Intel:SPDK加速框架演进


全文概览
存储性能开发工具包(SPDK)作为一个用户空间的高性能存储软件集合,为解决这些问题提供了基础框架。然而,即使是SPDK,在处理复杂的IO操作时,也曾因多次调用硬件加速器和低效的缓冲区管理而遭遇瓶颈。本文将深入探讨SPDK加速框架的演进,特别是如何通过引入链式操作和优化缓冲区管理,结合IPU/DPU等硬件能力,实现存储工作流的显著提速和效率提升,为构建下一代高性能存储解决方案指明方向。
阅读收获
- 掌握 SPDK 加速框架如何通过计算卸载提升存储性能。
- 理解 IPU/DPU 等专用硬件如何与 SPDK 协同工作以优化数据流。
- 认识 SPDK 新引入的链式操作和缓冲区优化如何解决性能瓶颈。
- 了解 SPDK 在高性能存储领域最新的发展方向和技术亮点。
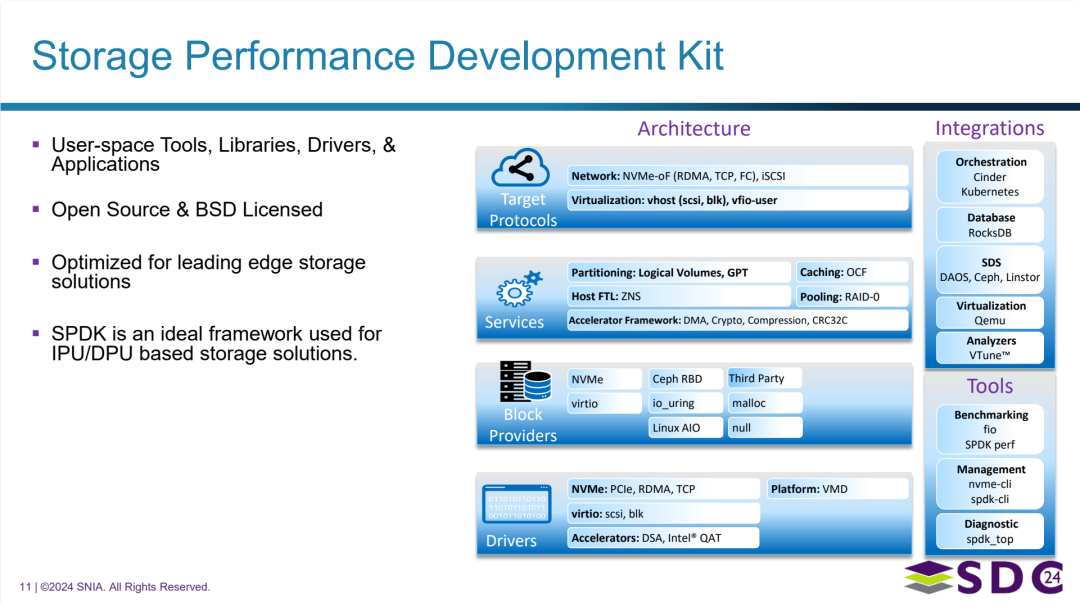
存储性能开发工具包
存储性能开发工具包
- 一套位于用户空间的软件集合,包含工具、库、驱动和应用程序。
- 开源项目,采用宽松的 BSD 许可。
- 专注于高性能存储,针对前沿存储解决方案进行了优化。
- 被明确指出是用于构建基于 IPU/DPU 的存储解决方案的理想框架。
核心架构与功能 (Architecture):
- 支持多种目标协议:
- 网络存储: 完全支持 NVMe over Fabrics (NVMe-oF),可通过 RDMA、TCP、光纤通道 (FC) 和 iSCSI 等多种网络传输。
- 虚拟化: 支持通过 vhost (SCSI 和块设备) 和 vfio-user 等机制,为虚拟机提供高性能存储访问。
- 提供丰富的存储服务: 具备实现逻辑卷、GPT 分区、缓存 (OCF)、主机侧闪存转换层 (Host FTL for ZNS SSDs) 和 RAID-0 池化等功能的能力。
- 利用硬件加速器: 提供框架支持利用 DMA、加密、压缩和 CRC32C 计算等硬件加速功能,提升性能。
- 支持多样的块设备来源 (Block Providers): 可以直接访问原生 NVMe 设备,支持 virtio、Linux AIO、Ceph RBD,利用 io_uring 接口,也包含用于测试的内存 (malloc) 和空设备 (null),并支持集成第三方块设备。
- 包含底层驱动: 提供用于访问 NVMe 设备(通过 PCIe, RDMA, TCP)、virtio 设备(SCSI, 块设备)的驱动,支持平台特性(如 VMD),以及用于利用 DSA 和英特尔® QAT 等加速器的驱动。
生态系统集成和配套工具 (Integrations & Tools):
- 广泛集成: 与主流的云编排平台 (Cinder, Kubernetes)、数据库 (RocksDB)、软件定义存储系统 (DAOS, Ceph, Linstor) 和虚拟化平台 (Qemu) 等集成。
- 提供开发和调试工具:
- 分析: 支持使用 VTune™ 进行性能分析。
- 工具链: 提供用于基准测试 (fio, SPDK perf)、管理 (nvme-cli, spdk-cli) 和诊断 (spdk_top) 的命令行工具。

SPDK 内置的计算加速框架及其工作原理
SPDK 内置的计算加速框架及其工作原理
核心概念:
- 加速框架: SPDK 包含一个成熟的、用于加速计算任务的框架。
- 目标: 将 SPDK 软件栈中那些对 CPU 资源消耗大、计算密集型的操作卸载到专用的硬件加速器上执行。
可卸载的计算操作类型:
- 加密与解密: 数据的加密和解密运算。
- 压缩与解压缩: 数据压缩和解压缩运算。
- CRC 计算: 循环冗余校验计算,常用于数据完整性检查。
- 其他: 框架支持扩展以卸载更多类型的计算任务。
支持的硬件加速器示例:
- 英特尔® I/O 加速技术 (IOAT) 引擎: 用于加速数据移动(DMA)和其他 I/O 相关操作。
- 英特尔® 数据流加速器 (DSA) 引擎: 专为高效数据移动和处理而设计。
- (结合之前信息,IPU/DPU 中集成的 QAT 等加速器也能通过此框架利用。)
软件插件模块和弹性机制:
- 插件设计: SPDK 加速框架采用软件插件的设计,不同的硬件加速器或软件实现可以作为插件集成进来。
- 回退路径 (Fallback): 这种插件机制提供了重要的“回退路径”。这意味着即使没有可用的硬件加速器,SPDK 也可以通过优化的软件实现来完成这些计算任务,确保功能可用性。
- 软件优化示例: ISA/L (Intel® Intelligent Storage Acceleration Library) 就是一个软件插件的例子,它提供了高度优化的 CRC32C 计算等功能,作为硬件加速不可用时的回退或补充。

推动 SPDK 加速框架演进的动因和目标
推动 SPDK 加速框架演进的动因和目标
变革的必要性 (当前方法的局限性):
- 效率低下: 在现有的 SPDK 加速框架中,每次对数据(IO 缓冲区)进行加速处理时,只能请求并执行单个独立的操作(例如,一次只能执行加密,另一次才能执行压缩)。
- 开销增加: 当需要对同一个数据缓冲区执行多个连续的加速操作(如先压缩后加密)时,必须分多次调用加速器。这会导致数据在内存和加速器之间多次往返,增加延迟和处理开销。
新的需求与硬件能力 (变革的驱动力):
- 硬件支持链式操作: 现代硬件加速器(特别是如英特尔 IPU 内置的旁路加密与压缩引擎 LCE)已经具备了在单次请求中对 IO 缓冲区执行“链式操作” 的新能力,即硬件可以按照预设顺序自动执行多个操作(例如,在硬件内部先完成压缩,然后直接将压缩后的数据进行加密,而无需将中间结果传回软件)。
- 软件调度灵活: 加速操作的调度可能发生在存储软件栈的不同层面。
- 利用 IPU/DPU 卸载: IPU/DPU 等平台提供了将这些计算密集型任务卸载到专用硬件(如 LCE)上的可能性。
需要进行的软件更改与验证:
- API 改进: 在 SPDK 加速框架的 API 中引入对“链式操作”的支持,使软件能够一次性向硬件请求执行一系列操作。
- 组件适配: 修改 SPDK 内部的相关组件,使其能够通过新的 API 来充分利用硬件加速器(如 LCE)支持的链式操作等新能力。
- 基于 IPU LCE 验证: 利用英特尔 IPU 的 LCE 硬件能力作为平台,验证新的支持链式操作的加速框架设计和实现是可行且高效的。
期望带来的收益:
- 显著提升系统性能: 通过减少数据往返和多次调用开销,链式操作可以大幅提高存储数据处理的整体性能。
- 降低内存带宽压力: 链式操作减少了数据在主机/IPU 内存和加速器之间的传输次数,从而减轻了内存带宽的瓶颈。
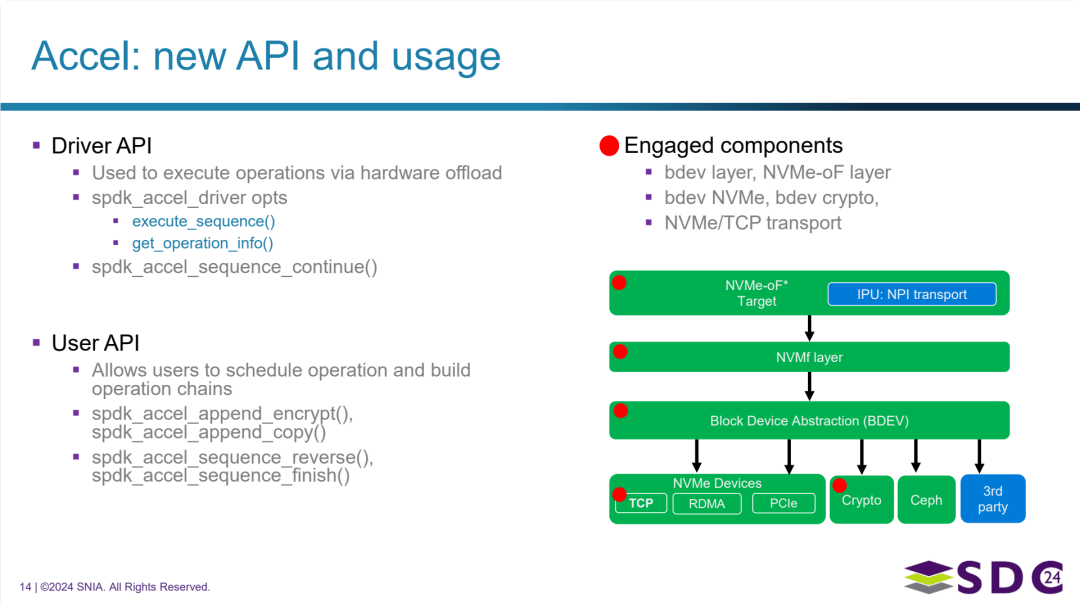
SPDK 加速框架为支持链式操作而引入的新 API 及相关组件
SPDK 加速框架为支持链式操作而引入的新 API 及相关组件
引入的新 API:
- 驱动 API (Driver API):
- 面向对象: 这是提供给底层硬件加速器驱动程序实现的接口。
- 目的: 用于通过硬件卸载来执行具体的加速操作序列(链)。
- 关键函数示例:
execute_sequence()是核心,用于提交一个操作链到硬件执行。其他如get_operation_info()用于查询信息,spdk_accel_sequence_continue()可能用于处理分阶段或续传的序列。
- 用户 API (User API):
- 面向对象: 这是提供给 SPDK 上层模块(如 bdev 层、NVMF 层)或构建存储应用的开发者调用的接口。
- 目的:允许用户构建复杂的操作链,将多个独立的加速操作(如加密、复制)组合成一个序列,然后提交给底层驱动 API 执行。
- 关键函数示例:
spdk_accel_append_encrypt()和spdk_accel_append_copy()用于向当前构建的操作链中添加特定的操作。spdk_accel_sequence_reverse()可能用于调整链中操作的顺序。spdk_accel_sequence_finish()用于结束链的构建并触发执行流程。
涉及的核心组件 (数据流路径):
在使用新的加速 API 进行数据处理时,数据会流经 SPDK 的多个关键层和组件:
- 块设备抽象层 (BDEV): 这是 SPDK 的基础层,向上提供统一的块设备接口给应用或上层模块,向下与各种底层块设备提供者对接。加速操作的请求通常在这一层或其下方产生。
- NVMF 层 (NVMe over Fabrics): 如果涉及到通过网络访问 NVMe 存储,NVMF 层负责处理 NVMe-oF 协议。加速操作可能在此层处理数据前或后进行。
- IPU: NPI 传输: 在基于 IPU 的方案中,这是 NVMe-oF 发起端在 IPU 上的实现,负责通过网络发送/接收 NVMe 命令和数据。加速操作可能与这里的传输过程结合。
- 具体的块设备提供者: 位于 BDEV 层之下,代表实际的数据来源或目的地。这包括直接访问本地 NVMe 设备(bdev NVMe),处理加密逻辑的块设备(bdev crypto),通过不同传输方式(TCP, RDMA, PCIe)连接的设备,以及集成 Ceph 或其他第三方存储。加速操作的驱动就位于这一层附近,负责与硬件加速器交互。

SPDK 在 IO 缓冲区处理方面的优化策略及其益处
SPDK 在 IO 缓冲区处理方面的优化策略及其益处
关键创新点:
- 延迟缓冲区分配 (Deferred buffer allocation):
- 机制: SPDK 采用了延迟分配 IO 缓冲区的策略,即不是在操作一开始就分配好缓冲区,而是将其延迟到实际需要时。可能通过引入“假缓冲区”机制来实现,先用一个占位符,直到数据真正到达或需要处理时再分配实际内存。
- 重要性: 这个优化对 IO 读操作尤为重要。在读取数据时,不必预先分配一个固定大小的缓冲区,可以等到知道实际数据大小时再分配,避免浪费内存。对写操作则相对不那么关键。
- 更快的缓冲区释放 (Faster buffer free):
- 机制: SPDK 在数据提交给底层硬件或网络后,会更快地释放用于该操作的 IO 缓冲区,而无需等待整个 IO 事务的最终完成确认。
- 重要性: 这个优化对 IO 写操作尤为重要。一旦数据被成功提交到网络发送队列或硬件进行处理,发送缓冲区就可以被回收,以便快速用于新的写操作。
核心收益:
- 减轻内存压力: 这些优化共同作用,显著降低了 SPDK 在运行过程中对系统内存大小和使用量的需求。通过延迟分配和提前释放,提高了内存的利用效率,减少了不必要的内存占用。
实现方式:
- 这些关键的 IO 缓冲区优化机制被集成在开源的 SPDK 核心代码中。
- 开放性和通用性: 这意味着这些优化是 SPDK 框架本身的特性,所有使用 SPDK 的存储解决方案都能从中获益,而不依赖于特定厂商的内部私有代码。
- 厂商代码职责: 厂商特有的代码只需要关注如何对自身的硬件进行底层编程和控制,而无需重复实现通用的缓冲区管理逻辑。
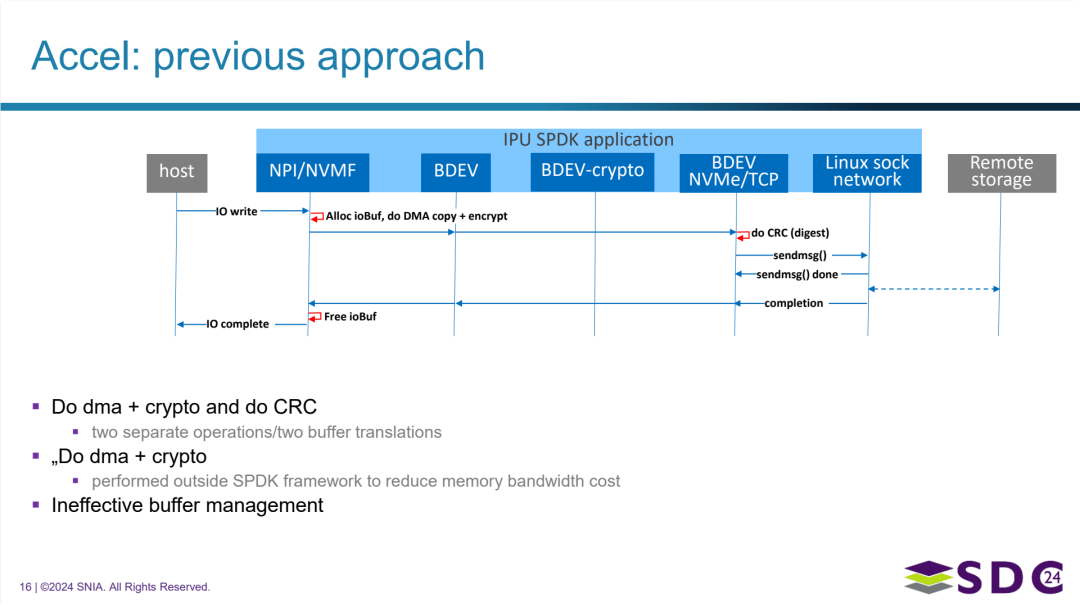
SPDK 加速框架之前的处理方式及其面临的问题
SPDK 加速框架之前的处理方式及其面临的问题
之前方法的特点与流程:
- 操作分解: 在处理一个需要多个步骤的 IO 操作(例如包含数据复制、加密和校验)时,这些步骤被分解成相互独立的加速操作。图示中明确指出,“执行 DMA + 加密” 和 “执行 CRC” 是两个分开的操作。
- 数据流经多模块: 一个 IO 请求在 IPU SPDK 应用程序内部需要依次经过多个模块处理,如 BDEV 层、加密模块 (BDEV-crypto)、NVMe/TCP 模块等,并与底层的网络和远程存储交互。
- 多次缓冲区操作: 由于操作的独立性,同一个 IO 缓冲区可能需要被处理多次,甚至导致两次或更多的缓冲区转换,增加了数据处理的开销。
面临的核心问题:
- 多操作处理效率低下: 将逻辑上相关的多个操作(如 DMA copy + 加密)拆分成独立步骤,并可能需要多次调用加速器,这与现代硬件加速器支持链式操作的能力不匹配,导致处理效率不高。
- 为了性能绕过框架: 为了降低内存带宽开销,某些计算密集型操作(如图中提到的“Do dma + crypto”)甚至不得不在 SPDK 框架外部执行。这种做法虽然可能在一定程度上提升性能,但破坏了 SPDK 框架的统一性和模块化设计,增加了软件实现的复杂性和维护难度。
- 缓冲区管理低效: 之前的方法存在 “低效的缓冲区管理” 问题。这可能体现在不必要的缓冲区分配和复制、释放不及时等方面,从而增加了内存占用和带宽压力。
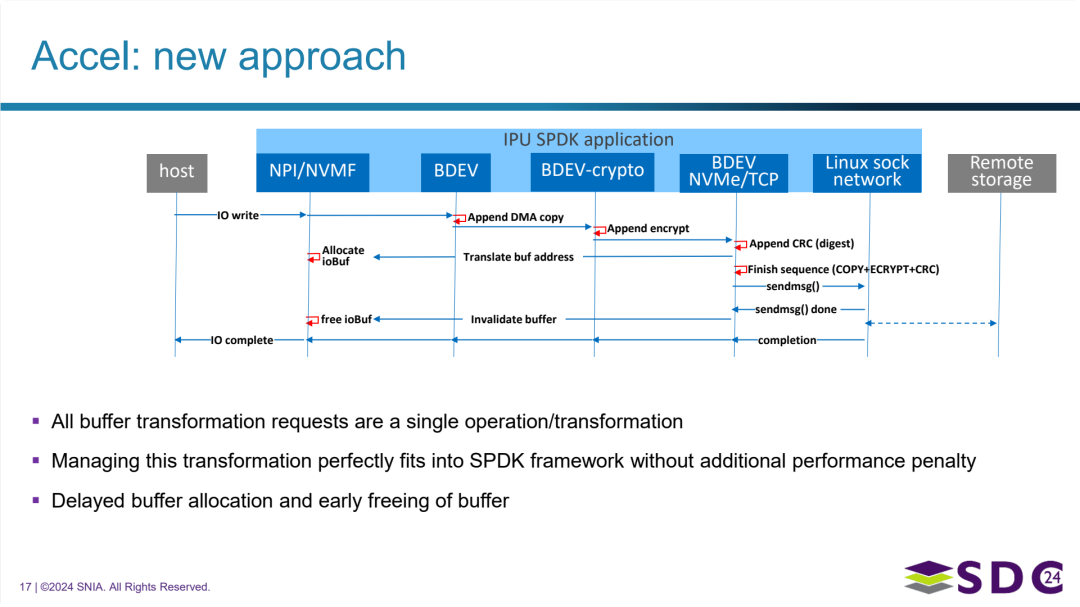
SPDK 加速框架采用的新处理方式(链式操作与优化缓冲区管理)
SPDK 加速框架采用的新处理方式(链式操作与优化缓冲区管理)
新方法的关键特点 (与之前方法的对比):
- 引入链式操作 (Chained Operations):
- 核心改变: 多个需要连续执行的加速操作(如图示中的 DMA 复制、加密、CRC 计算)不再作为独立的任务提交。通过新的 API (如
spdk_accel_append_*和spdk_accel_sequence_finish),这些操作被构建成一个操作序列或“链”。 - 单一请求:整个操作链被作为一个“单一的操作/转换”请求提交给底层硬件加速器或驱动进行处理。这与之前方法中需要多次独立调用形成鲜明对比。
- 核心改变: 多个需要连续执行的加速操作(如图示中的 DMA 复制、加密、CRC 计算)不再作为独立的任务提交。通过新的 API (如
- 优化的缓冲区管理:
- 新方法结合了之前介绍的延迟缓冲区分配和尽早释放缓冲区的优化策略。如图所示,缓冲区分配在操作开始时,但释放可以在数据发送完成后尽早进行。
- 图中还提到了“使缓冲区失效 (Invalidate buffer)”,这可能是配合延迟分配和释放机制,确保数据一致性或优化缓存使用。
- 框架内的统一处理:
- 完美融入框架: 管理和执行这种链式操作和缓冲区转换的逻辑完美地融入了 SPDK 框架。
- 无额外性能开销: 关键在于,这种更高级的处理方式没有引入额外的性能开销,反而通过减少交互次数和优化数据路径提高了效率。这解决了之前为了性能而将部分操作放在框架外执行的问题。
带来的主要优势:
- 显著提高处理效率: 通过将多个操作合并为一次硬件调用,减少了软件与硬件之间的交互次数、上下文切换以及数据在不同处理阶段的往返,从而大幅提高了数据处理的吞吐量和降低了延迟。
- 充分利用硬件能力: 能够充分发挥支持链式操作的硬件加速器(如 IPU 的 LCE)的性能潜力,实现硬件内部的高效数据流水线处理。
- 降低内存带宽和使用压力: 结合优化的缓冲区管理,减少了不必要的数据复制和内存占用,缓解了内存带宽瓶颈。
- 简化软件逻辑: 上层软件可以通过更简洁的 API 调用实现复杂的数据转换和加速任务,提高了代码的可维护性和可读性。

SPDK 加速框架的开发进展和后续工作重点
SPDK 加速框架的开发进展和后续工作重点
当前状态 (已完成的工作):
- 版本: 与加速框架相关的关键开发工作已经在 SPDK 的 v24.05 版本中完成并发布。
- API 变更: 为支持链式操作和优化处理流程而进行的加速框架 API (ACCEL API) 更改已经开发完成并合入。
- 组件适配: SPDK 内部的相关组件已经过修改和调整,以采用和利用这些新的 API 和方法。
- 效果验证:通过使用英特尔 IPU 平台进行的演示,已经初步验证了新的加速处理方法是有效且合理的,能够带来预期的性能和效率提升。
未来计划 (后续工作重点):
- 方向: 相关工作将继续在 SPDK 未来的版本中进行。
- 主要任务: 未来的主要工作将集中在对 SPDK 软件栈的各个层次进行更深入的性能调优。这可能包括进一步优化数据路径、减少开销、提升并发度等,以最大化利用硬件加速器的能力和提高整体存储解决方案的性能。

本次讨论应获得的关键知识点
本次讨论应获得的关键知识点
- 对 SPDK 加速框架的理解: 能够理解 SPDK 加速框架是如何组织构建的,以及如何使用这个框架来实现计算卸载。
- 硬件能力与 SPDK 的集成: 能够理解类似 IPU 这样的专用设备所提供的硬件加速能力,是如何被集成到 SPDK 加速框架中并加以利用的。
- Intel IPU NVMe 发起端卸载的细节与优势:
- 能够了解英特尔 IPU 是如何实现 NVMe 发起端功能卸载的具体方法。
- 能够理解结合使用 SPDK 框架的软件能力和 IPU 的专用硬件能力所带来的具体好处(例如性能提升、效率提高、资源节约等)。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- SPDK 链式加速框架在实际部署中,如何平衡硬件加速器资源分配与不同存储工作负载的需求?
- 除了加密和压缩,SPDK 加速框架未来还能集成哪些更复杂的计算任务(如数据去重、纠删码)进行卸载?
- SPDK 的这些优化对于边缘计算或混合云场景下的存储性能和资源利用率有何潜在影响?
#存储协议栈优化 #SPDK下一代存储
原文标题:Leveraging SPDK Acceleration Framework for Optimal IPU/DPU Storage Workflows
Notice:Human's prompt, Datasets by Gemini-2.5-flash-thinking
---【本文完】---
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号