高能效·高可靠·低成本:VCSEL基CPO方案的技术优势与最优路径探索

高能效·高可靠·低成本:VCSEL基CPO方案的技术优势与最优路径探索

光芯
发布于 2026-01-26 17:02:39
发布于 2026-01-26 17:02:39
随着人工智能(AI)模型训练对算力需求的爆炸式增长,AI数据中心内部的GPU全连接通信成为带宽瓶颈的核心所在。数据显示,scale-up网络在AI模型训练阶段占据了超过80%的数据中心带宽,而0.3至30米的短距离链路需求正随着每机架GPU数量的增加持续飙升。铜缆互连在高带宽需求下逐渐暴露其固有限制,功耗、传输距离与带宽密度的矛盾日益突出,推动行业向共封装光学(CPO)技术加速转型。
其中,垂直腔面发射激光器(VCSEL)凭借其成熟性、高能效与高可靠性,成为CPO架构下AI数据中心规模化扩展的理想选择之一。来自Coherent的M. Kohli 和 J. Teissier 近期在arxiv上传了题目为VCSEL-based CPO for Scale-Up in A.I. Datacenter. Status and Perspectives的论文,基于技术原理、竞争格局与关键指标,全面解析了VCSEL基CPO的技术细节与应用价值。https://arxiv.org/abs/2601.14342
一、铜缆数据链路的局限:AI规模化扩展的技术瓶颈
现代计算机系统长期依赖铜缆作为CMOS工艺与PCB上的信号传输介质,但在AI数据中心的高带宽场景下,其局限性已无法忽视。
铜缆链路的工作机制决定了其能效损耗:数据从处理器边缘以约4 Gbit/s的低速PAM2编码输出,需通过专用芯片如SerDes或UCIe多路复用到高速信号,这一步骤的能效损耗约为0.25 pJ/bit。若要提高每个通道的带宽,可采用更高阶的调制格式(如PAM4),在200 Gbit/s速率下,这种转换会使能量效率额外降低约0.25 pJ/bit。此外,该模块通常还会集成数字信号处理(DSP)功能,以补偿铜缆线路中的非线性失真。预失真处理的能耗取决于铜缆的损耗,传输至PCB边缘需额外消耗约0.5 pJ/bit,而更长距离链路的额外能耗则可能超过4 pJ/bit。 无源可插拔铜缆无需额外电力即可传输高速数据信号,但由于链路有效长度增加,串并转换器的DSP部分会增加4 pJ/bit的能耗。在200 Gbit/s每通道速率下,无源铜缆的最大传输距离限制在约1米,总能量效率为5 pJ/bit。
二、共封装光学(CPO):后铜缆时代的核心解决方案
与铜缆不同,光学互连可通过光谱、偏振与空间多路复用技术,实现比特率、功耗与带宽密度的优化平衡。共封装光学(CPO)将光学引擎与处理器共封装,大幅缩短了PCB上的铜缆走线长度,减少了电子损耗与延迟,同时满足高光学带宽密度与高温环境下的可靠性要求,成为解决AI数据中心带宽瓶颈的关键技术路径。
CPO架构主要分为两种技术路线:“快而窄”(FaN)与“慢而宽”(SaW)。“快而窄”方案追求单通道高速率,通常采用PAM4编码,速率超过100 Gbit/s,但持续提升速率会导致驱动能效下降,且需依赖DSP补偿信号失真;“慢而宽”方案则降低单通道速率(低于64 Gbit/s),采用NRZ编码,通过增加通道数量实现总带宽提升。这种方案凭借更高的信噪比,可去除DSP与纠错电子元件,简化电子链路复杂度,同时降低光电探测器的光功率需求,显著提升整体能效。
每通道的最佳工作速率需要在多个相互竞争的因素之间仔细权衡。首先,低速带来的简化与启动电压等静态开销之间存在权衡;其次,速率会影响电子器件与光学引擎的可靠性平衡——更多的低速通道会提高对单个通道的可靠性要求,而降低每通道功率预算和简化电子器件则有助于降低整体故障率;最后,占位面积和成本构成了另一个必须在整体设计中优化的权衡因素,需在提高带宽密度的同时将成本控制在可接受范围内。
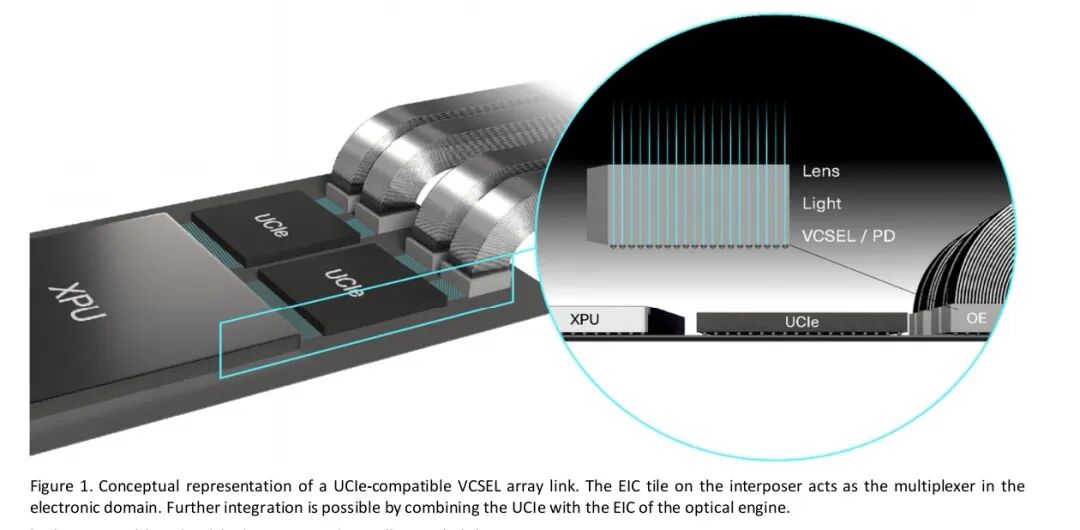
从系统集成来看,UCIe兼容的VCSEL阵列链路是典型的SaW架构实现:处理器(XPU)输出的信号经中介层上的EIC电芯片多路复用后,传输至EIC+VCSEL/PD 套片,再通过多芯光纤实现信号传输。这种架构可进一步将UCIe与光学引擎的EIC集成,实现更高的集成度与带宽密度。
三、CPO竞争技术全景解析
当前,行业内共有五种主流技术路线角逐CPO市场,分别基于“快而窄”与“慢而宽”两种架构,各有其技术特点与应用局限:
1. 快而窄(FaN)PAM4 VCSEL
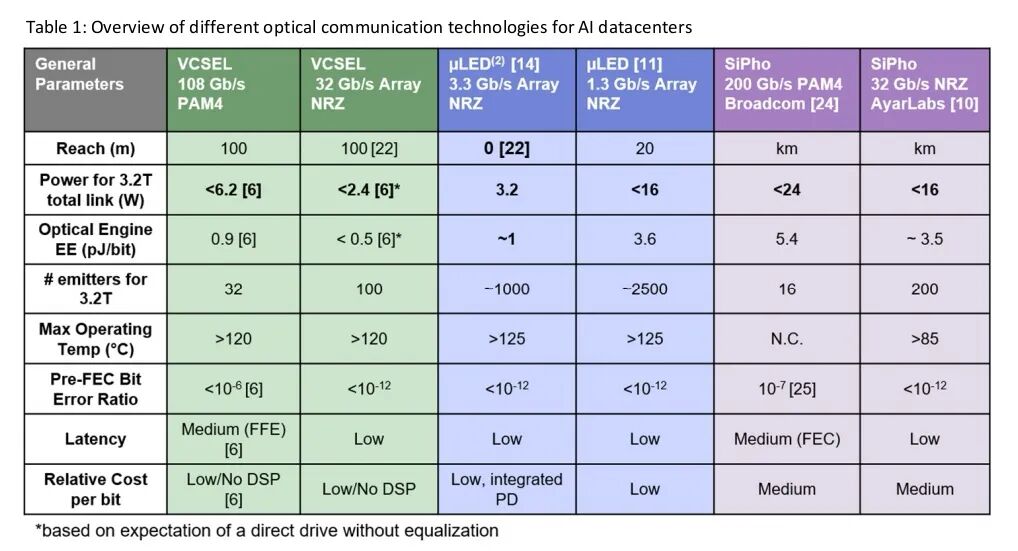
该方案已实现108 Gbps PAM4的CPO原型,3.2 Tbit/s的tile需32个VCSEL器件,200 Gbit/s速率的VCSEL技术已接近成熟。VCSEL作为成熟度极高的技术,已在可插拔模块中应用25年,累计出货量达数亿件,具备天然的可靠性优势。
2. 快而窄(FaN)硅光子微环调制器(SiPho MRM)PAM4
英伟达与博通等企业采用该方案用于scale-out网络,单通道速率达200 Gbit/s,与铜缆共享SerDes芯片,光源依赖外部可插拔激光器,学术研究已实现400 Gbit/s/lane(160 GBd/s PAM6)的符号率。其优势在于可与电子器件3D共集成、O波段色散小、可靠性优于硅光子可插拔模块,但存在外部激光器导致成本上升、微环谐振与激光锁定难度大、偏振不敏感探测需求及工艺公差严格等挑战。
3. 慢而宽(SaW)NRZ SiPho MRM
通过在同一总线波导上添加多个谐振频率偏移的微环实现波分复用,受益于CMOS兼容PD的高效探测,部分初创企业如Ayar labs已推出UCIe兼容tile。但该方案需生成多激光波长,且微环阵列与各波长的锁定复杂度极高,限制了其规模化应用。
4. 慢而宽(SaW)NRZ microLED阵列
基于氮化镓(GaN)材料,工作在可见光波段,可采用标准CMOS实现高效探测,具备小尺寸与CMOS共集成成熟的优势,微软与Avicena等企业是主要推动者。但uLED的宽光谱与宽发射轮廓导致光纤耦合难度大,依赖用于图像映射的成像光纤束进行空间复用,且壁插效率仅1.2%,驱动电压高达4.4 V,在30米传输距离下速率被限制在1.6 Gbit/s。
5. 慢而宽(SaW)VCSEL阵列
与microLED方案类似,采用多芯光纤进行空间复用,但激光特性使其光纤耦合更简便、传输距离更远,且壁插效率更高。VCSEL的带宽优势使其支持4至100 Gbit/s以上的NRZ速率,兼具灵活性与高性能,是当前SaW架构的核心竞争力方案。
四、CPO关键技术指标深度对比
1. 能效(Energy Efficiency, EE)
能效是CPO技术的核心指标之一。在200 Gbit/s速率下,数据从处理器传输至电路板边缘,包括串并转换器(SerDes)和短距离链路DSP,需消耗约3.5 pJ/bit。图2展示了从加速器(XPU)到可插拔器件的过程中,每条铜缆线路和每个接口对电信号损耗的影响,以及为校正由此产生的信号失真所需的能量成本。参考可插拔链路为无源铜缆链路,由于额外的DSP,总能量效率为5 pJ/bit,在200 Gbit/s速率下最大传输距离为1米。
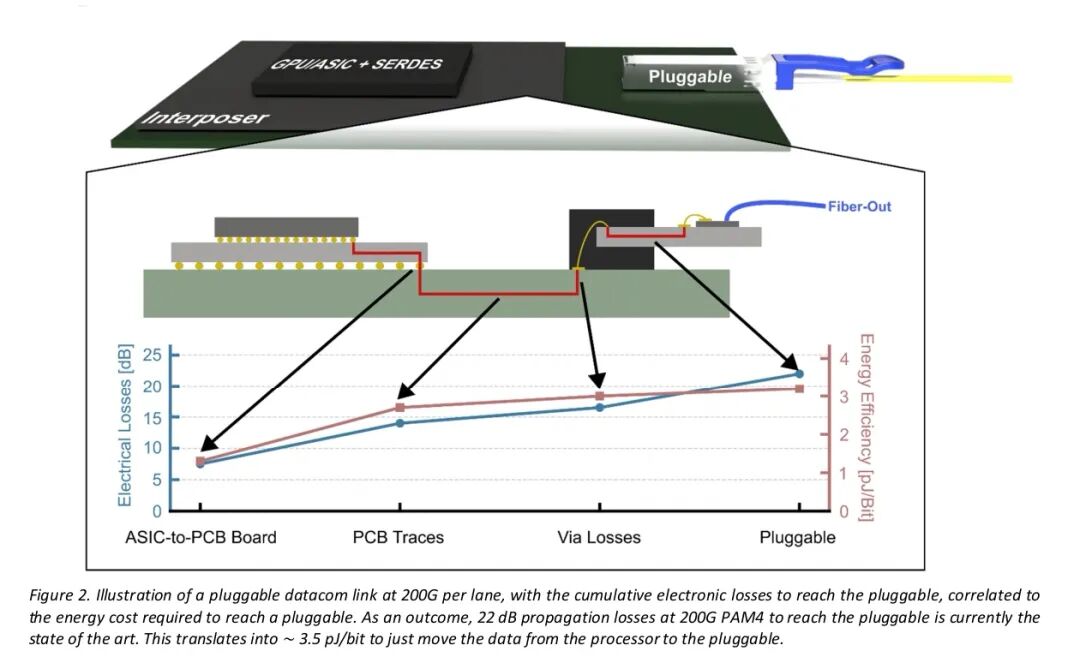
传输距离达到10米及以上的主流技术是集成DSP的可插拔光模块,其能量效率约为10 pJ/bit,加上串并转换器(SerDes)的3.5 pJ/bit,总能量效率为13.5 pJ/bit。若要提高能量效率,若光学引擎足够线性,可去除模块中的DSP,这就是所谓的线性驱动可插拔光学器件(LPO),但代价是串并转换器(SerDes)需承担更多处理工作。其典型能量效率约为5 pJ/bit,加上串并转换器(SerDes)中的5 pJ/bit(长距离协议DSP),总能量效率为10 pJ/bit。
另一种方案是在可插拔器件内部采用低速宽通道(WaS)技术,例如微软(Microsoft)通过microLED实现了可插拔器件3.6 pJ/bit的能量效率,总能量效率为6.6-7 pJ/bit。
CPO方案中,博通和NV的SiPh调制器的光学引擎能效约为6.7 pJ/bit(200 Gbit/s),含SerDes的总能效约8 pJ/bit,加上串并转换器(SerDes),总能量效率约为8 pJ/bit,仍有改进空间。理想情况下,若整个链路足够线性,可完全去除DSP,代之以模拟预失真。VCSEL作为竞争方案已验证了这种方法的可行性:在108 Gbit/s速率下,VCSEL CPO的光学引擎能量效率已达到0.9 pJ/bit,预计该模块的总能量效率约为2 pJ/bit。
Ayar Labs的SaW架构SiPho方案总能效低于5 pJ/bit。对于VCSEL,在约64 Gbit/s NRZ速率下,采用为PAM4设计的电子集成电路(EIC)已实现1.54 pJ/bit的能量效率。
Intel的VCSEL CPO光发射机(4×64Gb/s NRZ)
VCSEL在驱动电流低至0.5 mA时,带宽已可达到约15 GHz。结合发射端的电压驱动方案和接收端采用极低电容光电二极管以限制跨阻抗放大器(TIA)的能耗,借助UCIe、时钟转发和低速宽通道(SaW)方案带来的其他优势,估计32 Gbit/s VCSEL阵列的总能量效率可达到约0.75 pJ/bit。
最后,还可考虑采用无串并转换器(serializer-free)方案。在学术研究中,硅光子微环调制器(SiPho MRM)光学引擎在10 Gbit/s每通道速率下实现了0.3 pJ/bit的出色能量效率。结合UCIe模块标准,其潜在总能量效率可达到0.5-0.6 pJ/bit。但该方案的挑战在于,可插拔激光器内需集成大量波长的频率梳。
对于直接调制发射器可以无需可插拔激光器,但需增加光纤芯数。例如,Avicena采用可见光波长的microLED实现了这一方案:在3.3 Gbit/s速率下,通过精细调谐接收端电子电路,在光学引擎的背靠背测试中实现了1 pJ/bit的能量效率。对于这类精细调谐的系统,发射器的电源转换效率至关重要。在microLED的案例中,高效的接收端电子电路和无阈值工作特性无法完全弥补其1.2%的低发射器电源转换效率。此外,氮化镓(GaN)LED的驱动电压约为4.4 V,且光纤的高衰减要求比背靠背实验更高的输出功率。因此,microLED在1.6 Gbit/s的有限比特率下,光学引擎的能量效率为3.6 pJ/bit。
另一方面,VCSEL的工作电流无需远高于阈值电流,但通过去除跨阻抗放大器(TIA)并采用光电二极管的电阻性负载,VCSEL基链路在4 Gbit/s速率下有望实现0.5 pJ/bit的能量效率。
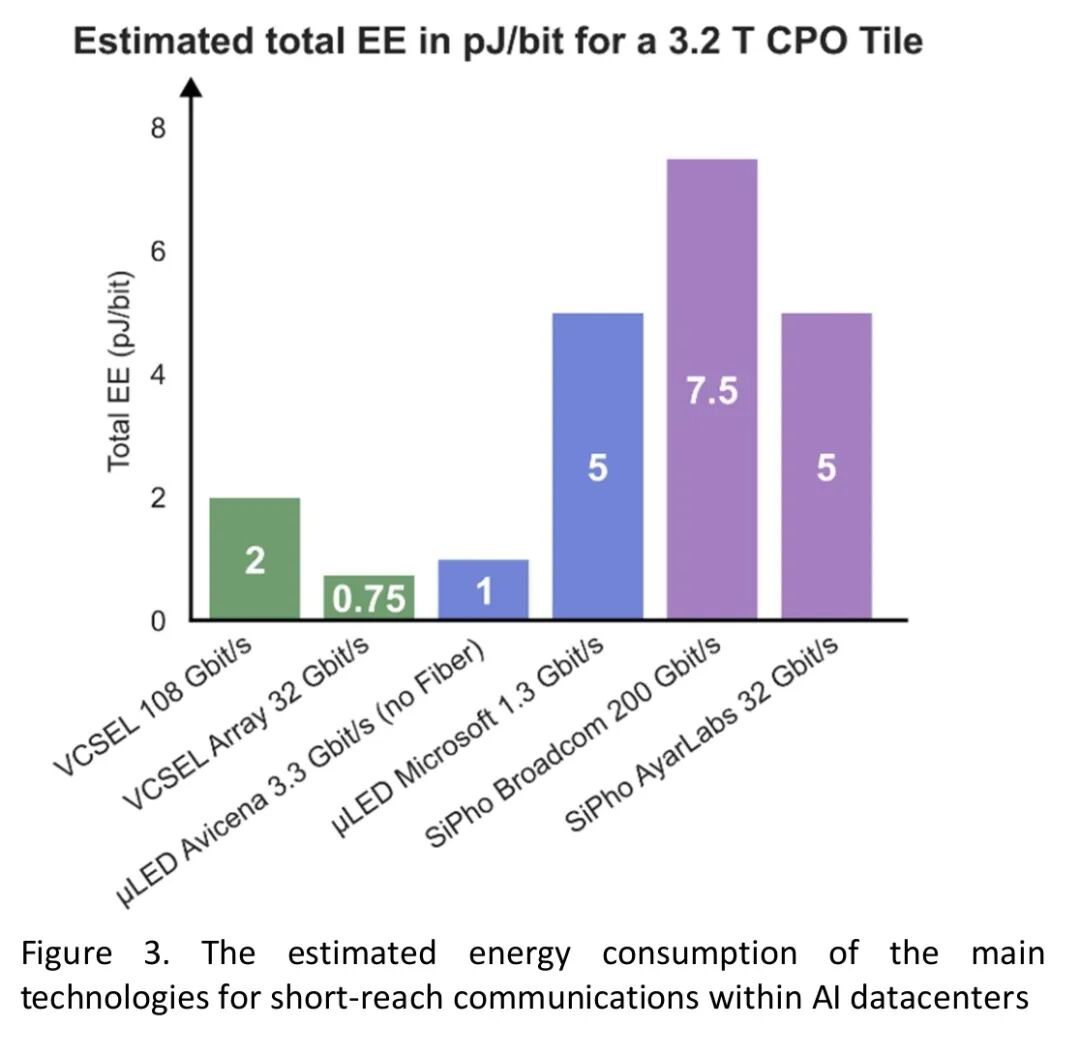
图3总结了基于本章数据估算的AI数据中心短距离通信的能量效率。VCSEL在整个比特率范围内均能实现带宽与电源转换效率(>20%)的独特结合。比特率越高,接收端所需的光功率越大,但这种额外功率会被比特率的提升所抵消。对于低速宽通道(WaS)方案,通过优化降低阈值,可使光学引擎的能量效率达到1 pJ/bit以下。与硅光子微环调制器(SiPho MRM)不同,VCSEL无需锁定电子器件和频率梳,因此是替代铜缆的最简单解决方案。
2. 占位面积(Footprint)
以前占位面积的主要关注点是GPU的接口带宽密度(即芯片边缘输出的带宽密度)。然而,垂直耦合技术的最新发展使关注点转向了太比特/秒/平方毫米(Tbit/s/mm²)级别的带宽密度。本文强调的所有方案均能满足当前CPO对带宽密度>0.5 Tbit/s/mm²的要求。通过3D共集成(将光学引擎与EIC堆叠)可实现最佳带宽密度。EIC在技术、节点和层堆叠方面的通用性,缓解了电子器件层面的带宽密度问题。速率越低,EIC的复杂度越低,可抵消通道数量增加带来的挑战。
对于发射端(Tx)和接收端(Rx)的光学部分,目前硅光子微环调制器(SiPho MRM)的最先进带宽密度(不含串并转换器/SerDes占位面积)为0.5至约1 Tbit/s/mm²。microLED的带宽密度主要受间距和每通道速率限制,在当前50微米(µm)间距和4 Gbit/s速率下,假设发射端(Tx)和接收端(Rx)占位面积相近,其带宽密度为0.8 Tbit/s/mm²。VCSEL可实现类似的间距,结合更高的速率,可实现更高的带宽密度——例如,在32 Gbit/s的中等速率和50微米间距下,VCSEL阵列的带宽密度可达到6.4 Tbit/s/mm²。
3. 传输距离(Reach)
AI数据中心scale-up网络的典型传输距离为1至30米,部分超级集群(如华为与谷歌计划的9000+ GPU集群)需求更长。不同技术的传输能力受光纤损耗、模态色散与色度色散影响:
- SiPho采用1310 nm单模光纤,吸收损耗低于0.3 dB/km,可实现数公里传输;
- VCSEL传统采用多模光纤(OMx),850至1060 nm波段损耗为2.3 dB/km,FaN架构下受模态色散限制,100 Gbit/s速率传输距离约150米,而SaW架构采用定制单模芯光纤束可抵消色散,传输距离达100米;
- microLED采用成像光纤束,420 nm波长下5米传输损耗约3 dB,且宽光谱( spectral width >20 nm)导致色度色散严重,30米传输速率仅1.6 Gbit/s,此时比特误码率(BER)才能控制在10⁻⁴以下。
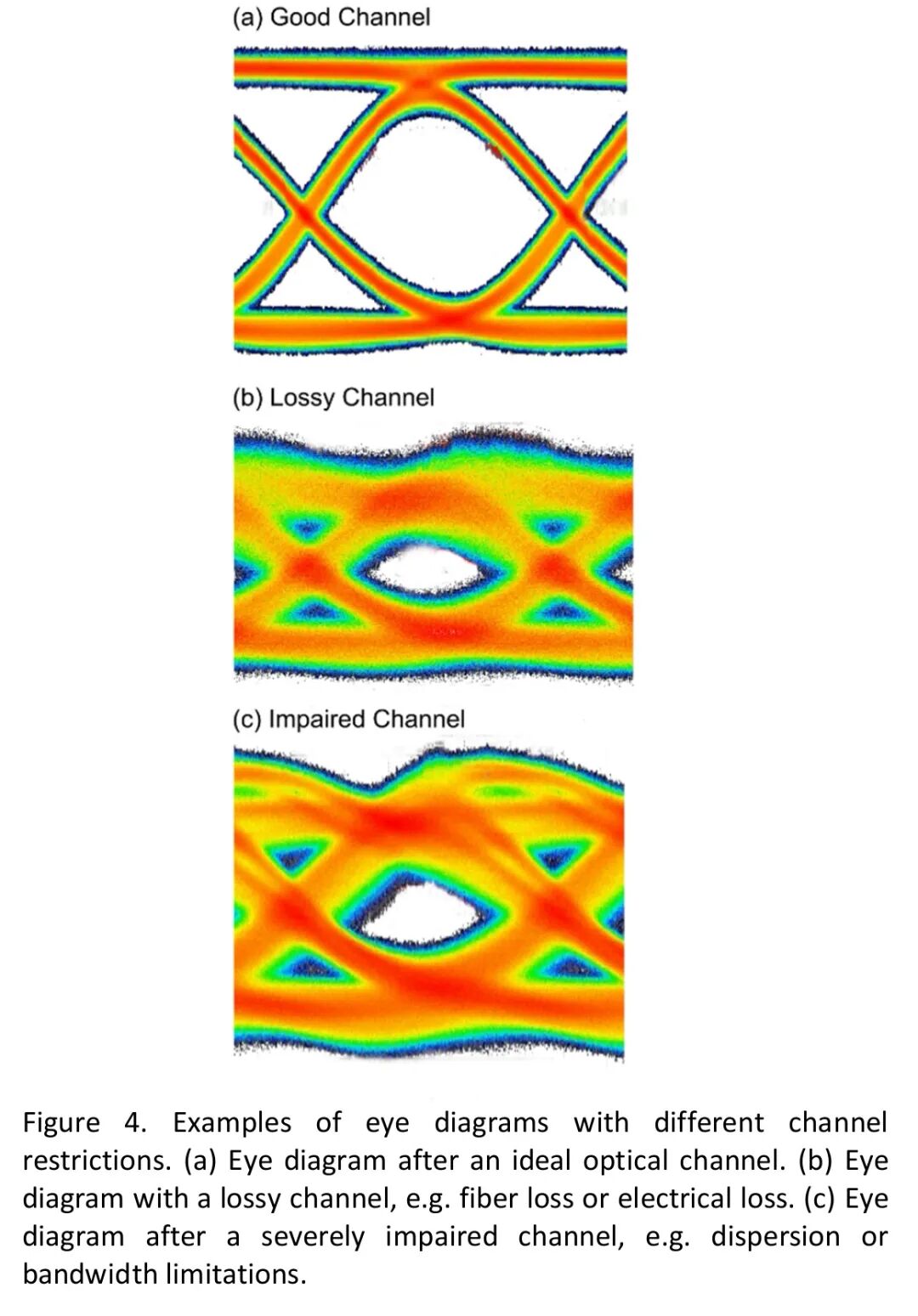
4. 可靠性(Reliability)
AI模型训练周期长达一个月,成本超1亿美元,任何链路故障都需从最近备份点重启,因此可靠性至关重要。CPO要求BER低于10⁻¹²(NRZ)或10⁻⁶(PAM4),且故障间隔时间(MTBF)需显著优于电子器件。
从可插拔架构转向CPO架构对可靠性提出了严格要求,因为光学引擎不可更换。理想情况下,光学引擎的故障发生率(FIT,每10⁹小时的故障次数)应显著低于电子器件。Meta的数据显示,CPO的链路平均无故障时间(MTBF)比可插拔器件提高了约5倍。博通(Broadcom)采用硅光调制器的Bailly 51.2 Tbit/s CPO交换机,0.8 Tbit/s CPO模块的不可维修故障发生率(FIT)低于66。
这种可靠性的提升,加上链路波动的减少,可减少重启次数,从而将训练成本降低约50%。对于microLED,单个发射器的典型故障发生率(FIT)预计为0.1,在2 Gbit/s速率下,3.2 Tbit/s模块的发射器总故障发生率(FIT)为160。低速宽通道(WaS)方案(尤其是microLED和VCSEL阵列)的优势在于易于实现冗余通道——添加15%的冗余通道后,总链路的故障发生率(FIT)有望降至10以下。
Coherent的100G VCSEL在120°C、4 mA驱动电流下,单个发射器的故障发生率(FIT)约为0.03;在85°C、5 mA驱动电流下,故障发生率(FIT)为0.07。假设直接调制激光器占故障总数的约40%,则整个链路的故障发生率(FIT)上限为0.2,32路100G链路(3.2 Tbit/s模块)的总故障发生率(FIT)为6.4,仅需添加2个冗余通道即可将总故障发生率(FIT)降至约1。
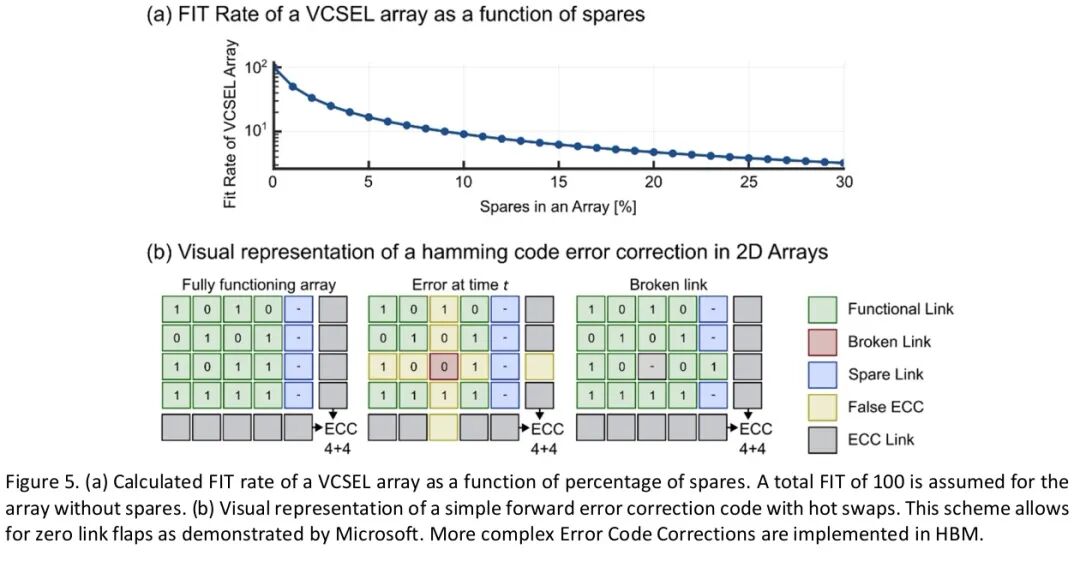
对于低速宽通道方案,假设包含512条链路,最坏情况下的总故障发生率(FIT)约为100,添加10%的冗余通道可将故障发生率(FIT)降至约10。图5(a)展示了初始总故障发生率(FIT)为100时,冗余通道百分比对VCSEL阵列故障发生率(FIT)的影响。针对低速宽通道(WaS)优化VCSEL(降低速率、阈值电流和输出功率,进而降低驱动电流)将进一步提高可靠性。
此外,微软(Microsoft)的研究表明,在低速宽通道(WaS)方案中,通过冗余通道与纠错码的结合,不仅可以从短期链路中断中恢复,还能通过热插拔任何故障链路实现长期链路激活。微软(Microsoft)的方案预测链路比铜缆更具韧性,类似方案也可应用于VCSEL阵列。图5(b)展示了带冗余通道和热插拔功能的二维阵列纠错码示意图。
5. 成本(Cost)
比较不同方案的成本时,需考虑整个链路,包括SerDes/UCIe模块。首先,从DSP可插拔器件转向线性驱动可插拔光学器件(LPO)可降低光学引擎的成本,原因是可插拔器件中的DSP是组件中最昂贵的器件。800G可插拔器件的成本已从3.5/Gbps(?)降至批量生产后LPO预计的约0.05 /Gbps。但包含串并转换器(SerDes)/UCIe模块会显著增加成本。
转向CPO可通过省去外壳以及共集成驱动电路和跨阻抗放大器(TIA)进一步节省成本。低速宽通道(WaS)方案中更简单的gearbox可进一步降低成本。对于硅光子微环调制器(SiPho MRM),与直接驱动方案(VCSEL、LED)相比,由于需要可插拔激光器(ELSFP),成本仍然较高。与功耗类似,若定制光纤的成本大幅下降,在CPU和GPU速率下采用直接驱动发射器有望实现最低的每吉比特/秒(Gbit/s)成本。最优权衡将取决于平均链路长度——若计入串并转换器(SerDes)/UCIe模块的成本,对于scale up网络所需的大批量应用,有望实现与铜缆相当的成本。
五、VCSEL基CPO的独特优势与量产潜力
VCSEL基CPO之所以成为AI数据中心scale-up网络的核心竞争者,源于其在技术特性与工程化上的综合优势:
其一,全比特率适配性。VCSEL既可支持100至200 Gbit/s的FaN PAM4架构,实现与铜缆的互操作性,也可优化为SaW NRZ架构,通过多芯光纤提升能效与可靠性,满足不同场景需求。
其二,高可靠性与冗余设计。VCSEL作为成熟量产技术,25年应用史验证了其稳定性,且直接调制特性使单通道故障互不影响,具备天然的冗余优势;而SiPho的多微环共享波导设计,单个元件故障可能影响相邻通道。
其三,极简系统复杂度。VCSEL无需外部激光器、锁相电子器件与频率梳,相比SiPho与microLED,系统集成难度更低,量产可行性更高。
其四,量产级成熟度。目前VCSEL是唯一实现量产级CPO解决方案的技术,且能在scale-up光纤链路中实现低于1 pJ/bit的能效,完全满足AI数据中心的严苛要求。虽然“高速窄通道”链路可实现与铜缆的互操作性,且关键指标更优,但本文表明,“低速宽通道”VCSEL阵列借助固有的冗余和先进编码技术,可进一步提升能量效率和链路平均无故障时间(MTBF)等关键指标。
六、结论
AI数据中心的规模化扩展对带宽、能效、可靠性与成本的多维需求,推动了从铜缆互连向CPO技术的不可逆转型。在众多CPO竞争技术中,VCSEL基方案凭借其全比特率下的高能效、高带宽密度、长传输距离、高可靠性与低成本优势,成为当前最具量产潜力的核心技术之一。SaW架构的VCSEL阵列通过简化电子链路、引入冗余设计与多芯光纤复用,进一步优化了能效与MTBF等关键指标,完美匹配AI模型训练的严苛需求。随着VCSEL技术在更高速率、更高集成度上的持续突破,以及多芯光纤成本的下降,VCSEL基CPO将成为AI数据中心scale-up网络的主流解决方案,为下一代人工智能算力扩展奠定坚实基础。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号