深度学习之MHA|MQA|GQA|MLA注意力机制对比分析

深度学习之MHA|MQA|GQA|MLA注意力机制对比分析

阳光宅猿
发布于 2026-03-05 18:48:39
发布于 2026-03-05 18:48:39


01、注意力机制历史演变
最初的注意力机制是在Seq2Seq模型中,注意力机制被引入,用于在解码时关注编码器的隐藏状态。这是单向的,通常只有一个头,也就是单头注意力机制。
后面谷歌提出了Transformer和MHA,Transformer模型引入了MHA,使模型能够同时关注不同位置的不同特征,大大提升了模型性能。此后,MHA成为Transformer架构的标准配置。
之后谷歌又相继提出MQA,为了减少推理时的计算和内存开销,MQA被提出,并在一些大规模模型中得到应用,如T5和一些对话模型。
之后谷歌又又提出GQA注意力机制,不得不说谷歌还是太超前了,为了在效率和性能之间取得更好的平衡,GQA被提出,并在一些最新模型中使用,如LLaMA-2和PaLM。
- 注意力发展时间线:
- 2017.06,MHA(Multi-Head Attention),Google提出Transformer,MHA是核心设计之一。 2019.11,MQA(Multi-Query Attention)Google提出Fast Transformer Decoding: One Write-Head is All You Need 2023.05,GQA(Group-Query Attention)Google提出GQA:Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints 2024.05,MLA(Multi-Latent Attention)在DeepSeek-v2中提出 DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
02、MHA的昂贵代价
前面已经比较系统的总结了多头注意力(Multi-Head Attention, MHA)机制的实现原理深度学习之MHA多头注意力机制剖析。
MHA将注意力机制重复多次(多头),每次使用不同的线性变换将Q、K、V投影到不同的子空间,然后并行计算注意力,最后将结果拼接并再次投影。MHA表达能力最强,能捕捉丰富的信息,但是其计算量大、内存占用高,也就是为什么已经有了这么好用的注意力机制还要引入MQA、GQA的原因。
这就取决于在性能和效率之间如何寻找平衡了。
其实在长序列下,MHA的计算和内存开销会非常大,主要有以下两个问题:
内存占用高:每个头都有自己的K和V,在长序列生成(如自回归生成(文本生成))时,需要缓存每个头的K和V,内存占用大。
计算量大:每个头都要计算QK^T,然后加权求和V。
在自回归生成任务(如文本生成)中,模型需要缓存之前时间步的K和V以加速计算。MHA需要缓存H个头的K和V,而MQA只需要缓存1份,GQA需要缓存G份。当序列长度S很大时,MHA的缓存可能成为内存瓶颈。
早期Transformer使用MHA,因为模型规模不大,序列长度也不长,内存和计算不是主要瓶颈。但随着模型规模增大,序列长度变长,MHA的KV缓存成为问题。因此,T5和PaLM等模型开始使用MQA。LLaMA-2等模型发现GQA在性能和效率之间取得更好平衡,成为当前主流。
MHA比喻:多个专家团队并行工作
MQA比喻:多个问题专家共享同一份参考资料
GQA比喻: 多个专家小组,组内共享资料
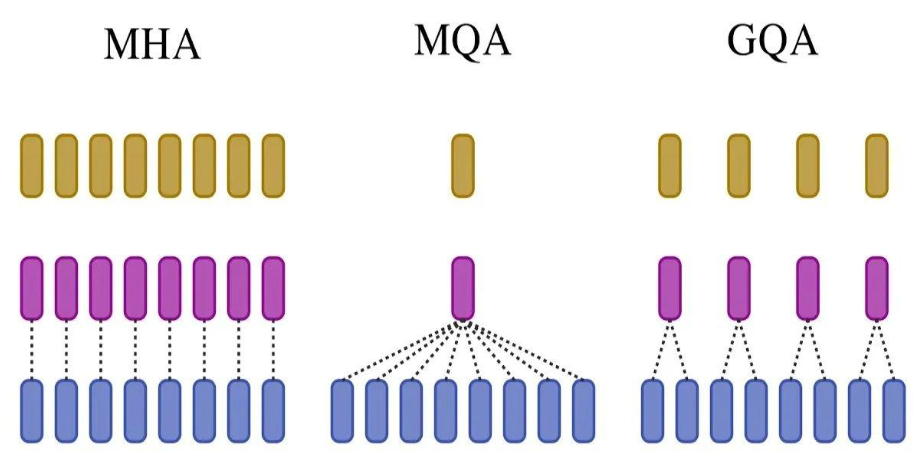
MHA/左侧:头注意力有 H 查询、键和值头。
MQA右侧:多查询关注在所有查询头之间共享单个键和值头。
GQA/中间:分组查询注意为每组查询头共享单个键和值头,在多头和多查询注意之间进行插值。
03、MQA极致的推理优化
假设我们有一个典型的大语言模型配置:
神经网络层数(L): 32层
注意力头数(H): 32个头
维度(d_model): 4096
批次大小(B): 1
序列长度(S): 2048
MHA的KV缓存内存需求:
每个头的维度 = 4096 / 32 = 128
每个token的KV缓存 = 2 × 128 × 32 = 8192
浮点数2048个token的KV缓存 = 2048 × 8192 = 16,777,216
浮点数转换为字节(假设float16): 16,777,216 × 2 = 33,554,432 字节 ≈ 32 MB
只是KV缓存就需要32MB/层,32层就是1GB!这仅仅是KV缓存,还不包括模型参数、激活值等。在大模型最开始火的早些年,大家都关注模型训练时的表现,而现在对应应用层面上大家更关注效率和成本。因此长序列下,KV缓存成为MHA主要瓶颈。
MQA是如何处理这种情况的呢?MQA的原理就是将所有查询头共享同一套K和V。MQA通过共享键和值来减少参数和计算量,同时保持多个查询头以捕捉不同的注意力模式。
MQA是对MHA的改进,旨在减少计算和内存开销。在MQA中,多个头共享同一个键和值矩阵,但查询矩阵仍然独立。
传统MHA计算:Q@Kᵀ (32×32次) 矩阵乘法
MQA计算:Q@Kᵀ (32×1次)
减少:~97%的K@V计算量MHA:Q头32个,K头32个,32 个 Q 头,每一个都要和32个K头做点积注意力计算,一共要算32×32组QK匹配。
MQA:还是查询头数量 = 32,但所有Q共享1组K,只需要算32×1组QK 匹配,计算量暴减。
这意味着我们使用相同的键和值集合,但通过不同的查询来提取不同的信息。
MQA的机制如下:
1、对查询进行h次不同的线性变换,得到h个查询头。
2、对键和值进行一次线性变换,得到共享的键和值。
3、每个查询头与共享的键和值计算注意力。
4、将h个头的输出拼接起来,然后通过线性变换得到最终输出。
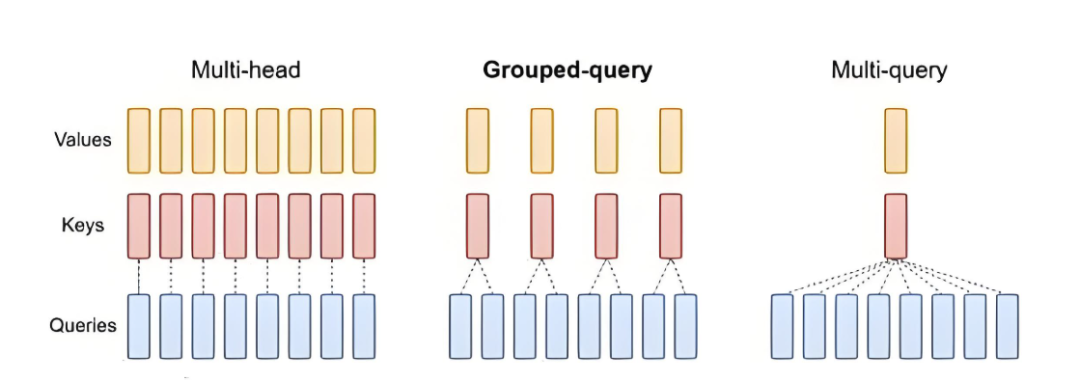
04、GQA平衡的艺术
MQA太极端了,所有head都共享同一组K/V,虽然性能得到了提升但是这样会是表达能力下降,GQA是稍微拉回来一点,介于MHA和MAQ的中间态,所有head共享多组K/V。
GQA是MHA和MQA的折中方案。在GQA中,查询头被分成g组,每组内的头共享同一个键和值矩阵,但不同组使用不同的键和值矩阵。经过训练的 GQA 以与 MQA 相当的速度实现了接近多头注意力的质量。
分组查询注意将查询头划分为多个 组,每个组共享一个键头和值头。 GQA-g 是指带 组的分组查询。 特别地,GQA- 1 具有单个组,因此具有单个键和值头,等价于 MQA,而 GQA-h 具有等于注意力头数的组,等价于 MHA。
GQA将头分组,组内共享K和V,平衡KVCache压缩与模型性能的注意力机制。GQA通过分组共享键和值来平衡模型性能和计算效率。当组数g等于头数h时,GQA退化为MHA;当g=1时,GQA退化为MQA。
中间数量的组会,导致插值模型的质量高于 MQA,但比 MHA 快,这是一个balance。 先来看MQA:
从 MHA 到 MQA 将键和值头减少到单个键和值头,从而减小了键值缓存的大小,从而减少了需要加载的数据量 。 但是,较大的模型通常会缩放注意力头的数量,因此多查询注意力表示内存带宽和容量的削减幅度更大。 所以,MQA减少K/V太过了。
GQA 允许我们,随着模型大小的增加而保持带宽和容量的相同比例减少。
因此我们上面的例子,就可以改为如下配置,既能够保持性能又可以保障其表达能力。
8组KV,每组4个查询头
相比MHA:减少75%的KV缓存
相比MQA:保持更强的表达能力32个注意力头,分成8组,每组4个头。那么,第一组的4个头共享一套键和值,第二组的4个头共享另一套键和值。这样,我们既减少了键和值矩阵的数量(从32套减少到8套),又保持了比MQA更多的多样性。
GQA的机制如下:
1、将h个查询头分成g组,每组有h/g个头(假设h能被g整除)。
2、对每组分别进行键和值的线性变换,得到g套键和值。
3、每组内的多个查询头共享同一套键和值。
4、每个查询头与所在组的键和值计算注意力。
5、将所有头的输出拼接起来,然后通过线性变换得到最终输出。
典型应用模型
模型 | 说明 | 组数 |
|---|---|---|
LLAMA2-70B | Meta开源的大规模语言模型 | 8 |
LLAMA3系列 | Meta最新一代开源模型 | 8 |
TigerBot | 深度求索科技的中英双语模型 | 8 |
DeepSeek-V1 | 深度求索的高效长文本模型 | 8 |
Yi系列 | 零一万物开发的多模态模型 | 8 |
ChatGLM2/3 | 智谱AI的中英双语对话模型(实际为GQA) | 2 |
MHA、MQA、GQA三者区别对比
注意力类型 | 查询头数 | 键头数 | 值头数 | 参数量 | 计算效率 | 表达能力 |
|---|---|---|---|---|---|---|
MHA | h | h | h | 高 | 低 | 高 |
MQA | h | 1 | 1 | 低 | 高 | 较低 |
GQA | h | g | g | 中 | 中 | 中 |
MHA:每个头都有自己独立的Q、K、V变换,因此参数多,计算量大,但表达能力最强。
MQA:多个查询头共享同一套K和V,参数和计算量大大减少,但可能牺牲一些表达能力。
GQA:折中方案,通过分组共享K和V,在减少参数和计算量的同时,尽量保持表达能力。
05、MLA多头潜在注意力机制
MLA(多头潜在注意力机制 Multi-head Latent Attention)是DeepSeek-V2提出的兼顾KV Cache压缩与模型表达能力的新型注意力机制。其核心思想是通过低秩投影与恒等变换技巧,在保持GQA(Grouped-Query Attention)显存效率的同时增强语义多样性,并兼容RoPE(旋转位置编码)。MLA被视为GQA的进阶版本,实现了“训练时增强能力,推理时压缩显存”的优化目标。
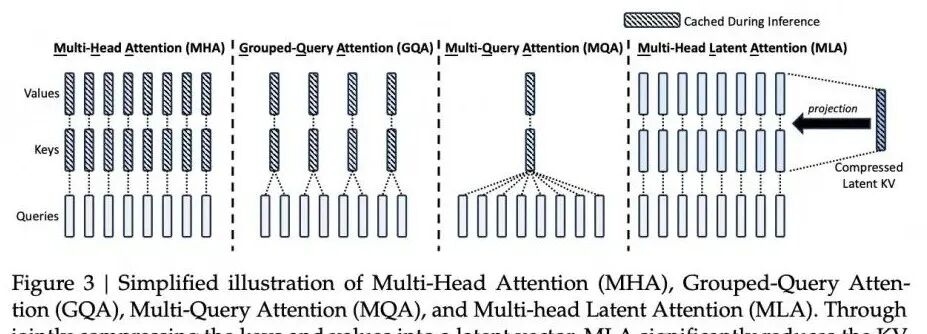
与传统MHA相比,MLA不直接存储完整的键值矩阵,而是存储一个维度更小的压缩向量。在需要进行注意力计算时,再通过解压缩重构出所需的键和值。这种压缩-解压缩机制使得模型可以在显著减少内存占用的同时,保持甚至提升性能。
DeepSeek-V2的技术报告显示,MLA使KV缓存减少了93.3%,训练成本节省了42.5%,生成吞吐量提高了5.76倍。在8个H800 GPU上实际部署时,实现了超过50,000令牌每秒的生成速度,这一数据充分证明了MLA的高效性。
以下表格总结了不同注意力机制的关键特性:
特性 | 多头注意力 (MHA) | 多查询注意力 (MQA) | 分组查询注意力 (GQA) | 多头潜在注意力 (MLA) |
|---|---|---|---|---|
KV缓存大小 | 大 | 非常小 | 小 | 显著减少 |
推理速度 | 基线 | 最快 | 快 | 比MHA快 |
性能 | 高 | 可能下降 | 轻微下降 | 与MHA相似或更好 |
关键特性 | 每个头独立的KV | 所有头共享KV | 一组头共享KV | KV的低秩压缩 |
内存效率 | 低 | 高 | 中 | 高 |
计算成本 | 较高 | 较低 | 较低 | 通过吸收可能更低 |
与GQA相比,MLA的一个关键优势在于其更具表现力的压缩方式。GQA使用固定的选择矩阵,而MLA学习一个上投影矩阵,这使得MLA能够实现更灵活的压缩,从而可能带来更好的性能。
有趣的是,研究表明GQA总是可以由MLA表示,但反之不成立,这进一步证明了MLA的灵活性和表达能力。
MLA在DeepSeek模型系列中的应用和演进如下:
模型 | MLA引入 | 关键MLA特性/改进 | 报告的MLA优势 |
|---|---|---|---|
DeepSeek-V2 | 首次引入 | 低秩KV联合压缩,解耦RoPE | 减少KV缓存(14-4%),性能优于MHA |
DeepSeek-V3 | 进一步改进 | 动态低秩投影,自适应查询压缩,改进RoPE,联合KV存储,自适应缓存 | 进一步减少内存,改进长序列处理(高达128K上下文) |
DeepSeek-R1 | 继续应用 | 基于V3的改进 | 为长上下文推理模型提供高效推理 |
DeepSeek Coder | 应用于代码领域 | 针对代码生成优化 | 高效的代码生成 |
V2-Lite | 轻量级实现 | 特定维度(dc=512,无查询压缩)的MLA | 在多项基准测试中优于同等规模模型 |
MLA在DeepSeek的模型系列中的持续使用和改进表明,它已成为DeepSeek架构中一个核心且基础的技术,而不仅仅是一个实验性功能。
总结
DeepSeek的多头潜在注意力(MLA)机制是解决传统Transformer模型中KV缓存内存瓶颈的一项重要创新。通过在低维潜在空间中压缩键和值矩阵,MLA显著减少了内存占用,提高了推理速度和吞吐量,同时保持或甚至提升了模型性能。
从DeepSeek-V2到V3和R1的演进过程中,MLA不断发展和完善,证明了其在各种基准测试中的卓越表现。DeepSeek开源模型和推理框架对MLA的支持,为该技术的进一步研究和应用奠定了坚实基础。
尽管MLA已显示出巨大潜力,但其在整个行业内的广泛采用仍有待发展。未来,随着技术的成熟和更多实际应用的验证,MLA有望推动更高效、更可扩展的大型语言模型发展,为更强大、更易于访问的人工智能应用铺平道路。
作为LLM效率优化的关键创新,MLA代表了一种新的思路:通过智能压缩和重构,在资源有限的情况下实现更强大的模型能力。这种思路不仅对大型语言模型具有重要意义,也可能对其他需要处理长序列数据的深度学习任务产生深远影响。


本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号