AI+Drug 文献速递 | 突破化学问答局限:用模块化操作评估大语言模型的化学推理能力

AI+Drug 文献速递 | 突破化学问答局限:用模块化操作评估大语言模型的化学推理能力

MindDance
发布于 2026-01-08 12:49:57
发布于 2026-01-08 12:49:57
1. Beyond Chemical QA: Evaluating LLM’s Chemical Reasoning with Modular Chemical Operations
期刊: arxiv 链接: https://arxiv.org/abs/2505.21318v1 代码: https://huggingface.co/datasets/OpenMol/ChemCoTBench, https://huggingface.co/datasets/OpenMol/ChemCoTBench-CoT
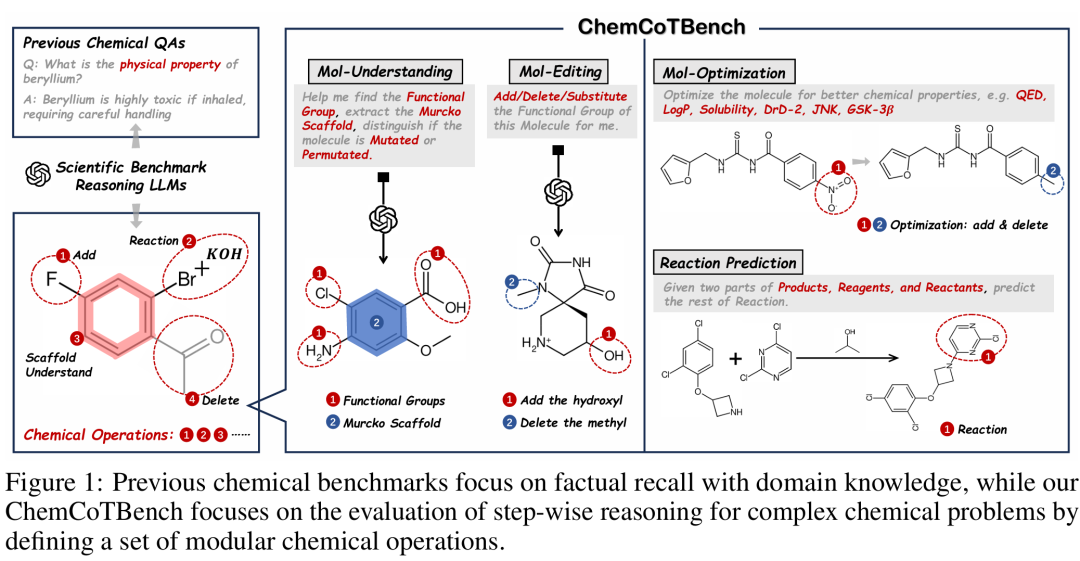
简介: 该论文提出ChemCoTBench框架,解决现有化学基准缺乏结构化推理评估的问题,通过模块化化学操作(如添加、删除、替换官能团)将复杂化学任务分解为可验证的分步流程,结合LLM判断与化学家评审确保数据质量。方法上定义分子理解、编辑、优化和反应预测4类任务共22个子任务,构建包含1495个基准样本和1.4万带思维链标注的数据集,评估19个LLM在化学推理中的表现。实验表明,商用推理LLM(如Gemini-2.5-pro)在复杂任务中表现优于开源模型,且专用化学思维链数据集可显著提升推理性能,但开源模型仍需更多领域数据优化。该研究为LLM在化学发现中的应用提供了标准化评估平台,推动AI驱动的科学创新。
2. FedEDM: Federated Equivariant Diffusion Model for 3D Molecule Generation with Enhanced Communication Efficiency
期刊: ACM on Web Conference 2025(WWW '25) 链接: https://doi.org/10.1145/3701716.3717648
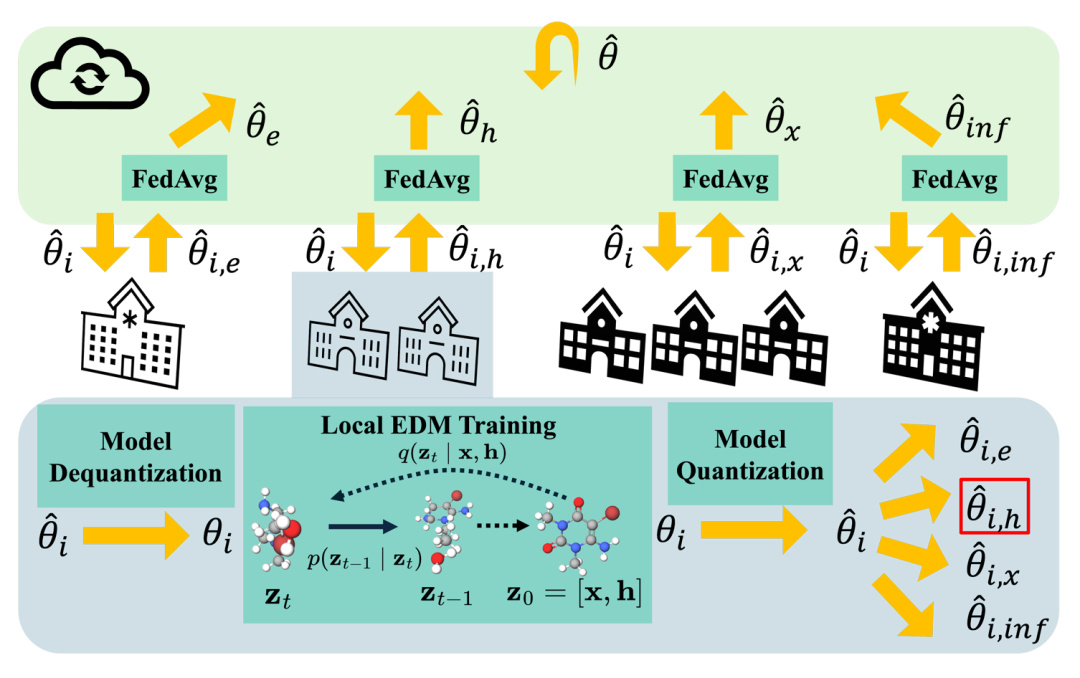
简介: 针对3D分子生成中联邦学习的通信开销问题,论文提出FedEDM框架,结合参数拆分与量化更新提升通信效率。方法上通过随机分配客户端更新扩散模型的特定参数子集(如θ_e、θ_h等),并引入后训练量化技术压缩模型更新,在保持几何对称性约束的同时减少传输数据量。在QM9和GEOM数据集上的实验显示,FedEDM相比基线GraphGANFed减少约70%通信量,生成分子的稳定性、有效性和唯一性指标更高,例如在QM9中原子稳定性达97.4%,且生成分子的能量分布与真实数据接近。该研究为隐私敏感场景下的分子设计提供了高效的联邦学习方案,平衡了模型性能与通信效率。
3. Designing Cyclic Peptides via Harmonic SDE with Atom-Bond Modeling
期刊: arxiv 链接: https://arxiv.org/abs/2505.21452v1
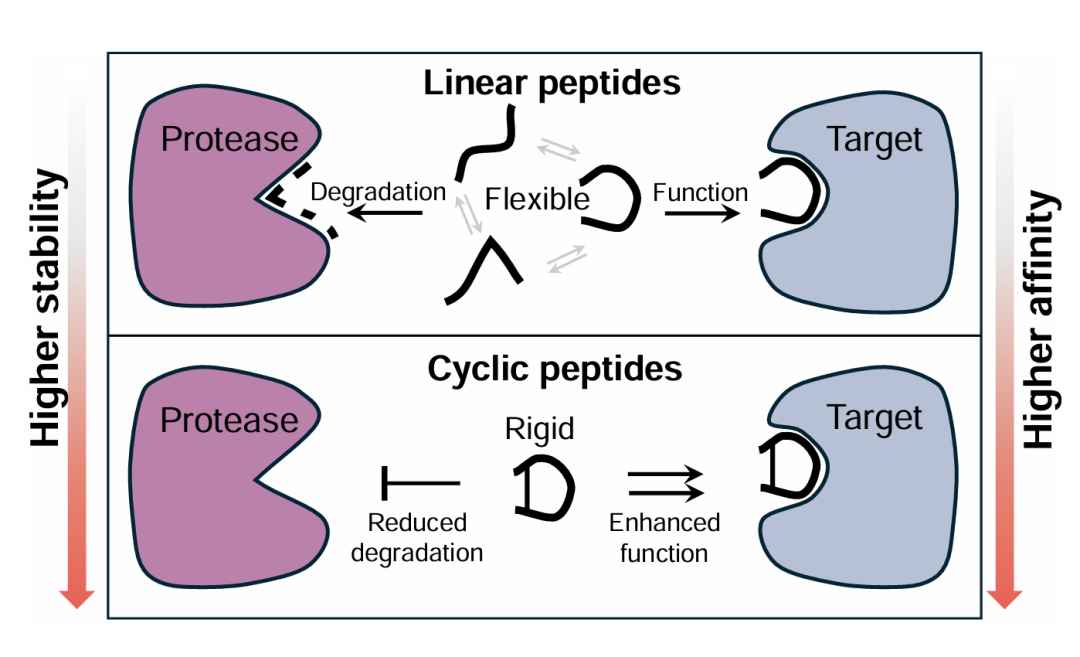
简介: 论文提出CPSDE框架,解决环状肽设计中结构数据稀缺和几何约束难题,通过谐波随机微分方程(SDE)和残基类型预测器RESROUTER,结合全原子与化学键建模生成多样化环状肽。方法上利用ATOMSDE模型基于受体3D结构和环化化学图生成原子坐标,通过路由采样算法交替更新序列和结构,支持头-尾、侧链-侧链等四种环化类型。在SMYD2和SET8等靶点的实验中,生成的环状肽稳定性(如Rosetta能量)和结合亲和力优于线性肽基线(如PepFlow),例如头-尾环化肽在SMYD2靶点的结合能达-24.02 kcal/mol,且分子动力学模拟显示结构更稳定。该研究首次实现基于结构的全类型环状肽生成,为药物开发提供了新工具。
4. Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction
期刊: arXiv 链接: https://arxiv.org/abs/2505.20589v1
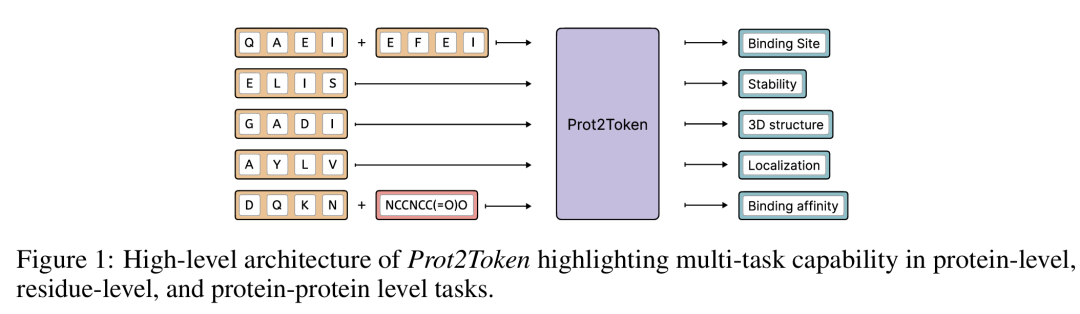
简介: 论文提出Prot2Token框架,通过统一的下一个标记预测格式,将蛋白质序列分析、结构预测、相互作用预测等多任务整合为基于Transformer的端到端模型。创新点在于引入任务标记(Task Token)和自监督解码器预训练,解决传统模型需专项优化的问题。方法上,通过预训练蛋白质编码器(如ESM2)提取序列特征,结合 autoregressive 解码器生成结构化输出,支持多任务学习和跨任务迁移。实验覆盖23个PMO-1K基准任务,在17个任务上达SOTA,如在分子相似性、属性优化任务中超越LICO、MOLLEO等基线,且通过消融实验验证组件重要性,证明任务标记和工具整合的有效性。该研究为蛋白质建模提供了高效统一的解决方案,推动AI在生物分子设计中的应用。
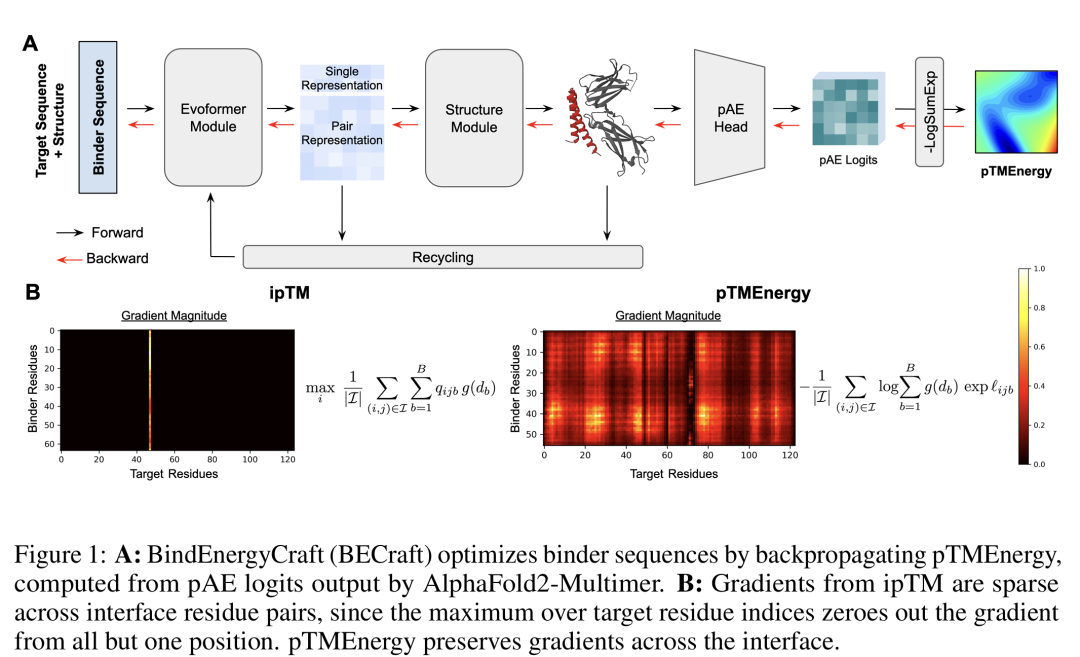
5. BindEnergyCraft: Casting Protein Structure Predictors as Energy-Based Models for Binder Design
期刊: arXiv 链接: https://arxiv.org/abs/2505.21241v1
简介: 论文提出BindEnergyCraft(BECraft)框架,将AlphaFold2的预测误差分布转化为能量函数pTMEnergy,解决传统ipTM指标的稀疏梯度问题。创新点在于将结构预测器视为能量模型,通过联合能量建模(JEM)框架优化结合剂设计。方法上,利用AlphaFold2的pAE logits构建能量函数,指导梯度优化生成高亲和力结合剂。实验在8个蛋白质靶点上验证,BECraft在Rosetta约束和折叠模型约束下均优于BindCraft、RFDiffusion等基线,尤其在虚拟筛选任务中AUPRC提升显著,如在miniprotein和RNA适配体筛选中达新SOTA,证明能量函数的有效性和泛化能力。该研究为蛋白质结合剂设计提供了物理意义明确的优化目标,推动AI在药物设计中的精准性。
6. MT-MOL: Multi Agent System with Tool-based Reasoning for Molecular Optimization
期刊: arXiv 链接: https://arxiv.org/abs/2505.20820v1 代码: https://anonymous.4open.science/r/mt_mol-0448
简介: 论文提出MT-MOL多智能体框架,整合RDKit工具库(154个化学函数),通过分析师、科学家、验证器、评审员四类代理协作实现分子优化。创新点在于分工式代理设计:分析师分领域提取结构特征,科学家生成SMILES并推理,验证器检查逻辑一致性,评审员提供工具导向反馈。方法上,通过五分类工具集(结构描述、电子特性、功能基团等)引导生成过程,结合迭代优化机制。实验在PMO-1K基准23任务中17项达SOTA,如在化学相似性、异构体生成任务中超越LICO、MOLLEO,消融实验验证工具整合和多代理协作的必要性。该框架为分子优化提供了可解释、工具驱动的多智能体协作范式,推动AI在药物设计中的系统性应用。
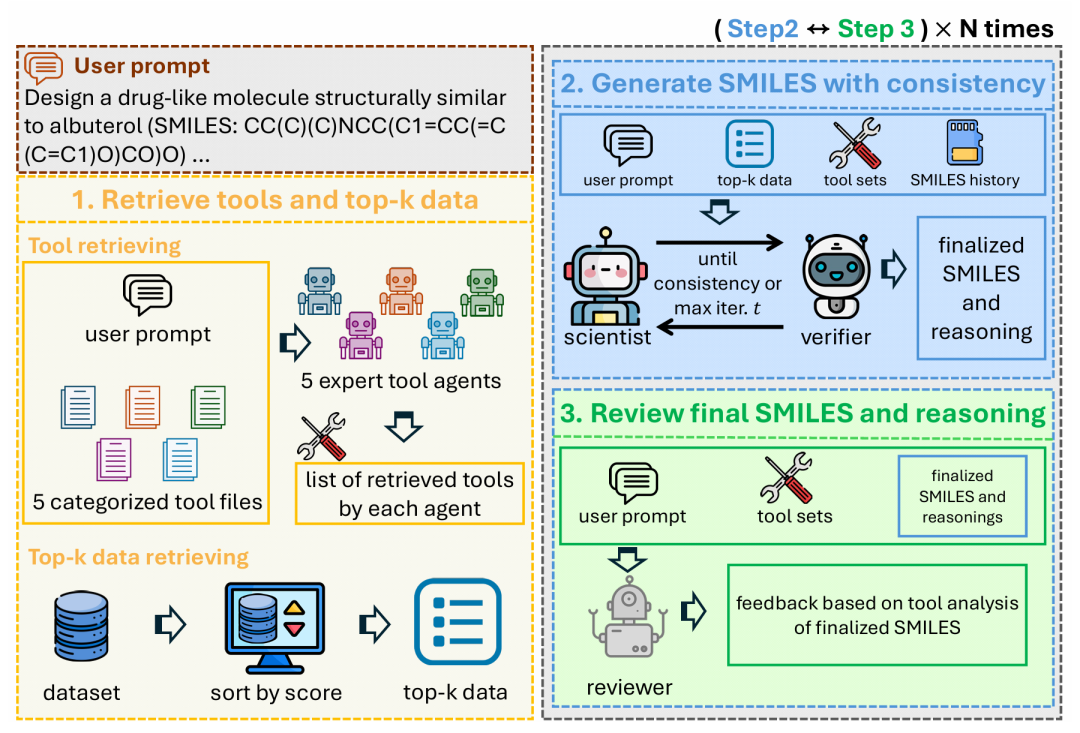
7. BiomedSQL: Text-to-SQL for Scientific Reasoning on Biomedical Knowledge Bases
期刊: arXiv 链接: https://arxiv.org/abs/2505.20321v1 代码: https://github.com/NIH-CARD/biomedsql
简介: 论文提出BiomedSQL基准,首次专门评估文本到SQL系统在生物医学知识库中的科学推理能力,包含6.8万问题/SQL/答案三元组,整合基因-疾病关联、组学因果推断等多源数据,要求模型推断领域特定标准(如全基因组显著性阈值)而非仅语法翻译。方法上构建基于BigQuery的统一数据库,通过领域专家标注黄金SQL并程序扩展数据集,评估多种提示策略和交互范式下的开源与闭源LLM。实验显示,GPT-o3-mini执行准确率59.0%,自定义多步代理BMSQL达62.6%,但均远低于专家基线90%。该研究为提升文本到SQL系统在生物医学领域的推理能力提供了标准化平台,推动数据驱动的科学发现。
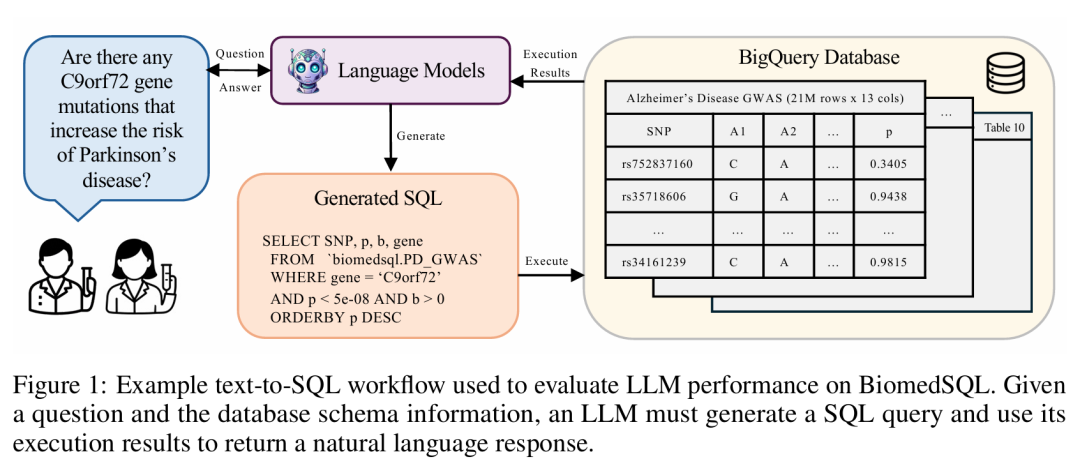
8. Ctrl-DNA: Controllable Cell-Type-Specific Regulatory DNA Design via Constrained RL
期刊: arXiv 链接: https://arxiv.org/abs/2505.20578v1 代码: https://github.com/bowang-lab/Ctrl-DNA
简介: 论文提出Ctrl-DNA框架,通过约束强化学习(RL)实现可控的细胞类型特异性调控DNA设计,解决现有方法难以平衡目标细胞活性与脱靶效应的问题。方法上结合拉格朗日正则化策略,在预训练基因组语言模型基础上迭代优化序列,最大化目标细胞调控活性同时抑制脱靶效应,并引入TFBS频率相关性正则化增强生物合理性。在人类启动子和增强子数据集上,Ctrl-DNA在17项任务中优于现有生成和RL方法,生成序列兼具高细胞特异性和结构折叠能力,例如在HepG2细胞中目标活性达0.49,显著高于基线。该研究为合成生物学和基因治疗提供了精准设计细胞特异性调控元件的新工具。
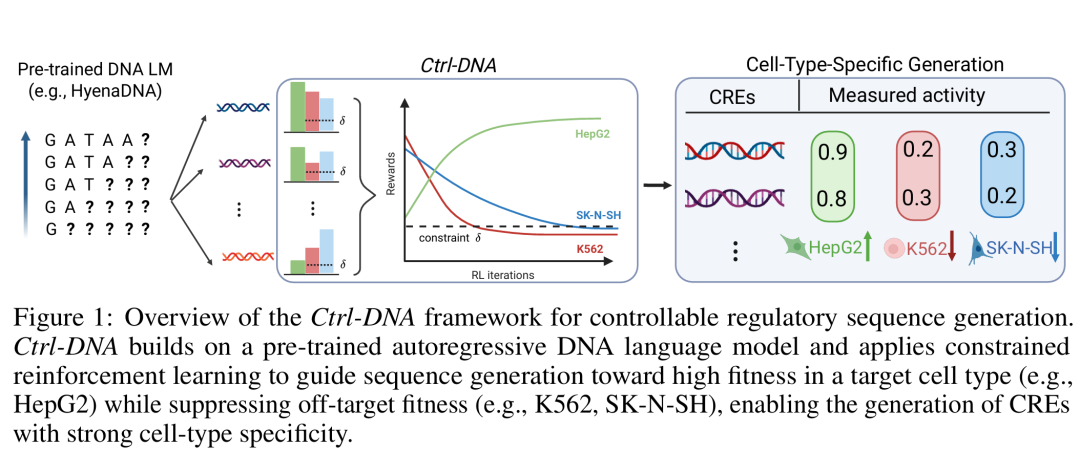
9. PDFBench: A Benchmark for De novo Protein Design from Function
期刊: arXiv 链接: https://arxiv.org/abs/2505.20346v1
简介: 论文推出PDFBench基准,首次全面评估功能驱动的从头蛋白质设计,涵盖描述引导和关键词引导两项任务,集成22项指标评估序列合理性、结构保真度、语言-蛋白质对齐等维度。方法上构建包含64万描述-序列对和55.4万关键词-序列对的数据集,评估五种先进基线模型。实验表明,Pinal在结构折叠和语言对齐中表现最佳(pLDDT达75.25,检索准确率41.83%),但关键词引导任务更具挑战性,所有模型折叠能力均不理想。研究揭示了不同指标间的相关性(如PPL与pLDDT负相关),为蛋白质设计评估提供了统一框架,推动功能导向的生成模型发展。
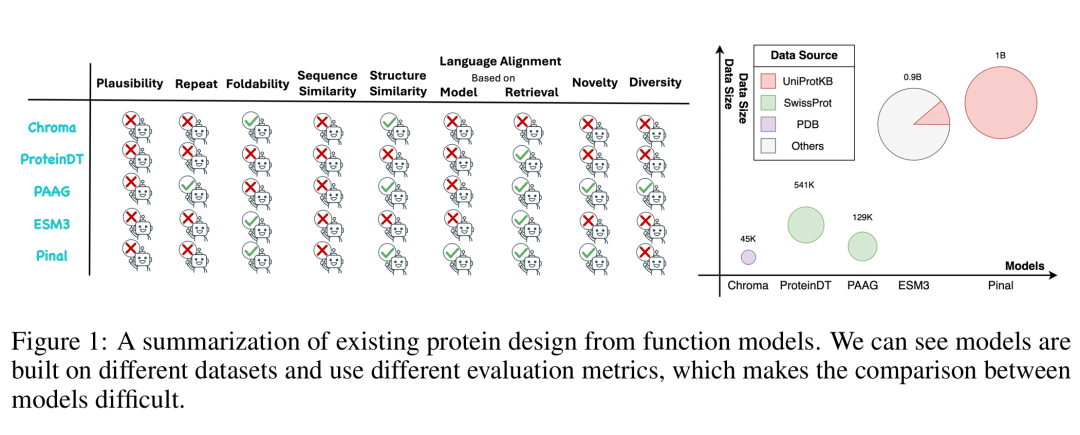
10. Transformer in Protein: A Survey
期刊: arXiv 链接: https://arxiv.org/abs/2505.20098v1
简介: 该综述全面分析Transformer模型在蛋白质研究中的应用,涵盖结构预测、功能注释、相互作用分析及药物发现等领域,强调其在捕捉长程依赖和多模态数据整合中的优势。方法上,通过梳理超100篇研究,总结了Transformer架构的改进(如AlphaFold的混合结构、ESM-Fold的无MSA设计)及其与生物知识的结合(如分子图嵌入、进化信号整合)。实验部分对比了不同模型在蛋白质结构预测(如CASP14中AlphaFold的GDT分数92.4)、功能预测(如ProtTrans的F1分数0.64)等任务的性能,并讨论了计算效率、数据偏差等挑战。该综述为Transformer与蛋白质信息学的交叉研究提供了系统框架,指出未来需在多模态整合、模型可解释性及跨物种泛化性等方向突破。
11. Fine-grained List-wise Alignment for Generative Medication Recommendation
期刊: arXiv 链接: https://arxiv.org/abs/2505.20218v1 代码: https://github.com/cxfann/Flame
简介: 论文提出FLAME框架,通过细粒度列表对齐和强化学习优化,解决多病症用药推荐中药物协同效应与相互作用(DDI)的平衡问题。方法上,结合分步组相对策略优化(GRPO)和潜在奖励塑造,将推荐建模为序列决策过程,同时融合结构化临床数据与LLM文本理解。在MIMIC-III等数据集上,FLAME的Jaccard相似度达0.4836,显著优于基线模型,且在DDI控制(如DDI率降低至0.05)和跨机构泛化(如eICU数据集F1分数0.64)中表现突出。该研究为临床决策支持系统提供了安全可控的用药推荐方案,推动AI在精准医疗中的应用。
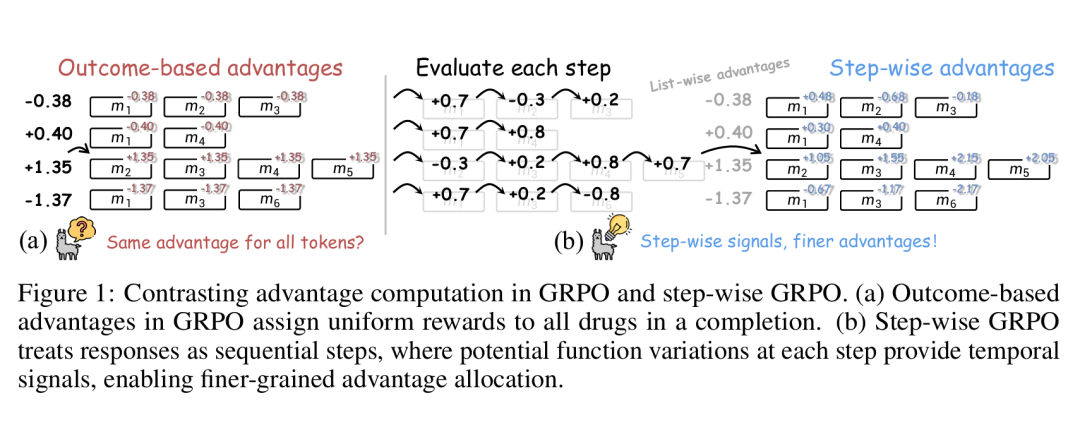
12. MolEditRL: Structure-Preserving Molecular Editing via Discrete Diffusion and Reinforcement Learning
期刊: arXiv 链接: https://arxiv.org/abs/2505.20131v1
简介: MolEditRL框架通过离散扩散与强化学习结合,实现分子编辑中结构保留与属性优化的精准平衡,解决传统字符串表示难以捕捉图结构约束的问题。方法分两阶段:先通过图扩散模型基于源分子和文本指令重构目标分子,再以编辑感知RL优化属性并维持结构保真度。在自建MolEditInstruct数据集(300万例,10类属性)中,MolEditRL的编辑成功率较基线提升74%,Fréchet ChemNet距离低至6.97,且参数用量减少98%。该研究为药物设计中分子优化提供了高效工具,尤其在多属性编辑(如LogP降低与合成可及性提升)中表现出强泛化能力。
13. ADGSyn: Dual-Stream Learning for Efficient Anticancer Drug Synergy Prediction
期刊: arXiv 链接: https://arxiv.org/abs/2505.19144v1 代码: https://github.com/Echo-Nie/ADGSyn.git
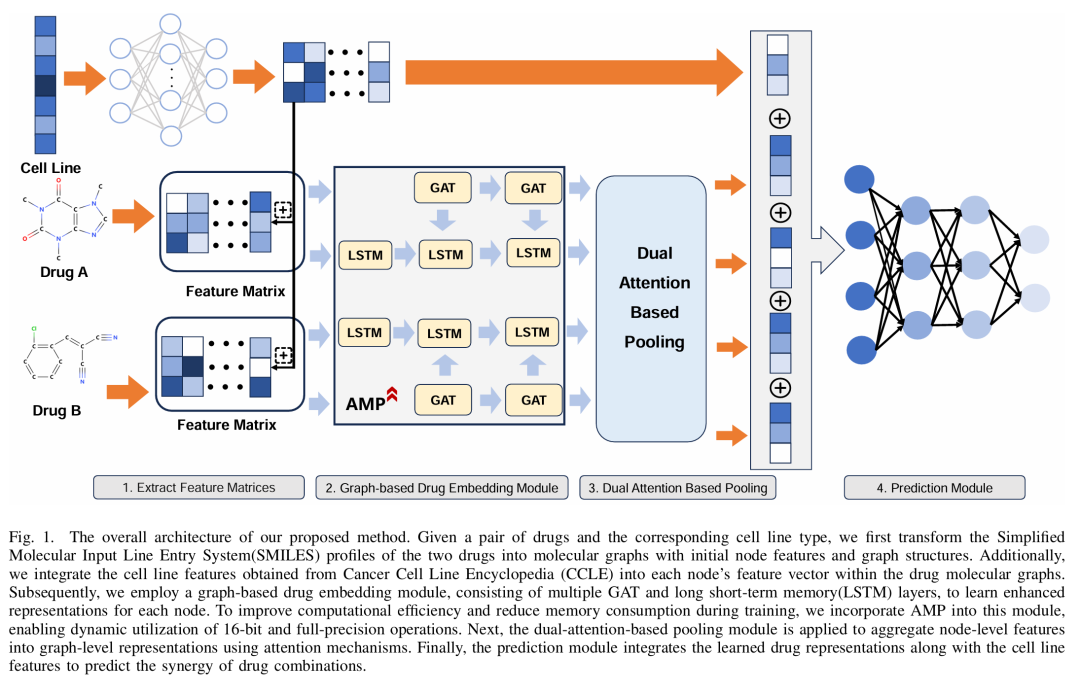
简介: 论文提出ADGSyn框架,通过双流学习结合图神经网络(GNN)与注意力机制,解决抗癌药物协同效应预测中计算效率低和特征对齐不足的问题。方法上,利用共享投影矩阵实现跨药物特征对齐,结合自动混合精度(AMP)优化图操作以减少40%内存消耗并加速3倍训练,同时通过残差路径和层归一化稳定梯度传播。在O’Neil数据集(13,243个药物-细胞系组合)上,ADGSyn的AUROC达0.92,Cohen’s Kappa系数0.72,显著优于8个基线模型,且支持单GPU全批量处理256个分子图。该研究为高效药物协同预测提供了新范式,推动AI在肿瘤药物发现中的应用。
14. Unfolding AlphaFold’s Bayesian Roots in Probability Kinematics
期刊: arXiv 链接: https://arxiv.org/abs/2505.19763v1
简介: 论文重新诠释AlphaFold1的物理势能函数为概率运动学(PK)框架下的广义贝叶斯更新,而非传统热力学势能。通过将氨基酸二面角先验与距离软证据结合,利用PK的杰弗里条件保持条件分布不变,实现对蛋白质结构的概率更新。在二维合成模型中,通过角随机游走先验和距离分布证据验证了PK更新的精确性,模型在保留局部结构信息的同时优化全局距离约束。该理论为AlphaFold1提供了更严谨的概率基础,揭示其与贝叶斯方法的深层联系,为蛋白质结构预测的不确定性量化和多模态数据融合提供了新视角。
15. FlashMD: long-stride, universal prediction of molecular dynamics
期刊: arXiv 链接: https://arxiv.org/abs/2505.19350v1
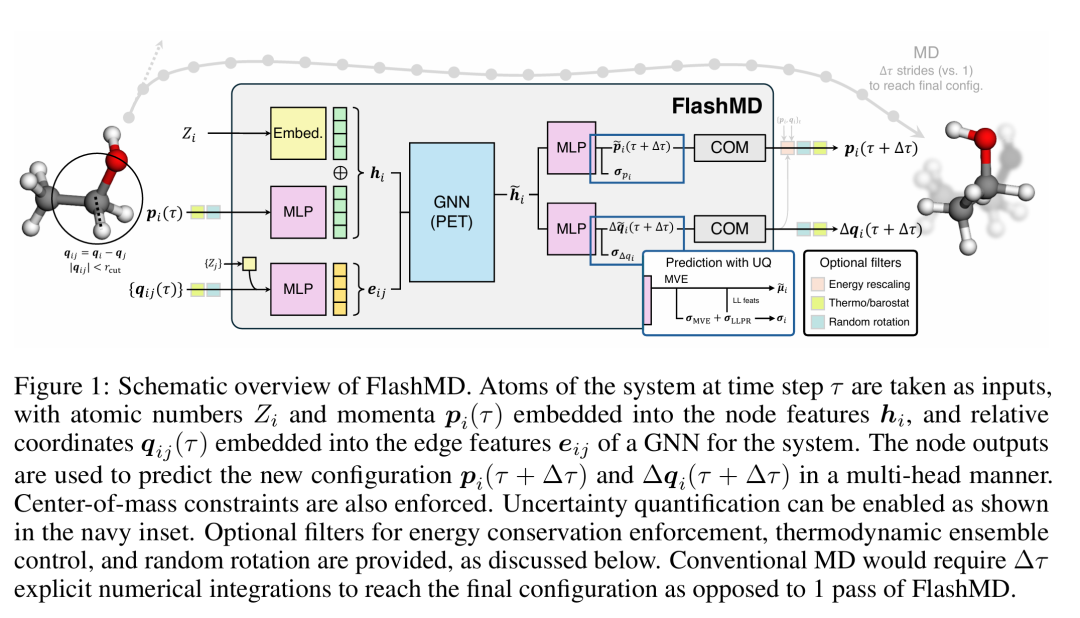
简介: FlashMD框架通过图神经网络直接预测分子动力学轨迹的长步长演化,解决传统方法因小时间步导致的计算效率瓶颈。方法融合哈密顿动力学的物理约束,通过质量缩放位置和动量、中心质量守恒及能量重缩放确保模拟稳定性,并支持任意热力学系综。在液态水、铝表面和硫化物电解质等系统中,FlashMD实现16-64 fs长步长预测,均方根误差低于0.01 Å,能量守恒误差小于0.1 eV,且在NV T和NpT系综中准确再现径向分布函数和扩散系数。该研究突破传统MD的时间尺度限制,为模拟复杂系统的慢动力学过程提供了高效工具,推动原子尺度建模在材料和生物领域的应用。
16. Conformal Prediction for Uncertainty Estimation in Drug-Target Interaction Prediction
期刊: arXiv 链接: https://arxiv.org/abs/2505.18890v1
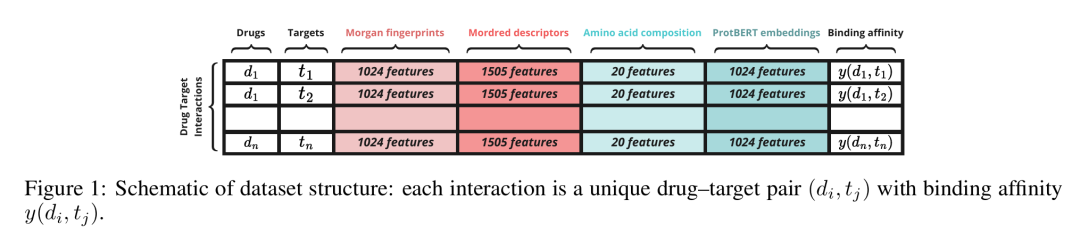
简介: 论文提出基于聚类的共形预测框架(CCP),解决药物-靶点相互作用(DTI)预测中不确定性估计的子群体覆盖不足问题。通过非一致性分数聚类(CCP-NC)、特征聚类(CCP-FC)和最近邻校准(CCP-NN)三种方法,结合梯度提升回归模型,在KIBA数据集上评估四种数据拆分策略。实验表明,CCP-NC在随机和完全未见药物-蛋白拆分中表现最佳,预测区间更紧凑且子群体覆盖可靠,例如在随机拆分中pLDDT>70的比例比基线高32.65%,PAE<10的比例高9.28%。该研究为DTI预测提供了更精准的不确定性量化方法,提升模型在稀疏或新场景下的鲁棒性。
17. Tokenizing Electron Cloud in Protein-Ligand Interaction Learning
期刊: arXiv 链接: https://arxiv.org/abs/2505.19014v1
简介: 论文提出ECBind框架,通过量化电子云信号为离散标记,结合原子结构和电子密度提升蛋白-配体相互作用预测的准确性。利用结构感知Transformer和分层码本将3D结合位点编码为标记,结合知识蒸馏开发轻量级模型。在MISATO、LBA和LEP数据集上,ECBind的预训练版本在相对结合亲和力预测中,每结构皮尔逊相关系数提升6.42%,斯皮尔曼相关系数提升15.58%,且电子云无关的学生模型性能接近教师模型。该研究为分子相互作用建模提供了量子化学特征与深度学习结合的新范式。
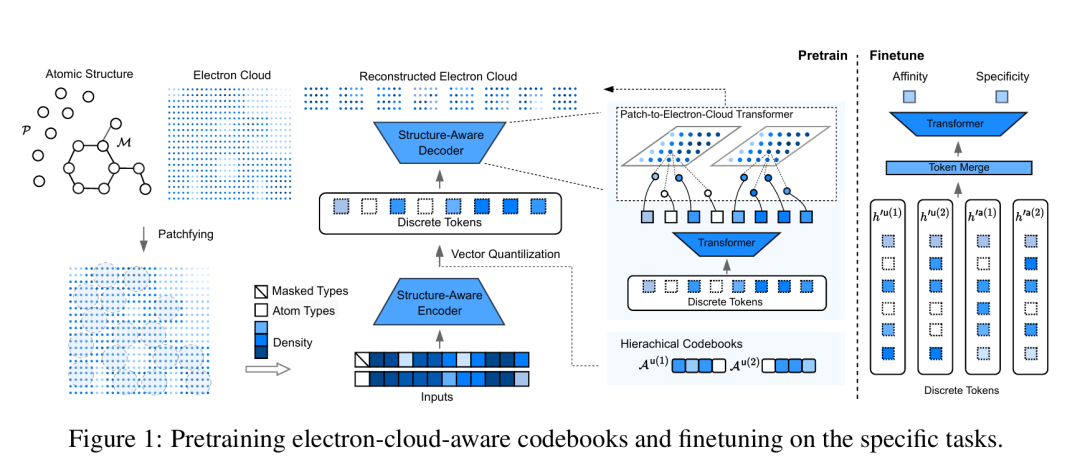
18. Protein Design with Dynamic Protein Vocabulary
期刊: arXiv 链接: https://arxiv.org/abs/2505.18966v1 代码: https://github.com/sornkL/ProDVa
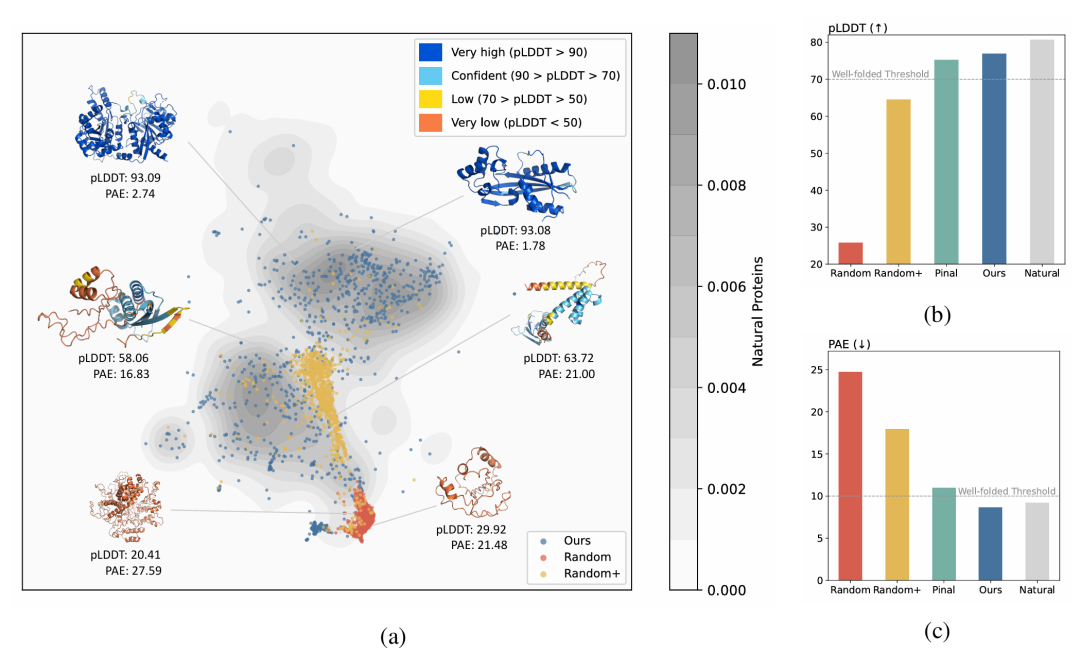
简介: 论文提出PRODVA框架,通过动态蛋白质词汇整合文本描述、蛋白质语言模型和片段编码,提升生成蛋白质的结构合理性和功能对齐性。利用InterPro提取功能片段,结合文本编码器和片段检索生成序列,在CAMEO子集和Mol-Instructions数据集上,PRODVA生成的蛋白质中pLDDT>70的比例比Pinal高7.38%,PAE<10的比例高9.6%,且仅用0.04%训练数据实现可比的功能对齐。该研究为基于自然语言的蛋白质设计提供了高效的生成框架,平衡结构折叠能力与功能特异性。
19. Artificial Intelligence for Direct Prediction of Molecular Dynamics Across Chemical Space
期刊: arXiv 链接: https://arxiv.org/abs/2505.16301v1
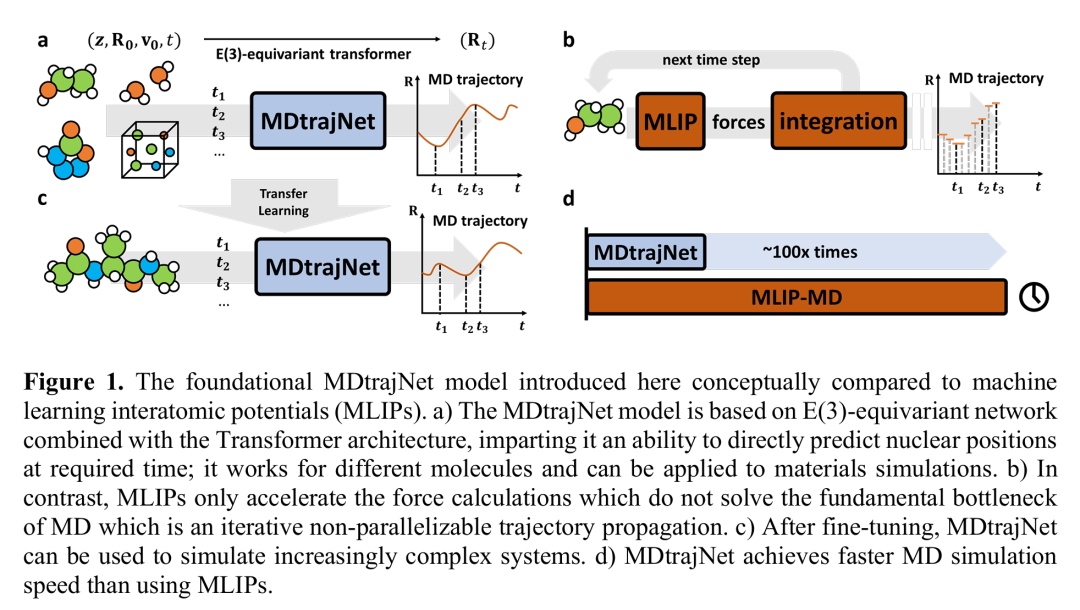
简介: 论文提出MDtrajNet-1模型,通过结合等变神经网络与Transformer架构,直接预测分子动力学轨迹,突破传统MD依赖迭代力计算的效率瓶颈。该模型利用四维时空建模,绕过力场计算和数值积分,支持多统计系综和周期性边界条件,实现对已知和未知分子系统的长时轨迹预测。实验在ANI-1xMD数据集上显示,MDtrajNet-1生成轨迹的误差接近传统从头算MD,在乙醇、金刚石等系统中,长时模拟稳定性优于机器学习势场(MLIPs),速度提升两个数量级。模型在迁移学习至丙氨酸二肽等更大系统时表现出良好泛化性,验证了其跨化学空间的适用性。该研究为高效原子模拟提供了新范式,推动复杂系统动态行为的快速预测。
20. CLaDMoP: Learning Transferrable Models from Successful Clinical Trials via LLMs
期刊: arXiv 链接: https://arxiv.org/abs/2505.18527v1 代码: https://github.com/murai-lab/CLaDMoP
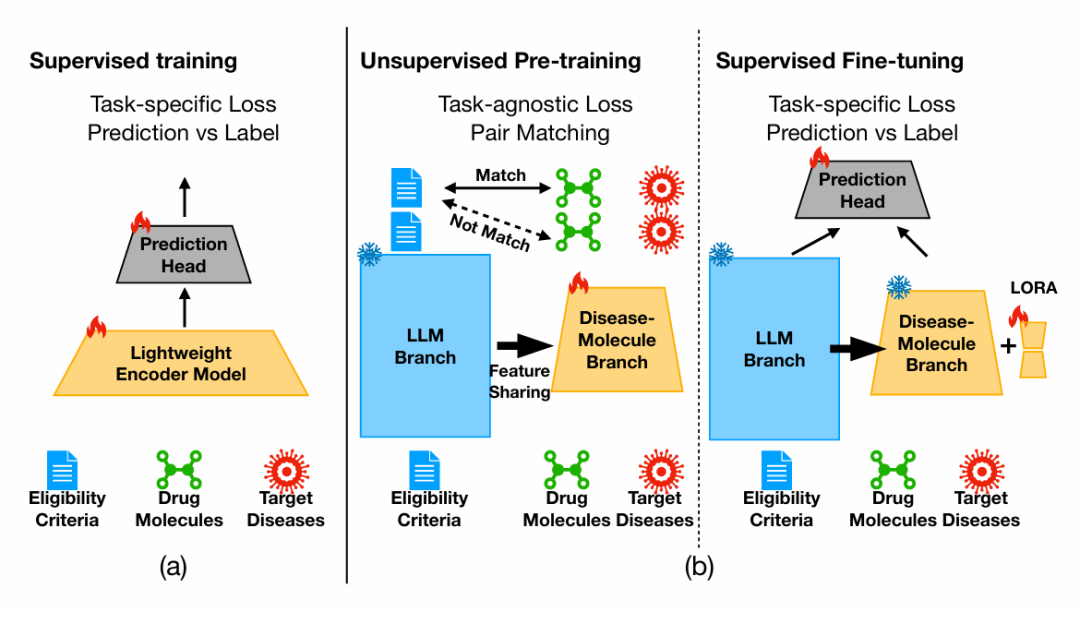
简介: 论文提出CLaDMoP框架,通过大语言模型(LLM)与轻量级药物-分子分支的多级融合,结合自监督预训练和参数高效微调(PEFT),提升临床试验结果预测的泛化能力。预训练阶段利用成功临床试验数据集(SCT),通过配对匹配任务学习任务无关表示;微调阶段引入LoRA层优化模型参数。在Trial Outcome Prediction(TOP)基准测试中,CLaDMoP在I/II/III期试验中均优于现有基线,PR-AUC提升10.5%,ROC-AUC提升3.6%,尤其在新疾病预测中准确率显著提高。该研究为临床预测提供了数据高效的迁移学习方案,平衡模型性能与计算成本,推动AI在医疗领域的应用。
21. Applications of Modular Co-Design for De Novo 3D Molecule Generation
期刊: arXiv 链接: https://arxiv.org/abs/2505.18392v1
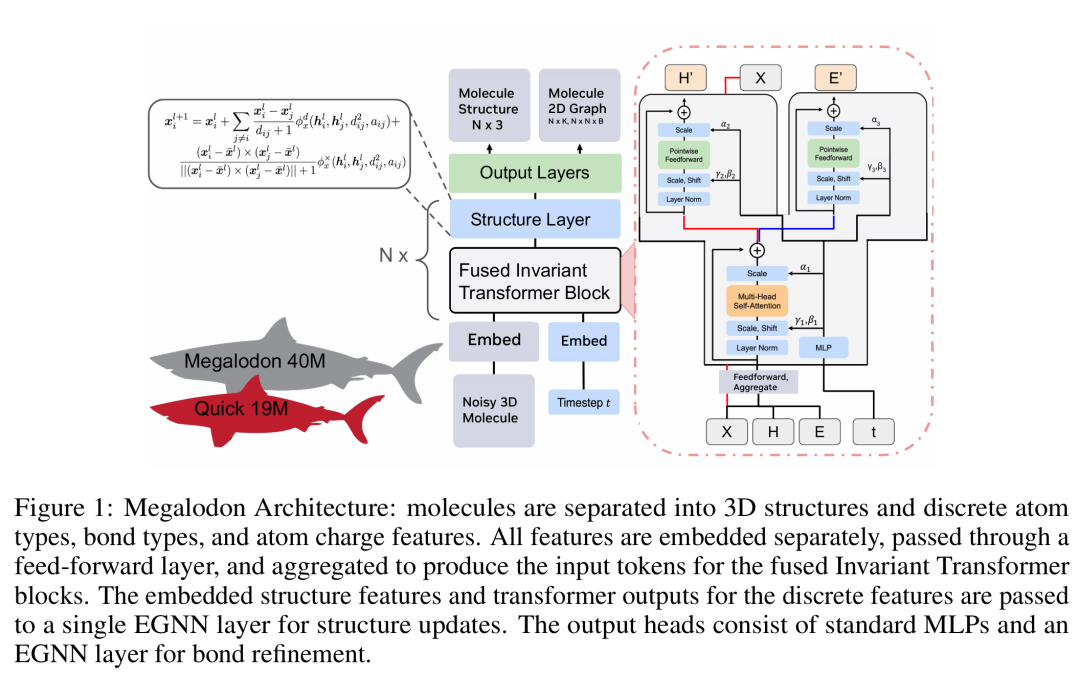
简介: 论文提出Megalodon模型家族,通过Transformer结合等变层和联合连续-离散去噪设计,实现高质量3D分子生成。模型支持无条件生成和条件结构生成,引入基于量子力学能量的几何基准,评估生成分子的稳定性和能量合理性。在GEOM-Drugs数据集上,Megalodon-40M生成的大尺寸分子有效性提升49倍,能量水平比现有模型低2-10倍,在扩散和流匹配任务中均达SOTA。实验表明,模型通过离散扩散和自条件机制,有效关联2D拓扑与3D结构,为药物发现提供了高效的分子设计工具,推动生成模型在化学空间探索中的应用。
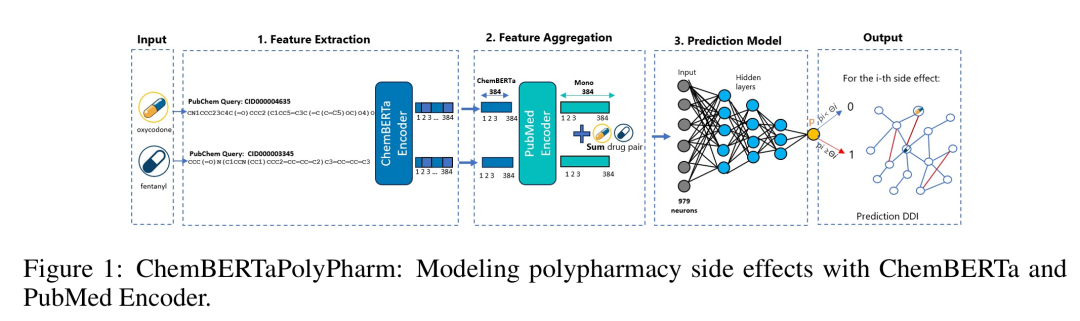
22. ChemBERTaPolyPharm: Modeling polypharmacy side effects with ChemBERTa and PubMed Encoders
期刊: bioRxiv 链接: https://doi.org/10.1101/2025.05.20.655109
简介: 论文提出ChemBERTaPolyPharm框架,结合ChemBERTa(化学分子结构编码器)和PubMed编码器(临床副作用文本编码器),通过深度学习预测药物-药物相互作用(DDI)及副作用。模型利用SMILES字符串提取分子特征,通过PubMed文本生成临床特征,经主成分分析降维后 concatenate 形成药物对特征向量,输入前馈神经网络进行分类。在TWOSIDES数据集上,该模型实现平均0.93的F1分数,显著优于Decagon、NNPS等基线模型,尤其在预测新药物对的DDI时表现出良好的泛化能力。研究表明,融合分子结构与临床文本数据可有效提升预测准确性,为药物安全评估提供了高效的计算方法,助力临床前药物相互作用筛查。
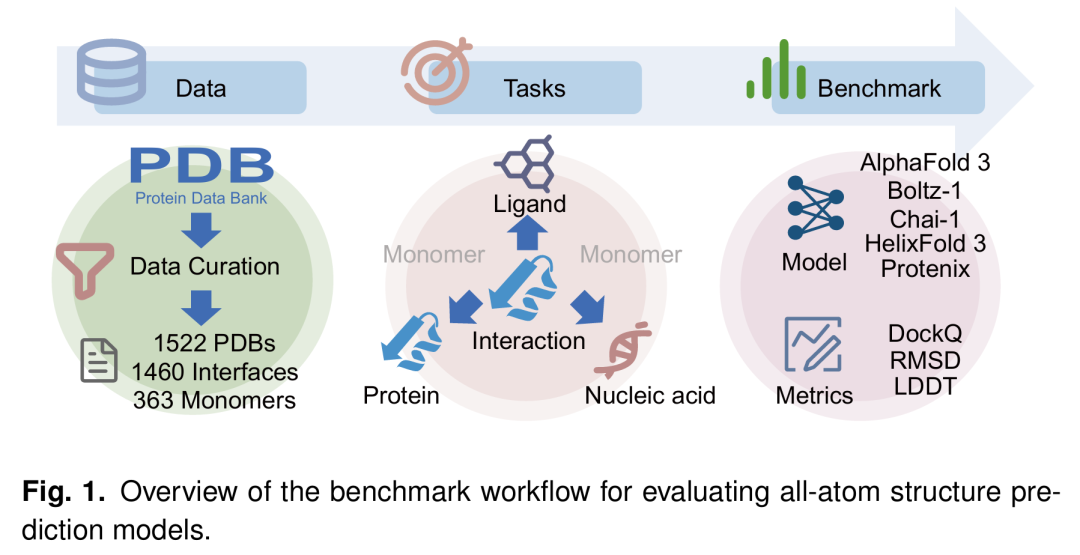
23. FoldBench: An All-atom Benchmark for Biomolecular Structure Prediction
期刊: bioRxiv 链接: https://doi.org/10.1101/2025.05.22.655600 代码: https://github.com/BEAM-Labs/FoldBench
简介: 论文发布FoldBench基准,包含1522个低同源生物分子组装体,覆盖9类预测任务(如蛋白质-配体、抗体-抗原、核酸复合物等),系统评估AlphaFold 3、Boltz-1等5种模型的全原子结构预测能力。实验发现,所有模型在配体相似性低时预测精度下降,抗体-抗原任务失败率超50%,而AlphaFold 3在多数任务中表现最优(如蛋白质-配体任务成功率64.9%)。核酸结构预测仍是短板,RNA单体平均LDDT仅0.61。该基准揭示了当前模型在动态构象捕捉和低同源数据泛化的局限,为未来模型优化提供了明确方向,推动多模态生物分子建模技术发展。
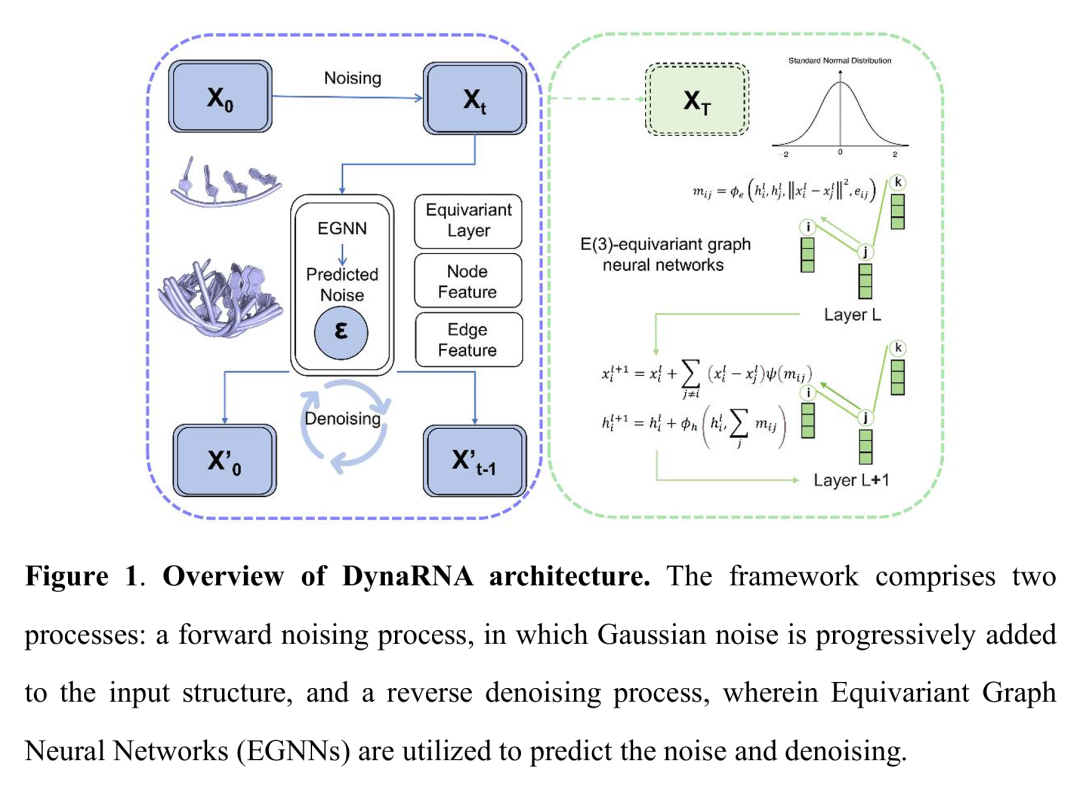
24. DynaRNA: Dynamic RNA Conformation Ensemble Generation with Diffusion Model
期刊: bioRxiv 链接: https://doi.org/10.1101/2025.05.22.655453
简介: 论文提出DynaRNA,基于去噪扩散概率模型(DDPM)和等变图神经网络(EGNN),实现RNA动态构象 ensemble 生成。模型直接对RNA的3D坐标进行建模,无需多序列比对,可快速探索构象空间。在四核苷酸、HIV TAR元件、四联体环等系统中,DynaRNA生成的构象 ensemble 与实验结果高度吻合,例如C4'-C4'距离分布与PDB数据一致,且在捕捉HIV TAR激发态(ES2)和四联体环从头折叠方面优于分子动力学模拟。与MD相比,其计算效率提升数个数量级,且能突破能量壁垒采样稀有构象。该研究为RNA结构动态建模提供了新范式,助力RNA功能机制解析和靶向药物设计。
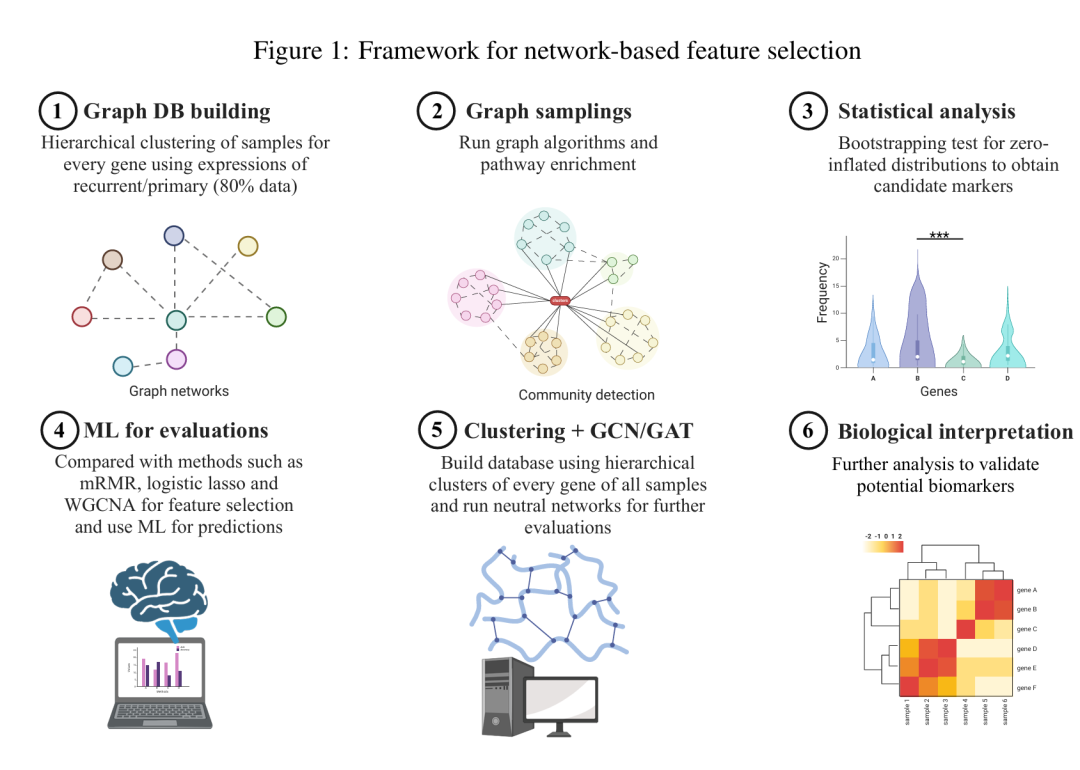
25. Expression Graph Network Framework for Biomarker Discovery
期刊: bioRxiv 链接: https://doi.org/10.1101/2025.04.28.651033 代码: https://github.com/yliu38/EGNF
简介: 论文提出表达图网络框架(EGNF),通过图神经网络(GNN)结合网络特征工程,解决复杂疾病生物标志物发现中高维基因表达数据的关联建模难题。该框架利用层次聚类构建基因-样本动态图网络,融合GCN和GAT进行特征提取与分类,实现生物标志物的统计显著性和功能相关性筛选。在胶质母细胞瘤、乳腺癌等三个独立数据集上,EGNF相比传统机器学习模型(如随机森林、SVM)分类准确率提升13.8%,尤其在正常-肿瘤样本区分中实现完美分离,且在治疗前后样本分类中AUC达0.926。其生成的生物标志物如PGR、CXCL14等具有明确生物学功能支持。该研究为精准医疗提供了可解释的高效生物标志物发现工具,推动基于网络的疾病机制解析。
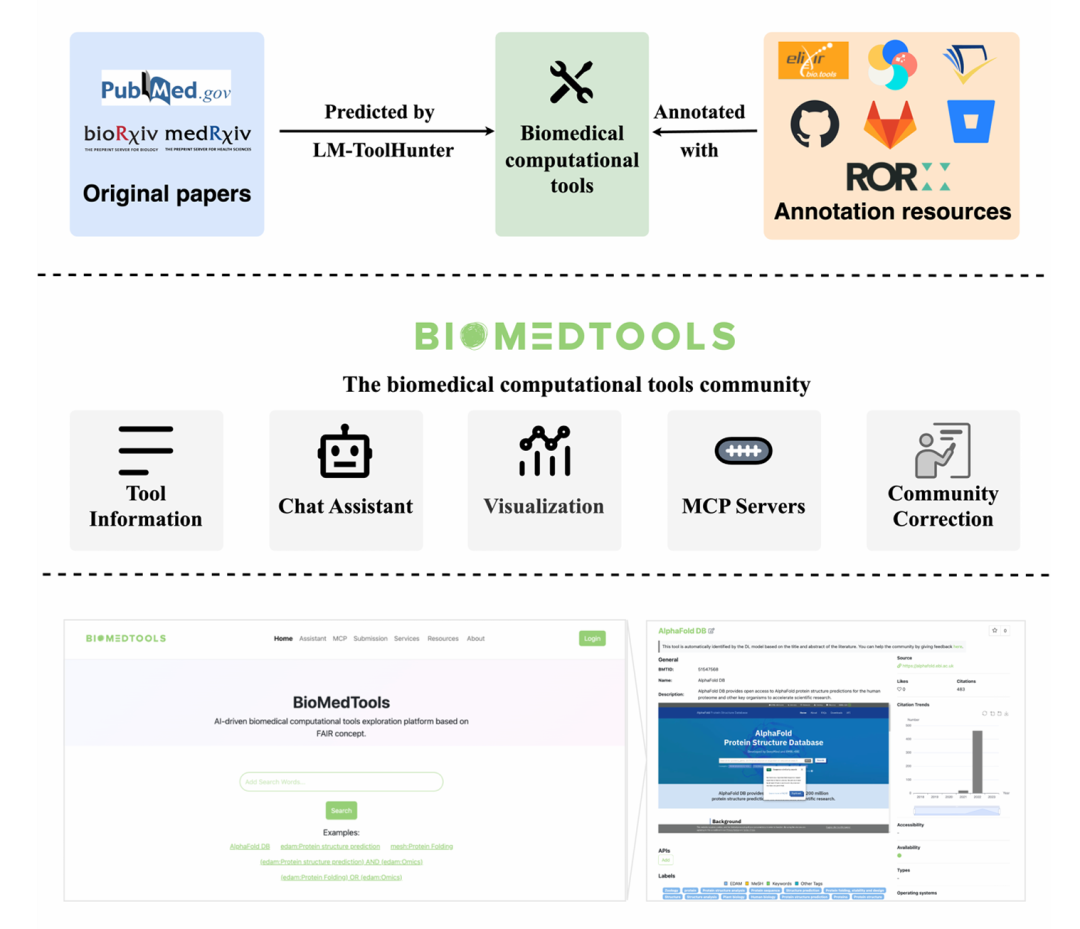
26. BioMedTools: a language model-powered community for biomedical computational tools
期刊: bioRxiv 链接: https://doi.org/10.1101/2025.05.02.651919
简介: 论文介绍BioMedTools平台,利用语言模型(LM)构建自动化生物医学工具社区,解决传统工具库更新滞后和数据不全的问题。通过LM-ToolHunter框架从文献标题和摘要中自动识别工具(分类F1分数0.966,实体识别F1分数0.905),集成多源数据(如bio.tools、Semantic Scholar)实现工具多维注释,并开发RAG驱动的聊天助手和MCP服务器中心以支持AI代理开发。平台收录493,647个工具,每日自动更新,在工具数量、更新频率和功能集成上优于现有平台(如bio.tools)。其构建的生物合成代理在青蒿酸合成路径设计中表现出优于GPT-4的准确性。该研究为生物医学工具的高效发现与智能化应用提供了新范式。
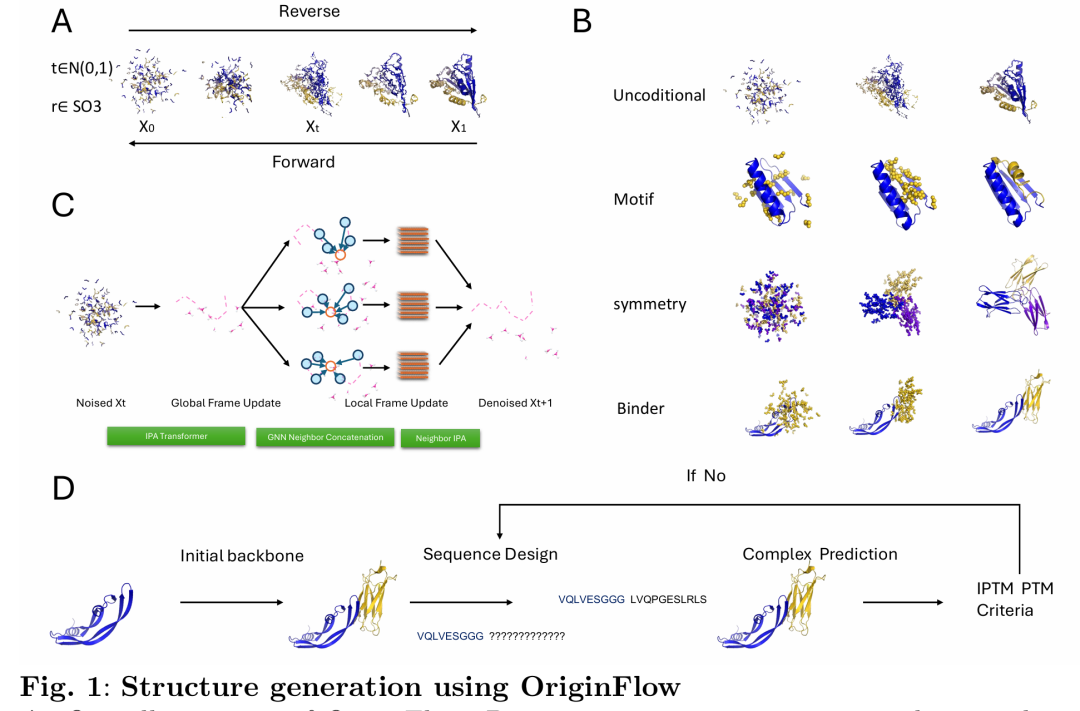
27. Robust and Reliable de novo Protein Design: A Flow-Matching-Based Protein Generative Model Achieves Remarkably High Success Rates
期刊: bioRxiv 链接: https://doi.org/10.1101/2025.04.29.651154
简介: 论文提出OriginFlow模型,结合随机微分方程(SDE)和流匹配(Flow Matching)技术,实现蛋白质从头设计中结构可设计性、多样性与功能设计的平衡。模型通过SE(3)空间的框架表示和全局-局部特征更新,支持基序支架、对称结构和结合剂设计。在17个基序设计基准中解决16个(RMSD<1Å),在PD-L1、VEGF等靶点的结合剂设计中,湿实验验证显示90%的表达、可溶性和亲和力成功率,KD值低至2 µM,显著优于现有算法(如AlphaProteo)。分子动力学和SPR实验证实其结构稳定性和结合特异性。该研究突破传统生成模型在功能设计中的瓶颈,为高可靠性蛋白质设计提供了新工具,推动AI在药物开发中的实际应用。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号