ollama v0.17.0 更新:OpenClaw 一键自动安装、Web 搜索支持、全新 Context 动态分配与 Tokenizer 性能大幅优化!

ollama v0.17.0 更新:OpenClaw 一键自动安装、Web 搜索支持、全新 Context 动态分配与 Tokenizer 性能大幅优化!

福大大架构师每日一题
发布于 2026-03-04 19:43:56
发布于 2026-03-04 19:43:56
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
2026 年 2 月 24 日,Ollama 发布了全新的 v0.17.0 版本。这一次更新可谓意义重大,不仅引入了全新的 OpenClaw 自动化集成与安装能力,还针对核心 Tokenizer 性能、VRAM 动态上下文分配、系统配置迁移逻辑、Web 搜索插件 等功能进行了深层次优化。这是一次面向 AI 模型本地化与云端融合、性能与易用性双提升的版本升级。
本文将全面解析 Ollama v0.17.0 的更新亮点、底层代码变化及其背后的设计逻辑,帮助开发者和高级用户快速理解这一版本的重要意义。
一、版本概览
版本号: v0.17.0 发布日期: 2026 年 2 月 24 日 代号: OpenClaw 核心变化:
- • OpenClaw 可通过 Ollama 自动安装、自动配置
- • 云模型自动启用 Web 搜索能力
- • 新的 VRAM 动态上下文长度机制
- • 数据库 schema 升级至 v14
- • Tokenizer 性能全面提升
- • macOS / Windows 应用默认上下文长度将基于显存自动配置
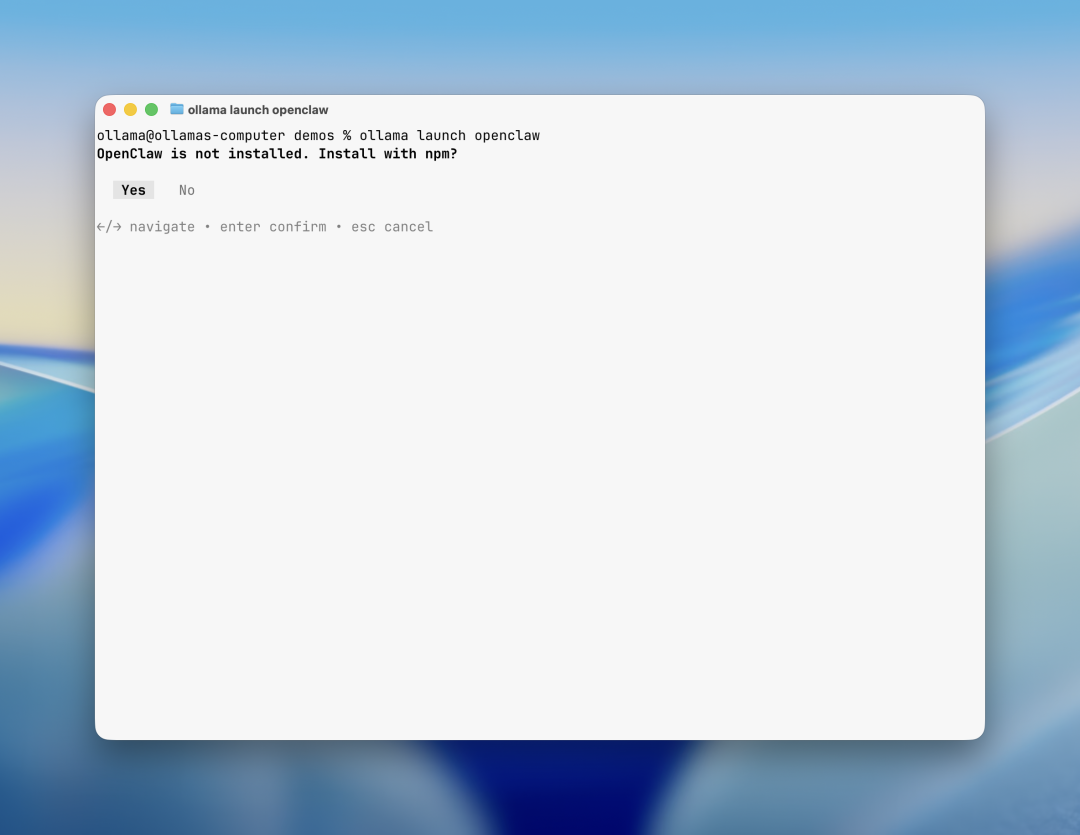
执行命令即可快速启动:
ollama launch openclaw二、OpenClaw:从手动部署到自动安装
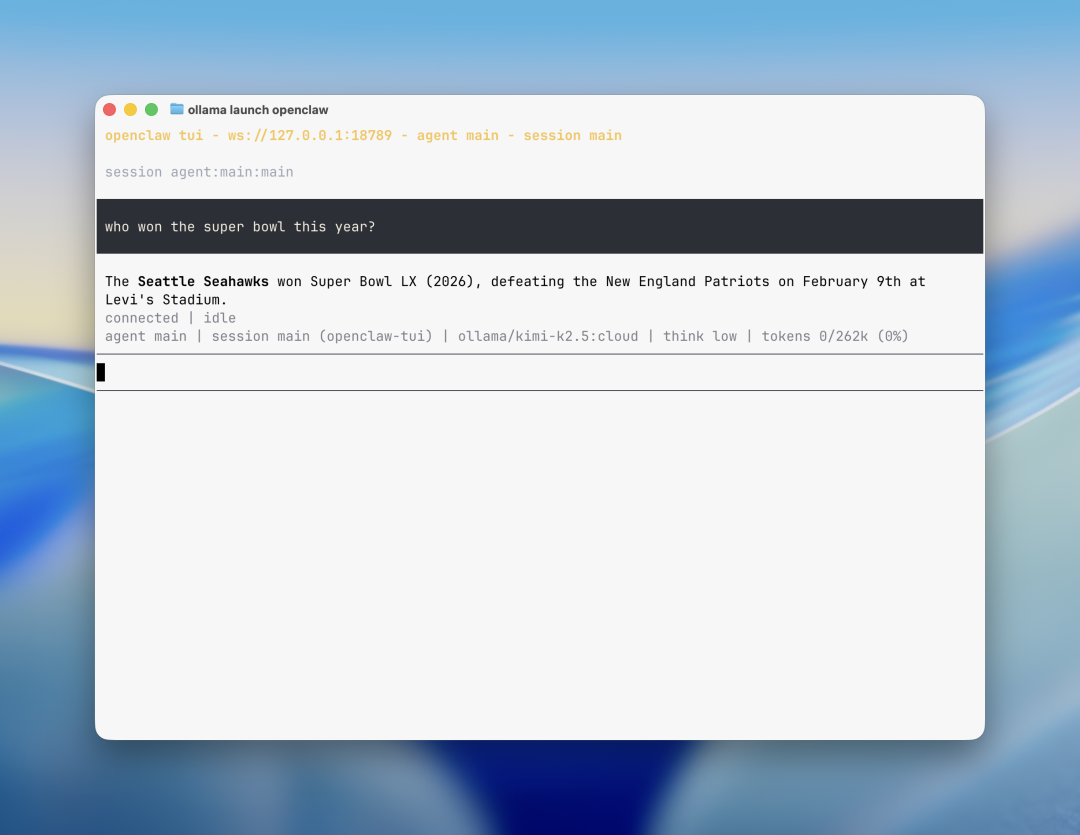
OpenClaw 是 Ollama 生态中的关键应用,它是一个运行在本地系统上的个人 AI 助手,能够把 WhatsApp、Telegram、Slack、Discord、iMessage 等消息服务与本地 AI 模型连接起来,实现跨平台智能交互。
在 v0.17.0 中,Ollama 引入了全新的 自动安装与集成机制,让 OpenClaw 能够一键配置:
- • Ollama 会检测系统环境并自动安装 OpenClaw;
- • 若未安装,将提示通过 npm 自动安装;
- • 启动流程包括安装、安全提示、模型选择、网关配置和启动;
- • 支持本地模型与云模型自动联动。
示例启动步骤:
ollama launch openclaw该命令会自动完成以下过程:
- 1. 检查 OpenClaw 是否已安装;
- 2. 如果未安装,执行 npm 安装;
- 3. 自动执行安全检查;
- 4. 启动模型选择器,支持 kimi-k2.5、glm-5、minimax-m2.5 等开放模型;
- 5. 自动启动后台网关守护进程。
新版本中还引入了 EnsureInstalled 机制:
if !AutoInstallable(name) { return nil }
if IsIntegrationInstalled(name) { return nil }
_, err := ensureOpenclawInstalled()
return err这意味着 OpenClaw、Clawdbot、Moltbot 都可以被 Ollama 自动检测与安装,无需手动干预。
三、Web 搜索新特性:云模型时代的增强能力
在使用云模型的场景下(如 kimi-k2.5:cloud、glm-5:cloud),Ollama v0.17.0 新增了 Websearch 插件支持,即 OpenClaw 能够自动调用网络搜索功能。
新增逻辑位于:
cmd/config: install web search plugin to user-level extensions dir这意味着在云端模型推理时,OpenClaw 可以根据用户问题动态调用实时网络信息,实现动态问题感知与上下文信息更新。这在代码生成、信息检索、任务自动化等场景中尤为关键。
四、VRAM 动态上下文长度:让模型智能适配显存
此前版本中,Ollama 使用固定 4096 context length。v0.17.0 版本则引入了全新的 基于 VRAM 动态上下文机制,上下文长度会自动根据可用显存进行推算。
关键变化:
- • 数据结构中新增 DefaultContextLength:
type InferenceInfo struct {
Computes []InferenceCompute
DefaultContextLength int
}- • 正则表达式识别日志中的 VRAM 配置信息:
defaultCtxMarker := regexp.MustCompile(`vram-based default context`)
defaultCtxRegex := regexp.MustCompile(`default_num_ctx=(\d+)`)- • 数据库迁移逻辑更新:
// migrateV13ToV14 changes the default context_length from 4096 to 0
UPDATE settings SET context_length = 0 WHERE context_length = 4096
UPDATE settings SET schema_version = 14- • 这代表从固定配置转变为动态配置,当显存较大时上下文自动调高,提升推理性能。
五、数据库 Schema 升级:从 v13 到 v14
当前版本号: 14 变化内容:
- • 原字段
context_length默认值从 4096 改为 0; - • 0 代表开启 VRAM 动态推理上下文功能;
- • 所有现有配置会自动迁移。
升级逻辑在 migrateV13ToV14 中定义,新增测试覆盖:
func TestMigrationV13ToV14ContextLength(t *testing.T)确保旧数据库升级后不会出现上下文错位或默认值丢失问题。
六、UI 改进:交互界面更智能
UI 代码也完成了同步迭代,增强了配置界面的智能体验:
- 1. 设置界面自动获取 Inference 信息
const { data: inferenceComputeResponse } = useQuery({
queryKey: ["inferenceCompute"],
queryFn: getInferenceCompute,
});
const defaultContextLength = inferenceComputeResponse?.defaultContextLength;- 2. 界面控件根据 defaultContextLength 自动禁用
<Slider
value={settings.ContextLength || defaultContextLength || 0}
disabled={!defaultContextLength}
/>- 3. Slider 新增禁用态与透明度控制
<div className={`space-y-2 ${disabled ? "opacity-50" : ""}`} ref={ref}>当模型尚未加载时,滑块灰显,避免误操作。
七、TUI(终端界面)改进与 Auto-install 快捷交互
命令行交互界面以及 TUI(text UI)在 v0.17.0 中进行了深度集成改造:
逻辑优化:
- • 如果某集成包未安装且属于可自动安装类别(如 OpenClaw),会提示“Press enter to install”;
- • 增加提示标记
(install); - • 防止误选未安装的普通插件。
if config.AutoInstallable(item.integration) {
title += " (install)"
} else {
title += " (not installed)"
}同时确保 UI 光标交互与快捷键反馈一致性。
八、文档更新:更清晰、更易用的 OpenClaw 指南
新版文档强化了 OpenClaw 快速上手 体验,并更新了命令使用方式:
快速启动
ollama launch openclaw无需复杂配置,一键即可启动。系统会提示模型选择与安全说明。
配置启动
ollama launch openclaw --config或使用:
openclaw configure --section channels推荐模型
- • 云端模型:kimi-k2.5:cloud、minimax-m2.5:cloud、glm-5:cloud
- • 本地模型:glm-4.7-flash(约 25GB VRAM)
注意事项
建议为 OpenClaw 使用至少 64k tokens 的上下文窗口,以保证长对话上下文与代码编辑智能性。
九、Tokenizer 核心性能优化:更快速、更准确、更高吞吐
v0.17.0 的 Tokenizer 模块改写为高性能版本(x/tokenizer/tokenizer.go),重点优化以下方面:
1. 支持多种 TokenizerType
TokenizerBPE、TokenizerSentencePiece2. 加入多 EOS 支持
3. 预缓存 byte-level 编码
4. 支持并行编码 根据输入长度自动判断是否启用多线程:
encodeParallelMinInputBytes = 4 * 10245. 全新 UTF-8 有效前缀输出策略:
flushValidUTF8Prefix确保流式输出时不会截断多字节字符。
Tokenizer 基准测试新增
完整的性能基准包括:
- • BPE 编码、解码;
- • WordPiece;
- • SentencePiece;
- • Mini-LLaMA 模型全流程;
- • LoadFromBytes 性能。
测试覆盖范围广泛,性能优化在长文本场景下尤为明显。
十、MLX Runner 改进:动态加载与内存优化
在底层推理模块(x/mlxrunner/mlx/dynamic.go)中,v0.17.0 新增了更智能的动态库加载策略:
- • 优先从 rpath 加载;
- • 兼容 Linux 与 macOS;
- • 移除了不必要的错误日志输出,减少控制台噪音。
libraryName := "libmlxc.so"
if C.mlx_dynamic_load(&handle, cPath) != 0 {
return false
}同时增加了 UTF-8 安全输出机制,防止推理输出中乱码或断字问题。
十一、细节优化与稳定性提升
- • macOS / Windows 版 Ollama 将默认根据显存自动设置上下文长度;
- • 修复了动态库加载的错误输出冗余;
- • 修复了配置文件迁移中部分集成丢失别名的 bug;
- • 优化了数据库清理逻辑;
- • 新 UI 默认 ContextLength=0,即开启动态上下文机制;
- • 全面增强测试覆盖率,包括超时测试、迁移测试、UTF-8 流输出测试、特性行为回归测试等。
十二、总结:v0.17.0 是“智能自动化”的关键里程碑
代码地址:github.com/ollama/ollama
Ollama v0.17.0 的核心目标是让复杂 AI 模型集成与推理环境更加自动化、智能化、用户友好:
- • OpenClaw 一键集成自动化 —— 无需安装脚本,自动配置环境;
- • Websearch + 云模型结合 —— 即时联网回答不再受限;
- • Tokenizer 全性能重构 —— 更快更稳;
- • VRAM 自适应上下文机制 —— 自动根据显存调整模型上下文,性能更优;
- • 数据库与 UI 全链路适配 —— 迁移平滑、交互更直观。
本次更新不仅优化了底层推理管线与数据库结构,也重新定义了 Ollama 的可扩展性与生态集成路径。对于开发者而言,v0.17.0 不仅提升了执行效率,更显著降低了环境配置与模型集成的门槛。
一句话总结:
Ollama v0.17.0 = 自动化 AI 助手 + 智能上下文 + 极速 Tokenizer + 一键全生态集成。
·
我们相信人工智能为普通人提供了一种“增强工具”,并致力于分享全方位的AI知识。在这里,您可以找到最新的AI科普文章、工具评测、提升效率的秘籍以及行业洞察。 欢迎关注“福大大架构师每日一题”,发消息可获得面试资料,让AI助力您的未来发展。
·
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号