AI 工程化落地实践:推翻"完美架构",回归提示词本质

AI 工程化落地实践:推翻"完美架构",回归提示词本质

腾讯云开发者
发布于 2026-02-27 11:19:27
发布于 2026-02-27 11:19:27
关注腾讯云开发者,一手技术干货提前解锁👇
01
一个"完美"架构的诞生与死亡
1.1 我们最初的野心
故事要从几周前说起。
那时候,团队刚开始系统性地探索 AI 辅助开发。我们读了大量论文和博客,看到业界在讨论"多智能体协作"、"Agent 编排"、"知识图谱"……我们想:既然要做,就做一套"正经"的架构。
于是我们设计了这样一套系统:
用户需求
↓
┌───────────────────────────────────────────────────────┐
│ Command 层(入口) │
│ /req-dev(启动研发流程) │
└───────────────────────────────────────────────────────┘
↓
┌───────────────────────────────────────────────────────┐
│ Agent 层(决策) │
│ phase-router → 意图识别 → 路由到专业 Agent │
│ ├── design-manager(设计管理) │
│ ├── impl-coordinator(实现协调) │
│ └── experience-depositor(经验沉淀) │
└───────────────────────────────────────────────────────┘
↓
┌───────────────────────────────────────────────────────┐
│ Skill 层(执行) │
│ req-create, workspace-setup, meta-maintainer... │
└───────────────────────────────────────────────────────┘我们还定义了严格的"九步工作流":需求录入 → 上下文准备 → 方案设计 → 设计评审 → 代码实现 → 代码审查 → 测试验证 → 经验沉淀 → 需求关闭。
每一步都有专门的 Agent,每个 Agent 都有专门的 Skill,一切井井有条。
我们甚至为 Agent 之间的通信设计了标准的 JSON 协议,为元信息管理写了专门的维护脚本。
1.2 第一个裂缝
架构设计完成后,我们试着在脑子里“走一遍流程”。
假设我想改一个配置文件里的默认值。按照我们的设计,我应该:
- 创建一个“微需求”
- 等待 phase-router 识别意图
- 被路由到
impl-coordinator - 初始化标准的工作空间
- 然后才能改那一行代码
想象中,我将花 15 分钟走完流程,只为改 1 秒钟的代码。
我当时想:可能是因为这个需求太小了,不适合用完整流程。于是我又试想了一个“正经”的需求——给服务加一个新接口。
这次流程在脑子里走得更顺畅了。但我开始担忧一些问题:如果真的实现这套架构,我花在“让 AI 理解流程”上的精力,会不会比花在“让 AI 理解业务”上的还多?
phase-router 可能会误判意图,需要手动纠正。Agent 之间的上下文传递可能会丢失关键信息。元数据维护也可能出问题。
1.3 一个诚实的问题
就在我们讨论架构设计的间隙,我需要完成一个小任务。我直接在聊天框里写:
“帮我在 user 表加一个 last_login_at 字段,datetime 类型,默认 null,然后在登录接口里更新它。”AI 直接帮我完成了。没有走任何流程,没有创建需求 ID,没有初始化工作空间。
5 分钟,完事。
那一刻我问自己一个问题:如果按照我们设计的架构来做这个任务,效率会更高还是更低?
这个问题让我很不舒服。因为它意味着我们过去几天的设计工作可能是无效的。
1.4 回到原点的勇气
我把这个困惑分享给团队。讨论了很久之后,我们决定做一件需要勇气的事:暂停所有架构开发,重新思考 AI 工程化到底应该是什么。
我们问自己三个问题:
- 我们到底在解决什么问题? —— AI 辅助开发的效率和质量
- 现有架构解决了吗? —— 没有,反而增加了认知负担
- 有没有更简单的方案? —— 不知道,需要重新调研
带着这三个问题,我们开始了新一轮的探索。
02
两个产品的启发
转折点来自两个看似不相关的产品:Google 的 NotebookLM 和 Anthropic 的 Claude Code。
2.1 NotebookLM:简单到让人惭愧
在准备团队分享时,我用 NotebookLM 整理资料。把几篇论文和博客丢进去,它就能帮我总结要点、回答问题、生成播客。
然后我注意到这个产品的界面——简单到让人惭愧。
┌──────────────────────────────────────────────────────────────────────────┐
│ NotebookLM │
│ │
│ 左栏:来源 │ 中栏:对话 │ 右栏:输出 │
│ ───────────── │ ───────────── │ ───────────── │
│ + 添加来源 │ [AI 自动总结] │ 思维导图 │
│ ☐ PDF │ 推荐问题: │ 播客 │
│ ☐ 网页 │ • ... │ 报告 │
│ ☐ 视频 │ • ... │ ... │
│ ☐ 笔记 │ │ │
│ │ [输入框] │ │
└──────────────────────────────────────────────────────────────────────────┘就这?就这!
没有"智能路由",没有"多 Agent 协作",没有"知识图谱"。就是来源 + 对话 + 输出,三栏设计。
但它解决了一个核心问题:让人能快速消化大量信息。
我开始思考:NotebookLM 的设计逻辑是什么?
输出 = f(来源, 输出格式)
其中:
- 来源:你丢进去的材料
- 输出格式:播客、报告、思维导图...
- f:LLM 的理解和生成能力这个公式简单到不需要任何架构。 你只需要:
- 把材料组织好
- 告诉 AI 你想要什么格式的输出
我们的三层架构、九步工作流,本质上是在 f 这个函数上做文章,试图让它更"智能"。但 NotebookLM 告诉我们:f 已经够强了,问题在于如何组织好输入。
2.2 Claude Code:反直觉的极简主义
如果说 NotebookLM 是一个启发,Claude Code 就是一记重锤。
Anthropic 发布 Claude Code 时,我花了一整个周末研究它的设计理念。有几点让我印象深刻:
第一,他们也曾想做复杂架构,然后放弃了。
“一开始 Claude Code 就能给自己创建和使用工具。我们试图在后台创建一个复杂的工具图……我们做的越多,它就变得越不可靠。”
听起来熟悉吗?我们也在做"复杂的工具图"。
第二,他们选择了最小化工具数量。
“你给模型的工具越少,每次调用的效率就越高……与其创造很多小的、精确的工具,不如创造大的、表达力强的工具,然后信任模型。”
我们的做法正好相反——我们设计了 req-create、workspace-setup、meta-maintainer 等一堆精细的 Skill。
第三,Claude Code 创作者的实际工作方式印证了这一点。
Claude Code 创作者分享过他的使用经验:他几乎不做复杂的定制,而是依靠最基本的能力——同时运行 10-15 个 Claude 实例,每个处理一个独立任务,每周产出 50-100 个 PR。
这个数字让我们反思:我们花那么多时间设计"完美架构",是不是本末倒置了?
第四,他们强调"完全的能力对等"。
“你能做的事情,Claude 都能做。”
我们的九步工作流实际上是在限制 AI 的能力——它必须按照我们规定的路径走。
第五,最让我震撼的一句话:
“最好的工具是你不知道它存在的工具。”
我们的架构不是在创造"工具",而是在创造"流程"。用户每次使用都能感受到流程的存在,这本身就是失败。
2.3 核心洞察:文本是通用接口
两个产品给我们的共同启发是:LLM 本身就是最好的解释器,它不需要复杂的"协议"。
NotebookLM 直接读 PDF 和网页。Claude Code 直接操作文件系统。它们都没有中间层的"意图识别"或"路由调度"。
回到我们的场景——代码开发,本质上也是信息处理:
代码 = LLM(业务需求 + 技术规范 + 项目约定 + 历史经验)既然如此,我们需要做的不是设计复杂的 Agent 编排,而是把"业务需求"、"技术规范"、"项目约定"、"历史经验"组织成 LLM 能理解的格式。
什么格式?Markdown。 最朴素的文本格式。
03
认知转变:从代码到文本
这次探索带来了一个根本性的认知转变。
3.1 旧思维 vs 新思维
维度 | 旧思维 | 新思维 |
|---|---|---|
如何让 AI 遵循规范 | 开发工具强制执行 | 写成提示词让 AI 理解 |
如何管理 AI 状态 | 设计元数据系统 | 保存到文件,下次读取 |
如何沉淀经验 | 开发"经验管理 Agent" | 写文档,放到 context 目录 |
如何路由意图 | 开发"路由 Agent" | 在提示词里写清楚决策逻辑 |
核心观点:你不需要为 AI 开发复杂的工具,你只需要把知识结构化地写下来。
3.2 一个具体的例子
假设我们有一个规范:提交代码前必须运行 lint 检查。
旧做法:
开发一个 pre-commit Skill
→ 在 impl-coordinator Agent 里调用
→ 检查失败时返回特定错误码
→ Agent 根据错误码决定下一步新做法:
# AGENTS.md
## 代码提交规范
- 提交前必须运行 `make lint`
- lint 不通过不要提交,先修复问题就这样。AI 会自己读这段话,自己执行 lint,自己修复问题。不需要任何代码。
3.3 这不是偷懒,这是更高效的工程
有人可能会说:这不就是把复杂度藏到提示词里了吗?
不是的。提示词和代码的本质区别在于:提示词是声明式的,代码是命令式的。
- 声明式:告诉 AI "应该是什么样"
- 命令式:告诉 AI "应该怎么做"
当你用代码实现一个流程,你需要考虑所有边界情况、错误处理、状态管理。当你用提示词描述一个规范,AI 会自己处理这些细节。
这不是偷懒,这是利用 LLM 的能力来降低工程复杂度。
04
落地哲学:三个核心原则
基于上述反思,我们提炼出三个落地原则。
原则一:文档即记忆(Dual Use)
AGENTS.md 既是新人的入职手册,也是 AI 的核心记忆。
这个原则的精妙之处在于:同一份文档,人类和 AI 都能读懂、都能用。 你不需要维护两套知识体系——一套给人看,一套给 AI 用。
当你写文档时,想象你在给一个聪明但对项目一无所知的新同事讲解。这个新同事可能是人类,也可能是 AI。
原则二:先跑起来
从最简单的提示词开始,让 AI 辅助工作能用。不要追求完美设计,先让流程转起来。
一个能用的简单系统,好过一个完美但用不起来的复杂系统。
我们的错误正是在系统"能用"之前就开始追求"完美"。
Claude Code 创作者的计划模式工作流印证了这一点:
“大多数会话都从计划模式开始。与 Claude 来回讨论直到满意其计划,然后切换到自动接受编辑模式。Claude 通常可以一次完成。一个好的计划非常重要。”
注意这里的关键:不是设计复杂的"计划 Agent",而是用对话的方式讨论计划,确认后再执行。简单、直接、有效。
原则三:自然演进
观察团队如何使用(甚至"滥用")工具,将高频模式固化为能力。不预设复杂架构,让需求驱动演进。
Claude Code 团队有一句话说得很好:"构建一个足够开放的产品,观察人们如何'滥用'它,然后为此而构建。"
不要试图预测用户需要什么。先给他们一个简单的工具,看他们怎么用,再决定要不要封装。
05
最简起点:一个文件搞定
5.1 只需一个文件
忘掉复杂的架构。在项目根目录创建 AGENTS.md:
# AGENTS.md
## 项目背景
这是 xxx 项目,使用 Go + MySQL,核心服务包括用户服务和订单服务。
## 工作规范
- 先读代码再改,不要猜测未检查的代码
- 代码注释用中文,变量命名用英文
- 不确定的地方问我,不要自己瞎猜
## 常见坑点
(遇到问题再补充)这就是全部起点。 启动 AI 工具,它会自动读取这个文件,开始工作。
5.2 提示词的自然演进
随着使用,提示词会自然生长。以下是一个典型的演进路径:
起步阶段:基础背景
## 项目背景
微服务架构,Go 语言,核心服务有用户服务、订单服务。积累阶段:补充踩过的坑
## 常见坑点
- Apollo 配置格式:key 必须是 xxx.yyy.zzz 三段式
- 数据库连接:测试环境 IP 是 10.0.0.1,不是 localhost
- 商品发放:虚拟商品发到虚拟钱包,实物商品发到实体钱包成熟阶段:形成知识索引
## 关键知识
详细的技术背景见 context/ 目录:
- 服务架构:context/tech/services/
- 业务逻辑:context/business/
- 历史经验:context/experience/关键:不要一开始就设计完美的知识结构。遇到什么记什么,自然演进。
5.3 提示词设计的实用技巧
技巧 1:用 XML 标签隔离不同类型的指令
<coding_style>
<dos>
- 错误处理必须包装:fmt.Errorf("failed to x: %w", err)
- 日志必须带 traceId
</dos>
<donts>
- 禁止使用 panic
- 禁止在循环中调用数据库
</donts>
</coding_style>技巧 2:写决策逻辑而不是散乱的规则
## 遇到不确定的业务逻辑时
1. 先搜索 context/business/ 下的相关文档
2. 如果文档没写,搜索相关代码实现
3. 如果代码也不明确,再问我技巧 3:记录 AI 容易犯的错
每次 AI 犯错后,把纠正内容加入 AGENTS.md:
## AI 注意事项
- 【重要】修改 config 后要重启服务才能生效
- 【重要】用户表的 status 字段:0=未激活,1=正常,2=封禁(不是布尔值!)这是最低成本的"模型微调"——记一次,终身受益。
技巧 4:简单的自然语言指令比复杂工具更有效
你想要的效果 | 直接说 |
|---|---|
AI 不确定时问你 | "有不清楚的就问我" |
AI 先想清楚再动手 | "先想想方案再动手" |
简化冗长的代码 | "简化一下" |
深度思考复杂问题 | "Think" 或 "仔细想想" |
5.4 何时需要封装成工具?
判断标准:如果在 AGENTS.md 里写几句话就能达到同样效果,那就不需要封装。
场景 | 是否需要封装 |
|---|---|
需要特定领域知识(如服务代码分析框架) | ✅ 是 |
流程复杂且固定(如发布流程、安全检查) | ✅ 是 |
自然对话能完成(需求澄清、方案讨论) | ❌ 否 |
只是提示词优化 | ❌ 否 |
Claude Code 创作者的经验:只为"内部循环"封装工具
"我为每天多次执行的'内部循环'工作流使用斜杠命令。避免重复提示,Claude 也可以使用这些工作流。"
他的 /commit-push-pr 命令每天使用数十次,这种高频操作才值得封装。而且命令使用内联 bash 预计算 git status 等信息,"使命令运行快速,避免与模型来回交互"。
另一个实用技巧:用 Hook 处理格式化
"我们使用 PostToolUse hook 格式化 Claude 的代码。Claude 通常开箱即用生成格式良好的代码,Hook 处理最后 10% 的格式化,避免后续 CI 中的格式化错误。"
这是"把复杂度交给自动化"的好例子——不需要在提示词里反复强调格式规范,用 Hook 自动处理。
06
解决 AI "失忆"问题
6.1 核心问题:AI是无状态的
AI 的记忆只存在于当前对话窗口。会话结束,记忆清空。这就是为什么:
- 昨天告诉它的注意事项,今天又忘了
- 做到一半的任务,换个会话就不知道进度了
这是 LLM 的本质特性,而不是产品缺陷。 理解这一点很重要。
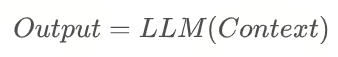
大模型本质上是一个无状态的纯函数。它随时可以处理任何需求,前提是你必须恢复它的"内存"(上下文)。
解决方案:把"记忆"保存到文件,新会话时从文件恢复。
会话内存(易失) 文件系统(持久)
↓ ↓
当前思维状态 ──保存──→ process.txt
↑ ↓
新会话开始 ←──恢复── process.txt6.2 保存与恢复进度
在会话结束前,让 AI 把当前状态保存到文件:
# process.txt
## 当前状态
正在开发用户认证功能,API 已完成,下一步是写单元测试。
## 已完成
- [x] 设计 JWT Token 结构
- [x] 实现登录接口
- [x] 实现 Token 校验中间件
## 待完成
- [ ] 编写单元测试
- [ ] 处理 Token 刷新逻辑
## 注意事项
- Token 过期时间配置在 config/auth.yaml
- 测试时需要先启动 Redis新会话开始时,让 AI 读取这个文件,它就能恢复上下文:
已读取过程文件。上次停在"编写单元测试"。
当前环境已检查:
- Git 状态:干净,最后提交是"feat: 实现 Token 校验中间件"
- Redis:需要启动
是否继续编写单元测试?就像游戏的存档/读档机制——会话切换变得无缝。
6.3 长期任务的最佳实践
Anthropic 的研究指出了两种常见的失败模式:
失败模式 | 症状 | 解决方案 |
|---|---|---|
一次性完成 | 试图一口气完成所有功能,上下文耗尽后留下半成品 | 一次只做一个功能,做完就提交 |
过早宣布胜利 | 看到部分功能完成就认为任务结束 | 用功能清单跟踪,全部完成才算完成 |
功能清单的关键作用:
对于复杂任务,创建 features.json:
{
"requirement_id": "example-requirement",
"features": [
{
"id": "F001",
"name": "用户登录",
"description": "实现用户登录功能",
"priority": 1,
"status": "done",
"estimated_effort": "2h",
"actual_effort": "2h",
"dependencies": [],
"acceptance_criteria": ["AC-001"],
"related_files": ["src/login.ts"],
"review_status": "approved"
},
{
"id": "F002",
"name": "Token 刷新",
"description": "实现 Token 刷新能力",
"priority": 2,
"status": "in_progress",
"estimated_effort": "2h",
"actual_effort": null,
"dependencies": ["F001"],
"acceptance_criteria": ["AC-002"],
"related_files": ["src/refresh.ts"],
"review_status": null
}
],
"summary": { "total": 2, "done": 1, "in_progress": 1, "pending": 0 }
}关键约束:AI 只能修改执行态字段(status/actual_effort/review_status/summary/last_updated 等),禁止删改功能点定义性字段;以 context/project/AgenticMetaEngineering/design/元工程规范/资源/结构示例/features.json.example 为唯一口径,避免口径漂移与“偷懒跳过功能”。
6.4 高级技巧:利用"独立上下文"进行自我审查
Claude Code 团队发现了一个反直觉的现象:
“价值往往不在于角色扮演,而在于不相关的上下文窗口。”
当你完成一段复杂的代码后,不要在同一个会话中让 AI review。因为此时的上下文已经"被污染"了——它包含了之前的试错、假设和偏见。
最佳实践:
- 提交代码,保存进度
- 开启一个全新的会话
- 让新会话的 AI 对刚才的改动进行审查
两个互不知道对方上下文的窗口,往往能发现明显的逻辑漏洞。这就像找了另一个同事来做 Code Review。
6.5 最重要的技巧:给 AI 一个验证其工作的方式
Claude Code 创作者在分享他的经验时特别强调:
“这可能是从 Claude Code 获得出色结果的最重要的事情——给 Claude 一种验证其工作的方式。如果 Claude 有这个反馈循环,它会将最终结果的质量提高 2-3 倍。”
不同场景的验证方式:
开发场景 | 验证方式 |
|---|---|
后端 API | 运行测试套件、curl 调用接口 |
前端 UI | 浏览器预览、截图对比 |
配置变更 | 重启服务验证配置生效 |
移动应用 | iOS/Android 模拟器测试 |
关键洞察:
“实际上非常简单,我认为人们有时会把它过度复杂化。给 Claude 一个查看代码输出的工具,告诉 Claude 关于这个工具。就是这样。Claude 会自己弄清楚其余的部分。”
这印证了我们的核心观点:不需要复杂的架构,只需要给 AI 正确的能力和明确的指引。
07
团队共享:单仓库模式
7.1 为什么用单仓库?
既然大模型是无状态函数,那么团队其实不需要"50 个 Agent 实例",只需要"1 个 Agent 工程 + 50 个独立的上下文空间"。
这里说的"单仓库"有两层含义:
第一层:团队共享同一套 AI 配置(知识层面)
传统做法是每个人各自维护自己的 AI 配置——你的 CLAUDE.md 和我的 CLAUDE.md 完全不同。问题是:
- 你踩过的坑,我不知道
- 好的提示词技巧无法共享
- 团队知识变成孤岛
单仓库的解法:把 CLAUDE.md、context/、.codebuddy/ 等 AI 配置文件统一放在一个 Git 仓库里,团队成员通过 clone 这个仓库获得完全一致的 AI "记忆"。
第二层:并行工作时的隔离(执行层面)
Claude Code 创作者的实践验证了这一点:
“我在终端中并行运行 5 个 Claude。我使用同一仓库的 5 个独立 git checkout。”
关键在于:每个 checkout 都包含相同的 CLAUDE.md 和团队知识(因为都是从同一个仓库 clone 的),但各自在独立的分支上工作,互不干扰。
团队共享仓库(master)
├── CLAUDE.md ← 所有人共用的 AI 记忆
├── context/ ← 所有人共用的知识库
└── .codebuddy/ ← 所有人共用的工具
开发者 A 的 checkout 开发者 B 的 checkout 开发者 C 的 checkout
├── (继承 master) ├── (继承 master) ├── (继承 master)
├── feature/auth ├── feature/payment ├── bugfix/login
└── 独立的工作空间 └── 独立的工作空间 └── 独立的工作空间这样实现了:知识共享(大家的 AI 都知道同样的事情)+ 工作隔离(各自的代码改动不会冲突)。
总结——传统模式 vs 单仓库模式:
维度 | 传统模式 | 单仓库模式 |
|---|---|---|
AI 配置 | 每人各自维护 → 知识孤岛 | 统一工程,所有人共用一套 AGENTS.md |
踩坑经验 | 你踩过的坑,同事不知道 → 重复踩坑 | 记录到 context/,通过 PR 共享给所有人 |
好的实践 | 只能口头传授 | Git 版本管理,合并到 master 瞬间分发 |
并行工作 | 容易冲突 | 独立分支隔离,互不干扰 |
7.2 目录结构
AgenticMetaEngineering/
├── AGENTS.md # AI 的"入职手册"(最重要)
├── context/ # 团队知识库
│ ├── team/ # 团队通用知识
│ └── project/ # 项目特定知识
├── requirements/ # 需求记录(Git 管理)
│ └── {requirement-id}/
├── workspace/ # [废弃] 占位目录(实际工作区迁移至 ../workspace/)
│ └── {requirement-id}/
└── .codebuddy/
└── commands/ # 自定义命令7.3 分支策略
master(模板,保持干净)
├── AGENTS.md # 团队共享的提示词
├── context/ # 团队共享的知识库
└── .codebuddy/ # 团队共享的工具
feature/your-work(你的工作分支)
├── 继承 master 全部内容
├── requirements/ # 你的需求记录
└── ../workspace/ # 你的代码(与本仓库同级)核心原则:
- master 是模板,不直接在上面工作
- 创建分支开始需求开发
- 好的实践通过 PR 合并回 master,所有人受益
7.4 上下文检索:为什么不需要 RAG
很多人第一反应是"要不要用向量数据库做 RAG?"——答案是:不需要。
Claude Code 团队最初也尝试过向量 embeddings,但发现了问题:
- 维护成本高:需要持续重建索引,本地文件修改后难以实时同步
- 安全风险:独立的向量数据库增加了攻击表面积
- 检索准确率:对于代码库这种结构化数据,简单的语义搜索往往不如 Agent 主动探索精准
我们的方案:直接给 AI 赋予 grep、find、ls 能力。它能像资深工程师一样,通过文件结构和关键词自己找到答案。
组织原则:
- 按领域分文件夹:tech/、business/、experience/
- 文件名要清晰:让 ls 出来的列表就有语义
- 内容是 Markdown:最自然的文本格式
7.5 知识路由表
信息类型 | 放哪里 | 示例 |
|---|---|---|
新人必读的项目背景 | AGENTS.md | "本项目使用 DDD 架构" |
踩坑经验 | context/experience/ | "Apollo 配置本地需要加 -Denv=dev" |
业务逻辑规则 | context/business/ | "VIP 用户提现额度计算规则" |
整体计划 | plan.md | "designing 完成后进入 developing" |
当前任务进度 | process.txt | "API 完成,下一步写测试" |
已确认关键发现 | notes.md | "JWT exp 使用 UTC 时区,需要注意转换" |
未确认临时记录 | process.txt | "发现 User 表有个字段没用,待确认" |
决策口诀:
- 是整体计划?→ plan.md
- 是当前进度?→ process.txt
- 是长期知识?
- 所有人都得知道?→ AGENTS.md
- 特定领域?→ context/ 目录
08
复合工程:让每次实践产生复利
8.1 复合工程的核心理念
回到文章开头的问题:我们走了那么多弯路,有什么价值?
价值在于:这些弯路本身可以被记录下来,成为团队的共享知识。
这就是"复合工程"的核心理念:
让每一单元的工程工作使后续工作变得更容易,而非更难。
Claude Code 创作者的团队正是这样做的:
“我们团队为 Claude Code 仓库共享单个 CLAUDE.md。将它检入 git,整个团队每周贡献多次。每当看到 Claude 做错什么,就添加到 CLAUDE.md,这样 Claude 下次就知道不要那样做了。”
这是最朴素但最有效的复合工程——把纠错变成资产。
第 1 次做支付需求:45 分钟 → 记录坑点
第 2 次做支付需求:20 分钟 → AI 自动提醒
第 n 次做支付需求:5 分钟 → 知识已编码进系统8.2 最简的复合工程实践
记录即工程。
不需要复杂的架构,只需要一个习惯:
每次遇到问题解决后 → 花 2 分钟记录
记录到哪里?→ AGENTS.md 或 context/
记录什么?→ 问题、原因、解决方案示例:
# context/experience/商品发放-钱包问题.md
## 问题
商品发放到错误的钱包类型
## 原因
虚拟商品和实物商品的钱包不一样
## 解决方案
根据 goods_type 判断:
- virtual → virtual_wallet
- physical → physical_wallet8.3 三层迭代循环
第一层:日常开发循环(每天)
遇到问题 → 解决 → 记录到 AGENTS.md 或 context/第二层:周期整理循环(每周)
Review 本周记录 → 整理归类 → 提交 PR → 团队 Review → 合并到 master第三层:能力固化循环(每月)
识别高频模式 → 讨论是否封装 → 创建 Command/Skill → 团队共享8.4 通过 PR 共享经验
好的实践不要藏着,通过 PR 合并到 master,全团队受益。
Claude Code 创作者的团队更进一步:他们在代码审查期间直接通过 @.claude 标记,让 AI 作为 PR 的一部分向 CLAUDE.md 添加内容。这是用 CI 自动化"经验沉淀"的绝佳示例。
示例 PR:
## PR 标题
add: 商品发放钱包选择经验
## 变更内容
- 新增 context/experience/商品发放-钱包问题.md
## 背景
开发 xxx 需求时发现虚拟商品和实物商品的钱包配置不同,
多次踩坑后整理成文档。09
团队推广
9.1 不要强推,用效果说话
错误做法:开会宣布"以后大家都要用 AI 工程化"
正确做法:
- 先自己用起来
- 展示实际效果:"这个需求我只花了 10 分钟,因为 AI 帮我避开了 3 个坑"
- 分享你的配置
- 让感兴趣的同事也试试
9.2 分级推进
阶段 | 参与者 | 目标 |
|---|---|---|
试点 | 1-2 个种子用户 | 验证流程可行,积累初始 context |
扩展 | 感兴趣的同事 | 补充更多经验,形成正反馈 |
全员 | 整个团队 | 成为日常工作方式 |
9.3 避免常见陷阱
陷阱 | 症状 | 解决方案 |
|---|---|---|
过度流程化 | PR 审核变成形式主义 | 简化 Review 标准,快速合并 |
只有少数人参与 | 大部分人从不提 PR | 降低门槛,鼓励"小"贡献 |
context 膨胀失控 | 文件太多找不到 | 定期清理过时文档 |
知识过时不更新 | 老文档误导人 | 遇到问题时顺手更新 |
10
回顾与反思
10.1 我们学到了什么
关于架构:
- 复杂的 Agent 编排不是必需的,简单的提示词往往更有效
- 不要预设架构,让需求驱动演进
- 文本是最好的接口,LLM 能直接理解 Markdown
关于产品思维:
- 最好的工具是你感觉不到它存在的工具
- 先让系统"能用",再让它"好用"
- 观察用户如何"滥用"你的产品,那里有真正的需求
关于团队协作:
- 知识要流动,孤岛是效率的敌人
- 每次踩坑都是沉淀经验的机会
- 用效果说话,不要强推
10.2 Workflow vs Agent:再次辨析
回顾 Anthropic 的 Building Effective AI Agents,我们对 Workflow 和 Agent 的边界有了更清晰的理解:
概念 | 定义 | 适用场景 |
|---|---|---|
Workflow | 预定义的代码路径 | 确定性任务,步骤固定 |
Agent | LLM 动态决策的过程 | 开放性任务,需要灵活判断 |
判断是否需要 Agent 的三个问题:
问题 | 答案 → 方案 |
|---|---|
任务步骤是否可预先定义? | 是 → 用 Workflow |
是否需要根据中间结果灵活调整? | 是 → 用 Agent |
能否用单次 LLM 调用解决? | 是 → 先优化 Prompt |
我们最初的错误是:用僵化的 Workflow(九步工作流)来约束本应灵活的 Agent。
10.3 还有什么没想清楚
诚实地说,有些问题我们还没有答案:
- 如何衡量 AI 工程化的 ROI? 我们能感觉到效率提升,但很难量化
- context 的最佳组织方式是什么? 目前是按领域分,但可能有更好的方式
- 团队规模增大后,如何避免 context 混乱? 我们还在探索
如果你有好的想法,欢迎讨论。
11
总结
我们的核心认知转变:
- 从"精密设计"到"最简起点"
- 从"代码实现"到"文本描述"
- 从"个人使用"到"团队共享"
AI 工程化的本质:把 AI 当成团队的新成员来培养——给它入职手册(AGENTS.md),教它项目知识(context/),让它记住经验(process.txt),最终成为团队的共享能力。
落地三原则:
- 文档即记忆 —— AGENTS.md 是人机共用的入职手册
- 先跑起来 —— 从最简单的提示词开始
- 自然演进 —— 观察使用模式,让需求驱动演进
最后想说的是:AI 工程化没有银弹。这篇文章记录的是我们的探索路径,不是唯一正确的答案。你的团队、你的项目、你的场景可能完全不同。
但有一点是通用的:先让它跑起来,在实践中迭代。
如果你也在探索 AI 工程化,希望我们的弯路能给你一些参考。也欢迎分享你的经验——这正是"复合工程"的精神:让每个人的实践,成为所有人的财富。
参考资料
- Claude Code 创作者的 Claude Code 使用经验:13 个核心实践,本文多处引用了这些来自一线的经验为我们的理论提供了有力佐证(https://x.com/bcherny/status/2007179832300581177)
- Anthropic: Building Effective AI Agents,关于 Workflow 与 Agent 边界的深入分析(https://www.anthropic.com/engineering/building-effective-agents)
- Google: NotebookLM,简单到让人惭愧的产品设计(https://notebooklm.google/)
- Anthropic: Claude Code 文档(https://code.claude.com/docs)
-End-
原创作者|侯迎圣
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号