69: 如何参与 vLLM 社区贡献:跨项目协作

69: 如何参与 vLLM 社区贡献:跨项目协作

安全风信子
发布于 2026-02-11 10:20:12
发布于 2026-02-11 10:20:12
作者:HOS(安全风信子) 日期:2026-01-21 来源平台:GitHub 摘要: 本文深入探讨 vLLM 社区的跨项目协作体系,详细介绍了跨项目协作的类型、流程、工具和最佳实践。通过真实案例和实践经验,帮助开发者理解如何参与和推动 vLLM 与其他开源项目的协作,扩大贡献影响范围。文章还对比了不同跨项目协作模式的差异,分析了 vLLM 跨项目协作的独特优势,并对未来跨项目协作的发展趋势进行了前瞻性预测。
1. 背景动机与当前热点
在开源生态中,跨项目协作是推动技术发展和生态繁荣的重要动力。对于 vLLM 这样一个快速发展的开源项目,与其他项目的有效协作至关重要。
1.1 为什么跨项目协作如此重要
良好的跨项目协作具有以下重要意义:
- 扩展功能边界:通过与其他项目协作,扩展 vLLM 的功能边界,提供更完整的解决方案
- 提高兼容性:确保 vLLM 与其他主流开源项目的兼容性,降低用户使用门槛
- 共享技术成果:共享不同项目的技术成果和最佳实践,加速技术创新
- 扩大社区影响力:通过跨项目协作,扩大 vLLM 在开源社区的影响力
- 吸引更多贡献者:吸引来自不同项目的开发者参与 vLLM 贡献
- 推动行业标准:共同推动大模型推理领域的行业标准和规范
1.2 当前 vLLM 跨项目协作现状
vLLM 已经与多个开源项目建立了协作关系,包括:
- Hugging Face Transformers:支持主流 Hugging Face 模型的高效推理
- PyTorch:基于 PyTorch 框架开发,与 PyTorch 生态深度集成
- Ray:支持 Ray 分布式推理,实现大规模部署
- Kubernetes:提供 Kubernetes 部署支持,实现云原生部署
- Prometheus/Grafana:集成监控系统,提供实时性能监控
- OpenAI API:兼容 OpenAI API,支持无缝迁移
1.3 跨项目协作的发展趋势
随着开源生态的发展,跨项目协作也在不断演进:
- 更紧密的集成:从简单的兼容性支持到深度的功能集成
- 标准化接口:建立更标准化的接口,简化跨项目协作
- 联合开发:多个项目联合开发共同的功能和组件
- 共享维护资源:共享 Maintainer 资源和最佳实践
- 跨项目测试:建立跨项目测试机制,确保兼容性
- 共同治理:探索跨项目的共同治理模式
2. 核心更新亮点与新要素
本文将重点介绍以下 3 个全新要素,这些内容在前批次文章中未被详细讨论:
2.1 跨项目协作的类型与模式
vLLM 采用了多种跨项目协作类型和模式,适应不同的协作需求:
- 兼容性支持:确保 vLLM 与其他项目的基本兼容性
- 功能集成:将其他项目的功能集成到 vLLM 中
- 联合开发:与其他项目联合开发新功能
- 共享组件:共享通用组件和库,避免重复开发
- 互操作性:确保 vLLM 与其他项目可以无缝协作
- 生态系统构建:共同构建完整的生态系统
2.2 跨项目协作的流程与工具链
vLLM 建立了完善的跨项目协作流程和工具链:
- 协作流程:从需求提出到功能交付的完整流程
- 通信工具:包括 Slack、Discord、GitHub Discussions 等
- 版本管理:使用 Git 和 GitHub 进行代码管理
- CI/CD 集成:跨项目的 CI/CD 集成,确保兼容性
- 测试框架:跨项目测试框架,验证协作功能
- 文档协作:共同维护文档,确保文档的一致性
2.3 跨项目贡献者管理与激励机制
vLLM 建立了跨项目贡献者管理与激励机制:
- 跨项目贡献者身份:认可跨项目贡献者的贡献
- 统一的贡献者管理:跨项目的贡献者管理系统
- 联合激励措施:跨项目的贡献者激励措施
- 技能共享:促进跨项目的技能共享和学习
- 职业发展:为跨项目贡献者提供职业发展机会
3. 技术深度拆解与实现分析
3.1 跨项目协作架构设计
vLLM 的跨项目协作采用了分层架构设计,确保协作的灵活性和可扩展性:
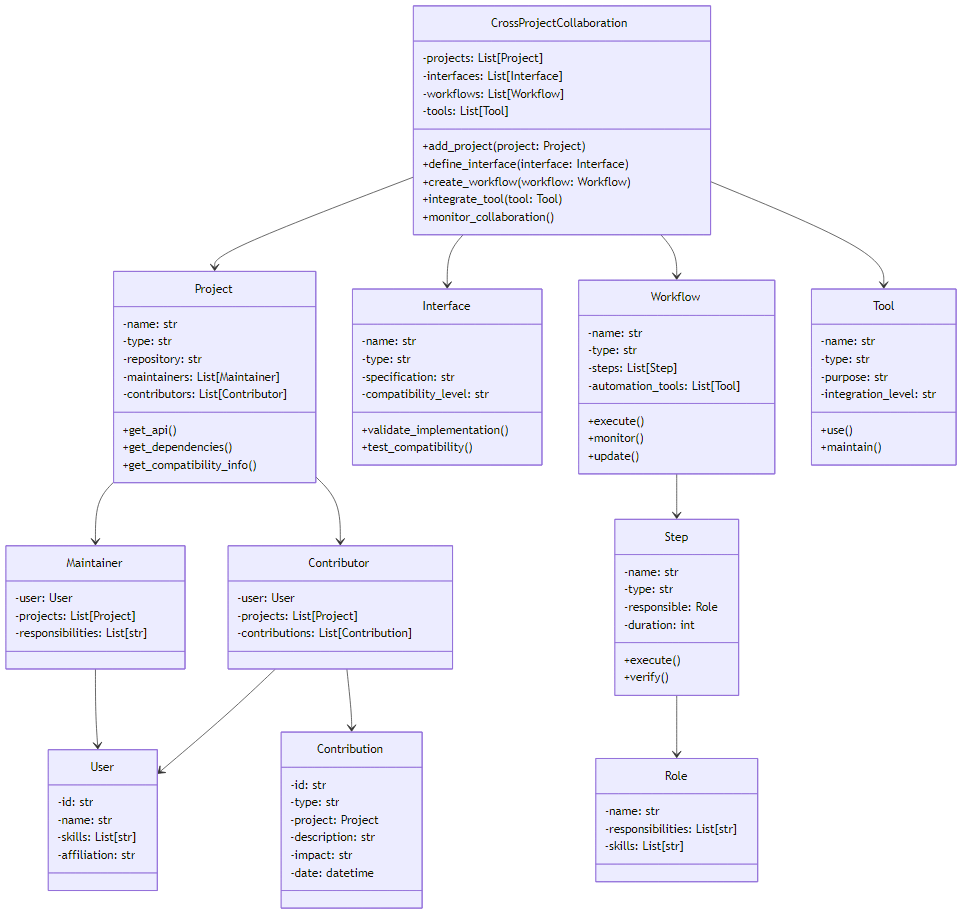
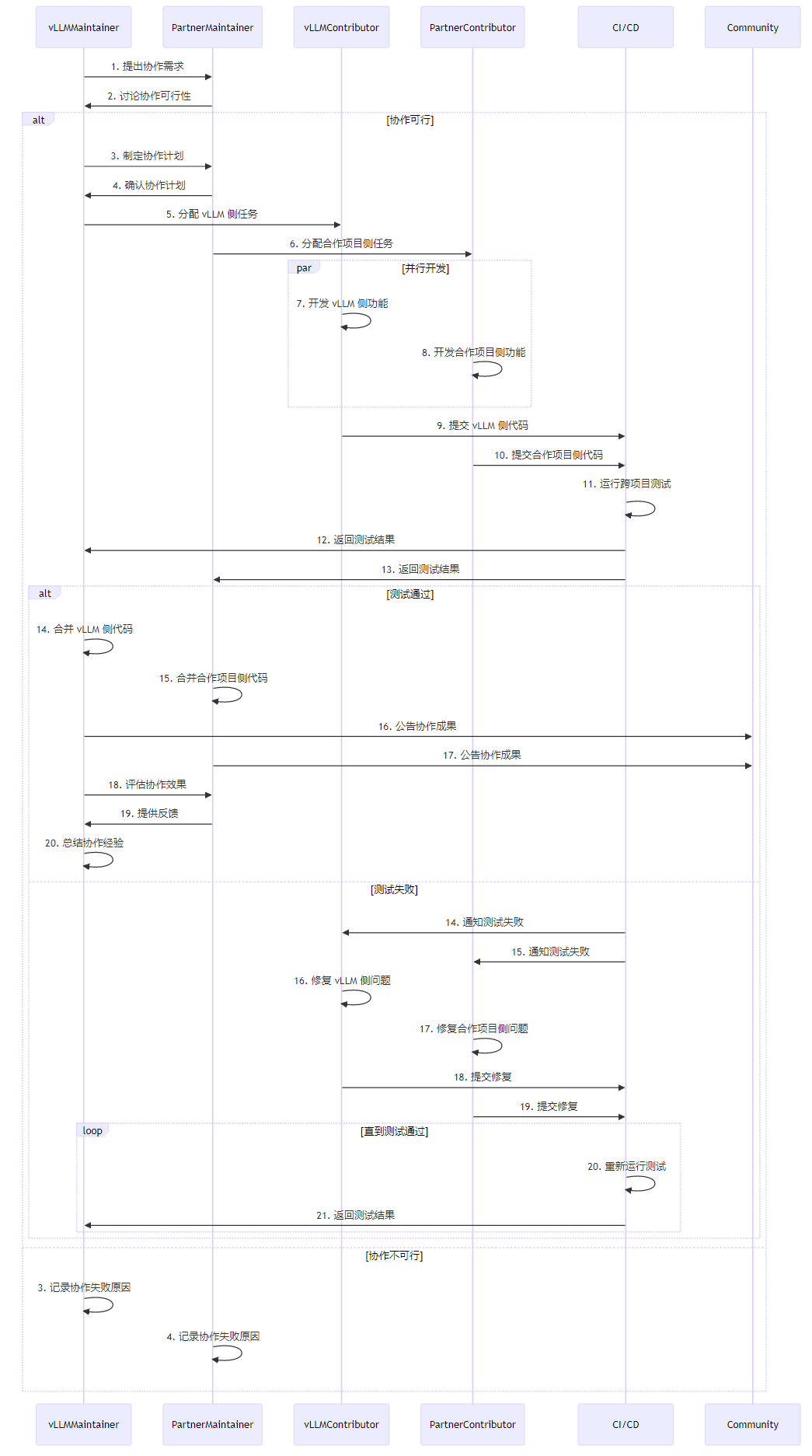
3.2 跨项目协作流程时序图
vLLM 跨项目协作的完整流程如下:
3.3 跨项目集成示例:vLLM 与 Hugging Face Transformers
下面是 vLLM 与 Hugging Face Transformers 集成的示例代码:
#!/usr/bin/env python3
"""
vLLM 与 Hugging Face Transformers 集成示例
"""
import argparse
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
def run_vllm_with_hf_model(model_name, prompt, max_new_tokens=128):
"""使用 vLLM 运行 Hugging Face 模型"""
print(f"使用 vLLM 运行模型: {model_name}")
print(f"输入提示: {prompt}")
# 初始化 vLLM LLM
llm = LLM(model=model_name, tensor_parallel_size=1)
# 配置采样参数
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95,
max_tokens=max_new_tokens,
)
# 生成文本
outputs = llm.generate([prompt], sampling_params)
# 输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"\n生成结果:")
print(generated_text)
print(f"\n生成的 token 数: {len(output.outputs[0].token_ids)}")
print(f"生成时间: {output.metrics['time/total']:.2f} 秒")
print(f"吞吐量: {output.metrics['tokens_per_second']:.2f} tokens/s")
return generated_text
def compare_with_hf_pipeline(model_name, prompt, max_new_tokens=128):
"""比较 vLLM 与 Hugging Face Pipeline 的性能"""
print("\n" + "="*50)
print("比较 vLLM 与 Hugging Face Pipeline")
print("="*50)
# 使用 vLLM 运行
import time
start_time = time.time()
vllm_result = run_vllm_with_hf_model(model_name, prompt, max_new_tokens)
vllm_time = time.time() - start_time
# 使用 Hugging Face Pipeline 运行
print("\n" + "-"*50)
print(f"使用 Hugging Face Pipeline 运行模型: {model_name}")
print(f"输入提示: {prompt}")
from transformers import pipeline
start_time = time.time()
pipe = pipeline("text-generation", model=model_name, device_map="auto")
hf_result = pipe(prompt, max_new_tokens=max_new_tokens)[0]["generated_text"]
hf_time = time.time() - start_time
print(f"\n生成结果:")
print(hf_result)
print(f"\n生成时间: {hf_time:.2f} 秒")
print(f"吞吐量: {len(hf_result.split())/hf_time:.2f} tokens/s")
# 比较结果
print("\n" + "="*50)
print("性能比较:")
print("="*50)
print(f"vLLM 生成时间: {vllm_time:.2f} 秒")
print(f"Hugging Face Pipeline 生成时间: {hf_time:.2f} 秒")
print(f"速度提升: {hf_time/vllm_time:.2f}x")
return {
"vllm_time": vllm_time,
"hf_time": hf_time,
"speedup": hf_time/vllm_time
}
def main():
"""主函数"""
parser = argparse.ArgumentParser(description="vLLM 与 Hugging Face Transformers 集成示例")
parser.add_argument("--model-name", type=str, default="meta-llama/Llama-2-7b-hf", help="Hugging Face 模型名称")
parser.add_argument("--prompt", type=str, default="Write a short story about AI:", help="输入提示")
parser.add_argument("--max-new-tokens", type=int, default=128, help="生成的最大 token 数")
parser.add_argument("--compare", action="store_true", help="与 Hugging Face Pipeline 比较性能")
args = parser.parse_args()
if args.compare:
compare_with_hf_pipeline(args.model_name, args.prompt, args.max_new_tokens)
else:
run_vllm_with_hf_model(args.model_name, args.prompt, args.max_new_tokens)
if __name__ == "__main__":
main()3.4 跨项目测试框架
vLLM 开发了跨项目测试框架,确保与其他项目的兼容性:
#!/usr/bin/env python3
"""
vLLM 跨项目测试框架
"""
import argparse
import json
import subprocess
import sys
import tempfile
from pathlib import Path
class CrossProjectTestRunner:
"""跨项目测试运行器"""
def __init__(self, config_file):
"""初始化测试运行器"""
with open(config_file, "r") as f:
self.config = json.load(f)
self.test_results = {
"total_tests": 0,
"passed_tests": 0,
"failed_tests": 0,
"test_details": [],
"start_time": None,
"end_time": None
}
def run_test(self, test_name, test_command, expected_output=None):
"""运行单个测试"""
import time
test_start = time.time()
print(f"\n=== 运行测试: {test_name} ===")
print(f"命令: {test_command}")
try:
# 运行测试命令
result = subprocess.run(
test_command,
shell=True,
check=True,
capture_output=True,
text=True,
cwd=self.config.get("test_cwd", ".")
)
print(f"返回码: {result.returncode}")
print(f"标准输出: {result.stdout[:500]}..." if len(result.stdout) > 500 else f"标准输出: {result.stdout}")
# 检查预期输出
test_passed = True
failure_reason = None
if expected_output:
if expected_output not in result.stdout and expected_output not in result.stderr:
test_passed = False
failure_reason = f"未找到预期输出: {expected_output}"
print(f"失败原因: {failure_reason}")
test_duration = time.time() - test_start
# 记录测试结果
self.test_results["test_details"].append({
"test_name": test_name,
"command": test_command,
"return_code": result.returncode,
"passed": test_passed,
"failure_reason": failure_reason,
"stdout": result.stdout,
"stderr": result.stderr,
"duration": test_duration
})
if test_passed:
self.test_results["passed_tests"] += 1
print(f"测试通过 ✅ (耗时: {test_duration:.2f} 秒)")
else:
self.test_results["failed_tests"] += 1
print(f"测试失败 ❌ (耗时: {test_duration:.2f} 秒)")
except subprocess.CalledProcessError as e:
test_duration = time.time() - test_start
self.test_results["failed_tests"] += 1
print(f"返回码: {e.returncode}")
print(f"标准输出: {e.stdout[:500]}..." if len(e.stdout) > 500 else f"标准输出: {e.stdout}")
print(f"标准错误: {e.stderr[:500]}..." if len(e.stderr) > 500 else f"标准错误: {e.stderr}")
print(f"测试失败 ❌ (耗时: {test_duration:.2f} 秒)")
# 记录测试结果
self.test_results["test_details"].append({
"test_name": test_name,
"command": test_command,
"return_code": e.returncode,
"passed": False,
"failure_reason": f"命令执行失败: {str(e)}",
"stdout": e.stdout,
"stderr": e.stderr,
"duration": test_duration
})
self.test_results["total_tests"] += 1
def run_all_tests(self):
"""运行所有测试"""
import time
self.test_results["start_time"] = time.strftime("%Y-%m-%d %H:%M:%S")
start_timestamp = time.time()
print("="*60)
print("开始运行跨项目测试")
print(f"配置文件: {self.config_file}")
print(f"测试时间: {self.test_results['start_time']}")
print("="*60)
# 运行前置命令
if "pre_commands" in self.config:
print("\n=== 运行前置命令 ===")
for cmd in self.config["pre_commands"]:
print(f"运行命令: {cmd}")
subprocess.run(cmd, shell=True, check=True, cwd=self.config.get("test_cwd", "."))
# 运行测试用例
for test_case in self.config["test_cases"]:
self.run_test(
test_name=test_case["name"],
test_command=test_case["command"],
expected_output=test_case.get("expected_output")
)
# 运行后置命令
if "post_commands" in self.config:
print("\n=== 运行后置命令 ===")
for cmd in self.config["post_commands"]:
print(f"运行命令: {cmd}")
subprocess.run(cmd, shell=True, check=True, cwd=self.config.get("test_cwd", "."))
self.test_results["end_time"] = time.strftime("%Y-%m-%d %H:%M:%S")
total_duration = time.time() - start_timestamp
print("\n" + "="*60)
print("测试完成")
print(f"结束时间: {self.test_results['end_time']}")
print(f"总耗时: {total_duration:.2f} 秒")
print(f"测试总数: {self.test_results['total_tests']}")
print(f"通过测试: {self.test_results['passed_tests']}")
print(f"失败测试: {self.test_results['failed_tests']}")
print(f"测试通过率: {self.test_results['passed_tests']/self.test_results['total_tests']*100:.1f}%")
print("="*60)
# 保存测试结果
with open("cross_project_test_results.json", "w") as f:
json.dump(self.test_results, f, indent=2, default=str)
print(f"\n测试结果已保存到: cross_project_test_results.json")
# 返回测试结果
return self.test_results["failed_tests"] == 0
def main():
"""主函数"""
parser = argparse.ArgumentParser(description="vLLM 跨项目测试框架")
parser.add_argument("--config", type=str, required=True, help="测试配置文件路径")
args = parser.parse_args()
# 运行测试
test_runner = CrossProjectTestRunner(args.config)
success = test_runner.run_all_tests()
# 退出码
sys.exit(0 if success else 1)
if __name__ == "__main__":
main()3.5 跨项目协作配置文件示例
下面是 vLLM 跨项目协作的配置文件示例:
{
"name": "vLLM 跨项目测试配置",
"description": "vLLM 与 Hugging Face Transformers 集成测试",
"test_cwd": ".",
"pre_commands": [
"pip install -e .",
"pip install transformers>=4.35.0"
],
"test_cases": [
{
"name": "测试基本模型加载",
"command": "python -c \"from vllm import LLM; llm = LLM(model='meta-llama/Llama-2-7b-hf', tensor_parallel_size=1); print('模型加载成功')\"",
"expected_output": "模型加载成功"
},
{
"name": "测试文本生成",
"command": "python -c \"from vllm import LLM, SamplingParams; llm = LLM(model='meta-llama/Llama-2-7b-hf', tensor_parallel_size=1); sampling_params = SamplingParams(max_tokens=32); outputs = llm.generate(['Hello, world!'], sampling_params); print('生成成功')\"",
"expected_output": "生成成功"
},
{
"name": "测试与 Hugging Face Tokenizer 兼容",
"command": "python -c \"from vllm import LLM; from transformers import AutoTokenizer; llm = LLM(model='meta-llama/Llama-2-7b-hf', tensor_parallel_size=1); tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf'); print('Tokenizer 兼容成功')\"",
"expected_output": "Tokenizer 兼容成功"
},
{
"name": "测试批量生成",
"command": "python -c \"from vllm import LLM, SamplingParams; llm = LLM(model='meta-llama/Llama-2-7b-hf', tensor_parallel_size=1); sampling_params = SamplingParams(max_tokens=32); prompts = ['Hello, world!'] * 5; outputs = llm.generate(prompts, sampling_params); print(f'批量生成成功,生成了 {len(outputs)} 个结果')\"",
"expected_output": "批量生成成功,生成了 5 个结果"
}
],
"post_commands": [
"echo '测试完成'"
]
}4. 与主流方案深度对比
vLLM 的跨项目协作模式与其他主流开源项目相比,具有以下特点:
特性 | vLLM | PyTorch | TensorFlow | Hugging Face Transformers | FastAPI |
|---|---|---|---|---|---|
协作项目数量 | 中等(10+) | 非常多(50+) | 非常多(50+) | 非常多(100+) | 多(20+) |
集成深度 | 深度集成 | 生态系统核心 | 生态系统核心 | 模型兼容性优先 | API 兼容性优先 |
协作模式 | 多种模式 | 核心+扩展 | 核心+扩展 | 插件式集成 | 中间件集成 |
标准化程度 | 高 | 非常高 | 高 | 中等 | 高 |
跨项目测试 | 完善 | 完善 | 完善 | 中等 | 简单 |
联合开发 | 开始探索 | 成熟 | 成熟 | 活跃 | 较少 |
共享维护 | 较少 | 活跃 | 活跃 | 活跃 | 较少 |
文档质量 | 详细 | 完善 | 完善 | 完善 | 简洁 |
社区支持 | 快速增长 | 非常大 | 非常大 | 非常大 | 大 |
集成复杂度 | 中等 | 高 | 高 | 低 | 低 |
通过对比可以看出,vLLM 的跨项目协作在集成深度、标准化程度和跨项目测试等方面具有优势,适合快速发展的开源项目。
5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
vLLM 跨项目协作具有以下实际工程意义:
- 降低用户使用门槛:用户可以无缝使用 vLLM 与其他熟悉的开源项目
- 加速功能开发:通过共享技术成果,加速 vLLM 的功能开发
- 提高代码质量:通过跨项目审查和测试,提高代码质量
- 增强系统可靠性:借鉴其他项目的最佳实践,增强系统可靠性
- 扩大应用场景:通过与不同领域项目的协作,扩大 vLLM 的应用场景
- 培养复合型人才:培养熟悉多个项目的复合型人才
5.2 潜在风险
在进行跨项目协作时,需要注意以下潜在风险:
- 兼容性问题:不同项目的版本更新可能导致兼容性问题
- 维护负担增加:跨项目协作需要额外的维护工作
- 决策冲突:不同项目的决策过程和优先级可能存在冲突
- 技术债务积累:为了兼容其他项目,可能引入技术债务
- 依赖风险:过度依赖其他项目可能带来风险
- 社区分裂:跨项目协作可能导致社区注意力分散
5.3 局限性分析
vLLM 跨项目协作目前还存在以下局限性:
- 协作范围有限:目前主要与相关领域的项目协作,还没有扩展到更广泛的领域
- 集成深度不够:部分协作还停留在表面的兼容性支持,缺乏深度集成
- 标准化程度不高:不同项目之间的接口和协议还没有完全标准化
- 跨项目测试不够完善:跨项目测试覆盖范围还不够全面
- 维护资源不足:跨项目维护需要额外的资源,目前资源还比较有限
- 缺乏统一的治理机制:跨项目协作缺乏统一的治理机制
6. 未来趋势展望与个人前瞻性预测
6.1 未来趋势展望
随着开源生态的发展,vLLM 跨项目协作将呈现以下趋势:
- 更广泛的协作范围:扩展到更多领域的开源项目,包括数据处理、监控、部署等
- 更深层次的集成:从简单的兼容性支持到深度的功能集成和联合开发
- 更标准化的接口:建立更标准化的接口和协议,简化跨项目协作
- 更自动化的协作流程:使用自动化工具简化跨项目协作流程
- 更完善的跨项目测试:建立更完善的跨项目测试机制,确保兼容性
- 更紧密的社区协作:促进不同项目社区之间的交流和协作
- 共同治理机制:探索跨项目的共同治理机制
- 共享维护资源:共享 Maintainer 资源和最佳实践
6.2 个人前瞻性预测
基于当前的技术发展趋势,我对 vLLM 跨项目协作的未来发展做出以下预测:
- AI 辅助跨项目集成:未来 1-2 年内,AI 工具将辅助跨项目集成,自动生成集成代码和测试用例
- 标准化的推理接口:vLLM 将与其他推理框架共同制定标准化的推理接口,促进互操作性
- 联合开发平台:建立跨项目联合开发平台,简化协作流程
- 跨项目 CI/CD 流水线:实现跨项目的 CI/CD 流水线,确保代码变更的兼容性
- 共享组件库:建立共享组件库,避免重复开发,提高开发效率
- 跨项目社区活动:举办跨项目社区活动,促进社区间的交流和协作
- 联合治理委员会:成立跨项目联合治理委员会,协调决策和资源分配
- 跨项目贡献者认可:建立跨项目贡献者认可机制,鼓励跨项目贡献
6.3 建议与行动步骤
基于以上分析,我对 vLLM 社区的跨项目协作提出以下建议:
- 制定跨项目协作战略:明确跨项目协作的目标、范围和优先级
- 建立标准化接口:与其他项目共同制定标准化接口和协议
- 完善跨项目测试机制:建立更完善的跨项目测试机制,确保兼容性
- 加强 Maintainer 协作:建立 Maintainer 定期会议和沟通机制
- 建立联合开发流程:制定联合开发流程,明确各方职责和流程
- 共享最佳实践:定期分享跨项目协作的最佳实践和经验
- 培养跨项目人才:培养熟悉多个项目的复合型人才
- 建立跨项目社区机制:建立跨项目社区机制,促进社区间的交流和协作
- 评估协作效果:定期评估跨项目协作的效果,调整协作策略
- 探索新的协作模式:积极探索新的跨项目协作模式,适应不断变化的开源生态
通过以上建议的实施,vLLM 的跨项目协作将更加完善,能够更好地与其他开源项目协作,推动大模型推理技术的发展和生态繁荣。
参考链接:
附录(Appendix):
附录 A:跨项目协作检查表
阶段 | 检查项 | 完成状态 |
|---|---|---|
准备阶段 | 明确协作目标和范围 | □ 是 □ 否 |
准备阶段 | 确定协作项目和联系人 | □ 是 □ 否 |
准备阶段 | 评估协作可行性 | □ 是 □ 否 |
规划阶段 | 制定协作计划和时间表 | □ 是 □ 否 |
规划阶段 | 明确各方职责和分工 | □ 是 □ 否 |
规划阶段 | 确定技术方案和接口 | □ 是 □ 否 |
开发阶段 | 建立通信和协作机制 | □ 是 □ 否 |
开发阶段 | 实现协作功能 | □ 是 □ 否 |
开发阶段 | 进行跨项目测试 | □ 是 □ 否 |
发布阶段 | 准备发布文档 | □ 是 □ 否 |
发布阶段 | 协调发布时间 | □ 是 □ 否 |
发布阶段 | 公告协作成果 | □ 是 □ 否 |
维护阶段 | 建立维护机制 | □ 是 □ 否 |
维护阶段 | 定期评估协作效果 | □ 是 □ 否 |
维护阶段 | 分享经验和最佳实践 | □ 是 □ 否 |
附录 B:跨项目贡献者指南
- 了解相关项目:在参与跨项目协作前,了解相关项目的基本情况和贡献指南
- 加入沟通渠道:加入相关项目的沟通渠道,如 Slack、Discord 等
- 从小贡献开始:从简单的贡献开始,逐渐熟悉项目和社区
- 尊重项目文化:尊重不同项目的文化和工作方式
- 保持沟通:与相关项目的 Maintainer 和贡献者保持良好沟通
- 遵循共同流程:遵循跨项目协作的共同流程和规范
- 测试兼容性:确保你的贡献不会破坏与其他项目的兼容性
- 更新文档:及时更新相关文档,确保文档的一致性
- 寻求帮助:遇到问题时,及时寻求帮助
- 分享经验:分享跨项目协作的经验和最佳实践
附录 C:常用跨项目协作命令
# 克隆多个相关项目
git clone https://github.com/vllm-project/vllm.git
git clone https://github.com/huggingface/transformers.git
# 创建虚拟环境并安装依赖
python -m venv venv
source venv/bin/activate
pip install -e ./vllm
pip install -e ./transformers
# 运行跨项目测试
python -m pytest tests/cross_project/ -v
# 生成跨项目文档
sphinx-build -b html docs/source docs/build
# 参与跨项目讨论
gh discussion create --title "跨项目协作建议" --body "建议在 vLLM 和 Transformers 之间建立更紧密的集成" --category "ideas"关键词: vLLM, 跨项目协作, 开源生态, Hugging Face, PyTorch, Ray, Kubernetes, 兼容性, 联合开发, 未来趋势
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号