MCP是理想,Skills是现实

MCP是理想,Skills是现实

AI智享空间
发布于 2026-02-27 11:53:37
发布于 2026-02-27 11:53:37
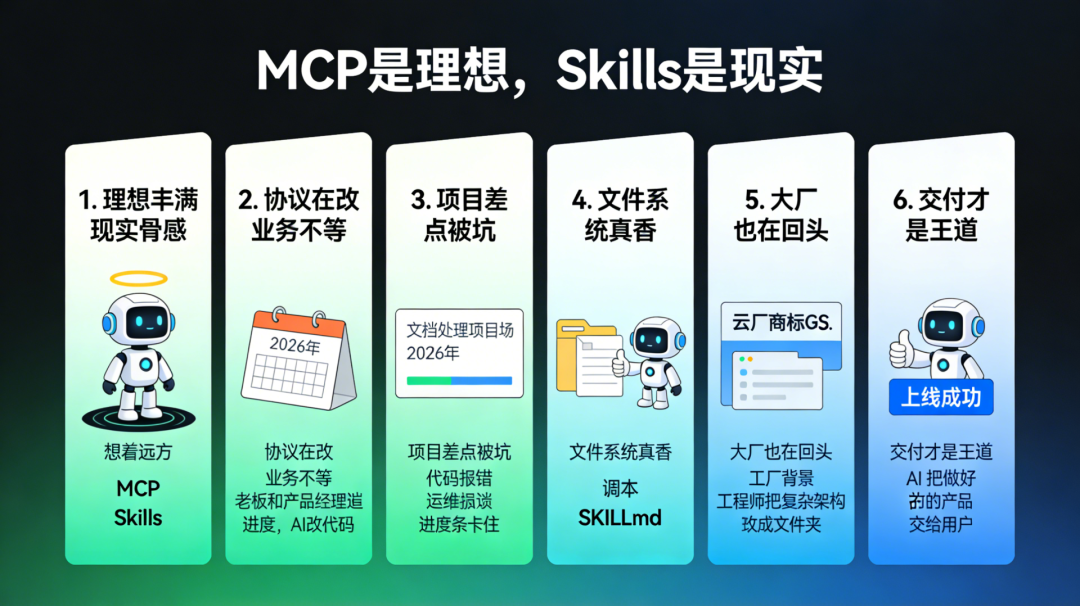
不知道大家有没有这种感觉:2025年下半年,整个AI圈都在谈MCP。Anthropic说要做“AI界的USB”,各家大厂都在喊“Agent互联”,技术社区天天讨论A2A(Agent-to-Agent)的美好未来。但回到现实,老板在催项目进度,产品经理在问“什么时候能上线”,运维在抱怨“又双叒挂了”。
这就是2026年初最尴尬的局面:协议还在演进,业务已经等不及了。今天就来聊聊,为什么说“MCP是理想,Skill是现实”。
01 MCP的美好愿景:AI界的USB梦想
先说清楚,我不是要黑MCP。相反,我非常认同它的设计理念。
MCP想解决的问题其实很明确:让不同的AI Agent能够标准化地交互。就像USB统一了设备接口,MCP想统一Agent之间的通信协议。想象一下这个场景:
你的“数据分析Agent”发现销售额下降,自动调用“市场洞察Agent”分析原因,后者又调用“竞品监控Agent”获取对手动态,最后“决策支持Agent”综合所有信息给出建议。整个过程无需人工介入,Agent之间自动协作,完美!
Anthropic的官方文档里是这么描述MCP的:
- 标准化的消息格式:所有Agent用JSON-RPC通信
- 能力发现机制:Agent可以查询其他Agent提供什么功能
- 安全的权限控制:细粒度的访问控制和数据隔离
- 传输层抽象:支持stdio、HTTP、WebSocket等多种传输方式
技术上看起来很完美对吧?但这里有个致命问题:协议还在快速迭代。
我去年10月开始研究MCP,当时是0.1.x版本。11月升级到0.2.x,消息格式变了;12月又出0.3.x,能力注册机制改了;今年1月0.4.x,权限模型又调整了。每次更新,之前写的代码都得改。
更要命的是,MCP Server的生态还很薄弱。想接入数据库?要么自己写Server,要么等社区实现。想和现有系统集成?对不起,大部分工具还不支持MCP。你会发现,花了两周搞定MCP集成,结果发现能调用的功能还不如直接写API。
说白了,MCP现在处于“技术上可行,工程上不成熟”的阶段。它是未来,但不是现在。
02 现实的拷问:业务等不起协议成熟
讲个真实的故事。去年11月,我们团队接了个项目:给公司做一个智能文档处理系统,要求两个月上线。需求包括:
- 自动解析各种格式的文档(Word、PDF、Excel)
- 提取关键信息生成摘要
- 根据模板生成新文档
- 支持多人协作和版本管理
技术选型的时候,我们其实考虑过MCP方案:
1. 写一个“文档解析MCP Server”,暴露解析能力
2. 写一个“内容生成MCP Server”,负责生成逻辑
3. 用Claude作为协调者,通过MCP协议调度这些Server
方案看起来很优雅,完全符合“Agent互联”的理念。但落地时问题一大堆:
问题一:Server开发成本高 每个MCP Server都要处理:
- JSON-RPC的请求解析和响应封装
- 能力注册和schema定义
- 错误处理和日志记录
- 连接管理和并发控制
光是搭架子就花了一周,还没写业务逻辑。
问题二:调试地狱MCP是跨进程通信,出了问题很难定位:
- 是Claude调用Server的问题?
- 还是Server内部逻辑的问题?
- 还是参数序列化的问题?
经常要在三个地方打日志才能找到bug。
问题三:部署复杂 生产环境要跑:
- Claude API调用服务
- 多个MCP Server进程
- 进程间通信的管理
- 健康检查和自动重启
运维同学直接说:“能不能别搞这么复杂?”
最关键的是,时间不够了。产品经理每天来问进度,老板在问“为什么这么慢”,我们却还在和MCP的技术细节死磕。
03 Skill的务实之道:文件系统就是最好的协议
转折点发生在12月中旬。我偶然看到Claude的Skill机制文档,发现了一个被我忽视的设计哲学:文件系统本身就是最稳定的“协议”。
Skill的工作方式非常简单:
1. 把“怎么做”写在Markdown文件里(SKILL.md)
2. 把工具脚本放在约定的目录里
3. Claude读取Skill文件,理解能力和流程
4. 需要时调用bash_tool执行脚本或操作文件
看起来low-tech对吧?但这恰恰是它的优势。
优势一:零学习成本不需要理解JSON-RPC、不需要写Server、不需要管理进程。就是文件和脚本,任何开发者都会用。
我们项目里的文档处理Skill长这样:
/mnt/skills/document-processing/
├── SKILL.md # 能力描述和使用说明
├── parse_docx.py # Word解析脚本
├── parse_pdf.py # PDF解析脚本
├── generate_summary.py # 摘要生成
└── templates/ # 文档模板
├── report.docx
└── contract.docxSKILL.md里写明白触发条件、处理流程、输出标准,Claude自己就知道该怎么用。
优势二:调试友好 出了问题?直接看文件:
- 输入文件在
/mnt/user-data/uploads - 输出文件在
/mnt/user-data/outputs - 中间文件在
/home/claude - 日志?
bash_tool的stdout/stderr都能看到
不需要抓包、不需要跨进程调试,所见即所得。
优势三:渐进式集成 最妙的是,Skill可以逐步演化:
- 第一版:纯Python脚本处理文件
- 第二版:加上数据库查询(写个查询脚本)
- 第三版:接入第三方API(curl或requests)
- 第四版:需要时再考虑MCP(Skill可以调用MCP Server)
不需要一开始就设计完整的架构,根据需求逐步增强就好。
04 并不是说MCP没价值:定位问题
可能有人会问:你这不是在否定MCP吗?
不是。我想说的是:MCP和Skill解决的是不同层面的问题。
MCP的定位:Agent之间的标准化通信 适用场景:
- 大型企业的Agent生态,需要严格的权限控制
- 跨组织的Agent协作,需要标准化接口
- 复杂的Agent编排,需要动态能力发现
- 长期的系统演进,需要协议稳定性
Skill的定位:单个Agent的能力封装 适用场景:
- 快速原型验证和MVP开发
- 中小团队的AI应用落地
- 现有系统的AI能力增强
- 需要快速迭代的业务场景
说白了,MCP是“企业级基础设施”,Skill是“实用主义工具”。如果你是大厂,有专门的平台团队,有充足的时间打磨,MCP当然是更好的选择。但如果你是创业公司、业务团队、或者个人开发者,Skill能让你活下去。
而且,这两者不是互斥的。我现在的架构是:
- 核心能力用Skill封装,保证稳定和易用
- 需要跨系统协作的地方,用MCP连接
- Skill里可以调用MCP Server,MCP Server也可以调用Skill
这种“混合架构”兼顾了实用性和扩展性。
05 为什么文件系统是被低估的架构?
说到这里,可能有人觉得:“文件系统?这也太原始了吧?”
但其实,文件系统恰恰是最被低估的架构模式。
Unix哲学的回归记得Unix的设计哲学吗?“一切皆文件”。为什么这个理念流传了50年?因为它简单、可靠、可组合。
- 想看系统状态?
cat /proc/cpuinfo - 想配置网络?编辑
/etc/network/interfaces - 想写日志?重定向到文件
Claude的Skill机制本质上就是Unix哲学在AI时代的复兴:
- 能力描述?就是Markdown文件
- 数据传递?就是文件读写
- 工具调用?就是bash命令
关注点分离的极致 文件系统天然实现了关注点分离:
- Skill.md关注“做什么”(声明式)
- Python脚本关注“怎么做”(命令式)
- 文件目录关注“组织结构”(模块化)
不需要复杂的依赖注入、不需要服务发现、不需要消息队列。文件在哪,能力就在哪。
版本管理和协作的天然支持所有Skill都是文本文件,意味着:
- 可以用Git管理版本
- 可以做Code Review
- 可以多人协作开发
- 可以回滚到任意历史版本
这些在MCP里需要额外设计的能力,在Skill里是免费的。
挺有意思的是,我最近看到一些大厂也在往这个方向走。某云厂商的内部AI平台,核心架构就是“基于文件系统的能力编排”。他们的技术负责人说:“试了一圈复杂方案,最后发现还是最简单的最靠谱。”
06 我的预测
说实话,我不知道一年后MCP会发展成什么样。但我有几个预测:
预测一:MCP会找到自己的位置不会是“取代所有方案”的银弹,而是在特定场景(大型企业、跨组织协作)成为标准。就像GraphQL没有取代REST,但在合适的地方很好用。
预测二:Skill会持续演进Anthropic会继续优化Skill机制,可能会加入:
- Skill版本依赖管理
- Skill性能监控和优化
- Skill市场和共享平台
预测三:会出现混合架构模式 最终不是“MCP vs Skill”,而是两者结合:
- 团队内部用Skill快速开发
- 跨团队协作用MCP标准化
- 两者通过适配层连接
预测四:更多“务实方案”会出现看到Skill的成功,会有更多基于简单可靠技术栈的AI方案出现。技术圈会意识到:有时候最好的创新,是回归基础。
结语
写到最后,我想说的是:这篇文章不是要否定MCP,而是想提醒大家——不要把希望都寄托在未来的技术上,而忽视了当下能用的方案。
MCP是理想,代表了AI Agent互联的美好愿景。但Skill是活下去的工具,能帮你在竞争激烈的市场中快速交付价值。
技术选型的本质不是追逐最酷的技术,而是选择最适合团队、最适合业务、最适合时机的方案。如果你的团队只有3个人、老板给了2个月时间、还要保证系统稳定——那么,拥抱文件目录,可能是最明智的选择。
记住:没有交付,再美的架构都是空谈。
关注公众号「AI智享空间于老师」,获取更多落地方案。
如果你想深入了解Skills开发实践、获取开源Skills库、或者和其他务实派开发者交流,欢迎关注我的公众号。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号