【存储100问】智能数据分层:场景、价值与实现

【存储100问】智能数据分层:场景、价值与实现

数据存储前沿技术
发布于 2026-03-09 18:01:53
发布于 2026-03-09 18:01:53
问题意识
当对数据的访问增加时,Stargate 会将数据从较低层移动到较高层。Curator 是一个后台进程,用于执行文件系统作(如分层、重新平衡和修复数据冗余错误),当对数据的访问变得不那么频繁时,它会将数据从较高层移动到较低层。通过此过程,AOS 充分利用了更高层的空间,并且只有需要较低延迟的最频繁访问的数据才会保留在那里。
- AOS 中通过 Stargate + Curator 实现数据智能分层,对于洞悉数据分层如何实现有帮助
- Amazon FSx for Lustre 智能分层存储 也讨论到类似的数据分层实现
研究方向:
- 如何理解这里的数据智能分层,从技术上是如何实现的?和缓存、CDN的实现原理做对比
- 为实现业务数据的智能分层设计,需要业务层做哪些改造?
- 针对AI推理、大数据分析场景,数据的智能分层的价值,以及需要注意哪些问题?

智能数据分层技术深度解析与应用实践
引言
智能数据分层的定义与核心价值
智能数据分层是一种先进的存储管理策略,其核心在于根据数据的访问频率、新旧程度、业务价值或其他预设策略,自动对数据进行分类,并将其迁移到最合适的存储层级。这些层级通常包括高性能的固态硬盘 (SSD)、大容量高性价比的机械硬盘 (HDD) 以及成本极低的云归档存储等 1。该技术的主要目标有两个:一是通过将访问频率较低的“冷”数据存放在成本较低的存储介质上,从而优化存储总拥有成本 (TCO);二是通过确保访问频繁的“热”数据驻留在高速存储层,以提升应用的性能和响应速度。
报告研究范围与主要探讨的系统
本报告将深入剖析智能数据分层的技术实现细节,重点以 Nutanix AOS (Acropolis Operating System) 和 Amazon FSx for Lustre 作为领先的行业实践案例进行分析。此外,报告还将对比智能数据分层与缓存 (Caching)、内容分发网络 (CDN) 等相关技术的原理差异,探讨为实现业务数据的智能分层,应用层面可能需要的改造,并分析其在人工智能 (AI) 推理和大数据分析等现代工作负载场景下的具体价值和潜在挑战。
第一部分:数据智能分层的技术实现与原理对比
1.1 Nutanix AOS 智能数据分层详解
Nutanix AOS 作为超融合基础设施 (HCI) 的核心,其智能数据分层能力是确保性能和成本效益的关键。
架构概览:控制器虚拟机 (CVM) 的核心地位
Nutanix 架构的基石在于其分布式的控制器虚拟机 (CVM)。每个 Nutanix 节点均运行一个 CVM,该 CVM 负责管理该节点上 hypervisor 和所有用户虚拟机的全部 I/O 操作 3。这种分布式设计使得存储资源和服务与计算资源紧密集成。AOS 将集群中所有节点的物理存储资源(包括 SSD 和 HDD)抽象为一个统一的存储池,并呈现给上层 hypervisor 3。
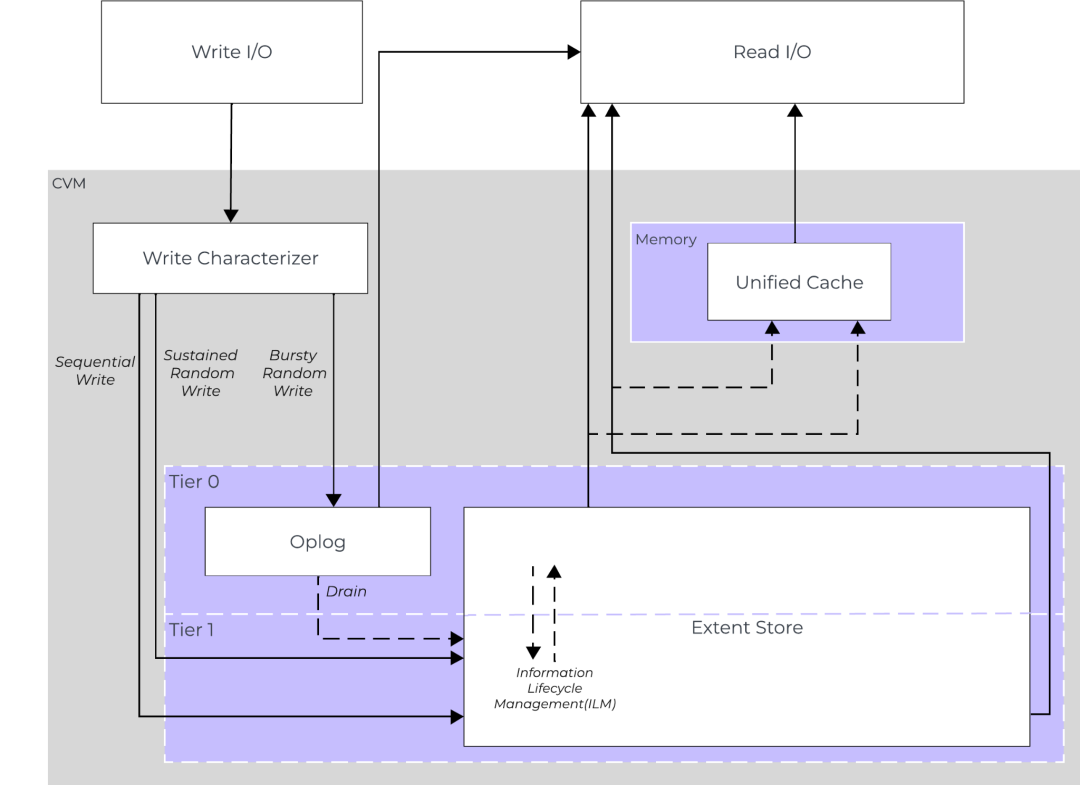
Stargate:I/O 路径的关键枢纽
Stargate 是 Nutanix AOS 的核心 I/O 引擎,运行在每个节点的 CVM 上,负责处理所有来自用户虚拟机的读写请求 4。它是数据路径上的关键组件,执行包括数据读写、复制、压缩、去重以及智能分层在内的多种操作。
- I/O 分类 (I/O Classification): 当 Stargate 接收到写 I/O 时,它会首先对 I/O 进行分类,判断是随机 I/O 还是顺序 I/O,并据此决定数据的初始放置位置和处理方式 4。
- 突发随机 I/O (Bursty Random I/O): 对于突发性的随机写入,数据会被写入一个位于最快存储层(如 SSD 或 NVMe)的专用区域,称为 Oplog。写入 Oplog 后即可向虚拟机快速返回确认,从而降低写入延迟。同时,数据会同步复制到集群中其他一个或多个节点的 Oplog,以保证数据冗余和高可用性 3。
- 顺序 I/O (Sequential I/O): 对于顺序写入(例如,当虚拟机 vDisk 有超过 1.5 MB 的未完成 I/O 时),数据会绕过 Oplog,直接写入后端的 Extent Store 3。这是因为顺序数据本身是连续的,可以高效地以大块方式写入磁盘,从而获得高吞吐量,且对元数据的更新需求较少。
- Oplog:写入性能的加速器 (Oplog: Write Performance Accelerator) Oplog 类似于文件系统的日志 (journal),主要用于处理随机写入。它将离散的随机写操作聚合并进行整理,然后以顺序的方式批量“排出”(drain) 到 Extent Store,这种机制将随机写转化为顺序写,显著提升了磁盘写入效率 3。Oplog 始终部署在集群中速度最快的存储介质上,例如在混合节点(同时包含 SSD 和 HDD)中位于 SSD,在同时包含 NVMe SSD 和其他类型 SSD 的节点中则位于 NVMe SSD 5。
- Autonomous Extent Store (AES):持续性随机写入优化 (Autonomous Extent Store (AES): Optimization for Sustained Random Writes) 从 AOS 5.10 版本开始引入的 AES 功能,针对持续性的随机写入负载进行了优化。在满足特定条件下,这类写入可以绕过 Oplog,直接写入 Extent Store 4。这避免了 Oplog 可能成为瓶颈的情况,并提升了此类工作负载的性能。AES 的实现还得益于元数据管理的优化,AOS 将元数据分为本地存储(节点级别)和全局存储两部分,增强了元数据的局部性,减少了元数据查找的开销 5。这种设计不仅服务于 AES,也间接提升了数据迁移和分层操作的效率,因为这些操作同样涉及元数据的更新和查询。
- 统一缓存 (Unified Cache): Stargate 还在 CVM 的内存中维护一个统一缓存 (Unified Cache),用于缓存从 Oplog 和 Extent Store 中读取的数据。当发生读请求时,系统会首先尝试从 Unified Cache 中满足请求,如果缓存未命中,则从 Extent Store 读取数据并填充到缓存中,以加速后续访问 3。
Curator:后台数据管家
Curator 是一个在 Nutanix 集群中分布式运行的后台进程,负责执行一系列重要的文件系统维护任务,包括数据分层(即信息生命周期管理 ILM)、数据重新平衡、数据冗余修复等 4。Curator 通过定期扫描集群中的数据,分析其访问模式(例如,通过 MapReduce 作业来确定数据的“温度”6),并根据预设策略执行相应操作。
- 数据分层迁移 (Data Tiering Migration):
- Stargate 向上迁移 (Stargate Moves Data Up): 当 Curator 的扫描或其他机制(如读操作)识别到某些数据的访问频率显著增加(数据变“热”)时,Stargate 会负责将这些数据从较低性能的存储层(如 HDD)迁移到较高性能的存储层(如 SSD)4。这通常是为了提升后续访问的性能,利用 SSD 的低延迟特性。
- Curator 向下迁移 (Curator Moves Data Down): 相反,当 Curator 发现某些数据的访问频率持续降低(数据变“冷”)时,它会启动任务将这些数据从高性能层迁移到成本更低的存储层 4。这样做的目的是为了优化高性能存储空间的使用效率,确保宝贵的快速存储资源留给真正需要它的“热”数据。
这种 Stargate 和 Curator 之间的职责划分体现了一种精妙的设计:Stargate 作为 I/O 路径上的核心组件,能够对数据“升温”做出快速响应,及时提升数据访问性能;而 Curator 作为后台进程,则可以更从容地处理数据“降温”的迁移任务,以及其他不需要立即完成的系统维护工作,避免对前台业务性能造成冲击。
- 信息生命周期管理 (ILM) (Information Lifecycle Management - ILM): ILM 策略由 Curator 管理和执行,定义了数据如何根据其访问模式和热度在不同存储层之间流动 5。在混合存储配置(如 SSD+HDD)的 Nutanix 集群中,SSD 通常作为 Tier 0(最高性能层),HDD 作为 Tier 1(容量层)。对于全闪存配置的节点,由于只存在单一的闪存层,通常不进行层内的 ILM 智能数据迁移 5。
Nutanix AOS 智能分层架构图
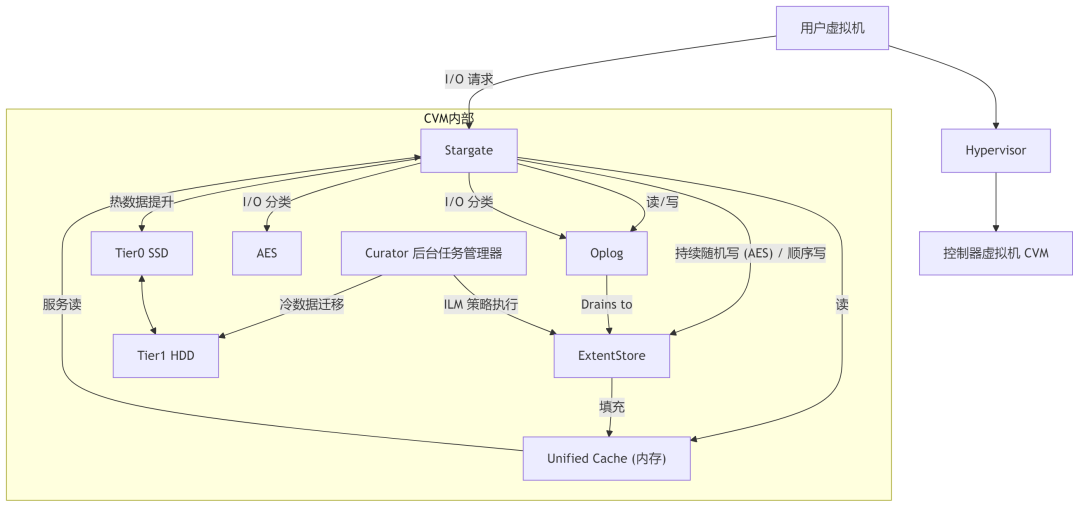
Nutanix AOS 的智能数据分层不仅是简单的热冷数据迁移,其对 I/O 类型的细致分类(突发随机、顺序、持续随机)和针对性的处理路径(Oplog、AES、直接写入 Extent Store)表明了一种在数据生命周期早期就进行智能化处理的设计哲学。这种主动的性能优化与后续基于访问历史的被动分层相结合,共同构成了 AOS 高效数据管理的基础。
表 1: Nutanix AOS 分层组件与角色
组件 (Component) | 在分层中的主要角色 (Primary Role in Tiering) | 关键特性/交互 (Key Characteristics/Interactions) |
|---|---|---|
Stargate | I/O 处理与分类,热数据实时提升 | 将随机/顺序写入导向 Oplog/Extent Store;根据访问增加将数据从低层移至高层 4 |
Curator | 后台数据生命周期管理,冷数据迁移 | 定期扫描,根据访问频次降低将数据从高层移至低层,执行ILM策略 5 |
Oplog | 突发随机写入的低延迟持久化缓存 | 位于最快存储层,聚合并顺序化写入到 Extent Store 3 |
Autonomous Extent Store (AES) | 持续性随机写入的直接存储路径 | 绕过 Oplog 直接写入 Extent Store,优化元数据局部性 5 |
Unified Cache | CVM 内存中的动态读取缓存 | 缓存来自 Oplog 和 Extent Store 的数据以加速读取 3 |
Extent Store | 持久化批量存储,跨越所有设备层级 (NVMe, SSD, HDD) | AOS 中数据的主要存储位置,ILM 的目标层级 3 |
1.2 Amazon FSx for Lustre 智能分层存储详解
Amazon FSx for Lustre 是一种专为计算密集型工作负载(如机器学习训练、高性能计算 HPC、媒体处理和金融分析)设计的高性能文件系统服务 10。其智能分层 (Intelligent-Tiering) 存储类别旨在通过自动化的数据迁移来平衡性能与成本。
架构概览与核心优势
FSx for Lustre 智能分层存储类别的核心优势在于其“弹性”和“自动化”。它提供了几乎无限的存储可扩展性,文件系统容量会根据数据的增删自动伸缩,用户只需为实际存储的数据付费 10。这种设计免去了传统 HPC 存储中复杂的容量规划和手动数据管理工作。通过自动将冷数据分层到成本更低的存储层,并结合可选的 SSD 读取缓存来加速对延迟敏感数据的访问,FSx for Lustre 智能分层致力于提供云中成本最低的 Lustre 文件存储方案 10。
存储层级与数据迁移策略
FSx for Lustre 智能分层内部包含多个基于访问模式自动管理的存储层级:
- 频繁访问层 (Frequent Access Tier): 用于存储在过去 30 天内被访问过的数据 10。这一层通常由性能较高的存储介质(如 SSD 或针对性能优化的 HDD)构成,以保证热数据的快速访问。
- 不频繁访问层 (Infrequent Access Tier): 如果数据在 30 到 90 天内未被访问,系统会自动将其迁移到此层。相比频繁访问层,此层可降低约 44% 的存储成本 10。
- 存档即时访问层 (Archive Instant Access Tier): 若数据超过 90 天未被访问,则会进一步迁移到此成本更低的归档层,可比不频繁访问层再节省约 65% 的成本 (与频繁访问层相比总节省约 68%) 10。此层级的数据仍可实现毫秒级即时检索。
所有这些层级间的数据迁移完全由 AWS 自动管理,用户无需进行任何手动操作 10。
SSD 读取缓存
为了进一步提升对热点数据或延迟敏感型工作负载的访问性能,FSx for Lustre 智能分层包含一个可选的 SSD 读取缓存 10。在创建文件系统时,可以根据所需的吞吐能力自动配置缓存大小,用户也可以后续独立调整缓存容量,甚至在不需要低延迟访问时禁用缓存。缓存中的数据可实现亚毫秒级的首次字节访问延迟,而其他未缓存数据的访问延迟则在数十毫秒级别 10。
与 Amazon S3 的深度集成:数据存储库关联 (DRA)
FSx for Lustre 与 Amazon S3 之间通过数据存储库关联 (Data Repository Association, DRA) 功能实现了深度集成,这构成了其分层策略的重要延伸 14。DRA 允许 FSx for Lustre 文件系统与一个或多个 S3 存储桶或前缀自动同步数据。这意味着 FSx for Lustre 可以作为 S3 中海量数据的高性能 POSIX 兼容文件接口。
- DRA 释放任务 (DRA Release Task): 这是实现 FSx for Lustre 到 S3 分层的关键机制。当文件内容已经同步到 S3,并且在 FSx for Lustre 文件系统上超过用户指定的“自上次访问以来的持续时间 (Duration Since Last Access, DSLA)”后,DRA 释放任务可以将这些文件内容从 FSx for Lustre 文件系统中“逐出”(evict)。此操作仅删除 FSx for Lustre 上的文件副本,S3 中的数据不受影响,从而释放 FSx for Lustre 上的存储容量以供更热的数据使用 14。
- 自动化机制 (Automation Mechanisms):
- EventBridge 调度器 (EventBridge Scheduler): 可以配置 Amazon EventBridge 调度器来定期(例如每天一次)触发 DRA 释放任务,确保持续优化文件系统容量,自动归档冷数据到 S3 14。
- 容量监控与告警 (Capacity Monitoring and Alerting): 结合 Amazon CloudWatch 对 FSx for Lustre 文件系统的可用存储空间进行监控。当可用空间低于预设阈值(例如总容量的 25%)时,CloudWatch 警报会触发,并通过 Amazon SNS 向管理员发送通知。更进一步,当可用空间低于更危急的阈值(例如总容量的 15%)时,可以通过 AWS Lambda 函数触发一个“紧急”DRA 释放任务,该任务通常将 DSLA 设置为 0,以更积极地将所有未被使用且已同步到 S3 的文件释放,从而快速回收空间 14。
这种 FSx for Lustre (作为性能层) 与 S3 (作为容量和归档层) 结合的 DRA 机制,形成了一种混合的性能/容量模型。它不仅仅是简单的数据导入导出,而是一种动态的、持续的跨服务分层策略,特别适用于需要对 S3 数据湖中部分数据进行高性能计算或分析的场景。
Amazon FSx for Lustre 智能分层架构图
下图概念性地展示了 Amazon FSx for Lustre 智能分层的架构:
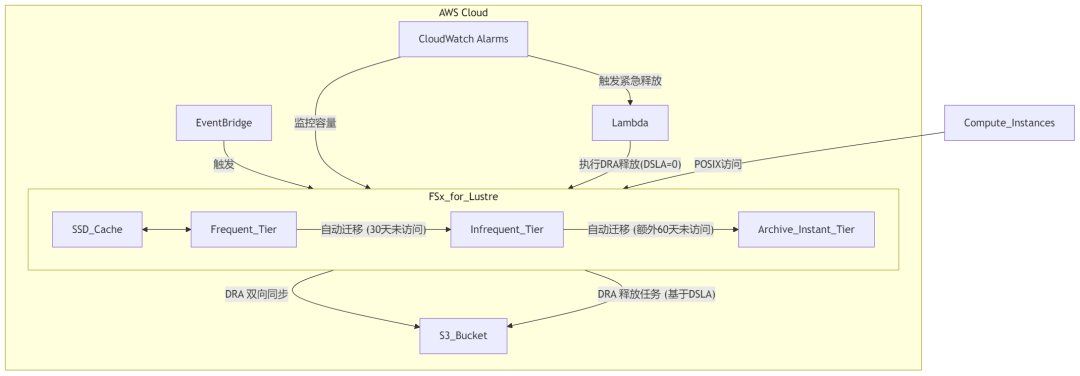
FSx for Lustre 智能分层通过其内部多级自动分层以及与 S3 的 DRA 集成,提供了从亚毫秒级高性能访问到极低成本长期归档的完整数据管理光谱。这种多层次的“冷数据”处理能力,使得用户可以根据数据的实际访问需求和生命周期,实现非常精细化的成本与性能平衡。
表 2: Amazon FSx for Lustre 智能分层 - 层级与策略
层级名称 (Tier Name) | 主要存储介质 (Primary Storage Medium) (推断/典型) | 数据迁移触发条件 (Access Criteria for Movement) | 成本影响 (Cost Implication vs. Frequent) | 检索特性 (Retrieval Characteristics) |
|---|---|---|---|---|
频繁访问层 (Frequent Access Tier) | SSD/HDD (性能优化) | 数据在过去30天内被访问 10 | 基准 | 亚毫秒级 (通过SSD缓存) 或 数十毫秒级 10 |
不频繁访问层 (Infrequent Access Tier) | HDD (成本优化) | 数据在30-90天内未被访问 10 | 约 44% 节省 | 数十毫秒级 10 |
存档即时访问层 (Archive Instant Access Tier) | 低成本归档存储 | 数据在90天以上未被访问 10 | 约 68% 节省 (相对频繁访问层) | 毫秒级可立即检索 10 |
SSD 读取缓存 (SSD Read Cache) | SSD | 缓存最常访问或对延迟敏感的数据 10 | 额外成本 | 亚毫秒级 10 |
(通过DRA关联S3) S3 存储层 | S3 Standard, S3 IA, S3 Glacier 等 | 通过DRA释放任务和DSLA策略管理 14 | S3 各层级成本 16 | 取决于S3层级 13 |
1.3 数据智能分层、缓存 (Caching) 与内容分发网络 (CDN) 对比
虽然数据智能分层、缓存和 CDN 都旨在优化数据访问和管理,但它们的核心目标、工作原理和适用场景存在显著差异。
- 核心目标 (Primary Goal):
- 智能分层: 主要目标是在数据的整个生命周期内平衡存储性能和长期存储成本。它通过将不常访问的数据移动到成本较低的存储介质,同时保留常访问数据在高性能介质上来实现这一目标 1。
- 缓存: 主要目标是降低对频繁访问数据的读取延迟,并减轻后端源服务器的负载。它通过在更靠近计算单元或用户的快速临时存储中保存数据的副本来实现 17。
- CDN: 主要目标是为地理位置分散的用户提供低延迟的内容访问体验,并分担源服务器的流量压力。它通过在全球多地部署的边缘服务器上复制和分发网站的静态内容(有时也包括部分动态内容)来实现 17。
- 数据处理方式 (Data Handling):
- 智能分层: 数据的权重副本在不同层级之间移动,其原始位置的元数据会更新。
- 缓存: 创建数据的临时副本。原始数据仍保留在其持久化存储位置。
- CDN: 在众多地理位置分散的边缘服务器上创建数据的多个副本。
- 数据范围 (Data Scope):
- 智能分层: 通常管理整个数据集或其中大部分数据,贯穿其生命周期。
- 缓存: 通常管理整体数据集中一个较小的、当前活跃使用的子集。
- CDN: 主要管理网站可公开访问的内容子集,特别是静态资源(图片、CSS、JS 文件)和流媒体。
- 持久性 (Persistence):
- 智能分层: 数据在所有层级(包括低成本的长期存储层)都保持持久化存储。
- 缓存: 缓存中的数据通常是易失的。缓存条目会根据特定策略(如 LRU 最近最少使用、LFU 最不经常使用、TTL 生存时间)被逐出,它不是一个持久化存储解决方案。
- CDN: 边缘服务器上缓存的数据是半持久的,但会根据 TTL 设置和源服务器内容的变化而刷新或失效。边缘副本并非权威数据源。
- 应用透明性 (Application Transparency):
- 智能分层: 理想情况下对应用透明,应用通过统一的命名空间访问数据,无需感知数据所在的具体物理层级 19。但不同层级带来的性能特征(尤其是延迟)差异是客观存在的。
- 缓存: 可以是透明的(如 CPU 缓存、某些存储系统内置的读缓存),也可能需要应用层面感知并主动管理(如应用级缓存 Redis、Memcached)。
- CDN: 需要进行配置(如修改 DNS 解析、重写 URL)以将用户请求导向 CDN 网络,但最终用户通常感知不到他们访问的是边缘服务器而非源站 17。
表 3: 对比分析:智能数据分层 vs. 缓存 vs. CDN
特性 (Feature) | 数据智能分层 (Intelligent Data Tiering) | 缓存 (Caching) | 内容分发网络 (CDN) |
|---|---|---|---|
主要目标 (Primary Goal) | 长期成本与性能平衡 1 | 即时读取延迟降低 17 | 地理分布用户的内容交付延迟降低 17 |
数据处理 (Data Handling) | 移动权威副本 | 创建临时副本 | 创建和分发多个副本 |
数据范围 (Data Scope) | 完整数据集或大部分 | 活跃使用的数据子集 | Web可访问内容的子集 |
持久性 (Persistence) | 持久 (所有层级) | 通常易失,非持久存储 | 边缘副本半持久,可刷新 |
位置 (Location) | 不同性能/成本的存储介质 | 靠近计算的快速存储 (如内存, SSD) | 地理分散的边缘服务器 |
主要受益者 (Primary Beneficiary) | 存储管理员/预算 | 应用/用户 (即时性能) | 终端用户 (访问速度) |
应用透明性 (App Transparency) | 目标透明,但性能特征可变 19 | 可透明或需应用感知 | 用户透明,配置层面需介入 17 |
典型用例 (Typical Use Case) | 数据生命周期管理,归档,大规模数据集成本优化 | 数据库查询加速,常用对象读取,Web应用会话 | 网站加速,视频流,大规模软件分发,静态资源分发 |
这三种技术并非总是相互排斥,反而常常协同工作。例如,一个复杂的 Web 应用可能在后端数据库存储中使用智能数据分层来管理历史数据和活跃数据;在应用服务器层面使用缓存(如 Redis)来加速对常用业务对象或查询结果的访问;同时利用 CDN 来分发其全球用户访问的静态资源(图片、脚本)和动态内容。这种分层协同的策略能够针对不同层面的瓶颈和优化目标提供综合解决方案。
选择这些技术时,一个关键的考量点是数据一致性模型的复杂性。智能分层主要涉及移动权威数据,一致性问题相对集中在确保元数据(指向数据位置的指针)的准确性。而缓存和 CDN 则创建数据副本,这就引入了缓存一致性和内容新鲜度的问题,需要通过 TTL、缓存失效、CDN 内容刷新等机制来管理,以避免用户访问到过期数据。
此外,管理和控制的粒度也不同。CDN 通常作为一种托管服务,用户通过服务商提供的控制面板进行高级配置。本地缓存(如浏览器缓存或应用服务器内置缓存)则允许开发者和管理员进行非常细致的调优。智能数据分层系统则旨在基于预设策略(例如,“数据 X 天未访问则迁移到 Y 层”)实现自动化管理,虽然策略本身是可配置的,但具体的迁移决策和执行由系统自动完成。
第二部分:业务数据智能分层的应用层改造
虽然许多现代智能数据分层系统致力于实现对上层应用的透明性,但在某些情况下,应用层进行适当的改造或具备一定的“分层感知”能力,可以更充分地发挥智能分层的效益,甚至实现更优的性能和成本控制。
2.1 应用层感知与数据访问模式
理解数据“温度”与生命周期
应用是数据的生产者和消费者,它们最了解自身数据的访问模式、重要性及生命周期特征 2。例如,电商平台的订单数据,在刚生成时是“热”数据,需要频繁访问和快速更新;几周后可能变为“温”数据,用于生成报表和近期分析;数月或数年后则变为“冷”数据,主要用于历史追溯或合规存档 2。应用开发者或数据架构师需要对这些模式进行分析和识别,这是制定有效数据分层策略的基础。数据分类是这一过程的核心,分类标准可以包括访问频率、数据的重要性、数据类型、预期的保留期限、数据大小等多个维度 8。
应用与分层存储的交互
理想情况下,智能分层对应用是透明的,应用无需关心数据具体存储在哪个物理层。然而,如果应用能够提供关于数据预期访问模式的“提示”,或者能够根据当前数据所处的层级调整其行为,则可能获得更好的效果。例如,一个应用在完成对一批数据的密集处理后,若能预知这些数据在短期内不会再被频繁访问,它可以主动通知存储系统将这批数据迁移到成本更低的层级,而不是等待存储系统通过被动监测来发现其“变冷”。
2.2 实现应用透明性的策略
存储系统层面的抽象
现代存储系统,尤其是软件定义存储和云存储服务,通常通过提供统一的命名空间和标准化的访问接口(如 POSIX 文件接口、NFS/SMB 协议、S3 对象存储 API 等)来屏蔽底层存储介质的复杂性 19。例如,GigaSpaces 的智能分层方案允许客户端应用通过标准 API 与数据交互,无论数据实际位于内存中的“热层”还是 SSD 上的“温层”,应用代码无需改变,由系统负责数据的路由和管理 19。这种抽象是实现应用透明性的基石。
业务逻辑调整:显式提示 vs. 隐式依赖
- 隐式依赖 (Implicit Reliance): 这是最常见且对应用开发者最友好的方式。应用完全不感知分层细节,完全依赖存储系统自身的自动化分层逻辑。这种方式简化了应用开发,但可能无法应对所有特殊的性能或成本需求。
- 显式提示 (Explicit Hints): 在某些高级场景下,应用可以向存储系统提供关于数据生命周期或预期访问模式的元数据或指令。例如,应用可以为新创建的数据打上“临时高性能”、“长期归档”等标签,如果存储系统支持解析这些标签并将其纳入分层决策,就能实现更精准和主动的数据管理。这虽然增加了应用的复杂度,但可能带来显著的效益。Oracle ILM 允许基于维护对象特定标准定义多个保留期,如按测量数据的类型或单位 23,这即是一种应用层面的信息输入。
2.3 改造示例与最佳实践
数据模型设计
在设计应用的数据模型时,可以考虑如何使其更容易被智能分层系统理解和处理。例如,对于时序数据或日志数据,按时间范围进行分区或分表,不仅便于查询,也使得存储系统更容易识别和迁移旧的、访问频率较低的“冷”分区到低成本层。
API 利用
如果存储系统提供了查询数据所在层级或控制数据放置的 API(例如 GigaSpaces 允许的 MEMORY_ONLY_SEARCH 19),那么对延迟高度敏感的应用模块在执行关键操作前,可以检查目标数据是否位于“热层”,如果不是,则根据业务逻辑决定是等待数据提升、访问性能较低的副本,还是返回特定提示。
查询优化
对于需要在分层存储上执行分析查询的应用(如大数据分析平台),其查询优化器最好能感知数据的分层状态。当查询需要访问分布在不同层级的数据时,优化器可以生成更高效的执行计划,例如,优先在数据量大的冷层进行过滤操作,或者在必要时将冷数据预取到热层再进行复杂计算。
避免的陷阱
- 过度耦合 (Tight Coupling): 应用逻辑应避免与特定存储系统的分层行为和内部实现细节过度耦合。例如,不应假设数据在特定时间后“一定”会被迁移到某个层,因为分层策略和系统负载都可能变化。应依赖于标准的接口和抽象。
- 性能误判 (Performance Misjudgment): 应用需要为访问可能已被迁移到冷层的数据做好准备,这意味着需要处理更长的访问延迟。超时机制、重试逻辑以及用户界面的反馈都需要考虑到数据“回写”(rehydration)所需的时间 24。
- 忽略元数据操作 (Ignoring Metadata Operations): 对于包含大量小文件的场景,如果元数据本身的访问和管理没有得到优化,单纯对数据文件进行分层可能效果有限。元数据操作的开销也应纳入考量。
应用层改造的核心在于找到“透明性”与“可控性”之间的平衡点。完全透明简化了开发,但可能牺牲部分优化机会;而过多的应用层控制则增加了复杂性并可能引入与存储系统的紧耦合。一种理想的模式可能是:默认情况下应用透明地与存储交互,同时存储系统提供可选的高级 API 或元数据机制,供有特殊需求的应用进行更细致的优化。
此外,有效的数据生命周期管理 (DLM) 是应用层与存储层共同的责任 8。应用最了解数据的业务上下文、合规要求和预期生命周期,而存储系统负责根据这些信息(可能通过应用提供的元数据或策略)和实际观测到的访问模式来自动化物理数据的放置。这种协作能够使智能分层超越简单的基于访问频率的冷热判断,实现更符合业务需求的、真正意义上的信息生命周期管理。
最后,引入智能数据分层也对应用的测试和质量保证(QA)提出了新的要求。测试用例需要覆盖数据在不同层级(包括从冷层回写)时的应用行为和性能表现,确保应用在各种数据“温度”条件下都能稳定、可靠地运行 24。
第三部分:AI推理与大数据分析场景下的智能数据分层
智能数据分层技术在处理海量数据、对访问延迟敏感以及成本压力显著的 AI 推理和大数据分析场景中,展现出独特的价值和挑战。
3.1 AI 推理场景中的价值与挑战
价值
- 模型与热点数据集的低延迟访问: AI 推理过程,无论是图像识别、自然语言处理还是推荐系统,都要求对已训练好的模型文件以及当前推理请求所需的热点输入数据或特征进行极低延迟的访问 1。将这些关键组件置于最高性能的存储层(如 NVMe SSD 或内存),是保证实时或近实时预测响应的关键。
- 成本优化: 企业可能拥有大量的 AI 模型,其中一些可能不经常使用,或者会积累大量的历史推理请求和响应数据用于审计或再训练。智能分层可以将这些访问频率较低的模型或历史数据自动迁移到成本更低的存储层,从而在不牺牲活跃模型推理性能的前提下,显著优化总体存储成本 1。例如,模型训练完成后,用于训练的大部分数据会迅速“变冷”,自动分层技术可以将其迁移到冷存储 1。
挑战与注意事项
- 模型加载时间 (冷启动延迟): 如果一个不常用的 AI 模型被分层到了冷存储(如对象存储的归档层),当首次收到针对该模型的推理请求时,模型加载(回写)过程可能会引入显著的延迟,影响首次推理的响应时间 25。应对策略包括:
- 模型预热 (Pre-warming): 根据预测或调度,提前将可能被调用的冷模型加载到热层。
- 缓存策略: 在热层维护一个最近使用过或最有可能被使用的模型缓存。
- 分级加载: 对于非常大的模型,可以考虑是否能分块加载,优先加载核心部分。
- 小文件问题: 某些 AI 模型(尤其是传统机器学习模型)或其依赖的特征数据可能由大量小文件构成。智能分层系统在处理海量小文件时,其效率可能会受到元数据操作开销的影响。一些系统对小对象的自动分层支持有限,例如 Amazon S3 智能分层中,小于 128KB 的对象不参与自动分层 29。
- 与计算节点的数据局部性: 在分布式推理场景下,模型可能被拆分并部署到多个计算节点。确保每个计算节点能够从本地或就近的高性能存储层访问其所需的模型分片和相关数据,对于维持整体推理吞吐量和低延迟至关重要。智能分层策略需要与计算调度协同,以优化数据局部性。
智能数据分层为 AI 规模化部署提供了经济可行性。若无有效分层,AI 开发和部署过程中产生的大量“数据废气”(如中间训练数据、多版本模型、日志等)将因存储成本过高而难以为继。因此,分层不仅是优化手段,更是支撑大规模 AI 应用的关键技术。
3.2 大数据分析场景中的价值与挑战
价值
- 海量历史数据的成本效益存储: 大数据平台通常需要存储和管理 PB 乃至 EB 级别的历史数据,其中大部分数据随着时间的推移会迅速变冷 31。智能分层允许将这些海量历史数据经济高效地存储在低成本介质上(如云对象存储的低频访问层或归档层),同时保留其用于合规审计、趋势分析或未来探索性研究的可能性 2。Teradata 的研究发现,在典型数据仓库中,85% 的查询 I/O 仅使用了 20% 的数据空间,而高达 46% 的 I/O 仅使用了 2% 的“超热”数据 33,这充分说明了分层的潜力。
- 查询性能与成本的平衡: 对于频繁进行的运营性报表和即席查询,其依赖的“热”数据或“温”数据可以保留在高性能存储层以保证查询效率。而对于不常进行的深度历史分析或数据挖掘任务,其数据可以存放在成本更低的“冷”层,在需要时再进行访问,从而在查询性能和存储成本之间取得平衡 2。
- 数据湖中的分层策略: 在现代数据湖架构(如 Medallion 架构,包含原始层-Bronze、清洗层-Silver、汇总层-Gold)中,智能分层可以在这些区域内部或跨区域应用 34。例如,原始的、未经处理的 Bronze 层数据可以存放在最低成本的存储,而经过处理和汇总、直接服务于商业智能的 Gold 层数据则可以放在性能更高的存储层。
挑战与注意事项
- 查询规划与数据“温度”感知: 大数据分析的查询引擎(如 Presto, Spark SQL, Hive)需要能够感知数据的分层状态。如果查询需要访问冷层数据,引擎应能预估到可能产生的较高延迟,并据此优化查询计划。例如,它可能会尝试将计算下推到靠近冷数据的位置进行早期过滤,或者在用户可接受的延迟范围内决定是否需要将冷数据回写到热层进行处理。某些高级系统甚至可能允许用户在提交查询时指定可接受的延迟或成本预算,从而影响数据访问策略。
- 大规模数据迁移开销: 在 PB 级的数据环境中,层间数据迁移本身就是一个耗时且消耗网络带宽的过程。这些迁移任务需要被妥善调度,通常在系统负载较低的时段进行,以避免影响正常的分析工作负载。
- 元数据管理: 对于跨越多个层级、包含海量对象或文件的大数据集,高效的元数据管理至关重要。元数据需要准确记录每个数据块的位置、状态和属性,以便于数据发现、查询优化和生命周期管理。
- 数据格式与压缩: 采用优化的列式存储格式(如 Apache Parquet, Apache ORC)和高效的压缩算法,可以在所有存储层级上减少存储空间占用,并提升数据扫描和查询性能,这与智能分层策略相辅相成,共同提升大数据分析的性价比。
在大数据分析中,智能分层不仅仅关乎存储成本,它还深刻影响着“数据重力”(data gravity)问题。当分析查询需要跨越不同层级(甚至不同物理位置,如本地与云端)的数据时,如何高效地移动数据到计算资源,或将计算推近数据,成为查询性能的关键。这要求存储分层策略与分析平台的计算策略进行协同设计。
3.3 性能与成本优化案例分析
- Amazon S3 Intelligent-Tiering: 该服务通过自动监测对象访问模式,在频繁访问层、不频繁访问层和存档即时访问层之间移动数据。例如,连续 30 天未访问的对象会移至不频繁访问层(节省约 40% 成本),连续 90 天未访问则移至存档即时访问层(总节省约 68% 成本)。用户还可以选择激活异步的深度存档访问层,将 180 天以上未访问的数据移入,实现高达 95% 的存储成本节省 13。值得注意的是,小于 128KB 的小对象不参与自动分层,且无最小存储期限要求,早期删除不收取费用 29。23andMe 公司就利用 S3 Intelligent-Tiering 自动迁移数据以优化云存储成本,同时确保数据安全和持久性 36。
- Amazon FSx for Lustre for ML/HPC: FSx for Lustre 常用于高性能计算和机器学习的数据暂存和 I/O 管理,提供类似本地集群文件系统的访问体验 37。其基于 AWS Graviton 处理器的下一代文件系统,可提供高达每 TiB 5 倍的吞吐量,并将吞吐成本降低多达 60% 38。其智能分层存储类别进一步为混合了热、温、冷数据的 HPC 和 ML 工作负载优化了成本 10。
- Komprise TCO 分析: Komprise 对 10 个使用其服务的组织进行了 TCO 汇总分析,结果表明,通过识别 NAS(网络附加存储)中的冷数据并将其透明地分层到云或对象存储等二级存储,客户在主存储、备份和灾难恢复方面的成本均得到显著降低 39。
- 基于预测分析的分层: 学术研究和一些商业实践表明,利用机器学习模型来研究历史数据访问模式,可以预测未来的数据访问趋势,从而更主动和准确地进行数据放置决策。有研究称,此类模型在冷热数据分类方面可达到 90% 的准确率,有效降低运营成本 32。
随着数据在不同层级间流动,除了传统的“结果获取时间”(Time-to-Result) 外,“数据访问时间”(Time-to-Access),特别是冷数据的回写时间,成为一个新的关键性能指标。组织需要根据业务需求,为不同类型的数据和查询场景定义可接受的访问时间 SLA,并将其纳入分层策略和成本效益分析中。
表 4: AI/大数据场景下智能分层的 TCO/ROI 影响因素示例
因素类别 (Factor Category) | 成本/效益因素 (Cost/Benefit Factor) | AI训练 (AI Training) | AI推理 (AI Inference) | 大数据归档 (Big Data Archival) | 活跃大数据分析 (Active Big Data Analytics) |
|---|---|---|---|---|---|
成本降低 (Cost Reduction) | 主存储介质成本 (Primary Storage Media Cost) | 中 (M) | 中 (M) | 高 (H) | 中-高 (M-H) |
备份与灾难恢复成本 (Backup & DR Cost) | 中 (M) | 中 (M) | 高 (H) | 中 (M) | |
数据中心占用空间/电力 (Data Center Footprint/Power) | 低-中 (L-M) | 低-中 (L-M) | 中 (M) | 低-中 (L-M) | |
数据迁移/检索费用 (Data Migration/Retrieval Fees - if poorly managed) | 关注 (Note) | 关注 (Note) | 关注 (Note) | 关注 (Note) | |
效益提升 (Benefit Increase) | 应用/模型执行性能 (Application/Model Execution Performance) | 高 (H) | 高 (H) | 低 (L) (非目标) | 中-高 (M-H) |
分析洞察速度 (Speed of Analytics/Insights) | 高 (H) | - | 低 (L) (非目标) | 中-高 (M-H) | |
资源利用率优化 (Optimized Resource Utilization - Compute & Storage) | 高 (H) | 高 (H) | 高 (H) | 高 (H) | |
可扩展性与敏捷性 (Scalability & Agility) | 高 (H) | 高 (H) | 高 (H) | 高 (H) | |
运营管理开销降低 (Reduced Operational Overhead - due to automation) | 中 (M) | 中 (M) | 中 (M) | 中 (M) |
(H: 高影响, M: 中影响, L: 低影响, Note: 需特别关注的潜在成本项)
第四部分:实施智能数据分层的关键考量
成功实施智能数据分层策略,需要仔细评估和应对一系列技术和管理上的挑战。
4.1 数据分类的复杂性与自动化
有效的数据分层始于准确的数据分类。需要根据数据的业务价值、敏感性、访问需求、合规要求等多个维度进行综合评估 8。常用的分类标准包括访问频率、数据年龄、数据类型、重要性级别以及法定的保留期限等 2。然而,随着数据量的爆炸式增长和数据来源的多样化,完全依赖人工进行细致的数据分类变得不切实际且效率低下。因此,自动化成为关键 8。许多现代存储系统和数据管理平台提供了基于策略的自动化分类和迁移工具。更进一步,可以引入预测分析和机器学习技术,通过分析历史访问模式来预测数据未来的“温度”变化,从而实现更主动、更智能的分层决策 32。
4.2 数据迁移与回写延迟
将数据从活动层迁移到冷存储层,以及在需要时将其从冷层“回写”(rehydrate 或 restore)到活动层,是智能分层操作的核心。访问已被分层到冷存储(尤其是深度归档层)的数据时,不可避免地会引入延迟,这个延迟可能从毫秒级(如从即时访问归档层)到数小时甚至更长(如从磁带库或离线归档)24。
缓解回写延迟的策略包括:
- 设定回写优先级: 一些云存储服务(如 Azure Blob Storage)提供了不同的回写优先级选项。例如,“标准优先级”可能需要数小时完成,成本较低;而“高优先级”可能在数十分钟或一小时内完成(针对特定大小的对象),但成本也相应更高 26。组织可以根据数据恢复的紧急程度选择合适的优先级。
- 将归档数据复制到在线层: 与其在原地等待归档数据回写完成,不如将其直接复制为一个新的对象到热层或温层,应用可以立即开始访问这个新副本 26。
- 数据预取 (Prefetching): 对于可预测的访问模式,可以利用编译器或运行时技术,在数据被实际请求之前,就将其从慢速存储层预取到 CPU 缓存或更快的存储层中,从而掩盖部分回写延迟 25。
此外,需要注意的是,回写大量小文件的总开销和时间可能比回写同等总量的少数大文件要高,因为每个文件都可能涉及一定的处理开销 26。因此,在归档前对小文件进行聚合打包可能是个值得考虑的优化。
对“冷数据”的访问成本不应被低估。除了存储介质本身的 $/GB/月费用外,从冷层检索数据可能涉及额外的检索费用(特别是加急检索)和潜在的性能影响 16。如果分层策略设置不当,导致“温”数据被错误地移入“冷”层,频繁的回写操作不仅会抵消存储成本的节省,还会严重影响应用性能。
4.3 存根管理与数据访问透明性
传统的层级存储管理 (HSM) 系统通常在主存储上保留一个指向已迁移到二级存储的“存根文件”(stub file) 或指针。当应用访问这个存根时,HSM 系统会拦截该请求,并触发从二级存储回写数据的过程 24。
这种基于存根的机制存在一些潜在风险:
- 延迟增加: 存根的解析和实际数据的检索过程会给用户访问带来额外的延迟 24。
- 存根脆弱性: 如果存根文件本身损坏、丢失,或者其指向的后端数据位置发生变化而存根未及时更新,可能导致数据访问失败,甚至数据“孤立” (orphaned) 24。
- 备份与恢复复杂性: 备份策略需要明确是备份存根还是实际数据。如果只备份存根,那么在恢复时必须依赖 HSM 系统的可用性和后端数据的完整性。如果采用基于存储块的专有格式进行分层,可能导致备份窗口延长,因为备份软件可能需要先回写数据块才能进行备份 24。
现代的一些数据管理解决方案(如 Komprise)尝试通过使用标准文件系统特性(如符号链接)来替代专有的存根机制,以期提供更好的透明度和更低的风险 24。然而,如果数据在后端是以专有的块格式存储的,那么即便前端有符号链接,数据在二级存储或云端也可能无法被其他应用或服务直接原生访问 24。
4.4 供应商锁定风险与规避策略
许多存储供应商提供的智能分层解决方案,特别是将数据从本地存储分层到云端时,可能会以专有的数据格式(通常是块级)进行存储。这使得这些在云端的数据无法被标准的云原生服务直接访问和处理,从而将用户锁定在该存储供应商的技术生态系统中 24。一旦用户希望更换存储供应商或直接利用云平台的数据服务,就可能面临数据迁移困难、格式不兼容以及额外成本等问题。
Dave's ponit
JuiceFS 的实现就重新构建了对象的分块,虽然提升了元数据检索和可扩展性,但在多云之间的迁移存在挑战。
规避供应商锁定的策略包括:
- 优先采用开放标准和格式: 尽可能确保数据在所有层级,尤其是在云端目标层,都以开放的、非专有的格式(如 Parquet, ORC, 或标准文件格式)存储,以便于数据的迁移和跨平台互操作 43。
- 确保数据可移植性: 在选择解决方案和设计应用时,应充分考虑数据的可移植性,确保能够相对容易地将数据从一个平台迁移到另一个平台 43。
- 考虑多云或混合云架构: 通过将工作负载和数据分布在不同的云服务提供商或结合本地私有云和公有云,可以降低对单一供应商的依赖性,增加选择的灵活性 43。
- 明确出口成本和SLA: 在采用任何分层方案前,务必了解将数据迁出该方案(尤其是从云端迁回或迁至其他云)的成本结构、技术难度和服务水平协议 (SLA) 43。
- 倾向于文件级而非块级分层至云端: 通常情况下,文件级的数据分层更有可能在目标云存储上以较原生的格式保存数据,从而提高其可访问性和可利用性 24。
4.5 监控与持续优化
数据的访问模式并非一成不变,它会随着业务的发展、应用的变化以及时间的推移而演变 27。因此,智能数据分层不是一个“一劳永逸”的设置,而是一个需要持续监控、评估和优化的过程。
关键的监控与优化活动包括:
- 定期审计分层策略: 至少应定期(例如每季度或每半年)回顾和评估当前的分层策略是否仍然符合业务需求和成本效益目标。
- 监控关键指标: 跟踪存储容量使用率、各层级的数据分布、数据迁移活动的频率和数据量、数据回写的频率和延迟等关键性能指标 (KPIs) 14。
- 分析访问模式变化: 利用存储系统提供的分析工具或第三方工具,持续分析数据访问模式的变化趋势,识别是否有“概念漂移”(concept drift) 现象,即原有的冷热数据划分标准已不再适用 20。
- 调整分类规则和策略参数: 根据监控和分析结果,及时调整数据分类的规则、数据迁移的阈值(如未访问天数)以及回写策略等。
- 建立清晰的数据治理框架: 制定明确的数据治理政策,规范数据分层的目标、流程、责任和审计机制 27。
自动化是智能分层的核心优势,但这种自动化依赖于预设的策略或机器学习模型。如果这些策略配置不当,或者模型未能准确反映真实的业务需求,自动化系统反而可能持续做出次优的决策。因此,人工的监督、治理和定期的策略验证对于确保自动化分层系统长期有效地服务于业务目标至关重要。
此外,智能数据分层策略的实施需要与整体的数据保护策略(包括备份、容灾、归档)进行协同规划。需要明确不同层级数据的保护要求,避免重复保护(例如,对已经持久化归档的数据再进行全量备份),并确保在各种故障场景下,所有层级的数据都能满足恢复时间目标 (RTO) 和恢复点目标 (RPO) 的要求,同时要考虑到冷数据的回写时间对 RTO 的影响 24。
结论与展望
智能数据分层的核心价值总结
智能数据分层作为一项关键的存储管理技术,其核心价值在于通过自动化机制,在优化存储成本和保障数据访问性能之间取得动态平衡。它能够识别数据的“温度”,将访问频繁的“热”数据置于高性能存储层以满足低延迟需求,同时将访问稀少的“冷”数据迁移至低成本存储层以降低总体拥有成本。这一过程不仅提升了存储资源的利用效率,还使得企业能够经济有效地管理日益增长的海量数据,支持数据驱动的业务决策和创新。
未来发展趋势
展望未来,智能数据分层技术预计将在以下几个方向持续演进:
- 更智能的AI驱动分层: 当前的智能分层已开始应用机器学习技术,未来将更加深化。系统有望通过更复杂的 AI 模型,实现对数据访问模式更精准的预测,甚至理解数据的语义和上下文,从而做出更主动、更精细化的分层决策,动态适应应用行为和业务需求的细微变化 32。
- 应用与存储的深度协同: 应用与存储系统之间的信息交互将更加丰富和标准化。应用能够更方便地向存储系统传递关于数据生命周期、预期访问模式、业务价值或合规要求的“提示”或元数据,存储系统则利用这些信息来指导其分层策略,实现真正的“应用感知”存储。
- 跨云与混合云环境的统一分层: 随着多云和混合云架构的普及,市场将需要能够跨越本地数据中心和多个公有云平台,提供统一视图和单一控制平面的智能数据分层解决方案。这将允许数据在异构环境中根据策略自由流动,同时保持访问的透明性和管理的一致性。
- 关注数据“价值”而非仅“温度”: 未来的分层决策将超越单纯基于访问频率(“温度”)的考量,更多地融入数据的“价值”维度。这包括数据的业务关键性、合规性要求、潜在的未来分析价值、数据质量等因素,使得分层策略能更好地服务于整体业务目标 20。
- 与数据安全和治理的融合: 智能分层将与数据安全策略(如加密、访问控制)和数据治理框架(如数据主权、保留策略)更紧密地集成。例如,敏感数据在迁移到特定层级或云区域时,可能会自动应用更严格的安全防护。
总体而言,智能数据分层技术正朝着更自动化、更智能化、更与业务需求紧密结合的方向发展,它将继续作为应对海量数据挑战、优化 IT 基础架构成本和释放数据价值的关键赋能技术。
===
Cite
- Why Auto-Tiering is Essential for AI Solutions: Optimizing Data ..., 访问时间为 六月 7, 2025, https://insideainews.com/2024/11/11/why-auto-tiering-is-essential-for-ai-solutions-optimizing-data-storage-from-training-to-long-term-archiving/
- Storage Tiering Guide for Data Archival - NAKIVO, 访问时间为 六月 7, 2025, https://www.nakivo.com/blog/storage-tiering/
- Definitive Guide to Nutanix AOS Storage, 访问时间为 六月 7, 2025, https://www.nutanix.com/content/dam/nutanix/en/resources/ebook/eb-definitive-guide-to-aos-storage.pdf
- Nutanix Core Performance, 访问时间为 六月 7, 2025, https://portal.nutanix.com/page/documents/solutions/details?targetId=TN-2096-Nutanix-Core-Performance:TN-2096-Nutanix-Core-Performance
- Effective Data Classification and Tiering - Nutanix, 访问时间为 六月 7, 2025, https://portal.nutanix.com/page/documents/solutions/details?targetId=TN-2096-Nutanix-Core-Performance:effective-data-classification-and-tiering.html
- Prism 7.0 - Nutanix Platform Overview, 访问时间为 六月 7, 2025, https://portal.nutanix.com/docs/Web-Console-Guide-Prism-v7_0:app-about-nutanix-complete-cluster-c.html
- Nutanix Benefit 2: Automated App-Aware Data Management, 访问时间为 六月 7, 2025, https://www.nutanix.dev/2022/08/10/nutanix-benefit-2-automated-app-aware-data-management/
- A Guide to Data Lifecycle Management | Nutanix, 访问时间为 六月 7, 2025, https://www.nutanix.com/how-to/a-guide-to-data-lifecycle-management
- Cluster Components - The Nutanix Cloud Bible, 访问时间为 六月 7, 2025, https://www.nutanixbible.com/2f-book-of-basics-cluster-components.html
- Amazon FSx for Lustre launches new storage class with the lowest-cost and only fully elastic Lustre file storage | AWS News Blog, 访问时间为 六月 7, 2025, https://aws.amazon.com/blogs/aws/amazon-fsx-for-lustre-adds-new-storage-class-with-the-lowest-cost-and-only-fully-elastic-lustre-file-storage/
- Unlock higher performance for file system workloads with scalable metadata performance on Amazon FSx for Lustre | AWS Storage Blog, 访问时间为 六月 7, 2025, https://aws.amazon.com/blogs/storage/unlock-higher-performance-for-file-system-workloads-with-scalable-metadata-performance-on-amazon-fsx-for-lustre/
- Amazon FSx for Lustre adds new storage class that delivers the lowest-cost and only fully elastic Lustre file storage, 访问时间为 六月 7, 2025, https://aws.amazon.com/about-aws/whats-new/2025/05/amazon-fsx-lustre-new-storage-class
- Amazon S3 storage classes - AWS, 访问时间为 六月 7, 2025, https://aws.amazon.com/s3/storage-classes/
- Optimizing Amazon FSx for Lustre storage consumption using ... - AWS, 访问时间为 六月 7, 2025, https://aws.amazon.com/blogs/storage/optimizing-fsx-for-lustre-storage-consumption-using-automatic-data-tiering-with-amazon-s3/
- aws-samples/fsx-lustre-automatic-tiering - GitHub, 访问时间为 六月 7, 2025, https://github.com/aws-samples/fsx-lustre-automatic-tiering
- Amazon S3 Pricing - Cloud Object Storage - AWS, 访问时间为 六月 7, 2025, https://aws.amazon.com/s3/pricing/
- CDN vs Caching: The Key Differences You Need to Know, 访问时间为 六月 7, 2025, https://www.demoup-cliplister.com/en/blog/cdn-vs-caching-differences/
- CDN vs Caching: A Comparative Analysis - AccuWeb.Cloud, 访问时间为 六月 7, 2025, https://accuweb.cloud/blog/cdn-vs-caching/
- Tiered Storage Overview - GigaSpaces Technical Documentation, 访问时间为 六月 7, 2025, https://docs.gigaspaces.com/latest/admin/intelligent-tiering-overview.html
- Tiered Storage: A Data Strategy for 2025 and Beyond - Cribl, 访问时间为 六月 7, 2025, https://cribl.io/blog/tiered-storage-a-data-strategy-for-2025-and-beyond/
- What Is Tiered Storage? Our Guide on Everything You Need to Know - Parallels, 访问时间为 六月 7, 2025, https://www.parallels.com/blogs/ras/tiered-storage/
- TIERED STORAGE - Fujifilm, 访问时间为 六月 7, 2025, https://asset.fujifilm.com/master/americas/files/2020-08/ac5e7c1c0d8d877a2599c7af831e0542/Horison_Tiered-Storage_2020.pdf
- Understanding Information Lifecycle Management (ILM) - Oracle Help Center, 访问时间为 六月 7, 2025, https://docs.oracle.com/en/industries/energy-water/rate-cloud/254/rcs-user-guides/Topics/D1_AG_Understanding_Information_Lifecycle_Management__ILM_.html
- 7 Data Tiering Pitfalls That Reduce Your Storage Savings - Komprise, 访问时间为 六月 7, 2025, https://www.komprise.com/resources/7-archiving-pitfalls-that-reduce-your-savings/
- Tolerate It if You Cannot Reduce It: Handling Latency in Tiered Memory - acm sigops, 访问时间为 六月 7, 2025, https://sigops.org/s/conferences/hotos/2025/papers/hotos25-72.pdf
- Blob rehydration from the archive tier | Microsoft Learn, 访问时间为 六月 7, 2025, https://learn.microsoft.com/en-us/azure/storage/blobs/archive-rehydrate-overview
- What is Tiered Storage? Guide to Tiers, Automation, and Optimization | Aerospike, 访问时间为 六月 7, 2025, https://aerospike.com/blog/tiered-storage-guide/
- AI Inference Tips: Best Practices and Deployment - Mirantis, 访问时间为 六月 7, 2025, https://www.mirantis.com/blog/what-is-ai-inference-a-guide-and-best-practices/
- Optimizing storage costs using Amazon S3 - AWS, 访问时间为 六月 7, 2025, https://aws.amazon.com/s3/cost-optimization/
- Amazon S3 Intelligent-Tiering Overview - YouTube, 访问时间为 六月 7, 2025, https://www.youtube.com/watch?v=QB2TUII3wtc
- You don't have big data - Hacker News, 访问时间为 六月 7, 2025, https://news.ycombinator.com/item?id=7192839
- Intelligent Tier-Based Data Management: A Predictive Approach to Cloud Storage Cost Optimization - PhilArchive, 访问时间为 六月 7, 2025, https://philarchive.org/archive/VENAPA
- THE IMPACT OF DATA TEMPERATURE ON THE DATA WAREHOUSE - Teradata, 访问时间为 六月 7, 2025, https://assets.teradata.com/resourceCenter/downloads/WhitePapers/EB6690.pdf
- Data Lake Architecture for Unified Data Analytics Platform - Dataforest, 访问时间为 六月 7, 2025, https://dataforest.ai/blog/data-lake-architecture-for-unified-data-analytics-platform
- AWS Cost Optimization: Strategies, Best Practices, and Tools - Spacelift, 访问时间为 六月 7, 2025, https://spacelift.io/blog/aws-cost-optimization
- shalabh05/shalabh_most_updated · Datasets at Hugging Face, 访问时间为 六月 7, 2025, https://huggingface.co/datasets/shalabh05/shalabh_most_updated/viewer
- AWS Architecture Monthly July 2021 - awsstatic.com, 访问时间为 六月 7, 2025, https://d1.awsstatic.com/whitepapers/architecture-monthly/AWS-Architecture-Monthly-July-2021.pdf
- Amazon s3 storage lens metrics now available in amazon cloud watch | PPT - SlideShare, 访问时间为 六月 7, 2025, https://www.slideshare.net/slideshow/amazon-s3-storage-lens-metrics-now-available-in-amazon-cloud-watch/250864993
- Quantifying the Value of Komprise Intelligent Data Management, 访问时间为 六月 7, 2025, https://www.komprise.com/resources/quantifying-the-value-of-komprise-intelligent-data-management-read-online/
- Hammer: Towards Efficient Hot-Cold Data Identification via Online Learning - arXiv, 访问时间为 六月 7, 2025, https://arxiv.org/pdf/2411.14759?
- Komprise Architecture, 访问时间为 六月 7, 2025, https://www.komprise.com/wp-content/uploads/Komprise_Architecture_WhitePaper.pdf
- In-depth Guide to Storage Pools and Data Tiering Strategies, 访问时间为 六月 7, 2025, https://www.komprise.com/glossary_terms/storage-pool/
- What Is Cloud Vendor Lock-In (And How To Break Free)? - Cast AI, 访问时间为 六月 7, 2025, https://cast.ai/blog/vendor-lock-in-and-how-to-break-free/
Notice:Human's prompt, Datasets by Gemini-2.5-Pro-DeepResearch
---【本文完】---
👇阅读原文,查看历史文章(更新到 5.29)。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号