用Go重构C++老系统,一次降本82%的极致之旅

用Go重构C++老系统,一次降本82%的极致之旅

腾讯云开发者
发布于 2026-02-04 10:42:13
发布于 2026-02-04 10:42:13
01、背景:当“大力”不再“出奇迹”
该服务是 QQ 游戏生态中的核心基础设施之一,具有极高的并发写特性,直接关系到用户成就的实时展示与游戏权益的即时到账。
重构前规模: 部署 XX台 服务器(4核8G),在热门游戏活动期间仍面临巨大的资源压力和数据一致性挑战。
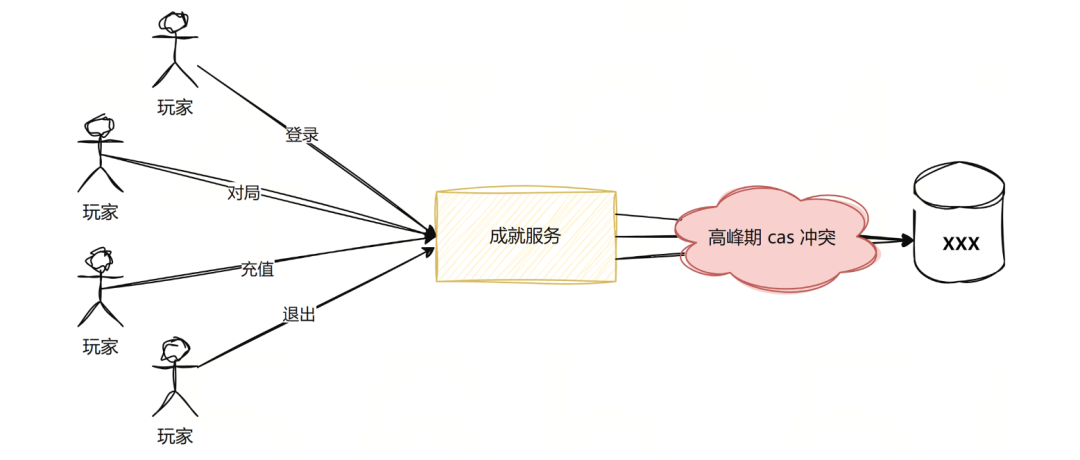
重构前,系统是基于 C++ 的同步直写架构。这就好比你去银行存钱,柜员(服务器线程)必须当着你的面(同步),跑去金库(CMEM),确认金额,存进去,然后再跑回来告诉你“好了”。 如果是平时还好,但到了腾讯旗下国民级体量的游戏搞活动时,成千上万个玩家同时挤在柜台前,甚至同一个玩家的多个行为并发上报(比如同时触发“登录”和“等级提升”),面临的压力就非常大。
C++ 老代码在处理这种并发时,采用的是乐观锁 CAS(Compare-And-Swap)机制。
痛点很明显:
- 资源利用率低: 大量线程阻塞在 I/O 等待上,为了维持并发度,我们不得不往上堆服务器规模。
- CAS 碰撞惨烈: 在
CAchieveSetImpl::ProcessData中,多个线程同时抢占同一个用户的版本号,谁手快谁赢,手慢的只能报错重试或者丢弃。
02、架构演进:从“大乱斗”到“流水线”
2.1 痛点:同步直写的“大乱斗”
在 C++ 旧版本中,我们的处理模型是典型的同步阻塞: Request→ProcessData→ Get(CAS Ver)→Calc→Commit(CAS Ver)。这就像 10 个线程同时去抢这一个数据版本号,只要有一个线程 Commit 成功,版本号变更,其余 9 个线程的 Commit 就会因为版本不一致而失败,导致大量的 CPU 浪费在无效计算和重试上。
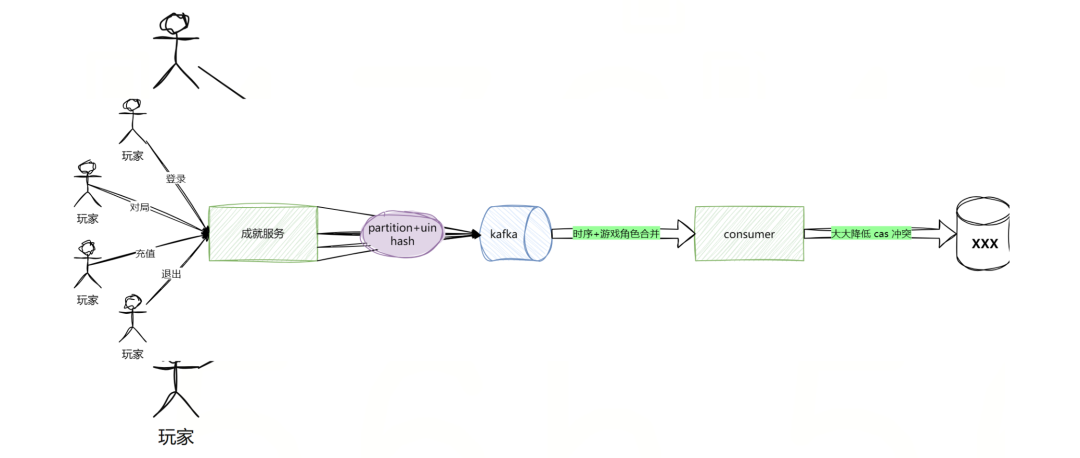
2.2 破局:Kafka 分区的“单行道”
重构的核心在于引入 Kafka 并利用其 Partition 机制。我们将用户的 UIN 作为 Partition Key,确保同一个用户的请求永远落在同一个 Partition。 而后端的 Go 服务作为 Consumer,单协程顺序读取 Partition 数据。在物理层面,我们将“并发写”变成了“串行写”。
03、代码重构: 系统的“减脂增肌”
架构决定上限,但代码细节决定下限。让我们把镜头拉近,看看 C++ 和 Go 在处理核心逻辑时的“降维打击”。
3.1 消失的 CAS 噩梦
虽然新架构依然保留了 CAS 机制作为兜底防线,但两者的生存环境天差地别。
- C++ (achieve_set_impl.cpp): 在 ProcessData 中,业务逻辑与存储 IO 高度耦合。代码先执行 oDs.Get 获取数据,经过一堆 UpdateOriginType 计算后,调用 oDs.QuickCommit。 问题: 在 Get 和 Commit 之间的时间窗口(Time Window),其他线程随时可能修改数据,导致 QuickCommit 频繁返回失败,日志中充斥着大量的重试错误。
- Go (achieve.go): 代码结构看似类似:GetAchieveData→逻辑处理→Proxy.Set(... WithSetCas(cas))。 优化: 得益于 Kafka 的串行化,当 Go 协程拿到数据时,几乎没有其他协程在竞争同一个 Key。这里的 CAS 仅仅是为了防止极端情况(如重平衡)下的数据覆盖,冲突率从重构前的两位数百分比降至接近 0%。代码逻辑变得异常纯粹:
// Go 版本的逻辑:清晰、自信
func (a *Achieve) ProcessAchieveData(...) error {
// 1. 获取数据 (因为串行,这里的 CAS 版本号极大概率是最新的)
cas, memAchieveInfo, err := a.GetAchieveData(ctx, cmemKey)
// 2. 内存计算 (更新逻辑与 C++ 保持一致,但没有了锁的焦虑)
// ...
// 3. 落库 (这一步几乎不会因为 CAS 失败)
if changed {
a.Proxy.Set(ctx, cmemKey, memAchieveInfo, ..., WithSetCas(cas))
}
}3.2 复杂用户数据的分裂
当用户成就数据过大时,我们需要将其拆分存储到子 Key 中。这部分逻辑的重构,充分体现了 Go 在数据结构操作上的便捷性。
- C++ 的“迭代器地狱”: 在 ClearOldAchieveInfo 中,为了保留最新的 100 条数据,C++ 代码不得不创建一个 multimap,将 lLastModifyTime 作为 Key 进行排序。
// C++ 代码片段:为了排序不得不折腾一遍 multimap
multimap<long long, SGCAchievePlayer> mapAllPlayerInfo;
for (; it != mapAllData.end(); ++it) {
mapAllPlayerInfo.insert(pair<long long, SGCAchievePlayer>(stAchieveData.lLastModifyTime, it->first));
}
// 然后反向迭代器遍历删除...这种写法不仅内存开销大(这就解释了为什么旧服务需要 8G 内存),而且迭代器失效(Iterator Invalidation)的风险极高。
- Go 的“优雅切片”: 同样的逻辑在 Go 的 fillOldAchieveInfo 中,我们利用 sort.Slice 轻松搞定:
// Go 代码片段:原生切片排序,清爽自然
sort.Slice(playerDataList, func(i, j int) bool {
return playerDataList[i].data.LLastModifyTime > playerDataList[j].data.LLastModifyTime
})
// 直接切片操作,无需额外的复杂容器逻辑更直观,内存抖动更小,代码量减少了近 40%。
3.3 数据合并策略优化
通过按角色(player)维度对上报消息分组,并按时间戳排序,确保每个type类型只保留最新数据。这种合并策略将原本可能产生的多次CAS竞争减少为单次操作。
// 按角色分组 + 时间戳排序 + 智能合并
type itemWithTS struct {
item achieve.SAchieveReportItem
ts int64 // Kafka消息的时间戳
}
func (a *AchievesLogic) ReportAchieveData(ctx context.Context, aMsgs []*model.AchieveMsg) {
playerItems := map[common.SGCAchievePlayer][]*itemWithTS{}
// 1. 按角色(平台+区+服+角色ID)分组
for _, aMsg := range aMsgs {
player, items := parseReportData(aMsg)
playerItems[player] = append(playerItems[player], items...)
}
// 2. 每个角色的数据按时间戳倒序排列(新的在前)
for _, items := range playerItems {
sort.Slice(items, func(i, j int) bool {
return items[i].ts > items[j].ts
})
}
// 3. 去重:同一个type只保留最新的
for player, items := range playerItems {
existType := map[int32]struct{}{}
typesTS := map[int32]int64{} // 记录每个type的最新时间戳
mergedVecData := []achieve.SAchieveReportItem{}
for _, item := range items {
if _, ok := existType[item.item.IType]; ok {
continue // 已经有更新的了,跳过
}
typesTS[item.item.IType] = item.ts
existType[item.item.IType] = struct{}{}
mergedVecData = append(mergedVecData, item.item)
}
// 4. 合并后的数据
reportData := aMsgs[0].Data
reportData.VecData = mergedVecData
err := a.Store.ProcessAchieveData(ctx, reportData, typesTS)
}
}04、战果:用数据说话
这次重构不仅是语言的迁移,更是对系统吞吐模型的重塑。
1、资源成本骤降 82%
- 从最初的堆服务器规模承压,到现在的服务器规模大幅减少。
- 分析: Go 的 Goroutine 极大地降低了 IO 等待时的上下文切换开销,配合 Kafka 的削峰填谷,我们用 26% 的算力 支撑起了同样的业务量。
2、稳定性指标跃升
- CAS 写入错误率:99.9% 消除。
- 接口平均耗时:降低 40%(省去了无效的 CAS 重试时间)。
指标 | 重构前 | 重构后 | 优化幅度 |
|---|---|---|---|
服务器数量 | xxx台 | xx台 | 减少82% |
CPU核数 | xxx核 | xxx核 | 减少73% |
内存规格 | xxxxG | xxxG | 减少91% |
综合成本 | - | - | 减少82% |
3、告警与监控能力提升
- 告警降噪: 之前大量由 CAS 冲突引发的“无效”告警被彻底清除,告警系统真正聚焦于底层存储异常或业务逻辑错误,提升了告警的有效性与优先级。
- 关键指标细化: 基于 伽利略 的监控指标集成,我们能够更精细地监控 Kafka 消费延迟、Goroutine 数量、内存分配等微观指标,对服务健康度有了更深层次的洞察。
4、掌控核心业务数据大盘,实现精细化运营
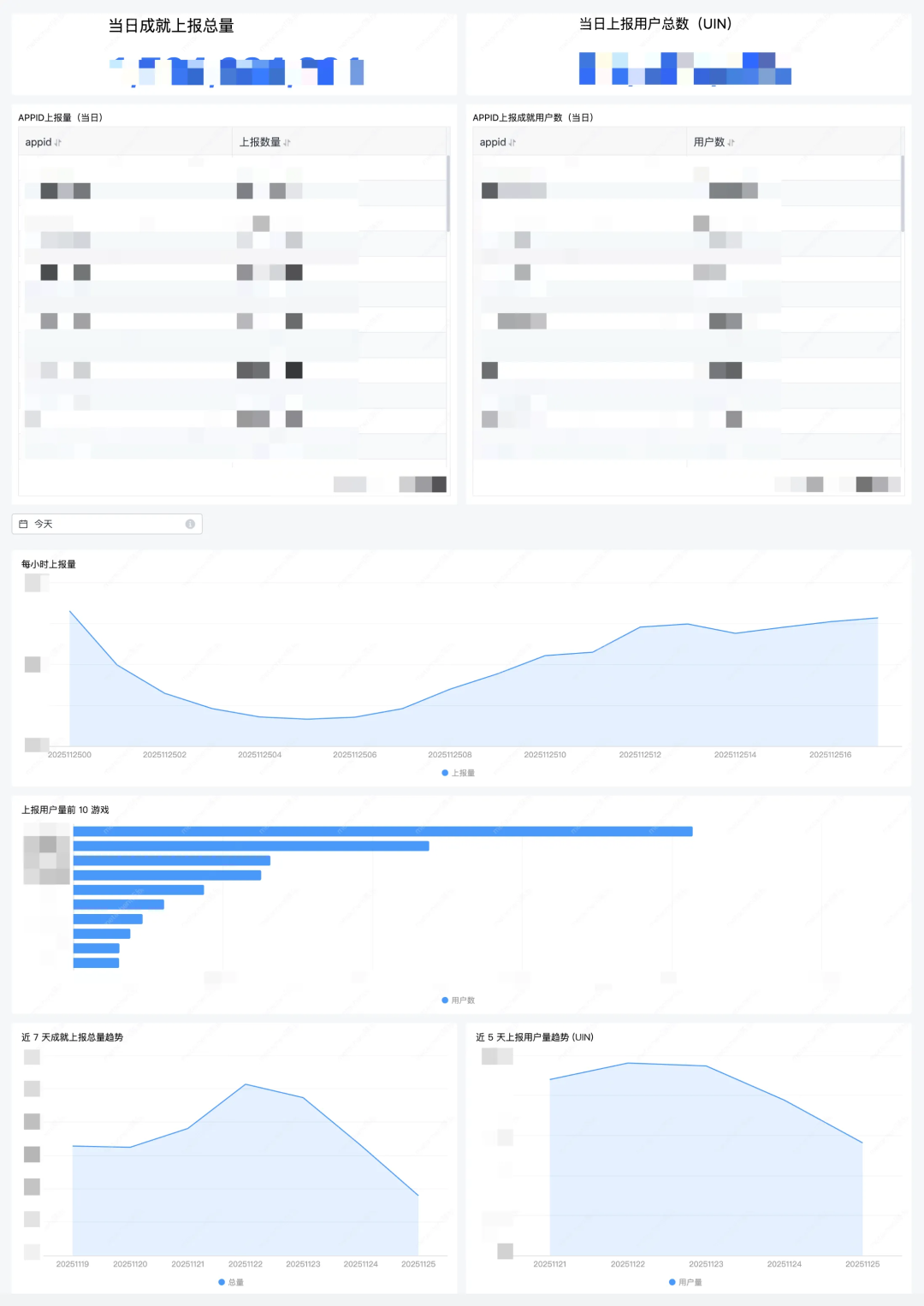
除了底层的系统指标,我还主导建设并完善了整个成就系统的业务大盘监控。通过对 Kafka 队列中流转的成就数据进行实时聚合和可视化,我们得以:
- 核心业务指标一目了然: 大盘能清晰展示“当日成就上报总量 ”、“当日上报用户总数”。这使得运营和产品团队能够实时掌握游戏活跃度与玩家行为情况,为决策提供数据支撑。
- 实时趋势洞察: 通过“上报对量趋势”图,我们可以直观地看到流量波动,及时发现异常峰谷,预判业务走势。这在大型活动上线时尤为关键,能够提前做好扩容或限流预案。
- 精细化运营支持: 大盘还提供了按 APPID 分类的数据,例如“APPID 上报量 Top 10”和“APPID 上报用户数 Top 10”。这使得我们能迅速识别出哪些游戏是核心流量来源、哪些游戏的玩家最为活跃,从而为运营策略调整和资源倾斜提供精确的数据依据。
05、写在最后
从 C++ 到 Go,从同步直写到异步队列,这次重构本质上是一次“用架构空间换取计算时间”的胜利。
我们不再让 CPU 在无休止的锁竞争和 IO 等待中空转,而是让每一行代码都运行在有效的业务逻辑上。这些服务器的轻装上阵,不仅承载了现有的业务压力,更为未来更高并发的游戏活动留足了想象空间。 对于后端工程师而言,最爽的时刻莫过于:看着监控大盘的流量波澜不惊,而服务器列表却缩减了一整页。
-End-
原创作者|陈颀玮
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号