深入解析 MeloTTS:中文 TTS Pipeline 与多音字修正实战
原创
深入解析 MeloTTS:中文 TTS Pipeline 与多音字修正实战
原创
buzzfrog
修改于 2026-02-14 21:40:13
修改于 2026-02-14 21:40:13
MeloTTS 是一个基于 VITS2 架构的高质量、多语言 TTS(文本转语音)系统,以其极快的推理速度和自然的韵律表现著称。虽然它在多语言支持上表现优异,但在中文语境下,多音字(Polyphone) 和 发音错误 仍然是实际工程落地中最大的痛点。
本文将深入剖析 MeloTTS 的中文处理 Pipeline,定位发音问题的根源,并提供三种不同层级的工程化解决方案。
MeloTTS 中文 Pipeline 详解
MeloTTS 的核心流程可以概括为:分句 → 文本归一化 → G2P (字转音) → BERT 特征提取 → 声学模型推理。
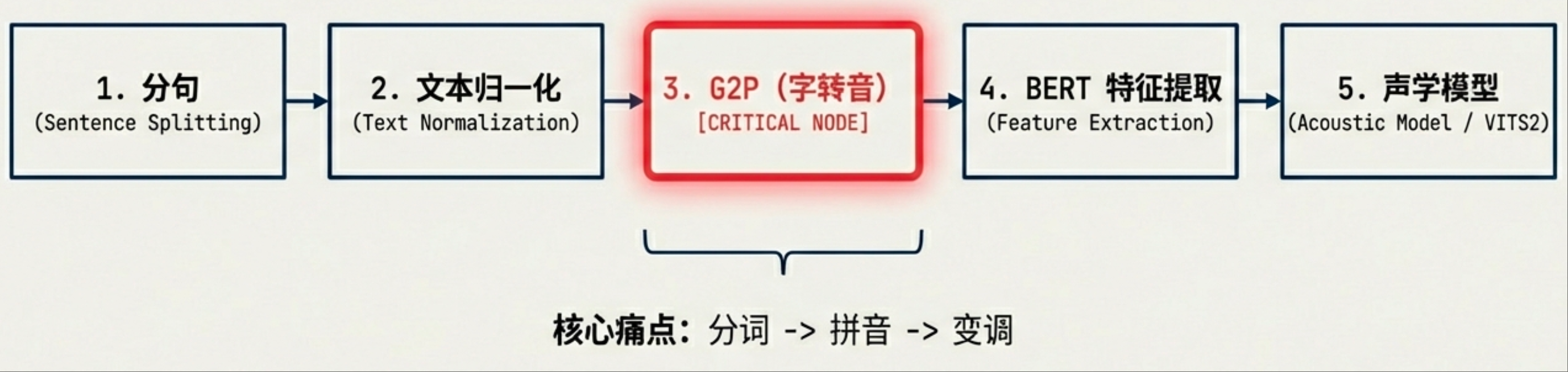
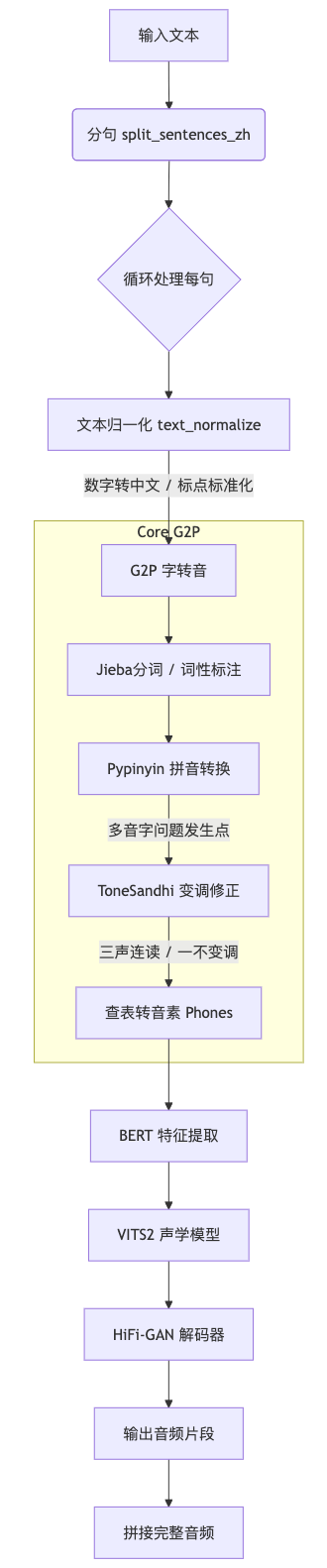
pipeline流程图
1. 分句 (Sentence Splitting)
代码位置: MeloTTS/melo/text/split_utils.py -> split_sentence
长文本在进入模型前,首先会按标点符号(。!?;)被切分成短句。这是为了避免长句导致模型推理不稳定或显存溢出。由于中文和英文的标点符号不同,系统会根据语言选择不同的切分逻辑。
2. 文本归一化 (Text Normalization)
代码位置: MeloTTS/melo/text/chinese_mix.py -> text_normalize
文本经过清洗和标准化:
- 数字转汉字:使用
cn2an将 "2024年" 转换为 "二零二四年"。 - 标点标准化:将中文标点(
,。!?)统一映射为英文标点,便于模型对齐。 - 特殊字符处理:过滤无法发音的特殊符号。
2. G2P:从汉字到音素 (核心环节)
代码位置: MeloTTS/melo/text/chinese.py -> g2p
这是决定发音准确性的关键步骤,主要由三个模块组成:
- 分词 (Segmentation):
使用
jieba进行分词和词性标注。分词的准确性直接影响多音字的判断(例如 "银行" vs "行长")。seg_cut = psg.lcut(text)Output: pair('中国', 'ns'), pair('人民', 'n'), pair('银行', 'n') - 拼音转换 (Pinyin Conversion):
使用
pypinyin库将汉字转换为拼音。 - 痛点:MeloTTS 默认使用lazy_pinyin,这是一种基于词典和规则的转换,不包含上下文语义模型。因此,对于未收录的词组或歧义句,极易出现多音字错误。 - 声调变调 (Tone Sandhi):
代码位置:
MeloTTS/melo/text/tone_sandhi.py这是一个 700+ 行的规则库,处理中文复杂的变调逻辑: - 三声连读 (Sandhi):两个三声相连,前一个变二声(如 "你好")。 - "一"、"不" 变调:根据后字的声调变化("一定" vs "一个")。 - 轻声处理:基于内置的轻声词表进行修正。
3. BERT 特征提取
代码位置: MeloTTS/melo/text/chinese_bert.py
MeloTTS 使用 chinese-roberta-wwm-ext-large 模型提取文本的语义特征。这些特征作为辅助输入喂给声学模型,帮助模型理解句子的语义和语气,从而生成更自然的韵律。
4. 声学模型 (Acoustic Model)
最后,音素序列、声调、BERT 特征和说话人 Embedding 一起输入 VITS2 模型,生成最终的音频波形。
完整流程示例
让我们通过一个例子来直观感受每一步的变化:
输入文本 (Input):
"2024年,小明的银行存款达到了100万元。"
Step 1: 分句 (Sentence Splitting)
["2024年,小明的银行存款达到了100万元。"](这里只有一句,如果是长文会被切分)
Step 2: 文本归一化 (Text Normalization)
"二零二四年,小明的银行存款达到了一百万元."(数字转汉字,标点转英文标点)
Step 3: G2P (Grapheme-to-Phoneme) & 变调
分词:
["二零二四年", ",", "小明", "的", "银行", "存款", "达到", "了", "一百万", "元", "."]拼音:['er', 'ling', 'er', 'si', 'nian', ',', 'xiao', 'ming', 'de', 'yin', 'hang', 'cun', 'kuan', 'da', 'dao', 'le', 'yi', 'bai', 'wan', 'yuan', '.']变调修正:yin2(阳平) +hang2(阳平) 音素:er0 l ing2 er4 s ang1 n ian2 , x iao3 m ing2 d e5 y in2 h ang2 c un2 k uan3 d a2 d ao4 l e5 y i4 b ai3 u an4 y uan2 .
Step 4: BERT 特征提取
提取整句的 Semantic Embedding (1024维向量)
Step 5: VITS2 推理
生成最终音频波形 (.wav)
实战:解决发音错误与多音字问题
针对实际业务中遇到的发音错误,我们推荐三种不同成本和精度的解决方案。
方案一:自定义词典
这是成本最低、见效最快的方法。pypinyin 支持加载自定义词典,我们可以直接覆盖特定词组的发音。
适用场景:修正固定的专有名词、特定领域术语(如 "重载" chóng zài vs zhòng zài)。
实施步骤:
在 MeloTTS/melo/text/chinese_mix.py 或初始化代码中注入:
from pypinyin import load_phrases_dict
# 定义修正词典
custom_phrases = {
'重载': [['chóng'], ['zài']], # 覆盖默认为 zhòng zài 的错误
'行长': [['háng'], ['zhǎng']],
'都': [['dū']], # 强制特定单字读音(慎用)
}
# 加载词典
load_phrases_dict(custom_phrases)优点:
- 无需修改核心代码架构。
- 零推理延迟增加。
- 维护简单(只需维护一份 JSON/Dict)。
方案二:支持手动拼音标注
如果你的系统允许人工介入(如内容编辑后台),可以支持类似 SSML 的拼音标注语法,让用户指定发音。
适用场景:人名、生僻字、极度依赖上下文的多音字。
实施步骤:
修改 chinese_mix.py 中的 _g2p_v2 函数,在分词前增加预处理逻辑,解析标注语法(如 [重:chong2]新)。
# 伪代码示例
def transform_user_notation(text):
# 将 "重(chong2)新" 转换为 pypinyin 可识别的格式或直接替换音素
# 这需要修改 _g2p 内部循环,检测到特定标记时跳过 pypinyin
pass注:由于 MeloTTS 的 G2P 逻辑耦合较深,建议采用“预处理替换”策略,将标注词替换为模型绝对不会读错的同音字(Trick),或者深度修改 _g2p 逻辑支持音素直通。
方案三:替换 G2P 引擎
pypinyin 的静态规则上限较低。要从根本上解决多音字问题,可以替换为基于模型的 G2P 引擎,如 g2pM 或 pypinyin-dict-bert。
适用场景:对全自动生成准确率要求极高,且允许少量推理延迟增加。
实施步骤:
- 安装 g2pM:
pip install g2pM - 修改
MeloTTS/melo/text/chinese.py:
from g2pM import G2pM
model = G2pM()
def _get_initials_finals(word):
# 原逻辑:
# orig_initials = lazy_pinyin(...)
# 新逻辑:
pinyin_list = model(word, tone=True, char_split=False)
# 将 g2pM 的输出转换为 lazy_pinyin 的格式
# ...优点:
- 多音字准确率从 ~85% 提升至 ~98%。
- 无需维护庞大的黑名单词典。
缺点:
- g2pM 模型加载需要额外内存。
- 推理速度轻微下降(但在 GPU 环境下可忽略)。
总结
MeloTTS 的中文效果底子很好,但原生 G2P 较为薄弱。
- 短期修补:使用 方案一(自定义词典),将高频错误加入白名单。
- 长期优化:建议实施 方案三(引入 g2pM),彻底提升多音字识别能力。
对于工程落地,建议先建立一个发音修正配置中心,动态下发自定义词典,配合方案一即可解决 90% 的用户反馈。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号