同事问我什么是大数据分层?我用“厨房做菜”给他讲明白了!

同事问我什么是大数据分层?我用“厨房做菜”给他讲明白了!

数智转型架构师
发布于 2026-03-04 21:45:32
发布于 2026-03-04 21:45:32
今天上午,我去公司茶水间接咖啡,刚好碰到了隔壁业务部门的产品经理老李(化名)。老李端着杯子,一脸愁容地跟我大吐苦水:“哎,你们数据团队的人说话太难懂了!今天开会,你们那个数据工程师开口就是什么ODS、DWD、DWS、ADS,不仅如此,还一直念叨什么‘建个大宽表’。听得我是一头雾水。我不就是想要一张能展示‘上个月活跃用户购买转化率’的看板吗?弄这么多名词,到底有什么用嘛?”
看着老李抓狂的样子,我忍不住笑了。其实,老李的困惑非常有代表性。不仅是业务人员,很多刚入行的产品经理、甚至是一些前端后端的开发人员,面对大数据平台的复杂架构,都会觉得云山雾罩。
但我跟老李说:“这些看似高深的词汇,其实是任何一家现代企业搭建大数据平台时,必须要构建的最基本架构。不仅如此,咱们现在天天喊着要搞的大模型、要做数据湖,甚至未来要让 AI 来自动帮我们分析数据,全都要仰仗这套基础架构。”
看着老李半信半疑的眼神中流露出对新知识的渴望,我就决定用大白话,把这里面的门道给他,也给屏幕前可能有同样困惑的你,掰开揉碎了讲一讲。
一、 抛开代码,用“中央厨房”搞懂四层架构
为了让你最快地理解这四层架构到底在干嘛,咱们先别想什么服务器啦、数据库、代码什么的,咱们就想象有一家超大型的连锁餐饮中央厨房。
每天,这家餐厅都要接待成千上万的顾客,大家点的菜五花八门。如果每个厨师都是从头开始洗菜、切菜、配料、炒菜,那上菜速度肯定慢得让人砸桌子。为了提高效率,中央厨房必须有一条极其严密的流水线。
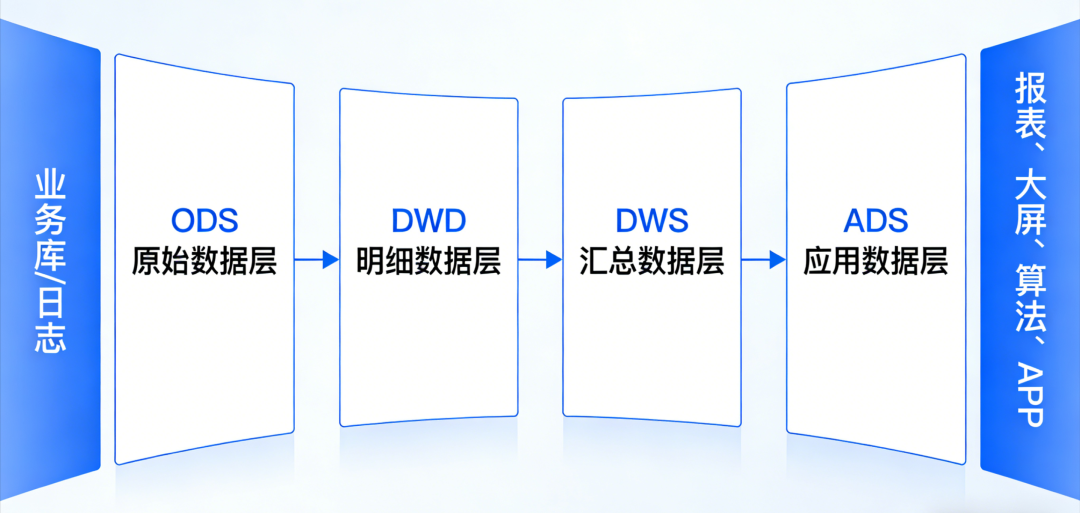
大数据的 ODS、DWD、DWS、ADS 四层架构,干的就是这条流水线的活儿。
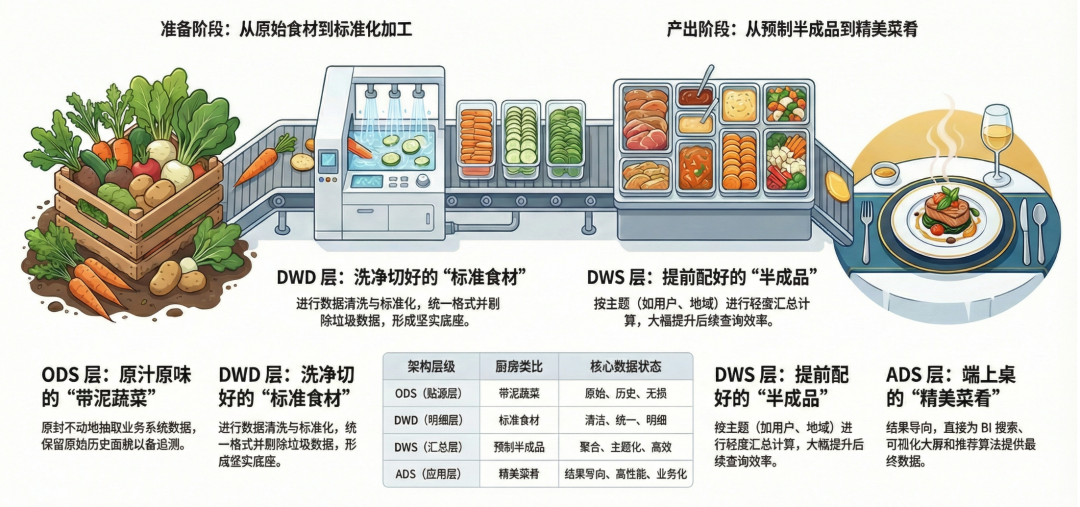
1. ODS(Operational Data Store):数据贴源层 —— 刚买回来的“带泥蔬菜”
每天一大早,采购员会从各个农贸市场买回来大量的蔬菜、鲜肉、活鱼。这些食材都是最原始的状态:萝卜上带着泥,鱼还在水桶里蹦跶,有些菜叶子可能还烂了。
在企业里,这就是 ODS 层。
我们把公司各个业务系统(比如电商系统的订单库、用户注册的后台、甚至是用户在 App 上点来点去的日志记录)里的数据,原封不动地抽过来,放在这里。
ODS 层的特点就是“原汁原味”。业务系统里是什么样,这里就是什么样。它保留了数据最原始的历史面貌,以防后续处理出错了,我们还能回到源头重新查。
2. DWD(Data Warehouse Detail):数据明细层 —— 洗净切好的“标准食材”
带着泥的萝卜是没法直接炒菜的。所以,中央厨房的师傅要把烂叶子摘掉,把萝卜洗干净,统一削皮,切成标准的萝卜丝或萝卜块。
在数据平台里,这就是 DWD 层。
这步极其关键,我们管它叫“数据清洗”和“标准化”。ODS 里的原始数据往往非常的脏乱差:你比如,有的日期写的是“2023-01-01”,有的写的是“23/01/01”;有的用户填了性别,有的没填;甚至还有乱码。
在 DWD 层,工程师们会把这些错乱的数据洗干净,统一格式,把没用的垃圾数据过滤掉,把不同系统里的同一个用户拼接到一起。最后,形成一张张非常干净、详细的基础数据表。这是整个数据仓库最坚实的底座。
3. DWS(Data Warehouse Service):数据汇总层 —— 提前准备好的“半成品”
如果等顾客点了一份“鱼香肉丝”,厨师才去配调料,那就太慢了。所以,有经验的厨房会提前把最常用的调料配好(比如鱼香汁),或者把一些需要炖很久的高汤提前熬好。
对于大数据平台来说,这就是 DWS 层。
如果业务上要看指标:比如“每个省份的日访问量”、“每个用户的月累计消费额”。如果每次看报表都要去 DWD 层几亿条明细数据里现算,服务器早就冒烟了。
所以,我们在 DWS 层,会按照不同的“主题”(比如用户主题、商品主题、地域主题),提前把数据进行轻度的汇总和计算。你想要用户的月消费额?我已经提前按月算好存放在这了,直接拿去用就行。
4. ADS(Application Data Service):数据应用层 —— 端上桌的“精美菜肴”
最后,厨师根据顾客的点菜单,把半成品和准备好的食材下锅翻炒,装入精美的盘子,由服务员端上桌。顾客只管吃就行了。
这就是 ADS 层。
这是距离老李这种业务人员最近的一层。你在 BI (商业智能报表,也有叫数据赋能平台的)里看到的那些酷炫的折线图、饼图,老板每天早上看的大屏数据,业务系统里用到的推荐算法数据,全是从 ADS 层拿出来的。
ADS 层的设计完全是“结果导向”的。业务需要什么报表,我们就用 DWS 或 DWD 的数据组合计算,生成最终的这张 ADS 表。它的结构最简单,查询速度最快,就是为了满足前端应用的需求。
二、 等等,那经常听说的“大宽表”又是啥?
听到这里,老李一拍大腿:“你早这么说我不就明白了!ODS 是进货,DWD 是洗菜,DWS 是备菜,ADS 是上菜。那我们那个数据分析师天天嚷嚷着要的‘大宽表’,又是个什么货?”
我笑着摆摆手:“大宽表不是什么新的一层,它通常存在于 DWS 层或者 ADS 层,它是数据的一种特殊形态。”
咱们继续拿厨房打比方。假设你们餐厅推出了一款极豪华的“佛跳墙”,里面需要用到鲍鱼、海参、干贝等几十种顶级食材。如果厨师每次做这道菜,都要跑去海鲜冰柜拿鲍鱼,跑去干货柜拿干贝,跑去冷鲜库拿高汤……来回跑十几趟,效率极低。
怎么办?厨房会准备一个“超级全家桶配菜盒”——把这几十种食材,按照一份佛跳墙的量,全都装在这一个大盒子里。厨师拿这一个盒子,就能搞定整道大菜。
这个“超级全家桶配菜盒”,就是大宽表。
在数据库里,用户的基础信息(性别、年龄)在一张表里,用户的订单记录在另一张表里,用户的点击行为还在别的表里。如果分析师想要分析“25岁以上、过去一个月买过美妆产品、并且昨天浏览过直播间的女性用户”,数据库在查询时,需要把这好几张表“关联”(Join)在一起才能查。
在大数据环境里,几亿条数据的多表关联是非常极其耗费时间和计算资源的。
为了解决这个问题,工程师会用空间换时间。他们会把这几张表的数据提前“打平”,拼接到一张极其庞大的表里。这张表可能只有一行代表一个用户,但是它可能有几百个甚至上千个“列(字段)”:包含了这个用户的年龄、性别、注册时间、最近一次购买时间、累计消费金额、最爱商品类目等等各种维度的数据。
因为这张表在结构上“非常宽”(列特别多),所以顾名思义叫“大宽表”。有了它,业务分析师(或者 AI)在做复杂查询或者跑机器学习模型时,只需要查这一张表就行了,速度自然就快起来了!
如果你还是有点晕,看下面这张图就懂了:
三、 那么,这两年爆火的“数据湖”又是来干嘛的?
搞懂了四层架构和大宽表,老李喝了口咖啡,抛出了第二个大问题:“既然你们这个流水线已经这么完美了,为什么现在公司大群里天天有人喊着要搞‘数据湖’?这和四层架构矛盾吗?”
“不仅不矛盾,还是天作之合。”我顺着刚才的比喻往下走。
过去这十几年,咱们的“中央厨房”(数据仓库)处理的都是结构化、规规矩矩的数据。比如 Excel 表格一样的订单记录、用户信息。这些数据像大米、白面一样好处理。
但是时代变了,现在企业里产生了大量稀奇古怪的数据:比如客服中心的通话录音、短视频平台里海量的视频文件、用户上传的图片、甚至是一大串毫无规律的机器传感器日志。你要是硬把一段视频塞进“大宽表”里,数据库非得崩溃不可。
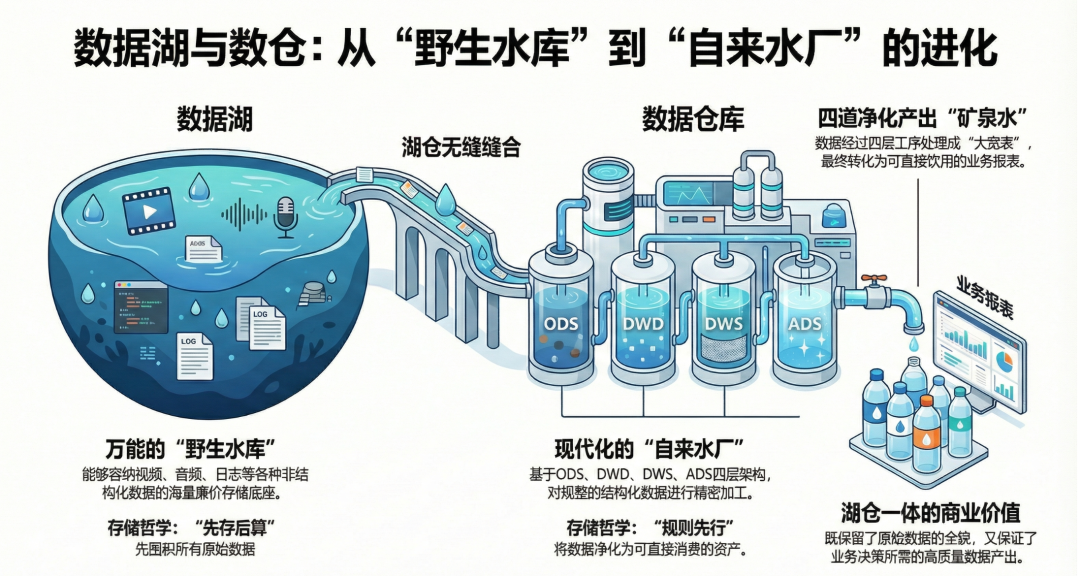
所以,我们需要一个“数据湖”。
顾名思义,数据湖就像是一个深不见底的天然大湖泊。它的核心哲学是:“有容乃大,先存进来再说”。
不管你是清澈的泉水(结构化数据),还是带着泥沙的洪水(非结构化数据如视频、音频),统统先引流到这个大湖里囤起来。因为现在存数据的硬盘成本非常便宜,所以不怕你数据多。
数据湖和四层架构的关系,其实就是“野生水库”与“自来水厂”的关系。
数据湖提供了海量、廉价、包容万象的存储底座。而我们的 ODS、DWD、DWS、ADS 四层架构,就像是建立在这个大湖旁边的一座高度现代化的“水质净化厂”。
我们从湖里抽取有价值的水源,经过严密的四道工序净化,或者装成大容量的“大宽表(超级水塔)”,最后变成可以直接饮用的矿泉水(业务报表),输送给千家万户。业界现在很火的“湖仓一体”,就是把这俩无缝缝合在一起。
四、 面对未来的 AI 时代,这套架构扛得住吗?
老李听到这里,频频点头,但他紧接着抛出了很前卫的一个问题:
“现在全网都在炒作 AI 大模型。如果未来,我想直接对 AI 说一句:‘帮我算一下上个月高价值用户的留存率’,AI 能直接去你们那个什么大宽表里找到对应的数据,把报表给我画出来吗?”
我放下咖啡杯,严肃地告诉他:“很抱歉,在目前的纯传统架构下,AI 根本看不懂。 这也是我们数据团队目前最焦虑的事情。”
为什么?因为这触及了当前数据平台建设中最核心的一个痛点——机器无法理解“业务语义”。
咱们想象一下 AI 看到“大宽表”时的场景。AI 兴冲冲地钻进去,看到一张表叫 user_wide_table_v2,里面有几个字段叫 act_type、is_vip_flag。
AI 直接傻眼了:
user_wide_table_v2 到底包含哪些用户?全量用户还是仅限国内用户?
act_type 里面存了数字 1 和 2,1 是代表“浏览”还是代表“加入购物车”?
业务口中的“高价值用户”,到底是指“每个月消费超过 1000 元”,还是指“每个月登录超过 20 天”?AI从哪个数据表中也找不到明确的解释,没办法我们现在只能通过写提示词这种笨办法来告诉它,这很考验工程师的业务理解能力和表达能力,而且这些提示词也很难实现复用。
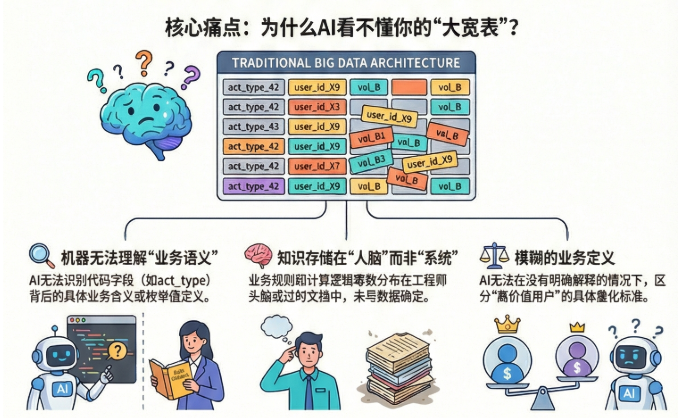
说白了,现有的大数据四层架构和大宽表,主要是为了人(数据分析师)和“传统的 BI 系统”设计的。虽然我们做了清洗和汇总,但这些表背后的“潜规则”和“业务含义”,全部都记在工程师的脑子里,或者零散地躺在没人更新的 Word 文档里。
要让未来的 AI 真正能够自己去大数据平台里“找菜、做菜”,现在的架构必须进行一次从内到外的革命:
1. 极其严苛的“元数据管理”与“业务数据字典”
未来,我们不能只存数据本身,还必须存储关于数据的“说明书”。这张大宽表是谁建的、每个字段对应的中文业务含义是什么、枚举值(比如 1 和 2)代表什么。这就要求我们在构建四层架构的同时,强制绑定一套高质量的“元数据字典”。没有说明书的食材,绝对不允许放入中央厨房。
2. 建立独立于数据的“语义层”
这是未来极其关键的一环。我们需要在 DWS 和 ADS 层之上,架设一层独立的“语义层”。
这就像是给 AI 配备了一个精通业务的“翻译官”。把复杂的 SQL 逻辑和冷冰冰的字段名,翻译成大语言模型能听懂的“自然语言”。比如,在语义层明确定义:高价值用户 = 过去30天内消费金额 >= 1000元的活跃用户。AI 只有读懂了这个翻译字典,才能去底层大宽表里精准抓取数据。
3. 专为大模型打造的“向量化”改造
AI 处理文本和图像的能力极强,但它更喜欢“向量”形式的数据。未来,我们的数据湖或者数据仓库中,不仅要存大宽表这种结构化表格,还要把海量的非结构化数据(如产品评论、客服记录)转化为“向量数据库(Vector Database)”能存的格式。这样 AI 才能实现真正跨越文本、图像和结构化数据的“联合查询”。
4. 从源头开始的数据治理
如果 ODS 层进来的数据本身就是错的,AI 哪怕再聪明,算出来的结果也是不准确的。因此,面向 AI 的数据架构,要求我们将数据质量监控的关口前移,必须在业务系统录入阶段就做到规范化。
五、 写在最后
跟老李聊完这些,他长舒了一口气,我也觉得仿佛完成了一次布道。
其实,无论是 ODS 到 ADS 的四层分层,还是为了提效而建的大宽表,亦或是包容万象的数据湖,其实其本质并没有变:技术永远在为业务服务。
数据就像是企业地下流淌的石油,架构设计得好不好,决定了我们是只能粗放地燃烧它取暖,还是能把它提炼成高辛烷值的航空燃油,推动企业这架飞机在 AI 时代一飞冲天。
作为在传统企业里摸爬滚打的一员,搞懂这些概念,并不是为了让我们去抢程序员的饭碗,而是为了在跨部门协作时,我们能用同一套语言沟通,能理解系统能力的边界,也能更好地拥抱即将到来的智能化时代。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号