深解华为UCM的KVCache优化之道

深解华为UCM的KVCache优化之道

数据存储前沿技术
发布于 2026-03-09 18:07:36
发布于 2026-03-09 18:07:36
全文概览
随着大模型(LLM)在各行业加速落地,推理(Inference)阶段的效率瓶颈日益凸显。Transformer架构的自回归机制与长上下文需求,共同将矛头指向了KVCache——这项“以存代算”的关键技术在提升速度的同时,也带来了巨大的显存压力,成为新的性能枷锁。当GPU算力不再是唯一瓶颈,我们如何从根本上优化数据流转与计算冗余?
业界普遍采用稀疏注意力等算法进行优化,但往往停留在计算层本身。华为近期开源的UCM(推理记忆数据管理器)则提供了一个系统级的解题新思路,它不仅在算法层面引入几何稀疏注意力(GSA),更在系统IO和调度策略上进行了深度创新。当KVCache直通向HBM,当重算不再是“一刀切”而是“精准手术”,当自回归的串行瓶颈可以被“历史记忆”检索所打破,AI推理的效能边界是否将被重新定义?本文将深入剖析UCM背后的三大核心技术,探讨其如何构建下一代AI推理的优化范式。
阅读收获
- 掌握系统级稀疏化新思路:理解GSA算法如何超越传统稀疏注意力,通过“最大范数+SVD”的块表征与系统IO协同,从而优化KVCache在外存与显存间的数据流动效率。
- 洞悉KVCache重用与加载的前沿技术:学习“自适应渐进式重算”如何分层、按需地精准修复位置编码偏差,以及“KV Cache直通HBM”机制如何通过零拷贝和计算加载交叠,彻底隐藏IO延迟。
- 解锁投机推理的创新路径:了解PMR-Tree后缀检索如何用“记忆检索”替代“模型计算”来生成预测序列,并通过算力感知的动态规划,解决高并发场景下的加速失效问题。
👉 划线高亮 观点批注
8月12日 华为 在2025金融AI推理应用落地与发展论坛上预发布 UCM(推理记忆数据管理器),目前产品原型代码已托管到 Github 。
截图是12月17号截取的,从Commits最近时间来看,仓库还是十分活跃的。
UCM Github仓库
UCM Github仓库
这款聚焦AI推理过程KVCache管理的中间件产品,在预发布演讲中,曾介绍其核心几大“黑科技”,今天我们一起来看看 UCM 是如何看待未来推理场景的 KVCache 管理的。
在聚焦其产品核心技术之前,先来介绍下行业内对推理场景的基本共识。
从 Transformer 标准注意力 到 稀疏注意力机制
Transformer 架构因其突破 Scaling Law 限制,而具备近乎无限注意力机制(标准注意力),与之匹配的是:对算力、高速显存的超高需求。在商用场景标准注意力注定无法高效落地,因此在推理成为AI应用基石的今天,稀疏注意力的算法研究成为实践路上的重点研究对象。
稀疏注意力的“得”,在于它通过引入“归纳偏置”,打破了“全体都算”的暴力计算模式。
- 计算效率的指数级提升 (Computational Efficiency)
- 最核心的收益是将计算和空间复杂度从“平方级增长”的 降低到了近乎线性的水平。这意味着序列长度翻倍,计算资源的消耗不再是灾难性的四倍增长,而是可控的线性增长。
- 长上下文处理成为可能 (Scalability to Long Sequences)
- 由于计算成本的大幅降低,模型不再局限于处理长度为 512 或 1024 的短序列。处理整篇文档、长段代码、甚至视频等多模态长序列成为现实,极大地扩展了 Transformer 架构的应用场景。
- 硬件资源消耗显著降低 (Reduced Resource Consumption)
- 稀疏注意力不再需要生成和存储一个完整注意力分数矩阵,从而大幅减少了 GPU 显存的占用。这使得我们可以在同等硬件条件下,处理更长的上下文,有效避免了“爆显存”的窘境。
- 缓解内存带宽瓶颈 (Alleviated I/O Bottleneck)
- 由于计算是稀疏的,GPU 无需在 HBM 和 SRAM 之间频繁搬运庞大的全注意力矩阵,减少了数据 I/O,从而提升了实际运行速度。
Transformer 架构的自回归限制
从本质上讲,像Transformer这样的大语言模型是以自回归 (Autoregressive) 的方式生成文本的,这意味着“基于所有已经生成的token,一次只生成下一个token”。

标准 Transformer 框架
标准 Transformer 框架
我们可以想象一位非常严谨的砌砖师傅在砌一堵墙。他必须在上一块砖完全砌好之后,才能砌下一块。在第4块砖没有就位之前,他绝对无法开始砌第5块砖。
LLM在推理(生成文本)时的工作方式与此完全相同:
- 为了生成第5个token,模型必须处理第1、2、3、4个token。
- 为了生成第6个token,模型必须处理第1、2、3、4、5个token。
这就造成了一个严重的串行瓶颈。尽管你拥有能够进行大规模并行计算的强大GPU(就像一整个准备就绪的施工队),但它却被迫等待,生成一个token,然后再次等待下一个循环。这个过程天然是序列化的,效率极低,尤其是在生成长文本时。
KVCache 以存代算的经济价值
Transformer 架构解决的是神经网络计算范式问题,计算阶段产生的数据被设计成KV键值对存放在HBM中,如何高效利用神经网络的计算数据,自然想到缓存技术。
KVCache 是一种推理时 (Inference-time) 的优化技术,它不改变模型本身的结构或注意力计算的根本逻辑,其核心目标是加速自回归生成 (Autoregressive Generation) 的过程。
- 解决的问题:在生成式任务中,模型需要逐个 token 生成内容。当生成第 个 token 时,它需要关注前面已经生成的全部 个 token。标准的做法是,每次都重新计算这 个 token 的 Key (K) 和 Value (V) 向量,这造成了巨大的重复计算浪费。
- 工作原理:KVCache 的思想很简单——“计算一次,处处使用”。它会把已经计算过的每个 token 的 K 和 V 向量存储在 GPU 的高带宽内存(HBM)中。当生成下一个新 token 时:
- 模型只需为这个新 token计算其 Query (Q), Key (K), Value (V) 向量。
- 将这个新 token 的 K 和 V 向量追加到 Cache 的末尾。
- 用新 token 的 Q 向量与 Cache 中所有的 K, V 向量进行注意力计算。
- 效果:极大地提升了推理速度,使总生成时间复杂度从 级别降低到 级别。但它的代价是占用大量显存来存储这个不断增长的 Cache,这本身也成为了长上下文推理的一个新瓶颈。
在了解以上技术背景之后,我们再来看看 UCM 产品中是如何思考、创新,以实现更高推理效能的。
GSA(Geometric Sparse Attention)稀疏化推理加速算法
推理稀疏化算法的演进历程
1. IO/内存优化(奠基阶段)
首先是IO/内存优化,这类技术以FlashAttention和xFormers的融合Attention内核为代表。它们的特点是Attention计算本身仍是密集(Dense) 的,因此并不会减少浮点运算量(FLOPs)。其核心价值在于减少了高带宽内存(HBM)与片上高速缓存(SRAM)之间的数据访问开销,并降低了中间激活的存储需求。这类优化为后续更复杂的稀疏Attention内核提供了高效的执行模板和底层基础。
2. KV Cache结构稀疏(工程化早期成功)
其次是针对KV Cache结构的稀疏化,这也是推理稀疏化最早实现工程化成功的类别。代表技术包括vLLM的PagedAttention、滑动窗口KV(Sliding Window KV)以及KV Cache的压缩/量化。这类方法主要关注Key/Value的存储,尤其是在时间维度(历史Token)上的优化。它们通过减少缓存命中开销和避免无效Token的常驻,来优化内存使用,但并不触动Q和K的内积计算逻辑。
3. Attention的算后稀疏(Top-K/阈值裁剪)
第三类是Attention的 “算后稀疏” ,例如Top-K Attention(推理裁剪版)和Attention Score阈值处理。这类方法的特点是必须先计算完整的Q Kᵀ,然后根据得分高低保留高分项。这意味着在进行稀疏化裁剪之前,模型已经付出了完整的FLOPs成本和Softmax计算成本,因此它在计算效率上的提升有限。
4. Query驱动的算前稀疏(FLOPs级别减法)
最后,也是最先进的一类,是Query驱动的算前稀疏。代表技术包括QUEST、低秩Query探测和基于能量的预选择。这类优化的核心在于直接针对Q K内积计算本身进行优化。在这种模式下,Attention的稀疏化不再仅仅是 “结构” 上的裁剪,而是一种 “执行决策” 。这是推理稀疏化中第一次在FLOPs级别真正实现减法,同时还能在语义上保持与密集Attention相近的效果。
演进阶段 | 稀疏化维度 | 技术模式 / 算法 | 代表方法 / 系统 | 与 Dense Transformer 的关系 |
|---|---|---|---|---|
Dense 执行 | 无稀疏 | 标准 Attention | 原生 Transformer | 全算全存 |
内存友好 | IO 优化 | Recompute / Tiling | FlashAttention | 不减 FLOPs,只减 IO |
KV 结构稀疏 | Cache 维度 | Paged / Window / Compress | PagedAttention, Sliding KV | 减少 KV 访存 |
Token 级稀疏 | Token 选择 | Early Exit / Skip | LayerSkip, Token Pruning | 跳过部分 token / layer |
Attention 执行稀疏 | QK 维度 | Top-K / Threshold | Sparse QK Kernel | 算后裁剪 |
Query 驱动稀疏 | 算前筛选 | QUEST | QUEST | Dense Attention 的稀疏执行 |
Speculative 稀疏 | 时间轴 | Draft / Verify | Speculative Decoding | 跳过未来 token |
混合执行 | 多维组合 | Hybrid Runtime | vLLM + QUEST + Spec | 多种稀疏叠加 |
GSA 几何稀疏化算法由来与优势
UCM 稀疏算法
UCM 稀疏算法
1. 继承基础: GSA属于广义的“结构稀疏化”范畴。本质上,它承袭了Transformer稀疏注意力算法的两个核心思路:
- 按块(Block)结构对齐:类似于Block/Chunk Attention(用于图像、长序列、表格等)
- 动态自适应稀疏:可根据算子、显存、时延自适应建立稀疏结构,兼具局部与全局,像部分内容稀疏方法(如Routing、Reformer)中的动态策略
2. 关键创新点: 与早期稀疏方法相比,GSA提出了几何块Block表征+KV Cache压缩协同稀疏化的新机制,针对实际大模型推理场景,尤其关注“外存<->显存”的数据流动瓶颈与显存命中率精度损失问题,以系统级稀疏和推理效率为目标。
- 稀疏分形、范数+SVD,稀疏分形解决“有效计算分布形态”问题,范数+SVD解决“如何度量和提取这个有效子空间”问题,从而减少模型在推理过程中的激活参数,减少KVCache产生。
- 稀疏卸载+预取,通过块级几何表征结合范数、SVD等方式,结合空间复用与动态预取算法物理地”减少需要般运、保留和操作的数据量,优化KVCache在HBM和外存之间的流动。
- 引入自适应策略,支持根据实际推理场景(如高延迟或高并发)灵活切换不同的稀疏化和缓存复用模式。
3. 对比传统方法:
- 传统Block/Chunk Sparse Attention:只管块内/块间的数学计算稀疏,未关注系统流动和外存瓶颈。
- Content-based方法(如Routing、Reformer):强调token之间的语义靠近与动态稀疏,KV-Cache流动不是核心目标。
- GSA兼顾块结构、动态性和系统性,打通算法+系统+硬件协同优化链路,如对KV Cache进行压缩、近似计算,并支持HBM与外存的分级调度。
GSA设计要素 | 创新机制 | 优势释义 |
|---|---|---|
最大范数+SVD联合Block表征 | 在Block内选取范数最大的k个tokens,再用SVD"概括"表征信息 | 兼顾稀疏压缩和表征质量,提升精度,避免暴力筛选丢失重要内容 |
卸载与预取算法 | 将KVCache保存在持久化的低成本闪存中,基于访问热度智能预取 | 介质-算法-缓存-带宽一体协同,极大提升端到端性能 |
自适应Attention稀疏策略 | 针对不同推理场景自适应切换稀疏/稠密与缓存复用策略 | 根据延迟和带宽灵活调优,实现0加速“空泡”,推理系统更稳健 |
KV Cache重用
重用,从字面上来理解,就是要提高已经计算生成的 KVCache 利用效率,尽可能减少冗余计算过程,这在长上下文场景中已经被证明是提高推理效率的关键途径。
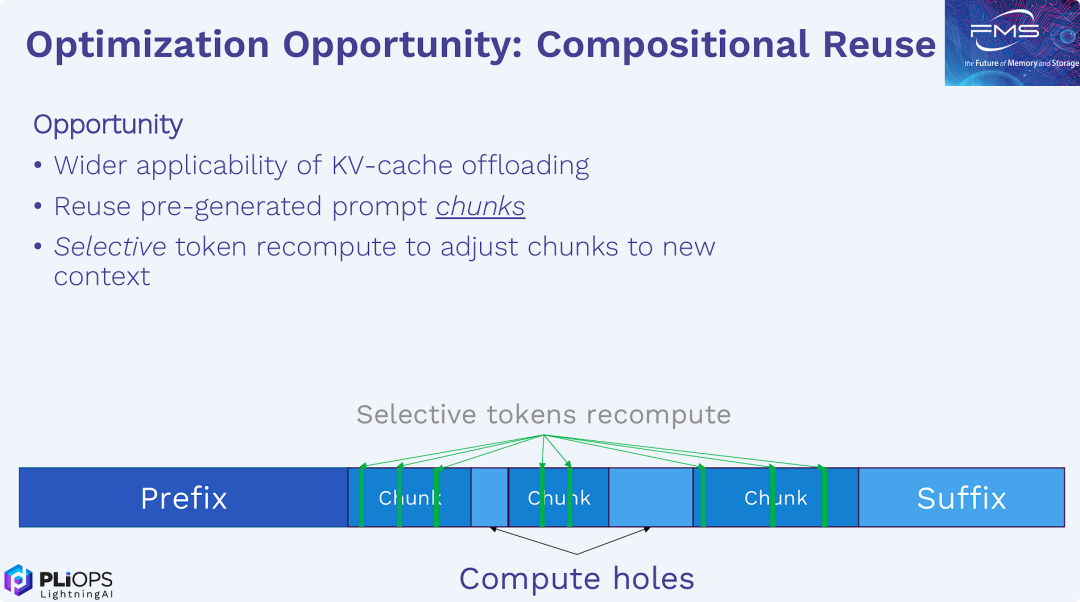
KVCache 分块重用原型
KVCache 分块重用原型
虽然业内现在已经支持KV Cache片段重用,但仍存在一些问题。其一是重算的精度的泛化性,其二是重算的性能仍有提升的空间。UCM在此基础上进行了改良:
自适应渐进式重算
UCM 通过 Transformer 前置层评估,后续层渐进的算法设计动态评估 token 级 KV 漂移程度,并据此决定重算比例:越靠近输入层,重算比例越高,以消除位置编码偏差;越靠近输出层,重算比例递减,仅对差异超过设定阈值的 token 进行补算。
它的核心思想是:在重用KV Cache时,不再采用“要么全部重用、要么全部重算”的粗暴方式,而是像一位经验丰富的外科医生一样,对因位置变化而产生的“计算偏差”进行精确、有重点、分层次的修复,从而在性能和精度之间取得最佳平衡。
为了更好地理解它,我们可以将其名称拆解为三个关键部分来深入探讨:
背景:为何需要“重算” (Recomputation)?
重用KV Cache时,拼接新输入会导致位置编码偏差 (Positional Encoding Bias)。Transformer的位置编码(如RoPE)对位置敏感,缓存片段的位置身份改变会引入错误信息,导致计算“漂移”并影响精度。因此,需要高效地“重算”来修正偏差。
“渐进式” (Progressive):分层递减的修复策略
“渐进式”策略根据Transformer层级采用不同重算力度,遵循递减规律:
- 靠近输入层 (Shallow Layers),重算比例高:浅层网络学习位置和语法等基础特征,位置偏差影响最大。在此“源头”彻底修复至关重要,以防错误逐层放大。
- 靠近输出层 (Deep Layers),重算比例递减:深层网络更关注抽象语义关系,对精确位置不敏感。微小偏差影响减弱,可减少重算量以换取性能。
此策略本质上是计算资源的最优化分配,将算力集中于对结果影响最大的浅层网络。
“自适应” (Adaptive):基于阈值的精准修复
“自适应”在“渐进式”策略下实现token级别的精细控制:
- 动态评估“KV漂移程度”:系统评估缓存KV值与新位置理论KV值的差异。
- 设定阈值,按需补算:
- 若“漂移程度”超过阈值,说明偏差影响精度,必须“补算”生成新KV值。
- 若低于阈值,则忽略微小偏差,直接重用缓存。
此机制确保算力只用于修复真正影响精度的token,避免计算浪费。
KV Cache 直通 HBM 的加载-计算交叠机制
传统方案先将 KV 块从外存读入 CPU 内存,再经由 PCIe 拷贝至 GPU HBM,链路长、延迟高。UCM 支持 KV Cache 零拷贝直通 HBM,并在算子内部引入“算当前层、预取下一层”的流水线:当第 i 层注意力计算完成时,第 i+1 层的 KV 块已提前驻留 HBM。该机制将加载延迟隐藏于计算时间内,显著提升加载效率。
如果说“自适应渐进式重算”是从算法层面优化“算什么、怎么算”的问题,那么这项技术就是从系统和IO层面优化“数据如何高效喂给计算单元”的问题。它的核心思想是:通过彻底改造数据从外存到GPU的传输路径和时机,最大限度地消除数据加载延迟对计算效率的影响,让GPU这台昂贵的“计算引擎”永不熄火。

Nvidia GPU数据直通模型
Nvidia GPU数据直通模型
痛点:传统数据加载方案的“漫长旅程”
在解释UCM的优势之前,我们先看看传统方案的效率瓶颈在哪里。当一个KV Cache块需要从外存(例如NVMe SSD)加载到GPU HBM以供计算时,它通常需要走过一条漫长且曲折的路径:
- 从外存到CPU内存:数据首先被从SSD读取到CPU的主机内存(DDR DRAM)中。
- 从CPU内存到GPU HBM:然后,CPU发出指令,数据再通过PCIe总线被拷贝到GPU的HBM中。
这个过程存在两大问题:
- 链路冗长,延迟叠加:数据必须经过CPU内存这个“中转站”,这不仅增加了一次不必要的数据拷贝,还引入了CPU调度和PCIe传输的延迟。整个过程是串行的,效率低下。
- 计算单元空闲等待:在数据“长途跋涉”的过程中,GPU的计算核心可能处于空闲状态,等待数据就位。这就好比一条高速生产线,因为原料供应不上而频繁停工,造成了巨大的资源浪费,这就是所谓的“IO瓶颈”或“加载空泡”。
UCM的解决方案:两把利器根治IO瓶颈
UCM通过两项关键创新,彻底解决了上述问题:
利器一:“零拷贝直通HBM” (抄近道)
这项技术从空间路径上进行了优化。它允许KV Cache数据块从外存(SSD)直接传输到GPU HBM,完全绕过了CPU主机内存这个中转站。
- 传统方案:
外存 -> CPU内存 -> PCIe -> GPU HBM - UCM方案:
外存 -> PCIe -> GPU HBM
这就像是从仓库(外存)修了一条直达生产线(GPU HBM)的传送带,不再需要先把货物搬进办公室(CPU内存)再转运。其优势显而易见:
- 路径最短:减少了一次内存拷贝操作。
- 延迟更低:消除了CPU内存中转带来的延迟。
利器二:“加载-计算交叠” (数据预取)
这项技术则从时间维度上进行了优化,其核心是将数据加载的耗时隐藏在计算的耗时之中。
它在算子内部实现了一个精巧的流水线(Pipeline):
- 当GPU正在计算第
i层的注意力时:它消耗的是已经提前加载到HBM中的第i层的KV块。 - 与此同时,系统并不会闲着:它会利用GPU计算的这段时间,并行地去预取(Pre-fetch)下一层(第
i+1层) 所需要的KV块,并启动从外存到HBM的直接加载。
最终的效果是:当第 i 层的计算任务一结束,第 i+1 层的数据也正好准备就绪,计算单元可以无缝衔接,立即开始新的计算任务。
这好比一位高效的厨师(计算单元)在炒菜,旁边始终有一位助手(加载机制)在同步备好下一道菜的原料。厨师永远不需要停下来等待原料,从而实现了最大化的烹饪效率。
PMR-Tree(Partial Matched Retrieval Tree)后缀检索预测加速算法

UCM 后缀预测加速算法
UCM 后缀预测加速算法
前面提及过 Transformer 架构自回归机制的串行机制,现代加速器动辄上万个核心,依赖串行生成结果肯定不是最优解,因此提出预测加速算法。
为了打破自回归机制瓶颈,业界发展出了投机推理 (Speculative Decoding) 技术。其核心思想简单而巧妙:与其让大师傅一块一块地砌砖,不如先用一个更快、但没那么精准的方法快速地铺设一个接下来几块砖的“草稿”,然后让大师傅一次性检查所有这些砖是否合格。
- 第一步:猜测(Speculate):一个快速的机制生成一个包含未来多个token(例如5-10个token)的“草稿”序列。
- 第二步:检查(Verify):强大的主LLM接收整个“草稿”序列,并通过一次并行的前向计算,来验证它自己是否也会生成同样的结果。
- 第三步:接受/拒绝(Accept/Reject):模型会接受草稿中直到第一个错误token之前的所有正确部分。如果整个草稿都正确,那么你就用大约生成一个token的成本,一次性生成了5-10个token。这极大地提升了速度。
那么,关键问题就变成了:生成“猜测”的最佳方式是什么?
“后缀检索”的答案:通过记忆和联想来进行猜测
这正是后缀检索预测加速算法发挥作用的地方。它为执行“猜测”这一步提供了一种高效得多的方法。
一种常见方法是使用一个更小的、更快的LLM来生成草稿。但这有其缺点(成本高、维护难、需逐模型适配)。后缀检索提出了一种不同且更优雅的思路:与其通过计算来猜测,不如从记忆中检索它。
下面是它的工作原理,并与自回归过程联系起来:
- 构建记忆体(后缀树):系统会持续观察正在处理的文本(用户输入、模型输出),并构建一个巨大的、可搜索的索引,例如PMR-Tree。这棵树存储了无数的文本序列,以及通常跟在它们后面的token(即它们的“后缀”)。
- “灵光一闪”的时刻(检索):在生成过程中,当模型产出了一段token序列(例如“...在人工智能领域”),后缀检索算法会实时查询它的记忆树,问道:“我以前见过‘...在人工智能领域’这个序列吗?”
- 借鉴历史(生成猜测):
- 如果树找到了匹配项,并且在历史记录中,这个序列后面跟着的是“
,这是一个...”,系统就会检索出这个后缀。 - 这个被检索出的后缀——“
,这是一个...”——就成为了极大概率正确的“草稿”或“猜测”,并被提交给主LLM进行验证。
- 如果树找到了匹配项,并且在历史记录中,这个序列后面跟着的是“
- 并行验证:主LLM接收原始的上下文(“...在人工智能领域”)和草稿(“
,这是一个...”),并一次性完成验证。如果正确,多个token就被瞬间接受,从而打破了自回归“逐字生成”的链条。
为什么后缀检索是一项突破
特性 | 传统自回归推理 | 后缀检索投机推理 |
|---|---|---|
过程 | 逐个token,串行生成。 | 猜测一个token块,然后并行验证。 |
瓶颈 | 串行依赖:必须等待前一个token生成完毕。 | 打破了对文本块的串行依赖链。 |
“猜测”方法 | 无 | 从历史序列的记忆库(后缀树)中检索一个可能的续写。 |
效率 | 低。GPU常因等待下一步而空闲。 | 高。用廉价的查找操作替代了昂贵的计算(运行小模型)。 |
核心原则 | “让我计算出下一个词是什么。” | “我以前见过这个短语吗?如果见过,后面跟着的是什么?” |
本质上,后缀检索利用了语言通常具有重复性和可预测性这一特点。通过创建一个系统记忆库,它可以使用快速、廉价的查找来“猜测”常见的短语和序列,从而让强大的LLM能够将宝贵的计算资源用于处理语言中真正新颖和复杂的部分。这也就是为什么说:“存得越多推得越快。”
UCM的方案主要是为了解决现有检索式方案 “粗放、冗余、高并发下失效” 的三大痛点。它通过一系列精巧的设计,将后缀检索技术从一个“能用”的方案,提升到了一个“好用且高效”的水平。
其技术实现和核心优势可以归结为以下三大创新点:
创新点一:更智能、更丰富的PMR字典树构建
UCM构建了一个信息维度更丰富的“记忆大脑”,而非仅依赖用户输入。
- 技术实现:
- 多源数据: 字典树利用私域知识和模型响应结果构建,知识更全面。
- 失败经验再利用: 模型“拒绝”的token对被记录,用于优化后续检索(“错题本”)。
- 多维度标注: 存储文本时增加KV语义、时间、频率等元数据。
- 核心优势:
- 提升匹配精度: 可根据时间、频率、语义等属性优先匹配,提高“猜测”质量。
创新点二:层次化检索策略(从“大海捞针”到“精确制导”)
UCM设计了“粗筛精排”的渐进式筛选流程,解决业界“粗放式检索”的无效计算问题。
- 技术实现:
- 利用多维度特征集(匹配度、语义、频率、时间性)进行两阶段筛选:
- 粗筛: 快速过滤不相关序列。
- 精排: 对少数候选者进行精细打分,选出最优“草稿”。
- 利用多维度特征集(匹配度、语义、频率、时间性)进行两阶段筛选:
- 核心优势:
- 降低无效计算: 提交给大模型的“草稿”质量高,显著节省GPU算力。
创新点三:算力感知的候选序列动态规划
此亮点解决了高并发下投机推理与正常解码争抢GPU算力导致加速下降的问题。
- 技术实现:
- 系统动态建模算力消耗,实时感知GPU负载。
- 根据并发量和负载,为每个请求动态调整最大token预算:
- 高并发: 减少“猜测”token数,保证服务稳定性。
- 低并发: 增加“猜测”token数,最大化单次加速比。
- 核心优势:
- 提升高并发加速比: 保证在高并发下仍有稳定加速收益。
- 最大化算力利用率: 确保有限算力被最有效利用,优化全局吞吐量。
Summary
UCM 核心技术的拆解就分享到这里了,具体算法实现,可以关注Github代码仓库,为了自己学习方便,我在CNB 克隆了一个版本,且自动生成了Wiki[1],后续有时间,可以就上述算法的代码实现做进一步分析,同时为了方便实验,也打了个vLLM镜像[2]。
UCM 开源真正价值是为更多加速器、高性能存储厂商,提供一个合作平台,如何围绕UCM框架,联合计算、存储生态做大AI推理应用,是产业内值得共同思考的问题。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- UCM方案强调算法与系统(如IO路径、内存管理)的深度协同。在你看来,未来AI推理优化的主要突破点,是会更多地来自于纯粹的算法创新,还是更依赖于这种软硬件一体化的系统级工程?为什么?
- “自适应渐进式重算”和“PMR-Tree”都引入了复杂的动态策略(如漂移阈值、Token预算)。在真实的生产环境中,你会如何设计实验来为不同业务(如实时对话、文档摘要)找到最佳的参数平衡点,以权衡延迟、吞吐量和精度?
- PMR-Tree的核心是“存得越多推得越快”,本质上是构建一个外部的“长时记忆”系统。这种机制在处理高度动态或涉及隐私的私域知识时,可能面临哪些数据一致性、安全性和管理上的挑战?
---【本文完】---
👇阅读原文,搜索🔍更多历史文章。
- https://cnb.cool/trrylab/unified-cache-management/-/wiki ↩
- https://cnb.cool/trrylab/unified-cache-management/-/packages/docker/unified-cache-management/vllm ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号