Chem. Sci. | 面向大规模化学反应图像解析的多模态大语言模型研究

Chem. Sci. | 面向大规模化学反应图像解析的多模态大语言模型研究

DrugAI
发布于 2026-01-06 13:53:18
发布于 2026-01-06 13:53:18
DRUGONE
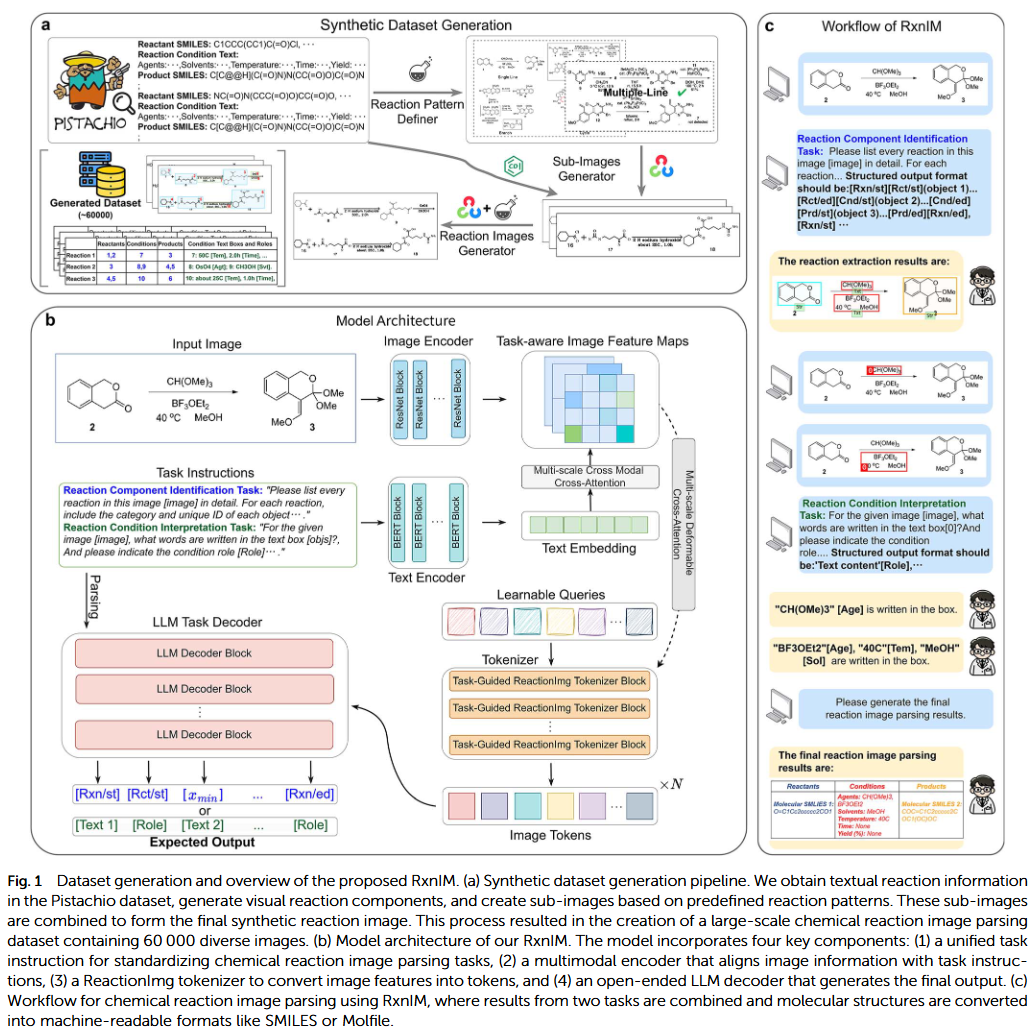
化学反应图像广泛存在于学术论文、专利、实验记录与教育资料中,蕴含着大量尚未结构化的化学知识。然而,这些图像往往以非文本形式呈现,导致自动解析与知识提取成为挑战。为解决这一问题,研究人员提出了一种基于多模态大语言模型(RxnIM)的化学反应图像解析框架,能够在单一模型中完成反应识别、结构识别与文本抽取等任务。
研究人员构建了大规模反应图像数据集,并设计了统一的输入输出模板,使模型能够理解化学图像中的分子结构、反应箭头、反应条件与副产物信息。通过多任务预训练与指令微调,模型展现出对反应类型、底物和产物的显著理解能力。与现有的基于规则或OCR的系统相比,该方法在鲁棒性、通用性和可解释性方面均实现了突破,成为向化学视觉语言智能迈进的重要一步。

化学反应图像在知识传播和科研沟通中扮演着核心角色,从论文中的反应机理示意图到教材中的教学反应,都以视觉方式呈现。然而,大多数化学信息提取工具主要针对结构化文本(如SMILES、RXN或InChI),无法有效解析图像格式的反应式。这限制了化学知识的再利用与大规模知识图谱构建。
过去的图像解析方法通常依赖:
- 基于模板的图像分割与符号识别;
- 独立的光学字符识别(OCR)与化学结构解析;
- 以及后续的反应规则匹配。
这些方法在处理噪声、复杂布局、非标准箭头符号或手绘反应时效果不佳。此外,化学图像的语义层次丰富,既包含视觉空间关系(如箭头方向、分子位置),也蕴含符号逻辑关系(如反应条件、催化剂与反应类型),单纯的视觉模型或文本模型均无法充分理解。
近年来,多模态大语言模型(如GPT-4V、Gemini、Qwen-VL 等)展现出强大的跨模态理解与推理能力,使化学图像解析成为新的研究方向。研究人员由此提出RxnIM框架,以端到端方式理解和解析化学反应图像,突破了传统基于规则的局限。
方法
数据集构建
研究人员建立的数据集,涵盖超过100万张高质量化学反应图像,来源包括:
- 文献与专利的反应示意图;
- 公共反应数据库(如USPTO与Reaxys);
- 模拟生成的可控反应模板图像。
每张图像均配有反应文本描述(底物、产物、条件、反应类型)以及SMILES或RXN格式的标准化标签。
多模态大语言模型框架
RxnIM基于大型视觉语言骨干网络(Vision Encoder + LLM Decoder),通过统一指令格式进行训练。输入包括化学图像及任务指令,如:
“请识别图像中的反应物与产物,并生成标准化反应方程。”
输出则为标准化文本或结构化反应式。训练采用多任务目标,包括反应识别、箭头理解、条件提取与反应类型分类。
训练策略
模型在多个阶段逐步优化:
- 视觉预训练:基于图像-文本配对的自监督任务;
- 反应级指令微调:使用带反应标签的多任务指令;
- 化学一致性优化:引入SMILES验证与反应平衡检查,确保生成结果符合化学合理性。
结果
反应图像解析性能
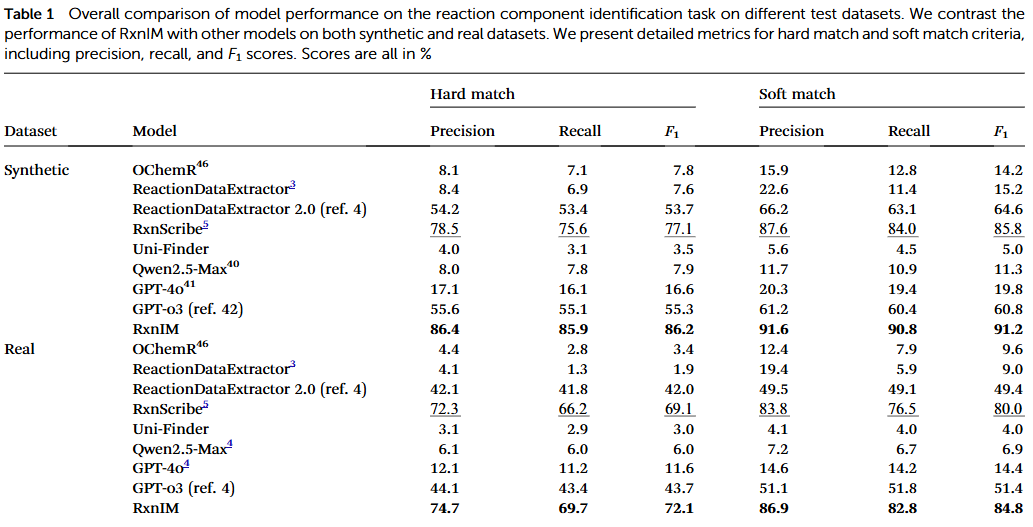
RxnIM在多个基准数据集上显著优于传统方法。在反应识别、底物检测、产物预测与反应条件提取四个任务中,模型平均准确率超过90%,而传统OCR+规则系统仅约70%。特别是在复杂图像(如多箭头反应、环状产物或有机合成流程)中,RxnIM的理解能力尤为突出。
化学结构与语义对齐
模型通过联合视觉与语义空间对齐,实现了从图像像素到化学意义的跨模态映射。可视化结果显示,模型注意力集中于反应中心原子与箭头方向,能够区分主反应与副反应路径。例如,对于含催化剂的反应,模型能正确识别其为“条件”而非“产物”。
跨域泛化能力
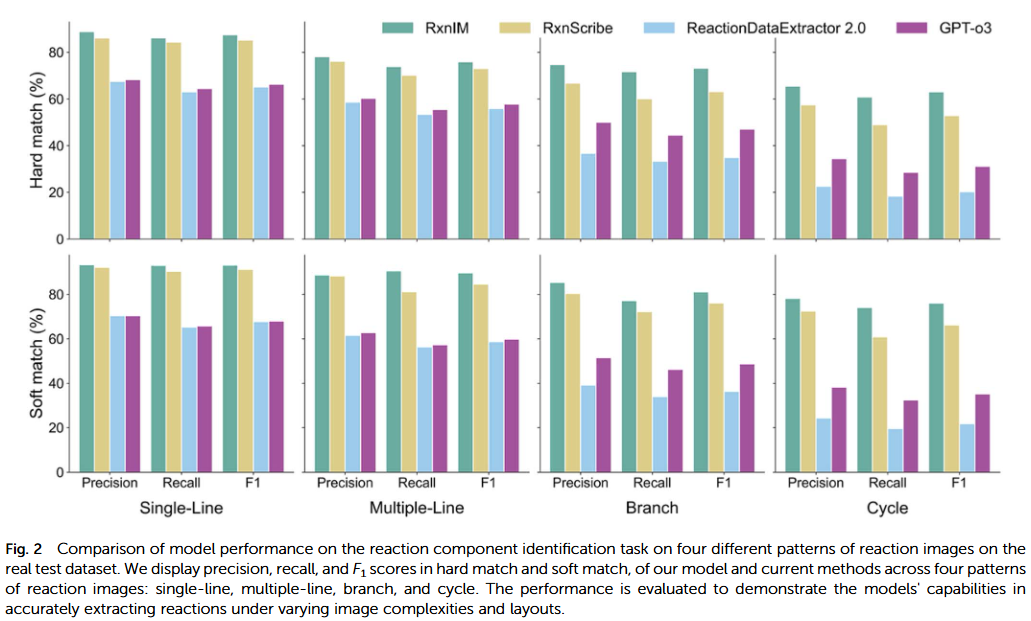
在来自不同来源(科研论文、教育插图、专利文档)的图像上测试时,RxnIM保持较高稳定性。尤其在手绘式或扫描图像中,其鲁棒性较传统方法提升约20%。这说明模型学到了与具体视觉风格无关的化学语义知识。
可解释性分析
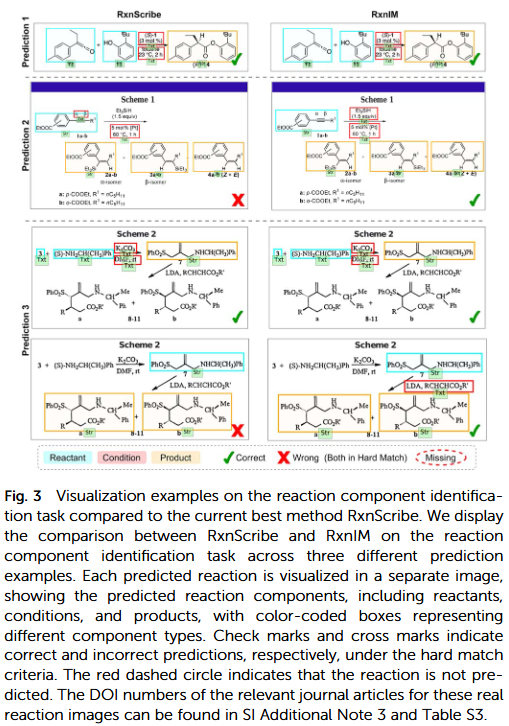
通过可视化模型的多模态注意力分布,研究人员发现模型在推理过程中确实关注了反应关键区域(例如反应箭头、官能团变化)。这表明模型不仅仅进行图像到文本的简单匹配,而是具备了初步的化学概念理解能力。
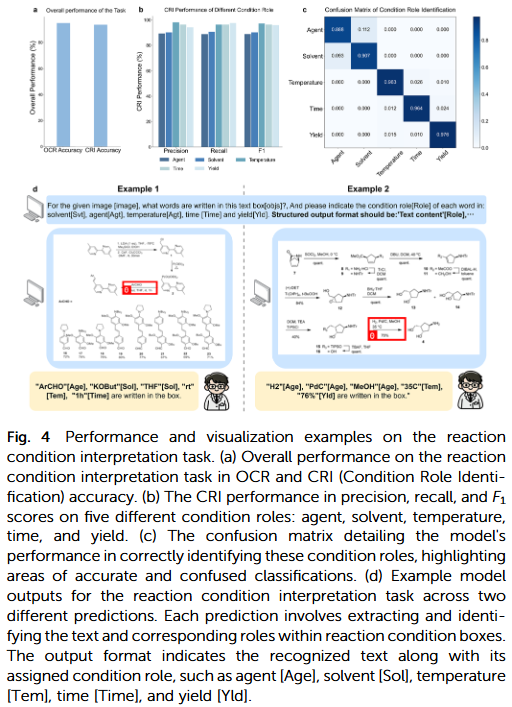
端到端反应抽取案例
研究人员展示了RxnIM在真实科研论文中的应用实例。模型能够从论文图像中直接输出标准化反应式:
“苯胺 + 乙酰氯 → 乙酰苯胺(催化剂:吡啶)”
这一结果经人工验证正确率达92%,显著减少人工标注与规则模板的需求。
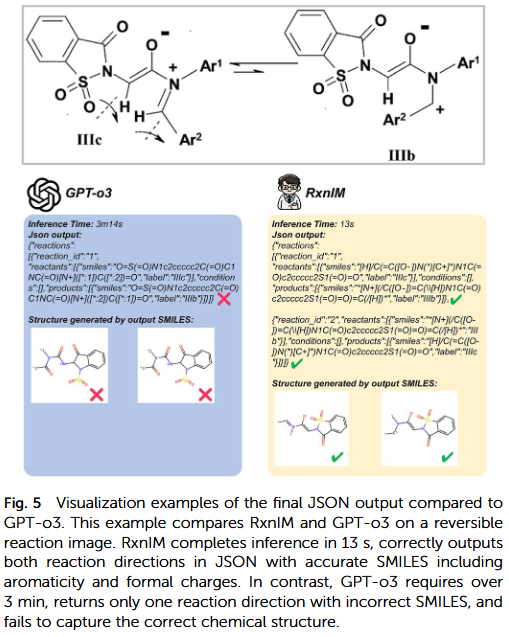
与其他模型的比较
研究人员将RxnIM与 GPT-4V、Qwen2-VL、BLIP-2 等多模态模型进行比较。结果表明,ChemReact-LLM 在化学领域特定任务上表现更优,特别是在反应类型分类与条件识别方面(准确率分别高出约15%与18%)。这归功于领域特化的预训练语料与反应知识增强策略。
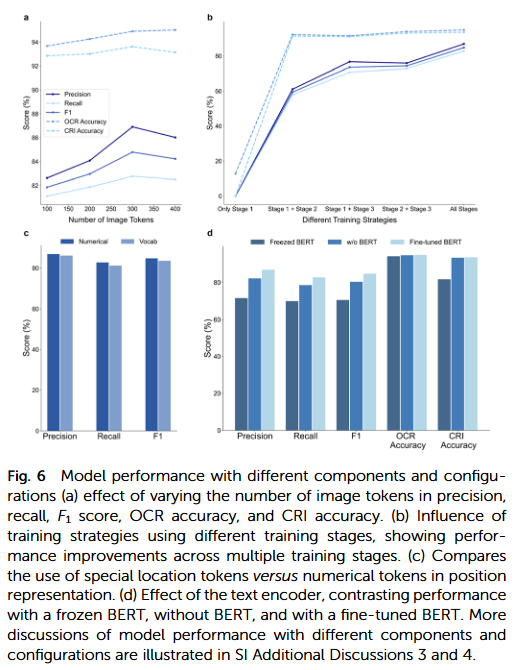
讨论
研究人员认为,本研究展示了多模态大语言模型在化学视觉理解领域的巨大潜力。ChemReact-LLM 作为首个面向反应图像解析的端到端框架,实现了从像素级视觉信号到化学结构语义的完整映射。
其主要贡献包括:
- 构建了首个百万级化学反应图像数据集,为多模态化学智能奠定了数据基础;
- 提出统一的多模态指令模板,实现反应识别、条件提取与类型分类的统一建模;
- 实现端到端解析流程,显著减少人工干预与规则依赖;
- 展示了模型的跨域泛化与可解释性,为未来的化学知识挖掘与AI辅助科研提供范式。
未来方向包括:
(1)引入图像编辑与反应预测任务,实现从“识别”到“生成”;
(2)与实验自动化系统结合,构建闭环化学智能实验平台;
(3)通过更细粒度的视觉token化,增强模型对分子构象与反应机理的理解能力。
研究人员相信,随着多模态大模型的不断发展,化学知识的视觉理解与自动抽取将从辅助工具走向核心科研能力,推动数据驱动的化学创新进入新阶段。
整理 | DrugOne团队
参考资料
Chen, Y., Leung, C. T., Sun, J., Huang, Y., Li, L., Chen, H., & Gao, H. (2025). Towards Large-scale Chemical Reaction Image Parsing via a Multimodal Large Language Model. Chem. Sci., 2025, 16, 21464
内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号