YOLO26技术详解:原生NMS-Free架构设计与实现原理
原创
YOLO26技术详解:原生NMS-Free架构设计与实现原理
原创
CoovallyAIHub
发布于 2026-01-27 10:54:49
发布于 2026-01-27 10:54:49
最近,计算机视觉领域再掀波澜!YOLO 家族最新成员——YOLO26横空出世,以“彻底移除NMS”为核心变革,开启了真正的端到端目标检测新时代。虽然官方论文尚未正式发布,但来自KIIT大学的深度分析报告已在arXiv上公开,详细剖析了这一颠覆性架构的设计哲学与技术实现。
今天,我们将深入解析这篇技术报告,看看YOLO26如何通过架构革新,解决长期困扰业界的部署难题,为边缘AI应用带来全新可能。

图片1.png
技术文档:https://docs.ultralytics.com/models/yolo26/ 论文地址:https://arxiv.org/abs/2601.12882
NMS之殇:目标检测的“阿喀琉斯之踵”
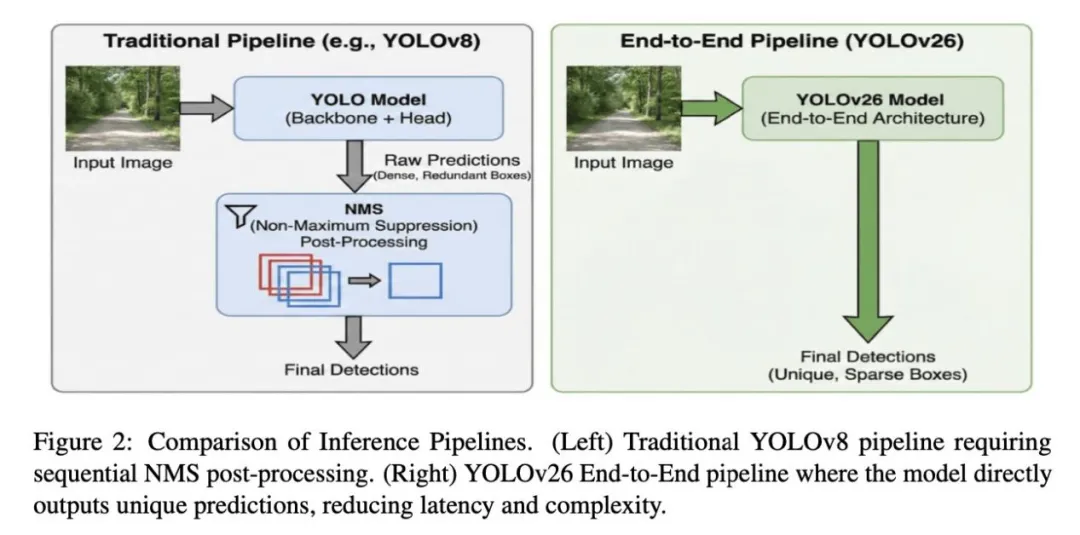
从YOLOv1到YOLOv11,非极大值抑制(NMS)一直是目标检测流程中不可或缺的后处理步骤。它的任务很明确:在模型输出的大量候选框中,筛选出最可能代表真实目标的那些,同时剔除冗余的重叠框。
图片2.png
然而,这一看似必要的步骤却暗藏两大痛点:
- 延迟瓶颈:NMS本质上是串行计算过程,当场景中目标密集时,候选框数量呈指数级增长,NMS的处理时间会显著增加,导致推理延迟极不稳定。
图片3.png
- 超参敏感:NMS的核心参数——IoU阈值需要人工设置,调优不当就会导致误删或漏检,尤其对相互重叠的物体极不友好。
即使是曾短暂尝试NMS-Free的YOLOv10,最终也未能在后续版本中坚持这一路线。如今,YOLO26决定彻底解决这个问题。
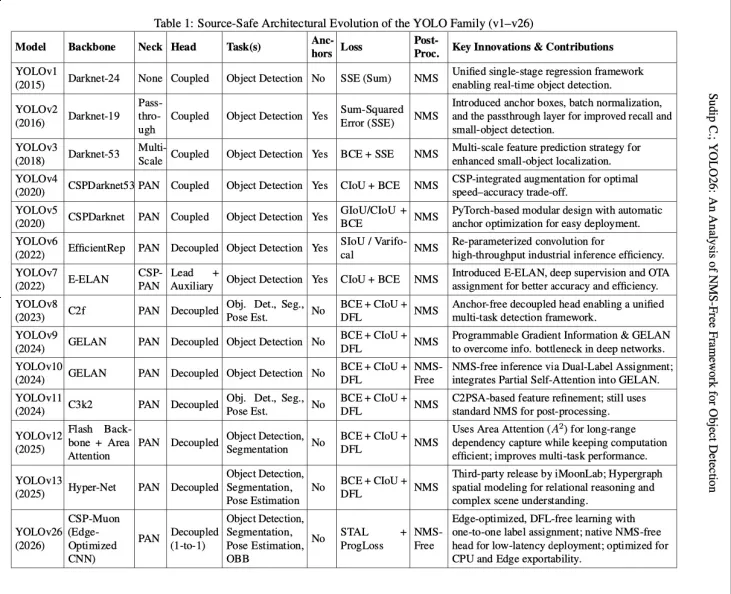
架构革命:从“候选+筛选”到“直接输出”
YOLO26的核心创新可以概括为“一个架构革命”和“三大训练神器”。
架构革新:真正的端到端设计
- 原生NMS-Free架构
YOLO26摒弃了传统的“先产生大量候选框,再通过NMS筛选”的两阶段思路,转而采用一对一(one-to-one)标签分配策略。
在训练阶段,模型就被教导每个真实物体只对应一个最精准的预测框。这意味着推理时,模型输出即是最终结果——无需任何后处理,干净利落。
这一变革带来的直接收益是推理速度的大幅提升。据报告,仅移除NMS一项,就带来了约43%的速度提升,更重要的是,延迟变得稳定可预测,不再受场景复杂度影响。
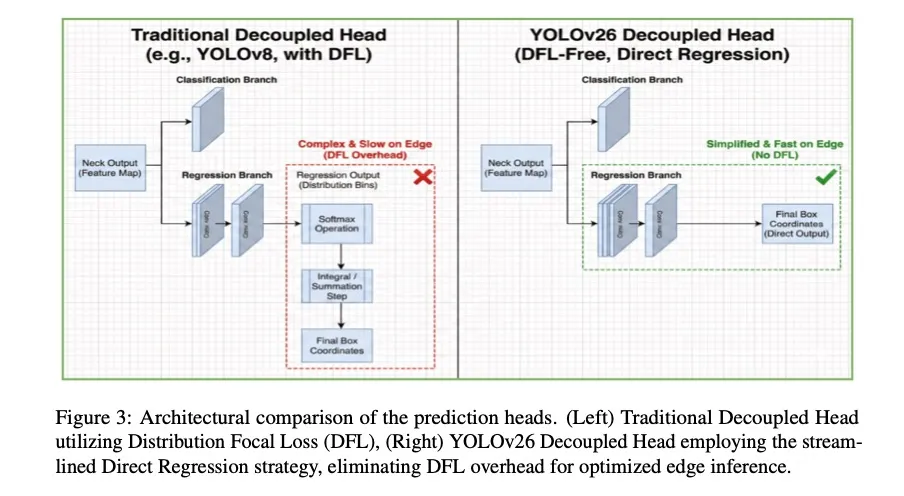
- DFL-Free头部:为边缘而生
近年来,为了提高定位精度,YOLO系列(如v8)普遍采用了分布焦点损失(DFL),将边界框坐标视为概率分布进行优化。
然而,DFL依赖的Softmax运算在边缘设备(如NPU/DSP)上效率低下,且难以量化,造成了严重的“导出鸿沟”——GPU上运行流畅的模型,一到边缘端就性能骤降。
图片4.png
YOLO26果断回归直接坐标回归,这一看似“倒退”的设计实则是面向实际部署的务实选择。简化后的头部不仅计算效率更高,而且更易于在各类硬件上部署和优化。
训练神器:稳定收敛的三大法宝
移除NMS和简化头部后,如何保证模型精度和训练稳定性?YOLO26引入了三套精妙的训练机制。
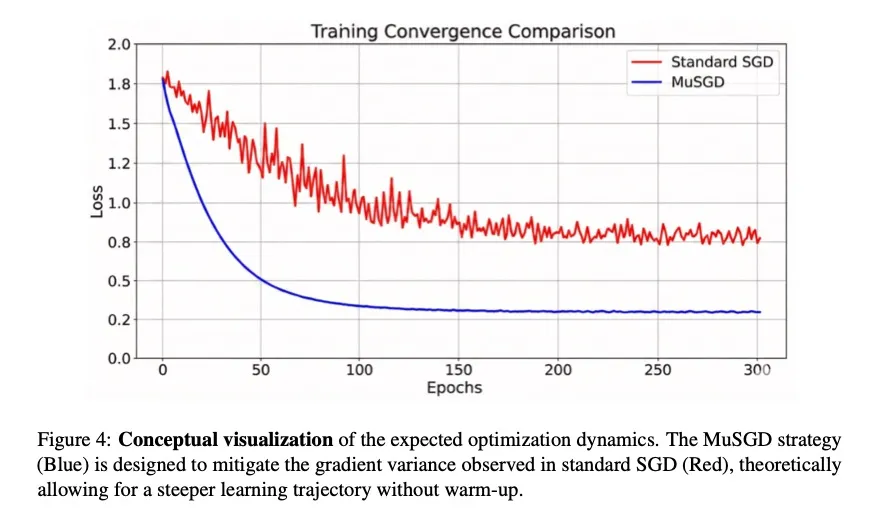
- MuSGD优化器:稳定收敛的新保障
YOLO26采用了名为MuSGD(Momentum-Unified SGD)的新型优化器,巧妙融合了传统SGD的动量机制与大模型训练中的先进技术。
MuSGD执行一种“矩阵正交化”更新,能最大化参数更新的效率。相比传统SGD,它能让模型在训练初期就找到更陡峭、更有效的学习路径,减少梯度方差,在不依赖复杂预热策略的情况下实现更快、更稳定的收敛。
图片5.png
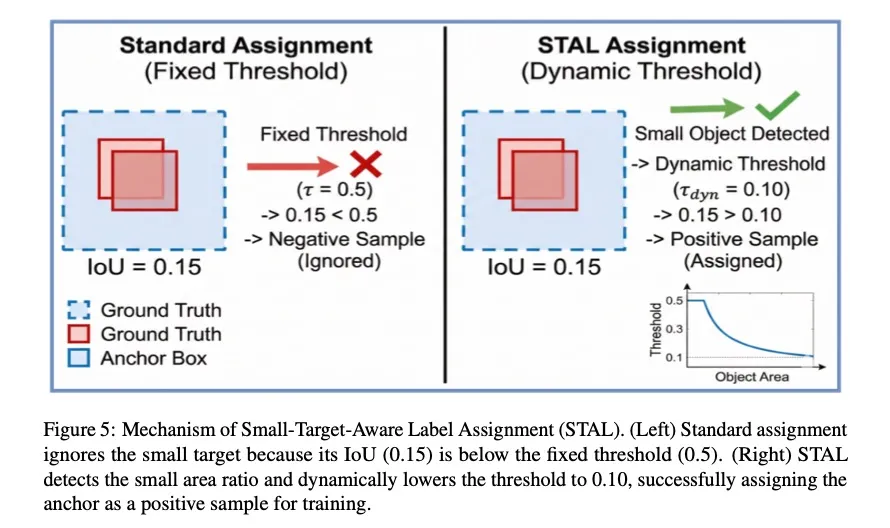
- STAL:小目标不再被忽视
在一对一分配策略中,小目标因与Anchor的IoU通常较低,很容易在训练中被忽略,导致模型对小物体检测能力不足。
STAL(Small-Target-Aware Label Assignment)机制通过动态调整IoU阈值解决了这一问题。当检测到小目标时,STAL会自动“放宽”匹配标准,降低所需的IoU阈值,确保这些小物体也能获得充分的训练监督。
图片6.png
这一机制显著提升了模型在无人机航拍、医疗影像等小目标密集场景下的召回率。
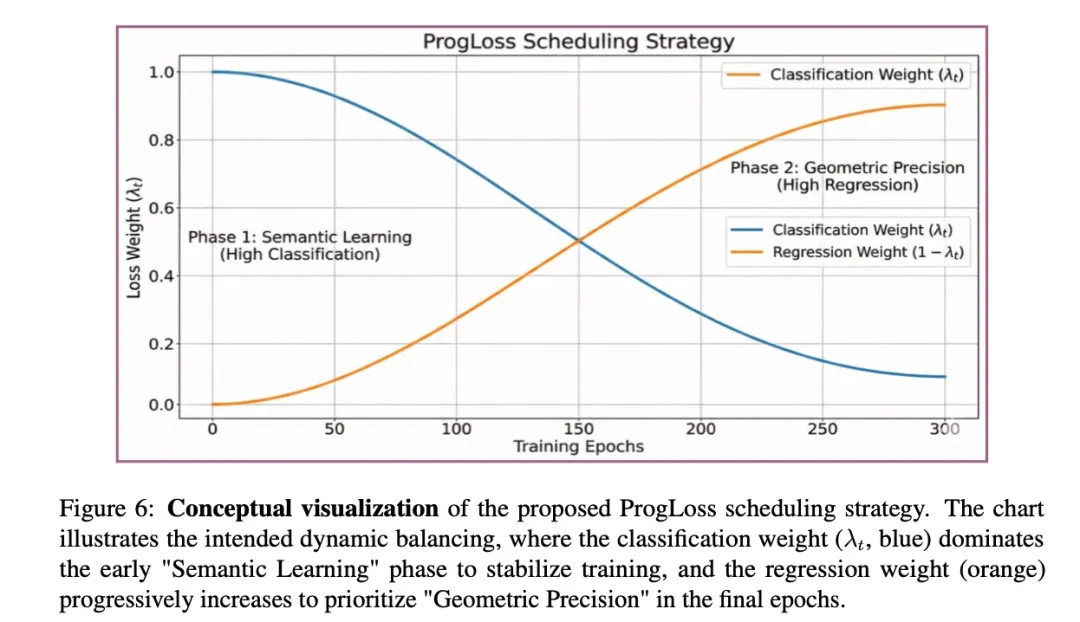
- ProgLoss:渐进式学习的艺术
同时优化分类和定位任务对端到端模型来说极具挑战。ProgLoss(Progressive Loss Balancing)引入了一种动态平衡策略。
训练初期,分类损失权重更大,让模型先学会“识别物体”;随着训练进行,逐步增加回归损失权重,让模型再学会“精确定位”。这种“先识别后定位”的渐进式学习,平滑了训练过程,使模型在没有DFL的情况下也能实现精准定位。
图片7.png
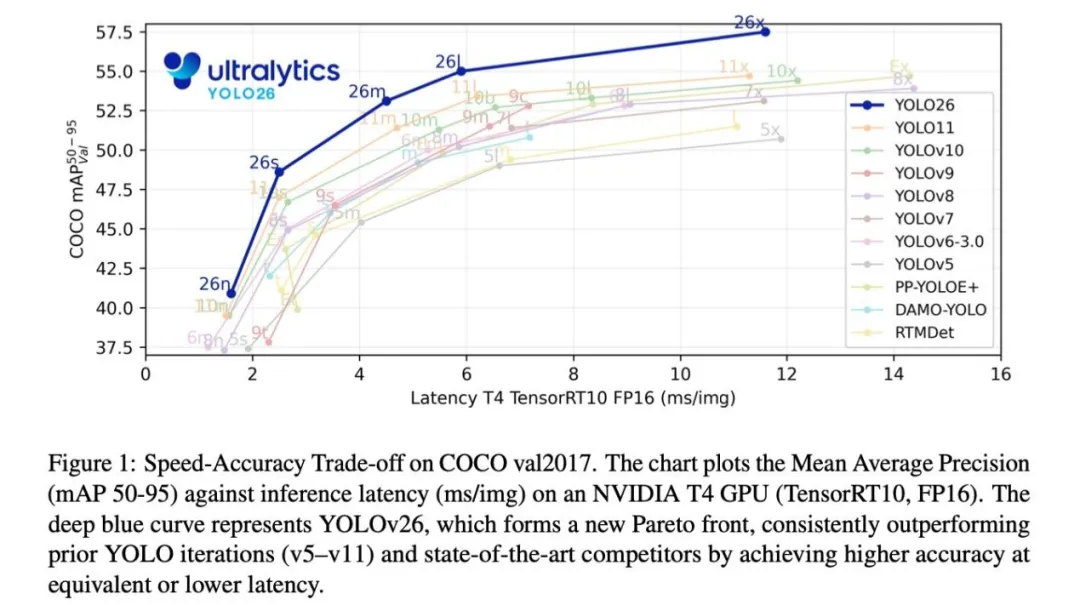
性能实测:重新定义效率边界
根据Ultralytics公布的基准测试,YOLO26家族在速度与精度的平衡上达到了新高度。
在COCO数据集和NVIDIA T4 GPU环境下:
- YOLO26-n:仅1.5ms推理延迟,实现超过40 mAP的性能
- YOLO26-x:达到57.5 mAP的顶尖精度,延迟控制在11.5ms以内
从帕累托曲线可以看出,YOLO26形成了全新的“效率边界”,在任何给定的延迟水平下都提供了更高的精度,全面超越了包括RTMDet在内的竞争对手。
图片8.png
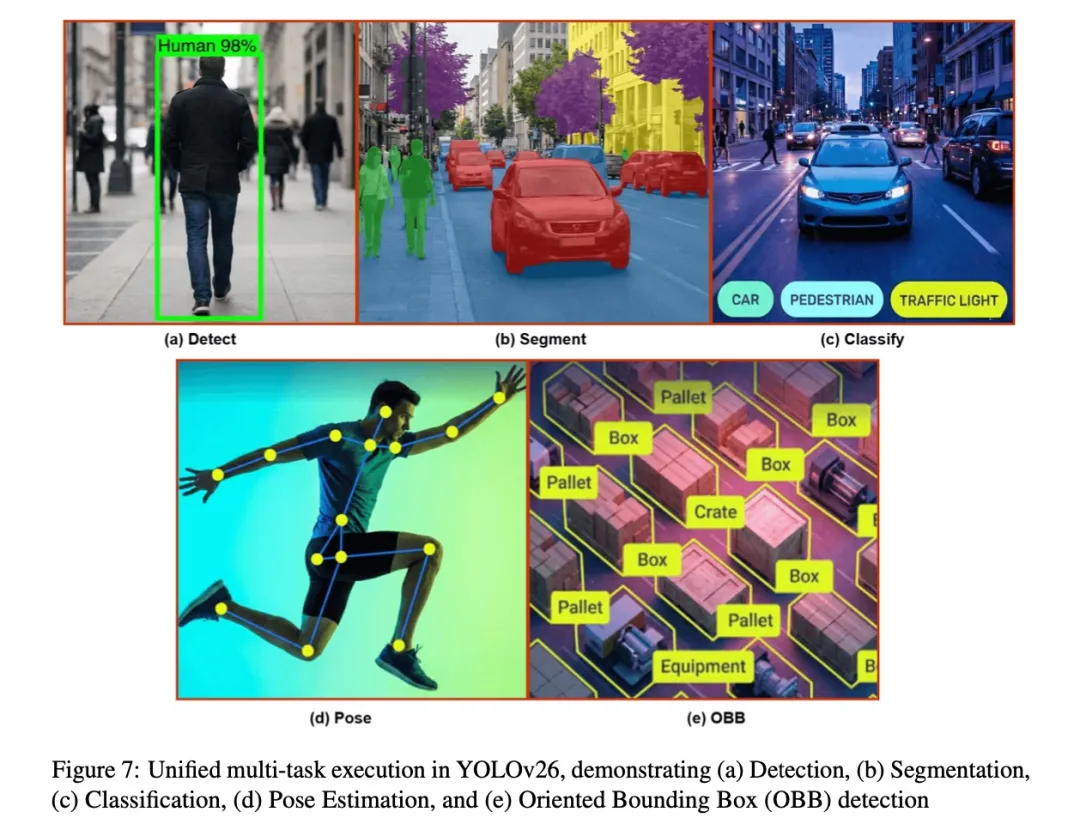
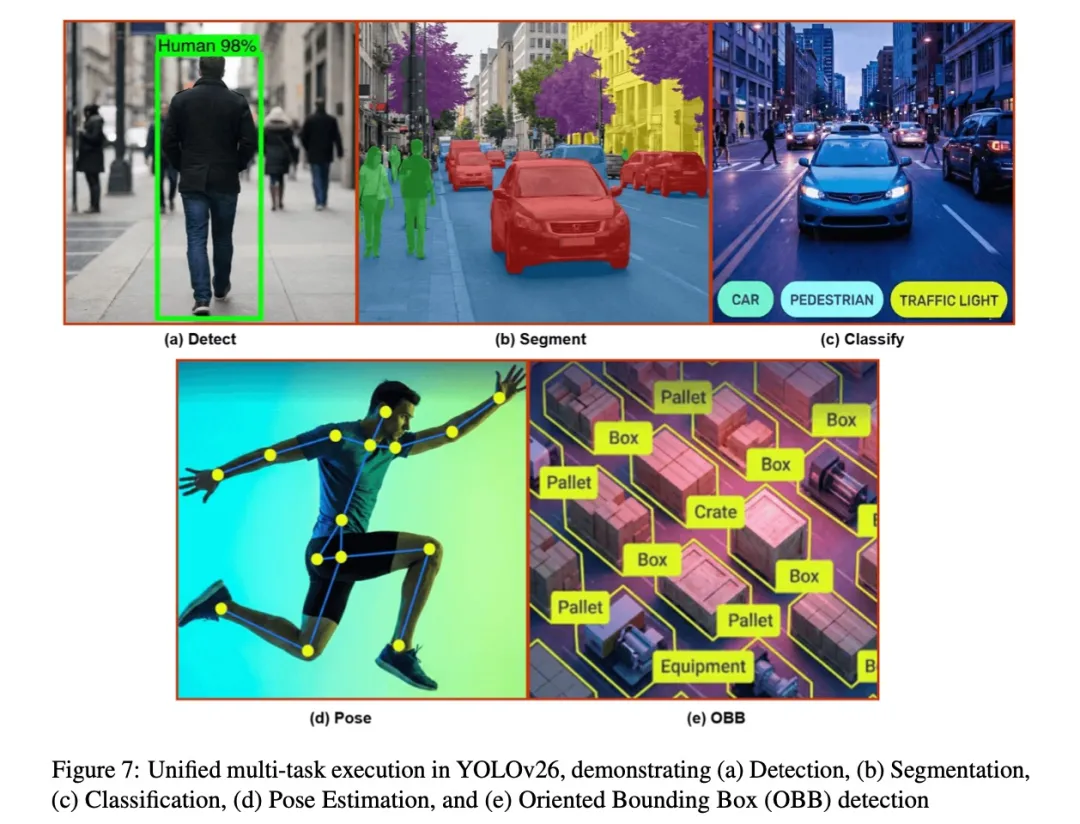
多任务扩展:不止于检测
YOLO26的优秀架构设计使其自然支持多种视觉任务。除目标检测外,它还能原生支持:
- 实例分割
- 人体姿态估计
- 旋转框检测
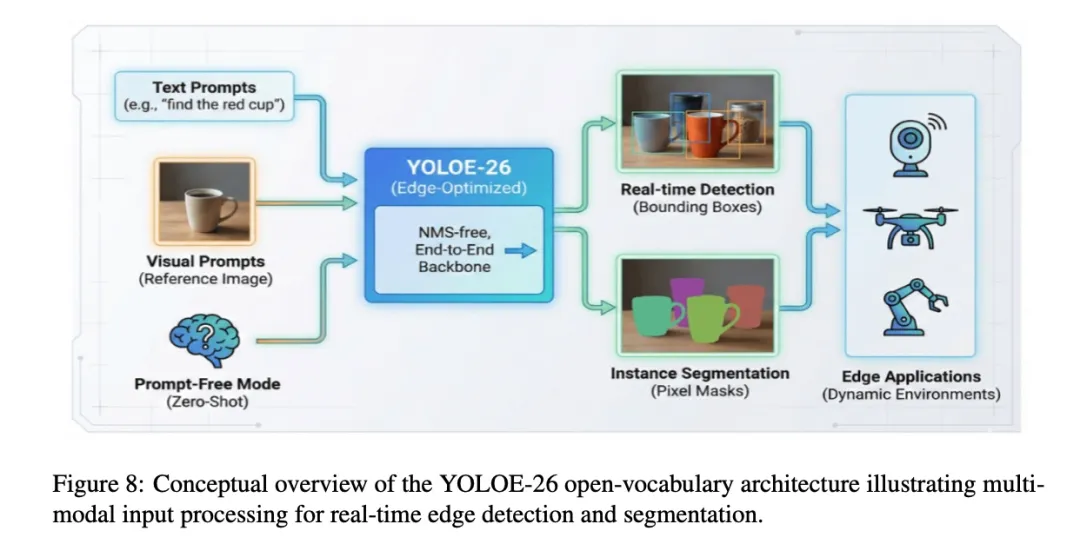
- 开放词汇检测(YOLOE-26)
图片9.png
这展现了YOLO26作为下一代视觉基础模型的强大潜力。
思考:从指标竞赛到实用价值
YOLO26的出现标志着目标检测领域的重要转向:从单纯追求精度指标,转向对实际部署价值的深度思考。
它没有通过堆砌复杂模块来刷高mAP,而是勇敢地做减法,直面并解决了长期困扰业界的“导出鸿沟”问题。这种务实的设计哲学,可能比单纯的性能数字更有意义——毕竟,追求精度的前提应该是实际可用性。
图片10.png
对于需要在边缘设备部署AI应用的企业和开发者来说,YOLO26提供了一个极具吸引力的选择:它不仅更快、更准,更重要的是,它的部署简单性前所未有。
图片11.png
随着YOLO26的正式发布和生态完善,我们很可能见证边缘AI应用的新一波爆发。从智能安防到工业质检,从自动驾驶到移动设备,更高效、更易部署的视觉模型将开启AI落地的新篇章。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号