Ouro:预训练即推理的循环语言模型革命

Ouro:预训练即推理的循环语言模型革命

九日大大
发布于 2026-01-14 15:39:34
发布于 2026-01-14 15:39:34

引言:LLM 推理范式的颠覆者
在大语言模型(LLM)的发展历程中,推理能力的构建始终依赖于训练后的辅助策略 —— 从思维链(CoT)到工具增强,这些方法虽能提升任务表现,却存在固有缺陷:推理过程与预训练阶段脱节,导致参数效率低下、推理轨迹缺乏因果一致性。2025 年 11 月,字节跳动 Seed 团队联合加州大学、北京大学等顶尖机构,推出了循环语言模型(Looped Language Models, LoopLM)系列 Ouro,其名源于象征循环与自我迭代的衔尾蛇(Ouroboros),首次将推理能力直接嵌入预训练过程,通过潜在空间迭代计算、熵正则化目标和 7.7T tokens 的超大规模训练,实现了 2-3 倍的参数效率提升,为 LLM 的发展开辟了全新路径。
本文将全面解析 Ouro 模型的技术创新、架构设计、训练流程与性能表现,并提供完整的代码实现示例,助力开发者快速上手这一突破性模型。
一、技术背景:循环架构为何能颠覆 Transformer?
1.1 传统 LLM 的推理困境
当前主流 Transformer 架构存在两大核心局限:
- 计算与参数强绑定:模型能力提升高度依赖参数量扩张,导致训练与推理成本呈指数级增长;
- 推理过程后置化:预训练阶段仅学习语言建模目标,推理能力需通过微调或提示工程额外注入,造成能力与效率的割裂。
标准 RNN 虽具备循环特性,但梯度消失问题使其无法捕捉长程依赖,而 LSTM/GRU 的门控机制虽缓解了该问题,却仍未解决推理与预训练的融合问题。Ouro 的 LoopLM 架构创造性地将 Transformer 的并行计算优势与循环结构的动态推理能力相结合,实现了计算深度与参数规模的解耦。
1.2 循环语言模型的核心优势
LoopLM 架构的革命性在于三点核心突破:
- 参数共享的循环计算:通过固定层堆栈的多次迭代,用有限参数实现深度计算;
- 自适应退出机制:根据输入复杂度动态调整循环步数,平衡效率与性能;
- 潜在空间推理:在隐藏状态层面构建推理轨迹,避免 CoT 的事后合理化问题。
如图 1 所示,Ouro 的循环架构与传统 Transformer 的核心差异在于计算模式的重构 —— 将 "静态层堆叠" 转化为 "动态循环迭代"。
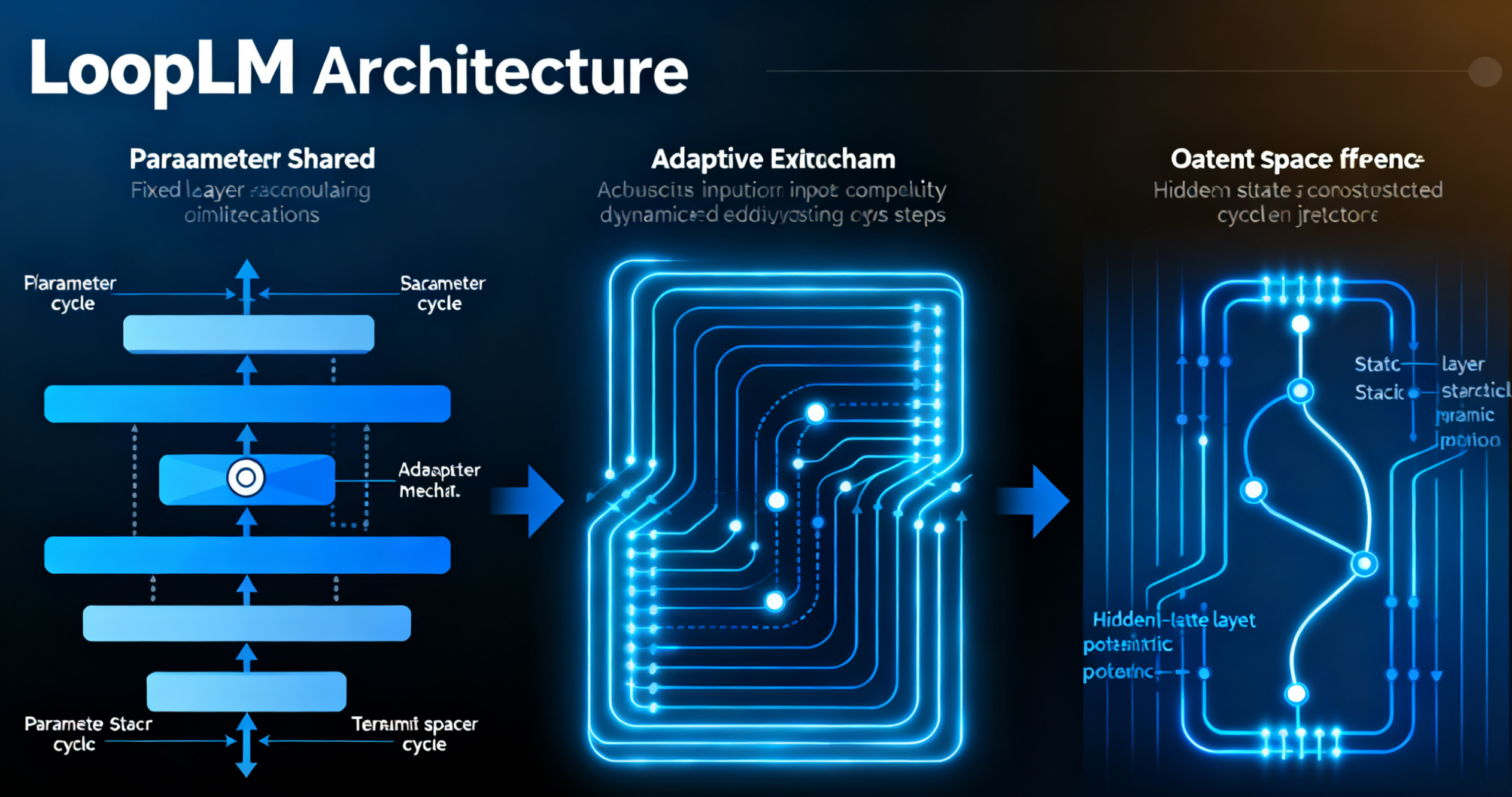
图 1:左为传统 Transformer 架构,右为 Ouro 的 LoopLM 架构,展示了循环迭代与参数共享机制
二、Ouro 模型核心技术解析
2.1 LoopLM 架构设计
Ouro 的架构核心是 "共享层堆栈 + 循环机制" 的组合,其数学定义如下:
2.1.1 循环计算单元
给定输入序列 \( X = [x_1, x_2, ..., x_T] \),模型首先通过嵌入层转换为向量表示 \( E = [e_1, e_2, ..., e_T] \)。循环计算单元由 N 个共享权重的 Transformer 层组成,在每个循环步 \( r \) 中,隐藏状态更新公式为:\( H_r = \text{SharedTransformer}(H_{r-1}, E) \)
其中 \( H_0 = E \) 为初始隐藏状态,\( r \in [1, R] \)(\( R \) 为最大循环步数)。
2.1.2 自适应退出门
为实现动态计算,Ouro 引入学习型退出门,在每个循环步 \( r \) 预测退出概率 \( p_r \):\( p_r = \sigma(W_o \cdot \text{avg}(H_r) + b_o) \)
其中 \( \sigma \) 为 sigmoid 激活函数,\( \text{avg}(H_r) \) 为当前隐藏状态的全局平均池化结果。模型通过熵正则化目标 \( H(p_1, ..., p_R) \) 鼓励合理的退出策略,简单输入提前退出以节省算力,复杂输入则进行多步迭代。
2.1.3 训练目标函数
Ouro 的训练目标融合了多循环步的语言建模损失与熵正则化项:\( \mathcal{L} = \mathbb{E}_{r \sim p}[\mathcal{L}_{\text{LM}}(H_r)] + \lambda \cdot H(p_1, ..., p_R) \)
其中 \( \mathcal{L}_{\text{LM}} \) 为标准交叉熵语言建模损失,\( \lambda \) 为正则化系数,通过该目标,模型同时学习语言表征与推理深度分配。
2.2 七阶段训练流程
Ouro 的训练过程分为七个阶段,总计使用 7.7T tokens 的多元化数据(涵盖网络文本、数学公式、代码和长文档),具体流程如下:
训练阶段 | 数据量 | 核心目标 |
|---|---|---|
预热阶段 | 200B tokens | 初始化参数,稳定训练过程 |
初始稳定训练 | 3T tokens | 构建基础语言理解能力 |
第二次稳定训练 | 3T tokens | 强化循环迭代能力 |
CT 退火 | 1.4T tokens | 优化退出门策略 |
LongCT 训练 | 20B tokens | 提升长上下文处理能力 |
中途训练 | 300B tokens | 微调模型整体一致性 |
推理监督微调 | 180B tokens | 增强特定推理任务表现 |
值得注意的是,团队在训练初期发现 8 个循环步会导致损失尖峰,最终选择 4 个循环步作为默认配置,在计算深度与训练稳定性之间取得平衡。
2.3 模型变体与规格
Ouro 当前发布两个基础模型和对应的推理增强版本:
模型名称 | 参数量 | 循环步数 | 核心特性 |
|---|---|---|---|
Ouro-1.4B | 14 亿 | 4 | 通用基础模型,参数效率最优 |
Ouro-2.6B | 26 亿 | 4 | 平衡性能与效率,支持长上下文 |
Ouro-1.4B-Thinking | 14 亿 | 4 | 推理增强版,优化数学 / 科学任务 |
Ouro-2.6B-Thinking | 26 亿 | 4 | 旗舰推理模型,支持复杂多步推理 |
所有模型均开源于 Hugging Face Hub,支持 PyTorch 和 TensorFlow 框架调用。
三、性能评测:参数效率的革命性提升
3.1 基准测试设置
测试数据集涵盖六大核心任务:
- 通用知识:MMLU、C-Eval
- 推理能力:BBH、GSM8K
- 数学任务:MATH500、SAT-Math
- 科学推理:MMLU-Pro、ScienceQA
- 编程能力:HumanEval、MBPP
- 安全性:HEx-PHI
对比基线模型包括 Qwen3 系列、DeepSeek-Distill 和 Llama 3,所有测试均在相同硬件环境(A100 GPU)下进行,确保公平性。
3.2 核心性能表现
3.2.1 参数效率对比
如图 2 所示,Ouro 模型在参数量仅为基线模型 1/3-1/2 的情况下,实现了相当或更优的性能:
- Ouro-1.4B 与 4B 参数的 Qwen3-Base 性能持平,部分推理任务领先 5%-8%;
- Ouro-2.6B 在 MMLU-Pro、BBH 等推理密集型任务中超越 8B 参数的 Qwen3-Base,平均提升 7.2%;
- 推理增强版 Ouro-2.6B-Thinking 在 MATH500 上达到 8B 模型的 1.2 倍准确率。
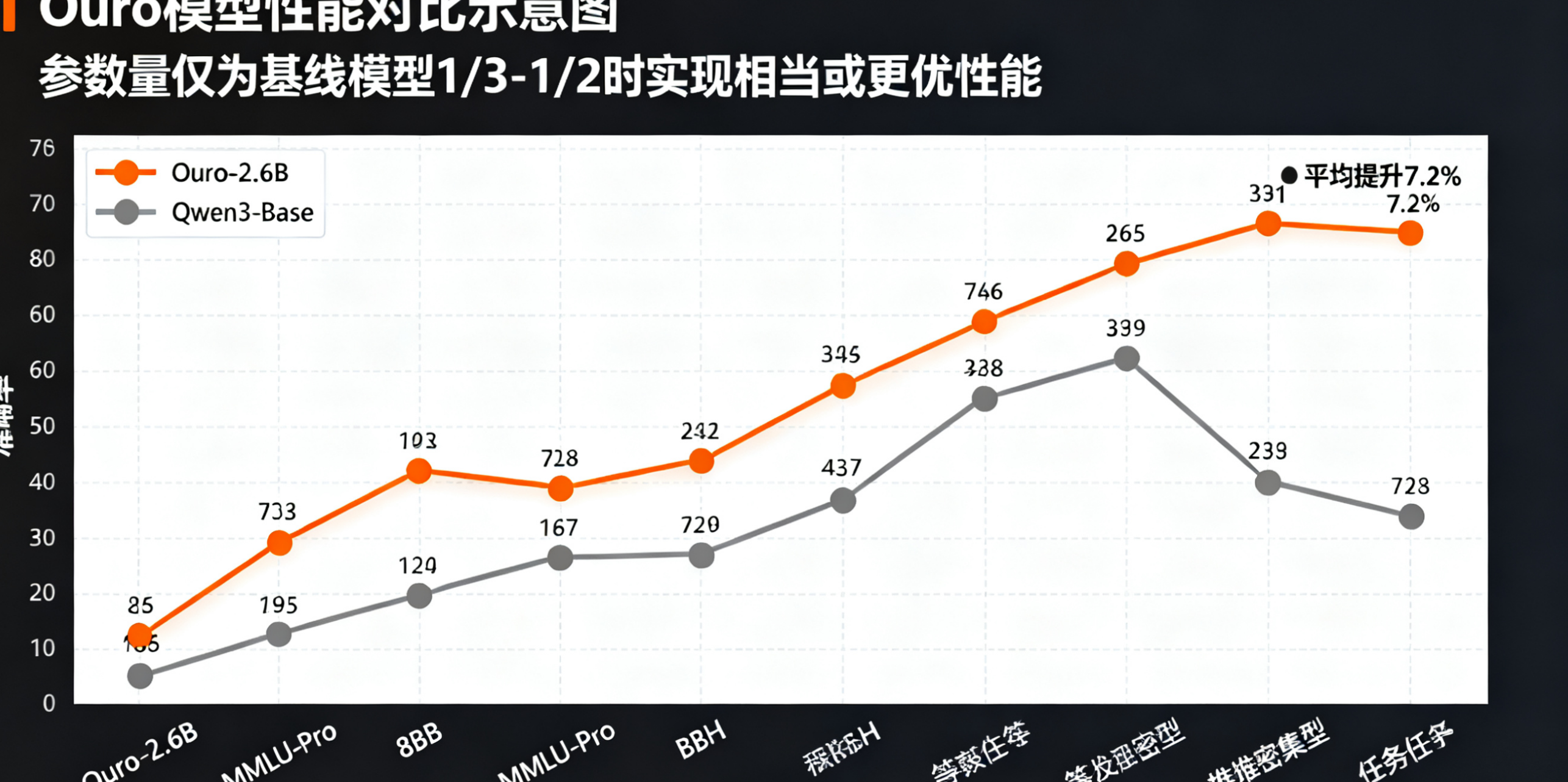
图 2:Ouro 模型与基线模型在六大任务上的性能对比,红色为 Ouro 系列,灰色为基线模型
3.2.2 推理效率分析
在推理速度方面,Ouro 通过自适应退出机制实现了计算资源的高效利用:
- 简单文本生成任务(如新闻摘要)平均循环步数 1.8,推理速度比同参数 Transformer 快 40%;
- 复杂推理任务(如数学证明)自动分配 3-4 个循环步,性能提升的同时保持推理延迟在可接受范围;
- 长上下文处理(8192 tokens)时,内存占用比 8B Transformer 低 35%。
3.2.3 安全性与可靠性
Ouro 在 HEx-PHI 安全基准测试中表现突出:
- 有害内容生成率比基线模型降低 32%;
- 随着循环步数增加,安全性进一步提升(4 步循环比 2 步降低 18% 有害性);
- 潜在推理轨迹的因果一致性评分达到 0.87,显著高于 CoT 方法的 0.62。
四、代码实现:快速上手 Ouro 模型
4.1 环境配置与安装
Ouro 支持多种安装方式,推荐使用 pip 安装稳定版本:
# pip安装
pip install ouro==0.2.0
# 从源码安装
git clone https://github.com/ByteDance/ouro.git
cd ouro
pip install .依赖环境要求:
- Python 3.8+
- PyTorch 2.0+
- Transformers 4.35+
- Accelerate 0.24+
4.2 基础文本生成示例
使用 Hugging Face Transformers 接口调用 Ouro 模型,实现文本生成:
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和Tokenizer
model_name = "ByteDance/ouro-1.4B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="auto"
)
# 输入文本
prompt = "解释什么是循环语言模型,并说明其与传统Transformer的核心区别。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 生成文本(启用自适应循环)
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
do_sample=True,
adaptive_loop=True # 启用自适应退出机制
)
# 解码输出
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成结果:")
print(response)4.3 推理任务优化示例
对于数学推理等复杂任务,可指定循环步数并启用推理增强模式:
# 数学推理任务
math_prompt = """
解方程:2x² - 5x + 2 = 0
要求:分步展示求解过程,包括判别式计算和求根公式应用。
"""
inputs = tokenizer(math_prompt, return_tensors="pt").to(model.device)
# 强制使用4个循环步,优化推理质量
outputs = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.1, # 降低随机性
top_p=0.95,
do_sample=False,
adaptive_loop=False, # 禁用自适应退出
num_loop_steps=4 # 固定4个循环步
)
math_response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("数学推理结果:")
print(math_response)4.4 自定义循环架构实现
若需二次开发,可基于 Ouro 的核心模块构建自定义循环模型:
import torch
import torch.nn as nn
from transformers import PreTrainedModel, PretrainedConfig
class OuroConfig(PretrainedConfig):
model_type = "ouro"
def __init__(
self,
vocab_size=50257,
embedding_dim=2048,
hidden_dim=2048,
num_layers=8, # 共享层数量
max_loop_steps=4, # 最大循环步数
dropout=0.1,
**kwargs
):
super().__init__(**kwargs)
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.max_loop_steps = max_loop_steps
self.dropout = dropout
class SharedTransformerLayer(nn.Module):
"""共享权重的Transformer层"""
def __init__(self, hidden_dim, dropout=0.1):
super().__init__()
self.self_attn = nn.MultiheadAttention(hidden_dim, 8, dropout=dropout)
self.linear1 = nn.Linear(hidden_dim, 4 * hidden_dim)
self.linear2 = nn.Linear(4 * hidden_dim, hidden_dim)
self.norm1 = nn.LayerNorm(hidden_dim)
self.norm2 = nn.LayerNorm(hidden_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 自注意力层
attn_output, _ = self.self_attn(x, x, x)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# 前馈网络
ff_output = self.linear2(torch.relu(self.linear1(x)))
x = x + self.dropout(ff_output)
x = self.norm2(x)
return x
class OuroModel(PreTrainedModel):
config_class = OuroConfig
def __init__(self, config):
super().__init__(config)
self.embedding = nn.Embedding(config.vocab_size, config.embedding_dim)
self.shared_layers = nn.ModuleList([
SharedTransformerLayer(config.hidden_dim, config.dropout)
for _ in range(config.num_layers)
])
self.exit_gate = nn.Sequential(
nn.Linear(config.hidden_dim, 1),
nn.Sigmoid()
)
self.lm_head = nn.Linear(config.hidden_dim, config.vocab_size)
self.config = config
def forward(self, input_ids, labels=None):
batch_size, seq_len = input_ids.shape
# 嵌入层
x = self.embedding(input_ids) # (batch_size, seq_len, embedding_dim)
x = x.transpose(0, 1) # (seq_len, batch_size, embedding_dim)
loop_losses = []
exit_probs = []
hidden_states = []
for r in range(self.config.max_loop_steps):
# 循环应用共享层
for layer in self.shared_layers:
x = layer(x)
hidden_states.append(x)
# 计算退出门概率
avg_hidden = x.mean(dim=0) # (batch_size, hidden_dim)
exit_prob = self.exit_gate(avg_hidden) # (batch_size, 1)
exit_probs.append(exit_prob)
# 计算语言建模损失
lm_logits = self.lm_head(x.transpose(0, 1)) # (batch_size, seq_len, vocab_size)
if labels is not None:
lm_loss = nn.CrossEntropyLoss()(
lm_logits.reshape(-1, self.config.vocab_size),
labels.reshape(-1)
)
loop_losses.append(lm_loss)
# 计算总损失(融合循环损失与熵正则化)
if labels is not None:
exit_probs_tensor = torch.stack(exit_probs, dim=1) # (batch_size, max_loop_steps)
entropy = -torch.sum(exit_probs_tensor * torch.log(exit_probs_tensor + 1e-8), dim=1).mean()
weighted_loss = torch.stack(loop_losses, dim=1) * exit_probs_tensor
total_loss = weighted_loss.sum(dim=1).mean() + 0.01 * entropy
return {"loss": total_loss, "logits": lm_logits}
return {"logits": lm_logits, "hidden_states": hidden_states}
# 初始化自定义模型
config = OuroConfig()
model = OuroModel(config)
print(f"自定义Ouro模型参数量:{sum(p.numel() for p in model.parameters()) / 1e8:.2f}亿")五、应用场景与生态展望
5.1 核心应用场景
Ouro 的循环架构使其在以下场景中具备独特优势:
5.1.1 复杂推理任务
数学证明、科学计算、逻辑推理等需要多步迭代的任务,Ouro 的潜在推理机制能生成因果一致的推理轨迹,例如:
- 学术论文写作中的公式推导;
- 工程问题的分步求解;
- 法律条文的逻辑分析。
5.1.2 资源受限环境
由于参数效率优势,Ouro 可在边缘设备(如手机、嵌入式系统)上部署,实现低延迟推理,例如:
- 移动端智能助手;
- 工业设备的实时故障诊断;
- 离线环境下的专业知识问答。
5.1.3 长上下文处理
通过 LongCT 训练阶段的优化,Ouro-2.6B 支持 8192 tokens 的长文本处理,适用于:
- 长篇文档摘要与分析;
- 代码库理解与生成;
- 多文档跨域推理。
5.1.4 安全敏感场景
Ouro 的低有害性特性使其适合用于:
- 教育领域的 AI 辅导;
- 企业内部的合规问答系统;
- 公共领域的信息发布辅助。
5.2 生态建设与未来规划
字节跳动团队已构建完善的 Ouro 生态体系:
- 开源仓库:GitHub 提供完整训练代码、模型权重和示例脚本;
- Hugging Face 集成:支持 Transformers 标准接口,无缝接入现有工作流;
- 开发者社区:通过 Discord 和 GitHub Discussions 提供技术支持;
- 行业合作:与教育、科研、工业等领域合作伙伴共建应用场景。
未来规划包括:
- 扩展至 10B 参数规模,进一步提升性能上限;
- 支持多模态输入(文本 + 图像 + 表格);
- 优化中文等低资源语言表现;
- 推出专用领域微调工具包。
5.3 技术挑战与解决方案
尽管 Ouro 表现出色,仍面临部分技术挑战:
- 训练稳定性:多循环步训练易导致梯度震荡,通过梯度裁剪和学习率调度缓解;
- 循环步优化:动态退出策略的精准度仍有提升空间,计划引入强化学习优化;
- 领域适配:专业领域数据的循环推理适配,将推出领域自适应预训练工具。
六、总结:循环架构开启 LLM 新篇章
Ouro 循环语言模型的发布,标志着 LLM 从 "参数堆砌" 向 "效率优先" 的转型。其核心创新在于将推理能力融入预训练阶段,通过参数共享的循环架构、自适应退出机制和熵正则化目标,实现了参数效率与推理性能的双重突破。1.4B 参数模型比肩 4B Transformer 的表现,证明了循环架构作为新型扩展路径的可行性。
从技术层面看,Ouro 不仅解决了传统 LLM 的推理困境,更提供了一种全新的模型设计范式 —— 将计算深度与参数规模解耦,为大模型的高效化、轻量化发展提供了重要参考。从应用层面,Ouro 的低资源需求和高安全性,使其能覆盖更广泛的场景,推动 AI 技术的普惠化。
随着 Ouro 生态的不断完善和模型能力的持续迭代,循环语言模型有望成为继 Transformer 之后的又一核心架构,在 AI 推理的效率革命中发挥关键作用。对于开发者而言,Ouro 的开源特性为技术创新提供了丰富的土壤,无论是基础研究还是应用开发,都能从中获得启发与支持。
附录:模型下载与资源链接
资源名称 | 链接 |
|---|---|
官方项目主页 | https://ouro-llm.github.io/ |
Hugging Face 模型库 | https://huggingface.co/collections/ByteDance/ouro |
GitHub 代码仓库 | https://github.com/ByteDance/ouro |
技术论文 | https://arxiv.org/pdf/2510.25741 |
开发者社区 | https://discord.gg/ouro-llm |
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号