大模型微调概述 - LoRA(低秩适应)


LoRA 是目前大模型微调领域最流行的参数高效微调技术之一,核心思想非常巧妙: 在冻结原始预训练模型权重的基础上,通过添加少量可训练的低秩矩阵来模拟模型对特定下游任务的适应过程。
1
原理详解
在预训练模型中,权重矩阵(例如 Transformer 中的 Wq 、 Wk 、 Wv 、 Wo 等)通常都是满秩的,当针对某个下游任务进行全参数微调时,会得到一个权重的更新量 ΔW,微调后的权重就是 W_0 + ΔW 。
LoRA 假设: ΔW 在适应特定任务时,其内在的“秩”是非常低的, 也就是说,ΔW 可以被分解为两个更 小的矩阵的乘积,而不会丢失太多信息。数学上,对于一个 d×k 的权重矩阵 W₀,其更新量 ΔW 可以表示为:
ΔW=B×A
其中:
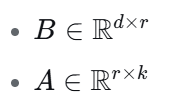
秩 r 远小于 min(d, k) ,通常 r = 1, 2, 4, 8, 16 等。
这样,微调时原本需要更新 d×k 个参数,现在只需要更新 B 和 A 中的参数,总参数量为 d×r + r×k。由于 r << d, k,参数量大幅减少。
为什么有效? 尽管预训练模型本身是高维复杂的,但针对特定任务的适应性调整往往是低维的。例如,模型原本已经学会了通用语法和知识,要适应某个特定领域的对话,只需要在几个关键方向上微调即可,这些方向就对应着低秩子空间。
2
操作过程
以微调一个 Transformer 模型(如 LLaMA)为例,LoRA 的具体操作步骤如下:
- 冻结预训练权重:将原始模型的所有参数设为不可训练(requires_grad=False)。模型仍然参与前向和反向传播,但梯度不会更新这些原始参数。
- 插入低秩矩阵:选择要应用 LoRA 的目标层(通常是注意力层的 qproj、vproj,有时也包括 kproj、oproj 以及 FFN 层)。对于每个选定的权重矩阵 W0,我们创建两个新的可训练矩阵:
- A:形状为 (r, k),使用随机高斯分布初始化(均值为0,方差由 r 和 k 决定,例如使用 Kaiming 初始化)。这相当于提供初始的随机方向。
- B:形状为 (d, r),初始化为零矩阵。这样可以确保在训练开始时,B×A=0,即对原始模型没有任何影响,模型输出与原始预训练模型完全一致,保证了训练的稳定启动。
- 前向传播:对于原始权重 W0 的输入 x,输出计算变为:
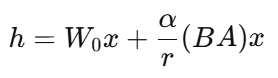
其中 α 是一个缩放超参数,用于控制低秩分支的影响强度。通常 α 设置为与 r 相同(或一个常数),这样调整 r 时只需要改变参数量,而不必大幅调整学习率。
- 反向传播:只更新 A 和 B 中的参数,原始权重 W0保持不动,梯度通过 B 和 A 回传并更新它们。
- 推理阶段:LoRA 提供两种推理方式:
- 合并式:将训练好的低秩矩阵合并回原始权重:。然后直接使用合并后的权重进行推理,没有额外的计算开销。
- 分离式:保留原始权重和低秩分支,在前向时分别计算后相加。这种方式允许快速切换不同的 LoRA 模块,方便多任务部署。
3
主要特点与优势
- 参数效率极高:可训练参数量通常只有全量微调的 0.1% ~ 1% 左右。例如,7B 参数的 LLaMA,若只微调注意力层,r=8 时 LoRA 参数量仅约几百万。
- 显存占用大幅降低:由于不需要计算和存储大部分参数的梯度,且优化器状态(如 Adam 的一阶和二阶矩)也大幅减少,训练所需的显存可降低 2/3 以上,使得在消费级 GPU 上微调大模型成为可能。
- 训练速度快:需要更新的参数少,反向传播的计算量减少,训练速度提升。
- 无推理延迟:合并权重后,模型结构和计算量与原始模型完全相同,不会增加任何推理延迟。
- 可插拔性强:训练好的 LoRA 模块(通常仅几 MB 到几十 MB)可以轻松保存、分享和加载,且可以针对不同任务训练多个 LoRA 模块,在推理时按需切换,实现“一基座多适配”。
- 保持基础能力:由于原始权重被冻结,LoRA 微调不会导致灾难性遗忘,模型原有的通用能力得以保留,只在特定任务上进行调整。
4
一些注意事项与变体
- 秩 r 的选择:r 是超参数,控制着低秩空间的表达能力。通常 r 越小,参数量越少,但可能不足以捕获任务的复杂适应;r 越大,效果可能更接近全量微调,但参数量增加。实践中常见 r=8 或 16 能在效果和效率之间取得良好平衡。
- 缩放因子 α:用于调节低秩分支的梯度更新幅度。如果训练不稳定,可以适当调整 α。
- 应用哪些层?:并非所有层都需要 LoRA。通常只对注意力层的 Q、V 矩阵应用 LoRA 就能取得很好的效果;扩展到 K、O 或 FFN 层可能带来轻微提升,但会增加参数量。
- 初始化方式:B 初始化为零保证了初始时模型行为不变,但 A 的初始化方式(随机)会影响收敛速度。一些研究尝试了其他初始化策略。
- 与其他 PEFT 方法结合:LoRA 可以与 Prefix Tuning、Adapter 等方法结合使用,进一步提升效果。
5
LoRA 与其他 PEFT 方法的简要对比
方法 | 原理 | 可训练参数量 | 推理延迟 | 特点 |
|---|---|---|---|---|
LoRA | 在权重旁添加低秩矩阵 | 极少 | 无(合并后) | 效果接近全量微调,无损推理速度 |
Adapter | 在层间插入小型前馈网络 | 少 | 有增加 | 引入额外层,增加延迟 |
Prefix Tuning | 在输入前添加可训练的前缀向量 | 极少 | 无 | 对长文本效果略差,训练不稳定 |
Prompt Tuning | 类似 Prefix,但只加在输入层 | 极少 | 无 | 效果通常弱于 Prefix Tuning |
BitFit | 只微调偏置项 | 极少 | 无 | 效果有限,但极简 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号