的根本原因。
- 队列深度(Queue Depth)不足: NVMe SSD需要高队列深度(QD > 32甚至更高)才能跑满带宽。然而,推理引擎的Decode是串行的,往往无法在同一时刻发起足够多的并行I/O请求来填满SSD的队列。业界正在开发并行Decode方案,如华为UCM中提及的 PMR-Tree(Partial Matched Retrieval Tree)后缀检索预测加速算法,通过并行输入,释放NVMe SSD性能,从而提高推理速度。
- 随机读延迟: 一个4KB的随机读,SSD的物理延迟约为80-100微秒。对于GPU而言,这100微秒是漫长的等待。如果一个Decode步长需要加载100个离散的Block,且无法完全并行,累积的I/O延迟将直接摧毁ITL指标 17。
4.3 表征I/O瓶颈的方法论
要识别系统中是否存在KVCache I/O瓶颈,可以采用以下指标体系:
指标维度 | 表征参数 | 瓶颈判定阈值 | 物理含义 |
|---|---|---|---|
I/O粒度 | Avg Request Size | < 32 KB | 请求过于碎片化,导致PCIe/SSD协议开销占比过高(Protocol Overhead)。 |
队列行为 | Avg Queue Depth | < 4 | 应用未能提供足够的并行度,导致存储设备空转。 |
带宽利用率 | Effective Bandwidth | < 20% Peak | 尽管总数据量大,但受限于随机IOPS,无法吃满带宽。 |
系统开销 | Syscall Overhead | High CPU Sys Time | 频繁的用户态/内核态切换(Context Switch)消耗了CPU,阻碍了数据调度。 |
应用延迟 | I/O Wait % | > 30% | GPU计算单元在等待数据搬运,流水线气泡(Pipeline Stall)严重。 |
4.4 卸载架构的I/O路径分析
从硬件路径来看,KVCache的数据流经:
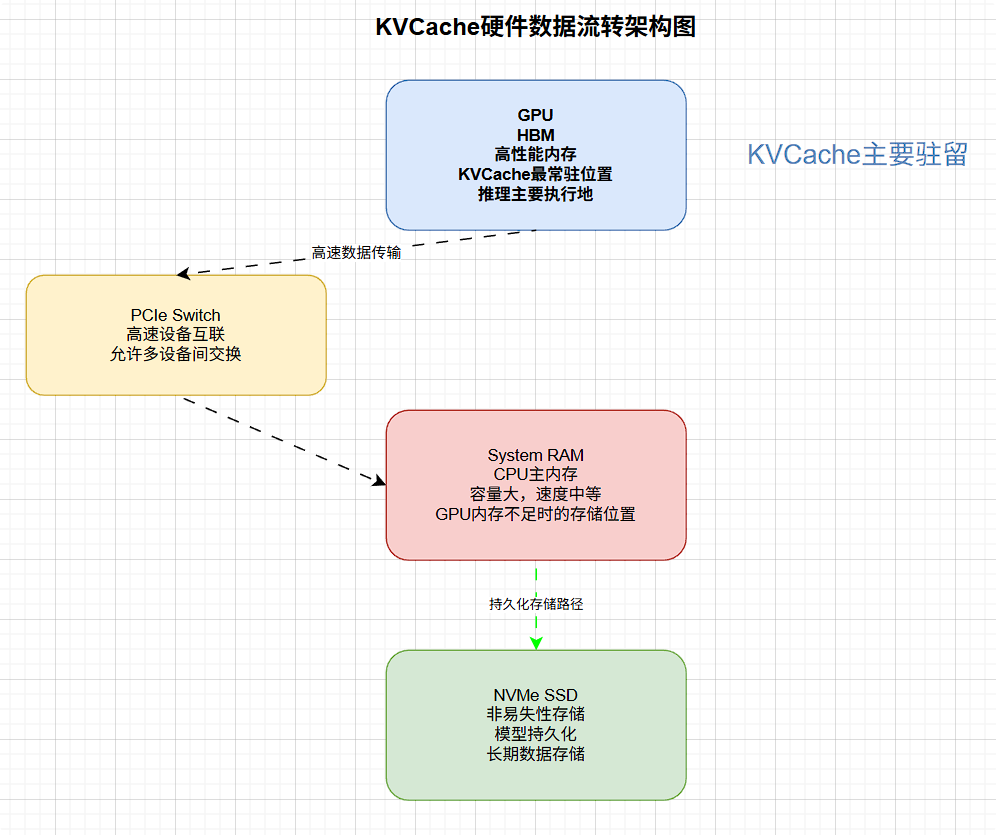
- PCIe瓶颈: 在System RAM卸载模式下,PCIe Gen5 x16提供~64GB/s(双向128GB/s)。对于Llama-3-70B,每生成一个token需要读取数百MB甚至GB级数据,64GB/s的带宽仅能支撑每秒几十个token的吞吐,这对于大Batch场景是捉襟见肘的 17。
- SSD瓶颈: 在Disk卸载模式下,NVMe SSD的随机读写性能(IOPS)成为核心。普通企业级SSD的4K随机读约为500k-1M IOPS。如果KVCache索引设计不当,导致大量微小的元数据查询,IOPS会先于带宽耗尽。这回答了为什么SSD厂商,现在开始集中关注 高IOPS场景的架构设计。
5. 向量数据库(Long-term Memory)的I/O特征:写入放大与索引维护
除了KVCache这种短期记忆,长上下文交互还依赖向量数据库(Vector Database)作为长期记忆(Long-term Memory)来检索历史信息(RAG)。这部分的I/O特征与KVCache截然不同,但同样面临“小I/O”挑战。
5.1 写入放大(Write Amplification)
在RAG或Chat History场景中,数据通常是流式写入的(例如用户每说一句话,就插入一条向量)。
- LSM Tree机制: 主流向量数据库(Milvus, RocksDB底层)使用日志结构合并树(LSM Tree)。数据先写入内存表(MemTable),满后刷写到磁盘(SSTable)。
- 小写入问题: 当单条向量(例如1KB)被插入时,LSM Tree为了保持数据有序和一致性,需要在后台进行多次Compaction(合并压缩)。研究表明,这种场景下的写入放大系数可达 10倍甚至64倍 21。
- I/O后果: 虽然应用层只写入了1MB数据,底层磁盘可能承受了64MB的写入负载。这不仅消耗了宝贵的I/O带宽,还加速了SSD的磨损。
5.2 索引构建与检索的随机性
- HNSW索引: 图索引(Hierarchical Navigable Small World)是目前的标准。在插入新节点或进行查询时,算法需要访问图中的邻居节点。
- 内存跳动(Pointer Chasing): 如果索引无法完全放入内存(DiskANN场景),每一次节点遍历都意味着一次随机的磁盘读取。由于图结构的邻居节点在物理存储上往往是不连续的,这导致了极其严重的随机小I/O 24。
- 特征: 这种I/O模式是延迟敏感且依赖性强的——必须读完节点A,计算距离,才能决定下一个读节点B。无法通过预读(Prefetching)来有效掩盖延迟。
6. 综合案例分析:Llama-3-70B在混合负载下的瓶颈模拟
为了更直观地理解上述原理如何转化为实际瓶颈,我们以Llama-3-70B模型为例进行理论推演。
设定:
- 模型:Llama-3-70B(FP16,GQA, KV Head=8, Dim=128, Layer=80)。
- 场景:Batch Size=32,上下文长度=32k。
- 总KVCache需求:。
- 硬件:单卡H100(80GB HBM),其余数据卸载至系统内存(PCIe Gen5)和NVMe RAID。
瓶颈分析:
- Prefill阶段: 输入32k token。计算产生335GB数据。HBM瞬间爆满。系统必须以PCIe带宽(64GB/s)将数据刷入CPU内存。这需要 秒。在此期间,GPU计算单元虽然只需要几百毫秒完成计算,但必须等待数据搬运,导致TTFT受限于PCIe写带宽。
- Decode阶段: 每生成1个token,模型需要访问这335GB的“虚拟”KVCache。
- 全量加载不可行: 即使是PCIe Gen5,读取335GB也需要5秒以上。生成速度退化为0.2 token/s,完全不可用。
- 稀疏加载(Sparse Attention): 假设算法只加载顶层1%的关键KV Block(约3.35GB)。这3.35GB分布在数万个非连续的Block中。
- I/O特征爆发: 系统瞬间发起数万个128KB或更小的随机读请求。如果存储系统的IOPS或队列深度处理能力不足,延迟将急剧飙升。此时,“小I/O特征”正式成为系统死锁的根源。
7. 结论与技术演进展望
通过深入拆解大模型KVCache的生成与更新机制,得出以下核心结论:
- KVCache生成的物理二象性决定了I/O优化的方向必须是分层的:Prefill阶段需要高吞吐写入,Decode阶段需要低延迟随机读取。
- PagedAttention虽然解决了显存碎片化问题,但在卸载场景下,它将连续的大块I/O打散成了无数个Block级的小I/O。这种粒度的失配(Mismatch)是存储瓶颈的根源。
- 小I/O瓶颈的本质是随机读延迟。在带宽看似充裕的PCIe和NVMe设备上,由于队列深度不足和协议开销,应用层无法获得理论性能。
- 向量数据库的写入放大进一步恶化了存储子系统的负载,特别是在流式RAG场景下。
未来演进方向:
- 硬件层面: CXL(Compute Express Link)技术的普及将允许GPU以Cache Coherent的方式直接访问CPU内存,大幅降低小I/O的各种协议开销。
- 系统层面: 引入io_uring等异步I/O接口,以及针对SSD特性的内核旁路(Kernel Bypass)存储栈,以提升低队列深度下的IOPS 26。
- 算法层面: 发展ShadowKV或InfiniGen等技术,将KV分离,仅保留极小的高频访问索引在GPU,将大容量数据转化为极稀疏的按需读取 17。
参考资料
- Prefill-decode disaggregation | LLM Inference Handbook - BentoML, https://bentoml.com/llm/inference-optimization/prefill-decode-disaggregation
- Understanding KV Cache: The Secret to Faster LLM Inference | by Sachin Soni - Medium, https://medium.com/@sachinsoni600517/understanding-kv-cache-the-secret-to-faster-llm-inference-a9a825d701de
- LLM Inference Optimization 101 | DigitalOcean, https://www.digitalocean.com/community/tutorials/llm-inference-optimization
- KV Cache Offload Accelerates LLM Inference | by NADDOD - Medium, https://naddod.medium.com/kv-cache-offload-accelerates-llm-inference-598ce469ba9d
- Serving LLaMA 3-70B on TPUs | How To Scale Your Model - GitHub Pages, https://jax-ml.github.io/scaling-book/applied-inference/
- Estimating LLM Inference Memory Requirements - TensorWave, https://tensorwave.com/blog/estimating-llm-inference-memory-requirements
- Understanding the Prefill-decode Disaggregation in LLM Inference Optimization - NADDOD, https://www.naddod.com/blog/understanding-the-prefill-decode-separation-technique-in-large-model-inference
- Disaggregated Prefill and Decode - Perplexity, https://www.perplexity.ai/hub/blog/disaggregated-prefill-and-decode
- Part 2 — Memory Is the Real Bottleneck: How Paged Attention Powers the vLLM Inference Engine | Data Science Dojo, https://datasciencedojo.com/blog/understanding-paged-attention/
- How PagedAttention resolves memory waste of LLM systems - Red Hat Developer, https://developers.redhat.com/articles/2025/07/24/how-pagedattention-resolves-memory-waste-llm-systems
- Implementation — vLLM, https://docs.vllm.ai/en/v0.6.0/automatic_prefix_caching/details.html
- The Architecture Behind vLLM: How PagedAttention Improves Memory Utilization - Medium, https://medium.com/@mandeep0405/the-architecture-behind-vllm-how-pagedattention-improves-memory-utilization-2f9b25272110
- How vLLM does it? - Rishiraj Acharya, https://rishirajacharya.com/how-vllm-does-it
- vllm.config.cache, https://docs.vllm.ai/en/v0.10.1/api/vllm/config/cache.html
- arxiv.org, https://arxiv.org/html/2511.11907v1
- How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo | NVIDIA Technical Blog, https://developer.nvidia.com/blog/how-to-reduce-kv-cache-bottlenecks-with-nvidia-dynamo/
- ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference, https://openreview.net/forum?id=oa7MYAO6h6
- RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval - arXiv, https://arxiv.org/html/2409.10516v2
- An I/O Characterizing Study of Offloading LLM Models and KV Caches to NVMe SSD - Large Research, https://atlarge-research.com/pdfs/2025-cheops-llm.pdf
- CLO: Efficient LLM Inference System with CPU-Light KVCache Offloading via Algorithm-System Co-Design - arXiv, https://arxiv.org/html/2511.14510v1
- 10x Write Amplification: PostgreSQL vs MySQL Index Architecture Analysis - Medium, https://medium.com/@sjksingh/10x-write-amplification-postgresql-vs-mysql-index-architecture-analysis-a55d4e2b13e5
- Closing the B-tree vs. LSM-tree Write Amplification Gap on Modern Storage Hardware with Built-in Transparent Compression - arXiv, https://arxiv.org/pdf/2107.13987
- ScyllaDB's Compaction Strategies Series: Write Amplification in Leveled Compaction, https://www.scylladb.com/2018/01/31/compaction-series-leveled-compaction/
- Turbocharging Vector Databases using Modern SSDs - VLDB Endowment, https://www.vldb.org/pvldb/vol18/p4710-do.pdf
- Vector Databases: I/O Characteristics - NetApp Community, https://community.netapp.com/t5/Tech-ONTAP-Blogs/Vector-Databases-I-O-Characteristics/ba-p/456488
- Lance File 2.1: Smaller and Simpler - LanceDB, https://lancedb.com/blog/lance-file-2-1-smaller-and-simpler/
Notice:Human's prompt, Datasets by Gemini-3-Pro-DeepResearch
---【本文完】---
👇阅读原文,搜索🔍更多历史文章。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号