大数据没有凋零,将在 AI Agent 时代迎来“新生”

大数据没有凋零,将在 AI Agent 时代迎来“新生”

苏奕嘉
发布于 2026-01-06 14:15:13
发布于 2026-01-06 14:15:13
引言
自2021年左右开始,大数据这个领域的从业者都真切的感受到了来自行业的“正规化”和“寒意”,所谓正规化就是用更多“价值”和“意义”给业务阐述明白更多“自证价值”的故事,而寒意就不用多言了,一路走低的薪资水平以及越来越少的工作岗位,无一不预示整个行业已经开始走下坡路了。

但自今年起深度的参与到 AI 这个赛道以后,尤其基于原本的 OLAP 数据库多年经验,两者结合做 AI4Data 的各种尝试以后,我开始反思和重新梳理,整个大数据领域的未来路途是否真的会犹如土木工程行业一样,陷入长期的泥泞和沼泽?
经过一年的实践和思考,尤其在我加入亿问以后,这件事逐渐清晰起来:
大数据只是陷入了周期性的低谷期而已,后续将再次起身迎来一定时长的好日子。
且容我娓娓道来。
企业需要什么 AI ?
时至今日,AI 领域在各行各业的活跃范畴,更多的集中在了多模态创作、信息检索、AI Coding这几方面,而这些方面其实对传统的企业而言,收益比在当前看来,很低。
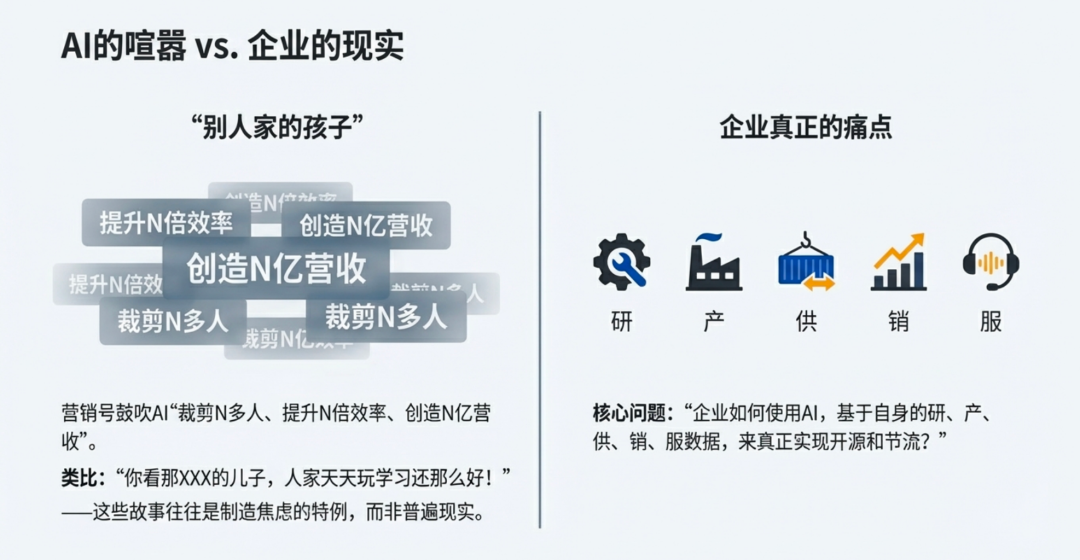
很多营销号都在吹嘘什么某个 AI 产品给企业带来了翻天覆地的变化、裁剪了N多人、提升了N倍效率、创造了N亿营收等等,然后老板对你痛加指责,对数据部门叕一次失去了信心,但是从大家在这个行业或者结合自己公司的情况来分析一下,是不是有一种似曾相识的感觉:
“你看那XXX的儿子,人家天天玩学习还那么好,还那么听话,你天天吃的好喝的好,连个学习都学不好!”
懂了吧?
其实绝大多数无非就是一些制造焦虑和吸引眼球来引流罢了,邻居家的孩子永远是一个谜,假设你真正的找到了某个孩子满足画像,那从与诸多企业技术/业务负责人沟通下来以后,仅能说明这样的企业真的只是特例而已,千里存一已是高比例,而且这些特例往往都是新兴企业,所以我建议大家考虑“企业需要什么 AI”时,是从自身企业、从普罗大众、从大数定律上去看待问题,而不是找特例。
好,那我们再回过头来看这个问题,或者把问题换一种更精细的问法,可能就更有指向性了:
“企业如何使用AI,基于自身研、产、供、销、服五类的数据,来开源和节流?”
无论是传统制造业、互联网企业,还是泛金融、泛服务型企业,其实在过去一二十年里,大家都深切的意识到了“数据”资产对整个企业运营将带来巨大的收益,所以按企业发展的时长,也是轰轰烈烈的掀起了“信息化”->“数字化”->“数智化”的多轮基建改造工程。
但是仅意识到和真切拿到了这个收益的企业比例,数量悬殊还是非常大的,很多企业忙活半天,发现自己连集团内统一化构建数仓都是奢望,也有很多企业构建了数仓并没有真正产生业务价值,被逼多次自证价值以后,开始自我怀疑:这不也就那样?也没见有啥收益啊?
而真正做到了的企业,又在烦恼如何将数据分析的能力赋能给更多的一线和二级主管,想基于一个已经良好的基座来扩大整个收益面,所以的确是各有各的烦恼。
可是没有人否定数据的价值:无论是人工抄录保持风度,还是AI4Data赶上潮流,大家都确信数据的价值和意义,但在当下阶段的 AI 时代,对企业内数据经营分析这个诉求,又衍生出了两个派别:
- 1. 坚信基于 Transfromer 的模型随着大力出奇迹的迭代方式加持,一定能诞生出完全无幻觉的通用大模型,或者逼近无幻觉这个目标的通用大模型来解决大模型当前处理数据困难的问题
- 2. 认为由于 Transformer 本身基础是以概率论为基座的,所以从本质而言,它永远没法做到100%准确,所以应当使用其他技术路径来填补这一块的能力,然后结合大模型泛化能力做二者结合的架构模型来解决这个问题
前者是业务方的妥协,后者是技术方的不屈,而我个人,倾向于第二种。
当前 AI4Data 领域没有很好的落地效果的根本原因是因为信任关系:无论你给 LLM 输入什么,他都能给你输出一段 Bbox 来助兴。
而业务方对数据准确度的渴望,是容忍不了这种戏谑在内的。

同时数据的准确性这个定义也是有商讨的价值的:
- 1. 比如准确的是100万这个值,查询出的结果是105万,那是一种由于数据质量或者查询逻辑导致的值准确性问题
- 2. 比如准确的是100万这个值,查询结果是3%,那这就是由于幻觉引发的语义准确性的问题
前者如果说有95%、且浮动误差在10%以内的准确率,大部分的业务同学或者领导是能接受的,因为绝大多数数据运营场景,都是看一个趋势和大数,往往不会特别要求一定要100%无误(当然这个是数据人永恒追求的目标)。
如果后者准确度95%,那给业务方和领导的体感就是:这玩意是个玩具,扯什么犊子上生产?
因为只是数据值误差,业务部门经过这么多年“数据可能有一定时效性误差”的心理建设下,是能接受的。
但幻觉误差,业务部门只会觉得自己在用一个类GPT的大模型玩具,而数据讲究的就是要准确,不是似是而非。
所以综合而言,如果大数据想要在 AI 时代赶上潮流,幻觉问题一定要解决,解决思路也一定要对,不要尝试使用魔法(LLM)打败魔法(取数幻觉),这种只会让系统熵增,无法实现最终的零幻觉取数目标。
那最后我们来回答标题的问题:企业核心需要能保证零幻觉的 AI Data Agent 来提升自己的业务 ROI 收益。
构建企业级的 AI Data Agent 需要什么基建?
资源需求分析
2025年大家往往都称之为 AI Agent 元年,无论是由于基建的蓬勃发展,还是因为编排应用技术的成熟,像 Dify、Coze、n8n 等一系列 Agent 编排平台工具,在 25 年成功的普及到了诸多大大小小企业和团队中,还有像 MCP、A2A、Skills 等各种增强 LLM 的独立技能模块,也在火速发展。
这些应用中,消耗的最大资源其实是 Token,也就是我们说的 GPU 资源,反而对 CPU、Mem、IO 等传统意义上的计算机资源消耗不是那么大了(自建算力中心除外,只论AI应用本身),但是在数据领域,对这些资源消耗的趋势是怎样的?也一样会变少下滑么?
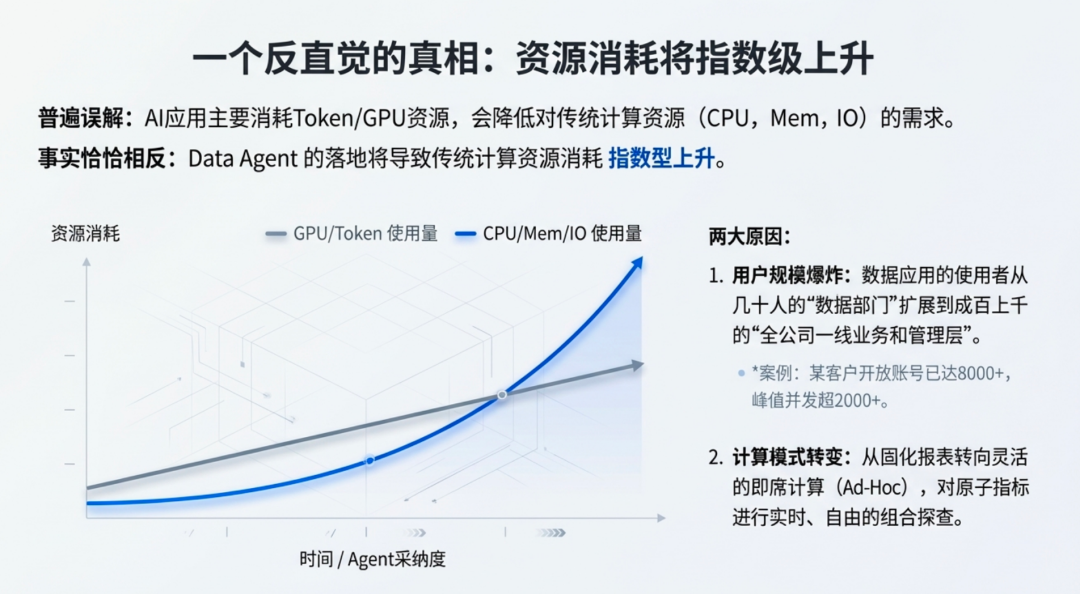
其实恰恰相反,随着 Data Agent 的落地和发展,传统计算机资源的消耗,也会指数型上升,原因有两个:
- 1. Data Agent 带来的最大变化,就是希望数据应用的适用人群从“数据部门”这个带有专业背景知识、专业技术能力的小规模专家群体,演变为全领域、全公司一线业务以及所有管理层的非专家群体,人数从几个、十几个变成几百上千个,如亿问的一个老客户,现在开放的账号已有8000+,最高峰值并发超2000+,日均并发也在500+
- 2. 计算指标的灵活编配,带来的风险是对业务方开放的指标集市更原子化,希望能通过实时的即席计算能力来满足业务上的数据探查能力,这时候对整体Ad-Hoc的查询资源要求就比较高了,虽然我们可以通过物化视图等方式来固定一批临时查询,降低资源消耗,但是总体而言,抵不住数量上的猛烈增加带来的成本提升
所以肉眼可见的,从资源量上而言,AI Data Agent 基建的第一个重要特征就是会大幅度增加物理资源的消耗,这时候有人就有新的疑问了:
我为什么不直接基于已有数仓的分层架构以及血缘关系来构建指标层,然后指标的复用性也上来了,整体资源消耗也会大幅度下降,跟你讲的完全是两个结果啊。
那回答这个问题之前,我们从另一个角度来看看,如继续沿用过往数据仓库构建的逻辑,那在构建过程中,另一个有比较明确的重要议题——数据治理所带来的困扰如何破局 值得我们讨论。
开发维护及业务易用性需求分析
需要数据治理的根本性原因,一方面是大量临时取数逻辑带来的负增长,一个是在日常分层构建的过程中,因为各种奇怪的原因(赶进度、上游改动变化、新业务条线增加等等),导致很多临时的技术债带来的负收益,这两个负增长和收益给数仓的冗余化带来了极高的成本:维护和优化。
所以如果你的 AI Data Agent 还是需要人工先行完成从原子指标到聚合指标/派生指标到构建,再交由业务部门进行加工以后的指标问答取数,以及进一步的业务探索答疑,那我个人认为这种做法完全误解了 AI Data Agent 适用的场景和基建平台应具备的能力,因为这种所谓的 Data Agent 平台,本质上跟做了一个BI看板或者预加工以后的报表,通过自然语言的规则匹配然后返回相应的结果集没有任何差别。
对业务而言,反而我还得自己去问,而不是一股脑给数据部门提需求等着就行了,这也是绝大多数公司在探索 Data Agent 过程中阻力最大的点,根本原因就是因为没有考虑清楚基建以及架构的构建应该是怎样的才能贴合业务需求或者心理去建设。
故此我认为这两个根本原因会随着数仓的进一步进化而得到根本性的解决,并不是年复一年,日复一日的治标不治本的梳理。
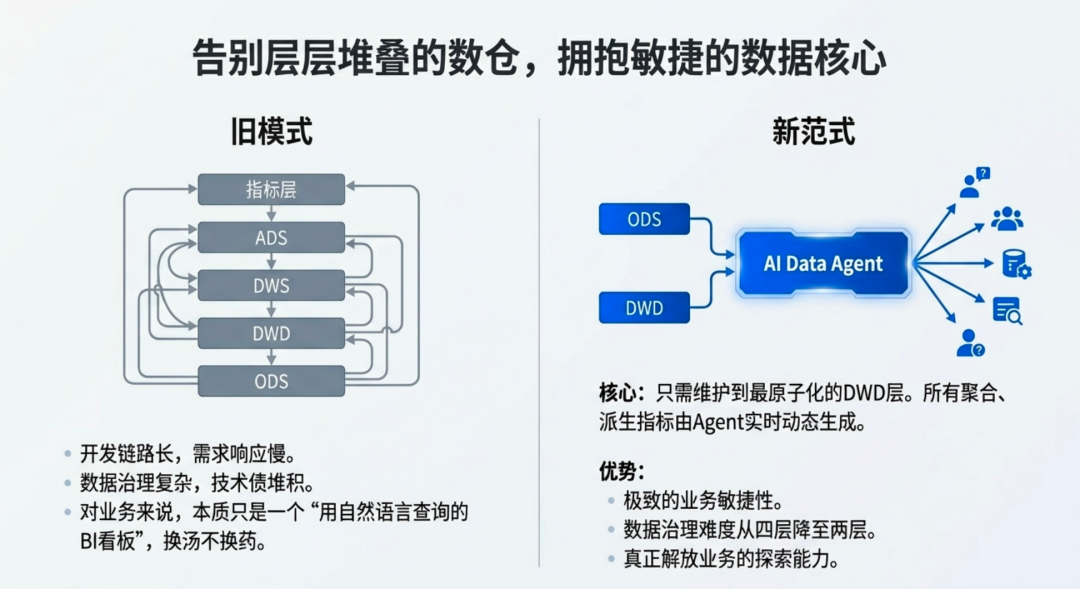
解决方案就是只需加工 ODS -> DWD 层,维护好最原子化的 DWD 层原子指标以后,其余的聚合指标、派生指标等,都交由 Data Agent 自行完成加工和构建,至于指标复用性的问题,可以通过自动构建物化视图,然后使用透明加速等特性来优化。
这样做的好处有几个:
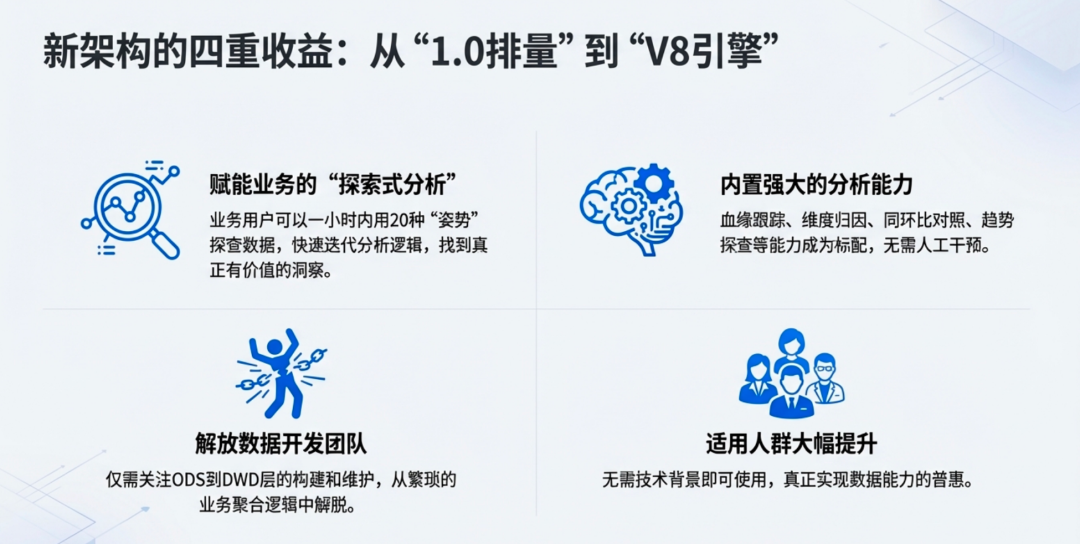
- 1. 业务方需要的其实是能快速获取按自己加工逻辑进行计算以后的结果,这个结果在没有看到之前,其实业务一般也不知道自己拿到的这个指标对自己接下来的分析到底有没有用,可能这个分析需要随着结果反过来多次调整计算过程才能获得最终的数值,而传统数仓是绝对做不到在高时效性、低人力投入的前提下,满足业务的这类诉求。而使用上述解决方案,所有的计算逻辑中血缘跟踪、维度归因、同环比对照、趋势探查等能力,就直接满足了,业务可能一小时时间使用20种姿势得到了自己在业务上真正提供帮助的结论数据,效率比起之前的传统数仓,不止高多少倍。
- 2. 开发同学仅需关注ODS到DWD层的构建即可,维护好原子指标的一致性,再维护好每日统计以后真正复用性高的查询自动构建物化视图即可,数据治理的难题从四层降至两层,而且还是更基础的两层,无需关注业务聚合逻辑,治理难度极大的降低。
- 3. 适用人群大幅度提升,无需技术背景即可完成探索式数据的获取,虽然这个是所有 Data Agent 都宣称的基础能力,但是就犹如两缸1.0排量和美式大V8发动机一样,都叫发动机,但是性能、效果完全不一样,一方面是真正的低延迟、零幻觉、自由探查、可维度归因等能力要具备,另一方面是如何保证使用方不觉得这只是把原有数据部门该干的活丢给了自己,别做到最后既没功劳又没苦劳。
当然坏处就是一方面,数据基建部门要认真的考虑,当前企业领导对 AI Data Agent 是政治任务居多,还是实实在在想得到一个良好结果的?同时也要考虑,当下的每一步往 AI 方向踏的道路,是不是正确的、长远的?如果不是,那沉没成本加技术债垒起来的山,可能会某一天崩盘以后砸死我们自己。
准确性需求分析
除去资源、开发、易用性上而言,最基础的核心,应该是零幻觉。
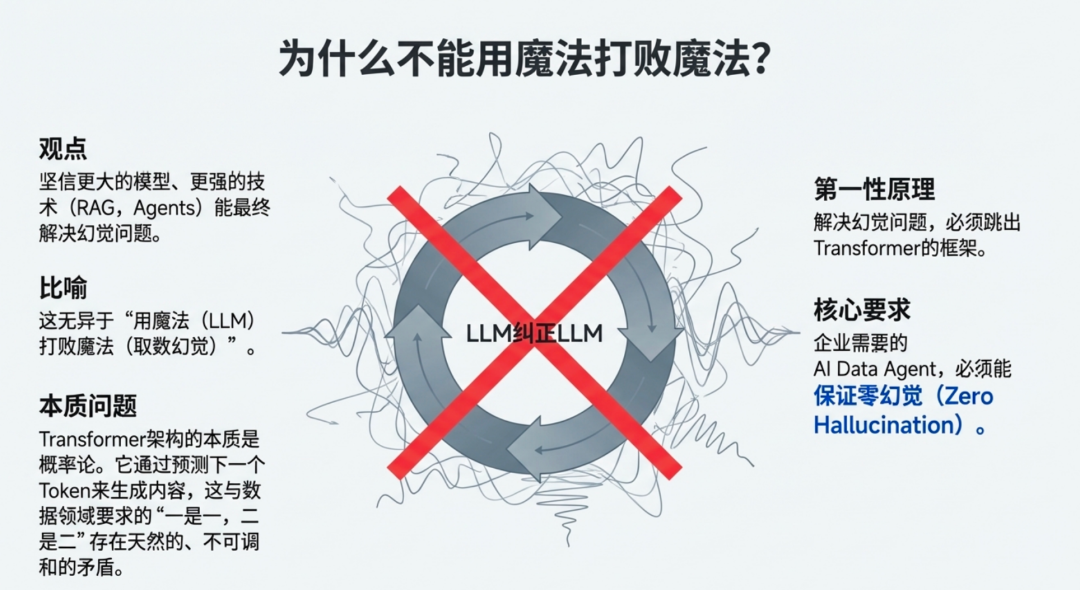
如果你只是希望构建一个平替或者补充当前 BI 场景的一个能力,市面上可选项很多,准确率高不高且不说,反正产品是挺多的,很多概念里:LLM + BI = ChatBI 这套公式是“易于大众理解”且“易于产品实现”的,但实际落地了半年一年以后,才发现路子走错了,随着时间的推移,又成了一个技术债,然后公司无论是管理层还是业务方,都顺理成章的把问题丢给了数据基建部门——你们做的什么玩意?
所以我觉得在这里需要跟大家去探讨,或者说看看在我的视角应该如何拆解这个问题,如何真正的去实现或者设计在企业里能上生产、满足 AI Data Agent 的数据基建工程。
首先第一步,就是一定要做到零幻觉。
前文中我们提到,所谓的“不准确”其实应该分成两个模块讨论,一个是值的准确性,一个是有无幻觉的问题,前者是数据治理的范畴,后者是大模型自带的天赋,很多人在强调:基模的威胁对上层应用而言是致命的,一旦他们解决了幻觉这个问题,那上层所有的数据应用工程都将死翘翘。
我说:为什么现在没有?或者为什么能确信以后一定做得到?
一部分人就开始用很多新兴的技术工具来作为论据支撑自己的论点,诸如使用 MCP、Skills、RAG、A2A 等等,又或者以多模态的迅捷发展(图片、视频、音频等)来说明以后幻觉这条路子一定是能被解决的。

其实我觉得段总讲的一个逻辑非常正确:我们应该去看每一件事物的本质是什么,而不是用更多的新概念来去试图理解。
当前 LLM 基于 Transformer 去做的,本质就是概率论作为基础,通过不断计算词根概率来预测下一个Token是什么,然后持续输出,这本质上和要求一是一、二是二的数据领域天然就有隔阂,所以我认为,如果要做到数据领域的绝对准确,就别依赖 Transformer 这一套,而是用思维链、图计算、知识图谱等技术去解决这个问题。
这里不是讲LLM在 Data Agent 中没有作用,而是它的作用点不在这里,它真正的作用点是泛化理解力、基于零幻觉数据的业务洞察力,两者互相不矛盾,反而应该是更精密结合的状态才对。
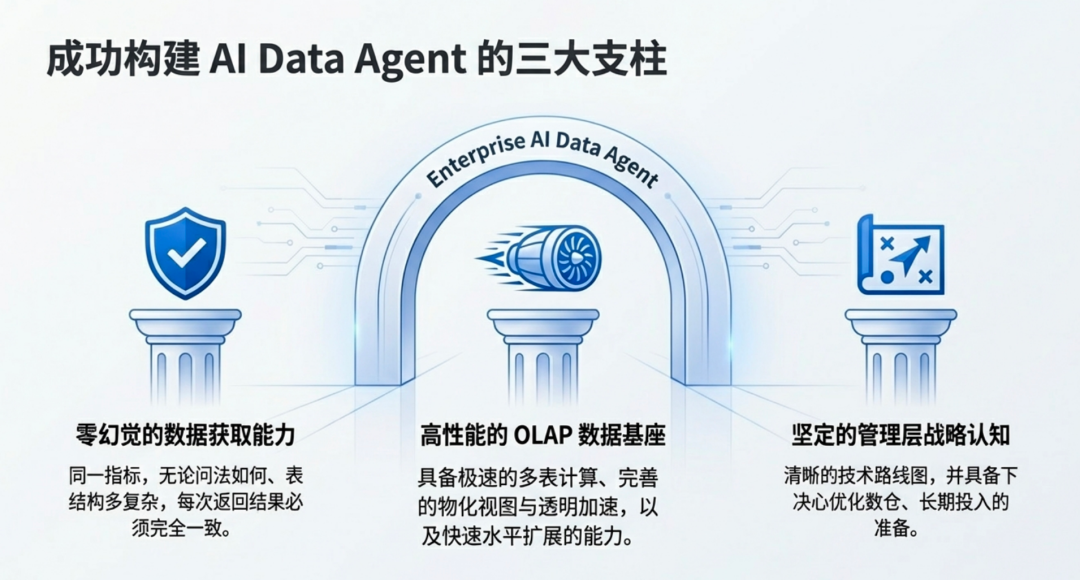
所以综上,构建企业级的 AI Data Agent,需要的是:
- 1. 零幻觉的数据获取能力(同一个指标提问,无论是大宽表还是多表关联,无论问多少次都应该完全一致才对)
- 2. OLAP 的数据基建基座,除单、多表的快速计算能力外,还应该具备相对完善多表物化视图及透明加速的能力,以及快速水平拓展的能力
- 3. 公司/集团管理层的战略认知要到位,对数据部门不要过多苛求,但是要同数据部门搞清楚未来的最佳技术发展路线,以及当下选择的技术栈和产品是否具备后续的迭代优化空间,而且要具备下决心优化数仓的准备
结语
写到最后,我想给所有还在大数据迷雾中徘徊的同行们一个“醍醐灌顶”的定论:
大数据从来没有凋零,凋零的只是“手动取数”和“被动报表”的旧时代;大数据正在应运而生的,是作为 AI Agent “行动中枢”和“决策大脑”的新纪元。
过去十年,我们把数据当成 “数字档案”。我们清扫它、存储它、膜拜它,然后卑微地祈求业务方在那堆尘封的数字里发现一丝价值。这种“伺候数据”的模式,在经济下行、效率至上的今天,必然会迎来寒冬。
但在 AI Agent 时代,大数据将完成向 “数字生命” 的关键一跃。
当 Agent 不再只是一个聊天窗口,而是能够自主调动企业 ODS/DWD 资源、自我完成维度归因、自动构建物化加速、且保证零幻觉地输出决策逻辑时,数据就不再是死寂的记录,而是流动的血液和跳动的大脑。
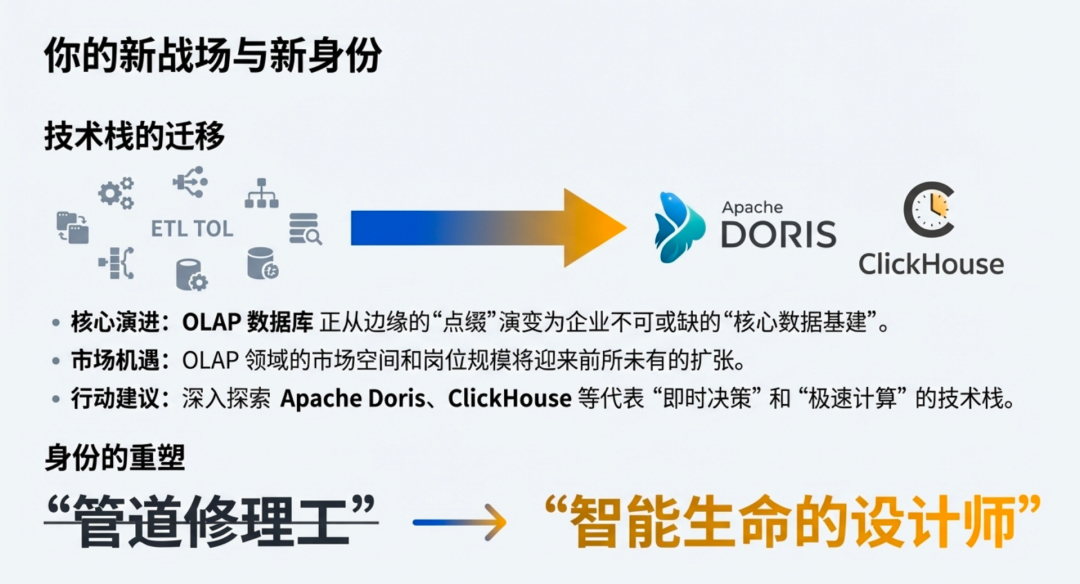
在这个进化的过程中,OLAP 数据库正从边缘业务的“点缀”,快速演进为企业不可或缺的“核心数据基建”。
原本只是为了看几个实时大屏而引入的 OLAP,如今已成为 Agent 实时感知世界、灵活调用指标的核心基座。这也意味着,大数据领域的市场需求并没有消失,而是发生了深刻的迁移——OLAP 这一分支的市场空间和岗位规模将迎来前所未有的扩张。
所以,我强烈建议那些准备在这一行继续深耕、继续卷下去的同学们,不要只盯着传统的离线 ETL,去更多地探索 OLAP 的实践与应用。无论是 Apache Doris( 必须首选 ^v^) 还是 Apache Doris(次选也要是 ^v^),这些代表着“即时决策”和“极速计算”的技术栈,才是你未来在 AI 时代保值增值的核心利器。
如果你还在纠结于 SQL 的技巧、还在迷茫于数仓任务的冗余,请抬头看天:未来的数据人,不再是“管道修理工”,而是“智能生命的设计师”。
那所谓的“新生”,不是指大数据岗位的数量回归,而是指数据价值密度的指数级爆发。当数据真正实现“零幻觉”的自由探查,当 AI Agent 能够像呼吸一样自然地吞吐大数据资源,那个已经被嘲笑为下一个“土木工程”的行业,将会在 AI 的加持下,焕发如核裂变般璀璨的第二春。
这,才是大数据在 2025 年之后,本该有的样子。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-18,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Apache Doris 补习班 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号