告别CLIP局限!SSVP框架实现零样本异常检测,刷新7大数据集SOTA
原创
告别CLIP局限!SSVP框架实现零样本异常检测,刷新7大数据集SOTA
原创
CoovallyAIHub
发布于 2026-02-02 10:45:12
发布于 2026-02-02 10:45:12
工业视觉检测一直是智能制造领域的关键技术,而零样本异常检测(ZSAD)更是被视为行业的“圣杯”——无需针对特定产线进行训练,即可直接投入使用的理想解决方案。然而,现有基于视觉语言模型(如CLIP)的方法往往面临一个根本性难题:CLIP擅长理解全局语义,却对划痕、裂纹等细微局部缺陷“视而不见”。
近日,北京邮电大学与中国电信人工智能研究院(TeleAI)联合提出了一项突破性工作——SSVP(Synergistic Semantic-Visual Prompting)框架。该框架不仅引入DINOv3补充细粒度视觉特征,更通过一种创新的“语义-视觉协同”机制,使提示词(Prompt)不再是静态文本,而是能根据图像内容动态生成的“灵动指令”。
该方法在权威工业数据集MVTec-AD上实现了93.0%的Image-AUROC,在七个主流工业检测数据集中全面刷新了SOTA性能,为零样本工业质检提供了全新思路。
论文链接:https://arxiv.org/abs/2601.09147

图片1.png
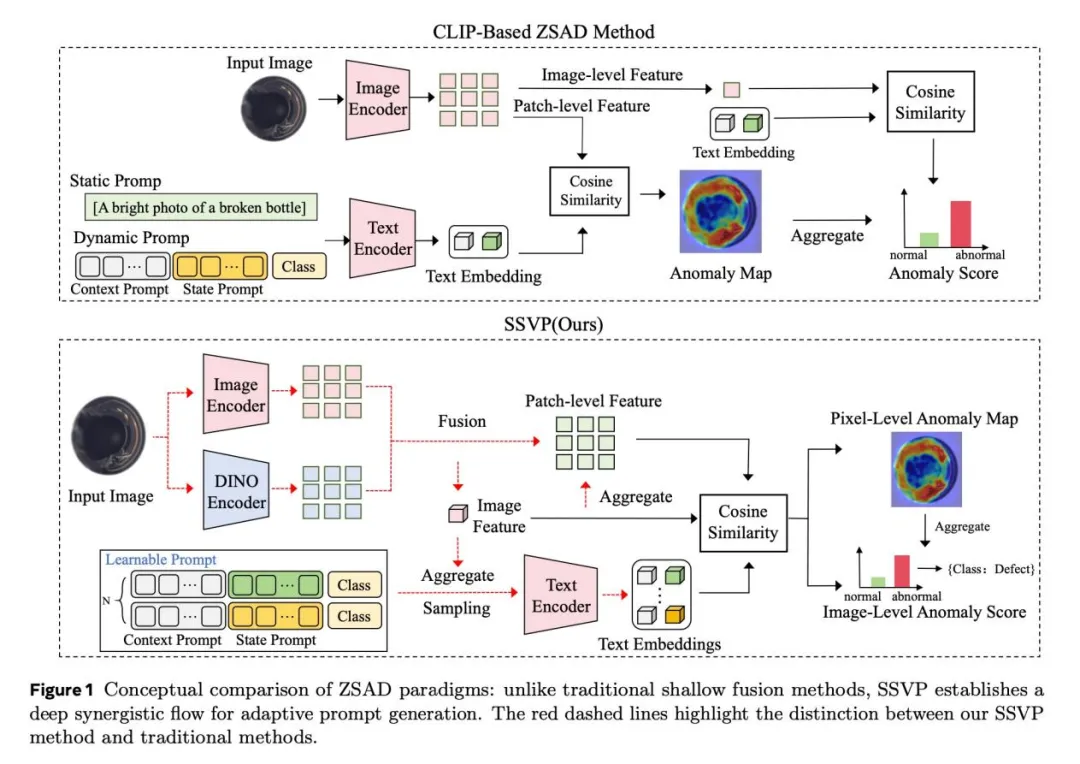
传统方法的局限:语义与细节的割裂
现有零样本异常检测方法大多采用CLIP与视觉特征的简单加权融合,这种“浅层拼接”存在明显短板:
- 语义过于抽象:CLIP特征偏向高层语义理解,难以捕捉工业场景中关键的纹理与结构细节。
- 提示词僵化:传统提示生成缺乏视觉条件约束,导致文本指令无法精准对应图像中的异常模式。
- 定位能力弱:全局评分易受背景干扰,微小缺陷容易被掩盖。
SSVP的核心创新在于提出了一种视觉条件化提示生成机制,真正实现“看图说话”,使模型能够同时理解“是什么”和“哪里不对”。
图片2.png
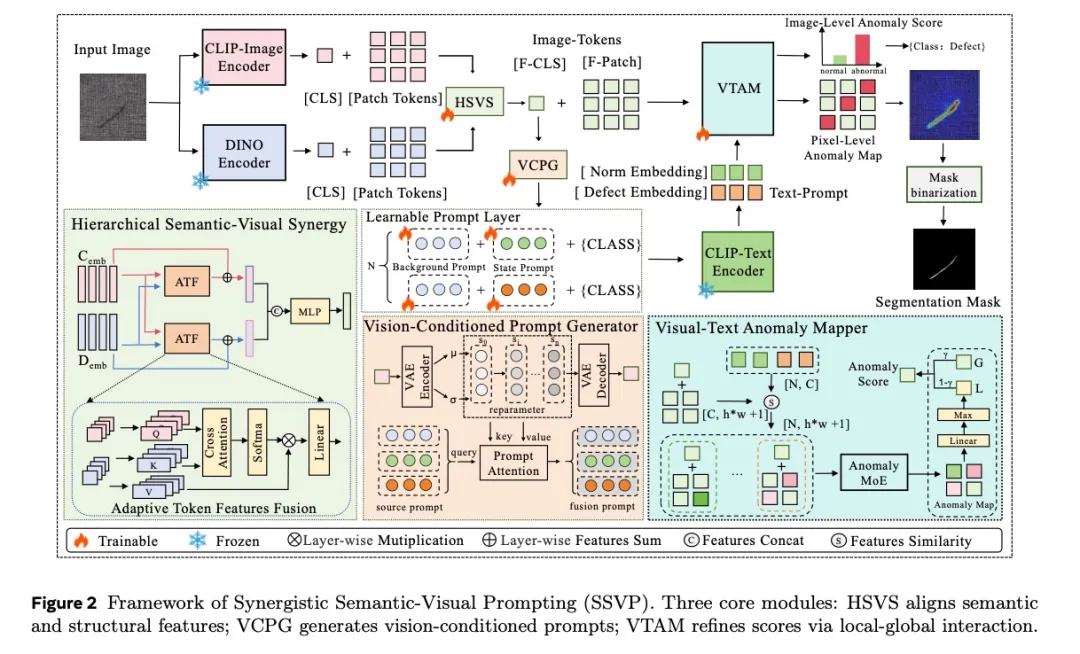
SSVP框架解析:三重协同,精准检测
SSVP架构设计精巧,包含三大核心模块,形成从特征融合到异常定位的完整闭环。
图片3.png
- 层级语义-视觉协同模块(HSVS)
该模块引入DINOv3作为“视觉专家”,与CLIP的语义特征进行深度融合。通过自适应Token特征融合(ATF) 与双向交叉注意力机制,显式地将结构先验注入语义表示中,生成兼具全局理解与细节感知的协同特征。
- 视觉条件提示生成器(VCPG)
传统提示词是静态的,而VCPG使其动态化。该模块通过变分自编码器(VAE)对视觉特征分布进行建模,生成视觉隐变量偏置,并通过交叉注意力机制动态调整文本嵌入表示。简单来说,如果图像中出现疑似裂纹,提示词会在特征空间中自动向“裂纹”语义偏移,实现精准对齐。
- 视觉-文本异常映射器(VTAM)
为实现像素级精确定位,VTAM引入异常专家混合(AnomalyMoE) 机制,通过双门控结构(全局尺度门控与局部空间门控)过滤背景噪声,突出异常区域,最终输出清晰、高对比度的异常热力图。
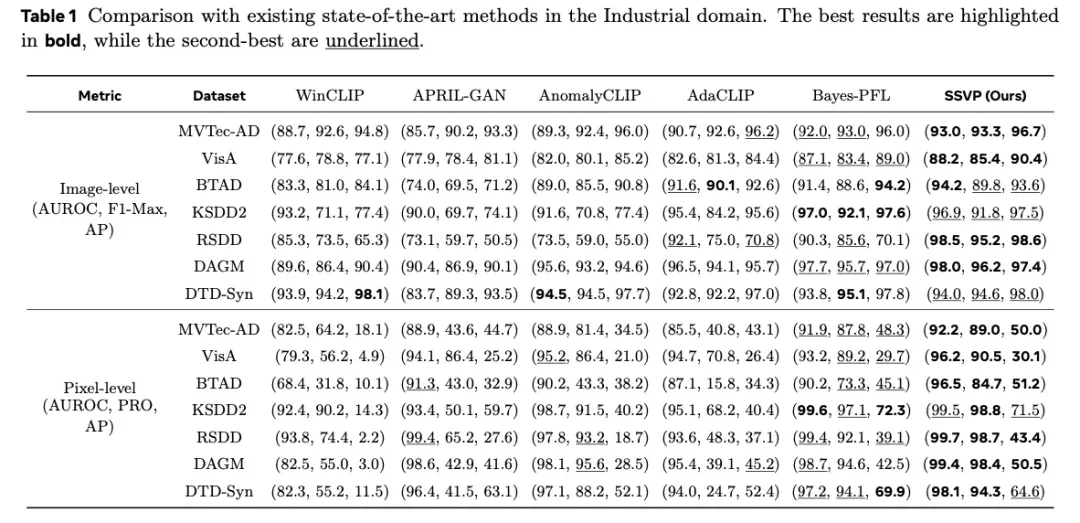
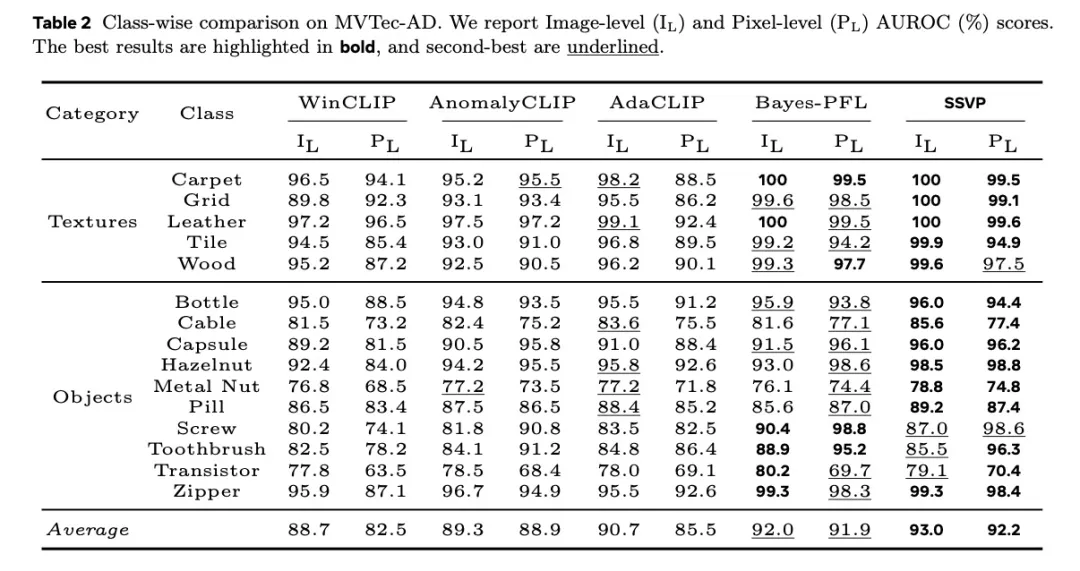
实验结果:全面领先,细节制胜
SSVP在MVTec-AD、VisA、BTAD等七个工业检测数据集上进行了系统评估,结果表现突出:
图片4.png
MVTec-AD:Image-AUROC达到93.0%,超越此前SOTA方法Bayes-PFL(92.0%)。
图片5.png
VisA:在结构复杂的物体检测中达到88.2%,显著领先同类方法。
RSDD铁路缺陷数据集:达到98.5%的惊人性能,证明其在纹理缺陷检测上的强大优势。

图片6.png
可视化对比显示,SSVP生成的异常热力图边界清晰、噪声极少,即使在微小缺陷定位上也表现精准,显著优于基线方法。
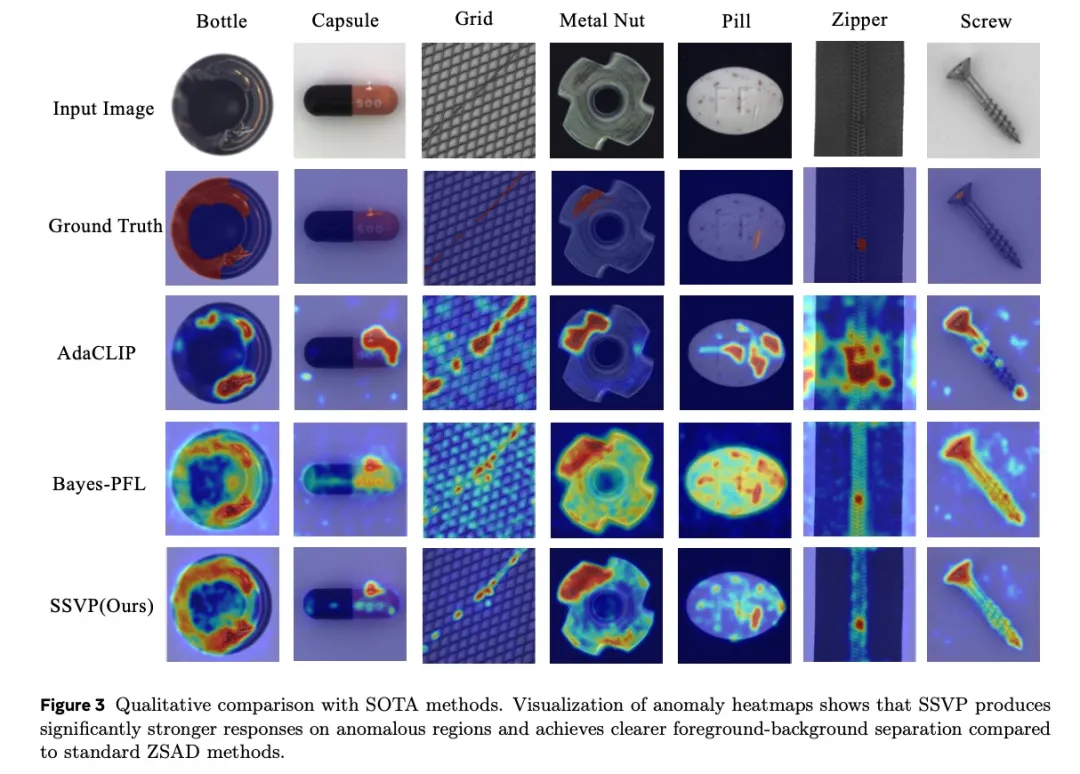
图片7.png
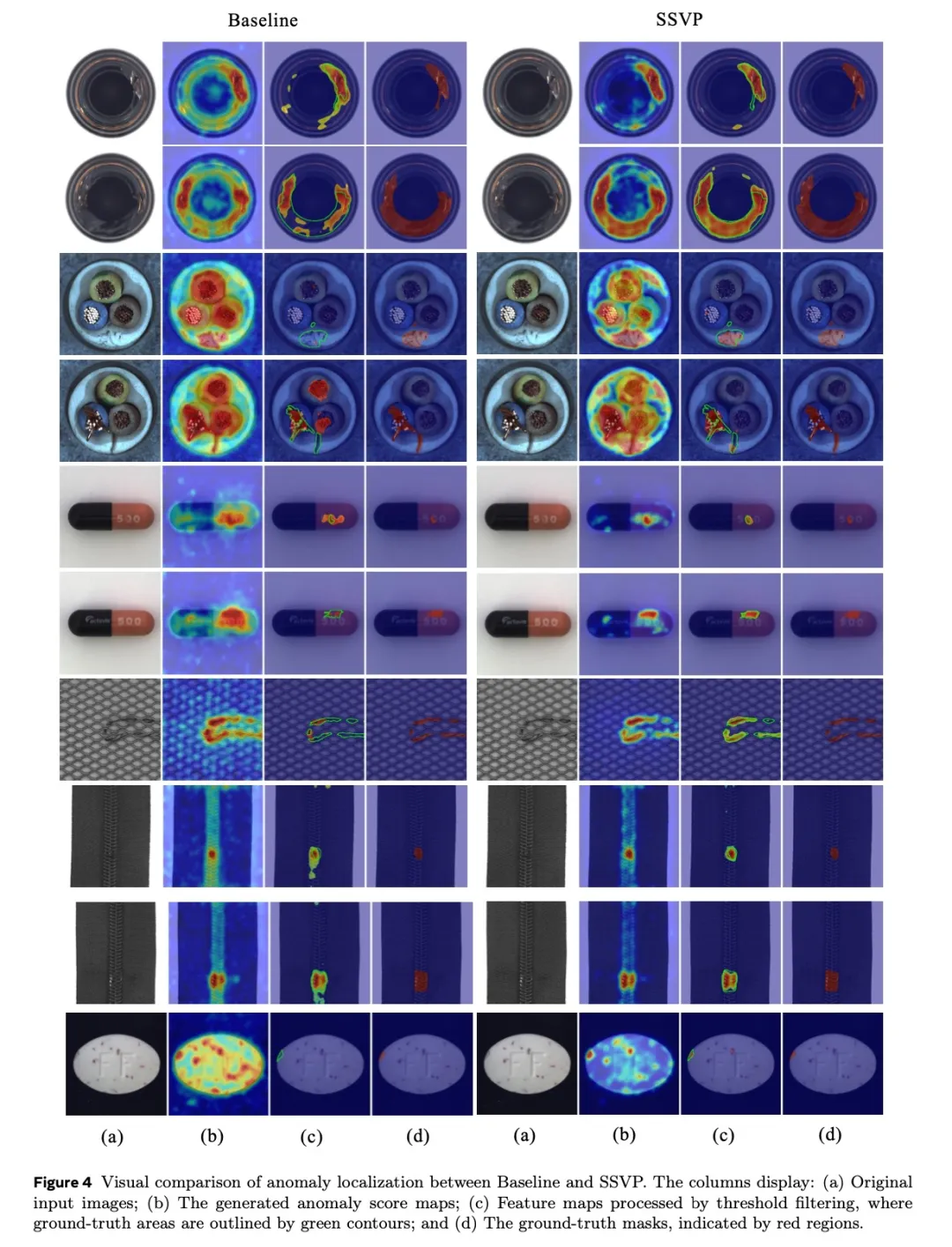
图片8.png
总结与展望
SSVP的成功标志着工业视觉异常检测从“静态匹配”迈向“动态协同”的重要一步。其核心启示在于:
- 多模态融合不是简单拼接,而应通过深层交互实现语义与结构的互补;
- 提示词应具备视觉感知能力,动态生成更贴合图像内容的描述;
- 定位机制需兼顾全局与局部,通过门控设计抑制噪声、增强信号。
该框架为高精度、零样本工业质检提供了可落地的技术路径,尤其适用于产品型号多样、缺陷类型未知的柔性生产线场景。
对于从事工业AI、视觉质检及相关应用的开发者而言,SSVP所提出的特征协同范式与视觉条件化提示生成思路,具有重要的参考价值和实践意义。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号