1秒传700部电影!三星HBM4量产,英伟达打响下一场封神战

1秒传700部电影!三星HBM4量产,英伟达打响下一场封神战

Henry Zhang
发布于 2026-03-04 12:56:12
发布于 2026-03-04 12:56:12

题图摄于广州珠江河畔
想象一下,你花重金买了一辆顶级超跑,结果每天只能在拥堵的市区道路上龟速行驶——这就是当前AI芯片面临的尴尬局面。
2026年2月,三星电子宣布了一个重磅消息:第六代高带宽内存(HBM4)正式量产,并且首批供货给英伟达的下一代 AI 平台 Vera Rubin。这则新闻在半导体圈引发轰动,但对于普通人来说,可能只是一条“不明觉厉”的技术快讯。
这个 HBM4 到底是什么神仙技术?它凭什么能成为 AI 算力的“救命稻草”?
从“提高车速”到“拓宽车道”
要理解 HBM4 的革命性,得先明白 AI 芯片的“瓶颈”在哪。
现在的 AI 大模型(比如 Gemini、豆包等)就像一群超级饿的“吃货”,需要不停地“吃”数据。GPU 是“厨师”,负责计算;而内存就是“服务员”,负责上菜。问题是,厨师的手速越来越快,服务员却跑不动了——这就是业内常说的“存储墙”困境。
前几代内存(HBM3、HBM3E)是怎么解决这个问题的?答案是:让服务员跑得更快。单引脚传输速率从几 Gbps 一路飙到 9.6 Gbps 。但这就好比让服务员穿轮滑鞋上菜,速度快了,摔倒的风险也直线上升——电磁干扰、信号失真、功耗飙升,这些问题让工程师们头疼不已。
三星 HBM4 的解决方案简单粗暴却极其有效:不提高车速,而是拓宽车道。

HBM4 将物理接口位宽从 1024 位直接翻倍到 2048 位。啥意思?原来只有一条双车道,现在直接变成四车道。即使车速不变,单位时间内能通过的“数据车辆”也翻了一番。
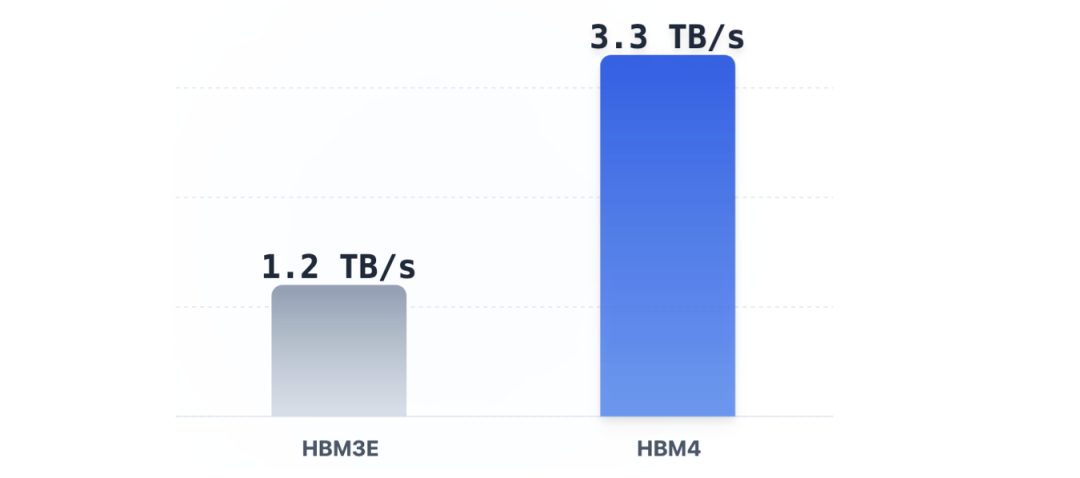
结果呢?单堆栈带宽飙到了惊人的 3.3 TB/s——这相当于一秒钟能传输近 700 部 4K 电影。对比上一代 HBM3E 的 1.2 TB/s,提升幅度高达 2.7 倍。
从“被动存储”到“主动计算”
HBM4 还有一个更本质的变化:它的“底座”升级了。
传统 HBM 的底层芯片(Logic Base Die)通常用成熟的 DRAM 工艺制造,功能单一,就是个“信号转接板”。但 HBM4 首次引入了 4nm/5nm 先进逻辑工艺来制造这个底座。

这一改,底座直接从“保安”变成了“管家”。
现在,这个底座不仅能管理数据进出,还能自己做一些简单的计算——比如数据预处理、纠错、甚至部分AI运算。这就是所谓的“近内存计算”技术。以前,数据必须在内存和 GPU 之间来回跑,现在有些活儿直接在内存里就干完了,延迟大大降低,功耗也省了。
打个比方:以前你要查资料,得跑到图书馆(GPU),告诉管理员,管理员再去书库(内存)找,然后跑回来告诉你。现在,书库门口就有个咨询台,简单问题直接解决,只有复杂问题才需要去找管理员。
英伟达Vera Rubin:有了“好菜”才能做“大餐”
三星 HBM4 这次是专门为英伟达下一代AI平台 Vera Rubin “量身定制”的。
Vera Rubin 平台的 Rubin R100 GPU,是英伟达首款原生支持 2048 位 HBM4 接口的处理器。每个 R100 配了8个 HBM4 堆栈,总带宽达到惊人的22TB/s——相比前代 Blackwell 平台的 8TB/s,提升了175%!
这意味着什么?
对于万亿参数级别的大模型来说,推理成本直接降到了 Blackwell 的十分之一。原来需要 10 块钱的电费才能回答一个复杂问题,现在 1 块钱就够了。这对于 OpenAI、谷歌、微软这些每天处理海量请求的云服务商来说,省下的可不是小数目。

更牛的是,在 NVL72 机架级别——也就是把 72个 Rubin GPU 连在一起形成一个超级计算机——总显存达到 20.7TB ,总带宽高达 1580TB/s。这种级别的算力底座,才是支撑未来“智能体式AI”(Agentic AI)——那种能自主决策、帮你订机票、点外卖、安排日程的智能助手——真正落地的物质基础。
三星的“翻身仗”与行业变局
这次三星率先量产 HBM4,还有个有趣的故事背景。
在上一代 HBM3E 周期中,三星因为验证进度和能效问题,一度被竞争对手SK海力士和美光甩在后面。这次能够“弯道超车”,靠的是三星独特的“IDM一站式”优势——它同时拥有存储工艺、逻辑代工和先进封装技术。1c DRAM、4nm逻辑芯片、垂直堆叠封装,全部内部完成,开发和良率控制效率极高。
这也反映出整个行业的三个深刻变化:
第一,算力竞赛从“堆规模”转向“抠效率”。以前拼的是谁家GPU多,现在电网受不了了,大家开始拼“每瓦性能”。HBM4带宽提升近3倍,能效反而提升了40%,这才是真正的技术含量。
第二,“定制化显存”时代开启。未来的HBM4不再是标准品,而是根据不同客户需求调整逻辑功能、容量配置,甚至引脚定义。三星和英伟达的深度绑定,本质上是构建一套排他性的硬件生态,让后来者望尘莫及。
这种“黑盒级”绑定源于三星“存储+代工+封装”一站式IDM模式。其内部垂直整合4nm底座与存储,无需跨公司协作。对手面临的不仅是产品竞争,更是被深度锁死的全产业链优势,追赶难度倍增。
第三,存储正在变成“计算的一部分”。随着HBM4逻辑底片工艺成熟,越来越多的AI算力将下沉到内存中。未来的AI芯片,可能不再是“CPU+GPU+内存”的拼盘,而是一个“计算无处不在”的统一体。
结语:通往AGI的物理基石
三星 HBM4 的量产,表面上看是一家公司的产品发布,背后却是人类挑战物理极限的一次胜利。

在 30 微米厚的晶圆上(相当于人类发丝直径的三分之一)打孔、堆叠、连接,还要保证数万个硅通孔精准对位——这种制造工艺的精密程度,已经不亚于在头发丝上雕刻《清明上河图》。
而对于我们普通人来说,HBM4 的意义更简单:更快、更便宜和更智能的 AI 服务。当AI的“记忆”不再成为瓶颈,当机器人能真正记住你上周说过的话、上个月放东西的位置,AGI(通用人工智能)的那一天,也许真的不远了。
毕竟,一个聪明的脑袋,总得配上过目不忘的记忆力才行。
欢迎关注 亨利笔记, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。
近期文章:
现象级开源AI智能体:OpenClaw(Clawdbot)五层架构深度解析
别再只会写提示词了!MCP+Skills这两大杀器,正在终结“AI智障”时代!
打破十年瓶颈!DeepSeek 重构神经网络底层逻辑,V4/R2 渐行渐近
本公众号聚焦人工智能,云原生和区块链等技术原理,请立即关注亨利笔记 ( henglibiji ),以免错过更新。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号