NVIDIA 与 AMD GPU 指令集到底差在哪?看懂为什么代码移植很难保住性能

NVIDIA 与 AMD GPU 指令集到底差在哪?看懂为什么代码移植很难保住性能

GPUS Lady
发布于 2026-03-05 12:53:29
发布于 2026-03-05 12:53:29
在指令集架构(ISA)层面,NVIDIA 和 AMD 几乎在所有核心设计上都分道扬镳。下面用通俗的语言,带你看懂两者底层最关键的差异,也明白为什么直接把 N 卡代码转到 A 卡,性能往往会 “翻车”。
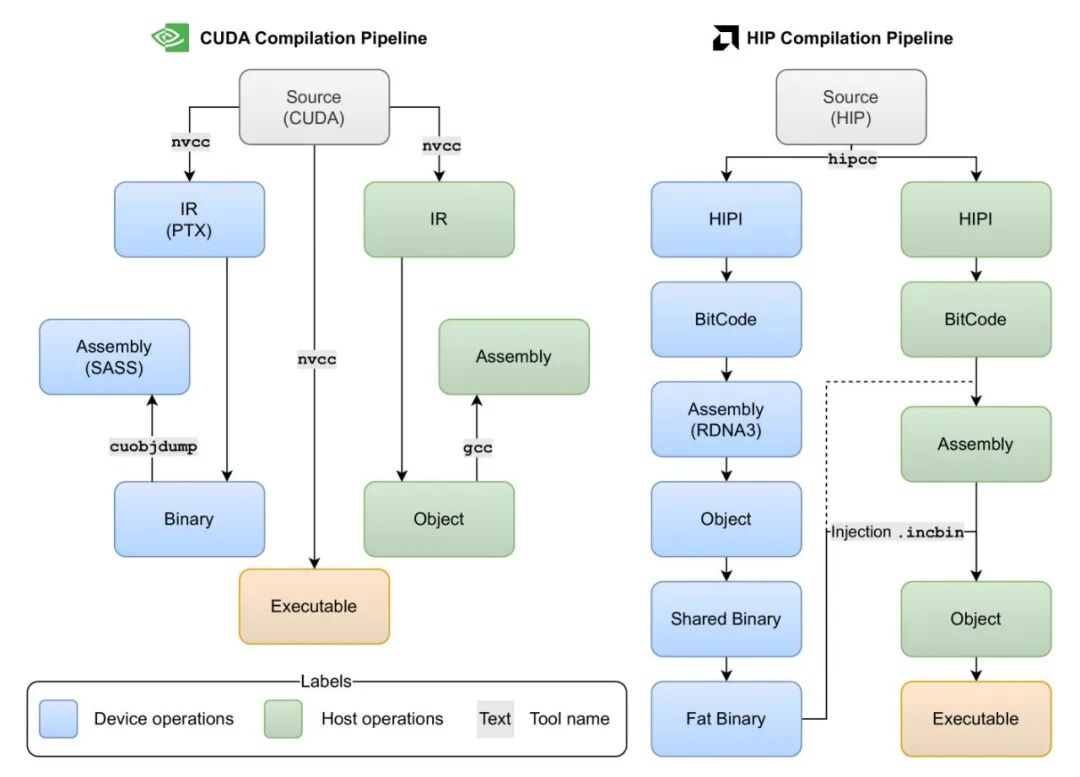
一、指令长度与调度:一个 “写死”,一个 “显式等”
NVIDIA
每条 SASS 指令固定128 位:64 位操作码 + 64 位控制字。
控制字里直接塞了:停顿周期、调度提示、依赖屏障等信息。
编译器ptxas会把所有调度决策直接编译进二进制,硬件拿到就按写好的流程跑。
AMD
指令只有32 位或 64 位,不带任何调度信息。
编译器要手动插入S_WAITCNT指令,相当于告诉硬件:“等一下,最多还剩 N 条向量内存操作没做完。”
延迟隐藏全靠三类显式计数器:
简单说:NVIDIA 是编译器包办调度,AMD 是代码手动控制等待。
二、FP8 格式:名字一样,数值完全不同
两家都叫FP8,但编码规则天差地别:
NVIDIA Hopper(H100):用 OCP 标准 E4M3,指数偏移 7,最大值 448。
AMD MI300:用 E4M3FNUZ,指数偏移 8,最大值 240。
同一个 8 位二进制,在两张卡上解出来的浮点数不一样。
再加上负零处理:
NVIDIA:负零合法。
AMD:负零直接当成 NaN(非法值)。
这意味着:在 H100 上量化好的 FP8 模型,直接扔到 MI300 上会直接出乱码,必须做格式转换。MI350(CDNA4)才同时支持两种格式,MI300 不行。
三、寄存器堆:N 卡一套,A 卡三套
NVIDIA
每个 SM 只有一套统一寄存器堆,每线程 256 个寄存器,编译器随便用。
AMD
直接分成三套寄存器,编译器必须严格分类:
VGPR:每通道独立,最多 256 个
SGPR:波前内统一,最多 106 个
AGPR:矩阵累加器
在老一代 CDNA1/2 上,从 AGPR 搬到 VGPR 还要显式指令,有额外开销。
四、标量内存:A 卡有 “专用快车道”
AMD 有一个 NVIDIA 没有的关键设计:
每个计算单元(CU)自带独立标量内存通路 + 16KB 专用 L1。
内核参数、循环边界等标量数据走 SGPR,完全不占向量计算单元开销。
NVIDIA 则是所有数据挤在同一套通用寄存器里,会互相争抢资源。
五、编译器:闭源黑盒 vs 开源透明
NVIDIA
ptxas
编译器完全闭源。
延迟表、调度策略都是商业机密,你看不到它对你的代码做了什么。
AMD
整套编译器基于开源 LLVM。
每一步调度、每一条等待指令、每一次寄存器分配都能查、能改、能审计。
也因此:
AMD 最快的内核(rocBLAS、推理算子)大量用手写汇编。
NVIDIA 最快的内核则是 C++ 内嵌 PTX。开源编译器目前还追不上闭源编译器的极致优化。
六、重点结论:为什么 HIP 移植保不住性能?
很多人以为用hipify把语法从 CUDA 转成 HIP 就完事了,根本不够。
hipify 只做语法翻译,但解决不了:
无法把 NVIDIA 128 位内嵌停顿指令,翻译成 AMD 显式S_WAITCNT。
无法自动把一套寄存器,合理分配到 AMD 三套寄存器里。
无法自动修正 FP8 指数偏移、负零 / NaN 差异。
真正的移植成本,全在指令集架构这一层。这就是为什么同一份代码,在 N 卡跑得飞快,放到 A 卡不深度改造就很难跑满性能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号