大模型应用:LlamaIndex、LangChain 与 LangGraph 细节深度、协同应用.24
原创
大模型应用:LlamaIndex、LangChain 与 LangGraph 细节深度、协同应用.24
原创
未闻花名
发布于 2026-02-21 11:23:58
发布于 2026-02-21 11:23:58
一、引言
在大模型应用开发中,如何高效地利用私有数据、编排复杂任务以及管理多轮对话状态是三个核心挑战。LlamaIndex、LangChain和LangGraph分别针对这三个挑战提供了专业解决方案。今天我们将深度解析这三个框架的架构设计、核心细节,并通过实战案例展示如何协同使用它们构建强大的LLM应用。
在 LLM 应用开发链路中,LlamaIndex、LangChain 与 LangGraph 形成了 “数据处理 - 基础编排 - 复杂流程” 的全链路支撑体系,三者互补共生而非替代关系:
- LlamaIndex:聚焦私有数据接入LLM的数据层,核心价值是让 LLM 高效、精准地访问和理解私有文档、数据库等非结构化/结构化数据,是 LLM 的私有数据引擎;
- LangChain:定位通用 LLM 应用开发框架,覆盖从输入处理、工具调用到输出生成的全链路基础能力,核心价值是整合LLM与各类工具/组件,是LLM应用的基础脚手架;
- LangGraph:作为 LangChain 生态的子项目,专注有状态、可循环的复杂流程编排,核心价值是解决多智能体协作、任务重试、状态持久化等高级场景需求,是 LangChain 基础编排能力的进阶引擎。
三者协同逻辑可概括为:LlamaIndex 解决LLM 如何获取私有数据,LangChain 解决LLM 如何整合基础工具与流程,LangGraph 解决LLM 如何完成复杂、可控的业务流程,共同构成从数据接入到业务落地的完整技术闭环。

二、三大框架概述
1. LlamaIndex
基础概念:数据连接专家,专注于数据索引和检索,为LLM提供外部知识接入能力。 核心理念:解决"LLM知识断层"问题,专注于构建外部知识到LLM的桥梁。 设计原则:
- 以数据为中心:一切围绕如何高效组织、索引和检索数据
- 检索优化导向:强调召回率和准确率的平衡
- 查询模式多样化:支持语义检索、关键词检索、混合检索等
- 轻量级封装:对LLM保持透明,不强制绑定特定模型
2. LangChain
基础概念:编排协调大师,提供模块化组件和链式编排,简化LLM应用的开发流程。 核心理念:解决"AI能力碎片化"问题,提供统一的组件化编程接口。 设计原则:
- 模块化设计:每个功能独立封装,可插拔替换
- 链式组合:通过管道式连接实现复杂逻辑
- 工具优先:将外部能力(API、数据库、函数)工具化
- 标准化接口:统一输入输出格式,降低集成成本
3. LangGraph
基础概念:状态流程管家,基于状态图的工作流管理,特别适合多轮对话和复杂任务。 核心理念:解决"复杂工作流管理"问题,将状态驱动与图计算结合。 设计原则:
- 显式状态管理:所有状态变化可见、可追踪
- 图结构思维:将业务流程建模为有向图
- 循环与分支:原生支持条件判断和迭代优化
- 持久化优先:内置检查点、恢复和版本管理
三、LlamaIndex详解
1. 架构设计
LlamaIndex的核心目标是将私有数据与LLM连接。其架构分为以下几个层次:
- 数据连接层:支持多种数据源(文档、数据库、API等)的数据加载。
- 索引层:将原始数据转换为结构化索引,便于快速检索。
- 检索层:根据查询从索引中提取相关上下文。
- 查询接口层:将检索到的上下文与用户查询结合,生成LLM可理解的提示。
核心定位不是数据工具,而是帮 LLM 搭建专属知识库的管理员。
- 解决痛点:LLM 自带 “公共知识”,但对你的 PDF、企业文档等私有数据一无所知。
- 核心逻辑:把零散数据(文档、数据库等)整理成 “索引目录”,当 LLM 需要回答相关问题时,快速找出对应的 “参考书页码”,让 LLM 基于这些私有信息作答。
- 关键动作:只做 “数据加载→分割→建索引→精准检索”,不涉及复杂逻辑编排,专注把 “私有数据” 变成 LLM 能直接用的 “上下文素材”。
2. 核心组件
- 数据加载器(Loader):支持 PDF、CSV、Notion、数据库等数百种数据源,核心接口为BaseLoader,开发者可通过自定义 Loader 适配特殊数据源,如医疗领域的专用文档格式。
- 文档处理(Document Processing):包含文本分割器(Text Splitter)与节点构建(Node Construction)。默认采用RecursiveCharacterTextSplitter按字符递归分割文本,支持自定义分割长度与重叠率,避免语义断裂;将分割后的文本块转化为 “节点(Node)”,包含文本内容、元数据及关联信息,为后续检索优化提供基础。
- 索引(Index):核心是将节点数据转化为可高效检索的结构,支持多种索引类型:
- 向量索引(VectorStoreIndex):最常用类型,将节点转化为向量存储(支持 Milvus、Chroma 等向量数据库),通过语义相似度匹配检索;
- 树形索引(TreeIndex):适合文档摘要场景,按层级结构组织节点,支持自上而下的摘要生成;
- 关键词索引(KeywordTableIndex):基于关键词匹配检索,适合精确匹配场景。
- 通过VectorStoreIndex.from_documents(documents)快速构建向量索引,实现私有数据的语义检索。
- 检索器(Retriever):从索引中获取与查询相关的节点,核心参数similarity_top_k控制返回结果数量,如设置为 5 表示返回最相似的 5 个节点。支持自定义检索策略,如结合向量检索与关键词检索的混合检索模式,提升检索精准度。
- 查询引擎(Query Engine):端到端的 RAG 入口,整合检索器与 LLM,支持 “检索→提示词构建→LLM 生成” 的自动化流程。通过RetrieverQueryEngine可自定义检索器配置,满足不同场景的检索需求。
3. 工作流程

流程说明:
- 1. 从原始数据开始,通过文档加载器转换为文档对象。
- 2. 文档分割器将文档分割成更小的节点。
- 3. 节点用于构建索引,索引可以持久化存储。
- 4. 当收到查询时,检索器从索引中检索相关节点。
- 5. 响应合成器将检索到的节点和查询组合,发送给LLM生成答案。
4. 索引类型
- 向量存储索引:将节点转换为向量嵌入,使用相似度搜索进行检索。适用于语义搜索。
- 列表索引:将节点存储为顺序列表,按顺序检索。适用于需要按顺序处理文档的场景。
- 树状索引:将节点组织成树状结构,允许从粗粒度到细粒度的检索。适用于层次化文档。
- 关键词表索引:提取关键词,建立倒排索引。适用于关键词检索。
5. 高级特性
- 递归检索:先检索粗粒度节点,再进一步检索细粒度节点。
- 响应合成模式:包括树总结、精炼、简单汇总等模式,控制如何将检索到的节点合成为答案。
- 多模态索引:支持图像和文本的混合索引。
- 检索优化:支持检索重排序,通过 Cross-Encoder 模型对初始检索结果二次排序;多索引融合,可以同时调用向量索引与树形索引,提升检索精准度;
- 数据隐私保障:支持与本地向量数据库集成,或通过 Ollama 对接本地大模型,实现全链路私有化部署,避免数据泄露;
- 轻量级集成:提供简洁的 API 接口,一行代码即可完成索引构建与查询,适合快速原型开发。
四、LangChain详解
1. 架构设计
LangChain是一个用于开发LLM应用的框架,通过提供模块化组件和链式编排,简化了LLM应用的开发。其核心设计理念是将LLM应用开发分解为多个可复用的组件,并通过链(Chain)将这些组件连接起来。
核心定位不是框架,而是给 LLM 配 “手脚” 和 “简单工作流程” 的平台。
- 解决痛点:LLM 只会想和说,不会主动用计算器、查 API、读数据库,也不会按步骤完成多任务。
- 核心逻辑:一方面封装了各种 “工具”(搜索、数据库、API 等),让 LLM 能调用;另一方面提供 “流水线”(Chain),把 “调用工具→处理结果→生成回答” 等步骤串起来,让 LLM 按固定逻辑干活。
- 关键动作:不专注某一环节,而是做 “组件整合”
2. 核心组件
- 模型(Models):封装各类 LLM,如主流的OpenAI、Qwen、Llama3、嵌入模型OpenAI Embeddings、BERT 等与输出解析器。支持本地模型集成,如通过 Ollama 调用 Llama3.1,适配私有化部署场景。
- 提示词(Prompts):提供提示词模板(Prompt Template)、示例选择器(Example Selector)等工具,支持动态注入上下文与参数。例如参考案例中通过ChatPromptTemplate定义智能客服的系统提示词,动态传入检索到的知识库内容。
- 链(Chains):将多个组件串联为执行流程,核心类型包括:
- 顺序链(SequentialChain):按固定顺序执行组件;
- 检索链(RetrievalQAChain):整合检索器与 LLM,实现基础 RAG 能力;
- 自定义链(Custom Chain):通过Runnable接口组合组件,支持复杂逻辑编排。参考案例中通过RunnablePassthrough传递用户输入,将 LlamaIndex 的检索结果与 LLM 调用串联为完整链路。
- 代理(Agents):让 LLM 自主决策调用工具,核心基于 ReAct 框架(思考 - 行动 - 观察)。支持多种代理类型,如ChatConversationalAgent,可对接数千种第三方工具,如搜索引擎、数据库、API 等。
- 记忆(Memory):维护对话上下文或任务状态,核心类型包括ConversationBufferMemory(保存完整对话历史)、ConversationSummaryMemory(保存对话摘要)等,支持多轮对话场景。
- 工具(Tools):封装外部系统能力,开发者可通过BaseTool接口自定义工具,如对接企业内部订单查询 API。可以通过自定义工具将 LlamaIndex 的检索能力集成到 LangChain 的代理流程中。
3. 工作流程

流程说明:
- 1. 用户输入进入检索器,检索相关文档。
- 2. 检索到的文档与用户输入一起填入提示模板。
- 3. 填充后的提示发送给LLM。
- 4. LLM的响应经过输出解析器处理,得到结构化答案。
4. 链式编排
LangChain的核心是链(Chain),它允许将多个组件连接起来。链可以是简单的线性链,也可以是复杂的分支链。
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
prompt = PromptTemplate(
input_variables=["product"],
template="为以下产品写一个广告语:{product}",
)
chain = LLMChain(llm=OpenAI(), prompt=prompt)
chain.run("智能手机")5. 代理和工具
代理使用LLM来决定采取哪些行动,行动可以是使用工具、观察结果,然后重复直到完成。
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("今天北京的天气怎么样?")6. 技术特点
- 生态兼容性:支持与主流向量数据库(Milvus、Pinecone、Chroma)、图数据库(Neo4j)、大模型管理工具(Ollama)等集成,覆盖各类技术栈;
- 低代码开发:提供大量开箱即用的组件与模板,降低复杂 LLM 应用的开发门槛;
- 多场景适配:支持云部署与本地部署,兼顾商业应用与隐私敏感场景,如医疗、金融。
五、LangGraph详解
1. 架构设计
LangGraph是建立在LangChain之上的一个库,用于构建有状态、多参与者的工作流。其核心概念是图(Graph),图中的节点代表步骤,边代表步骤之间的流转。LangGraph特别适合需要循环、多轮对话和复杂状态管理的应用。
核心定位不是Chain的升级版,而是给 LLM 配决策大脑,应对需要 “循环、协作、回溯” 的复杂场景。
- 解决痛点:LangChain 的流水线是线性的,遇到需要 “重试(比如检索结果不好重新查)、多角色分工(比如检索员 + 审核员)、长期跟踪(比如客户工单处理)” 的场景就失灵。
- 核心逻辑:把任务拆成多个角色节点,比如检索节点、评估节点、生成节点,用图结构定义节点间的跳转规则,比如评估不通过就回退到检索节点,让 LLM 能像项目经理一样指挥流程推进。
- 关键动作:不新增基础组件,而是复用LangChain的工具和LlamaIndex的检索能力,只负责复杂流程的编排与状态管理。
2. 核心概念
- 状态(State):存储流程执行过程中的所有数据,如用户问题、检索结果、中间生成内容,支持自定义状态结构。通过状态快照机制,在每个节点执行前创建状态快照,防止状态污染;每个节点仅能访问其声明的状态字段,实现节点级状态隔离。与传统集中式状态管理相比,LangGraph 的状态管理更灵活,扩展性更强,无需额外同步机制即可保障状态一致性。
- 节点(Node):流程的执行单元,可封装 LLM 调用、工具调用、数据处理等逻辑,如检索节点、生成节点、评估节点。支持自定义节点函数,接收状态输入并输出更新后的状态。
- 边(Edge):定义节点间的跳转规则,支持固定跳转、条件跳转与动态跳转:
- 固定跳转:从一个节点直接跳转到另一个节点,如检索节点到评估节点;
- 条件跳转:根据状态内容动态决定跳转路径,如评估节点根据检索结果是否足够,跳转到生成节点或调整检索节点;
- 动态跳转:通过 LLM 决策生成跳转路径,如多智能体场景中,由 LLM 决定下一个执行节点。
- 图(Graph):将节点与边的定义编译为可执行流程,支持异步执行与并发控制。在编译阶段,系统会分析状态依赖关系并优化执行路径,避免状态冲突。
3. 工作流程
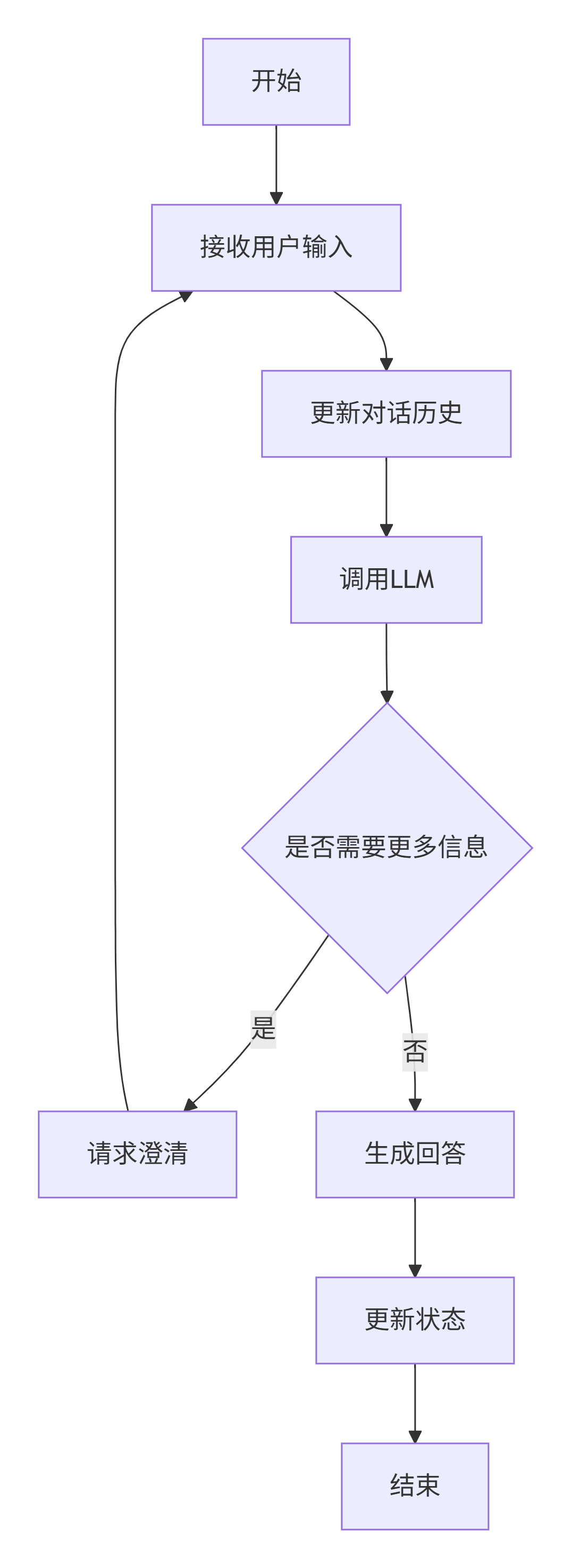
流程说明:
- 1. 从开始节点,接收用户输入。
- 2. 将用户输入添加到对话历史中。
- 3. 调用LLM,根据对话历史生成响应。
- 4. 判断是否需要更多信息,如果需要,则进入澄清节点,然后回到接收输入;如果不需要,则生成回答。
- 5. 更新状态,结束本轮对话。
4. 状态管理
LangGraph中的状态是一个字典,可以在节点之间传递和修改。状态的设计是灵活的,可以根据应用需求定义。
from typing import TypedDict, List
class ConversationState(TypedDict):
messages: List[str]
needs_clarification: bool
clarification_question: str5. 循环和条件边
LangGraph支持循环,通过条件边(conditional edge)来实现。条件边根据当前状态决定下一个节点。
from langgraph.graph import StateGraph, END
# 定义状态
class State(TypedDict):
value: int
# 定义节点
def increment(state: State):
return {"value": state["value"] + 1}
# 定义条件边函数
def should_continue(state: State):
if state["value"] < 5:
return "increment"
else:
return END
# 构建图
workflow = StateGraph(State)
workflow.add_node("increment", increment)
workflow.set_entry_point("increment")
workflow.add_conditional_edges("increment", should_continue)
# 编译
app = workflow.compile()6. 技术特点
- 流程可控性:支持循环、重试、回退等复杂流程逻辑,如检索结果不足时重新调整检索条件并再次检索,解决了 LangChain 原生 Chain 无法处理的非线性流程问题;
- 多智能体协作:通过多节点分工,如 “检索员节点 + 分析师节点 + 审核员节点”,实现多智能体的协同工作,适配复杂业务场景;
- 状态持久化:支持将状态存储到外部数据库,实现流程中断后恢复、跨会话状态共享等高级需求;
- 完全兼容 LangChain:可直接复用 LangChain 的模型、工具、记忆等组件,无需重复开发。
六、协调示例:企业知识库智能助手构建
1. 需求场景
构建支持多轮对话的企业知识库智能助手,具备以下能力:
- 检索企业私有文档(PDF、Word);
- 记忆对话上下文;
- 检索结果不足时自动调整检索条件重试;
- 生成回答前进行准确性审核。
2. 分工协作
- LlamaIndex:负责文档加载、索引构建与高精度检索,通过VectorStoreIndex构建企业知识库索引,VectorIndexRetriever实现语义检索;
- LangChain:负责记忆管理与工具封装,通过ConversationBufferMemory维护对话上下文,自定义 Tool 封装 LlamaIndex 的检索能力;
- LangGraph:负责复杂流程编排,构建 “检索→评估→生成→审核” 的非线性流程,支持检索重试与条件跳转。
3. 代码分解
3.1 LlamaIndex 构建知识库索引
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.retrievers import VectorIndexRetriever
# 加载企业知识库文档(PDF/Word等)
documents = SimpleDirectoryReader("./knowledge").load_data()
# 构建向量索引
index = VectorStoreIndex.from_documents(documents)
# 初始化检索器(返回最相似的5个结果)
retriever = VectorIndexRetriever(index=index, similarity_top_k=5)- 通过SimpleDirectoryReader加载本地文档,VectorStoreIndex将文档转化为向量存储,VectorIndexRetriever配置检索参数,为后续精准检索提供基础。
3.2 LangChain 封装工具与记忆组件
from langchain_core.tools import Tool
from langchain.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI
# 封装LlamaIndex检索器为LangChain工具
def retrieve_context(query):
response = retriever.retrieve(query)
return [doc.node.text for doc in response]
retrieval_tool = Tool(
name="企业知识库检索",
func=retrieve_context,
description="用于回答关于公司制度、产品手册、业务流程的问题"
)
# 初始化记忆组件(维护对话上下文)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# 初始化LLM(支持本地模型替换)
llm = ChatOpenAI(model="deepseek-v3")- 将 LlamaIndex 检索器封装为 LangChain 工具,便于 LangGraph 调用;
- ConversationBufferMemory保存对话历史,支持多轮对话上下文关联。
3.3 LangGraph 构建复杂流程
from langgraph.graph import StateGraph, END
from langchain_core.prompts import ChatPromptTemplate
# 定义流程状态结构
class GraphState(dict):
question: str
chat_history: list
retrieval_results: list
answer: str
need_retry: bool
# 定义核心节点逻辑
# 节点1:检索节点(调用LlamaIndex检索工具)
def retrieve_node(state: GraphState):
results = retrieve_context(state["question"])
return {**state, "retrieval_results": results, "need_retry": False}
# 节点2:评估节点(判断检索结果是否足够)
def evaluate_node(state: GraphState):
prompt = ChatPromptTemplate.from_messages([
("system", "判断检索结果是否足够回答用户问题,仅返回true/false"),
("user", "问题:{question}\n检索结果:{retrieval_results}")
])
evaluation = llm.invoke(prompt.format(
question=state["question"],
retrieval_results=str(state["retrieval_results"])
)).content
return {**state, "need_retry": evaluation.lower() == "false"}
# 节点3:生成节点(基于检索结果生成回答)
def generate_node(state: GraphState):
prompt = ChatPromptTemplate.from_messages([
("system", "基于检索结果和对话上下文回答问题,仅使用检索结果中的信息"),
("user", "上下文:{chat_history}\n问题:{question}\n检索结果:{retrieval_results}")
])
answer = llm.invoke(prompt.format(
chat_history=state["chat_history"],
question=state["question"],
retrieval_results=str(state["retrieval_results"])
)).content
return {**state, "answer": answer}
# 节点4:调整检索条件节点(重试用)
def adjust_retrieval_node(state: GraphState):
prompt = ChatPromptTemplate.from_messages([
("system", "为用户问题扩展同义词,生成更精准的检索关键词"),
("user", "原问题:{question}")
])
new_question = llm.invoke(prompt.format(question=state["question"])).content
return {**state, "question": new_question}
# 构建图流程
graph_builder = StateGraph(GraphState)
graph_builder.add_node("retrieve", retrieve_node)
graph_builder.add_node("evaluate", evaluate_node)
graph_builder.add_node("generate", generate_node)
graph_builder.add_node("adjust_retrieval", adjust_retrieval_node)
# 定义流程跳转规则
graph_builder.set_entry_point("retrieve")
graph_builder.add_edge("retrieve", "evaluate")
# 条件跳转:检索结果不足则调整后重试,足够则生成回答
graph_builder.add_conditional_edges(
"evaluate",
lambda state: "adjust_retrieval" if state["need_retry"] else "generate",
{"adjust_retrieval": "retrieve", "generate": END}
)
# 编译并运行流程
app = graph_builder.compile()
result = app.invoke({
"question": "公司2025年年假制度有哪些调整?",
"chat_history": memory.load_memory_variables({})["chat_history"],
"retrieval_results": [],
"answer": "",
"need_retry": False
})
print("最终回答:", result["answer"])- 通过 LangGraph 构建非线性流程,实现 “检索→评估→重试 / 生成” 的闭环;
- 状态对象全程跟踪流程数据,确保各节点间数据同步;
- 条件跳转规则支持检索结果不足时的自动重试,提升回答的准确性。
七、协调选择
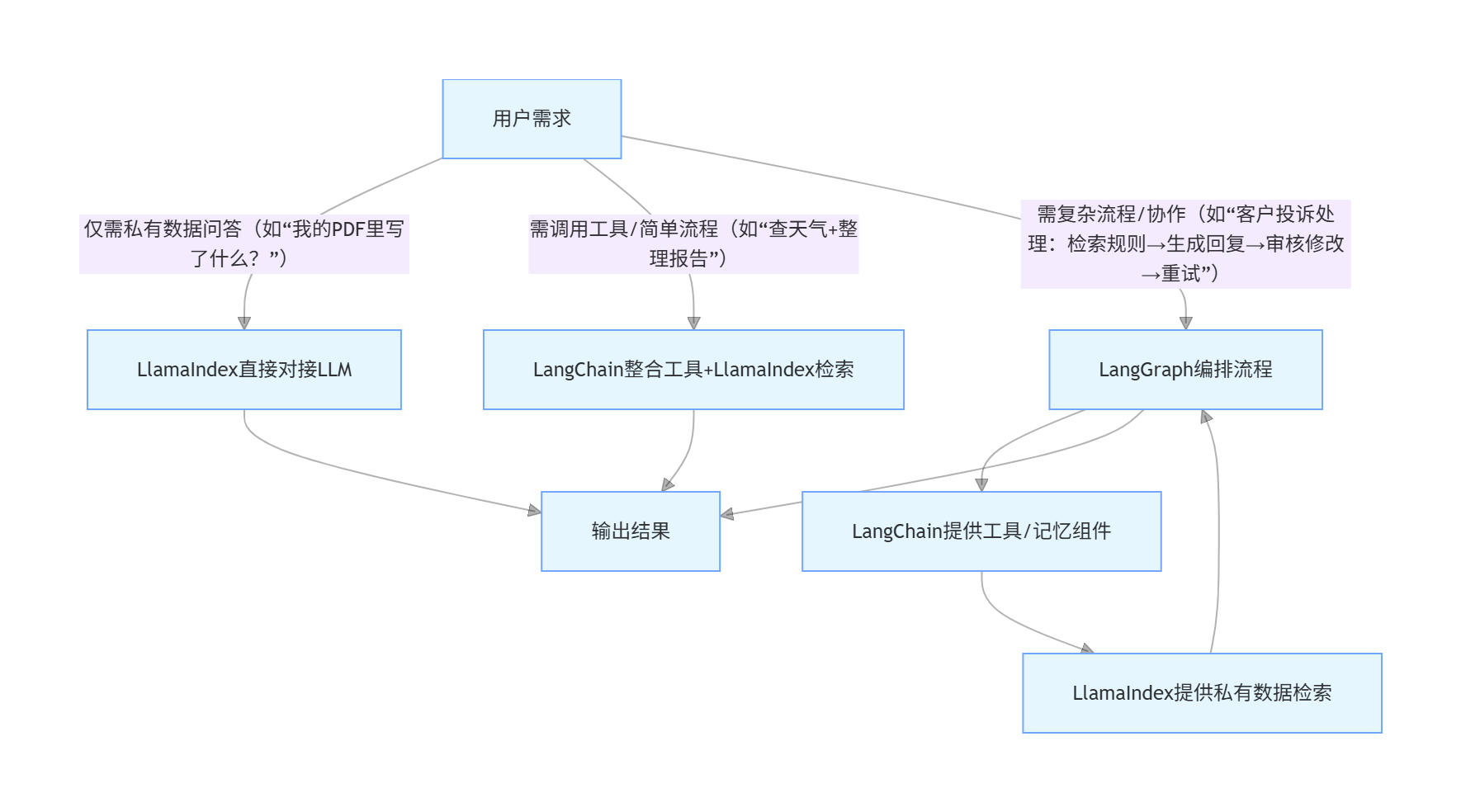
组合建议:
- 仅需私有数据问答(无复杂流程):优先选择 LlamaIndex,开发成本低、检索精准度高,适合快速搭建知识库问答系统;
- 需简单工具集成与线性流程:优先选择 LangChain,组件丰富、生态完善,适合构建基础的工具调用型应用(如单轮问答 + 天气查询);
- 需复杂流程与多智能体协作:选择 LangChain+LangGraph,LangChain 提供基础组件,LangGraph 负责复杂流程编排,适合企业级复杂应用;
- 需私有数据 + 复杂流程:选择 LlamaIndex+LangChain+LangGraph,LlamaIndex 处理数据检索,LangChain 管理工具与记忆,LangGraph 编排复杂流程,实现 “数据 - 工具 - 流程” 的全链路覆盖。
八、总结
LlamaIndex、LangChain 与 LangGraph 作为 LLM 应用开发的核心工具,分别聚焦 “数据处理”“基础编排”“复杂流程” 三大核心环节,形成了互补共生的技术体系。LlamaIndex 解决了 LLM 访问私有数据的核心痛点,LangChain 提供了灵活的组件化开发框架,LangGraph 则填补了复杂流程编排的能力空白。
在实际开发中,我们需根据业务场景的复杂度选择合适的工具组合:
- 简单场景可单独使用 LlamaIndex 或 LangChain;
- 复杂企业级场景则需三者协同,充分发挥各自优势,构建从数据接入到业务落地的完整 LLM 应用系统。
随着 LLM 技术的不断发展,三者的生态将持续完善,为更广泛的业务场景提供支撑。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号