2025大模型2.0:GPT到DeepSeek技术演进与产业落地报告|附200+份报告PDF汇总下载
原创
2025大模型2.0:GPT到DeepSeek技术演进与产业落地报告|附200+份报告PDF汇总下载
原创
拓端
发布于 2026-02-12 16:20:11
发布于 2026-02-12 16:20:11
当OpenAI在2023年推出ChatGPT时,业界或许未曾预料到,短短两年后大模型会以“2.0”形态重塑产业逻辑。本报告汇总解读基于国家工业信息安全发展研究中心与联想集团联合发布的《2025大模型2.0产业发展报告》,以及哈工大计算学部人工智能学院关于DeepSeek系列模型的技术白皮书,深入剖析大模型从“技术验证”向“商业落地”跃迁的关键节点。数据显示,中国智能算力规模正以33.9%的复合增长率狂奔,预计2027年达1117.4 EFLOPS,这种算力基座的夯实,为DeepSeek-R1等新型模型突破“推理天花板”提供了可能。
大模型1.0时代的“参数竞赛”已演变为2.0时代的“效能博弈”。报告洞察到,DeepSeek-V3以560万美元成本完成6710亿参数训练,仅为Llama 405B模型1/10的投入,这种“算力效率革命”正在打破行业垄断。从企业智能体实践到个人终端升级,大模型正以“混合人工智能”架构渗透生产生活——联想“擎天3.0”平台已在智能客服场景实现运维成本降低50%,而DeepSeek-R1在AIME数学竞赛中79.8%的通过率,更印证了推理能力向人类专家级的逼近。
本报告洞察基于《国家工业信息安全发展研究中心、联想集团:2025大模型2.0产业发展报告》及文末200+份人工智能行业研究报告的数据,最新报告合集及解读实时更新已分享在交流群,阅读原文进群咨询、定制数据报告和600+行业人士共同交流和成长。
一、大模型技术演进:从概率生成到推理优先的范式革命
1.1 技术代际跃迁:从GPT到DeepSeek的架构突破
大模型的进化轨迹呈现清晰的技术脉络:2018年GPT-1以Transformer架构开启预训练时代,2020年GPT-3凭借1750亿参数展现“少样本学习”潜力,但传统LLM的“概率生成”本质,导致其在AIME数学题中出现“铅笔比烤箱重”的逻辑谬误。这种局限性催生了DeepSeek-R1的“推理优先”架构——通过GRPO(分组相对策略优化)算法,该模型在AIME 2024测试中实现79.8%的通过率,较GPT-4o的39.2%提升近一倍(见下图)。
模型 | MMLU(Pass@1) | AIME 2024(Pass@1) | Codeforces(Rating) |
|---|---|---|---|
DeepSeek-R1 | 90.8 | 79.8 | 2029 |
GPT-4o | 87.2 | 39.2 | 1134 |
Claude-3.5 | 88.3 | 16.0 | 717 |
OpenAI o1-121 | 91.8 | 79.2 | 2061 |
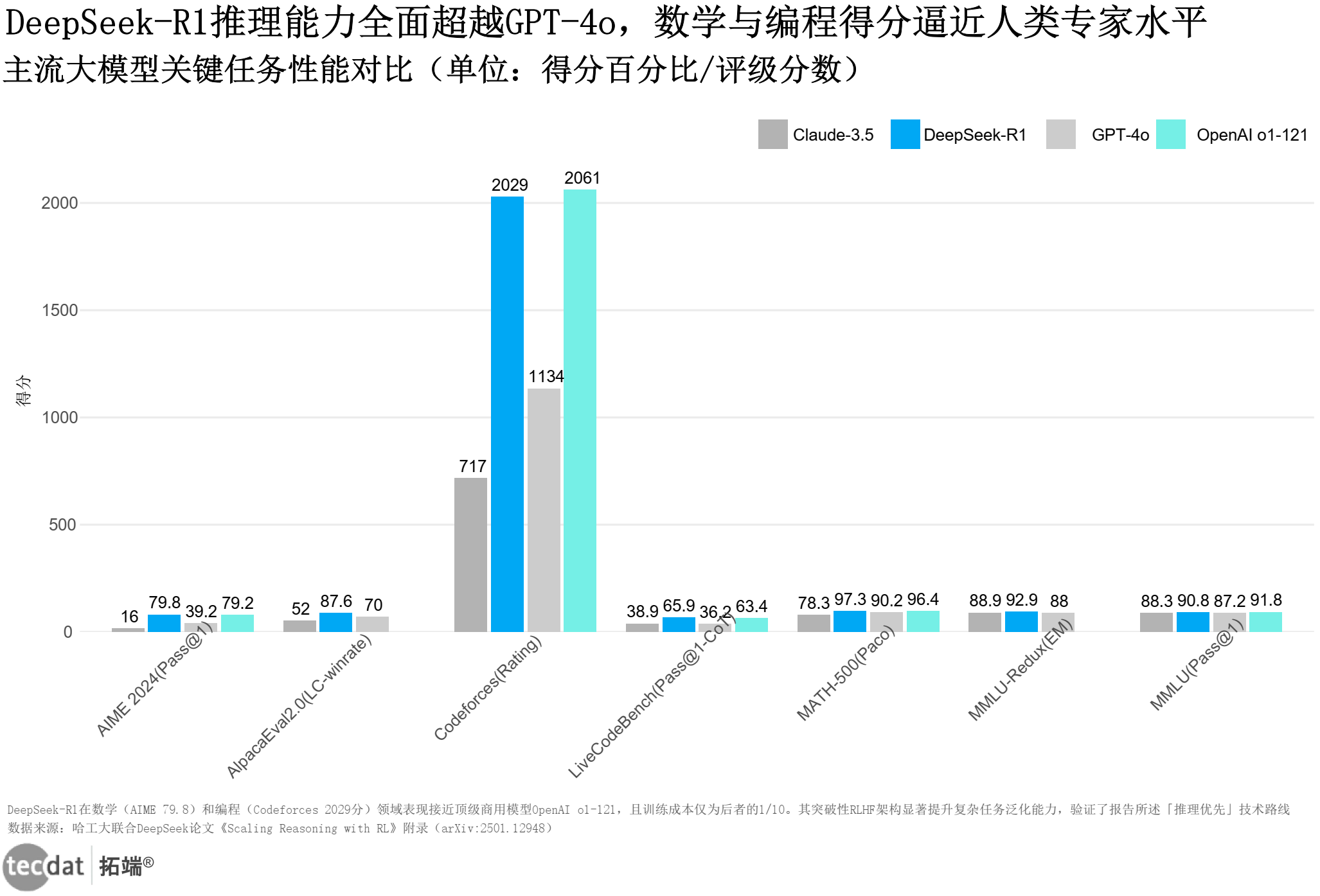
DeepSeek-R1推理能力对比表图表数据及PDF模板已分享到会员群 这种突破源于三重技术创新:一是SFT(监督微调)学习推理格式,使模型掌握数学证明的逻辑链条;二是RL(强化学习)习得推理策略,通过“准确率奖励+格式奖励”双机制优化输出;三是MTP(多词元预测)模块,将传统自回归生成的“逐词猜测”升级为“多词预演”,使Codeforces编程评级达2029分,逼近人类顶级选手水平。
1.2 成本革命:异构计算与算法压缩的双重奏
大模型产业化的核心障碍之一是“天价训练成本”。Llama 405B模型需30.8百万GPU小时、6160万美元投入,这种投入强度令中小企业望而却步。DeepSeek-V3通过“MoE稀疏专家混合+FP8混合精度训练”,将6710亿参数模型的训练成本控制在560万美元,仅为Llama同规模模型的1/10(见下图)。
模型名称 | 总参数量(十亿) | 训练成本(百万美元) | 训练卡时(百万小时) |
|---|---|---|---|
DeepSeek-V3 | 671 | 5.6 | 2.8 |
Llama 405B | 405 | 61.6 | 30.8 |
Llama 70B | 70 | 2.4 | 1.7 |
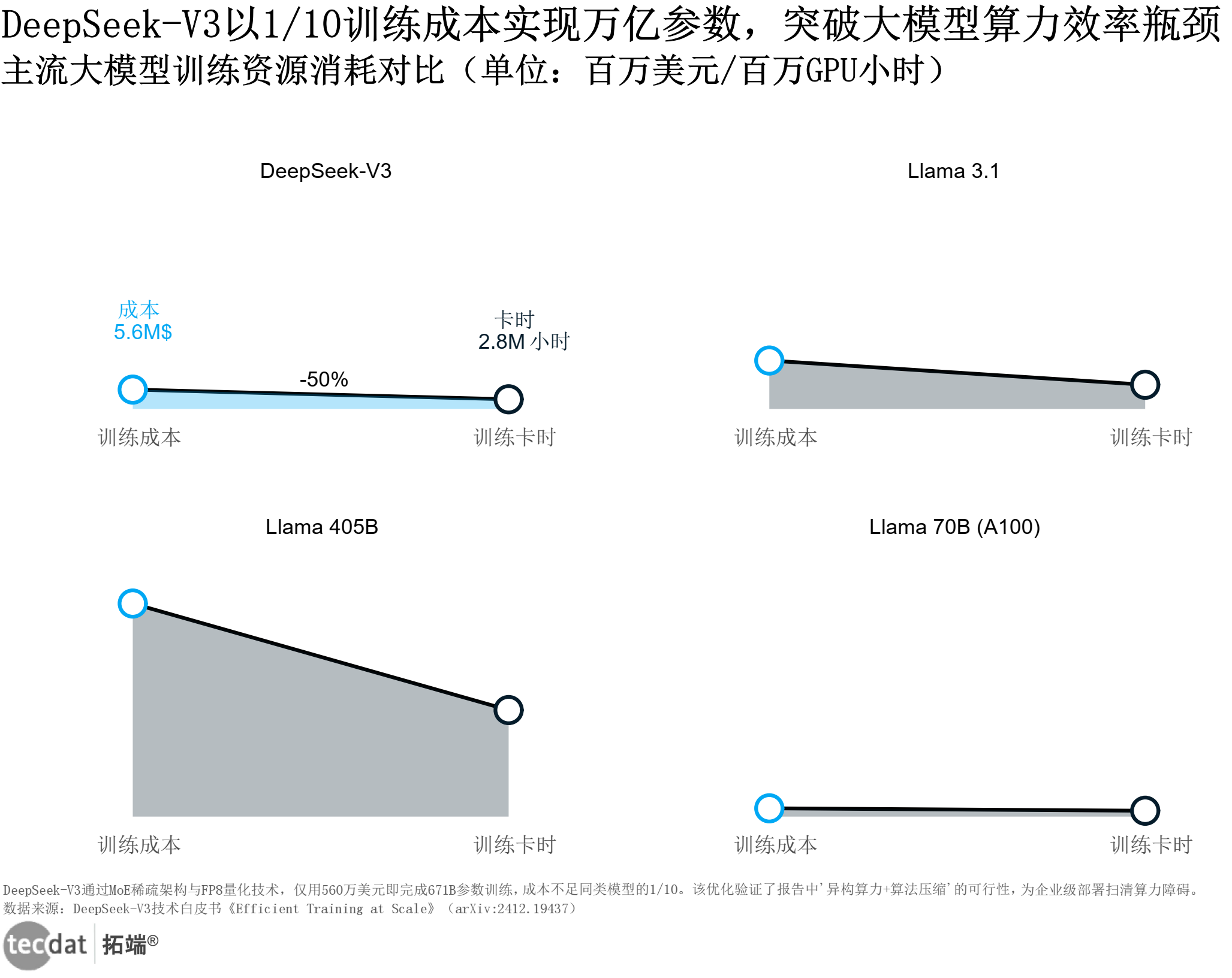
大模型训练成本对比表图表数据及PDF模板已分享到会员群 具体来看,DeepSeekMoE架构将稀疏门控机制与跨节点All-All通信结合,使专家利用率提升3倍;FP8混合精度训练通过动态缩放因子,在保持精度的同时减少40%内存占用;DualPipe流水线技术则实现前向传播与反向传播的重叠计算,硬件利用率突破90%。这种“算法+硬件”的协同优化,使大模型部署从“云端专属”走向“边缘可用”。
二、产业生态重构:从算力基座到智能体落地的全链条变革
2.1 算力基础设施:智能算力的爆发与异构融合
中国智能算力正经历“指数级增长”:2022年111.7 EFLOPS的规模,预计到2027年将达1117.4 EFLOPS,5年10倍增长的背后,是“通用算力+图形算力+智能算力”的混合架构普及(见下图)。
年份 | 算力规模(EFLOPS) |
|---|---|
2022 | 111.7 |
2023 | 180.0* |
2024 | 280.0* |
2025 | 430.0* |
2026 | 650.0* |
2027 | 1117.4 |
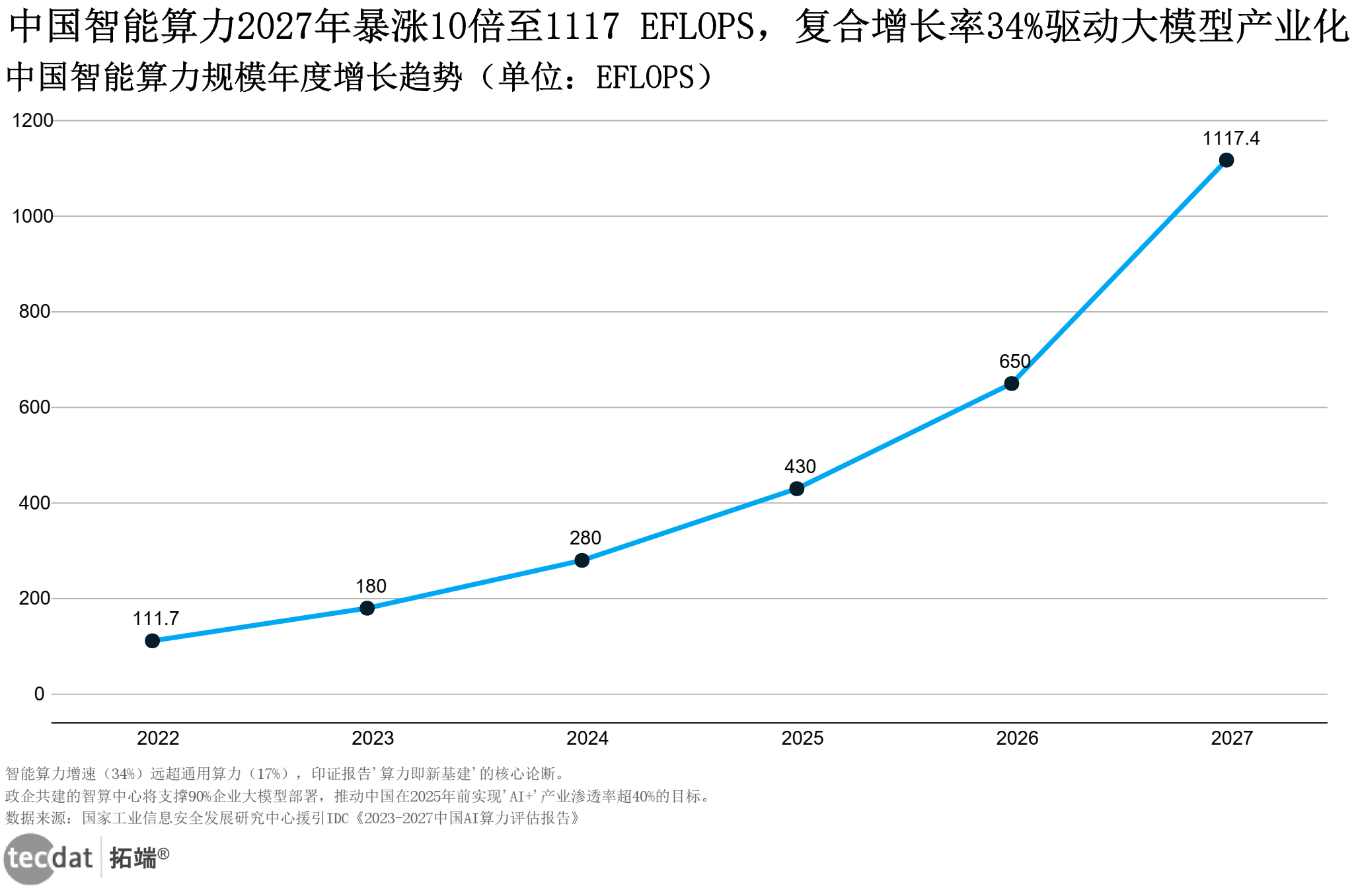
中国智能算力规模预测表图表数据及PDF模板已分享到会员群 这种算力进化呈现三个特征:一是GPU/NPU成为主流,2027年智能算力占比将超70%;二是“私有云+公有云”混合部署成为企业首选,联想“臻算服务2.0”已实现算力按需订阅;三是边缘算力崛起,AIPC、AI Phone等终端嵌入专用AI芯片,使个人大模型本地推理成为可能。
2.2 企业智能体实践:从场景验证到价值闭环
大模型2.0的商业价值在企业场景中集中释放。联想通过“五步走”方法构建智能体:定场景(如智能质检)→轻量微调→开发插件→知识整理→提示词生成,在笔记本屏幕检测场景中,大模型辅助AOI系统实现每小时300台的检测速度,误判率低于0.1%。 更深层的变革发生在生产关系层面:某烟草工厂通过智能体实现制丝生产线水分稳态预测,工艺稳定性提升15%;顺丰科技的AI Agent驱动物流路线优化,运输成本降低12%。这些案例印证了报告提出的“全栈智能化”路径——从“大模型+场景微调”到“大模型+企业私域知识库+场景闭环”,企业正通过智能体重构研发、生产、供应链全流程。
三、未来趋势:从技术突破到伦理框架的多维探索
3.1 技术演进方向:去概率化与目标驱动架构
大模型2.0的未来呈现三大趋势:其一是“去概率化”,通过RAG(检索增强生成)+知识图谱架构,解决传统LLM的“幻觉问题”,DeepSeek-R1-Zero已实现“无监督推理”;其二是“目标驱动架构”,模型从“被动回答”进化为“主动规划”,如医疗智能体可根据患者病史自动生成诊断路径;其三是“轻量化部署”,通过模型压缩技术,30亿参数模型已能在消费级终端流畅运行。
3.2 产业落地挑战:安全与伦理的平衡术
随着大模型渗透金融、医疗等关键领域,“安全-效率”的平衡成为必修课。《生成式人工智能服务管理暂行办法》的出台,标志着监管从“技术放任”转向“合规引导”。企业实践中,联想通过“数据加密+联邦学习”确保训练数据安全,某三甲医院的“本草”医学大模型则建立“伦理审查委员会”,对癌症诊断等敏感场景实施人工复核。 这种平衡需要技术与制度双重保障:技术上,差分隐私、同态加密等确保数据可用不可见;制度上,建立“模型备案-效果评估-风险预警”全流程管理。正如报告强调,大模型的可持续发展,离不开“创新活力”与“安全底线”的动态平衡。
文末:本专题内的参考报告(PDF)目录
- 《国家工业信息安全发展研究中心、联想集团:2025大模型2.0产业发展报告》
- 《哈工大计算学部人工智能学院:大模型原理、技术与应用——从GPT到DeepSeek报告》
- 2025年中国银行业大模型应用跟踪报告 报告2025-06-18
- 2025大模型、Agent、具身智能及人形机器人学习全路径规划报告 报告2025-06-17
- 中文大模型基准测评2025年5月报告 报告2025-06-17
- 2025大模型原理、技术与应用:从GPT到DeepSeek 报告2025-06-17
- 遥感大模型:综述与未来设想 报告2025-06-09
- 2025大模型翻译技术及产业应用蓝皮书 报告2025-06-02
- 金融业AI大模型智算网络研究报告 报告2025-06-02
- 表达力&大模型生产力——与大模型的语言游乐场 报告2025-05-28
- 2025年大模型能力来源与边界报告 报告2025-05-23
- 2025大模型2.0产业发展报告:商业落地创涌而现 报告2025-05-22
- DeepSeek消费电子行业大模型新型应用最佳实践分享 报告2025-05-21
- 质量大模型及其在接口测试场景下的实践 报告2025-05-20
- 2025年医疗大模型研究报告-新质生产力大模型在各医疗场景的赋能实践 报告2025-05-15
- 2025年DeepSeek洞察与大模型应用-人工智能技术发展与应用实践... 报告2025-05-12
- 2025私域大模型部署白皮书 报告2025-05-11
- DeepSeek等大模型工具使用手册(实战篇) 报告2025-05-07
- 2025年大模型平台落地实践研究报告 报告2025-05-07
- 从运维提效到LLMOps:如何用DeepSeek铺就大模型可观测性进阶... 报告2025-05-06
- 2025年面向审计行业DeepSeek大模型操作指南v1.0 报告2025-05-02
- 2023中国银行业大模型用例分析 报告2025-04-30
- 2025年机器语言大模型赋能软件自主可控与安全可信报告 报告2025-04-28
- 2025大模型发展回顾、国内外大模型进展及未来研判分析报告 报告2025-04-25
- Deepseek大模型在银行系统的部署方案设计 报告2025-04-24
- 2025年deepseek大模型生态报告 报告2025-04-22
- 2025年面向工程审计行业的DeepSeek大模型应用指南 报告2025-04-20
- 大模型时代的具身智能 报告2025-04-20
- 人人都能学会的AI指南:从机器学习到大模型全流程解析 报告2025-04-18
- 2025年人人懂AI之从机器学习到大模型报告 报告2025-04-14
- 2025年AI-R-IAM AI就绪的大模型身份与访问管理白皮书 报告2025-04-14
- 2025年基于大模型的企业架构建模助力银行数字化转型应用研究报告 报告2025-04-13
- 2024中国保险业大模型用例分析报告 报告2025-04-13
- 2025年AI大模型教育行业白皮书 报告2025-04-08
- 阿里团队Qwen2.5-1M系列大模型技术报告 报告2025-04-06
- 2025年大模型2.0产业发展报告-商业落地创涌而现 报告2025-04-03
- 计算机行业深度报告-私有化部署需求提升带来大模型一体机投资机会 报告2025-04-01
- 大模型发展图谱与DeepSeek创新应用 报告2025-03-31
- 2024年大模型混合云十大创新技术白皮书5.0 报告2025-03-31
- 2025年中国AI大模型产业市场前景及投资研究报告 报告2025-03-30
- 半导体行业深度报告(十二)-AI大模型竞赛方兴未艾-OpenAI与De... 报告2025-03-29
- 从大模型、智能体到复杂AI应用系统的构建——以产业大脑为例 报告2025-03-26
- 大模型概念、技术与应用实践 报告2025-03-22
- 2025大模型训练性能瓶颈定位流程案例 报告2025-03-21
- 人工智能行业-机器语言大模型赋能软件自主可控与安全可信 报告2025-03-18
- 2025中国多模态AI大模型座舱应用洞察研究报告 报告2025-03-18
- 2025年中国大模型年度评测报告 报告2025-03-16
- 中国金融大模型发展白皮书 报告2025-03-09
- 2025年DeepSeek大模型及其企业应用实践报告(企业篇) 报告2025-03-09
- 金融大模型应用评测报告-摘要版(2024) 报告2025-03-05
- 2025大模型Transformer架构发展历程、优势及未来发展趋势分... 报告2025-03-05
- Grok系列大模型发展历程与技术演进研究报告 报告2025-03-02
- 高质量大模型基础设施研究报告(2024年) 报告2025-02-28
- DeepSeek大模型赋能高校教学和科研 报告2025-02-28
- 2025年电力人工智能多模态大模型创新技术及应用报告 报告2025-02-22
- 中文大模型基准测评2024年度报告 报告2025-02-21
- 如何提升大模型通用推理能力?DeepSeek最新论文《CODEIO:通... 报告2025-02-21
- 2024年中国大模型行业应用优秀案例白皮书 报告2025-02-21
- 2024年大模型时代的异构计算平台报告 报告2025-02-21
- 人工智能行业-大模型概念、技术与应用实践 报告2025-02-18
- 2024生成式大模型安全评估白皮书 报告2025-02-15
- 大模型技术发展及治理实践报告 报告2025-02-10
- 浙江大学医学院附属第四医院:医疗健康大模型白皮书(1.0版) 报告2025-02-08
- 2025大模型时代主要国家破解算力困局的做法及建议 报告2025-02-07
- 大模型驱动的具身智能:发展与挑战 报告2025-02-03
- 百度智能云千帆大模型平台加速企业多模态生成式AI应用落地 报告2025-01-26
- AI终端系列专题(一)-AI故事-《银翼杀手》-以及情感大模型 报告2025-01-24
- 2024年中国AI大模型产业发展与应用研究报告 报告2025-01-22
- 2024年多模态大模型(MLLMs)轻量化方法研究现状和展望报告 报告2025-01-22
- 2024年面向AI大模型的网络使能技术白皮书 报告2025-01-17
- 2024年AI大模型赋能智能座舱研究报告 报告2025-01-16
- 2025年AI大模型发展现状、商业化关键及未来应用前景分析报告 报告2025-01-14
- 2025年大模型应用落地白皮书:企业AI转型行动指南 报告2025-01-12
- 2024年中国大模型行业应用优秀案例白皮书 报告2025-01-08
- 政务服务便民热线大模型研究白皮书(2024年11月) 报告2025-01-05
- 大模型如何判决?从生成到判决:大型语言模型作为裁判的机遇与挑战 报告2025-01-05
- 大模型AI代理的兴起和潜力:综述 报告2025-01-05
- 2024-2025中国AI大模型市场现状及发展趋势研究报告 报告2025-01-05
- 2023年大模型时代的危与机报告 报告2025-01-02
- 2024工商银行人工智能大模型白皮书 报告2024-12-31
- 2024年大模型赋能服务知识库解决方案 报告2024-12-31
- 2024人工智能大模型产业发展应用研究白皮书 报告2024-12-30
- 2024算法与AI大模型的用户认知调研报告 报告2024-12-30
- 大模型在华为推荐场景中的探索和应用 报告2024-12-30
- 电商大模型及搜索应用实践 报告2024-12-26
- 哈工大:2024年具身大模型关键技术与应用报告 报告2024-12-24
- 云计算开源产业联盟:2024开源大模型应用指南1.0(风险治理篇) 报告2024-12-24
- 中移智库:提示工程——大模型中提示词研究 报告2024-12-18
- 量子位:2024年大模型落地与前沿趋势研究报告 报告2024-12-10
- 量子位:2024年大模型落地与前沿趋势研究报告 报告2024-12-10
- 亿欧智库:2024年企业AI大模型应用落地白皮书 报告2024-12-09
- 中移智库:2024提示工程大模型中的提示词设计研究报告 报告2024-12-08
- 天津大学:2024年大模型轻量化技术研究报告(技术的详细讲解) 报告2024-12-05
- Graph AI:大模型浪潮下的图计算白皮书(2024年) 报告2024-11-30
- 清华五道口:大模型技术深度赋能保险行业白皮书(2024) 报告2024-11-24
- 奇安信:2024政务大模型安全治理框架 报告2024-11-24
- 爱分析:2024年AI大模型+知识库市场全景报告 报告2024-11-23
- 宁人研究院:2024年大模型企业出海法律实务报告 报告2024-11-18
- 阿里云:2024年阿里云百炼产品动态-产品&大模型更新动态指南 报告2024-11-18
- 沙利文&头豹:2024年中国行业大模型市场报告 报告2024-11-16
- SuperCLUE:中文大模型基准测评2024年10月报告-2024年... 报告2024-11-14
- 民生证券:计算机行业深度报告-AI搜索-大模型商业落地“第一束光” 报告2024-11-13
- 沙丘社区:2024中国“大模型+智能客服”最佳实践案例TOP10 报告2024-11-06
- 2024年自然语言处理:大模型理论与实践 报告2024-11-04
- 东华大学:2024人工智能中文大模型使用手册 报告2024-11-03
- 用友:YonGPT用友企业服务大模型白皮书(2024) 报告2024-11-01
- 中国传媒大学:大模型深度赋能媒体智创融合-中国智能媒体创新发展报告(2... 报告2024-10-31
- 百度智能云:百度AI大底座大模型研发基础设施方案 报告2024-10-31
- 36氪研究院:2024年具身智能产业发展研究报告:大模型赋能,人形机器... 报告2024-10-22
- 智能小巨人:2024年AI商业观察Vol.04:大模型不止价格战 报告2024-10-17
- OpenAI:《OpenAI+o1大模型》英文技术报告 报告2024-10-17
- 西南财经大学&电子科技大学:自然语言处理:大模型理论与实践 报告2024-10-16
- 阿里云&中国信通院:大模型安全研究报告(2024年) 报告2024-10-16
- 工商银行&华为:2024年大模型驱动的数字员工3.0建设应用白皮书 报告2024-10-14
- 腾讯云&中国信通院:行业大模型标准体系及能力架构研究报告 报告2024-10-12
- 中移智库:“弈衡”多模态大模型评测体系白皮书(2024年) 报告2024-10-11
- 2024年OpenAl最新大模型o1革新进展、突出表现及领域推进作用分... 报告2024-10-09
- 智能财务研究院:2024年人工智能大模型技术财务应用蓝皮书 报告2024-10-06
- 量子位:AI大模型创业格局报告 报告2024-10-06
- 艾瑞咨询:2024年中国工业大模型行业发展研究报告 报告2024-09-30
- 北大国发院&智联招聘:AI大模型对我国劳动力市场潜在影响研究报告(20... 报告2024-09-20
- 艾瑞咨询:2024年中国金融大模型产业发展洞察报告 报告2024-09-20
- 智能小巨人科技:AI商业观察系列:大模型,不止价格战 报告2024-09-19
- 东信大模型评测中心:2024营销大模型评测白皮书 报告2024-09-18
- 腾讯云:2024年AI大模型应用发展研究报告 报告2024-09-13
- 蚂蚁集团&中国信通院:大模型行业可信应用框架研究报告 报告2024-09-11
- 艾瑞咨询:中国政务行业大模型发展洞察 报告2024-09-10
- 2024交互型多模态大模型研究进展、应用前景以及商业模式分析报告 报告2024-09-09
- 中国信通院:大模型落地路线图研究报告(2024年) 报告2024-09-08
- DIIRC:2024年DIIRC大模型行业应用十大典范案例集 报告2024-09-08
- 维科网:2024年AI大模型推动新一代具身智能机器人产业发展蓝皮书 报告2024-09-04
- 头豹&沙利文:2024年中国大模型行研能力年中评测 报告2024-09-02
- 维科网:2024年AI大模型推动新一代具身智能机器人产业发展蓝皮书 报告2024-08-31
- 中国联通:2024中国联通元景大模型AI终端合作白皮书V1.0 报告2024-08-25
- 头豹:2024年中国端侧大模型行业研究:算力优化与效率革命 如何重塑行... 报告2024-08-25
- 智慧图书馆技术应用联盟:2024图书馆领域大模型创新应用需求调研报告(... 报告2024-08-23
- 腾讯:腾讯乐享+大模型-企业智能知识管理跨越式升级 报告2024-08-22
- 头豹研究院:2024年中国端侧大模型行业研究-算力优化与效率革命 如何... 报告2024-08-21
- 腾讯云:2024穿越智算奇点-解锁大模型的无限可能 报告2024-08-19
- 佐思汽研:2024汽车AI大模型TOP10分析报告 报告2024-08-11
- 爱分析:2024大模型+知识库厂商全景报告 报告2024-08-11
- 极客传媒:大模型在融合通信中的应用实践报告 报告2024-08-08
- 德勤:2024年AI大模型时代C端应用生态变局报告 报告2024-08-08
- 中国信通院:大模型基准测试体系研究报告(2024年) 报告2024-08-05
- 华为&中国信通院:2024智算与大模型人才白皮书 报告2024-08-02
- 百度智能云:2024百度智能云案例集:大模型激发新质生产力 报告2024-08-02
- 前瞻产业研究院&华为云:2024年中国AI大模型场景探索及产业应用调研... 报告2024-07-31
- 极客邦科技:大模型领航者AIGC实践案例集锦(第一期) 报告2024-07-31
- 百度智能云:2024水业大模型白皮书 报告2024-07-29
- 清华大学&中关村实验室:2024大模型安全实践白皮书 报告2024-07-28
- 极客邦科技:大模型领航者AIGC实践案例集锦(第一期) 报告2024-07-28
- 径硕科技:AI大模型应用助力企业“营销服”跃进与提效 报告2024-07-25
- ACM SIGSPATIAL中国分会:空间数据智能大模型研究-2024... 报告2024-07-15
- 数说安全:2024安全大模型技术与市场研究报告 报告2024-07-15
- 阿里云:2024大模型典型示范应用案例集 报告2024-07-15
- SuperCLUE:中文大模型基准测评2024年上半年报告 报告2024-07-13
- 鄂尔多斯市数字投资有限公司&华为云:2024矿山产业集群大模型运营最佳... 报告2024-07-11
- 腾讯:2024大模型十大趋势:走进“机器外脑”时代报告 报告2024-07-10
- 点点数据:2024国产AI大模型应用报告 报告2024-07-08
- 沙丘社区:2024中国大模型+数据分析最佳实践案例TOP10报告 报告2024-07-06
- 德邦证券:计算机行业深度-从技术路径-纵观国产大模型逆袭之路 报告2024-07-05
- 头豹:2024年中国大模型行业应用研究-大模型引领智能时代 助力各行业... 报告2024-07-03
- 甲子光年:2024人工智能开源大模型生态体系研究报告 报告2024-06-23
- 中移智库:弈衡人工智能大模型评测平台白皮书(2024年) 报告2024-06-21
- 百度智能云(刘瑛):大模型带来智能客服体验的跃迁 报告2024-06-20
- 渊亭科技:2024军事大模型评估体系白皮书v1.0(精简版) 报告2024-06-05
- 阿里研究院:2024大模型训练数据白皮书 报告2024-05-30
- 中移集智:2024政务大模型产业图谱研究报告 报告2024-05-22
- 赛迪四川:2023中国人工智能大模型企业综合竞争力50强研究报告 报告2024-05-16
- 腾讯研究院:2024行业大模型调研报告-向AI而行共筑新质生产力 报告2024-05-15
- 联合实验室&飞驳科技:2024医疗AI·数字医生与健康科普大模型研究报... 报告2024-05-11
- 爱分析:2024大模型应用实践报告 报告2024-05-10
- 清华大学:superBench大模型综合能力评测报告(2024年3月) 报告2024-05-07
- 北京市科学技术委员会:2024北京市人工智能大模型行业应用分析报告 报告2024-05-07
- 沙丘社区:2024中国大模型先锋案例TOP30 报告2024-05-04
- 极客邦科技:2024年第1季度中国大模型季度监测报告 报告2024-04-30
- 易慧智能&清华大学:大模型驱动的汽车行业群体智能技术白皮书2024 报告2024-04-28
- 商汤科技:2024大模型赋能下的AI 2.0数字人平台白皮书 报告2024-04-24
- InfoQ:2023年第四季度中国大模型季度监测报告 报告2024-04-19
- 头豹:2023年中国大模型行研能力市场探析-大模型底层助力-行研智慧前... 报告2024-04-16
- AI大模型研究框架 报告2024-04-16
- 中国移动:2024大模型时代智算网络性能评测挑战报告 报告2024-04-15
- 沙利文:2024年中国大模型评测报告(摘要版) 报告2024-04-14
- 上海财经大学:大模型在金融领域的应用技术与安全白皮书 报告2024-04-09
- 腾讯研究院:2024工业大模型应用报告 报告2024-04-07
- InfoQ研究中心:2023年第4季度中国大模型季度监测报告 报告2024-03-31
- 人民网&至顶科技:2024年中国AI大模型产业发展报告-开启智能新时代 报告2024-03-31
- 源达信息:人工智能专题研究系列五-Kimi智能助手热度高涨-国产大模型... 报告2024-03-27
- 中国工业互联网研究院:人工智能大模型工业应用准确性测评报告 报告2024-03-23
- 海尔智家:家庭大脑白皮书-大模型时代智慧家庭应用新范式(2024) 报告2024-03-22
- 中国工业互联网研究院:2024人工智能大模型工业应用准确性测评报告-v... 报告2024-03-22
- 6GANA:2023网络大模型十大问题白皮书 报告2024-03-13
- 中国信通院:数字时代治理现代化研究报告(2023年)-大模型在政务领域... 报告2024-03-05
- 清华大学自动化系:2023预训练大模型与医疗:从算法研究到应用 报告2024-03-03
- 6GANA:2023年网络管控大模型白皮书 报告2024-03-02
- 百炼智能:大模型招投标市场分析报告(2023) 报告2024-02-26
- 中国移动研究院:2024面向生产服务的大模型评估体系探讨报告 报告2024-02-25
- 中国软件行业协会:2024人工智能大模型的技术岗位与能力培养研究报告 报告2024-02-22
- 中国信通院:2023大模型落地应用案例集 报告2024-02-17
- 工信安全:大模型赋能智慧办公评测报告-PPT生成 报告2024-02-16
- 中国科学技术大学:2023大模型推荐技术及展望报告 报告2024-02-15
- 之江实验室:2023重构教育图景:教育专用大模型研究报告 报告2024-02-15
- 爱分析:2023大模型厂商全景报告 报告2024-02-15
- 中国信通院:2023工业大模型技术应用与发展报告1.0 报告2024-02-07
- 中国信通院:2023政务大模型建设路径及评价体系研究报告 报告2024-02-05
- 腾讯研究院:大模型安全与伦理研究报告2024 报告2024-02-01
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号