Science4AI?| 当长链推理遇上分子结构,字节跳动从零合成 CoT 思维链

Science4AI?| 当长链推理遇上分子结构,字节跳动从零合成 CoT 思维链

MindDance
发布于 2026-01-22 12:34:59
发布于 2026-01-22 12:34:59
大型语言模型在复杂推理任务中的卓越表现,很大程度上归功于思维链的引导。然而,当推理路径变得冗长复杂时,模型的学习和泛化能力往往会急剧下降。近期,一篇来自字节跳动 Seed 团队与哈工大、北大等机构的开创性论文,为这一难题提供了全新的解答。该研究是 Science4AI 范式的典型案例,首次将长思维链的推理过程类比为分子的形成与折叠过程,提出了一个全新的“思想的分子结构”理论框架。该研究不仅深刻揭示了 LLM 如何学习并执行长链推理,还基于此理论开发出 MOLE-SYN 方法,能够从零开始“合成”高效的思维链结构,为提升模型的复杂推理能力开辟了全新路径。
背景
思维链(Chain-of-Thought, CoT)通过引导模型生成一系列中间推理步骤,显著提升了其在算术、常识和符号推理等任务上的能力。然而,当模型需要处理包含数十甚至上百步的复杂问题时,即所谓的长思维链,挑战也随之而来。
研究表明,通过简单的监督微调或从强模型进行知识蒸馏,并不能稳定地让一个较弱的模型学会长链推理。模型在模仿人类或其他模型的长推理轨迹时,往往会在中途失去逻辑连贯性,或者无法将学到的推理模式泛化到新的、未见过的任务上。论文通过实验(见下面两个图)验证了这一点:从弱指令模型的上下文学习(ICL)蒸馏以及人类推理轨迹微调所带来的收益都非常有限,指令模型只能模仿约 6-8 步的短思维链,无法扩展探索同时保持中间步骤和轨迹连贯性。
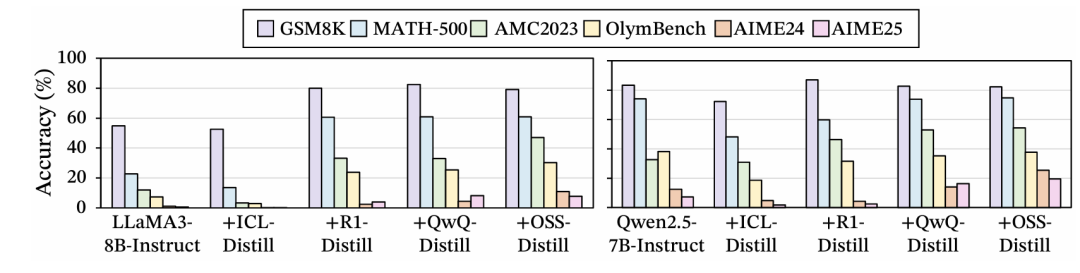
从弱指令模型蒸馏与从强推理模型蒸馏的性能对比
从弱指令模型蒸馏与从强推理模型蒸馏的性能对比
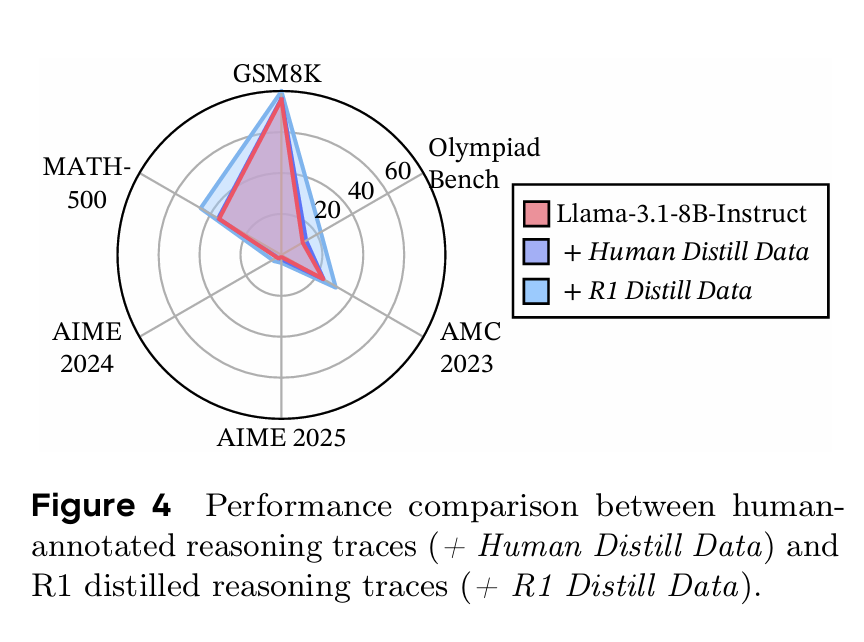
人类标注推理轨迹与 R1 蒸馏推理轨迹的性能对比
人类标注推理轨迹与 R1 蒸馏推理轨迹的性能对比
这种现象引出了一个核心问题:LLM 学习有效长链推理的内在机制究竟是什么?为什么有些推理路径是可学习的,而另一些则不是? 这正是本文试图解答的根本性难题。
方法
为了解开长链推理的黑盒,研究者提出了一个极具启发性的核心假设:一个稳定、有效的长思维链,其内部存在着类似于分子的拓扑结构。这个思想分子的稳定性并非凭空而来,而是由三种不同类型的化学键共同维系的。这一理论将抽象的认知过程与具象的化学生物学原理联系起来,为理解 LLM 推理提供了一个全新的分析视角,是 Science4AI 思想的绝佳体现。
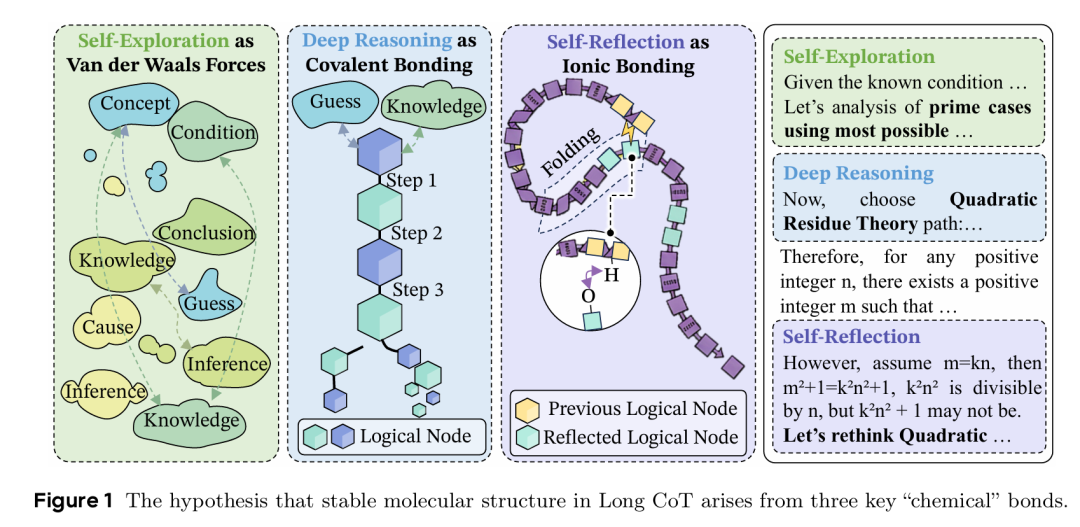
三种化学键形成稳定长思维链分子结构的假设示意图
三种化学键形成稳定长思维链分子结构的假设示意图
这三种逻辑上的化学键分别是:
深度推理(Deep Reasoning)—— 共价键。这是构成思维过程的骨架,代表了推理步骤之间最强的逻辑依赖关系,如同共价键连接起分子的主链。例如,一个数学证明中的步骤 B 必须基于步骤 A 的结论才能成立。这种强依赖关系保证了推理的方向性和连续性,一旦共价键断裂,整个推理链就会崩溃。论文指出,深度推理后 72.56% 的步骤保持在语义空间中组距离小于 3 的范围内,组间距离通常大于 5.6,这表明深度推理主要增加局部连通性,形成稳定子域。
自我反思(Self-Reflection)—— 氢键。这是思维链的稳定器,通过在推理链的不同部分之间建立长程连接,实现逻辑上的自洽和一致性检验。这非常类似于蛋白质分子通过氢键折叠形成稳定的三维结构。例如,在推理到第 100 步时,模型可能会回顾并检验第 10 步设立的一个前提是否仍然成立。实验数据显示,81.72% 的反思步骤会重新连接到先前形成的高语义相似性簇,而非线性延伸链。这种折叠机制极大地约束了逻辑漂移和幻觉,使得长链推理能够保持高度的内部一致性。
自我探索(Self-Exploration)—— 范德华力。这代表了思维过程中较为松散和探索性的联系,类似于分子间微弱的范德华力。它支持模型进行归纳和溯因推理,允许在没有强约束的情况下,对不同的概念和假设进行低成本的试探和关联。探索转换作为松散链接连接原本分离的簇,平均步间距离为 5.32(在 3D t-SNE 投影中)。这种探索为推理过程提供了灵活性和创造力,避免了过早陷入局部最优解。

t-SNE 可视化验证长思维链的逻辑折叠结构
t-SNE 可视化验证长思维链的逻辑折叠结构
基于这套理论,研究者进一步提出了语义同分异构体(Semantic Isomers)的概念。即便是由相同的概念原子组成,如果连接它们的化学键类型或顺序不同,也会形成结构和稳定性迥异的思想分子,从而导致一些推理路径有效,而另一些则失败。这解释了为什么简单的模仿和蒸馏往往效果不佳——因为它们可能复制了表面的文字,却忽略了其底层的、正确的分子结构。
为了验证并应用这一理论,团队开发了 MOLE-SYN 方法。该方法的核心思想是,既然有效的长思维链具有稳定的分子结构,那么或许可以不依赖昂贵的强模型蒸馏数据,而是直接从零开始合成这种结构。MOLE-SYN 通过分析强模型在不同推理行为(深度推理、自我反思、自我探索)之间的迁移概率图,将其作为合成蓝图,仅使用普通的指令微调模型进行随机游走,就能生成具有优良结构的长思维链数据,从而低成本地将复杂推理能力赋予普通模型。
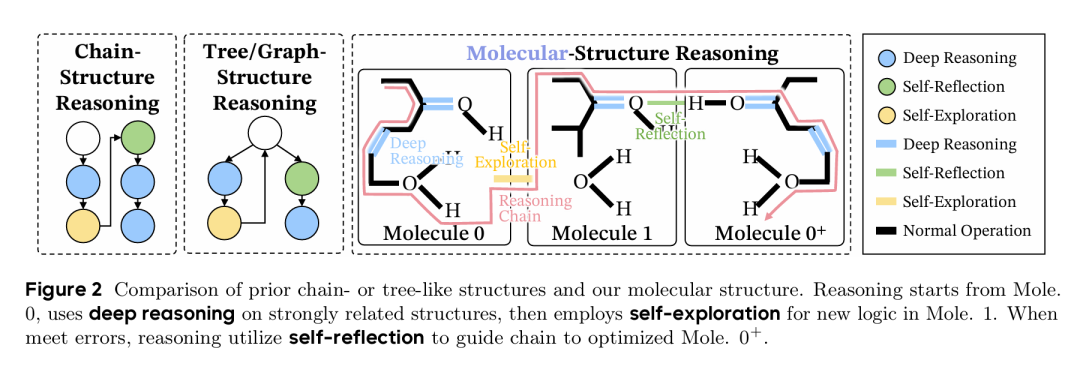
链式结构、树/图结构与分子结构推理的对比
链式结构、树/图结构与分子结构推理的对比
结果
研究通过一系列严谨的实验,为思想分子理论提供了有力证据,并展示了 MOLE-SYN 方法的有效性。
分子结构的普适性验证。实验首先验证了这种由化学键定义的推理结构是否真实存在且具有普适性。通过分析多个不同架构和规模的 LLM(如 DeepSeek-R1-0528, OpenAI-OSS-120B, QwQ-32B)生成的推理轨迹,研究发现它们在不同任务上展现出的推理行为转换模式(即迁移图)具有惊人的一致性。当采样量超过 2000 时,跨模型的皮尔逊相关系数高达 0.9 以上(p<0.001),迁移图稳定后相关性超过 0.95。这表明,高效的长链推理确实遵循着一套通用的、不依赖于特定模型的底层结构语法。
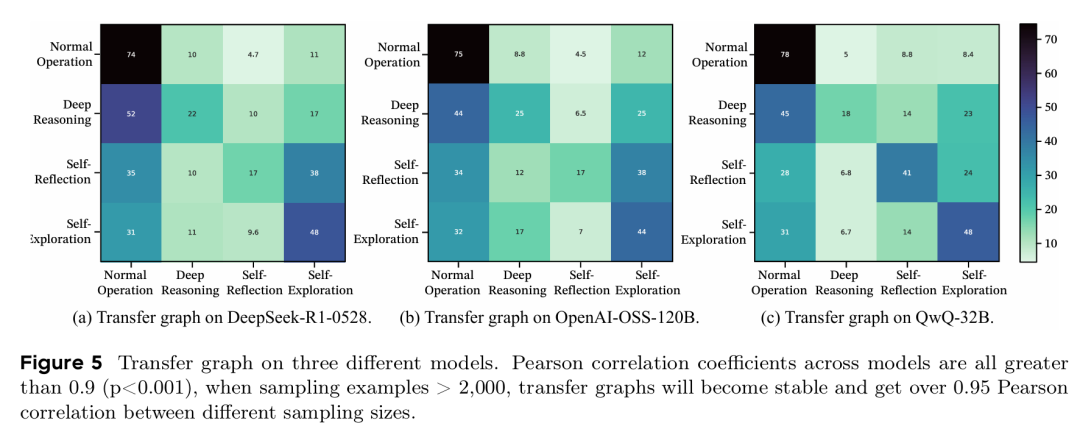
三个不同模型的推理行为迁移图及其高度相关性
三个不同模型的推理行为迁移图及其高度相关性
模型学习的是结构而非关键词。一个常见的假设是,模型通过学习特定的关键词(如 Maybe、But/so、Alternatively)来触发不同的推理行为。然而,本文的实验颠覆了这一认知。研究者将推理链中的所有关键词进行替换或完全移除,只保留其底层的逻辑结构,然后用这些数据对模型进行微调。下图的结果显示,从 1K 到 20K-5epoch 的数据规模下,模型的性能几乎没有下降。这雄辩地证明了,LLM 在学习 CoT 时,内化的是抽象的、可泛化的推理结构本身,而非表面的词汇线索。
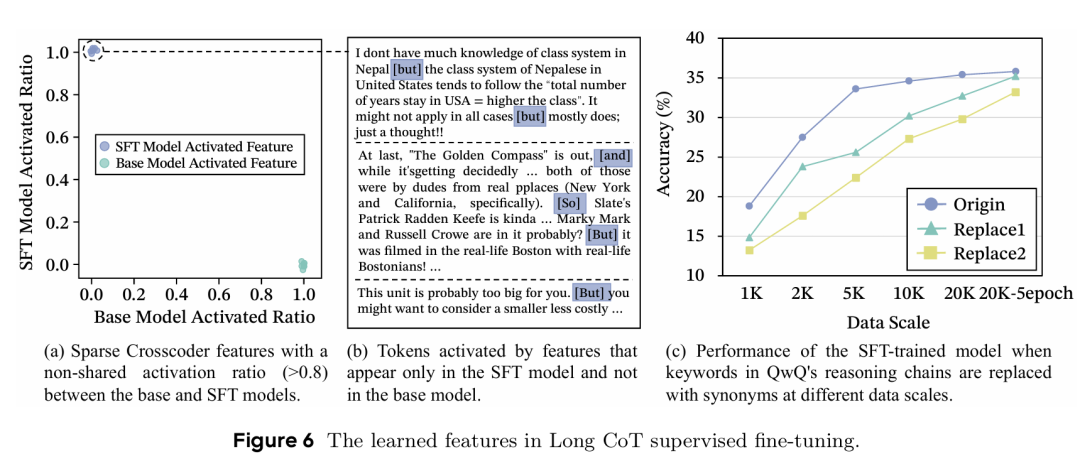
稀疏自编码器分析及关键词替换实验结果
稀疏自编码器分析及关键词替换实验结果
注意力机制与键能级的对应关系。研究发现 Transformer 中的注意力权重形成类似 Gibbs-Boltzmann 分布的模式。下图显示,深度推理展示最大的有效键能(),反思居中(),探索最弱(),这种排序在不同模型间保持一致。
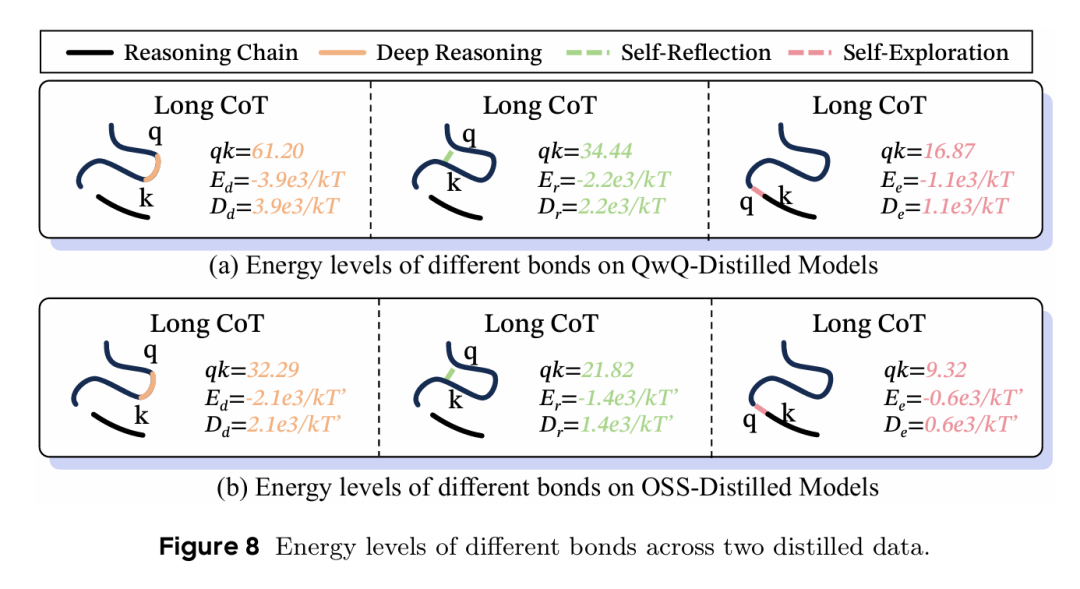
不同键类型的能级对比
不同键类型的能级对比
两种稳定结构之间的冲突。下图显示,尽管 DeepSeek-R1 和 OpenAI-OSS 的推理链高度相关(r ≈ 0.9),共同激活会阻止模型收敛到单一稳定模式,性能显著下降。这表明结构兼容性而非统计相关性决定推理系统能否共存。
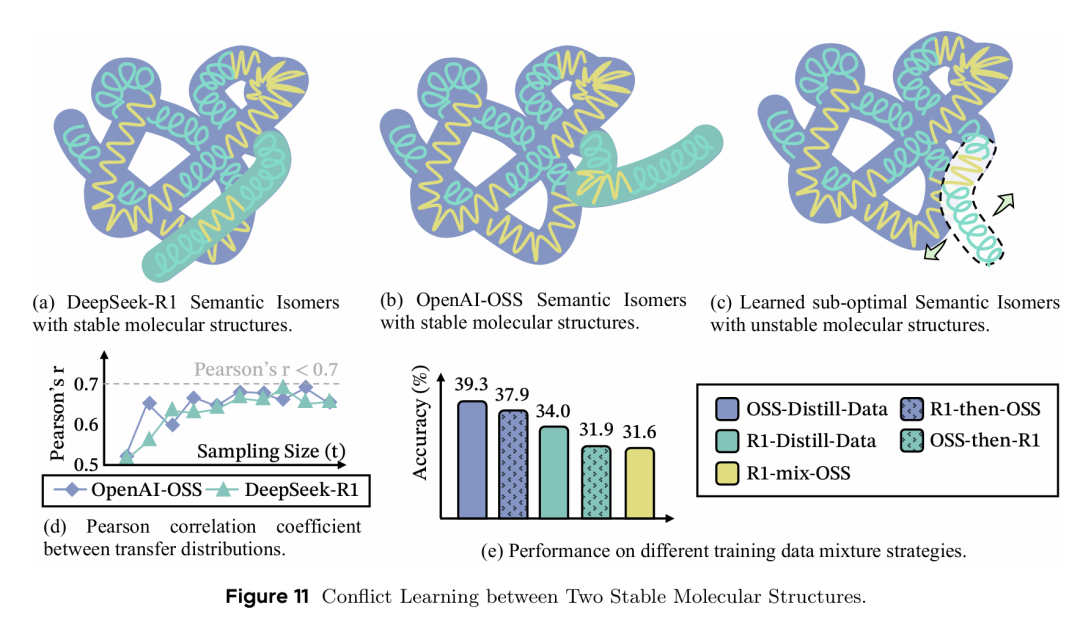
两种稳定分子结构的冲突学习现象
两种稳定分子结构的冲突学习现象
MOLE-SYN 的性能表现。MOLE-SYN 的表现是本次研究中最令人振奋的部分。下表显示,使用 MOLE-SYN 从零合成的数据进行训练的 LLaMA-3.1-8B 模型,在多个推理基准测试上的性能几乎可以媲美使用来自强模型的昂贵蒸馏数据的训练效果。例如,LLaMA-3.1-8B-Instruct + 20K QwQ-MOLE-SYN 在 GSM8K 上达到 84.31% ,在 MATH-500 上达到 50.20% ,与 + 20K QwQ-Distill-Data 的 82.41% 和 60.80% 相当接近。这证明了思想分子理论的正确性和实用价值:只要掌握了正确的合成蓝图,就能以极低的成本,高效地为模型注入强大的长链推理能力。
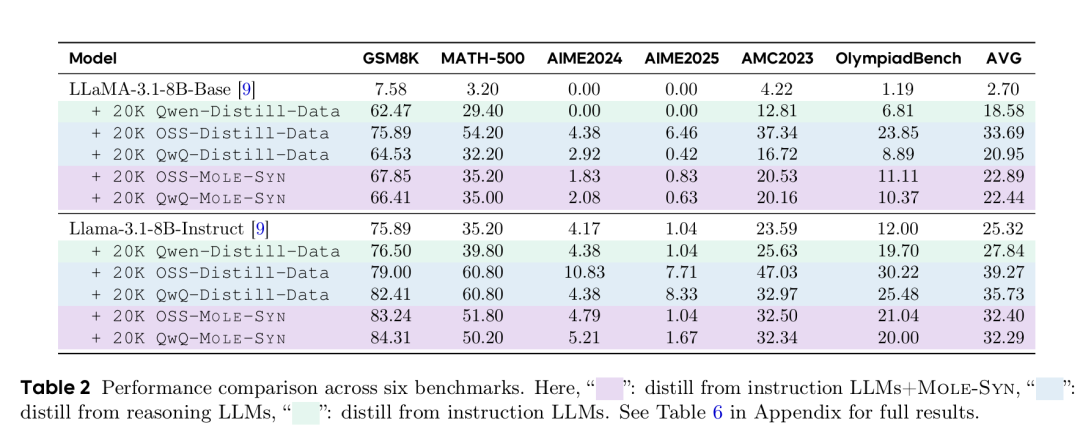
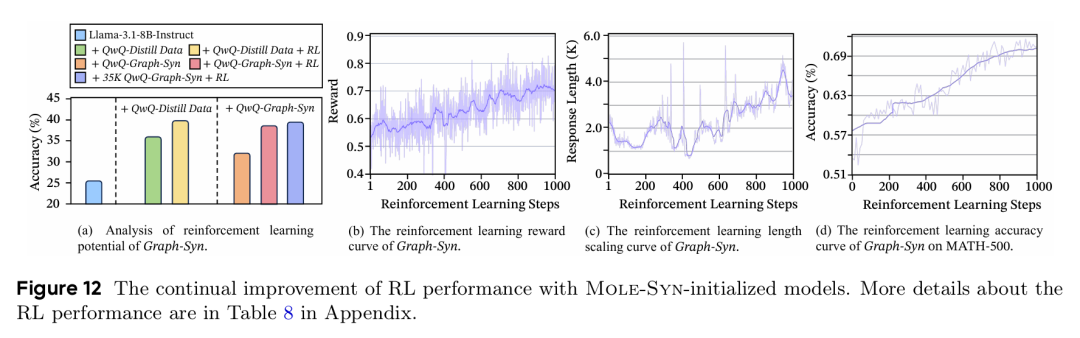
MOLE-SYN 初始化模型在强化学习中的持续改进曲线
MOLE-SYN 初始化模型在强化学习中的持续改进曲线
此外,上图显示,经 MOLE-SYN 初始化的模型在后续的强化学习(RL)中表现出更强的潜力和更稳定的性能提升,奖励曲线更平稳,响应长度缩放更合理,准确率持续上升。
局限与启示
尽管本研究取得突破性进展,但作者也指出了局限性:分析基于有限的教师模型和学生骨干,方法在带有 RL 反馈的在线设置中如何扩展仍是开放问题,分子结构的几何可视化仍是近似的。
这项工作的启示是深远的:思想的分子结构假说将指导从经验式的提示工程和数据蒸馏,转向更加结构化的模型能力构建。这正是 Science4AI 思想的核心——借助自然科学中成熟的理论和方法论来指导人工智能的发展。未来或许可以像设计新药分子一样,为特定任务设计和合成最优的思维链结构。
这项研究最核心的贡献在于,它为 CoT 能力的迁移和学习问题提供了一个极具洞察力的机制性解释,是 Science4AI 范式的一次成功实践。过去,CoT 被视为一个黑盒,通过模仿和蒸馏来期望模型能碰巧学到其中的精髓。而思想分子理论则将这个黑盒打开了一条缝,揭示了内部的分子骨架、氢键折叠和范德华力探索。
这种从经验到机制的转变意义重大,意味着可以对推理过程进行量化分析和定向优化。例如,可以诊断模型的分子结构是共价键太弱导致逻辑断裂,还是氢键不足导致思维发散,并通过强化学习增强特定键的形成概率。
此外,MOLE-SYN 方法的成功也为大模型能力的平民化提供了新的可能性。它表明,复杂推理能力并非顶级模型的专利,通过理解其内在结构,可以找到更经济、更高效的方法来将这些能力合成并赋予更多中小型模型,这将极大地推动 AI 技术的普及和应用。
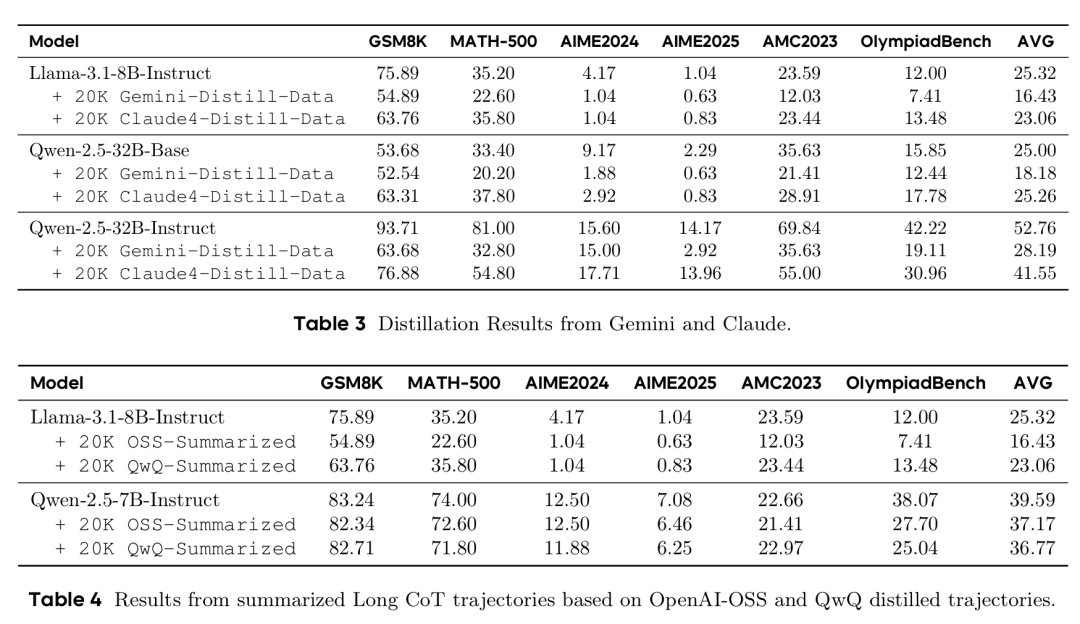
值得注意的是,论文还揭示了一个重要的防护机制:摘要化和推理压缩可以有效保护 Long CoT 结构免受蒸馏,阻止内部推理过程的未授权复制。下面两个表显示,超过约 45% 的 token 减少会破坏 Long CoT 结构,摘要化轨迹训练产生比完整轨迹训练更弱的性能。这为私有模型的知识产权保护提供了一种天然屏障。
值得思考的问题
Q1: 思想的分子结构理论对于理解人类认知过程有何启发?
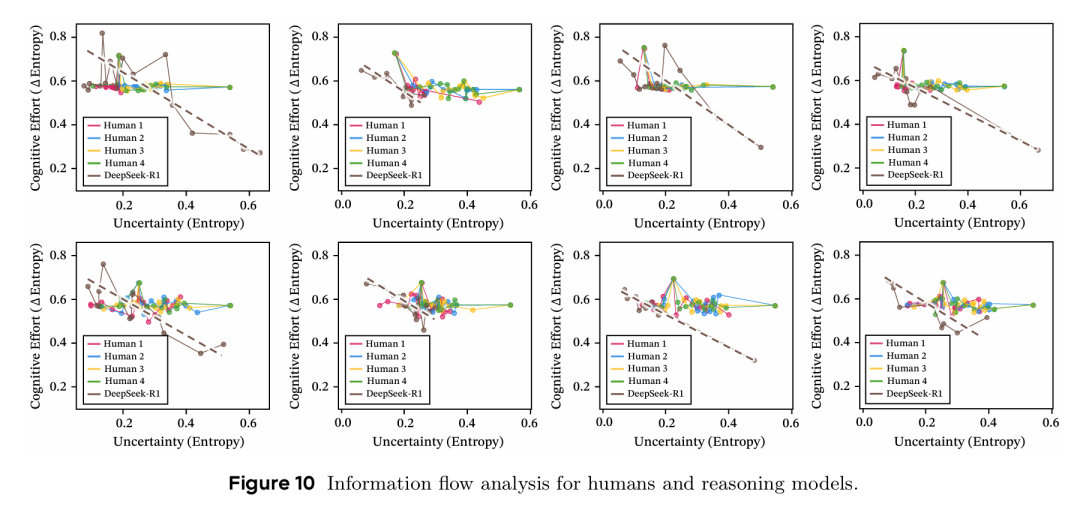
A1: 该理论受生物化学中蛋白质折叠等过程的启发,反过来也为理解人类思维提供了计算模型。人类在复杂推理时同样需要深度推理构建逻辑主线、自我反思检查一致性、探索性思考寻找新可能。下图显示,人类推理展现近乎均匀的前向信息增益(81.3% 的情况变化 < 0.1),而 R1 模型则显示高熵探索与稳定收敛交替的元认知振荡模式。这为认知科学提供了可计算、可验证的假设框架。
Q2: MOLE-SYN 方法是否意味着未来不再需要超大规模的教师模型来进行知识蒸馏?
A2: MOLE-SYN 显著降低了对昂贵蒸馏数据的依赖,但可能无法完全取代教师模型。MOLE-SYN 的合成蓝图仍需从强教师模型提取一次,且文章显示其在高难度任务(如 AIME2024、AIME2025)上与直接蒸馏仍有差距。因此,MOLE-SYN 更可能成为高效辅助合成手段,与少量高质量蒸馏数据结合实现低成本能力迁移。
Q3: 除了文中提到的三种化学键,是否存在其他类型的逻辑连接方式?
A3: 完全有可能。三键模型是开创性的简化框架,但可能不是全部。论文提到的 Normal Operation 对应每步内的稳定局部键,可能是第四种基础操作。此外,是否存在催化键加速推理转换,或抑制键剪除无效分支,都是未来值得探索的方向。
Q4: 如何将思想分子理论应用于多模态或具身智能领域?
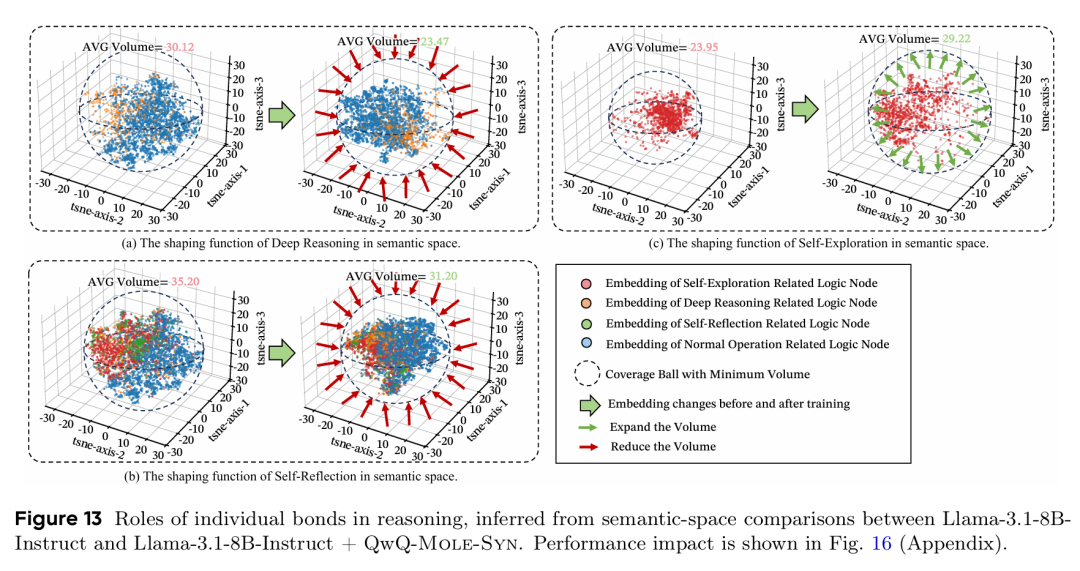
A4: 将这一理论扩展到多模态和具身智能领域极具前景。在多模态任务中,可以探索视觉观察与语言概念之间是否存在类似的跨模态键。在具身智能中,感知-规划-行动循环可被建模为更复杂的思想分子。下图展示的各键塑形功能(深度推理使体积减少 22%,自我反思使体积从 35.2 减少到 31.2,自我探索使体积从 23.95 扩展到 29.22)为这种扩展提供了可量化的分析框架。
欢迎关注、在看、分享,与 MindDance 一同探索 AI 的前沿。
参考文献:Chen, Q., Du, Y., Li, Z., et al. The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning. 2026.
文献链接:
https://huggingface.co/papers/2601.06002
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号