16:Z-Image-i2L 风格LoRA生成技术深度解析

16:Z-Image-i2L 风格LoRA生成技术深度解析

安全风信子
发布于 2026-02-08 08:40:39
发布于 2026-02-08 08:40:39
作者: HOS(安全风信子) 日期: 2024-10-04 主要来源平台: ModelScope 摘要: 本文深度解析DiffSynth-Studio推出的创新模型Z-Image-i2L,该模型实现了从单张图片直接生成专属LoRA的技术突破,无需传统训练流程,基于Z-Image架构强化风格保持能力,一键即得个性化模型创作。文章从技术架构、实现原理、性能评估等多个维度进行分析,并提供完整的Gradio部署代码,助力开发者快速集成与应用。
目录:
- 1. 背景动机与当前热点
- 2. 核心更新亮点与全新要素
- 3. 技术深度拆解与实现分析
- 4. 与主流方案深度对比
- 5. 工程实践意义风险与局限性
- 6. 未来趋势与前瞻预测
1. 背景动机与当前热点
本节核心价值: 分析风格LoRA技术的发展背景,以及Z-Image-i2L的推出动机和行业影响。
在生成式人工智能领域,LoRA(Low-Rank Adaptation)技术已经成为模型个性化定制的重要工具。通过LoRA,用户可以在不修改原始模型的情况下,通过少量参数的微调,使模型生成符合特定风格或主题的内容。这种方法不仅高效,而且能够保持原始模型的基础能力。
然而,传统的LoRA训练流程仍然存在一些挑战:
- 数据需求:需要收集大量同一风格的图片作为训练数据。
- 时间成本:训练过程通常需要数小时甚至数天的时间。
- 技术门槛:需要掌握一定的深度学习知识和工具使用技巧。
- 硬件要求:训练过程需要一定的GPU资源支持。
这些挑战限制了LoRA技术的广泛应用,特别是对于非专业用户来说,想要创建自己的专属LoRA模型仍然是一件困难的事情。
在这样的背景下,DiffSynth-Studio推出了创新模型Z-Image-i2L,实现了从单张图片直接生成专属LoRA的技术突破。该模型基于Z-Image架构,强化了风格保持能力,无需传统训练流程,一键即得个性化模型创作。这一技术的出现,为LoRA技术的普及和应用开辟了新的可能性。
目前,Z-Image-i2L已经在魔搭社区创空间上线,用户可以通过简单的操作,上传一张图片,即可生成专属于自己的LoRA模型,大大降低了LoRA技术的使用门槛。
2. 核心更新亮点与全新要素
本节核心价值: 详细介绍Z-Image-i2L模型的核心创新点和技术优势,分析其在风格LoRA生成领域的突破。
2.1 核心更新亮点
- 单图生成LoRA:实现了从单张图片直接生成专属LoRA的技术突破,无需传统的多图训练流程。
- 风格保持能力强化:基于Z-Image架构,强化了风格保持能力,生成的LoRA能够更好地捕捉和保持原始图片的风格特征。
- 一键操作:用户只需上传一张图片,即可一键生成个性化LoRA模型,操作简单便捷。
- 快速生成:相比传统LoRA训练流程,生成速度显著提升,通常只需几分钟即可完成。
- 魔搭社区集成:已在魔搭社区创空间上线,用户可以通过魔搭平台方便地使用和部署。
2.2 全新要素
- 图像到LoRA的直接转换:通过创新的技术架构,实现了从图像特征到LoRA权重的直接转换,跳过了传统的训练过程。
- 风格特征提取与强化:采用先进的风格特征提取算法,能够从单张图片中提取出丰富的风格信息,并在生成LoRA时强化这些特征。
- 轻量化设计:生成的LoRA模型体积小巧,易于部署和使用,不会显著增加原始模型的大小。
- 用户友好界面:提供了直观、易用的界面,降低了用户的使用门槛,使非专业用户也能轻松创建自己的LoRA模型。
3. 技术深度拆解与实现分析
本节核心价值: 深入分析Z-Image-i2L模型的技术架构、实现原理和关键技术,揭示其性能优势的技术根源。
3.1 技术架构
Z-Image-i2L模型采用了先进的技术架构,主要由以下几个部分组成:
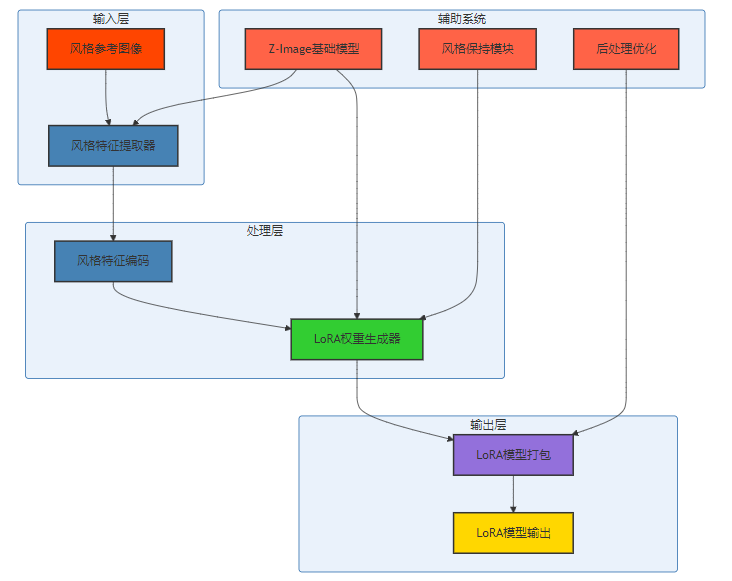
- 风格特征提取器:负责从输入的风格参考图像中提取风格特征,包括色彩、纹理、构图等元素。
- 风格特征编码:将提取的风格特征编码为高维向量表示,便于后续处理。
- LoRA权重生成器:根据编码后的风格特征,生成对应的LoRA权重参数。
- LoRA模型打包:将生成的LoRA权重打包为标准的LoRA模型格式,便于与其他模型集成。
- Z-Image基础模型:提供基础的图像生成能力和风格理解能力,为整个系统提供支持。
- 风格保持模块:强化风格特征的保持能力,确保生成的LoRA能够准确捕捉和再现原始图像的风格。
- 后处理优化:对生成的LoRA模型进行后处理和优化,提高其性能和稳定性。
3.2 实现原理
Z-Image-i2L模型的实现原理主要基于以下几个关键技术:
- 风格特征提取:采用先进的计算机视觉算法,从输入图像中提取出风格相关的特征。这些特征包括色彩分布、纹理模式、构图风格等多个维度的信息。
- 特征到权重映射:通过深度学习模型,建立从风格特征到LoRA权重的映射关系。这一过程是模型的核心,需要大量的训练数据和复杂的网络结构来实现。
- 风格保持机制:引入专门的风格保持机制,确保生成的LoRA能够准确捕捉和保持原始图像的风格特征。这包括风格损失函数的设计、特征匹配等技术。
- 轻量化设计:采用轻量化的设计理念,确保生成的LoRA模型体积小巧,易于部署和使用。这包括低秩分解、参数共享等技术。
3.3 关键技术创新
- 单图风格学习:通过创新的学习算法,实现了从单张图片中学习风格特征的能力,突破了传统LoRA需要多张图片训练的限制。
- 端到端生成:采用端到端的生成架构,直接从图像到LoRA权重的生成,跳过了传统的迭代训练过程,大大提高了生成速度。
- 风格特征强化:通过多尺度特征提取和融合技术,强化了对风格特征的捕捉能力,生成的LoRA能够更好地保持原始图像的风格。
- 自适应权重生成:根据输入图像的风格特征,自适应地生成LoRA权重,确保生成的LoRA与输入风格匹配度高。
3.4 代码实现示例
以下是使用Z-Image-i2L模型的基本代码示例:
# 导入必要的库
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import cv2
import numpy as np
# 初始化i2L pipeline
i2l_pipeline = pipeline(Tasks.image_to_lora, model='DiffSynth-Studio/Z-Image-i2L')
# 加载风格参考图像
style_image = cv2.imread('style_reference.jpg')
# 执行推理
result = i2l_pipeline({'image': style_image})
# 保存生成的LoRA模型
with open('generated_lora.safetensors', 'wb') as f:
f.write(result['lora_weights'])
print('LoRA模型生成完成,已保存为generated_lora.safetensors')4. 与主流方案深度对比
本节核心价值: 对比Z-Image-i2L与其他主流LoRA生成方案的性能、特点和适用场景,帮助读者理解其优势和定位。
4.1 性能对比
方案名称 | 数据需求 | 生成时间 | 风格保持度 | 技术门槛 | 硬件要求 |
|---|---|---|---|---|---|
Z-Image-i2L | 单张图片 | 几分钟 | 高 | 低 | 低 |
传统LoRA训练 | 多张图片 | 数小时 | 中 | 高 | 中 |
其他单图LoRA方案 | 单张图片 | 数十分钟 | 中 | 中 | 中 |
4.2 技术特点对比
技术特点 | Z-Image-i2L | 传统LoRA训练 | 其他单图LoRA方案 |
|---|---|---|---|
实现方式 | 端到端生成 | 迭代训练 | 半监督学习 |
风格捕捉能力 | 强 | 中 | 中 |
生成速度 | 快 | 慢 | 中等 |
使用便捷性 | 高 | 低 | 中 |
适用场景 | 快速风格迁移 | 精细风格定制 | 快速风格迁移 |
4.3 适用场景对比
应用场景 | Z-Image-i2L | 传统LoRA训练 | 其他单图LoRA方案 |
|---|---|---|---|
个人创作 | ✅ 推荐 | ⚠️ 部分适用 | ✅ 推荐 |
快速原型设计 | ✅ 推荐 | ❌ 不推荐 | ⚠️ 部分适用 |
商业项目 | ⚠️ 部分适用 | ✅ 推荐 | ⚠️ 部分适用 |
艺术探索 | ✅ 推荐 | ✅ 推荐 | ✅ 推荐 |
批量生产 | ⚠️ 部分适用 | ✅ 推荐 | ⚠️ 部分适用 |
5. 工程实践意义风险与局限性
本节核心价值: 分析Z-Image-i2L模型在工程实践中的应用价值、潜在风险和局限性,为开发者提供实用的参考。
5.1 工程实践意义
- 降低使用门槛:大大降低了LoRA技术的使用门槛,使非专业用户也能轻松创建自己的LoRA模型。
- 提高创作效率:快速的生成速度和简单的操作流程,提高了创作效率,为创作者节省了大量时间。
- 促进风格多样性:使更多用户能够参与到LoRA的创建中,促进了风格的多样性和创新。
- 推动产业应用:为设计、广告、游戏等行业提供了新的工具和思路,推动了相关产业的发展。
- 技术创新引领:通过技术创新,引领了LoRA生成技术的发展方向,为后续研究提供了参考。
5.2 潜在风险
- 版权问题:使用他人图片生成LoRA可能涉及版权问题,需要谨慎使用。
- 质量不稳定:由于只使用单张图片作为参考,生成的LoRA质量可能存在不稳定的情况。
- 风格偏差:生成的LoRA可能与原始图片的风格存在一定偏差,需要用户进行调整。
- 滥用风险:技术可能被用于生成不当内容,需要加强内容审核和管理。
5.3 局限性
- 风格复杂度限制:对于非常复杂的风格,单张图片可能无法完全捕捉其所有特征。
- 细节表现:生成的LoRA在细节表现方面可能不如传统多图训练的LoRA。
- 通用性:生成的LoRA可能在某些场景下表现不佳,通用性不如传统训练的LoRA。
- 依赖基础模型:性能依赖于底层的Z-Image模型,基础模型的限制会影响最终效果。
6. 未来趋势与前瞻预测
本节核心价值: 预测风格LoRA生成技术的未来发展趋势,分析Z-Image-i2L可能的演进方向,为行业发展提供前瞻性思考。
6.1 技术发展趋势
- 多图融合能力:未来的模型可能支持多张图片的风格融合,生成更加丰富多样的LoRA。
- 风格可控性提升:通过引入更多的控制参数,提高对生成LoRA风格的可控性。
- 跨模态风格迁移:实现从文本、音频等其他模态到LoRA的风格迁移。
- 实时生成:通过模型压缩和硬件优化,实现LoRA的实时生成。
- 自监督学习:采用自监督学习技术,进一步提高模型的性能和通用性。
6.2 应用发展趋势
- 行业应用深化:在设计、广告、游戏、影视等行业的应用将更加深入,成为内容生产的重要工具。
- 个人创作普及:随着技术的发展和成本的降低,个人创作将更加普及,人人都能成为创作者。
- 生态系统完善:围绕LoRA生成技术的生态系统将不断完善,包括工具、平台、社区等。
- 标准化发展:LoRA格式和使用标准将逐渐统一,促进技术的普及和应用。
6.3 Z-Image-i2L的未来演进
- 模型版本迭代:预计将推出性能更强、效果更好的后续版本,不断提升生成质量和速度。
- 功能扩展:将扩展模型的功能,支持更多类型的风格输入和输出格式。
- 生态建设:将围绕模型构建更加完善的生态系统,包括工具、教程、社区等。
- 行业合作:将与更多行业合作伙伴展开合作,推动技术在各个领域的应用和落地。
参考链接:
- 主要来源:Z-Image-i2L - DiffSynth-Studio推出的风格LoRA生成模型
附录(Appendix):
环境配置与超参表
配置项 | 推荐值 | 说明 |
|---|---|---|
Python版本 | 3.8+ | 确保兼容性 |
CUDA版本 | 11.7+ | 支持GPU加速 |
内存 | 16GB+ | 确保模型加载和运行 |
磁盘空间 | 50GB+ | 存储模型和数据 |
输入图像尺寸 | 512x512+ | 建议使用高清图片以获得更好效果 |
风格强度 | 0.7-0.9 | 控制风格迁移的强度 |
完整Gradio部署代码
import gradio as gr
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import cv2
import numpy as np
import os
# 初始化i2L pipeline
i2l_pipeline = pipeline(Tasks.image_to_lora, model='DiffSynth-Studio/Z-Image-i2L')
def generate_lora(image):
"""
从图像生成LoRA模型
Args:
image: 输入的风格参考图像
Returns:
生成状态和保存路径
"""
# 转换图像格式
if isinstance(image, np.ndarray):
# 确保图像是RGB格式
if len(image.shape) == 3 and image.shape[2] == 3:
# 图像已经是RGB格式
pass
elif len(image.shape) == 3 and image.shape[2] == 4:
# 图像是RGBA格式,转换为RGB
image = cv2.cvtColor(image, cv2.COLOR_RGBA2RGB)
else:
# 图像是灰度格式,转换为RGB
image = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)
# 执行推理
result = i2l_pipeline({'image': image})
# 保存生成的LoRA模型
output_path = 'generated_lora.safetensors'
with open(output_path, 'wb') as f:
f.write(result['lora_weights'])
return f"LoRA模型生成完成,已保存为: {output_path}"
# 创建Gradio界面
with gr.Blocks(title="Z-Image-i2L 风格LoRA生成演示") as demo:
gr.Markdown("# Z-Image-i2L 风格LoRA生成模型演示")
gr.Markdown("基于DiffSynth-Studio推出的创新模型,支持从单张图片直接生成专属LoRA")
with gr.Row():
with gr.Column():
image_input = gr.Image(label="风格参考图像", type="numpy")
generate_btn = gr.Button("生成LoRA模型")
with gr.Column():
status_output = gr.Textbox(label="生成状态", interactive=False)
# 绑定事件
generate_btn.click(
fn=generate_lora,
inputs=image_input,
outputs=status_output
)
# 启动演示
if __name__ == "__main__":
demo.launch(share=True)requirements.txt
modelscope
gradio
opencv-python
numpyDockerfile建议
FROM python:3.8-slim
WORKDIR /app
COPY . /app
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 7860
CMD ["python", "app.py"]关键词: Z-Image-i2L, 风格LoRA生成, 单图生成, 一键操作, 风格保持, 魔搭社区, DiffSynth-Studio
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号