AI数据存储:Hammerspace统一平台解析

AI数据存储:Hammerspace统一平台解析

数据存储前沿技术
发布于 2026-01-13 15:47:59
发布于 2026-01-13 15:47:59
阅读收获
• 深入理解AI时代存储架构的核心挑战:数据孤岛、迁移瓶颈和资源利用率低下等问题 • 掌握从基础设施中心到数据中心的存储理念转变,以及这种转变对AI工作负载的重要意义 • 了解Hammerspace的技术创新点:Tier 0共享存储、原位数据同化、智能分层等关键技术如何协同工作 • 获得现代AI基础设施设计的实践指导:如何在性能、成本和可管理性之间找到最佳平衡
全文概览
在AI和数据分析时代,传统的存储架构正面临前所未有的挑战。当企业试图将本地存储与云端GPU集群连接时,"数据孤岛"问题日益凸显——数据在不同系统和位置间反复迁移,不仅造成性能瓶颈,还带来高昂的管理成本。更糟糕的是,昂贵的GPU资源常常因等待数据而闲置,严重影响项目进度。
Hammerspace正是为解决这一痛点而生。这家专注于AI数据平台的厂商,提出了从"面向基建"到"面向数据"的范式转变,通过创新的软件定义存储方案,将分散的存储资源整合为统一的全局数据环境。无论是本地NVMe、云存储还是混合架构,都能在单一命名空间下透明访问。
这篇文章将深入剖析Hammerspace的核心技术理念:从Tier 0高性能共享存储,到原位数据同化,再到智能分层管理,看看它如何真正实现"AI Anywhere"的愿景,为现代AI工作负载提供高效、灵活且经济的数据基础架构。
👉 划线高亮 观点批注
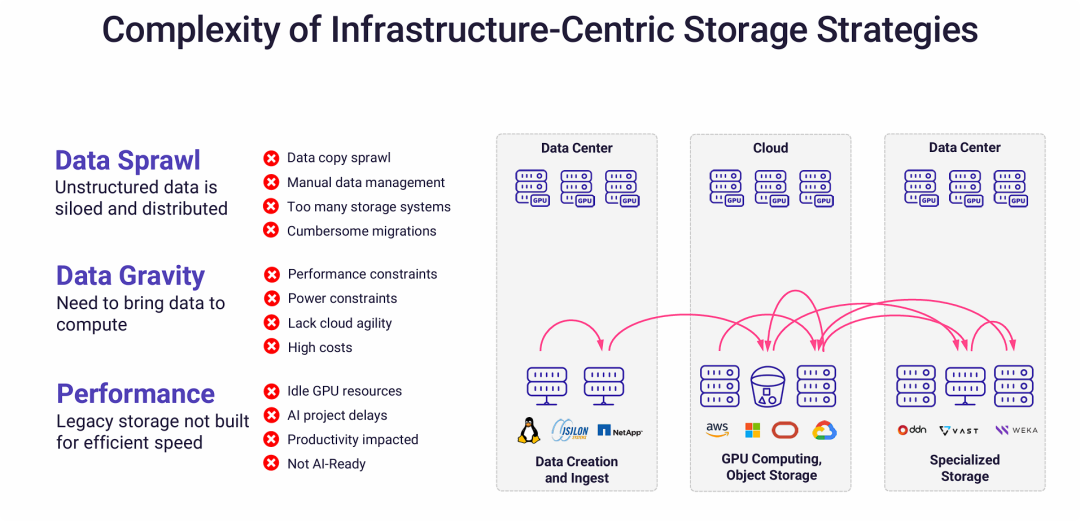
以基础设施为中心的存储策略的复杂性
以基础设施为中心的存储策略的复杂性
以基础设施为中心的传统存储策略已经无法适应现代AI和数据分析的需求,其固有的“数据孤岛”模式导致了极高的复杂性和效率低下。
- 问题的根源: 核心问题在于数据存储和数据计算是分离的。数据产生于传统的企业存储系统,而高性能的GPU计算资源却部署在云端或专门的AI集群中。
- “数据移动”成为瓶颈: 为了进行AI训练或数据分析,企业被迫在不同的存储系统、数据中心和云之间大规模地复制和迁移数据。这个过程不仅本身就是性能瓶颈,还带来了高昂的成本和管理负担。
- 三大负面影响: 这种过时的架构导致了三个主要问题:
- 数据蔓延:产生大量难以管理的数据副本。
- 数据引力:移动数据的过程限制了业务的敏捷性和性能。
- 性能不足:传统存储无法满足AI工作负载对数据吞吐和IOPS的要求,导致GPU等昂贵资源闲置,最终影响项目进度和生产力。
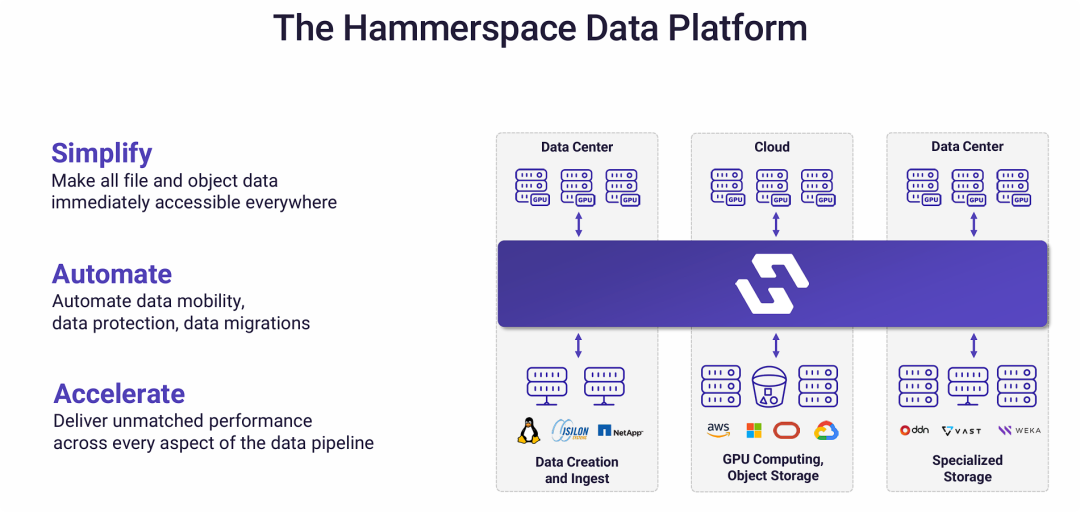
Hammerspace数据平台
Hammerspace数据平台
Hammerspace数据平台通过提供一个统一的软件定义抽象层,解决了传统以基础设施为中心的存储策略所带来的复杂性、低效率和性能瓶瓶颈问题。
- 从“面向基建”到“面向数据”的转变: Hammerspace将焦点从管理多个独立的存储“孤岛”转移到管理全局统一的数据。它在用户/应用和物理存储之间建立了一个智能的中间层。
- 打破孤岛,实现全局访问: 这是Hammerspace最核心的能力。通过这个平台,任何地方的计算资源都可以透明地访问任何地方的数据,无需关心数据具体存放在哪个物理设备上。这解决了“数据蔓延”和“数据引力”的问题。
- 智能自动化取代手动操作: 平台通过策略驱动的自动化引擎,在后台智能地处理数据的移动、放置和保护。例如,它可以自动将AI训练所需的热数据移动到高性能的专用存储上,而将冷数据归档到低成本的对象存储中。
- 释放计算潜能: 通过将数据按需、实时地提供给GPU集群,Hammerspace确保了计算资源不会因为等待数据而闲置,从而极大地提升了整个AI和数据分析流程的性能和效率,解决了“性能”问题。
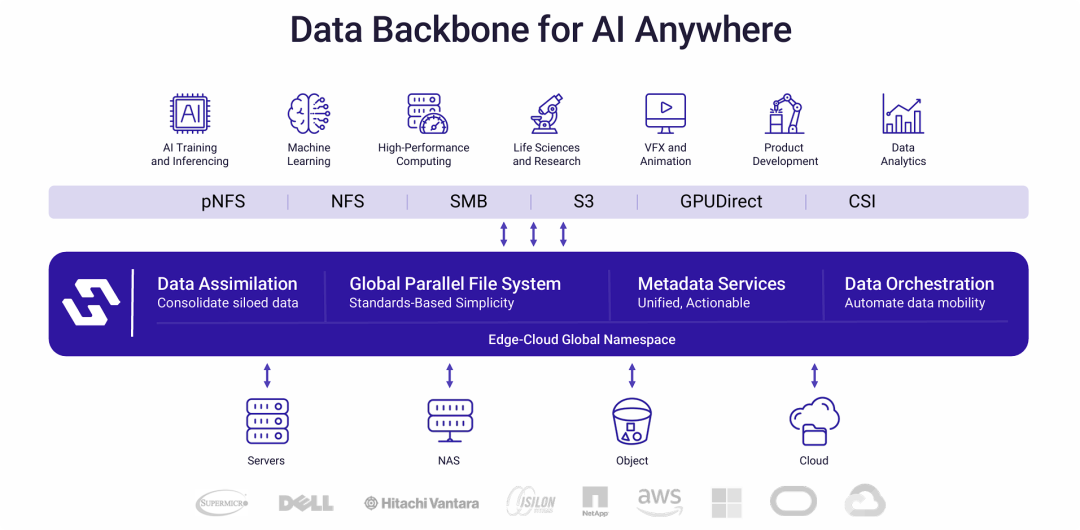
适用于任何地方的人工智能的数据骨干
适用于任何地方的人工智能的数据骨干
整个架构图分为四个层次,从上到下依次是:应用层、协议层、Hammerspace平台核心层和底层基础设施层。
Hammerspace是一个软件定义的、通用的数据骨干平台,它通过提供一个跨越边缘、数据中心和云的全局数据环境,来满足AI等现代高性能工作负载的需求。
- 全面的兼容性与开放性: 平台通过支持广泛的标准协议(从NFS/SMB到S3、GPUDirect)和兼容各类底层存储硬件及云服务,实现了对现有IT生态的无缝集成。
- 核心技术是“全局并行文件系统”: Hammerspace的核心价值在于将所有分散的存储孤岛,抽象成一个单一、标准的全局并行文件系统。这极大地简化了数据访问和管理。
- 智能化是关键驱动力: 平台不仅仅是连接,更是通过“可操作的元数据服务”和“数据编排”引擎,实现了数据的智能化管理。它可以根据应用需求和策略,自动优化数据放置,平衡性能与成本。
- 终极目标是“AI Anywhere”: 通过构建这样一个数据骨干,Hammerspace使得AI等计算密集型应用可以部署在任何最合适的地方(云端、本地数据中心或边缘),同时又能透明、高效地访问到全局范围内任何位置的数据,真正实现了计算与存储的解耦和数据的自由流动。
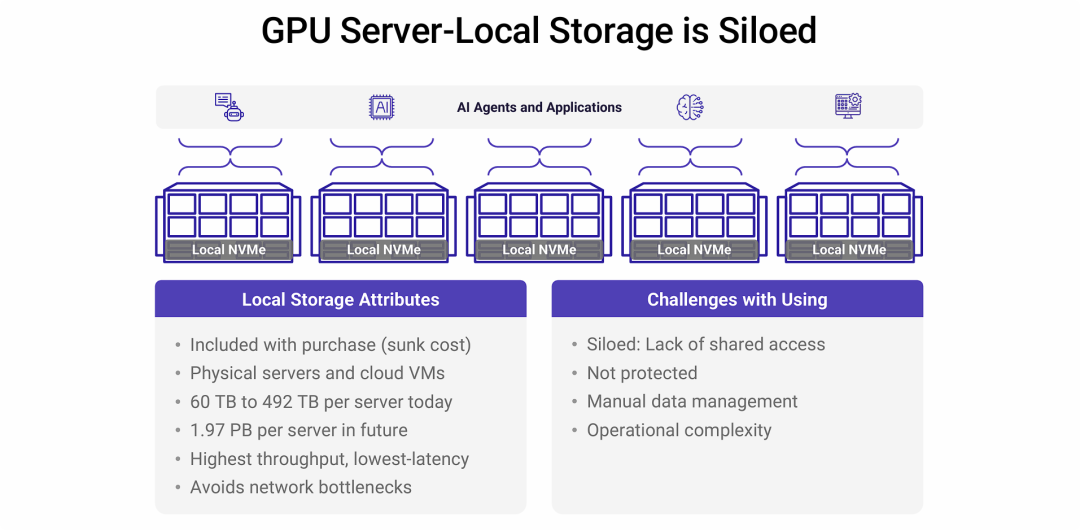
GPU服务器的本地存储是孤岛化的
GPU服务器的本地存储是孤岛化的
尽管GPU服务器的本地NVMe存储能提供极致的单点性能,但其固有的“孤岛”特性使其成为一种无法扩展、管理复杂且风险极高的架构,完全不适用于现代大规模AI工作负载。
- 性能的诱惑与陷阱: 团队可能会因为本地存储无与伦比的低延迟和高吞吐量而选择它,但这是一种短视的决定,因为它牺牲了数据共享性、可管理性和安全性。
- “孤岛化”是根本缺陷: 无法在计算节点之间共享数据,是这种架构的“原罪”。这与AI训练(尤其是分布式训练)需要访问统一、海量数据集的基本要求背道而驰。
- 高昂的隐性成本: 表面上看似节省了存储网络的成本,但实际上却带来了巨大的运维成本、人力成本和数据丢失的风险。手动数据管理会严重拖累AI团队的研发效率。
- 不可扩展性: 当GPU集群规模扩大时,本地存储的“孤岛”问题会呈指数级恶化,最终使得整个系统无法有效管理和使用。
从真实用例来看,GPU本地存储将发挥积极作用,此处强调其数据管理的短板,主要是为凸显 后面 Hammerspace 软件方案优势。
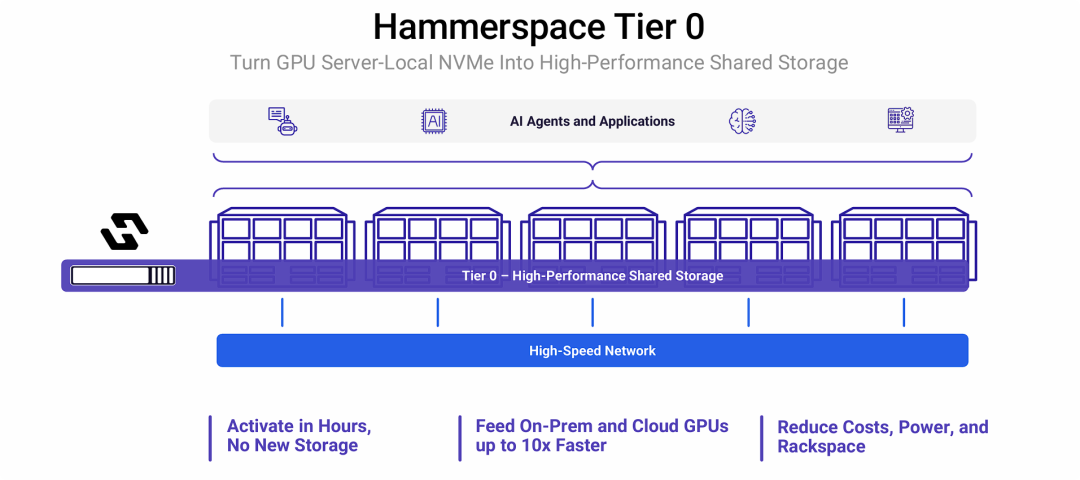
将GPU服务器的本地NVMe转变为高性能共享存储
将GPU服务器的本地NVMe转变为高性能共享存储
Hammerspace Tier 0 是一个创新的软件定义存储解决方案,它能将GPU服务器中孤立的本地NVMe硬盘,通过高速网络整合成一个逻辑上的、高性能的共享存储池,从而在不增加新硬件的情况下,解决了AI工作负载的数据访问瓶颈。
- “变废为宝”,激活沉没资产: Hammerspace的核心价值在于盘活了服务器中已有但被孤立的本地NVMe资源。它将这些“沉没成本”的硬件转变为企业级的、可共享的高性能存储。
- 兼得鱼与熊掌: 该方案巧妙地结合了本地存储的极致性能(低延迟、高吞吐)和共享存储的灵活性与可管理性。应用可以像访问本地盘一样快地访问数据,但数据实际上是在一个大的、可在所有节点间共享的池中。
- 软件定义,硬件解耦: 这是一个纯软件解决方案,不依赖特定的硬件品牌。它通过高速网络协议(如NVMe-oF)实现节点间通信,将一组标准的GPU服务器变成一个强大的分布式存储集群。
- 最终价值是加速AI并降低TCO: 通过解决数据供给问题,Hammerspace Tier 0可以直接加速AI训练和推理任务,同时通过利旧硬件和减少基础设施,显著降低了构建和运维高性能计算环境的总体成本。
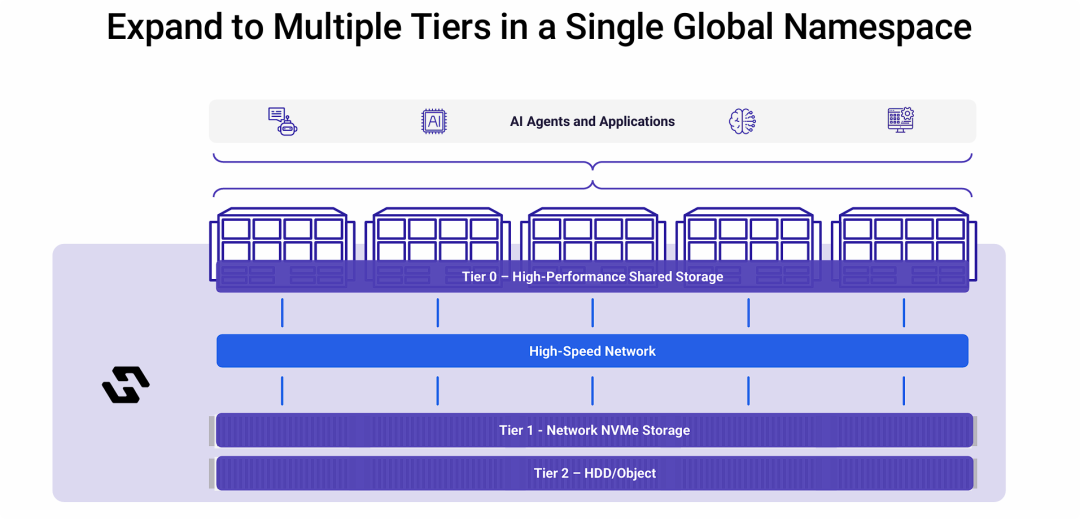
在单一全局命名空间内扩展至多层存储
在单一全局命名空间内扩展至多层存储
Hammerspace不仅仅是一个高性能的Tier 0解决方案,更是一个能够整合多层异构存储、实现智能数据生命周期管理的完整数据平台。
- 智能分层存储 (Intelligent Tiering): Hammerspace允许企业构建一个兼顾性能与成本的混合存储池。最活跃、对性能要求最高的“热”数据会被自动放置在Tier 0;次活跃的“温”数据可以放在Tier 1;而海量的“冷”数据则可以经济高效地存放在Tier 2。
- 透明访问与数据无感流动: “全局命名空间”是实现这一切的核心技术。它对用户和应用屏蔽了底层存储的复杂性。当应用需要访问一个文件时,Hammerspace会自动将其从所在的层级(如Tier 2)提升到高性能的Tier 0,供计算节点使用。这个过程对用户是透明的。
- 极致的扩展性和成本优化: 这种架构提供了近乎无限的扩展能力。企业可以按需扩展最高性能的Tier 0,同时将数据主体存放在低成本的大容量层,从而在满足AI等应用苛刻性能要求的同时,极大地优化了总体拥有成本(TCO)。
- 完整的数据生命周期管理: 通过策略驱动的数据编排,Hammerspace实现了从数据创建、使用、到归档和删除的整个生命周期的自动化管理,将正确的数据在正确的时间,放置在正确的存储层级上。
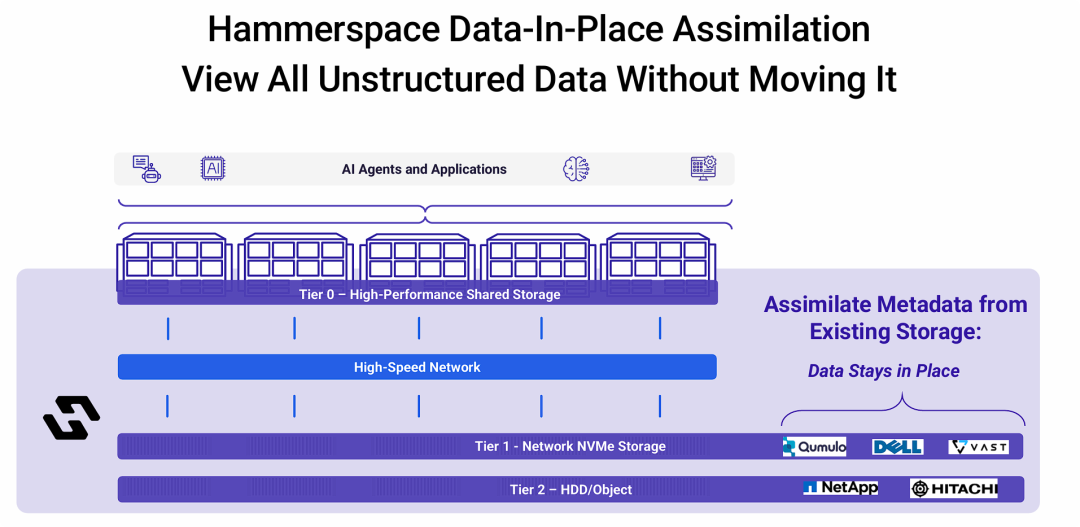
Hammerspace 原位数据同化-无需移动即可查看所有非结构化数据
Hammerspace 原位数据同化-无需移动即可查看所有非结构化数据
Hammerspace的“原位数据同化”技术,能够以一种非破坏性、零中断的方式,快速地将企业现有的、来自不同厂商的存储孤岛整合到一个统一的数据平台中,从而简化部署过程并保护了既有投资。
- 消除数据迁移的痛苦: 传统上,要引入新的存储平台,最痛苦、耗时最长、风险最高的就是数据迁移。Hammerspace通过只操作元数据的方式,彻底绕开了大规模的数据搬迁,实现了业务的平滑过渡。
- 数据立即可用: “同化”过程完成后,存储在旧系统上的海量数据可以立即被新的AI应用通过Hammerspace访问。当应用首次访问某个文件时,Hammerspace才会按需、在后台将该文件的数据块拉取到高性能层(如Tier 0),这个过程对应用是透明的。
- 保护现有投资 (Investment Protection): 企业无需废弃已购买的来自Dell、NetApp等厂商的存储设备。通过“同化”,这些设备可以继续作为Hammerspace管理的存储资源池的一部分发挥作用,延长了其生命周期,保护了硬件投资。
- 实现真正的异构存储统一管理: 这项技术是Hammerspace能够将各种品牌、各种协议、各种介质的存储设备整合成一个逻辑整体的关键。它为实现跨所有存储资源的数据生命周期管理、数据编排和全局访问奠定了基础。
对于企业数据管理员来说,原位接管不同存储源的方案,确实具有很大想象力。如何对接不同数据源的元数据,是个 Dirty work,或许等Iceberg 广泛落地,数据管理就能简单很多了
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 在您的AI项目中,是否遇到过GPU资源因数据供给不足而闲置的情况?您认为Hammerspace的统一数据平台方案能否有效解决这类问题?
- 对于企业现有的多品牌存储设备,您认为Hammerspace的"原位数据同化"技术与传统的数据迁移方案相比,在实际部署中可能面临哪些技术挑战?
- 随着AI模型规模的不断增长,对数据访问性能的要求也在持续提升。您认为未来3-5年内,存储架构还会发生哪些根本性的变革?
原文标题:The Data Platform for AI Anywhere[1]
Notice:Human's prompt, Datasets by Gemini-2.5-Pro
#FMS25 #统一数据平台
---【本文完】---
👇阅读原文,搜索🔍更多历史文章。
- https://files.futurememorystorage.com/proceedings/2025/20250807_AIML-303-1_Christofferson_fnl.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号