Wolley:基于 NVMe-oC 的 type3 SSD架构

Wolley:基于 NVMe-oC 的 type3 SSD架构

数据存储前沿技术
发布于 2026-03-09 17:48:21
发布于 2026-03-09 17:48:21
阅读收获
- 深入理解NVMe-oC架构如何利用CXL融合DRAM与NAND,构建应对AI内存挑战的三级混合架构。
- 掌握“主机管理分层”与“设备管理缓存”的性能与灵活性差异,指导技术选型。
- 洞察ASIC对CXL协议处理的性能加速,及其对NVMe-oC商业化落地的关键价值。
- 评估NVMe-oC在不同工作负载下的性能表现与成本效益,为数据中心内存优化提供新思路。
全文概览
在AI大模型时代,DDR内存的“带宽墙”与HBM内存的“容量墙”正日益凸显,传统存储器层次结构已难以满足对大容量、高带宽内存系统的双重需求。CXL(Compute Express Link)作为新兴互连协议,为内存扩展带来了新的曙光。本文将深入探讨NVMe-oC(NVMe-over-CXL)内存模式,一种将DRAM与NAND SSD物理融合的创新架构。它如何通过“主机管理分层”策略,在性能与成本之间找到最佳平衡点?ASIC相较FPGA的巨大性能优势,又将如何加速这一技术从原型走向大规模商用?NVMe-oC能否真正重塑数据中心内存架构,为AI及数据密集型应用带来革命性变革?
👉 划线高亮 观点批注

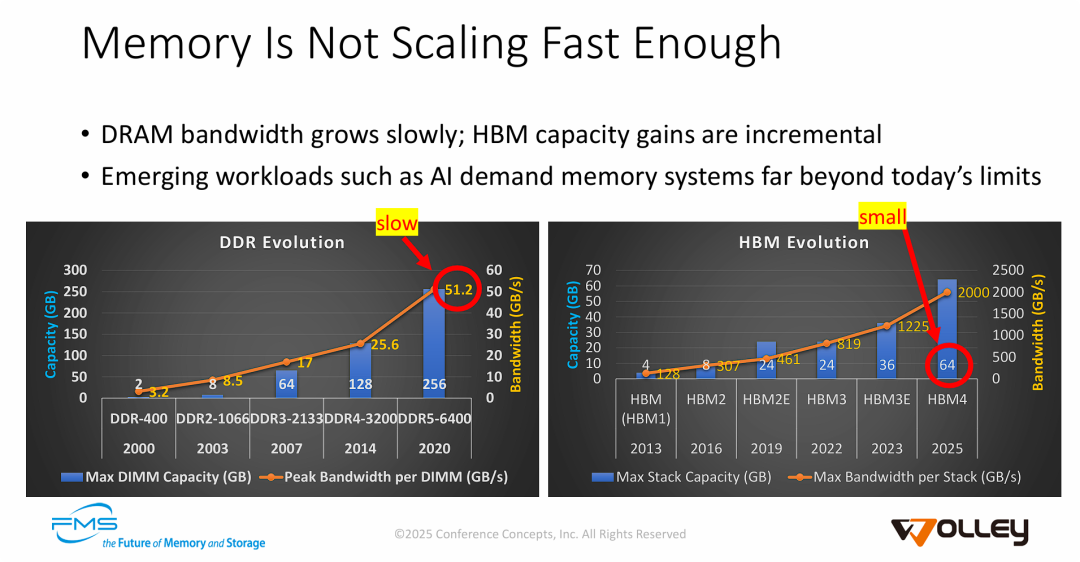
PPT 的核心目的是揭示现有内存技术发展与 AI 计算需求之间的供需鸿沟,具体概括为以下三点:
- DDR 内存面临“带宽墙”: 虽然 DDR 内存的容量(Capacity)在不断提升(单条可达 256GB),但其带宽(Bandwidth)增长过于缓慢。DDR5 的 51.2 GB/s 峰值带宽在面对海量数据吞吐的 AI 训练和推理时,显得力不从心 ("slow")。
- HBM 内存面临“容量墙”: HBM 虽然提供了极高的带宽(HBM4 可达 2000 GB/s),解决了速度问题,但其单堆栈容量增长受限。即便到 2025 年的 HBM4,单堆栈容量仅为 64GB,这对于参数量呈指数级增长的 AI 大模型来说,容量显得过小 ("small"),限制了模型的规模和效率。
- 迫切需要新的架构: 现有的存储器层次结构(DDR 和 HBM)各自存在明显的短板(一个慢,一个小),无法满足 AI 等新兴工作负载对大容量且高带宽内存系统的双重需求。这暗示了行业需要如 CXL (Compute Express Link) 内存扩展、存内计算 (PIM) 或 Wolley 正在开发的存储级内存解决方案来填补这一空白。
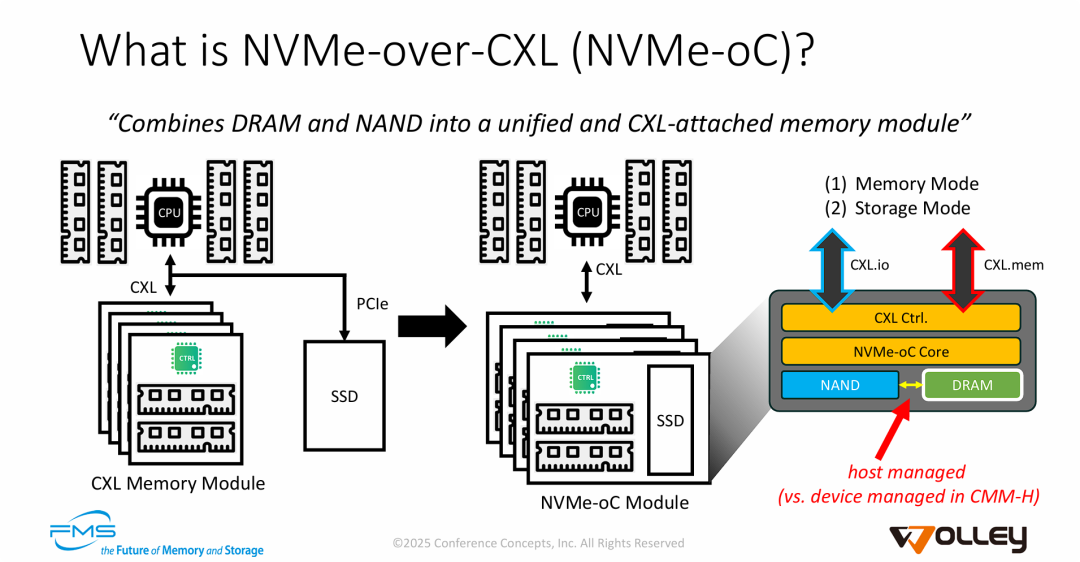
图片的核心目的是推介 NVMe-oC 这种新型混合存储架构,其主要技术观点如下:
- 物理融合 (Convergence): NVMe-oC 将传统的易失性内存 (DRAM) 和非易失性存储 (NAND SSD) 物理合并到了同一个 CXL 插槽的设备中。这消除了对独立 PCIe SSD 插槽的需求,简化了服务器物理架构(从作图的结构演进到中间图示架构)。
- 协议复用 (Protocol Efficiency): 该架构充分利用了 CXL 协议的多样性。它同时运行 CXL.mem(用于 DRAM 的极低延迟访问)和 CXL.io(用于 NAND 的存储类访问和设备管理),在同一物理链路实现了内存和存储的双重功能。
- 主机主导的数据分层 (Host-Managed Tiering): 这是该技术与传统混合设备最大的区别(后文将展开与与三星CMM-H 混合设备方案的比较)。Wolley 强调这是一种 "Host Managed" 的方案。与 CMM-H(设备自动管理 DRAM 作为 NAND 的缓存,对主机透明)不同,NVMe-oC 让主机(OS 或应用程序)明确感知到 DRAM 和 NAND 的存在,并由主机软件智能决策哪些热数据放入 DRAM,哪些冷数据留在 NAND。这提供了更高的灵活性和针对特定工作负载优化的能力。
一句话总结: NVMe-oC 是一种利用 CXL 接口将 DRAM 和 NAND 融合的单卡解决方案,它允许主机通过 CXL.mem 和 CXL.io 协议分别直接管理内存和存储资源,实现软件定义的高效数据分层。
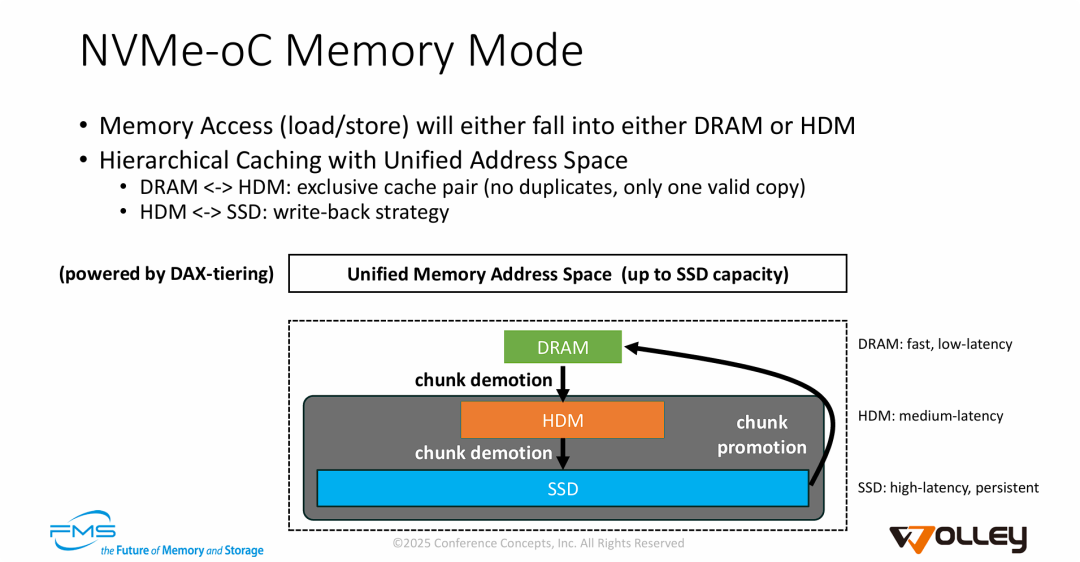
图片阐述了 NVMe-oC 模组如何实现“大容量内存” 的核心机制,主要观点如下:
- 构建三级混合内存架构: 系统构建了一个从 Host DRAM (极速) 到 Device DRAM/HDM (高速) 再到 Device SSD (容量) 的三级存储金字塔。通过这种架构,系统能够以接近内存的速度运行,同时享受 SSD 级别的海量容量(CXL的时延应该无法达到接近DIMM的访问速度)。
- 软件定义的分层策略 (DAX-tiering): 利用 DAX-tiering 技术,系统实现了一个统一的内存地址空间。这种分层对应用程序是透明的,应用看到的只是一个巨大的内存池(大小等于 SSD 容量),而不需要修改代码来管理复杂的存储读写。
- 智能的数据冷热调度:
- 独占式缓存 (Exclusive Caching): 在 Host DRAM 和 Device DRAM 之间通过独占策略避免数据冗余,从而扩大了有效的高速缓存容量。
- 动态升降级 (Promotion/Demotion): 热数据通过 "Promotion" 驻留在 DRAM,冷数据通过 "Demotion" 下沉至 SSD。这种机制确保了在扩大内存容量的同时,尽可能维持高性能的访问体验。
一句话总结: NVMe-oC 的内存模式通过将 SSD 虚拟化为内存,并利用板载 CXL DRAM (HDM) 和主机 DRAM 作为两级缓存,构建了一个容量巨大且性能分层的统一内存空间。
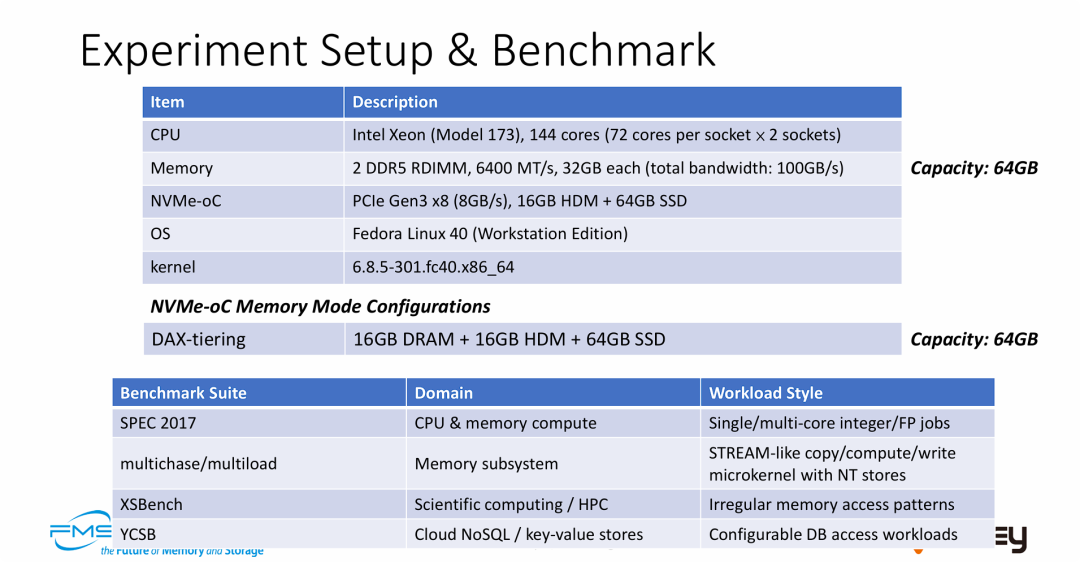
图片的主要目的是确立实验的可信度和测试范围,为后续展示性能数据做铺垫。核心信息如下:
- 明确的异构分层实验环境: 实验构建了一个包含 主机 DDR5 (极快)、CXL HDM (中速) 和 NVMe SSD (容量层) 的三级存储系统。值得注意的是,实验环境中的 NVMe-oC 设备使用的是 PCIe Gen3 x8 接口 (8GB/s),这意味着其理论带宽仅为系统主内存 (100GB/s) 的不到十分之一,这对分层算法的效率提出了极大挑战。
- 验证 "SSD 即内存" 的容量逻辑: 配置显示,尽管物理上使用了主机 DRAM 和设备 HDM,但系统最终呈现的可用内存容量 (64GB) 与 SSD 大小一致。这实际验证了 NVMe-oC 将 SSD 转化为系统可用内存空间的能力。
- 多维度的负载评估: 测试套件的选择非常全面,涵盖了从底层理论带宽 (multichase)、标准计算性能 (SPEC 2017),到延迟敏感型 HPC (XSBench) 和吞吐敏感型数据库 (YCSB) 的各种场景。这表明 Wolley 意在证明其 NVMe-oC 方案不仅能跑分,还能适应多种真实的复杂业务需求。
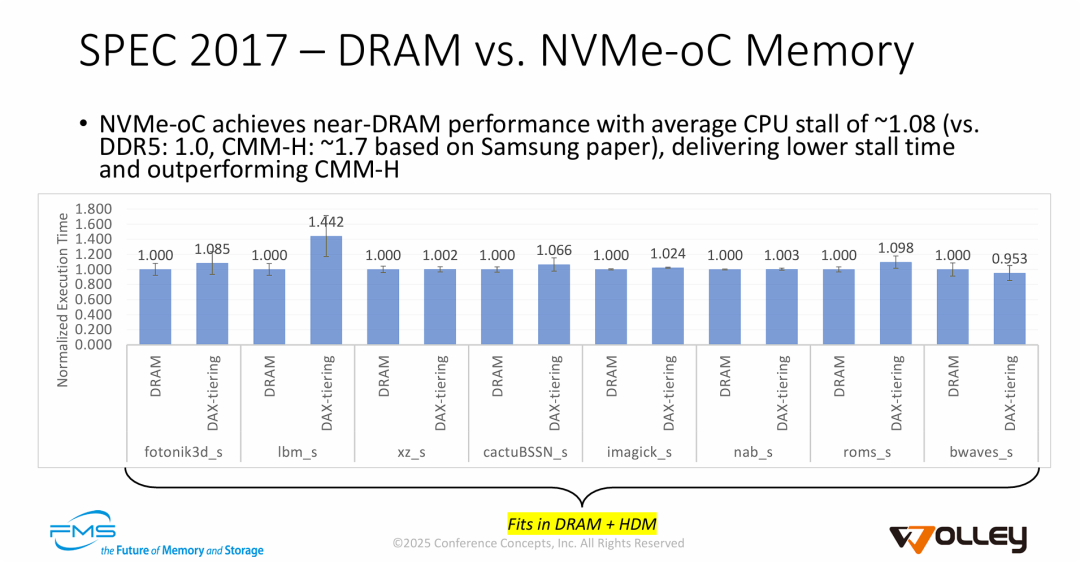
图片通过实测数据论证了 NVMe-oC 架构在“最佳情况”(数据在高速层)下的高效率,主要观点如下:
- 缓存层性能媲美原生内存: 在数据未溢出到 SSD 的情况下(即工作集小于 32GB),NVMe-oC 的平均性能损耗仅为 8% (1.08x)。这证明了通过 CXL 扩展内存并配合主机端软件分层(Host Managed),可以提供极高的响应速度。从上图的数据来看,主机侧软件分层管理并没有带来太大的CPU损耗。
- 显著优于 CMM-H竞品: PPT 强调其 1.08x 的表现远好于 CMM-H 方案的 1.7x。这暗示了 Wolley 采用的 "Host-Managed Tiering" (主机管理分层) 策略比 CMM-H 通常采用的 "Device-Managed Caching" (设备硬件管理缓存) 更加智能和高效,能够更精准地减少 CPU 等待时间。
- 技术可行性验证: 图表证明了操作系统的 DAX-tiering 机制是成熟可用的。即便在跨越 PCIe/CXL 链路的情况下,系统依然能保持流畅运行,除个别带宽敏感型应用(如
lbm_s)外,几乎没有感知的性能下降。
一句话总结: 在工作负载能被高速缓存(主机内存+CXL内存)容纳的场景下,NVMe-oC 方案能提供几乎等同于本地 DRAM 的性能,且效率显著优于传统的硬件管理混合内存模组。
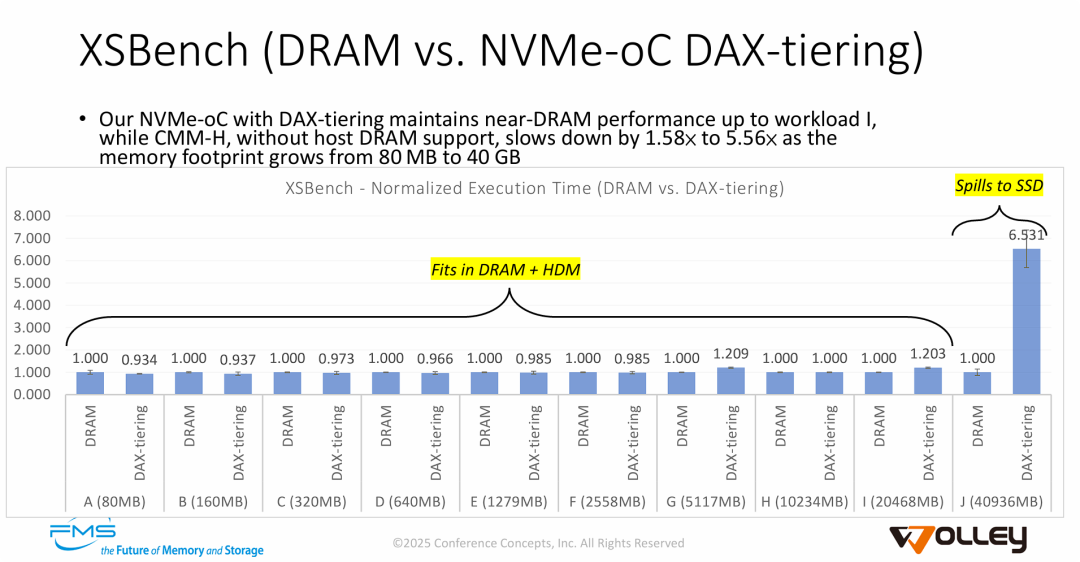
图片通过 XSBench 压力测试,清晰地界定了 NVMe-oC 方案的性能边界和适用场景:
- 验证了分层架构的有效性 (Tiering Efficiency): 在数据量未超过高速缓存总容量(主机 DRAM + CXL HDM)时,NVMe-oC 能够提供极为出色的性能,大多数情况下与原生 DRAM 相当(1.0x 左右),甚至在某些小负载下略有优势。这证明了其“主机管理分层”策略能够有效利用 DRAM 掩盖底层介质的延迟。
- 揭示了“性能悬崖” (Performance Cliff): 当工作负载 (40GB) 超过高速层容量 (32GB) 并溢出到 SSD 时,性能出现断崖式下跌 (6.5x 延迟)。这诚实地反映了当前 NAND Flash 与 DRAM 之间的物理速度鸿沟,也提示用户该技术最适合工作集 (Working Set) 大小在高速层容量范围内,但偶尔需要大容量突发的应用场景。
- 相对于 CMM-H 的架构优势: 通过文字对比强调,传统的 CMM-H 方案由于不像 NVMe-oC 这样智能地利用主机 DRAM 进行分层,即使在内存占用较小的情况下(80MB起),性能就已经开始显著下降(1.58x 起步)。这突显了 Wolley 方案中 Host-Managed DRAM Caching (主机管理 DRAM 缓存) 的关键价值——在缓存未满时,它能提供真正的内存级速度,而非仅仅是 CXL 设备速度。
一句话总结: XSBench 测试表明,只要工作负载能被 DRAM/HDM 高速层容纳,NVMe-oC 就能提供媲美纯内存的性能,显著优于传统 CMM-H;但一旦发生 SSD 溢出,系统将面临物理介质限制带来的显著性能回落。
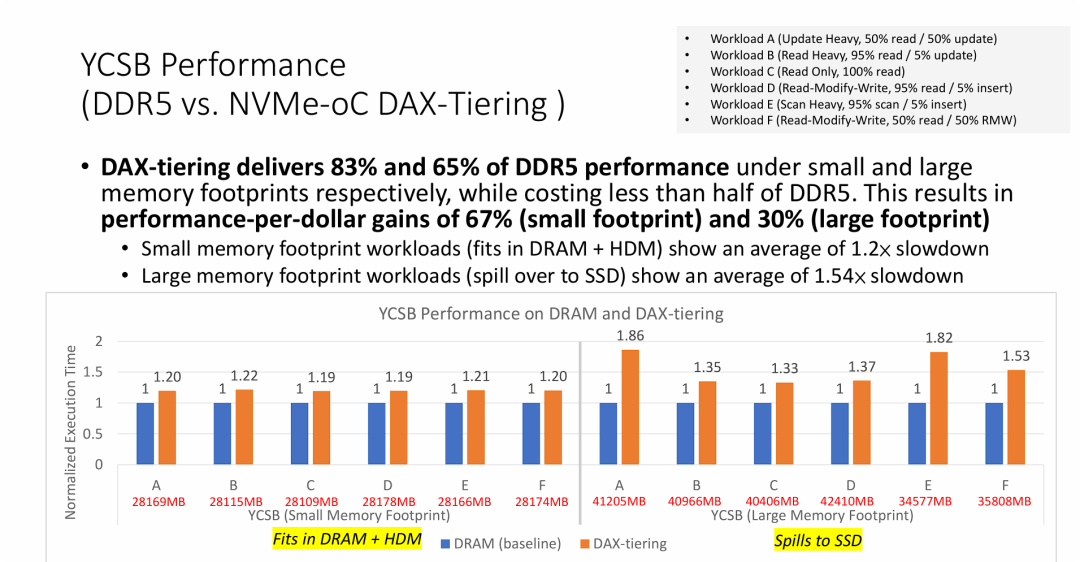
图片是整个技术展示的商业价值总结,它不再纠结于“是否比 DRAM 快”,而是强调“是否比 DRAM 更划算”,主要观点如下:
- 极具吸引力的性价比 (ROI): 这是该方案最强的卖点。虽然性能略有下降(保留 65%-83% 的性能),但由于利用了廉价的 NAND Flash 替代昂贵的 DDR5,硬件成本降低了一半以上。对于云服务商或大规模数据库部署来说,这意味着用 30% 到 67% 更少的钱完成同样的计算任务。
- 数据库场景下的“软着陆”: 与上一张 XSBench (HPC) 图表中出现的 6.5x 性能断崖不同,在 YCSB (NoSQL) 测试中,即使数据溢出到 SSD,平均性能下降也仅为 1.54x。这证明了数据库常见的 Zipfian(长尾)访问模式非常适合 NVMe-oC 的分层缓存算法——热数据能被有效保留在 DRAM/HDM 中,从而掩盖了 SSD 的延迟。
- 读写敏感度差异: 实验数据显示,NVMe-oC 架构在读多写少的场景下(如内容分发、缓存层)表现最佳(接近 1.3x 损耗);而在写密集或大范围扫描场景下(如日志记录、分析),由于受到 SSD 写入速度和带宽的物理限制,性能损耗会扩大到 1.8x 左右。
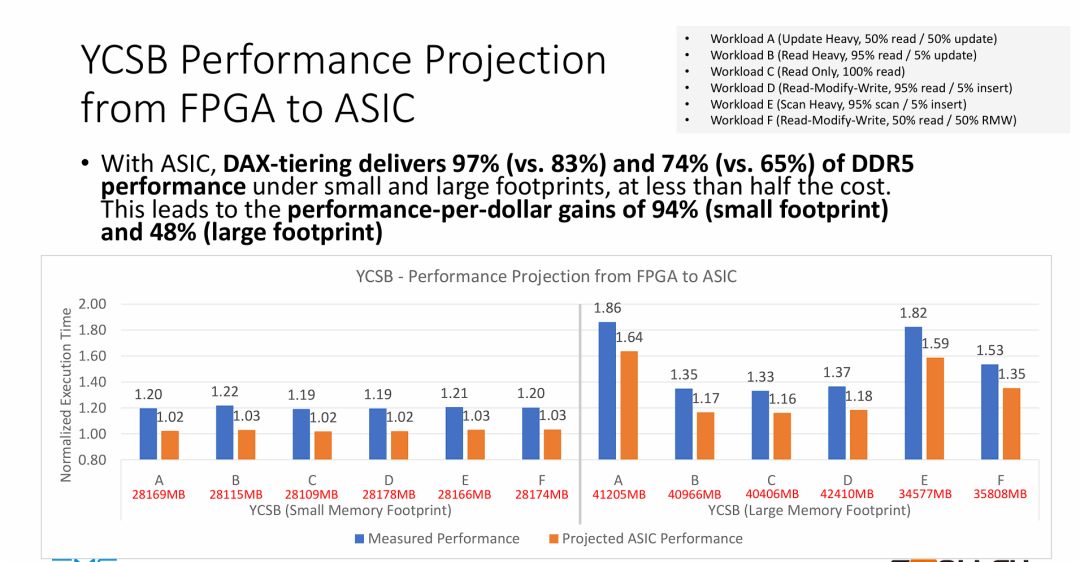
图片是整个演示的“强心剂”,旨在消除客户对前几张 PPT 中性能损耗(如 20%)的顾虑,主要观点如下:
- 消除原型机瓶颈: 它明确指出此前测试中观察到的约 20% 的性能开销主要是由于 FPGA 原型机的硬件限制造成的。一旦量产为 ASIC 芯片,这种“非介质层面的开销”将几乎消失。
- 实现“近乎零损耗”的缓存体验: 在 ASIC 阶段,只要数据能被高速层(DRAM/HDM)容纳,系统性能将达到原生 DDR5 的 97%。这对于用户来说意味着:你可以用不到一半的价格买到几乎一样快的内存系统。
- 极致的商业价值 (ROI): Wolley 最终强调的是惊人的性价比。通过 ASIC 优化,小内存负载下的性价比优势达到了 94%(几乎是花一份钱办两份事)。这为 NVMe-oC 技术在大规模云数据中心和企业级存储中的落地提供了极具说服力的商业理由。
FPGA和ASIC在处理CXL协议时的对比
对比项 | FPGA 特性 | ASIC 特性 | 对性能的影响 |
|---|---|---|---|
1. 时钟频率 (Clock Frequency) | 局限性: 本质上是通用原型验证芯片,内部逻辑块和互连线路可编程,信号路径长且复杂,限制最高工作频率。处理CXL时通常运行在 250MHz - 500MHz 左右。 | 优势: 为特定功能定制,电路连接物理固化,无冗余。内部逻辑可轻松运行在 1GHz、2GHz 甚至更高 的频率。 | 芯片主频从500MHz提升到1.5GHz,处理逻辑的延迟(Latency)直接减少2/3,是“20%额外开销”消失的主要原因之一。 |
2. 逻辑门与布线延迟 (Logic & Routing Latency) | “迷宫”式布线: 信号需经过一系列可编程开关矩阵,路径绕行,每一跳增加纳秒级延迟。信号穿过芯片内部可能需要几十纳秒。 | “高速公路”式布线: 电路布线是光刻机直接印在硅片上的最短物理路径,无绕路。信号穿过芯片内部可能被压缩到几纳秒。 | CXL对延迟极度敏感。几十纳秒的节省对于内存访问这种纳秒级操作至关重要。 |
3. 硬核 PHY 与控制器的优化 (Hardened PHY & Controller) | 通用/软核实现: CXL接口(PHY层)通常是通用的,或通过“软核”(Soft IP)逻辑实现,引入额外转换开销和抖动。 | 专用硬核实现: 集成经过物理验证的、专用的 硬核 (Hard IP) CXL控制器和PHY。这些硬核电路经过极致优化。 | 所谓的“非介质层面的开销”,很大一部分是CXL协议栈的处理时间。ASIC通过硬化电路将这一处理时间压缩到了物理极限。 |
从这一页片子来看,后续要集成 ASIC 专用芯片,意指增强盘内主控的计算能力,Wolley 作为主控厂商在这个材料里的立场,应该是要突出自家主控在 NVMe Over CXL 上的特性能力,相反整篇材料的重点放在盘内DRAM,主机分层管理上,后者的能力应该不是SSD主控的战场。

对比图是 Wolley 整个演示的“杀手锏”,旨在证明其 Host-Managed Tiering (主机管理分层) 架构在绝大多数实际应用场景中优于传统的 Device-Managed (设备管理) 混合内存方案:
- 碾压级的计算性能优势: 在 SPEC CPU2017 测试中,8.4% 的损耗 vs. 70% 的损耗,这一数据极具冲击力。它证明了在通用计算场景下,Wolley 的方案(利用主机 DRAM 掩盖 CXL 延迟)比单纯依赖 CXL 扩展内存的 CMM-H 方案要快得多。哪怕 Wolley 使用的板载内存频率更低 (DDR4-2000 vs 2666),架构优势依然使其完胜。
- “近乎原生”的体验 vs. “始终有感”的延迟: 在 XSBench 测试的小负载阶段,NVMe-oC 保持 1.0x (原生速度),而 CMM-H 起步就是 1.58x (显著变慢)。这强化了 Wolley 的核心价值主张:只要你的工作负载能被高速缓存层容纳,你就能获得仿佛在使用本地内存一样的体验,而无需忍受 CXL 设备固有的物理延迟。
- 诚实的边界展示: 图表也客观展示了在极端负载(40GB 溢出)下,NVMe-oC 的性能下降 (6.5x) 会略微超过 CMM-H (5.56x)。这表明 Wolley 的方案并非在所有极端情况下都是完美的,但在通常的“缓存命中”区间内,它提供了无与伦比的性能收益。
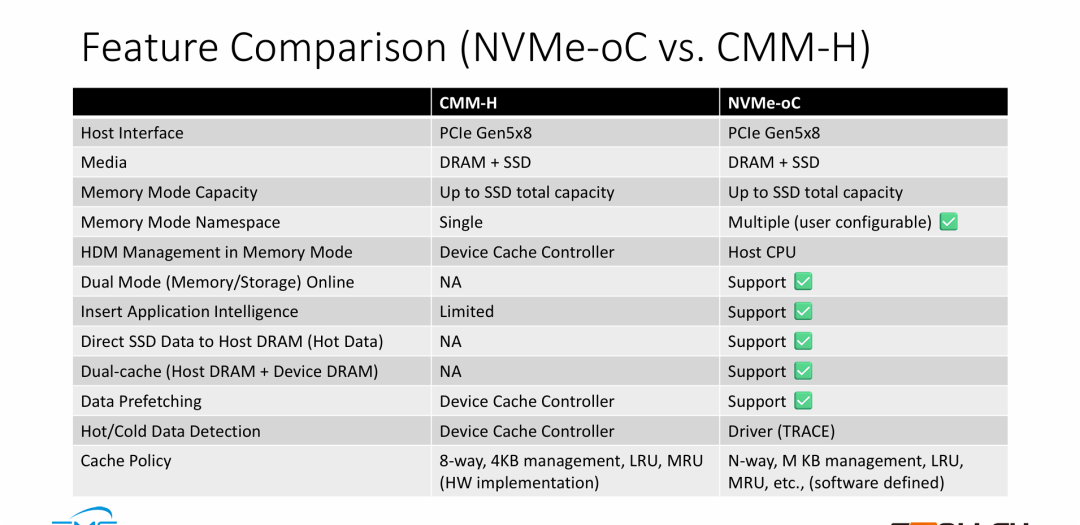
对比表是对前面所有性能数据背后的技术原理总结,它清晰地界定了 NVMe-oC 战胜传统硬件主导型 CMM-H 的三个核心维度:
- “软件定义”战胜“硬件固化”: CMM-H 采用硬件控制器管理缓存,策略固定(如 4KB 粒度、LRU 算法)。而 NVMe-oC 将管理权移交给主机软件(Driver/CPU),实现了软件定义内存 (SDM)。这使得用户可以根据具体业务(如数据库 vs AI 训练)自定义缓存粒度、算法和策略,极大提升了灵活性。
- 独有的“三层存储架构”: 表格中 "Dual-cache" 和 "Direct SSD Data to Host DRAM" 两项的差异,揭示了 NVMe-oC 性能更好的根本原因:CMM-H 只是在设备内部做缓存(SSD -> Device DRAM),而 NVMe-oC 构建了 SSD -> Device DRAM -> Host DRAM 的完整数据链路。利用 Host DRAM 做一级缓存,彻底掩盖了 CXL 链路的延迟。
- 真正的多功能融合: NVMe-oC 支持 "Dual Mode Online",即在同一时刻,它既可以被系统识别为扩展内存,也可以被识别为 NVMe SSD。这种物理融合为数据中心提供了极大的部署灵活性,这是单一功能的 CMM-H 所不具备的。
Note
这一页对CMM-H特性支持的对比有失偏颇,因为从物理架构上来看 CMM-H也是 DRAM+SSD的混合架构,上图强调盘内 Memory 控制的责任界面,三星的CMM-H设计是盘内不含加速器的,如果没有计算能力,主控管理盘内Memory 也没有太大用武之地。
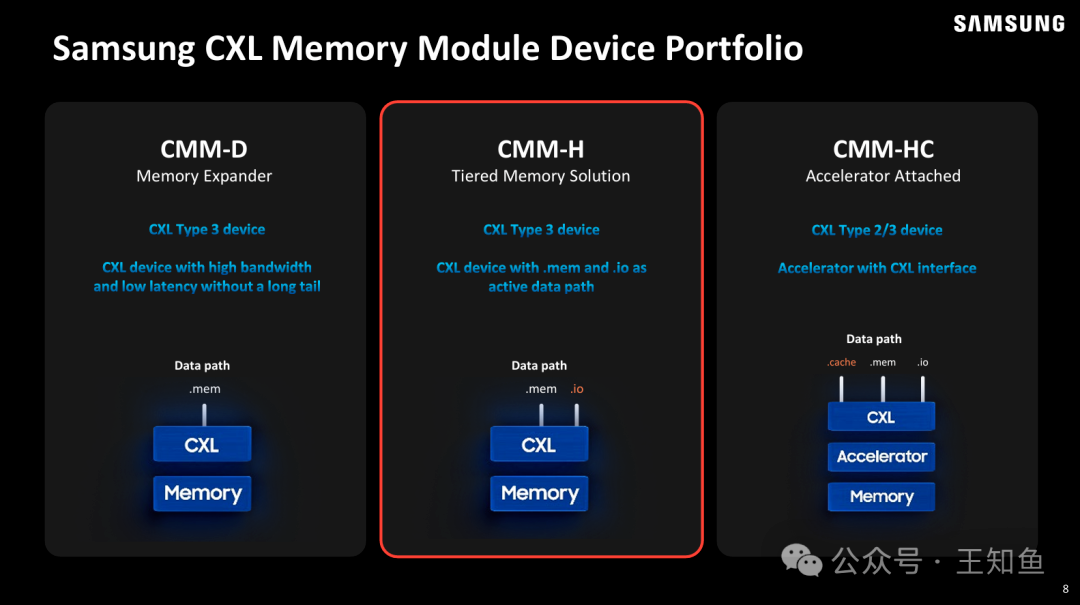

总结页将 Wolley 的技术叙事收束为三个关键的商业卖点:
- 极具竞争力的性价比 (ROI): 这是该技术最大的亮点。在处理大规模数据时,相比纯 DRAM 方案或传统的 CMM-H 方案,NVMe-oC 能带来 30%~90% 的性价比提升。它用廉价的 NAND 换取了海量容量,同时通过架构创新将性能损失降到最低。
- 独创的“主机参与”架构: 再次强调了与竞品(CMM-H)的本质区别:Wolley 不依赖设备端的黑盒控制器,而是利用主机 CPU 联合调度 Host DRAM + Device DRAM + NAND 三层资源。这种“主机管理的缓存智能”是其在性能和灵活性上胜出的核心原因。
- 无缝的部署体验: 强调 "No code changes",消除了客户采用新技术的最大顾虑(兼容性问题)。它承诺即插即用,让现有的数据密集型应用直接享受到内存扩容的红利。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- NVMe-oC的“主机管理分层”策略在实际大规模部署中,如何平衡性能、管理复杂度和资源利用率?其与现有内存管理方案的集成挑战有哪些?
- ASIC的量产将显著提升NVMe-oC的性能,但其高昂的研发和制造成本,将如何影响该技术在不同规模数据中心中的普及速度和定价策略?
- 除了AI工作负载,NVMe-oC还可能在哪些新兴应用场景中发挥独特优势?其与PIM、存储级内存等其他前沿技术将如何协同或竞争?
原文标题:System Test Results with NVMe-over-CXL (NVMe-oC) Memory Mode[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #CXL内存扩展
---【本文完】---

丰子恺-护生画集-诱杀
👇阅读原文,搜索🔍更多历史文章。
- https://files.futurememorystorage.com/proceedings/2025/20250805_TEST-101-1_Shung.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号