SMI:为AI加速,SSD主控数据传输升级(FPU)

SMI:为AI加速,SSD主控数据传输升级(FPU)

数据存储前沿技术
发布于 2026-03-09 17:45:36
发布于 2026-03-09 17:45:36
阅读收获
- 洞悉AI趋势下SSD主控从“单体”走向“DPU+FPU”分布式架构的核心驱动力与技术路径。
- 掌握ONFI 5.1 SCA协议与FPU子通道技术如何协同解决高速NAND的性能与信号完整性瓶颈。
- 识别Chiplet异构集成在下一代智能存储控制器商业落地中的关键作用与市场机遇。
全文概览
AI大模型时代,数据洪流对存储发起了前所未有的挑战,传统SSD架构的性能瓶颈日益凸显。当NAND接口速度迈向DDR4800,我们该如何解决指令拥塞与信号衰减的双重难题?存储控制器是选择继续修补,还是走向彻底的“分布式”革命?本文将深入剖析以ONFI 5.1 SCA协议和FPU(闪存处理单元)为基石的新一代分布式主控架构,揭示其如何通过软硬件解耦与架构创新,为AI工作负载构建真正的无阻塞数据通路。
👉 划线高亮 观点批注
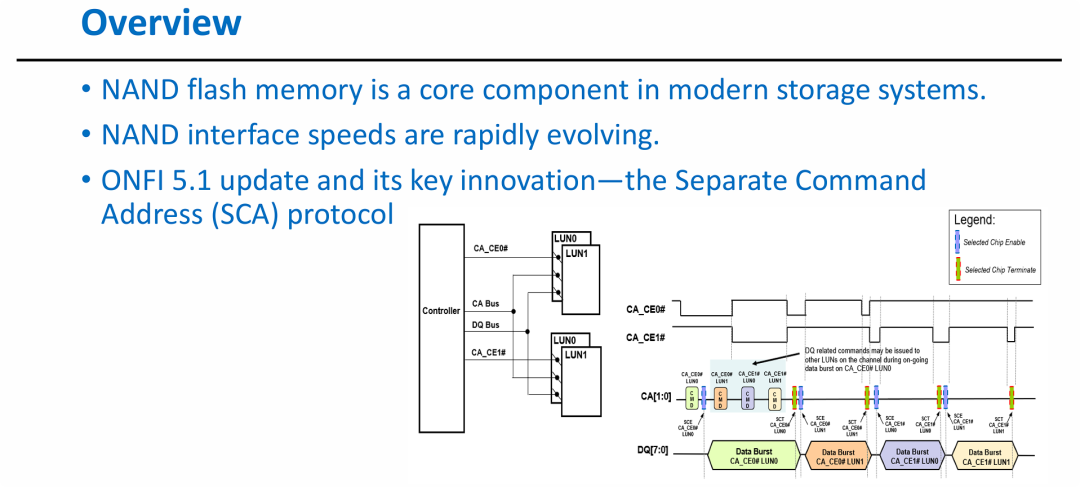
图片的核心观点是介绍 ONFI 5.1 标准中引入的 SCA(独立指令地址)协议 如何优化 NAND 性能。其关键信息包括:
- 指令与数据解耦: 通过引入 SCA 协议,系统将指令/地址总线(CA Bus)与数据总线(DQ Bus)的操作进一步分离。
- 消除总线等待: 传统的 NAND 操作中,数据传输往往会阻塞指令的下发。SCA 协议允许在某个 LUN 正在通过 DQ 总线传输数据时,控制器同时在 CA 总线上为其他 LUN 准备指令。
- 提升并发效率: 这种并行机制显著提高了多 LUN 环境下的总线利用率,降低了延迟,是应对 NAND 接口速度不断提升(追求更高 IOPS)的关键技术演进。
参考阅读
- 主要内容:该文章详细介绍了分离命令地址(SCA)协议,与传统SSD控制器协议相比,SCA协议通过分离数据总线和命令总线,显著提高了数据传输效率。在SCA协议中,命令和地址是分开传输的,这使得在数据总线中可以插入更多指令,从而提升小文件(4K)和大文件(16K)场景下的读性能。特别是在小文件场景中,SCA协议通过分离命令和数据管道,显著提升了IOPS性能,比传统协议高出约66%。此外,SCA协议在大文件场景中也有10-20%的性能提升
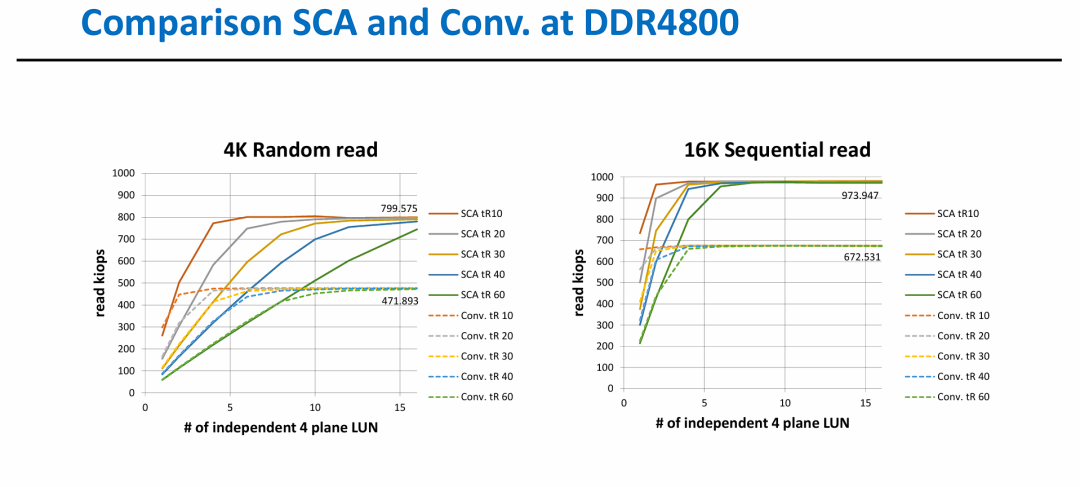
图表通过数据量化证明了 SCA 协议在高速接口(DDR4800)下的压倒性优势:
- 突破性能瓶颈: 传统协议由于指令和数据共享通道,在高并发(多 LUN)和高速接口下会由于总线冲突迅速达到性能天花板(4K 随机读约 471 KIOPS,16K 顺序读约 672 KIOPS)。
- 极致扩展性: SCA 协议通过指令与数据流的分离,允许性能随 LUN 数量增加而持续增长,最高可提升约 60-70% 的 IOPS 表现(4K 随机读提升至约 800 KIOPS)。
- 低延迟依赖性: 无论 NAND 本身的 tR 延迟如何,SCA 都能通过更高效的总线调度提升整体系统的吞吐量,这对于未来高速 NVMe 固态硬盘的设计至关重要。
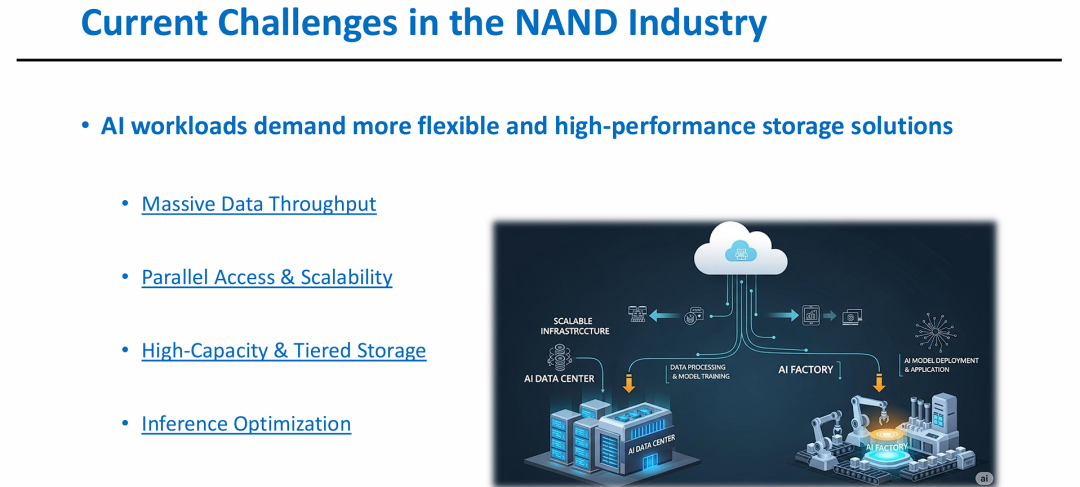
图片的核心观点是:AI 革命正在重塑 NAND 存储的设计标准。
- 从通用到专用:传统的存储设计已难以满足 AI 对超高吞吐量和并行性的严苛要求。
- 端到端的需求:从数据中心的大规模模型训练到工厂端的边缘推理应用,每一个环节都需要针对性的存储优化(如前几张图提到的 ONFI 5.1/SCA 协议正是为了解决这些瓶颈)。
- 系统级协同:存储不再是独立的组件,而是需要与 AI 基础设施(可扩展架构、模型训练流程)深度整合,以实现效率最大化。
这张图片为之前讨论的 SCA 协议提供了背景支撑——即高性能协议的演进正是为了应对此处提到的“AI 工作负载”挑战。

图片提炼了 NAND 闪存从组件级到系统级必须解决的 三大技术屏障:
- 性能提升的急迫性:在 AI 等高吞吐场景下,传统的读写延迟已成为整个系统的拖累。
- 信号完整性的挑战:随着接口频率不断推向极限,如何在高频干扰下维持稳定的数据传输(Signal Quality)是硬件设计的难点。
- 效率与功耗的平衡:在追求高性能的同时,能耗比(Performance per Watt)成为评价存储方案优劣的关键指标,特别是在大规模部署的 AI 数据中心内。
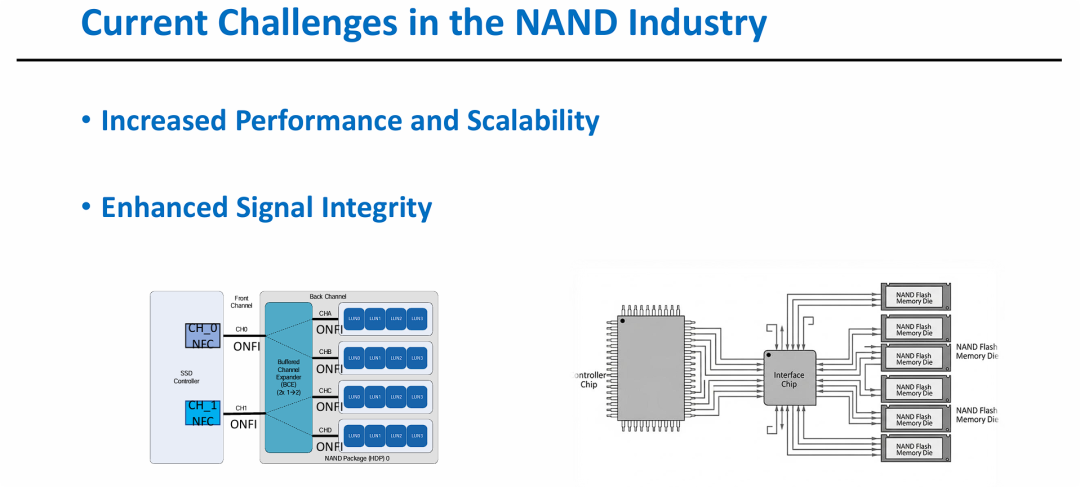
图片展示了基于缓冲通道扩展器 (BCE) 的新型存储架构,旨在解决上一张 PPT 中提到的痛点:
- 性能与扩展性的结合:通过 BCE 芯片实现通道扩展,使单通道能支持更多 LUN,直接服务于 AI 工作负载所需的大容量和高吞吐。
- 信号完整性的硬件保障:引入专用的接口芯片(Interface Chip)作为中继,解决了高速 DDR 接口下的信号劣化问题,保证了数据传输的可靠性。
- 系统级优化:这种架构是实现之前提到的 SCA 协议高效运行的物理基础,通过软硬结合提升 NAND 系统的整体效能。

图片提炼了下一代存储控制器的技术演进路线图:
- 硬件维度的增强:通过“并行性与通道扩展”解决物理吞吐能力的上限。
- 软件与算法的进化:通过“智能化”和“QoS 管理”提升复杂负载下的运行效率。
- 架构维度的颠覆:通过“存储内计算 (CIS)”打破传统的存算分离瓶颈。
这些创新方向共同构成了解决之前提到的性能瓶颈、能耗及 AI 工作负载挑战的控制层解决方案。
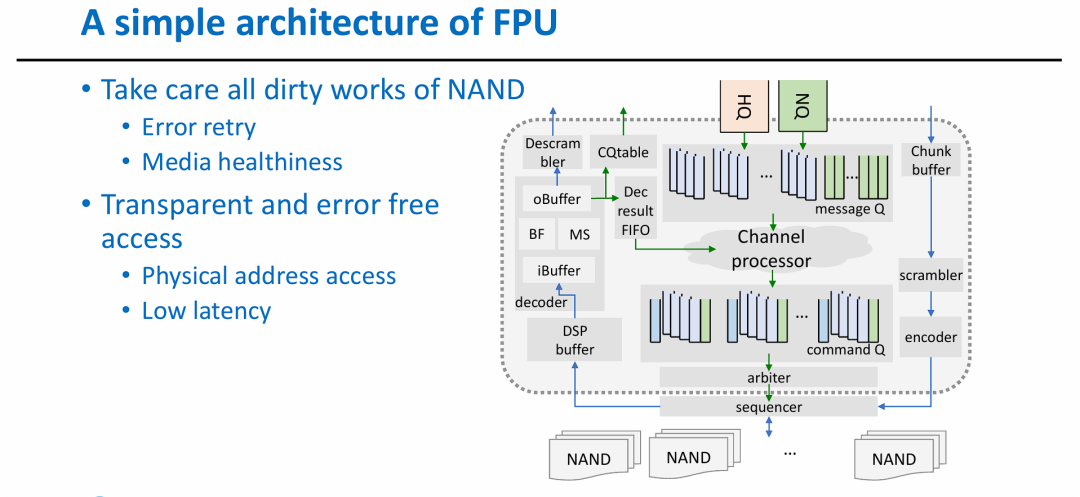
图片展示了存储控制器中 FPU (Flash Processing Unit) 的精细化设计方案,其核心目标是实现“存算分离”思想在闪存管理层的落地:
- 硬件卸载底层负担:将错误重试、健康管理等复杂的底层“脏活”从主 CPU 卸载到专用的 FPU 硬件中处理。
- 提升访问效率:通过高度并行的队列管理(HQ/NQ)和专用的编码/解码加速器,实现低延迟、高可靠的物理地址访问。
- 标准化接口:FPU 为上层提供了一个“无错”且“透明”的访问层,屏蔽了不同 NAND 颗粒之间的物理差异,这是实现之前提到的“智能化控制器”和“高性能并发”的重要基石。

图片展示了存储控制器从“单体式”向“分布式”演进的关键趋势。其核心观点包括:
- 功能解耦:将复杂的软件协议处理(DPU)与底层的闪存物理管理(FPU)分离,这正是前几张幻灯片提到的“计算存储”和“FPU 架构”的具体落地。
- 异构集成:这种分布式设计允许开发者针对不同的应用场景(如 AI 推理、企业级存储、GPU 加速)选择最合适的 FPU 插件。
- 优化系统 TCO:通过异构制程支持、更好的散热管理和模块化扩展,分布式控制器能显著提升大规模存储系统的效率和可靠性,应对 AI 时代的海量数据挑战。
值得注意的是,这里的 FPU 并不是独立类DPU的处理单元,而是 SSD 主控中的固件单元,做了特定场景能力的设计增强。
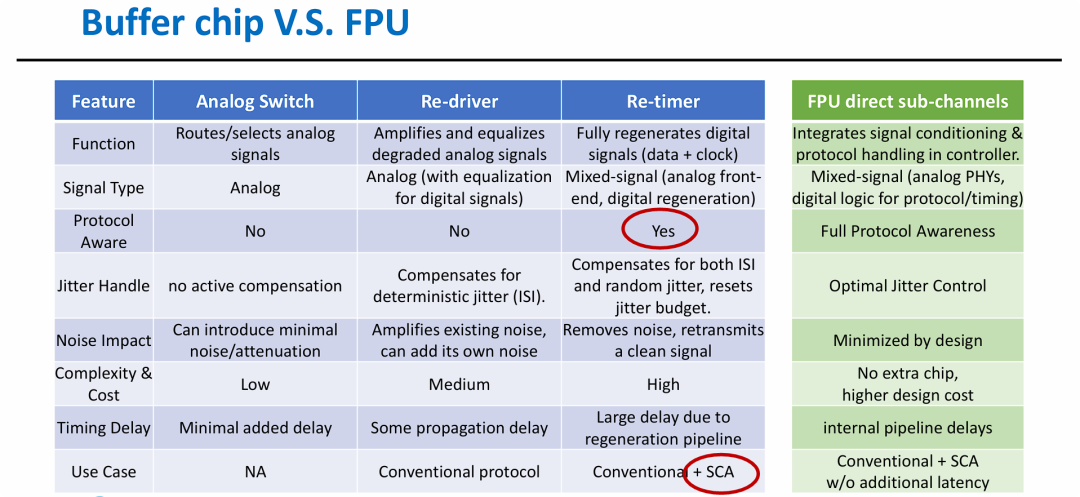
图片展示了为了适配高性能 SCA (Separate Command Address) 协议,硬件层级是如何从简单的模拟中继向深度协议集成演进的:
- 物理层升级的必然性: 随着速度提升至 DDR4800,传统的模拟开关和 Re-driver 已无法处理复杂的信号质量问题。
- Re-timer 的过渡地位: Re-timer 虽然支持 SCA 协议并能修复信号,但会带来较大的再生流水线延迟。
- FPU 的竞争优势: 相比于在 PCB 上增加额外的 Buffer 芯片,将 FPU 功能直接下放到子通道中,可以在维持最优信号质量的同时,实现全协议感知且无额外延迟。
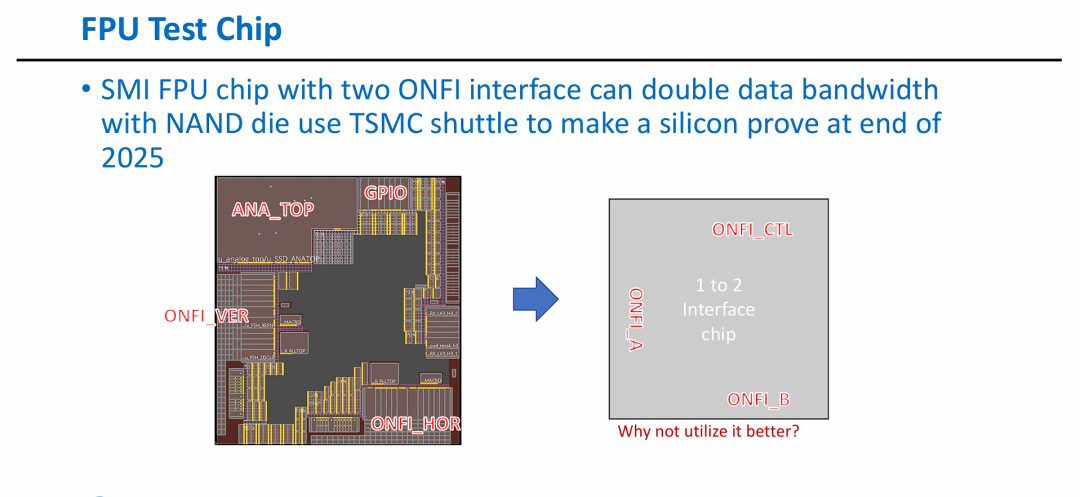
图片展示了 FPU 技术从理论架构向商用硬件落地的关键跨越:
- 带宽倍增的物理实现: 证实了通过单颗集成 FPU 功能的接口芯片,可以实现 1 对 2 的通道扩展,使单个控制器通道支持的 NAND 带宽直接翻倍。
- 明确的路线图: 指出了 2025 年底这一关键节点,标志着基于 FPU 的分布式控制器方案(如之前讨论的 DPU + FPU 组合)即将进入实际应用阶段。
- 高度集成的 SoC 设计: Layout 图展示了模拟与数字电路的紧密集成,支撑了之前 PPT 中提到的“FPU 直接子通道”在不增加延迟的情况下实现信号修复与协议感知的能力。

图片总结了 NAND 行业在 AI 大背景下的战略走向,将前几张 PPT 提到的碎片化技术统一到了行业生态层面:
- 硬件形态变革:Chiplet 将成为实现分布式控制器(DPU x FPU)物理落地的关键技术路径。
- 软件定义存储向 AI 定义存储转变:未来的存储不仅是数据的容器,更是具备自主管理能力的智能节点,能直接服务于从云到端的 AI 推理与训练。
- 生态融合:存储不再孤立发展,而是通过与 AI 框架(如 PyTorch, TensorFlow)和 AI 硬件(如 GPU, NPU)的深度打通,消除 I/O 瓶颈。
===
NAND 存储技术的最新演进逻辑:
- 协议层:引入 SCA 协议,解决 DDR4800 高速下的指令/数据拥塞。
- 物理层:通过 BCE 和 FPU 子通道 解决信号完整性与扩展性问题。
- 架构层:从单体控制器演进为 DPU + FPU 的分布式架构,并利用 Chiplet 实现异构集成。
- 落地层:SMI 的 FPU 测试芯片 计划于 2025 年底完成验证,标志着技术成熟。
===
未来存储的技术终局:主控不再是一个封闭的整体,而是一个由计算中枢(DPU)驱动、多个智能执行节点(FPU)支撑的分布式网络。 这种架构能够灵活适配从云端数据中心到边缘 AI 设备的各种高性能存储需求。
- DPU(计算单元/指挥官):负责“脑力活”。它处理高层逻辑,如 NVMe 协议、数据压缩、去重、FTL(闪存转换层)管理,甚至包括针对 AI 推理的近数据计算(Near Data Process)。
- FPU(执行单元/技术官):负责“底层活”。它直接管理闪存物理特性,提供“透明、无错”的访问接口,处理诸如错误重试(Error retry)和介质健康监测(Media healthiness)等繁琐任务。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 分布式主控将闪存管理(FPU)与上层协议处理(DPU)解耦,但这是否会增加固件开发和系统验证的复杂度?行业应如何平衡架构灵活性与标准化,以避免生态碎片化?
- FPU通过硬件卸载提升效率,但硬件的“固化”与AI算法的“多变”之间存在天然矛盾。在存内计算的演进中,我们应如何界定软硬件功能边界,以兼顾当前性能与未来算法的适应性?
- Chiplet技术被视为实现分布式主控的关键路径,但它也带来了多芯片集成的可靠性与散热挑战。对于需要7x24小时高可用运行的企业级SSD,这套新架构在设计和验证上会面临哪些新的“拦路虎”?
原文标题:A Distributed Controller for Flexible Applications in the AI Era[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #超高IO-SSD主控设计
---【本文完】---

丰子恺-护生画集-懺悔(忏悔)
👇阅读原文,搜索🔍更多历史文章。
- https://files.futurememorystorage.com/proceedings/2025/20250805_SSDT-102-1_Huang.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号