深度学习之一篇文章彻底搞懂【缩放点积注意力】




本篇从缩放点积注意力原理、缩放点积注意力与余弦相似度的区别到其在多头注意力机制中的角色与作用再到代码实战以及完整的计算流程,花了三天时间梳理出来,足足的干货,哪怕你是纯小白你都能明白缩放点积注意力机制到底是个啥。
01、再谈注意力机制
前面梳理并深度总结了注意力机制及其实现原理:
深度学习之一篇文章带你深度理解注意力机制
深度学习之注意力机制中QKV原理解读
无论是MHA、MQA还是GQA,它们都使用相同的缩放点积注意力核心计算,区别只在于如何生成Q、K、V矩阵以及如何组织计算。这种统一性使得注意力机制既强大又灵活,成为了现代深度学习的基石。因此弄懂缩放点积注意力就显得十分必要了。
注意力机制的核心思想是:在生成输出时,模型能够关注输入中与当前输出最相关的部分,判断词与词之间的相关性。例如,在翻译句子时,当生成下一个词时,模型会关注输入句子中与之最相关的词。那么模型是如何知道哪些词与下一个词最相关呢?这就是注意力中的评分函数的作用了。
经过评分函数会对词进行评分,得到注意力分数。注意力分数经过Softmax函数归一化处理之后变成注意力权重,注意力权重总和为1,可以直观的理解为概率分布。注意力分数越高,计算出来的权重也就越大,表示模型认为当前“查询”(Query)与某个“键”(Key)之间的相关性也就越大,意味着该“查询”与该“键”在模型所学习的向量空间中越相似,模型判定它们的相关性越强。
这种相关性是模型智能的核心体现,它使模型能够动态地、有选择地聚焦于输入中最相关的部分,从而做出精准的预测或生成。例如当生成中文“苹果”时,对英文“apple”有高分数 (语义对应);生成“吃”时,对“apple”和“I”都有较高分数 (语法与角色关联),当生成总结句的关键词时,对原文中表达核心信息的词或句子有高分数 (重要性关联)。
这种种机制就像一个非常精准的“信息探照灯”,分数就是调节灯光亮度的旋钮,最终最亮的地方(权重最高)就是模型认为最需要关注的地方。
突然发现这一点与RAG中的余弦相似度不谋而合,那么问题来了,为啥不采用余弦相似度呢?为啥要用点积注意力函数呢?
02、余弦相似度与缩放点积注意力的区别
现代深度学习框架和硬件对矩阵乘法的优化已经到了极致,任何偏离这个计算路径的操作都会造成显著性能损失。Transformer的成功本质上是算法与硬件的共谋。
缩放点积注意力完美契合了Transformer的设计哲学:一切为了大规模并行训练优化。QKᵀ就是矩阵乘法,是GPU最擅长的操作,没有之一。除以根号d_k那个神来之笔的缩放,既解决了模长影响数值稳定的问题,又保留了模长信息。
余弦相似度虽然能排除向量模长干扰,但计算需要归一化,多出L2范数计算和除法,在GPU上比纯矩阵乘法慢得多。更重要的是,在注意力机制里模长其实携带重要信息——高频词向量模长大,低频词模长小,这对语言建模有用,余弦相似度会丢弃这个信息。
因此余弦相似度损失了重要的“模长”信息。在训练好的词向量或Transformer中间层表示中,向量的模长(Norm)通常携带了信息。例如,出现频率高、意义明确的词其向量模长可能更大,表示模型对其表示更“确信”。点积会保留这个信息,而余弦相似度通过归一化强行抹除了它,这相当于丢弃了一部分有用的语言学特征。
在一个原因就是余弦相似度需要在点积之后,为每一个Q和K向量计算L2范数,然后执行大量除法运算。这会严重破坏纯矩阵乘法(QKᵀ)的连续性,在现代硬件(GPU/TPU)上无法进行最优化的并行计算,导致速度显著慢于纯点积。
特性 | 缩放点积注意力 (Scaled Dot-Product) | 余弦相似度 (Cosine Similarity) | 欧式距离 (Euclidean Distance) |
|---|---|---|---|
核心计算 | 相似度 = Q·K (点积) | 相似度 = (Q·K) / (‖Q‖‖K‖) | 差异度 = ‖Q - K‖² |
包含的信息 | 方向 + 模长 | 仅方向 (被归一化) | 绝对空间位置 |
计算复杂度 | 极低:一次矩阵乘法 | 较高:需额外计算L2范数并做除法 | 最高:需做减法和平方,计算量大 |
硬件友好度 | 完美:纯粹密集矩阵乘,GPU/TPU最爱 | 差:破坏纯矩阵乘流程,引入非规整计算 | 极差:计算模式复杂,难以并行优化 |
与Softmax的配合 | 天然匹配:输入值范围通过缩放调整 | 需要调整:输出范围固定[-1,1],Softmax前需伸缩 | 不匹配:衡量差异,需转换为相似度(如取负) |
梯度特性 | 优良 | 尚可,但范数计算可能引入不稳定梯度 | 较差,特别是当Q和K很近时梯度可能爆炸 |
主要优势 | 快、简单、有效、信息全 | 对向量绝对模长不敏感,纯比较方向 | 几何直觉强 |
主要劣势 | 模长影响可能成为干扰(但缩放缓解了此问题) | 丢弃模长信息,计算代价高 | 计算代价极高,与注意力机制需求不匹配 |
理解三种方法在“为查询词Q寻找最相关的键K”这个任务中的表现:
欧式距离:像是在地图上测量两个地址的直线距离。计算麻烦,而且只告诉你们“隔了多远”,没直接说“关系多近”。 余弦相似度:像是只比较两个人的兴趣方向(都爱科幻还是爱文艺)。它公平地比较了方向,但忽略了一个人是轻度爱好者还是资深专家(模长)的区别。 缩放点积注意力:像是同时考虑兴趣方向的吻合度和热衷程度。兴趣越吻合、热衷程度越高,得分就越高。并且,它还通过一个巧妙的“标准化”步骤(除以√(d_k)),确保不同领域的兴趣(不同维度)能放在同一个标准下公平比较,最终让选择过程既高效又准确。
确实,缩放点积注意力(Scaled Dot-Product Attention)绝对是Transformer模型中计算注意力分数的主流和奠基性方法。自从2017年Transformer原论文《Attention Is All You Need》提出以来,它几乎成为了所有现代Transformer架构变体的默认核心。可以说,它是现代注意力计算的“标准原子操作”。
标准点积本身有一个问题:当向量维度d_k很高时,点积结果的值会很大,导致Softmax函数的梯度非常小(进入饱和区),从而使模型难以学习。
缩放点积注意力中的除以 √(d_k) 操作,完美地解决了这个问题。
理论依据:假设Q和K的每个元素是独立随机变量,均值为0,方差为1,那么Q·K的方差就是d_k。除以√(d_k)后,方差被重新缩放为1。
实际效果:这使得无论维度多高,点积分数都能保持在一个合理的数值范围内,确保Softmax既能清晰区分高相关性和低相关性,又能保持健康的梯度流,这是模型稳定训练的关键。
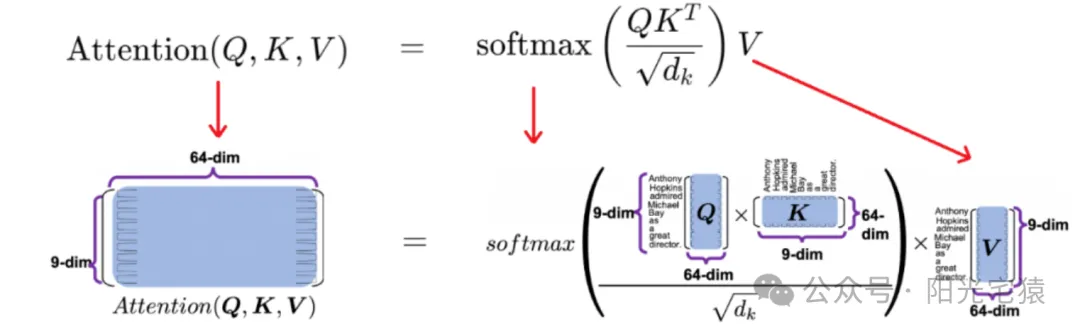
利用缩放点积注意力(Scaled Dot-Product Attention)来计算注意力权重得分,对于每个查询(Query),计算它与所有键(Key)的点积。并将点积结果进行缩放(除以键向量维度的平方根)得到注意力分数。
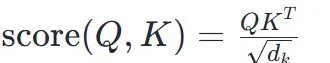
图片
然后将缩放后的结果通过softmax函数,得到归一化的注意力权重,最后使用注意力权重对值(Value)进行加权求和,得到最终的输出。
图片
所有高效注意力变体(MHA, MQA, GQA),其最底层的“注意力分数计算单元”都是缩放点积注意力。它们的区别仅在于如何组织和复用Q、K、V矩阵。
虽然缩放点积注意力是绝对主流,但在处理超长序列时,其O(n²)的计算和内存复杂度成为瓶颈。因此,研究界和产业界在此基础之上进行了创新,形成了两类主要路径:
保持核心,优化结构:这是主流路径。如MQA/GQA,保持了缩放点积计算,但通过共享KV来大幅减少计算和内存。
修改核心,实现稀疏:这是为了突破长度限制。如稀疏注意力(Sparse Attention)、线性注意力(Linear Attention)、MoBA(混合块注意力)等,它们改变了“每个词关注所有词”的全连接模式,或使用核函数近似来降低复杂度。但它们通常被视为在特定场景下对标准缩放点积注意力的替代或补充,而非取代其主流地位。
03、缩放点积注意力的完整计算流程
让我用一个完整的例子展示这个过程:
假设我们要翻译句子:"The cat sat on the mat",计算目标词"sat"的注意力权重,
步骤1要定义参数,这里假设我们嵌入维度为4维,序列长度为6。
嵌入维度:d=4(为简化)
序列长度:n=6(6个词)步骤2:经过线性变换得到Q、K、V矩阵(假设值)
查询 Q (target word "sat"): [1.2, -0.5, 0.8, 0.3](已经经过向量处理)
键 K (source words):
The : [0.9, 0.1, -0.2, 0.4]
cat : [0.3, 1.2, 0.5, -0.1]
sat : [0.6, -0.3, 0.7, 0.9]
on : [-0.2, 0.5, 0.1, 0.3]
the : [0.8, 0.0, 0.2, -0.1]
mat : [0.1, 0.4, -0.3, 0.6]
值 V (source words):
The : [0.2, 0.3, -0.1, 0.4]
cat : [0.5, -0.2, 0.8, 0.1]
sat : [0.3, 0.7, 0.2, -0.3]
on : [-0.1, 0.4, 0.5, 0.2]
the : [0.4, 0.1, -0.2, 0.3]
mat : [0.0, 0.6, 0.3, 0.5]步骤3:计算原始点积(相似度)
点积(Q, Kᵢ) = Q·Kᵢ
The : 1.2*0.9 + (-0.5)*0.1 + 0.8*(-0.2) + 0.3*0.4 = 1.08 - 0.05 - 0.16 + 0.12 = 0.99
cat : 1.2*0.3 + (-0.5)*1.2 + 0.8*0.5 + 0.3*(-0.1) = 0.36 - 0.60 + 0.40 - 0.03 = 0.13
sat : 1.2*0.6 + (-0.5)*(-0.3) + 0.8*0.7 + 0.3*0.9 = 0.72 + 0.15 + 0.56 + 0.27 = 1.70
on : 1.2*(-0.2) + (-0.5)*0.5 + 0.8*0.1 + 0.3*0.3 = -0.24 - 0.25 + 0.08 + 0.09 = -0.32
the : 1.2*0.8 + (-0.5)*0.0 + 0.8*0.2 + 0.3*(-0.1) = 0.96 + 0.00 + 0.16 - 0.03 = 1.09
mat : 1.2*0.1 + (-0.5)*0.4 + 0.8*(-0.3) + 0.3*0.6 = 0.12 - 0.20 - 0.24 + 0.18 = -0.14
原始点积分数: [0.99, 0.13, 1.70, -0.32, 1.09, -0.14]步骤4:缩放(除以√d)
d = 4, √d = 2
缩放后每个词的分数: [0.495, 0.065, 0.85, -0.16, 0.545, -0.07]步骤5:应用softmax得到注意力权重
计算指数: exp(0.495)=1.64, exp(0.065)=1.07, exp(0.85)=2.34,
exp(-0.16)=0.85, exp(0.545)=1.72, exp(-0.07)=0.93
求和: 1.64+1.07+2.34+0.85+1.72+0.93 = 8.55
注意力权重:
The : 1.64/8.55 = 0.192
cat : 1.07/8.55 = 0.125
sat : 2.34/8.55 = 0.274
on : 0.85/8.55 = 0.099
the : 1.72/8.55 = 0.201
mat : 0.93/8.55 = 0.109
总和检查: 0.192+0.125+0.274+0.099+0.201+0.109 = 1.000 ✓步骤6:加权求和V得到最终输出
输出 = Σ(权重ᵢ × Vᵢ)
维度1: 0.192*0.2 + 0.125*0.5 + 0.274*0.3 + 0.099*(-0.1) + 0.201*0.4 + 0.109*0.0
= 0.0384 + 0.0625 + 0.0822 - 0.0099 + 0.0804 + 0.0 = 0.2536
维度2: 0.192*0.3 + 0.125*(-0.2) + 0.274*0.7 + 0.099*0.4 + 0.201*0.1 + 0.109*0.6
= 0.0576 - 0.0250 + 0.1918 + 0.0396 + 0.0201 + 0.0654 = 0.3495
维度3: 0.192*(-0.1) + 0.125*0.8 + 0.274*0.2 + 0.099*0.5 + 0.201*(-0.2) + 0.109*0.3
= -0.0192 + 0.1000 + 0.0548 + 0.0495 - 0.0402 + 0.0327 = 0.1776
维度4: 0.192*0.4 + 0.125*0.1 + 0.274*(-0.3) + 0.099*0.2 + 0.201*0.3 + 0.109*0.5
= 0.0768 + 0.0125 - 0.0822 + 0.0198 + 0.0603 + 0.0545 = 0.1417
最终输出向量: [0.254, 0.350, 0.178, 0.142]04、缩放点积注意力的数学原理
点积的计算公式:
相似度 = Q·K = |Q||K|cos(θ)当Q和K方向相同时:点积最大,表示最相关
当Q和K垂直时:点积为0
当Q和K方向相反时:点积最小(负值)表示最不相关
为什么要缩放?从统计学理论来解释,假设Q和K的每个维度是独立同分布,均值为0,方差为1:
Var(Q·K) = d × Var(Q) × Var(K) = d所以点积的标准差是√d。
如果不缩放,d很大时(如512、1024),点积值会非常大,进入softmax饱和区(梯度接近0),进而导致模型训练困难,收敛慢。缩放使得点积的标准差保持在1左右,确保softmax梯度合理。
3. 实际对比:缩放vs不缩放
假设d=64,Q和K是随机向量:
不缩放的点积: 可能范围[-64, 64],典型值±8
缩放后的点积: 可能范围[-8, 8],典型值±1“典型值” 就是 ±1 倍标准差,是正态分布里最常见、最有代表性的区间,正态分布中,±1σ、±2σ、±3σ下的概率分别是68.3%、95.5%、99.73%,在实际应用中(如质量控制、数据分析、教育评估等),人们常将±1σ区间视为“正常”或“典型”的波动范围。
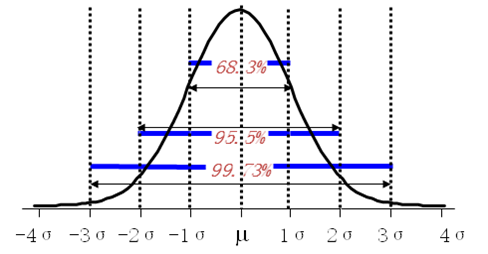
根据中心极限定理,当d_k足够大时,点积的分布趋近于正态分布。缩放使得这个分布的方差保持在1,确保数值稳定性。
softmax对不同输入的响应:
输入 = [10, 1, 0, -1] # 不缩放,差异太大
softmax ≈ [0.9999, 0.0001, 0.0000, 0.0000] # 几乎只有最大值
输入 = [1.0, 0.1, 0.0, -0.1] # 缩放后
softmax ≈ [0.58, 0.21, 0.16, 0.05] # 更均衡的分布05、多头注意力中的缩放点积计算
以MHA为例,假设h=2个头,d_model=4,每个头维度d_k=2:
输入序列(2个词):
X = [[1.0, 0.5, -0.3, 0.8], # 词1
[0.2, 0.9, 0.4, -0.1]] # 词2定义参数矩阵W:
W_Q1 = [[0.1, 0.2], [0.3, 0.4], [-0.1, 0.5], [0.6, -0.2]] # 头1的Q变换
W_K1 = [[0.2, -0.1], [0.4, 0.3], [0.1, 0.5], [-0.3, 0.2]] # 头1的K变换
W_V1 = [[0.3, 0.1], [-0.2, 0.4], [0.5, 0.2], [0.1, -0.3]] # 头1的V变换
W_Q2 = [[-0.2, 0.3], [0.1, 0.5], [0.4, -0.1], [0.2, 0.6]] # 头2的Q变换
W_K2 = [[0.3, 0.1], [-0.1, 0.4], [0.2, 0.5], [0.1, -0.2]] # 头2的K变换
W_V2 = [[0.1, 0.4], [0.3, -0.2], [-0.1, 0.5], [0.2, 0.3]] # 头2的V变换这里W_Q1 是一个 4×2 的矩阵(d_model × d_k),它的作用是把单个词的 d_model 维向量(4 维)线性变换为该头的 d_k 维QKV向量(2 维)。
不同头有不同的矩阵,如果都用相同W矩阵那就和自注意力相同了,怎么做线性变换都是一个。最后每个头独立计算缩放点积注意力,最后拼接所有头的输出,恢复为d_model维。
头1计算:
步骤1:计算Q1、K1、V1
Q1 = X × W_Q1
词1: [1.0, 0.5, -0.3, 0.8] × W_Q1 = [1.0*0.1+0.5*0.3-0.3*(-0.1)+0.8*0.6,
1.0*0.2+0.5*0.4-0.3*0.5+0.8*(-0.2)]
= [0.1+0.15+0.03+0.48, 0.2+0.2-0.15-0.16]
= [0.76, 0.09]
词2: [0.2, 0.9, 0.4, -0.1] × W_Q1 = [0.2*0.1+0.9*0.3+0.4*(-0.1)-0.1*0.6,
0.2*0.2+0.9*0.4+0.4*0.5-0.1*(-0.2)]
= [0.02+0.27-0.04-0.06, 0.04+0.36+0.2+0.02]
= [0.19, 0.62]
Q1 = [[0.76, 0.09], [0.19, 0.62]]
类似地计算K1、V1...
假设得到:
K1 = [[0.35, 0.25], [0.42, 0.18]]
V1 = [[0.21, 0.33], [0.28, 0.15]]步骤2:计算注意力分数
缩放因子: √d_k = √2 ≈ 1.414
计算Q1 × K1ᵀ:
[0.76, 0.09] × [0.35, 0.42]ᵀ = 0.76*0.35 + 0.09*0.42 = 0.266 + 0.0378 = 0.3038
[0.76, 0.09] × [0.25, 0.18]ᵀ = 0.76*0.25 + 0.09*0.18 = 0.190 + 0.0162 = 0.2062
[0.19, 0.62] × [0.35, 0.42]ᵀ = 0.19*0.35 + 0.62*0.42 = 0.0665 + 0.2604 = 0.3269
[0.19, 0.62] × [0.25, 0.18]ᵀ = 0.19*0.25 + 0.62*0.18 = 0.0475 + 0.1116 = 0.1591
分数矩阵: [[0.3038, 0.2062], [0.3269, 0.1591]]
缩放后: [[0.215, 0.146], [0.231, 0.112]]步骤3:softmax得到权重
第一个词的注意力(对自身的权重):
exp(0.215)=1.240, exp(0.146)=1.157
权重: 1.240/(1.240+1.157)=0.517, 1.157/2.397=0.483
第二个词的注意力:
exp(0.231)=1.260, exp(0.112)=1.118
权重: 1.260/(1.260+1.118)=0.530, 1.118/2.378=0.470
权重矩阵: [[0.517, 0.483], [0.530, 0.470]]步骤4:加权求和
头1输出 = 权重 × V1
第一个词输出:
维度1: 0.517*0.21 + 0.483*0.28 = 0.1086 + 0.1352 = 0.2438
维度2: 0.517*0.33 + 0.483*0.15 = 0.1706 + 0.0725 = 0.2431
→ [0.244, 0.243]
第二个词输出:
维度1: 0.530*0.21 + 0.470*0.28 = 0.1113 + 0.1316 = 0.2429
维度2: 0.530*0.33 + 0.470*0.15 = 0.1749 + 0.0705 = 0.2454
→ [0.243, 0.245]
头1最终输出: [[0.244, 0.243], [0.243, 0.245]]多头注意力的核心是 “分而治之,合而为一”:每个头算出独立的注意力输出(维度为 d_k),先把所有头的输出按维度拼接,恢复到和输入一样的 d_model 维度。
步骤5:拼接
头 1 输出(2 个词,每个词 d_k=2 维):
[[0.244, 0.243], [0.243, 0.245]]
头 2 输出(2 个词,每个词 d_k=2 维):
[[0.355, 0.343], [0.343, 0.345]]拼接规则:把每个词在不同头的维度 “串起来”(维度从 [序列长度, d_k] → [序列长度, h×d_k],而 h×d_k = d_model)。计算过程:
词 1:头 1 的 [0.244, 0.243] + 头 2 的 [0.355, 0.343] → 拼接后 [0.244, 0.243, 0.355, 0.343]
词 2:头 1 的 [0.243, 0.245] + 头 2 的 [0.343, 0.345] → 拼接后 [0.243, 0.245, 0.343, 0.345]拼接后的整体输出:
[[0.244, 0.243, 0.355, 0.343], # 词1(4维,和输入X的维度一致)
[0.243, 0.245, 0.343, 0.345]] # 词2(4维)步骤6:线性变换(可选但必须)
拼接后并不是最终输出,还要过一个全局的线性变换矩阵 W_O(维度 d_model × d_model),目的是把拼接后的特征做一次融合,让模型学习如何整合不同头的信息。
这一步是多头注意力(MHA)的标准流程,补充完整的 MHA 公式:MHA(X)=Concat(head1,head2,...,headh)⋅W_0
假设我们定义 W_0(4×4 矩阵,d_model=4):
W_O = [[0.1, 0.2, 0.3, 0.4],
[0.2, 0.1, 0.4, 0.3],
[0.3, 0.4, 0.1, 0.2],
[0.4, 0.3, 0.2, 0.1]]用拼接后的输出 × W_O 计算最终结果(以词 1 为例):
词 1 最终输出 = [0.244, 0.243, 0.355, 0.343] × W_O= 0.244×0.1 + 0.243×0.2 + 0.355×0.3 + 0.343×0.4 = 0.0244 + 0.0486 + 0.1065 + 0.1372 = 0.3167= 0.244×0.2 + 0.243×0.1 + 0.355×0.4 + 0.343×0.3 = 0.0488 + 0.0243 + 0.142 + 0.1029 = 0.318= 0.244×0.3 + 0.243×0.4 + 0.355×0.1 + 0.343×0.2 = 0.0732 + 0.0972 + 0.0355 + 0.0686 = 0.2745= 0.244×0.4 + 0.243×0.3 + 0.355×0.2 + 0.343×0.1 = 0.0976 + 0.0729 + 0.071 + 0.0343 = 0.2758
最终 MHA 输出(简化后):
[[0.3167, 0.318, 0.2745, 0.2758], # 词1
[0.315, 0.317, 0.273, 0.274]] # 词2(词2计算逻辑同上)合并的意义
- 每个头只捕捉了部分依赖关系(比如头 1 抓语法、头 2 抓语义),拼接 + 线性变换能把这些信息融合成完整的特征;
- 输入 X 是 d_model 维(4 维),输出也需要保持 d_model 维,才能和后续的前馈网络、残差连接等模块衔接。
- 最终输出维度和输入 X 一致(这里是 2 个词 ×4 维),保证整个 Transformer 网络的维度统一。
注意这里W_0是纯线性的,因为我们这个例子本身是一个自回归的一个任务,如果是分类或者文本生成就得涉及到非线性函数了。
06、代码实战
三种注意力机制的缩放点积对比
1. MHA中的缩放点积
# 每个头独立计算
for i in range(num_heads):
Q_i = X @ W_Q[i] # (n, d_k)
K_i = X @ W_K[i] # (n, d_k)
V_i = X @ W_V[i] # (n, d_v)
# 缩放点积注意力
scores = Q_i @ K_i.T / sqrt(d_k) # (n, n)
weights = softmax(scores, dim=-1) # (n, n)
head_i = weights @ V_i # (n, d_v)2. MQA中的缩放点积
# 多个Q,共享K和V
Q_all = X @ W_Q_all # (n, h×d_k) -> reshape -> (h, n, d_k)
K_shared = X @ W_K_shared # (n, d_k)
V_shared = X @ W_V_shared # (n, d_v)
heads = []
for i in range(num_heads):
Q_i = Q_all[i] # (n, d_k)
# 缩放点积注意力(共享K和V)
scores = Q_i @ K_shared.T / sqrt(d_k) # (n, n)
weights = softmax(scores, dim=-1) # (n, n)
head_i = weights @ V_shared # (n, d_v)
heads.append(head_i)3. GQA中的缩放点积
# 分组共享K和V
num_groups = num_heads // group_size
Q_all = X @ W_Q_all # (n, h×d_k) -> reshape -> (h, n, d_k)
K_groups = []
V_groups = []
for g in range(num_groups):
K_g = X @ W_K[g] # (n, d_k)
V_g = X @ W_V[g] # (n, d_v)
K_groups.append(K_g)
V_groups.append(V_g)
heads = []
for i in range(num_heads):
group_id = i // group_size
Q_i = Q_all[i] # (n, d_k)
K_shared = K_groups[group_id] # (n, d_k)
V_shared = V_groups[group_id] # (n, d_v)
# 缩放点积注意力(组内共享K和V)
scores = Q_i @ K_shared.T / sqrt(d_k) # (n, n)
weights = softmax(scores, dim=-1) # (n, n)
head_i = weights @ V_shared # (n, d_v)
heads.append(head_i)实际代码实现示例
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Q: (batch_size, num_heads, seq_len_q, depth)
K: (batch_size, num_heads, seq_len_k, depth)
V: (batch_size, num_heads, seq_len_v, depth_v)
返回: 输出, 注意力权重
"""
# 1. 计算点积
matmul_qk = torch.matmul(Q, K.transpose(-2, -1)) # (..., seq_len_q, seq_len_k)
# 2. 缩放
dk = K.size()[-1]
scaled_attention_logits = matmul_qk / math.sqrt(dk)
# 3. 应用mask(可选)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# 4. softmax得到权重
attention_weights = F.softmax(scaled_attention_logits, dim=-1) # (..., seq_len_q, seq_len_k)
# 5. 加权求和
output = torch.matmul(attention_weights, V) # (..., seq_len_q, depth_v)
return output, attention_weights
# 测试示例
batch_size = 2
num_heads = 8
seq_len = 10
depth = 64
Q = torch.randn(batch_size, num_heads, seq_len, depth)
K = torch.randn(batch_size, num_heads, seq_len, depth)
V = torch.randn(batch_size, num_heads, seq_len, depth)
output, weights = scaled_dot_product_attention(Q, K, V)
print(f"输出形状: {output.shape}") # (2, 8, 10, 64)
print(f"权重形状: {weights.shape}") # (2, 8, 10, 10)总结
无论是MHA、MQA还是GQA,它们都使用相同的缩放点积注意力核心计算,区别只在于如何生成Q、K、V矩阵以及如何组织计算。这种统一性使得注意力机制既强大又灵活,成为了现代深度学习的基石。


本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号