《人工智能导论》第 8 章 人工神经网络及其应用

《人工智能导论》第 8 章 人工神经网络及其应用

啊阿狸不会拉杆
发布于 2026-01-21 12:25:29
发布于 2026-01-21 12:25:29
一、神经元与神经网络
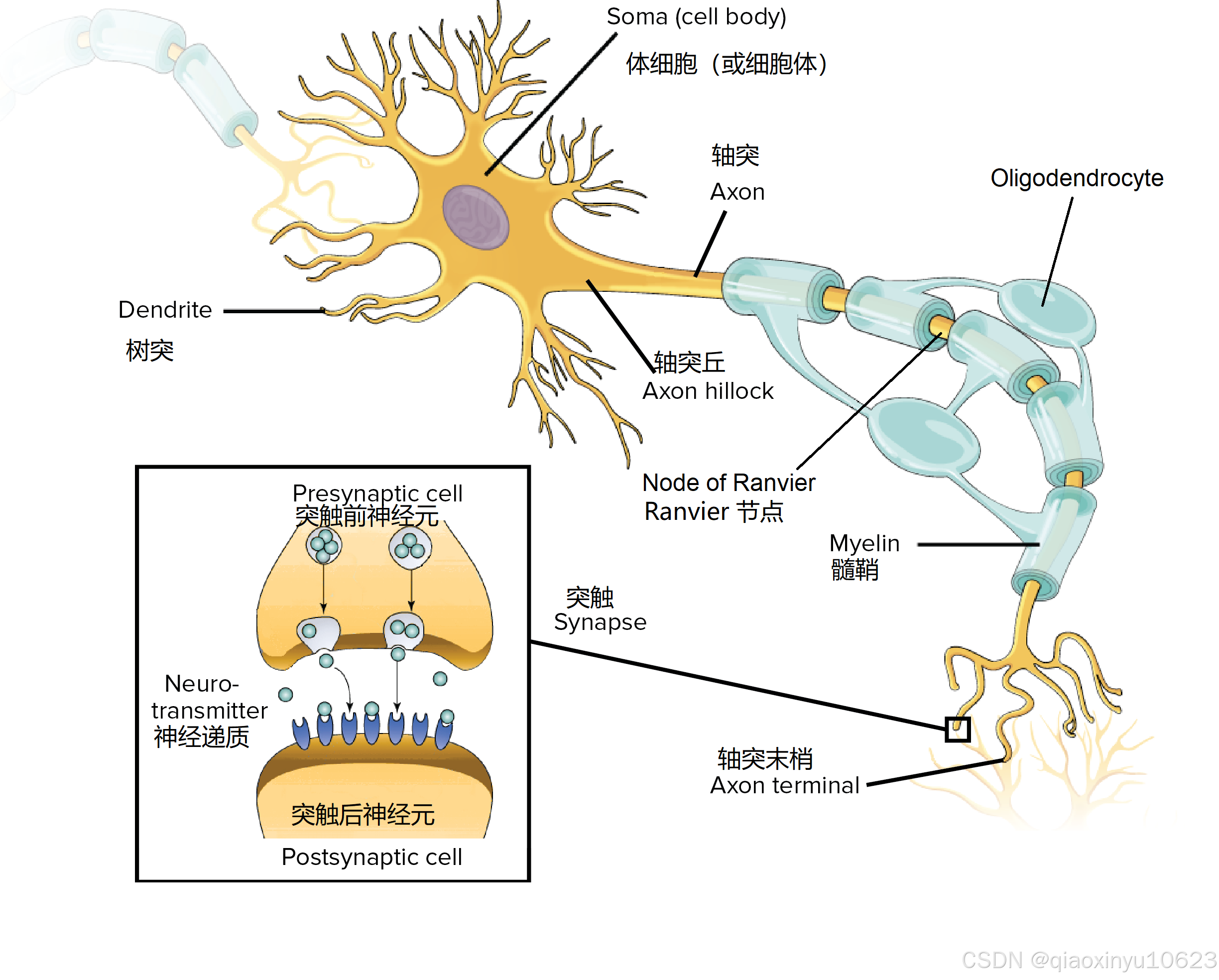
8.1.1 生物神经元结构
生物神经元主要由细胞体、树突、轴突和突触组成。树突接收其他神经元的信号,细胞体处理信号,轴突传递信号至其他神经元的突触。
8.1.2 神经元数学模型

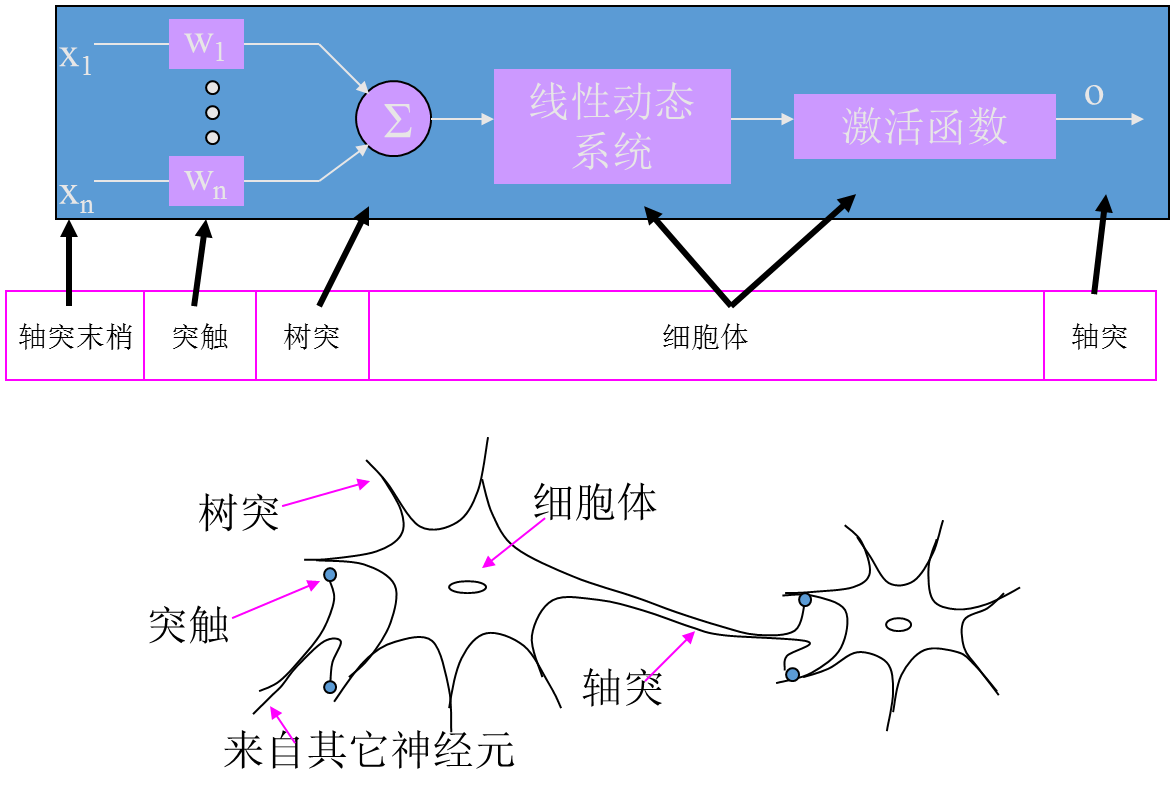
下面是一个简单的感知机实现:
import numpy as np
class Perceptron:
def __init__(self, input_dim, learning_rate=0.1):
"""
初始化感知机
input_dim: 输入维度
learning_rate: 学习率
"""
# 初始化权重和偏置,使用小的随机值
self.weights = np.random.randn(input_dim) * 0.01
self.bias = 0
self.lr = learning_rate
def activation(self, x):
"""阶跃激活函数"""
return 1 if x >= 0 else 0
def forward(self, x):
"""前向传播计算输出"""
# 计算加权和加上偏置
z = np.dot(x, self.weights) + self.bias
# 应用激活函数
return self.activation(z)
def train(self, X, y, epochs):
"""训练感知机"""
for epoch in range(epochs):
errors = 0
for xi, target in zip(X, y):
# 前向传播获取预测值
pred = self.forward(xi)
# 计算误差
error = target - pred
# 如果有误差,更新权重和偏置
if error != 0:
self.weights += self.lr * error * xi
self.bias += self.lr * error
errors += 1
# 打印训练进度
if epoch % 10 == 0:
print(f"Epoch {epoch}, Errors: {errors}")
return self
# 测试感知机 - 异或问题(需要线性可分数据,异或非线性可分,这里仅作演示)
if __name__ == "__main__":
# 异或数据(线性不可分,仅作演示)
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
# 创建感知机实例
perceptron = Perceptron(input_dim=2)
# 训练感知机
perceptron.train(X, y, epochs=100)
# 测试
for xi in X:
print(f"Input: {xi}, Predicted: {perceptron.forward(xi)}")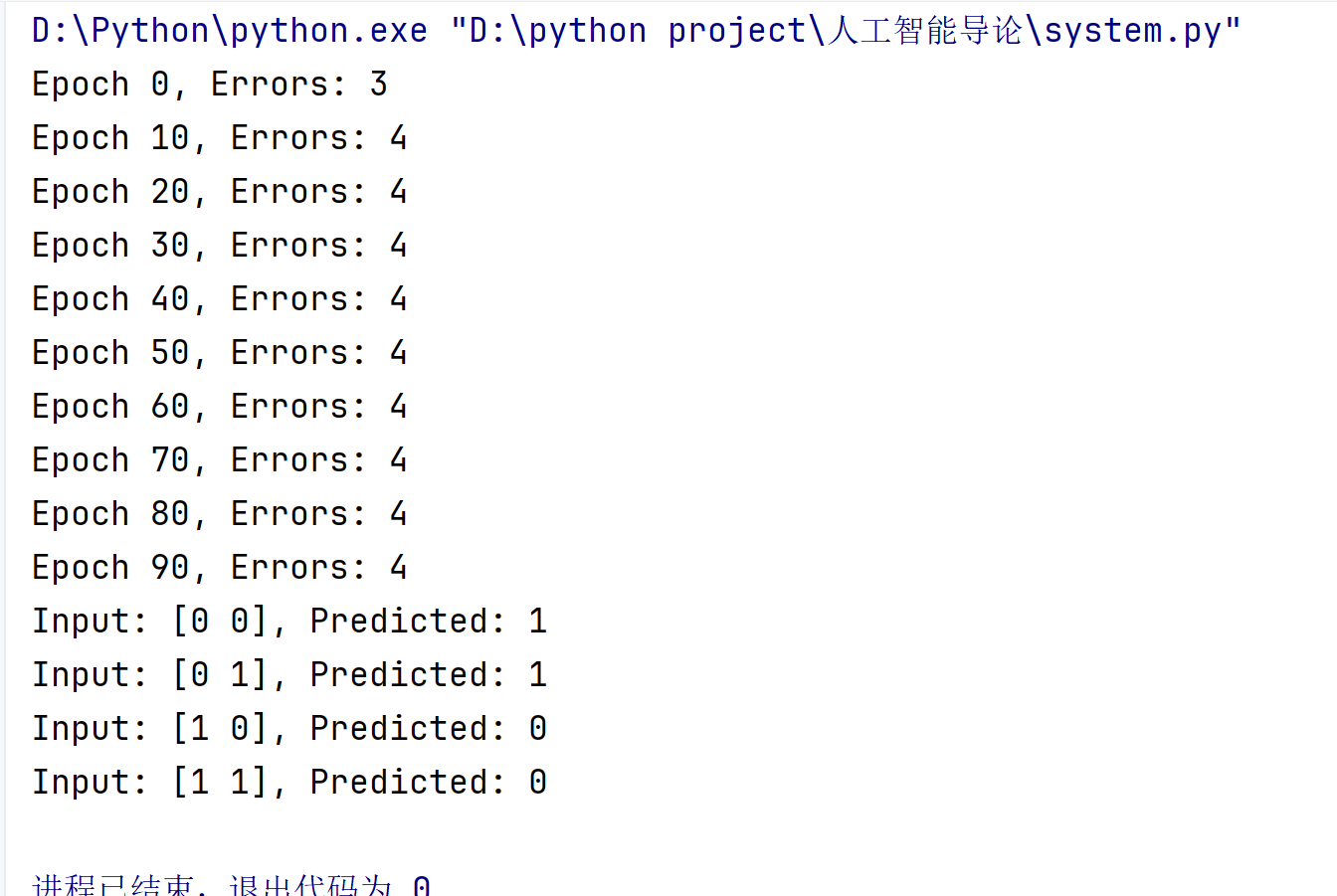
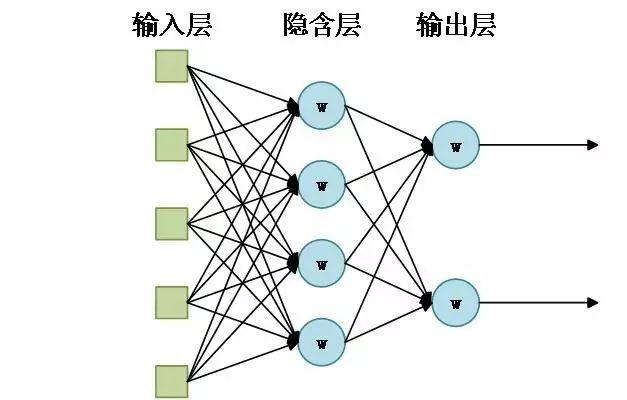
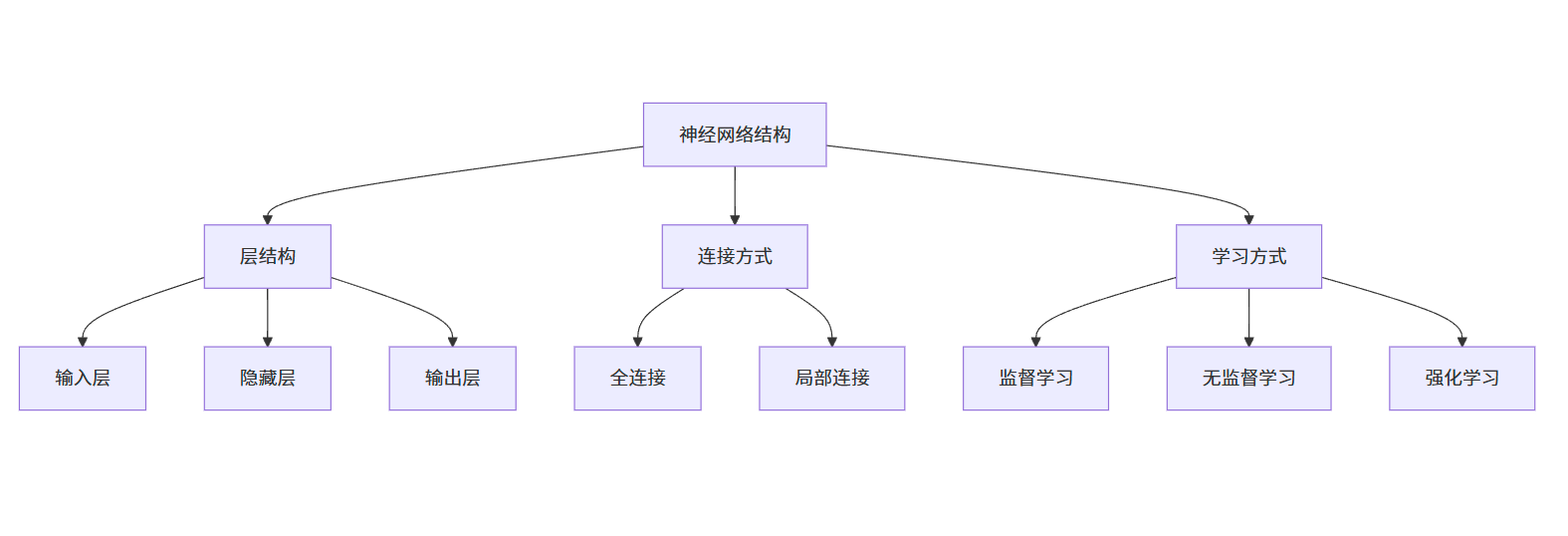
8.1.3 神经网络的结构与工作方式
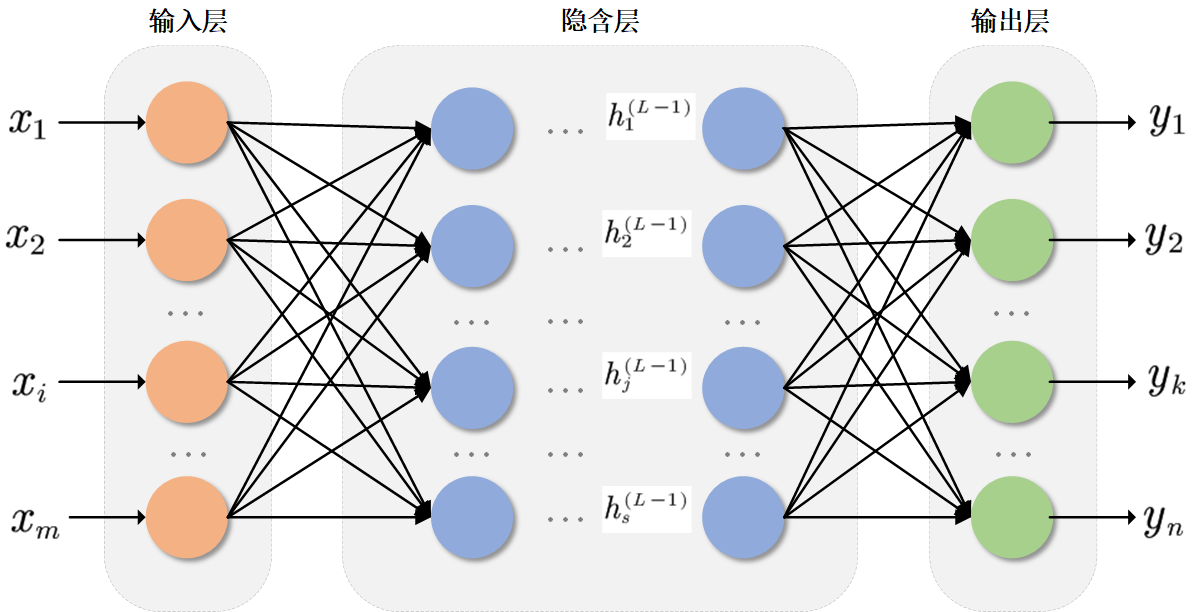
神经网络由输入层、隐藏层和输出层组成,层与层之间通过权重连接。工作方式包括前向传播和反向传播。
8.1.4 神经网络的学习
神经网络的学习过程主要是调整权重和偏置,使网络输出与期望输出的误差最小。常用的学习算法有梯度下降法等。
神经网络结构思维导图:
二、BP 神经网络及其学习算法
8.2.1 BP 神经网络的结构
BP(反向传播)神经网络是一种多层前馈神经网络,其结构包括输入层、若干隐藏层和输出层,层内神经元无连接,层间全连接。
8.2.2 BP 学习算法
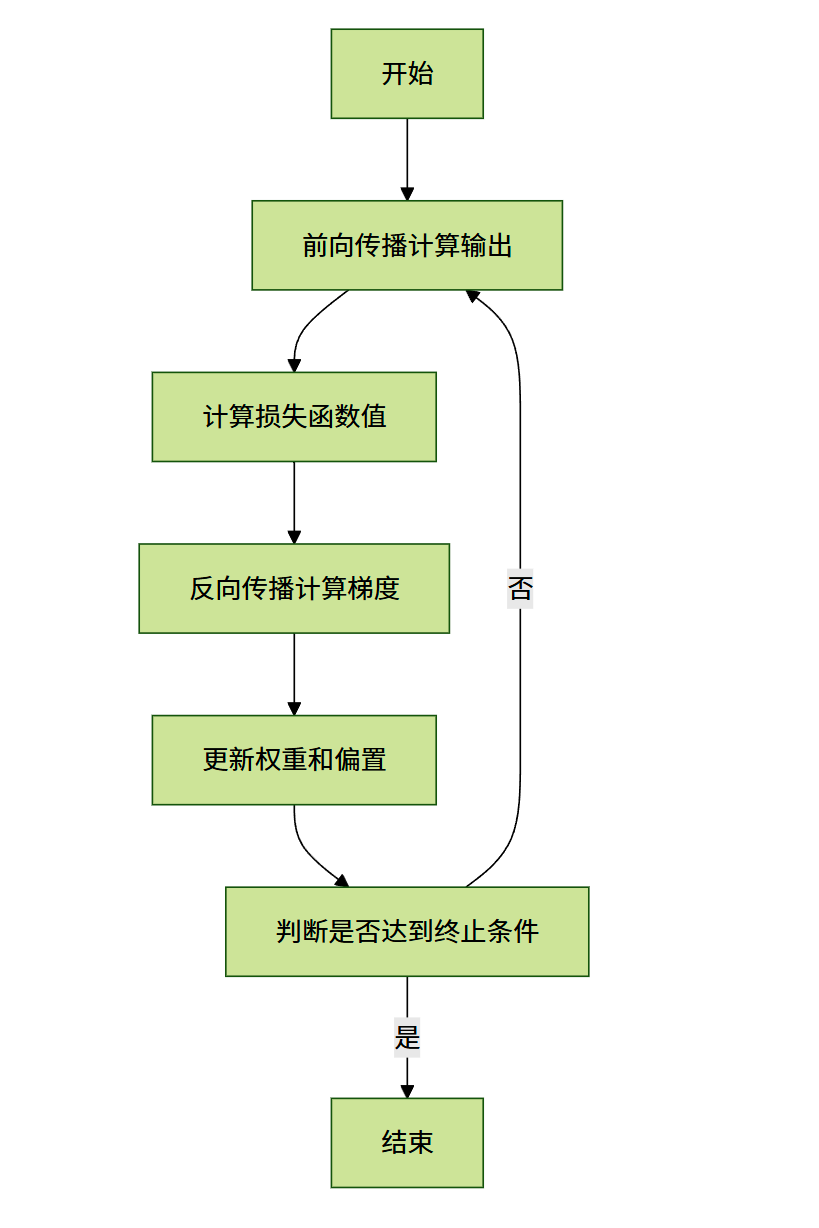
BP 算法的核心是将输出误差通过反向传播的方式,逐层调整权重和偏置,其过程包括前向传播计算误差、反向传播计算梯度、权重更新三个步骤。
8.2.3 BP 学习算法的实现
下面使用 PyTorch 实现一个简单的 BP 神经网络,用于手写数字识别:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# 设置Matplotlib后端为兼容模式
plt.switch_backend('agg') # 或使用 'TkAgg'、'Qt5Agg' 等
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST数据集
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义BP神经网络模型
class BPNeuralNetwork(nn.Module):
def __init__(self):
super(BPNeuralNetwork, self).__init__()
# 定义网络层
self.flatten = nn.Flatten() # 展平输入图像
# 第一个全连接层:784个输入特征,256个输出特征
self.linear1 = nn.Linear(28 * 28, 256)
# 第二个全连接层:256个输入特征,128个输出特征
self.linear2 = nn.Linear(256, 128)
# 输出层:128个输入特征,10个数字类别
self.linear3 = nn.Linear(128, 10)
# ReLU激活函数
self.relu = nn.ReLU()
def forward(self, x):
"""前向传播"""
x = self.flatten(x)
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.linear3(x)
return x
# 确定训练设备:优先使用GPU,否则使用CPU
def get_training_device(preferred_device='cuda'):
"""
获取训练设备,支持指定首选设备
preferred_device: 'cuda' 或 'cpu'
"""
if preferred_device == 'cuda' and torch.cuda.is_available():
device = torch.device('cuda')
print(f"使用GPU训练,设备名称: {torch.cuda.get_device_name(0)}")
print(f"GPU内存情况: {torch.cuda.get_device_properties(0).total_memory / (1024**3):.2f} GB")
else:
device = torch.device('cpu')
print("使用CPU训练")
return device
# 创建模型实例
model = BPNeuralNetwork()
# 定义损失函数:交叉熵损失
criterion = nn.CrossEntropyLoss()
# 定义优化器:随机梯度下降
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 获取训练设备(可修改'cuda'为'cpu'强制使用CPU)
device = get_training_device('cuda')
# 将模型移至指定设备
model = model.to(device)
# 训练模型
def train(model, device, train_loader, optimizer, epoch):
model.train() # 设置模型为训练模式
losses = []
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model(data)
# 计算损失
loss = criterion(output, target)
losses.append(loss.item())
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
# 打印训练进度
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} '
f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
return losses
# 测试模型
def test(model, device, test_loader):
model.eval() # 设置模型为评估模式
test_loss = 0
correct = 0
with torch.no_grad(): # 不计算梯度,节省内存
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 累加批次损失
test_loss += criterion(output, target).item()
# 获取最大概率的类别
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader) # 平均损失
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} '
f'({100. * correct / len(test_loader.dataset):.2f}%)\n')
return test_loss, correct / len(test_loader.dataset)
# 训练过程
epochs = 5
train_losses = []
test_losses = []
test_accuracies = []
for epoch in range(1, epochs + 1):
epoch_losses = train(model, device, train_loader, optimizer, epoch)
train_losses.extend(epoch_losses)
test_loss, test_acc = test(model, device, test_loader)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(range(0, len(train_losses), len(train_loader)), test_losses, label='Test Loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('Training and Testing Loss')
plt.legend()
# 绘制准确率曲线
plt.subplot(1, 2, 2)
plt.plot(test_accuracies)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Testing Accuracy')
plt.tight_layout()
plt.savefig('bp_network_results.png')
plt.show()
# 保存模型
torch.save(model.state_dict(), 'bp_mnist_model.pth')
print("模型已保存至 bp_mnist_model.pth")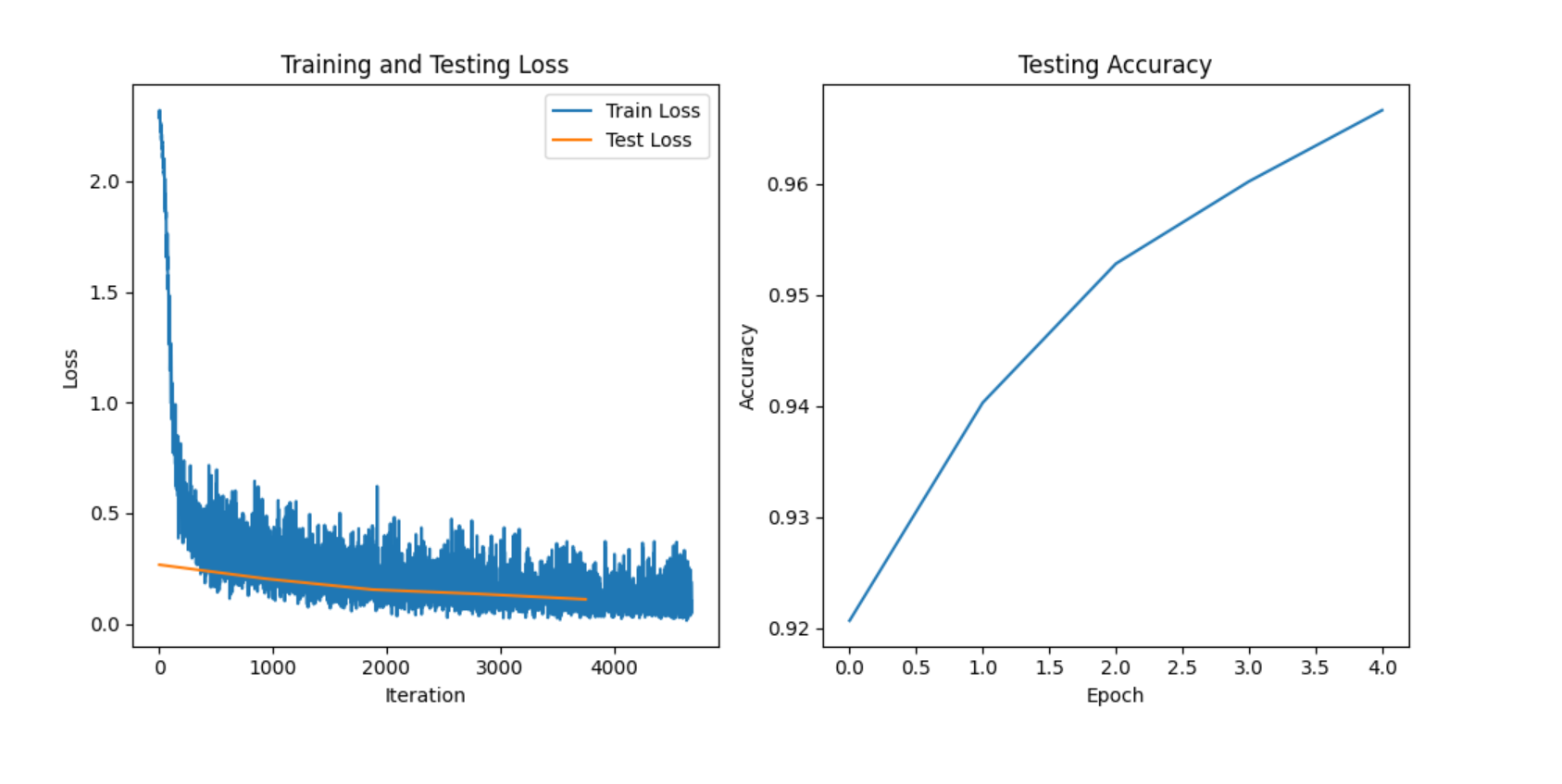
BP 算法流程图:
以下是如何加载并使用训练好的模型进行预测的代码:
import torch
import torch.nn as nn
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# 设置Matplotlib后端和字体
plt.switch_backend('agg') # 解决后端兼容性问题
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 正确显示负号
# 定义BP神经网络模型(与训练时相同)
class BPNeuralNetwork(nn.Module):
def __init__(self):
super(BPNeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(28 * 28, 256)
self.linear2 = nn.Linear(256, 128)
self.linear3 = nn.Linear(128, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.linear3(x)
return x
# 数据预处理(与训练时相同)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载测试数据集
test_dataset = datasets.MNIST('data', train=False, transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=True)
# 创建模型实例并加载权重
model = BPNeuralNetwork()
model.load_state_dict(torch.load('bp_mnist_model.pth'))
model.eval() # 设置为评估模式
# 随机选择一个样本进行预测
def predict_random_sample():
# 从测试集中随机获取一个样本
data, target = next(iter(test_loader))
# 进行预测
with torch.no_grad():
output = model(data)
predicted = output.argmax(dim=1, keepdim=True)
# 显示原始图像和预测结果
plt.figure(figsize=(4, 4))
plt.imshow(data[0][0], cmap='gray')
plt.title(f'真实标签: {target[0]}, 预测: {predicted[0][0]}')
plt.axis('off')
plt.savefig('prediction_example.png')
# plt.show() # 注释掉show,仅保存图像
print(f"预测完成,图像已保存至 prediction_example.png")
# 进行预测
predict_random_sample()
三、BP 神经网络在模式识别中的应用
BP 神经网络在模式识别中广泛应用于图像识别、语音识别等领域。上面的 MNIST 手写数字识别案例就是一个典型的模式识别应用。通过训练 BP 神经网络,可以准确识别手写数字图像。
图 1:BP 神经网络训练过程损失与准确率曲线
四、Hopfield 神经网络及其改进
8.4.1 离散型 Hopfield 神经网络
离散型 Hopfield 网络是一种递归神经网络,神经元输出为二进制值(0 或 1),网络状态由权重矩阵决定,通过迭代更新直至稳定。
8.4.2 连续型 Hopfield 神经网络及其 VLSI 实现
连续型 Hopfield 网络神经元输出为连续值,常用于优化问题求解,其 VLSI 实现可提高计算效率。
8.4.3 随机神经网络
随机神经网络引入概率机制,如 Boltzmann 机,通过模拟退火算法寻找最优解。
下面实现一个离散型 Hopfield 神经网络,用于联想记忆:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
class DiscreteHopfieldNetwork:
def __init__(self):
"""初始化离散型Hopfield神经网络"""
self.weights = None
self.num_neurons = 0
def activation(self, x):
"""符号激活函数"""
return 1 if x >= 0 else -1
def train(self, patterns):
"""训练Hopfield网络,使用Hebbian学习规则"""
# 获取模式数量和每个模式的神经元数量
num_patterns, self.num_neurons = patterns.shape
# 初始化权重矩阵为零矩阵
self.weights = np.zeros((self.num_neurons, self.num_neurons))
# Hebbian学习规则:权重矩阵等于所有模式的外积和
for pattern in patterns:
self.weights += np.outer(pattern, pattern)
# 确保对角线元素为零(神经元不与自身连接)
np.fill_diagonal(self.weights, 0)
# 权重矩阵除以模式数量进行归一化
self.weights /= num_patterns
def recall(self, input_pattern, max_iterations=100):
"""联想记忆,恢复完整模式"""
# 复制输入模式,避免修改原始数据
current_pattern = input_pattern.copy()
# 迭代更新直至网络稳定或达到最大迭代次数
for _ in range(max_iterations):
old_pattern = current_pattern.copy()
# 随机选择一个神经元进行更新
idx = np.random.randint(0, self.num_neurons)
# 计算该神经元的输入
activation = np.dot(self.weights[idx], current_pattern)
# 应用激活函数
current_pattern[idx] = self.activation(activation)
# 检查是否稳定(所有神经元状态不再变化)
if np.array_equal(old_pattern, current_pattern):
break
return current_pattern
def energy(self, pattern):
"""计算网络能量"""
return -0.5 * np.dot(np.dot(pattern, self.weights), pattern)
# 测试Hopfield网络 - 使用简单的二值图像
def test_simple_images():
# 创建简单的二值图像(14x14,这里展平为196维向量)
# 定义三个模式:数字1、2、3的简单表示
pattern1 = np.ones(196) * -1
pattern1[42:56] = 1 # 数字1的竖线
pattern1[70:84] = 1
pattern1[98:112] = 1
pattern2 = np.ones(196) * -1
pattern2[0:14] = 1 # 数字2的上横线
pattern2[14:28] = 1
pattern2[28:42] = 1
pattern2[42:56] = 1
pattern2[56:70] = 1
pattern2[70:84] = -1
pattern2[84:98] = 1
pattern2[98:112] = 1
pattern2[112:126] = 1
pattern2[126:140] = 1
pattern2[140:154] = 1
pattern3 = np.ones(196) * -1
pattern3[0:14] = 1 # 数字3的上横线
pattern3[14:28] = 1
pattern3[28:42] = 1
pattern3[42:56] = 1
pattern3[56:70] = 1
pattern3[70:84] = 1
pattern3[84:98] = -1
pattern3[98:112] = 1
pattern3[112:126] = 1
pattern3[126:140] = 1
pattern3[140:154] = 1
pattern3[154:168] = 1
pattern3[168:182] = 1
pattern3[182:196] = 1
# 转换为-1和1的模式
patterns = np.array([pattern1, pattern2, pattern3])
# 创建并训练Hopfield网络
hopfield = DiscreteHopfieldNetwork()
hopfield.train(patterns)
# 测试联想记忆 - 给数字1添加噪声
noisy_pattern1 = pattern1.copy()
# 随机翻转20%的位
flip_indices = np.random.choice(196, size=int(196 * 0.2), replace=False)
noisy_pattern1[flip_indices] *= -1
# 恢复模式
recovered_pattern1 = hopfield.recall(noisy_pattern1)
# 可视化原始模式、噪声模式和恢复模式
plt.figure(figsize=(12, 4))
plt.subplot(131)
plt.title('Original Pattern 1')
plt.imshow(pattern1.reshape(14, 14), cmap='binary')
plt.axis('off')
plt.subplot(132)
plt.title('Noisy Pattern 1')
plt.imshow(noisy_pattern1.reshape(14, 14), cmap='binary')
plt.axis('off')
plt.subplot(133)
plt.title('Recovered Pattern 1')
plt.imshow(recovered_pattern1.reshape(14, 14), cmap='binary')
plt.axis('off')
plt.tight_layout()
plt.savefig('hopfield_simple_images.png')
plt.show()
if __name__ == "__main__":
test_simple_images()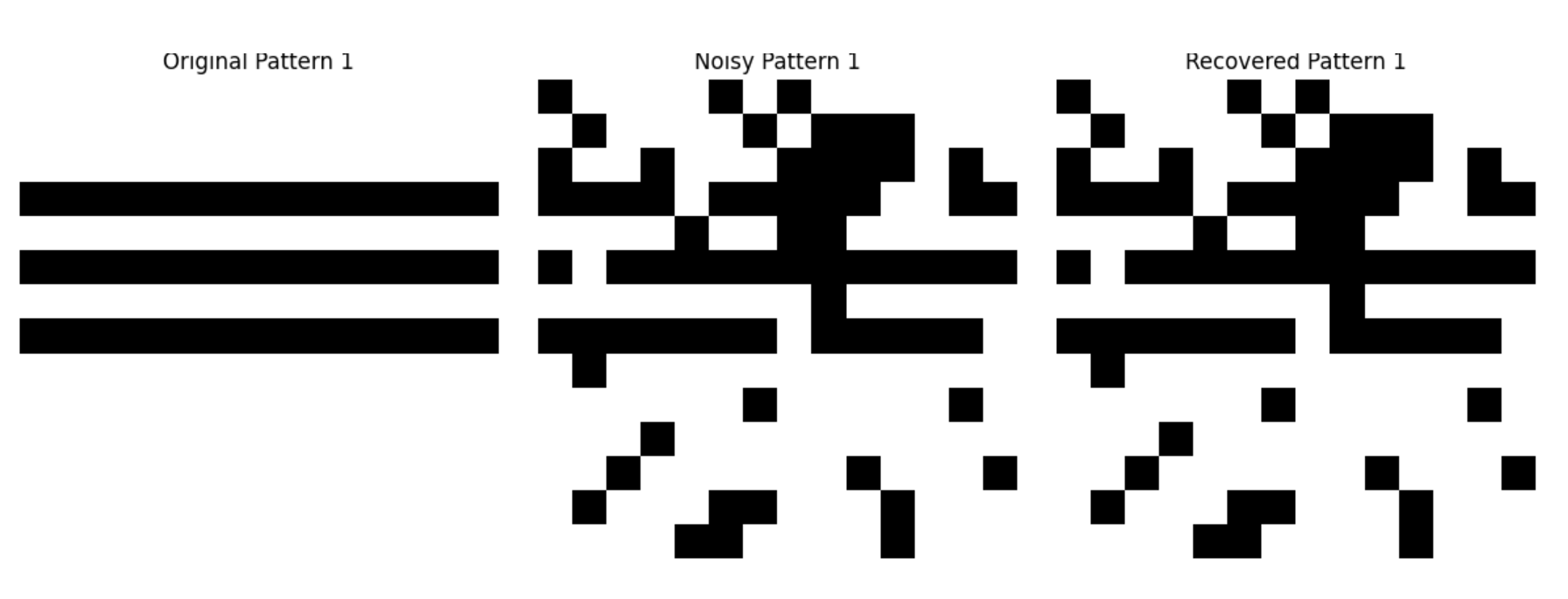
五、Hopfield 神经网络的应用
8.5.1 Hopfield 神经网络在联想记忆中的应用
Hopfield 网络可以用于联想记忆,如上面的案例所示,即使输入带有噪声的不完整模式,也能恢复出完整的模式。
8.5.2 Hopfield 神经网络优化方法
Hopfield 网络可用于解决优化问题,如旅行商问题(TSP),通过构造合适的能量函数,找到最优路径。
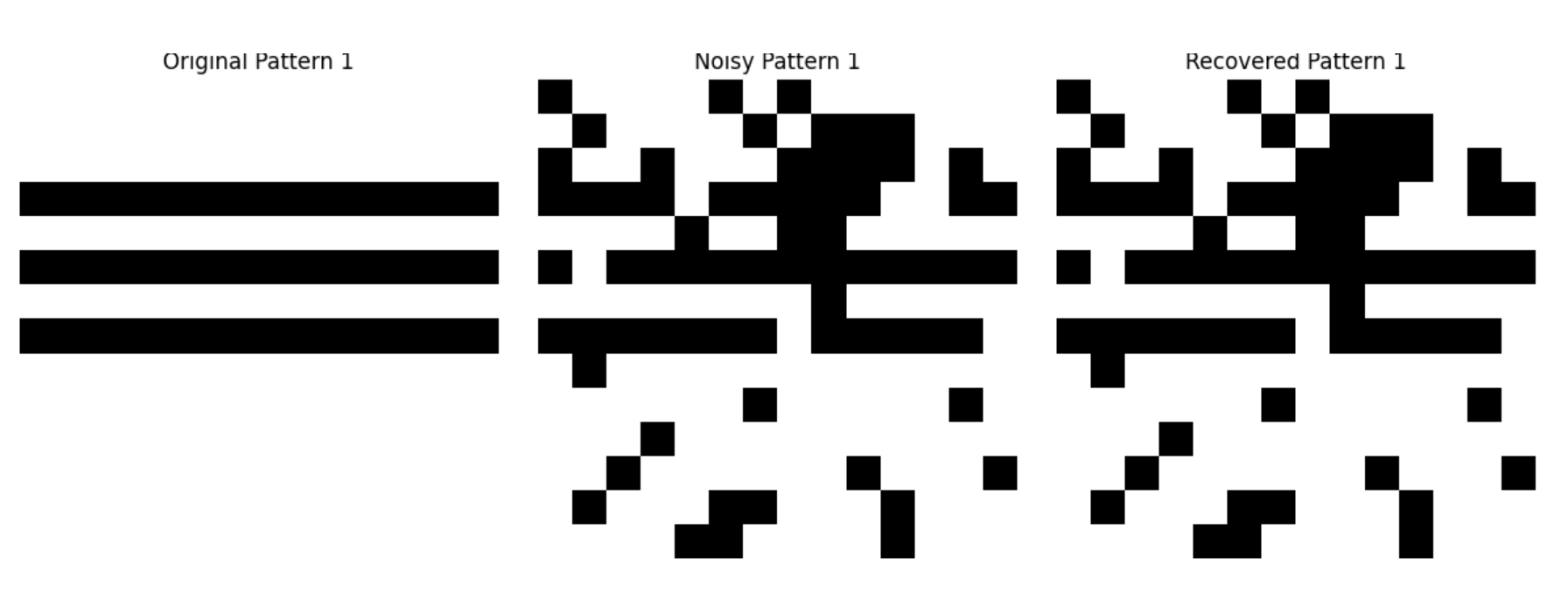
图 2:Hopfield 网络联想记忆结果
六、卷积神经网络与深度学习
8.6.1 卷积神经网络的结构与学习
卷积神经网络 (CNN) 是深度学习的重要模型,其结构包括卷积层、池化层、全连接层等,通过局部连接和权值共享减少参数数量。
8.6.2 卷积神经网络的卷积运算
卷积运算是 CNN 的核心操作,通过卷积核与输入特征图的滑动窗口运算,提取局部特征。
8.6.3 卷积神经网络中的关键技术
关键技术包括池化操作、批量归一化、Dropout、迁移学习等。
下面实现一个简单的 CNN 用于 CIFAR-10 图像分类:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
# 数据预处理
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10('data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10('data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 第一个卷积块:卷积层 + ReLU + 池化
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2)
# 第二个卷积块:卷积层 + ReLU + 池化
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2)
# 全连接层
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, 10) # 10个类别
def forward(self, x):
"""前向传播"""
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8) # 展平特征图
x = self.relu3(self.fc1(x))
x = self.fc2(x)
return x
# 创建模型实例
model = CNN()
# 定义损失函数:交叉熵损失
criterion = nn.CrossEntropyLoss()
# 定义优化器:Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 确定训练设备(CPU或GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 将模型移至指定设备
model = model.to(device)
# 训练模型
def train(model, device, train_loader, optimizer, epoch):
model.train() # 设置模型为训练模式
losses = []
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model(data)
# 计算损失
loss = criterion(output, target)
losses.append(loss.item())
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
# 打印训练进度
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} '
f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
return losses
# 评估模型(重命名为evaluate而非test)
def evaluate(model, device, test_loader):
model.eval() # 设置模型为评估模式
test_loss = 0
correct = 0
with torch.no_grad(): # 不计算梯度,节省内存
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 累加批次损失
test_loss += criterion(output, target).item()
# 获取最大概率的类别
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader) # 平均损失
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} '
f'({100. * correct / len(test_loader.dataset):.2f}%)\n')
return test_loss, correct / len(test_loader.dataset)
# 训练过程
if __name__ == "__main__":
epochs = 5
train_losses = []
test_losses = []
test_accuracies = []
for epoch in range(1, epochs + 1):
epoch_losses = train(model, device, train_loader, optimizer, epoch)
train_losses.extend(epoch_losses)
test_loss, test_acc = evaluate(model, device, test_loader)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(range(0, len(train_losses), len(train_loader)), test_losses, label='Test Loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('Training and Testing Loss')
plt.legend()
# 绘制准确率曲线
plt.subplot(1, 2, 2)
plt.plot(test_accuracies)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Testing Accuracy')
plt.tight_layout()
plt.savefig('cnn_cifar10_results.png')
# plt.show() # 注释掉show,仅保存图像
# 保存模型
torch.save(model.state_dict(), 'cnn_cifar10_model.pth')
print("模型已保存至 cnn_cifar10_model.pth")
print("图像已保存至 cnn_cifar10_results.png")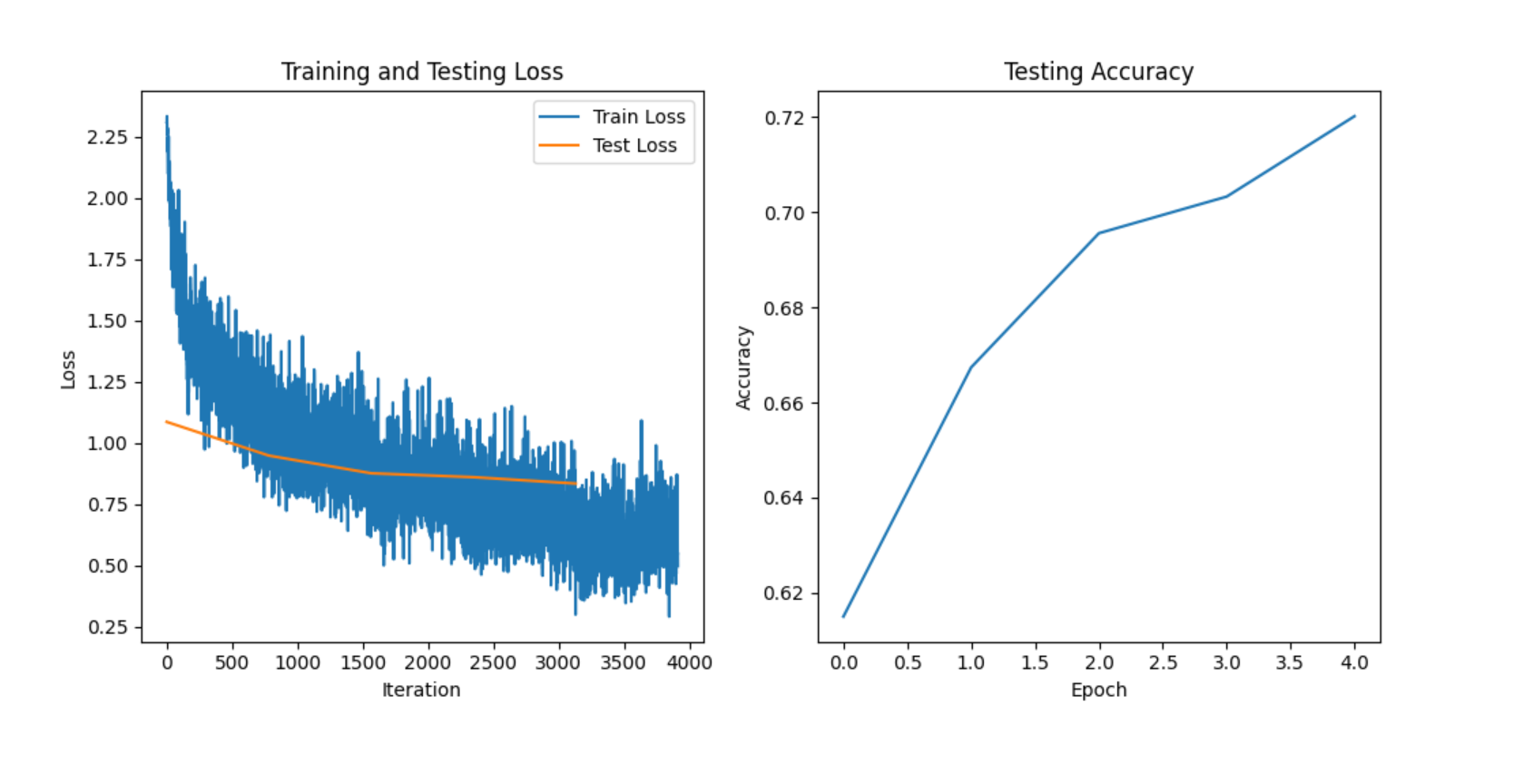
七、生成对抗网络及其应用
8.7.1 生成对抗网络的基本原理
生成对抗网络 (GAN) 由生成器和判别器组成,通过两者的对抗训练,使生成器能够生成逼真的样本。
8.7.2 生成对抗网络的结构与训练
GAN 的训练过程是一个极小极大博弈问题,生成器试图最小化判别器的准确率,判别器试图最大化准确率。
8.7.3 生成对抗网络的应用
GAN 在多个领域有广泛应用,包括图像生成、博弈、图像处理、语言处理、视频生成和医疗等。
下面实现一个简单的 GAN 用于生成 MNIST 数字图像:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, utils
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
# 确定训练设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载MNIST数据集
dataset = datasets.MNIST('data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=128, shuffle=True)
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
# 输入是噪声,进入第一层
nn.Linear(100, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 784), # 784 = 28*28
nn.Tanh()
)
def forward(self, input):
return self.main(input)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# 输入图像,进入第一层
nn.Linear(784, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input.view(-1, 784))
# 创建模型实例并移至设备
netG = Generator().to(device)
netD = Discriminator().to(device)
# 定义损失函数:二元交叉熵损失
criterion = nn.BCELoss()
# 优化器:生成器和判别器使用不同的优化器
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 固定噪声,用于可视化训练过程
fixed_noise = torch.randn(64, 100, device=device)
# 训练函数
def train_gan(netG, netD, dataloader, criterion, optimizerG, optimizerD, num_epochs=25):
# 记录训练过程
d_losses = []
g_losses = []
# 开始训练
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(dataloader):
############################
# (1) 更新判别器:最大化 log(D(x)) + log(1 - D(G(z)))
###########################
## 使用真实图像训练判别器
netD.zero_grad()
real_images = real_images.view(-1, 784).to(device)
batch_size = real_images.size(0)
label = torch.full((batch_size,), 1.0, device=device).view(-1, 1) # 真实图像标签为1,形状[batch_size, 1]
output = netD(real_images)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
## 使用生成图像训练判别器
noise = torch.randn(batch_size, 100, device=device)
fake = netG(noise)
label.fill_(0.0) # 生成图像标签为0
output = netD(fake.detach()) # 不计算生成器梯度
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
optimizerD.step()
############################
# (2) 更新生成器:最大化 log(D(G(z)))
###########################
netG.zero_grad()
label.fill_(1.0) # 生成图像标签为1(欺骗判别器)
output = netD(fake)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
# 打印训练进度
if i % 50 == 0:
print(f'[{epoch + 1}/{num_epochs}][{i}/{len(dataloader)}] '
f'Loss_D: {errD.item():.4f} Loss_G: {errG.item():.4f} '
f'D(x): {D_x:.4f} D(G(z)): {D_G_z1:.4f}/{D_G_z2:.4f}')
# 记录 epoch 损失
d_losses.append(errD.item())
g_losses.append(errG.item())
# 每个 epoch 结束后,生成并保存图像
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title(f"生成图像 - Epoch {epoch + 1}")
plt.imshow(np.transpose(viz_images(fake), (1, 2, 0)))
plt.savefig(f"gan_generated_epoch_{epoch + 1}.png")
plt.close()
return d_losses, g_losses
# 可视化生成的图像
def viz_images(images, nrow=8):
"""将图像张量转换为可可视化的格式"""
images = (images + 1) / 2 # 从[-1,1]反归一化到[0,1]
grid = utils.make_grid(images.view(-1, 1, 28, 28), nrow=nrow)
return grid.numpy()
# 开始训练
d_losses, g_losses = train_gan(
netG, netD, dataloader, criterion, optimizerG, optimizerD, num_epochs=10
)
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.plot(d_losses, label='Discriminator Loss')
plt.plot(g_losses, label='Generator Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('GAN Training Losses')
plt.legend()
plt.savefig('gan_losses.png')
# plt.show() # 注释掉,避免显示错误
# 保存模型
torch.save(netG.state_dict(), 'gan_generator.pth')
torch.save(netD.state_dict(), 'gan_discriminator.pth')
print("模型已保存")
print("生成的图像已保存为 gan_generated_epoch_*.png")
print("损失曲线已保存为 gan_losses.png")

图 :GAN 生成图像结果(Epoch 10)
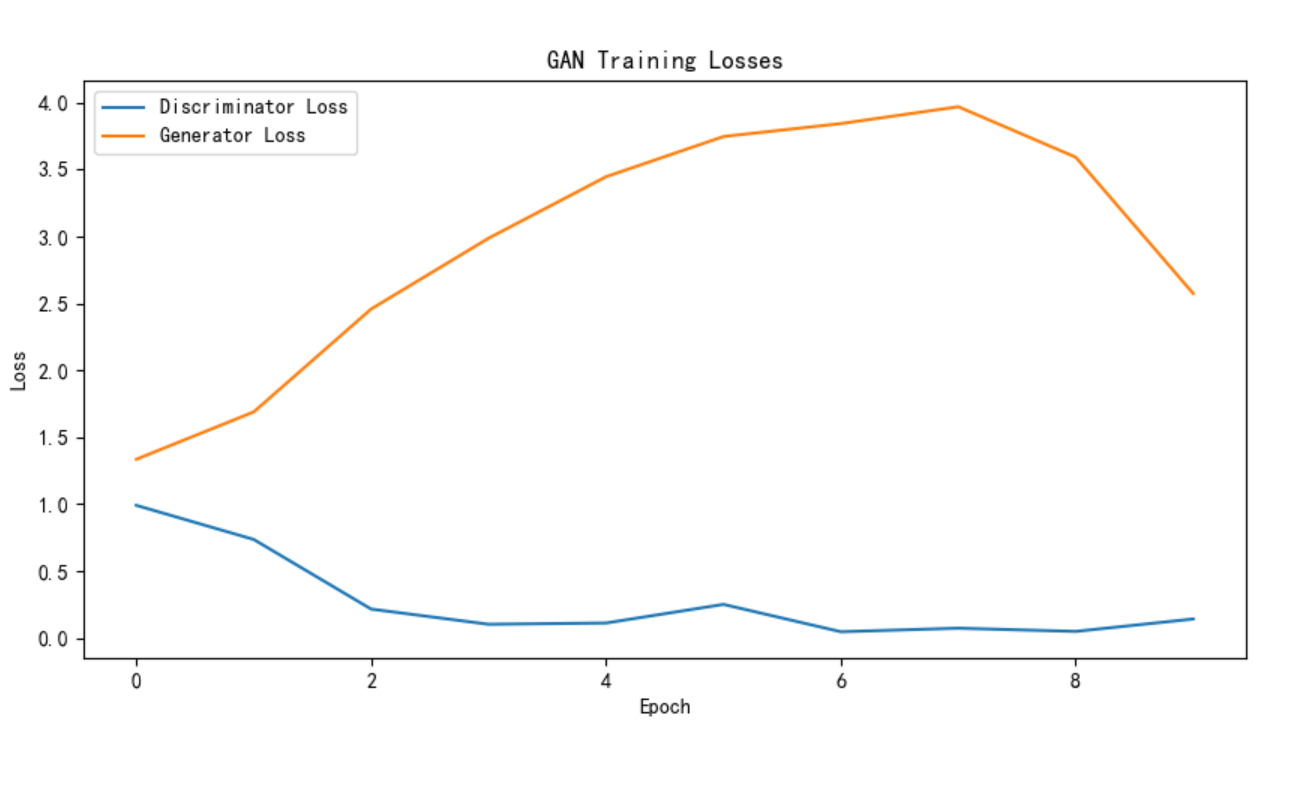
图 :GAN 训练损失曲线
八、小结
本章详细介绍了人工神经网络的基本概念、BP 神经网络、Hopfield 神经网络、卷积神经网络和生成对抗网络及其应用。通过理论讲解和代码实现,展示了神经网络在模式识别、联想记忆、图像分类和图像生成等领域的应用。
神经网络作为人工智能的重要分支,其发展迅速,应用广泛。从简单的感知机到复杂的生成对抗网络,神经网络的结构和算法不断创新,为解决各种实际问题提供了强大的工具。未来,随着深度学习的不断发展,神经网络在更多领域将发挥重要作用。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号