2026了,为什么高手还在钻研 Llama 3.1?

2026了,为什么高手还在钻研 Llama 3.1?

CloudStudio
发布于 2026-01-14 16:45:13
发布于 2026-01-14 16:45:13
答案是肯定的,而且非常有必要。
就像学习操作系统绕不开 Linux 内核,学习深度学习绕不开 ResNet 一样,Llama 3.1 时代所确立的 SFT(监督微调)、DPO(直接偏好优化)、MoE(混合专家)以及 GGUF 量化标准,至今仍是 LLM 工程师的底层“内功”。

这门课程(点击直达)不是带你追逐虚无缥缈的热点,而是带你拆解大模型工业化落地的标准范式。
为什么“旧”模型是最好的老师?
在 2026 年的今天,学习这门课的价值在于 “透视本质”:
1. 掌握 LLM 调优的“标准方程”
现在的模型自动化程度虽然高,但黑盒化也越来越严重。
- • Unsloth 与 Llama 3.1: Unsloth 当年对梯度检查点和显存的极致优化,是理解如今高效训练框架的基石。
- • ORPO 与 DPO: 现在的对齐算法大多是 DPO 的变体。通过 Mistral 实战 DPO,你才能真正看懂现在的模型是如何学会“说人话”的。
2. 只有懂量化,才能做部署
现在的端侧 AI 已经普及,但其核心技术依然源于当年的 GPTQ 和 GGUF。
- • 课程深入讲解的 4-bit 量化 和 ExLlamaV2 推理库,是任何想做 Edge AI(边缘智能)开发的工程师必须掌握的“物理定律”。
3. 经典的 MoE 架构构建
MoE 如今已是巨型模型的标配。通过 MergeKit 手动通过“弗兰肯斯坦式”拼接构建一个 MoE 模型,能让你比任何人都清楚 Sparse Attention(稀疏注意力)是如何工作的。
2026 年,CloudStudio 才是学习这门课的“唯一解”
作为资深开发者,你应该深有体会:跑通两年前的代码,比写新代码更难。
随着 Python 版本迭代、CUDA 升级、PyTorch 废弃旧接口,想在 2026 年的本地电脑上完美复现 Llama 3 时代的 Unsloth 环境,简直是 “依赖地狱”。
这就是我们需要 CloudStudio 的核心理由:
1. 穿越时空的“环境胶囊”
CloudStudio 基于容器化技术。在课程创建时就已经把所有的环境系统都适配成功,所以CloudStudio 都能为你一键拉起适配 Llama 3.1 和 Unsloth 旧版本的特定运行环境。
- • 无需降级: 你不需要为了学个课程把本地的开发环境回滚到两年前。
- • 开箱即用: 那个时代的
requirements.txt,在这里依然能由系统自动完美解析并预置。

2. 极低成本体验“工业级微调”
CloudStudio 无需你购置昂贵硬件,用单卡 A800 可复现 13B 以内模型的微调实验。
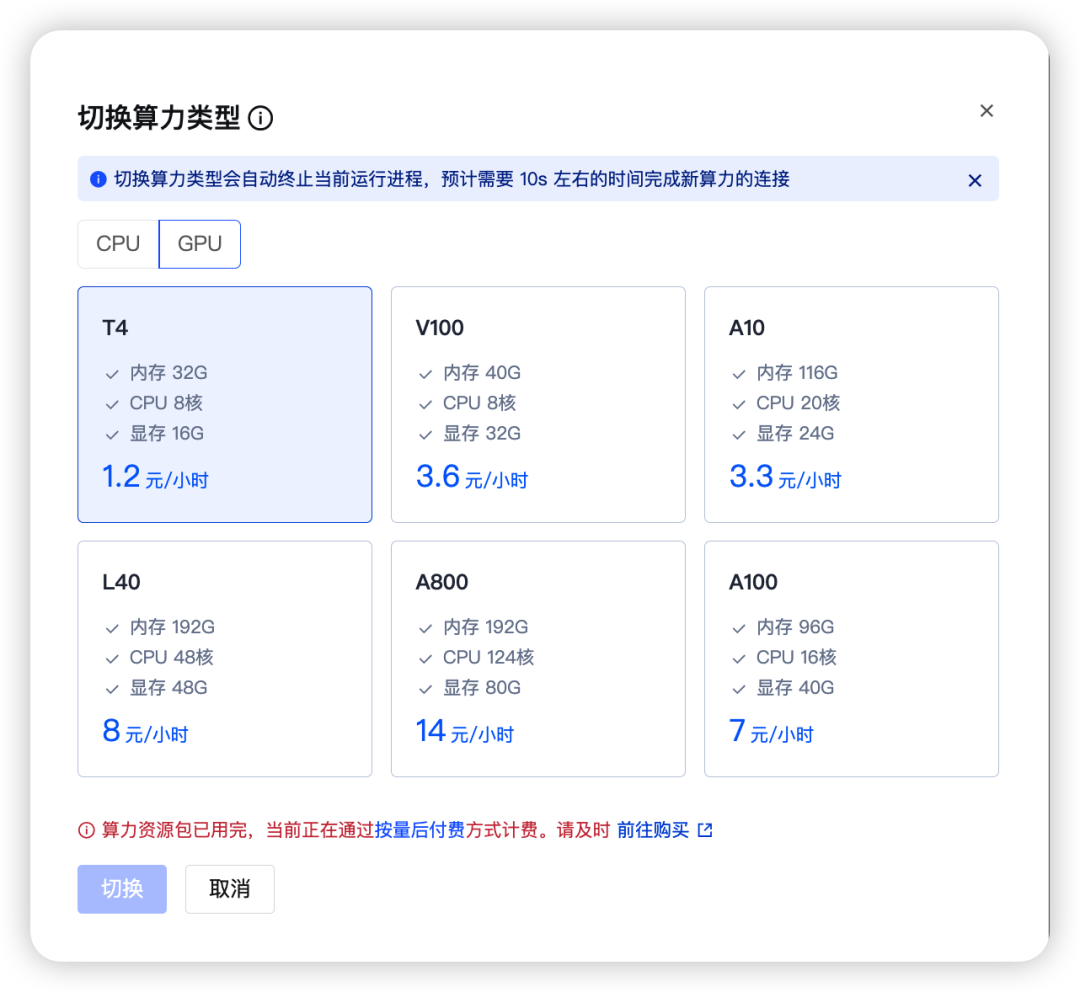
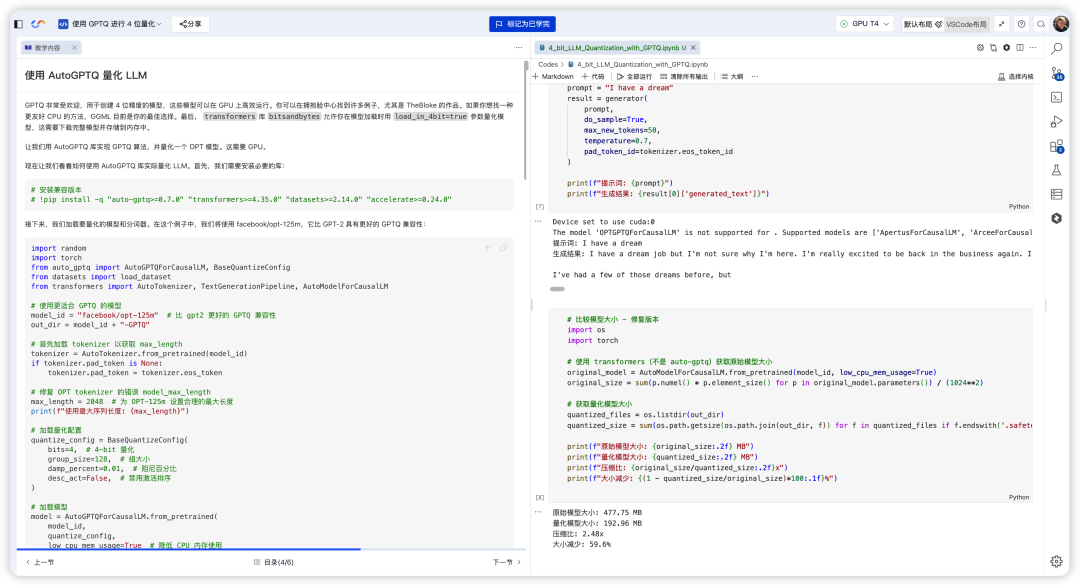
3. 真正的 IDE 体验
这不是简单的 Jupyter Notebook。CloudStudio 提供的是完整的 VS Code 风格体验。你可以像在本地一样调试那些经典的量化脚本,查看当年的代码逻辑,甚至利用现在的 Copilot 能力去重构老的代码,这种新旧结合的学习体验,只有云端 IDE 能给。
结语:以史为鉴,可知兴替
不要因为模型号变了,就忽略了技术的传承。
这门课程记录了开源大模型最辉煌的“寒武纪大爆发”时刻。通过 CloudStudio,你可以毫无阻碍地回到那个技术井喷的现场,亲手拆解那些定义了今天 AI 格局的技术基石。
如果你想成为一名知其然更知其所以然的 AI 架构师,而不是只会调 API 的“调包侠”,这门课是你的必修课。
👇 点击下方链接或者扫描下方二维码,立刻穿越回经典现场:
>> 点击此处,一键直达 Cloud Studio 课程页面 <<

关于 CloudStudio
CloudStudio 是 AI时代开发者的创客平台,也是围绕人工智能知识体系的教学内容实训平台。服务于百万开发者,与数百家高专院校与教育机构。 现在,登陆 CloudStudio 开始创作与学习吧!探索 AI时代的应用创作,汲取AI时代的知识,你会发现它远比想象中更精彩!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-06,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 腾讯云CloudStudio 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号