强化学习 | 优化策略 Roadmap 介绍


强化学习(Reinforcement Learning)是大模型后训练的重要一环,其主要是研究智能体和环境的交互问题,其中涉及多种强化学习策略和优化方案。本节围绕强化学习,梳理主要策略的方式和它们之间的演进路线,主要包括:
1)强化学习的基本概念,组成和与环境的交互过程。 2)和监督学习sft之间的区别和主要优势。 3)各种强化学习策略之间的关系和迭代优化路线。
微信关注“AI老马” —【获取资源】&【进群交流】
1,强化学习基本框架
1.1,强化学习流程
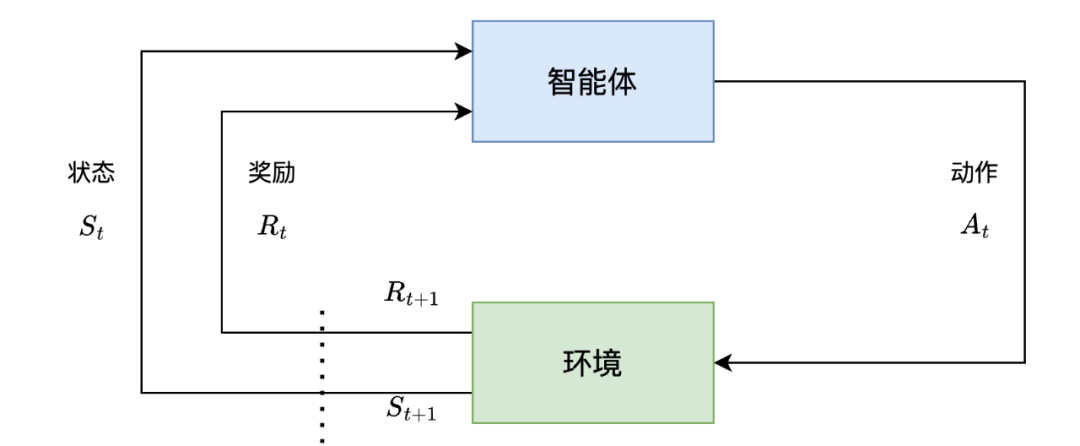
图1,强化学习基本框架
强化学习(Reinforcement Learning)研究智能体和环境交互的问题,其目标是使智能体在复杂且不确定的环境中最大化奖励。强化学习的基本框架主要由两部分组成,智能体和环境。
- • 智能体
智能体是强化学习的核心执行单元,具备感知、决策和行动能力。它获取环境状态信息,基于自身策略(Policy)生成具体行动,并且可以通过学习调整策略,最终实现奖励最大化的目标。
- • 环境
环境是智能体所处的外部场景与互动对象,是状态和奖励的来源。它会接收智能体的行动并产生反馈,包括新的环境状态和即时奖励(或惩罚),且环境状态的转换可能带有随机性,无法被智能体完全控制。
- • 交互流程
初始时刻,环境生成初始状态并传递给智能体。智能体根据当前状态和自身策略,输出具体行动。环境接收行动后,转换为新状态,并计算即时奖励返回给智能体。智能体结合新状态和奖励更新策略,优化后续决策逻辑。重复上述步骤,直到达到预设终止条件,如完成任务、达到最大交互步数。
小结:智能体是决策与执行主体,环境是交互场景与反馈来源,二者通过 “感知 - 决策 - 执行 - 反馈” 循环完成交互。
1.2,强化学习和监督学习区别
- • 强化学习更可能考虑整体影响
监督学习针对单个词元进行反馈,目标是要求模型针对给定的输入给出确切的答案,并且其损失为基于总和规则的交叉熵函数,造成这种损失对个别词元变化不敏感。而强化学习是针对整个输出文案进行反馈,并不是针对特定词元。反馈的粒度不同,使其既可以兼顾表达多样性又可以增强对微小变化的敏感性。
- • 强化学习更容易解决幻觉问题
用户在大语言模型主要是三种类型的输入,文本型,求知型和创造型。监督学习非常容易使求知型的输入产生幻觉。在模型不包含或者不知道答案的情况下,监督训练仍然会促使模型给出答案。而强化学习通过奖励函数,将正确答案赋予非常高的分数,将放弃回答的答案给予中低分,将不正确的答案给予低分,使得模型学会依赖内部知识选择放弃回答,从而一定程度上缓解模型幻觉问题。
- • 强化学习可以更好解决多轮对话奖励积累问题
监督学习很难构造多次交互过程,而强化学习通过构建奖励函数,根据整个对话的背景及连贯性可以很好的对当前模型输出的优劣进行判断。
2,各种强化学习关系

图2,强化学习策略关系图
2.1,基础框架-策略梯度SG
策略梯度 SG(Policy Gradient)是强化学习中直接优化策略的最基础方法,是后续所有策略梯度类算法的 “源头”。
核心逻辑:通过计算 “策略的梯度”,即策略参数变化对累积奖励的影响,直接调整策略参数,使策略倾向于获得更高奖励的行动。问题:梯度估计方差大,训练不稳定;学习率稍大就可能导致策略 “崩塌” 性能骤降,样本效率低。
2.2,近端策略优化 PPO
近端策略优化算法 PPO(Proximal Policy Optimization)是SG的改进版,主要是解决 SG 的不稳定性,提升实用性。目前强化学习中最常用的策略梯度算法。
核心改进:针对 SG 中 “策略更新幅度过大导致不稳定” 的问题,PPO 通过 “剪辑(Clip)” 或 “KL 散度约束” 限制新策略与旧策略的差异即 “信任域” 思想,确保每次更新在安全范围内,同时保留足够的学习效率。
关系:PPO 是 SG 的工程化优化版本,通过约束策略更新幅度,解决了 SG 的稳定性问题,成为实际场景,如机器人控制、游戏 AI 的首选算法。
2.3,群体相对策略优化 GRPO
群体相对策略优化 GRPO(Group Relative Policy Optimization)进一步简化 PPO,提升效率,是PPO 的简化与改进版。
核心改进:PPO 的 “剪辑” 机制虽然稳定,但依赖手动调参(如剪辑系数),且可能引入偏差。GRPO 通过数学推导,将 PPO 的约束条件转化为更简洁的 “自适应正则项”,无需手动调参,同时理论上保留了 PPO 的稳定性,且计算效率更高。
关系:GRPO 是对 PPO 的 “去冗余” 优化,继承了 PPO 的信任域思想,但通过简化约束逻辑,降低了调参成本,提升了训练效率,可视为 PPO 的 “轻量化升级版”。
2.4,基于人类反馈的强化学习 RLHF
基于人类反馈的强化学习 RLHF(Reinforcement Learning from Human Feedback)整合策略优化与人类反馈,是一种强化学习框架而非单一算法。
核心: 用人类反馈替代环境的自动奖励,解决 “环境奖励难以定义” 的问题。
奖励模型 RM (Reward Model):通过由人类反馈标注的偏好数据来学习人类的偏好,判断模型回复的有用性,保证内容无害。其模拟了人类偏好信息,能够不断的为模型训练提供奖励信号。
流程: 先让模型生成候选输出,收集人类对这些输出的偏好排序(如 “好 / 坏”“更优 / 较差”);用这些偏好数据训练 奖励模型(RM),让 RM 能模仿人类对输出的打分;用 PPO 等策略梯度算法,基于 RM 的打分作为 “奖励”,优化模型策略,使其生成更符合人类偏好的输出。
与其他算法的关系:RLHF 是 “目标 + 流程”,而 PPO/DPO 是实现这一流程的 “工具”。早期 RLHF 常用 PPO,后期 DPO 通过简化步骤跳过 RM,成为 RLHF 的更高效实现方式。
RLAIF(Reinforcement Learning from AI Feedback) RLHF 的变体,用 AI 模型,如更强大模型的反馈,替代人类反馈,解决人类标注成本高、一致性低的问题,是大模型对齐的新兴方向。
2.5,直接偏好优化 DPO
直接偏好优化 DPO(Direct Preference Optimization),针对 “基于人类反馈的强化学习(RLHF)” 场景设计的策略优化算法,为了脱离环境交互,直接利用偏好数据。
核心逻辑:传统 RLHF 需要先训练 “奖励模型(RM)”,再用 PPO 等算法基于 RM 优化策略,步骤复杂。DPO 跳过奖励模型,直接通过人类对 “两个输出的偏好” 数据(如 “回答 A 比回答 B 好”),构建损失函数,直接优化策略,使策略更倾向于生成被偏好的输出。
与 PPO 的关系:PPO 依赖环境反馈的 “数值奖励”,DPO 依赖人类反馈的 “相对偏好”;DPO 是 RLHF 场景下对 PPO+RM 流程的简化,通过直接建模偏好,减少了中间步骤的误差和计算成本。
3,总结
核心关系链
基础线:策略梯度(SG)→ 改进稳定性(PPO)→ 简化优化逻辑(GRPO),均为 “与环境交互” 场景下的策略优化算法,逐步提升稳定性和效率。
人类反馈线:RLHF(框架)→ 早期用 PPO + 奖励模型 → 简化为 DPO(直接优化偏好),针对 “无明确环境奖励” 场景,用人类反馈替代环境奖励,逐步简化流程、降低成本。
简言之,SG 是起点,PPO 是 SG 的实用化标杆,GRPO 是 PPO 的轻量化升级;而 DPO 是 RLHF 框架下对 PPO 的替代方案,专注于用人类偏好数据更高效地优化策略。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号