OpenAI 用一个 PostgreSQL集群 撑住了 8亿用户?

OpenAI 用一个 PostgreSQL集群 撑住了 8亿用户?

萝卜要努力
发布于 2026-01-27 16:15:00
发布于 2026-01-27 16:15:00
昨天刷到 OpenAI 的技术博客,标题挺唬人的:《如何扩展 PostgreSQL 以支持 8 亿 ChatGPT 用户[1]》。
说实话,第一眼看到还挺激动。在这个动不动就上分布式数据库的年代,居然还有公司敢说自己用单体 Postgres 扛住了 8 亿用户?这得有多少干货啊。
结果看完才发现,OpenAI 你也学会标题党了,还是个营销号。
他们到底做了什么
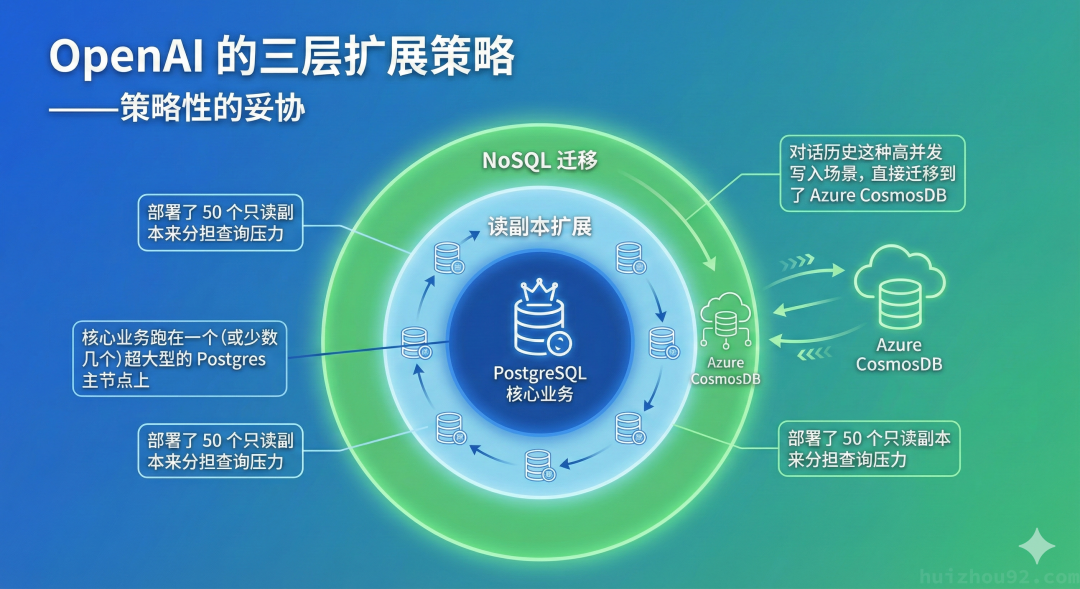
OpenAI 并没有把一个 PostgreSQL "优化" 到能处理 8 亿用户的所有请求。实际上,他们做的是一系列非常务实的取舍。
读压力大?那就加副本呗,部署了 50 个只读副本来分担查询。这操作有啥稀奇的。
写入扛不住?那就换数据库。像对话历史这种高并发写入的场景,直接甩给 Azure CosmosDB 了。
核心业务呢?还是老老实实跑在几个超大型的 Postgres 主节点上。
Gemini_Generated_Image_vud86svud86svud8
所以准确来说,OpenAI 用的是一整套混合架构,PostgreSQL 只是负责核心业务那块,NoSQL 接手了高频写入。标题多少有点过度包装了。
有钱真的能为所欲为
看完最大的感触就是:钱真 TM 重要。
OpenAI 能这么玩,是因为人家用得起 Azure 最顶配的机器。有人扒出来应该是 M 系列虚拟机,配置离谱到什么程度呢:
- 896 个 vCPU
- 32 TB 内存
- 一个月租金 17.5 万美元
这配置意味着什么?意味着你可以把大部分热数据全塞内存里,意味着复杂查询随便跑,意味着垂直扩展基本能解决所有问题。

Pasted image 20260123224924
对大多数公司来说,这方案根本没法复制。但它至少说明了一件事:在你真正达到 OpenAI 这种体量之前,PostgreSQL 的性能天花板远比你想的高。很多时候不是数据库不行,是你舍不得砸钱买硬件。
最讽刺的地方在这儿
文章里有个细节我印象特别深。OpenAI 解释为什么不做分片时说,改几百个代码端点可能要花几个月甚至几年。
这理由本身没毛病,做过大型系统重构的都懂,这真不夸张。
但问题是,这话是从 OpenAI 嘴里说出来的。一家卖 AI 编程工具的公司,一家天天宣传 "AI 将改变软件开发" 的公司,面对自己的遗留代码,给的答案是:"人工重构太难了"。

Pasted image 20260123223910
我倒不是想黑 OpenAI,恰恰相反,我觉得这话挺诚实的。它说明了一个现实:AI 工具确实能提效,但距离替代人类做大规模系统重构还差得远。自动补全代码是一回事,理解一个跑了好几年、有几百个端点的复杂系统,然后安全地重构它,完全是另一回事。
文章里倒是有些干货
抛开标题和营销不谈,OpenAI 分享的一些技术细节还是值得看看的。
比如 Schema 变更时的锁管理。在高吞吐场景下改表结构,锁竞争是大问题。OpenAI 的做法是设严格的 lock_timeout,避免长时间阻塞。但更狠的方案是:执行 DDL 的同时,主动干掉冲突的事务。
听起来很暴力对吧?但逻辑很清楚:让 DDL 锁在那儿排队会阻塞所有后续请求,造成的破坏远大于主动杀几个正在跑的事务。两害相权取其轻。
再说读写分离。50 个只读副本听着挺多,但换个角度想:如果你的业务读多写少(大多数应用都这样),通过加副本来扩展读能力,成本最低、风险最小。
相比分库分表要改代码、切 NoSQL 要重新设计数据模型、上分布式数据库运维成本暴增,简单的读写分离反而是最务实的选择。
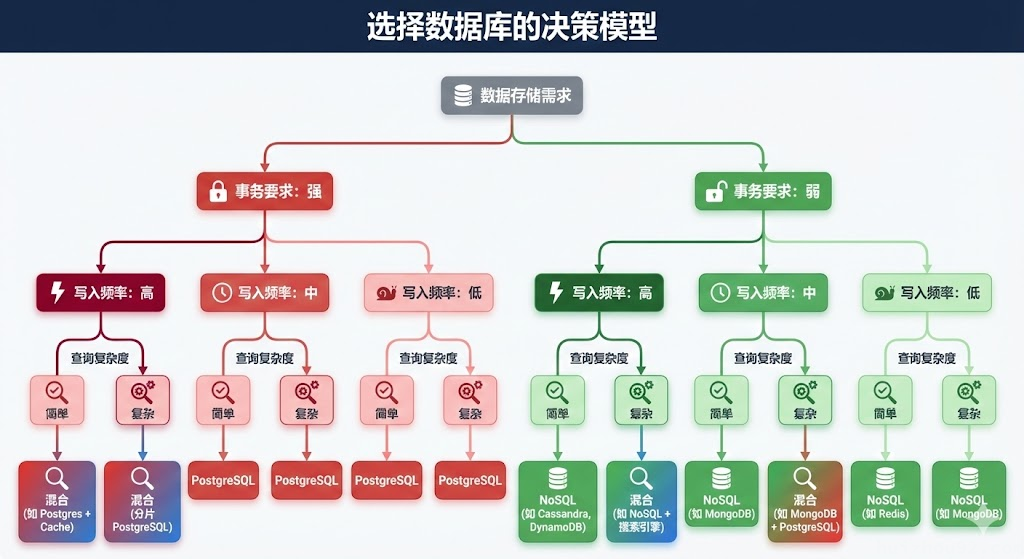
还有就是什么时候该迁移到 NoSQL。
OpenAI 把对话历史扔给 CosmosDB,这决策挺有参考价值。
判断标准其实很简单:写入频率极高、数据结构相对简单、不需要复杂关联查询、能接受最终一致性。符合这些条件,用 NoSQL 确实更合适。
Pasted image 20260123224300
但你得接受混合架构带来的复杂性:数据分散在多个系统、要维护多套技术栈、跨系统的数据一致性问题。这些都是真实成本。
说到底
OpenAI 这案例其实就一个道理:别瞎折腾。
2026 年了,单体 PostgreSQL 加上顶配硬件,足够撑到你成为独角兽。在真正遇到瓶颈前,别急着搞微服务、分库分表那套。连 OpenAI 都在用最 "笨" 的方法解决问题:能砸钱买硬件就砸钱,能绕过去的技术债就先拖着。
务实点,没毛病。
引用链接
[1]如何扩展 PostgreSQL 以支持 8 亿 ChatGPT 用户: https://openai.com/index/scaling-postgresql/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号