赛博神农尝百草——表型药物发现的前世今生

赛博神农尝百草——表型药物发现的前世今生

MindDance
发布于 2026-01-08 13:08:23
发布于 2026-01-08 13:08:23
许多药物或其前身都是通过观察它们对正常或疾病生理的影响而发现的。但药物发现是一个复杂且耗时的过程,传统上主要分为两大方法:靶点导向的药物发现(Target-Based Drug Discovery, TDD)和表型导向的药物发现(Phenotypic Drug Discovery, PDD)。
随着计算机技术的发展,计算机辅助药物设计(Computer-Aided Drug Design, CADD)和人工智能驱动的药物设计(AI-Driven Drug Design, AIDD)相继出现,为药物研发带来了新的契机。然而,这些方法也存在各自的局限性。
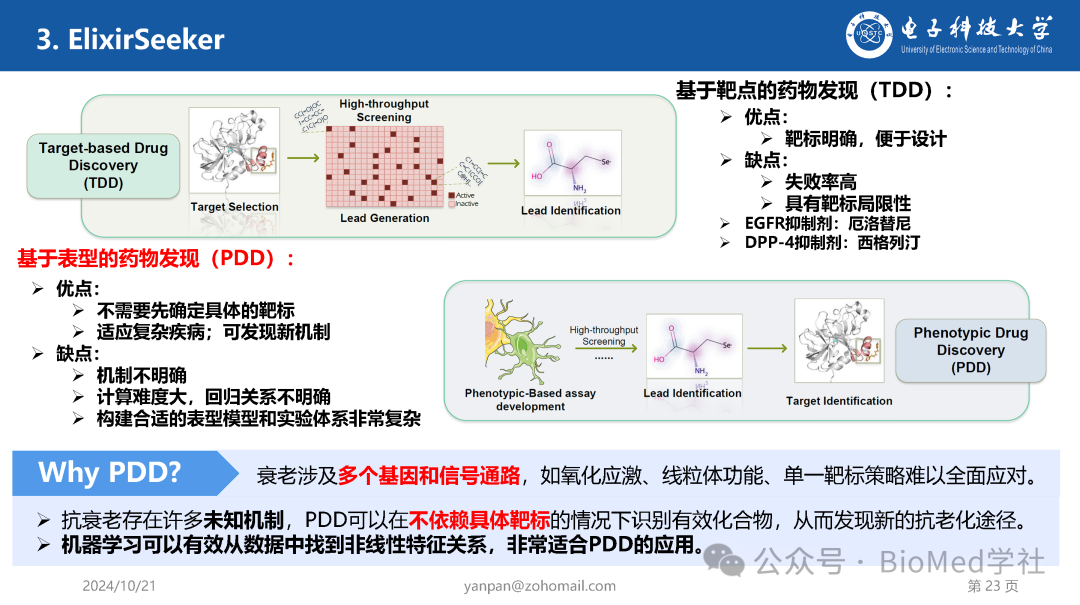
靶点药物发现(TDD)是基于对疾病相关生物学靶点的深入理解,首先确定特定的分子靶点,然后设计或筛选能够与其相互作用的化合物。这个方法在20世纪末期随着分子生物学和基因组学的进步而兴起。
TDD的优势在于,其针对特定靶点设计药物,具有高度的选择性。况且,可以深度了解药物的作用机制,有助于预测药物的疗效和副作用。然而对于多基因或机制复杂的疾病,单一靶点的策略可能不足。
在这三十年间,TDD发展了许多药物开发的计算方法。比如基于结构的药物设计(Structure-Based Drug Design, SBDD)。SBDD利用已知的靶点蛋白质的三维结构,通过计算机模拟预测小分子与靶点的结合方式。这一方法依赖于高分辨率的蛋白质结构数据,通常通过X射线晶体学、核磁共振(NMR)或冷冻电镜技术获得。SBDD的核心技术包括分子对接(Molecular Docking)和分子动力学(Molecular Dynamics, MD)模拟。
然而,令人惊讶的是,在 1999 年至 2008 年期间,大多数 first-in-class 药物都是在没有药物靶点假设的情况下通过经验发现的。
历史上,新药是通过观察其对疾病表型的治疗效果而发现的,这种观察要么直接在人类身上作为传统医学的一部分——例如,神农尝百草;要么在疾病模型中。
目前,PDD方法已经取得显著成功,包括用于治疗囊性纤维化的ivacaftor和lumicaftor、用于治疗脊髓性肌萎缩症(SMA)的risdiplam和branaplam、用于治疗精神分裂症的SEP-363856、用于治疗疟疾的KAF156和用于治疗特应性皮炎的crisaborole[1]。
TDD和PDD一个是确认靶点----筛选----确认功能----疾病模型进一步验证;一个是筛选-----确认功能-----疾病模型进一步验证----靶点研究。其各有优点和缺点,PDD的优势在于筛选出来的药物靶点直接和疾病生物学模型相关(因为就是拿疾病生物学模型筛到的),而且一次筛选筛到的几个药物可能针对多个靶点,多种机制。这些靶点很可能是全新的,所以潜在的竞争要少很多。
但它也有自己的问题,比如靶点和机理未知在后面进一步开发的时候可能会有困难,尤其找到已经筛选到的药物作用的靶点实际是个非常有挑战性的工作,即使找到了靶点,进一步的靶点验证可能还是必须的。况且,不仅构建合适的表型模型和实验体系非常复杂,在计算筛选上也相当有难度。
如何筛选PDD药物呢?
在数学上,PDD可以被视为一个高维空间中的优化问题:
- 输入空间(X):所有可能的化合物集合,维度极高。
- 输出空间(Y):化合物引起的生物表型变化,可量化为多维响应数据。
- 目标函数(f):从X到Y的映射,反映了化合物与生物系统的交互作用。
PDD的问题实质上是寻找函数f的逆映射,即给定期望的表型响应y,找到对应的化合物x,使得f(x) ≈ y。这是一个典型的逆问题,具有以下特点:1)非线性和多解性,f可能是高度非线性且不唯一的;2)高维性和稀疏性:输入和输出空间都非常高维,但实际有效的变量可能很少。
基于PDD在计算上的难度,据所知,机器学习,特别是深度学习,擅长处理高维和非结构化的数据,能够从复杂的数据中提取特征。
这就是笔者要说的赛博神农尝百草——机器学习的引入为PDD带来了新的希望。

使用关键词“深度学习”、“人工智能”和“表型”或“药物发现”在 PubMed 上查询已发表的文献,会得到两类截然不同的论文:1)应用于大量化合物或化学结构的分类器和 2)应用于表型测定得出的特征的分类器。绝大多数已发表的著作属于第一类(基于图或深度学习,有或没有从不同的训练数据集进行迁移学习),适用于大量化合物或化学结构以及之前筛选中生成的相关药理学数据。
因此,分类器不是应用于表型得出的特征,而是应用于化学结构,以便提出潜在的新型支架,而这些支架反过来可以成为实验验证的基础。一个典型的例子是 DeepMalaria 研究,其中基于图的模型在 GSK 数据集中的抗疟原虫命中上进行训练,以预测恶性疟原虫的生长抑制(和哺乳动物细胞的细胞毒性),从而帮助合理选择支架作为进一步研究的输入[1]。
在这里,PDD的一个典型例子是电子科技大学医学院和北京市疾控中心毒理所的团队在bioRxiv上发表的赛博神农——ElixirSeeker模型[2]。这一研究展示了机器学习在表型药物发现中的潜力,特别是在抗衰老药物的开发方面。
衰老涉及多个基因和信号通路,如氧化应激、线粒体功能、单一靶标策略难以全面应对。并且,抗衰老存在许多未知机制,PDD可以在不依赖具体靶标的情况下识别有效化合物,从而发现新的抗老化途径。所以,机器学习可以有效从数据中找到非线性特征关系,非常适合PDD的应用。

ElixirSeeker通过以下几个关键步骤实现其目标:模型整合了由不同算法生成的分子指纹,分子指纹是用于描述分子结构特征的数值表示。通过融合多种分子指纹,模型能够更全面地捕捉化合物的结构信息。并且,模型为不同的分子指纹分配权重,采用注意力驱动的方法,强调对预测结果贡献较大的指纹特征,从而增强模型的表达能力。通过KPCA技术,模型对高维分子指纹数据进行降维处理,减少计算复杂度,同时保留关键的分子特征。
通过ElixirSeeker模型,研究团队成功筛选出多个具有潜在抗衰老活性的化合物。在对秀丽隐杆线虫(Caenorhabditis elegans)进行实验验证时,发现在测试的六种新化合物中,以下四种化合物显著延长了线虫的寿命:Polyphyllin VI、Medrysone、Thymoquinone和Medrysone。
通过深度学习与大数据的协同作用,人工智能不仅加速了抗衰老药物的发现,更揭示了人类健康与长寿的崭新密码。赛博神农以科技为犁,智慧为犁头,开拓出衰老医学的广袤田野,孕育出希望与永恒的未来。
参考文献:
[1] Vincent F, Nueda A, Lee J, Schenone M, Prunotto M, Mercola M. Phenotypic drug discovery: recent successes, lessons learned and new directions. Nat Rev Drug Discov. 2022 Dec;21(12):899-914. doi: 10.1038/s41573-022-00472-w. Epub 2022 May 30. Erratum in: Nat Rev Drug Discov. 2022 Jul;21(7):541. doi: 10.1038/s41573-022-00503-6. PMID: 35637317; PMCID: PMC9708951.
[2] Yan Pan; Hongxia Cai; Fang Ye; Wentao Xu; Zhihang Huang; Jingyuan Zhu; Yiwen Gong; Yutong Li; Anastasia Ngozi Ezemaduka; Shan Gao; Shunqi Liu; Guojun Li; Hao Li; Jing Yang; Junyu Ning; Bo Xian. ElixirSeeker: A Machine Learning Framework Utilizing Attention-Driven Fusion of Molecular Fingerprints for the Discovery of Anti-Aging Compounds. bioRxiv 2024 .
学术平台 专 注 生 物 医 学 领 域
商务合作 | 品牌推广 | 文章投稿 | 会议发布 | 招生信息
还想了解哪些关于 生物医学/线虫/定量生物学 相关的内容,欢迎留言或私信~
相关内容合作以及文章投稿:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号